Self-organising map (SOM) analysis
Robert Schlegel
2019-06-04
Last updated: 2019-07-31
workflowr checks: (Click a bullet for more information)-
✔ R Markdown file: up-to-date
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
-
✔ Environment: empty
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
-
✔ Seed:
set.seed(20190513)The command
set.seed(20190513)was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible. -
✔ Session information: recorded
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
-
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility. The version displayed above was the version of the Git repository at the time these results were generated.✔ Repository version: 498909b
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can usewflow_publishorwflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.Ignored files: Ignored: .Rhistory Ignored: .Rproj.user/ Ignored: data/ALL_anom.Rda Ignored: data/ERA5_lhf.Rda Ignored: data/ERA5_lwr.Rda Ignored: data/ERA5_qnet.Rda Ignored: data/ERA5_qnet_anom.Rda Ignored: data/ERA5_qnet_clim.Rda Ignored: data/ERA5_shf.Rda Ignored: data/ERA5_swr.Rda Ignored: data/ERA5_t2m.Rda Ignored: data/ERA5_t2m_anom.Rda Ignored: data/ERA5_t2m_clim.Rda Ignored: data/ERA5_u.Rda Ignored: data/ERA5_u_anom.Rda Ignored: data/ERA5_u_clim.Rda Ignored: data/ERA5_v.Rda Ignored: data/ERA5_v_anom.Rda Ignored: data/ERA5_v_clim.Rda Ignored: data/GLORYS_mld.Rda Ignored: data/GLORYS_mld_anom.Rda Ignored: data/GLORYS_mld_clim.Rda Ignored: data/GLORYS_u.Rda Ignored: data/GLORYS_u_anom.Rda Ignored: data/GLORYS_u_clim.Rda Ignored: data/GLORYS_v.Rda Ignored: data/GLORYS_v_anom.Rda Ignored: data/GLORYS_v_clim.Rda Ignored: data/NAPA_clim_U.Rda Ignored: data/NAPA_clim_V.Rda Ignored: data/NAPA_clim_W.Rda Ignored: data/NAPA_clim_emp_ice.Rda Ignored: data/NAPA_clim_emp_oce.Rda Ignored: data/NAPA_clim_fmmflx.Rda Ignored: data/NAPA_clim_mldkz5.Rda Ignored: data/NAPA_clim_mldr10_1.Rda Ignored: data/NAPA_clim_qemp_oce.Rda Ignored: data/NAPA_clim_qla_oce.Rda Ignored: data/NAPA_clim_qns.Rda Ignored: data/NAPA_clim_qsb_oce.Rda Ignored: data/NAPA_clim_qt.Rda Ignored: data/NAPA_clim_runoffs.Rda Ignored: data/NAPA_clim_ssh.Rda Ignored: data/NAPA_clim_sss.Rda Ignored: data/NAPA_clim_sst.Rda Ignored: data/NAPA_clim_taum.Rda Ignored: data/NAPA_clim_vars.Rda Ignored: data/NAPA_clim_vecs.Rda Ignored: data/OAFlux.Rda Ignored: data/OISST_sst.Rda Ignored: data/OISST_sst_anom.Rda Ignored: data/OISST_sst_clim.Rda Ignored: data/node_mean_all_anom.Rda Ignored: data/packet_all.Rda Ignored: data/packet_all_anom.Rda Ignored: data/packet_nolab.Rda Ignored: data/packet_nolabgsl.Rda Ignored: data/som_all_anom.Rda Ignored: data/som_nolab.Rda Ignored: data/som_nolabgsl.Rda Ignored: data/synoptic_states.Rda Ignored: data/synoptic_vec_states.Rda Untracked files: Untracked: data/node_mean_nolab.Rda Untracked: data/node_mean_nolabgsl.Rda Untracked: output/som_plot_mld_anom.pdf Untracked: output/som_plot_qnet_anom.pdf Untracked: output/som_plot_sst_anom_nogsl.pdf Untracked: output/som_plot_t2m_anom.pdf Untracked: output/som_plot_u10_anom.pdf Untracked: output/som_plot_u_anom.pdf Untracked: output/som_plot_v10_anom.pdf Untracked: output/som_plot_v_anom.pdf Unstaged changes: Modified: code/functions.R Modified: code/workflow.R Modified: data/.gitignore Modified: output/som_plot_sst_anom.pdf Deleted: output/som_plot_uoce_anom.pdf
Expand here to see past versions:
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 498909b | robwschlegel | 2019-07-31 | Re-publish entire site. |
| html | 35987b4 | robwschlegel | 2019-07-09 | Build site. |
| Rmd | 34efa43 | robwschlegel | 2019-07-09 | Added some thinking to the SOM vignette. |
| html | e2f6f42 | robwschlegel | 2019-07-09 | Build site. |
| Rmd | 609cca8 | robwschlegel | 2019-07-09 | Added some thinking to the SOM vignette. |
| html | 81e961d | robwschlegel | 2019-07-09 | Build site. |
| Rmd | 7ff9b8b | robwschlegel | 2019-06-17 | More work on the talk |
| Rmd | b25762e | robwschlegel | 2019-06-12 | More work on figures |
| Rmd | 413bb8b | robwschlegel | 2019-06-12 | Working on pixel interpolation |
| html | c23c50b | robwschlegel | 2019-06-10 | Build site. |
| html | 028d3cc | robwschlegel | 2019-06-10 | Build site. |
| Rmd | c6b3c7b | robwschlegel | 2019-06-10 | Re-publish entire site. |
| Rmd | 1b53eeb | robwschlegel | 2019-06-10 | SOM packet pipeline testing |
| Rmd | 4504e12 | robwschlegel | 2019-06-07 | Working on joining in vector data |
| html | c61a15f | robwschlegel | 2019-06-06 | Build site. |
| Rmd | 44ac335 | robwschlegel | 2019-06-06 | Working on inclusion of vectors into SOM pipeline |
| html | 6dd6da8 | robwschlegel | 2019-06-06 | Build site. |
| Rmd | 07137d9 | robwschlegel | 2019-06-06 | Site wide update, including newly functioning SOM pipeline. |
| Rmd | 990693a | robwschlegel | 2019-06-05 | First SOM result visuals |
| Rmd | 25e7e9a | robwschlegel | 2019-06-05 | SOM pipeline nearly finished |
| Rmd | 4838cc8 | robwschlegel | 2019-06-04 | Working on SOM functions |
| Rmd | 94ce8f6 | robwschlegel | 2019-06-04 | Functions for creating data packets are up and running |
| Rmd | 65301ed | robwschlegel | 2019-05-30 | Push before getting rid of some testing structure |
| html | c09b4f7 | robwschlegel | 2019-05-24 | Build site. |
| Rmd | 5dc8bd9 | robwschlegel | 2019-05-24 | Finished initial creation of SST prep vignette. |
| html | a29be6b | robwschlegel | 2019-05-13 | Build site. |
| html | ea61999 | robwschlegel | 2019-05-13 | Build site. |
| Rmd | f8f28b1 | robwschlegel | 2019-05-13 | Skeleton files |
Introduction
This vignette contains the code used to perform the self-organising map (SOM) analysis on the mean synoptic states created in the Variable preparation vignette. We’ll start by creating custom packets that meet certain experimental criteria before then feeding them into a SOM. We will finish up by creating some cursory visuals of the results. The full summary of the results may be seen in the Node summary vignette.
# Insatll from GitHub
# .libPaths(c("~/R-packages", .libPaths()))
# devtools::install_github("fabrice-rossi/yasomi")
# Packages used in this vignette
library(jsonlite, lib.loc = "../R-packages/")
library(tidyverse) # Base suite of functions
library(ncdf4) # For opening and working with NetCDF files
library(lubridate) # For convenient date manipulation
# library(scales) # For scaling data before running SOM
library(yasomi, lib.loc = "../R-packages/") # The SOM package of choice due to PCI compliance
library(data.table) # For working with massive dataframes
# Set number of cores
doMC::registerDoMC(cores = 50)
# Disable scientific notation for numeric values
# I just find it annoying
options(scipen = 999)
# Set number of cores
doMC::registerDoMC(cores = 50)
# Disable scientific notation for numeric values
# I just find it annoying
options(scipen = 999)
# Individual regions
NWA_coords <- readRDS("data/NWA_coords_cabot.Rda")
# The NAPA variables
NAPA_vars <- readRDS("data/NAPA_vars.Rda")
# Corners of the study area
NWA_corners <- readRDS("data/NWA_corners.Rda")
# Create smaller corners to use less RAM
# This also better matches the previous South African work
# The Tasmania work had corners of roughly 2 degrees greater than the study area
# NWA_corners_sub <- c(NWA_corners[1]+8, NWA_corners[2]-8, NWA_corners[3]+8, NWA_corners[4]-8)
# The base map
map_base <- ggplot2::fortify(maps::map(fill = TRUE, col = "grey80", plot = FALSE)) %>%
dplyr::rename(lon = long) %>%
mutate(group = ifelse(lon > 180, group+9999, group),
lon = ifelse(lon > 180, lon-360, lon)) %>%
select(-region, -subregion)
# The grid that will convert the tri-polar coordinates to cartesian
# NB: This file was created in the 'tikoraluk' project
# load("data/lon_lat_NAPA_OISST.Rdata")
# Change to fit with this project
# lon_lat_NAPA_OISST <- lon_lat_NAPA_OISST %>%
# dplyr::select(-lon, -lat, -dist, -nav_lon_corrected) %>%
# dplyr::rename(lon = nav_lon, lat = nav_lat) %>%
# mutate(lon = round(lon, 4),
# lat = round(lat, 4)) %>%
# mutate(lon_O = ifelse(lon_O > 180, lon_O-360, lon_O))Tailored data packets
In this last stage before running our SOM analyses we will create data packets that can be fed directly into the SOM algorithm. These data packets will vary based on the exclusion of certain regions in the study area. In the first run of this analysis on the NAPA model data it was found that the inclusion of the Labrador Sea complicated the results quite a bit. It is also unclear whether or not the Gulf of St Lawrence region should be included in the analysis. While creating whatever packets we desire we will also be converting them into the super-wide matrix format that the SOM model desires.
Unnest synoptic state packets
Up first we must simply load and unnest the synoptic state packets made previously.
# Load the synoptic states data packet
system.time(
synoptic_states <- readRDS("data/synoptic_states.Rda")
) # 3 seconds
# Unnest the synoptic data
system.time(
synoptic_states_unnest <- synoptic_states %>%
select(region, event_no, synoptic) %>%
unnest()
) # 8 secondsCustom packets
With all of our data ready we may now trim them as we see fit before saving them for the SOM.
# The study area size when the Labrador region is excluded
NWA_coords_nolab <- NWA_coords %>%
filter(region != "ls")
# The study area size when the Labrador and GSL regions are excluded
NWA_coords_nolabgsl <- NWA_coords %>%
filter(!region %in% c("ls", "gsl"))
# Test visuals of reduced study areas
synoptic_states[1,] %>%
unnest() %>%
filter(lat <= round(max(NWA_coords_nolabgsl$lat))+0.5) %>%
ggplot(aes(x = lon, y = lat)) +
geom_raster(aes(fill = sst_anom)) +
geom_polygon(data = NWA_coords_nolabgsl, aes(colour = region), fill = NA)
# Function for casting wide the custom packets
create_packet <- function(df){
# Cast the data to a single row
res <- data.table::data.table(df) %>%
reshape2::melt(id = c("region", "event_no", "lon", "lat"),
measure = c(colnames(.)[-c(1:4)]),
variable.name = "var", value.name = "val") %>%
dplyr::arrange(var, lon, lat) %>%
unite(coords, c(lon, lat, var), sep = "BBB") %>%
unite(event_ID, c(region, event_no), sep = "BBB") %>%
reshape2::dcast(event_ID ~ coords, value.var = "val")
# Remove columns (pixels) with missing data
res_fix <- res[,colSums(is.na(res))<1]
return(res_fix)
}
# Packet for entire study region
system.time(
packet_all <- create_packet(synoptic_states_unnest)
) # xxx seconds
saveRDS(packet_all, "data/packet_all.Rda")
# Exclude Labrador region
system.time(
packet_nolab <- synoptic_states_unnest %>%
filter(region != "ls",
lat <= round(max(NWA_coords_nolab$lat))+0.5) %>%
create_packet()
) # 128 seconds
saveRDS(packet_nolab, "data/packet_nolab.Rda")
# Exclude Labrador and Gulf of St Lawrence regions
system.time(
packet_nolabgsl <- synoptic_states_unnest %>%
filter(!region %in% c("ls", "gsl"),
lat <= round(max(NWA_coords_nolabgsl$lat))+0.5) %>%
create_packet()
) # xxx seconds
saveRDS(packet_nolabgsl, "data/packet_nolabgsl.Rda")Run SOM models
Now that we have our data packets to feed the SOM, we need a function that will ingest them and produce results for us.
# Function for calculating SOMs using PCI
# NB: 4x4 produced one empty cell and one cell with only one event
# So the default size has been reduced to 4x3
som_model_PCI <- function(data_packet, xdim = 4, ydim = 3){
# Create a scaled matrix for the SOM
# Cancel out first column as this is the reference ID of the event per row
data_packet_matrix <- as.matrix(scale(data_packet[,-1]))
# Create the grid that the SOM will use to determine the number of nodes
som_grid <- somgrid(xdim = xdim, ydim = ydim, topo = "hexagonal")
# Run the SOM with PCI
som_model <- batchsom(data_packet_matrix,
somgrid = som_grid,
init = "pca",
max.iter = 100)
return(som_model)
}With the function sorted, we now feed the data.
# The SOM on the entire study area
# NB: Not running for some reason...
# Possibly due to a column with no range in values
# Not too worried about it as this one isn't being used
# packet_all <- readRDS("data/packet_all.Rda")
# system.time(som_all <- som_model_PCI(packet_all)) # 201 seconds
# saveRDS(som_all, file = "data/som_all.Rda")
# The SOM excluding the Labrador Sea region
packet_nolab <- readRDS("data/packet_nolab.Rda")
system.time(som_nolab <- som_model_PCI(packet_nolab)) # 78 seconds
saveRDS(som_nolab, file = "data/som_nolab.Rda")
# The SOM excluding the Labrador Sea and Gulf of St Lawrence regions
packet_nolabgsl <- readRDS("data/packet_nolabgsl.Rda")
system.time(som_nolabgsl <- som_model_PCI(packet_nolabgsl)) # 75 seconds
saveRDS(som_nolabgsl, file = "data/som_nolabgsl.Rda")
# A 9 node SOM
# A 16 node SOM
system.time(som_nolab <- som_model_PCI(packet_nolab)) # 78 seconds
saveRDS(som_nolab, file = "data/som_nolab.Rda")
# A SOM without moderate eventsUnpack SOM results
We will create two functions below that will be useful for unpacking the SOM results.
# Function for determining node indexes
# testers...
# data_packet <- all_anom; som_output <- som_all_anom
event_node_index <- function(data_packet, som_output){
# Count the number of events per node
node_count <- as.data.frame(table(som_output$classif)) %>%
dplyr::rename(node = Var1,
count = Freq) %>%
mutate(node = as.numeric(as.character(node)))
# Create a more complete data.frame of info
event_node <- data.frame(event_ID = data_packet[,"event_ID"],
node = som_output$classif) %>%
separate(event_ID, into = c("region", "event_no"), sep = "BBB") %>%
left_join(node_count, by = "node")
# NB: This is potentially where the season of the event would be inserted
return(event_node)
}
# Function for unpacking som results and creating
# mean results from initial data frame based on node clustering
# testers...
# data_packet <- packet_nolab; som_output <- som_nolab
som_unpack_mean <- function(data_packet, som_output){
# Determine which event goes in which node and melt
data_packet_long <- data.frame(event_ID = data_packet[,"event_ID"],
node = som_output$classif) %>%
separate(event_ID, into = c("region", "event_no"), sep = "BBB") %>%
cbind(data_packet[,-1]) %>%
data.table() %>%
reshape2::melt(id = c("region", "event_no", "node"),
measure = c(colnames(.)[-c(1:3)]),
variable.name = "variable", value.name = "value")
# Create the mean values that serve as the unscaled results from the SOM
var_unscaled <- data_packet_long[, .(val = mean(value, na.rm = TRUE)),
by = .(node, variable)] %>%
separate(variable, into = c("lon", "lat", "var"), sep = "BBB") %>%
dplyr::arrange(node, var, lon, lat) %>%
mutate(lon = as.numeric(lon),
lat = as.numeric(lat))
return(var_unscaled)
}And now we unpack the SOM results.
# Load data packets
# packet_all <- readRDS("data/packet_all.Rda")
packet_nolab <- readRDS("data/packet_nolab.Rda")
packet_nolabgsl <- readRDS("data/packet_nolabgsl.Rda")
# Load SOM packets
# som_all <- readRDS("data/som_all.Rda")
som_nolab <- readRDS("data/som_nolab.Rda")
som_nolabgsl <- readRDS("data/som_nolabgsl.Rda")
# Determine node index
# node_index_all <- event_node_index(packet_all, som_all)
node_index_nolab <- event_node_index(packet_nolab, som_nolab)
node_index_nolabgsl <- event_node_index(packet_nolabgsl, som_nolabgsl)
## Create and save mean synoptic states per node
# All
# node_mean_all <- som_unpack_mean(packet_all, som_all)
# saveRDS(node_mean_all, "data/node_mean_all.Rda")
# No Labrador Sea
node_mean_nolab <- som_unpack_mean(packet_nolab, som_nolab)
# saveRDS(node_mean_nolab, "data/node_mean_nolab.Rda")
# No Labrador Sea or Gulf of St Lawrence
node_mean_nolabgsl <- som_unpack_mean(packet_nolabgsl, som_nolabgsl)
# saveRDS(node_mean_nolabgsl, "data/node_mean_nolabgsl.Rda")Visualise SOM results
First up the functions for visualising the unpacked results.
# Ease of life function
som_node_visualise <- function(sub_var = "sst_anom",
node_data = node_mean_nolab,
node_index = node_index_nolab){
# Subset data
node_data_sub <- node_data %>%
filter(var == sub_var)
# Create plot
som_panel_plot <- ggplot(node_data_sub, aes(x = lon, y = lat)) +
# geom_point(aes(colour = val)) +
geom_raster(aes(fill = val)) +
geom_polygon(data = map_base, aes(group = group), show.legend = F) +
geom_label(data = node_index, aes(x = -60, y = 35, label = paste0("n = ",count))) +
# geom_polygon(data = NWA_coords, aes(group = region, fill = region, colour = region), alpha = 0.1) +
coord_cartesian(xlim = c(max(node_data$lon), min(node_data$lon)),
ylim = c(max(node_data$lat), min(node_data$lat)),
expand = F) +
scale_fill_gradient2(low = "blue", high = "red") +
# scale_colour_viridis_c(option = viridis_option) +
labs(x = NULL, y = NULL, fill = sub_var) +
facet_wrap(~node, ncol = 4) +
theme(legend.position = "bottom")
return(som_panel_plot)
}And now we create a PDF for each of the 12 nodes for each variable individually.
# SST
# NB: Comparing the SST anomaly results from the two restricted study areas
plot_sst_anom <- som_node_visualise()
plot_sst_anom_nogsl <- som_node_visualise(node_data = node_mean_nolabgsl,
node_index = node_index_nolabgsl)
# plot_sst_anom
# plot_sst_anom_nogsl
ggsave(plot_sst_anom, filename = "output/som_plot_sst_anom.pdf", height = 9, width = 13)
ggsave(plot_sst_anom, filename = "output/som_plot_sst_anom.png", height = 9, width = 13)
ggsave(plot_sst_anom_nogsl, filename = "output/som_plot_sst_anom_nogsl.pdf", height = 9, width = 13)
# Air temperature (t2m)
plot_t2m_anom <- som_node_visualise("t2m_anom")
# plot_t2m_anom
ggsave(plot_t2m_anom, filename = "output/som_plot_t2m_anom.pdf", height = 9, width = 13)
# Net downward heat flux (qnet)
plot_qnet_anom <- som_node_visualise("qnet_anom")
# plot_qnet_anom
ggsave(plot_qnet_anom, filename = "output/som_plot_qnet_anom.pdf", height = 9, width = 13)
# Surface wind U (u10)
plot_u10_anom <- som_node_visualise("u10_anom")
# plot_u10_anom
ggsave(plot_u10_anom, filename = "output/som_plot_u10_anom.pdf", height = 9, width = 13)
# Surface wind V (v10)
plot_v10_anom <- som_node_visualise("v10_anom")
# plot_v10_anom
ggsave(plot_v10_anom, filename = "output/som_plot_v10_anom.pdf", height = 9, width = 13)
# Ocean current U (u)
plot_u_anom <- som_node_visualise("u_anom")
# plot_uoce_anom
ggsave(plot_u_anom, filename = "output/som_plot_u_anom.pdf", height = 9, width = 13)
# Ocean current V (v)
plot_v_anom <- som_node_visualise("v_anom")
# plot_v_anom
ggsave(plot_v_anom, filename = "output/som_plot_v_anom.pdf", height = 9, width = 13)
# Mixed Layer Depth (mld)
plot_mld_anom <- som_node_visualise("mld_anom")
# plot_mld_anom
ggsave(plot_mld_anom, filename = "output/som_plot_mld_anom.pdf", height = 9, width = 13)Juggling back and forth between the SST anomaly photos with and without the Gulf of St Lawrence it first appears that they are very different, but this is mostly due to the top and bottom rows of nodes being flipped. The actual differences are much more muted and the patterns tend to hold. The patterns appear more crisp in the larger study extent (no Labrador). This is likely because the inclusion of the shallow GSL gives more power. to the atmospheric variables to compete with the Gulf Stream. For this reason we are going to proceed with the inclusion of the Gulf of St Lawrence.
See the files in the output/ folder in the GitHub repo for this project. They aren’t all shown here because they take a bit too long to render. But the following shows what the SST anomaly nodes look like.
plot_sst_anom <- som_node_visualise("sst_anom")
plot_sst_anom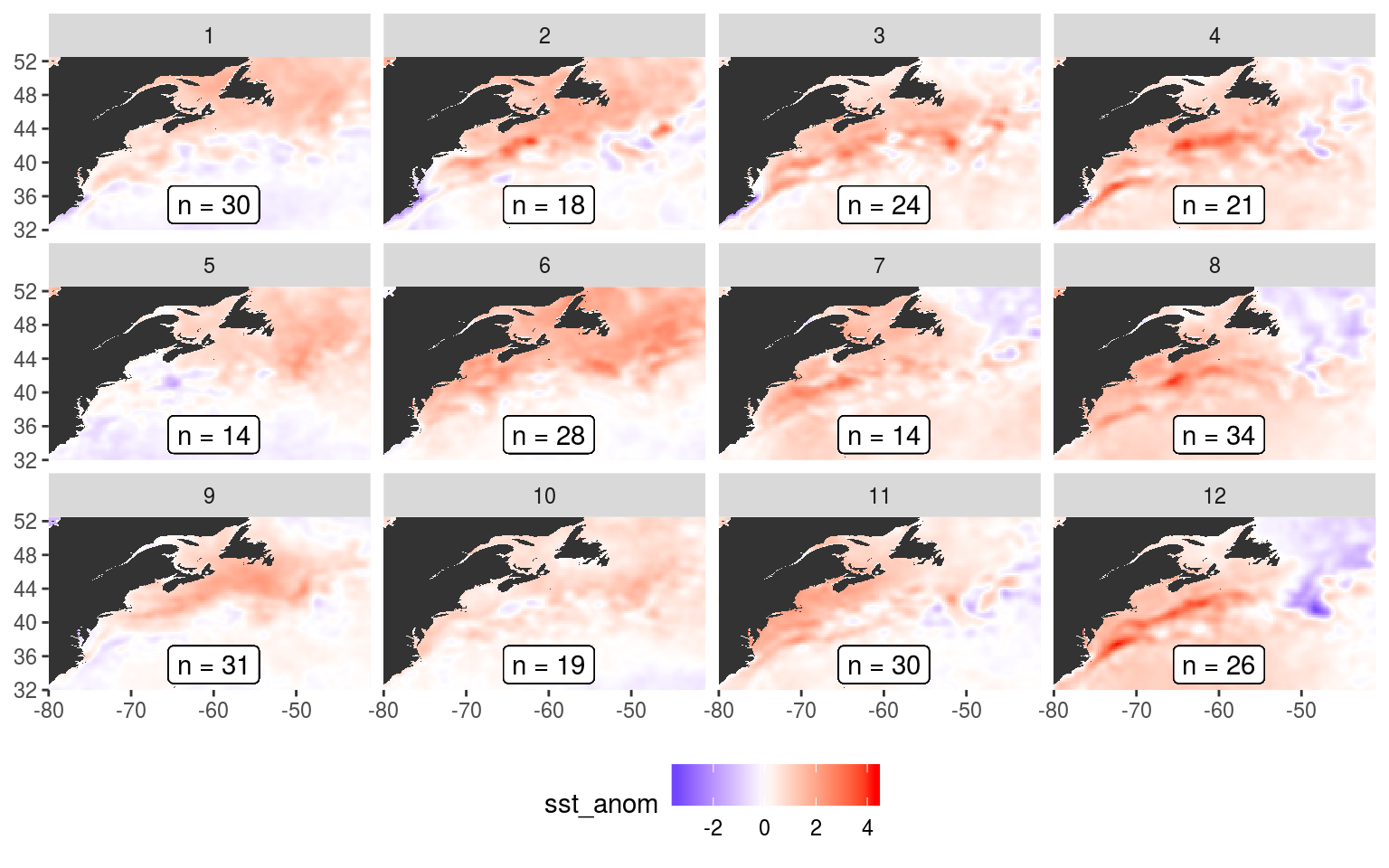
Expand here to see past versions of plot-sst-anom-1.png:
| Version | Author | Date |
|---|---|---|
| 81e961d | robwschlegel | 2019-07-09 |
| 028d3cc | robwschlegel | 2019-06-10 |
Up next in the Node summary vignette we will show the results in more depth. The code used to create the summary figures may be found in the Figures vignette.
Musings
Possible mechanisms
“Finally, Shearman and Lentz (2010) showed that century-long ocean warming trends observed along the entire northeast U.S. coast are not related to local atmospheric forcing but driven by atmospheric warming of source waters in the Labrador Sea and the Arctic, which are advected into the region.” (Richaud et al., 2016)
Downwelling
Net heatflux (OAFlux) doesn’t line up perfectly with seasonal SST signal, but is very close, with heat flux tending to lead SST by 2 – 3 months (Richaud et al., 2016). It is therefore likely one of the primary drivers of SST and should therefore be strongly considered when constructing SOMs.
There is almost no seasonal cycle for slope waters in any of the regions (Richaud et al., 2016).
More ideas
It would be interesting to see if the SOM outputs differ in any meaningful ways when only data from the first half of the study time period are used compared against the second half.
The output of the SOMs could likely be more meaningfully conveyed from the point of view of the regions. What I mean by this is to take the summary of the nodes, convey them into a table, and then use that table to inform a series of information bits that is focused around each region. Some sort of interactive visual may be useful for this. Showing the percentage that each region has in each node would be a good start. This would allow for a more meaningful further explanation for which drivers affect which regions during which seasons and over which years.
Once this summary is worked out it would then follow that the same analysis be run 1, 2, 3 etc. months in the past and see what the same information format provides w.r.t. a sort of predictive capacity. All of this can then be used to check other data products with a more focused lens in order to maximise the utility of the output.
References
Richaud, B., Kwon, Y.-O., Joyce, T. M., Fratantoni, P. S., and Lentz, S. J. (2016). Surface and bottom temperature and salinity climatology along the continental shelf off the canadian and us east coasts. Continental Shelf Research 124, 165–181.
Session information
sessionInfo()R version 3.6.1 (2019-07-05)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Ubuntu 16.04.5 LTS
Matrix products: default
BLAS: /usr/lib/openblas-base/libblas.so.3
LAPACK: /usr/lib/libopenblasp-r0.2.18.so
locale:
[1] LC_CTYPE=en_CA.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_CA.UTF-8 LC_COLLATE=en_CA.UTF-8
[5] LC_MONETARY=en_CA.UTF-8 LC_MESSAGES=en_CA.UTF-8
[7] LC_PAPER=en_CA.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_CA.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] bindrcpp_0.2.2 data.table_1.11.6 yasomi_0.3
[4] proxy_0.4-22 e1071_1.7-0 lubridate_1.7.4
[7] ncdf4_1.16 forcats_0.3.0 stringr_1.3.1
[10] dplyr_0.7.6 purrr_0.2.5 readr_1.1.1
[13] tidyr_0.8.1 tibble_1.4.2 ggplot2_3.0.0
[16] tidyverse_1.2.1 jsonlite_1.6
loaded via a namespace (and not attached):
[1] tidyselect_0.2.4 reshape2_1.4.3 haven_1.1.2
[4] lattice_0.20-35 colorspace_1.3-2 htmltools_0.3.6
[7] yaml_2.2.0 rlang_0.2.2 R.oo_1.22.0
[10] pillar_1.3.0 glue_1.3.0 withr_2.1.2
[13] R.utils_2.7.0 doMC_1.3.5 modelr_0.1.2
[16] readxl_1.1.0 foreach_1.4.4 bindr_0.1.1
[19] plyr_1.8.4 munsell_0.5.0 gtable_0.2.0
[22] workflowr_1.1.1 cellranger_1.1.0 rvest_0.3.2
[25] R.methodsS3_1.7.1 codetools_0.2-15 evaluate_0.11
[28] labeling_0.3 knitr_1.20 parallel_3.6.1
[31] class_7.3-14 broom_0.5.0 Rcpp_0.12.18
[34] backports_1.1.2 scales_1.0.0 hms_0.4.2
[37] digest_0.6.16 stringi_1.2.4 grid_3.6.1
[40] rprojroot_1.3-2 cli_1.0.0 tools_3.6.1
[43] maps_3.3.0 magrittr_1.5 lazyeval_0.2.1
[46] crayon_1.3.4 whisker_0.3-2 pkgconfig_2.0.2
[49] xml2_1.2.0 iterators_1.0.10 assertthat_0.2.0
[52] rmarkdown_1.10 httr_1.3.1 rstudioapi_0.7
[55] R6_2.2.2 nlme_3.1-137 git2r_0.23.0
[58] compiler_3.6.1 This reproducible R Markdown analysis was created with workflowr 1.1.1