给定一个整数n以及一个二维整数序列arr,arr中的数值介于[0,n)之间,现要求从arr中挑选出部分子序列,使得这些子序列的并集范围囊括[0,n),问满足条件的最小子序列数量为几?
1 | arr = [[0, 2], |
遍历所有的子序列的组合,找出其中所有满足条件的子序列,最后输出其中最小数量即可。显然可以采用递归来进行深度遍历:
1 | n=3 |
问题需要的只是最小组合中的子序列数量,稍稍改一下上述代码:
1 | all_groups_num=[] |
sergfsm利用itertools.combinations(iterable,r)函数,其将创建一个迭代器,返回参数iterable中所有长度为r的子序列组合(譬如combinations('ABC',2)将返回[('A', 'B'), ('A', 'C'), ('B', 'C')]),可以说相当契合本题题意了:
1 | from itertools import combinations |
从最小的组合数开始寻找,一旦符合条件,就停止寻找,而我的递归解法则需要穷尽所有组合
给定一个二维数组arr,判断是否是二维回文数组(Sator Square)?
1 | v |
1 | import numpy as np |
参考RazNaot的解法,实际上,前面所说的判断规则可以进一步转变为:
- 二维数组旋转180度后还是自身(第
i列等于倒数第i列的倒序,或者,第i行等于倒数第i行的倒序) - 二维数组转置后还是自身(第
i列等于第i行)
1 | def judge(a): |
ZozoFouchtra提供了上述写法的简写:
1 | def judge(a): |
给定一个序列arr,将其中的奇数按升序排列,偶数保持不动
1 | [7, 1] => [1, 7] |
1 | import numpy as np |
jgdodson的解法:
1 | def sort_array(arr): |
MFreidank的解法(同上):
1 | def sort_array(source_array): |
给定一个二元组列表,其中每一个二元组(a,c)代表直线斜截式方程y=ax+c的两个参数a(斜率)和c(直线在y轴上的截距),要求所有直线的绝对值方程的和函数,一个分段函数
1 | 给定一个二元组列表[(0.25,-3),(-1,1)],也就是一组直线: |
问题本身很简单,就是求分段函数嘛,首先找出所有的零点,也就是分段点,然后再分别求出每一段的(直线)函数,没什么好说的:
1 | inf=float('inf') |
稍稍简化一下写法,并且使用decimal.Decimal做精确浮点数计算:
1 | from decimal import Decimal |
这也是一开始尝试提交的代码,测试过了,但是提交报错:Execution Timed Out。因此我又用numpy矩阵运算重写了上述代码:
1 | from decimal import Decimal |
结果仍然是Execution Timed Out。然后我将expand()函数的第一行代码注释掉,就ok了…
我的提交
Blind4Basics提供的解法:
1 | def expand(arr, inf=float('inf')): |
略,没看懂
给定一个长度为4的倍数的正整数序列arr=[x1,x2,x3,x4,⋯,xm,xm+1],记P=(x12+x22)×(x32+x42)×⋯×(xm2+xm+12),要求满足条件P=A2+B2的未知参数A和B(注:A,B为非负整数,满足条件的A和B可能有多对,只要求出任意一对即可)
1 | arr = [2, 1, 3, 4],于是P=125 |
这不就是一个多元方程根求解的问题嘛,给定n个n元方程,f1(x1,x2,...,xn)=0、f2(x1,x2,...,xn)=0、…、fn(x1,x2,...,xn)=0,根据牛顿迭代法,将fi(x1,x2,...,xn)(i=1,2,...,n)在X0(记X=[x1,x2,...,xn]T)位置处做一阶泰勒展开并令其为0,得到:fi(X)=fi(X0)+∇fi(X0)T(X−X0)=0(i=1,2,...,n),于是有⎣⎢⎢⎢⎢⎡f1(X0)f2(X0)⋮fn(X0)⎦⎥⎥⎥⎥⎤+⎣⎢⎢⎢⎢⎡∇f1(X0)T∇f2(X0)T⋮∇fn(X0)T⎦⎥⎥⎥⎥⎤(X−X0)=⎣⎢⎢⎢⎢⎡00⋮0⎦⎥⎥⎥⎥⎤,可得迭代公式X:=X−⎣⎢⎢⎢⎢⎡∇f1(X)T∇f2(X)T⋮∇fn(X)T⎦⎥⎥⎥⎥⎤−1⎣⎢⎢⎢⎢⎡f1(X)f2(X)⋮fn(X)⎦⎥⎥⎥⎥⎤
牛顿法用于求解方程f(x)=0在x=x0附近的根(也称为切线法),设x∗是方程f(x)=0的根,选取x0作为其初始近似值,迭代的目的就是从x0开始不断地去接近x∗
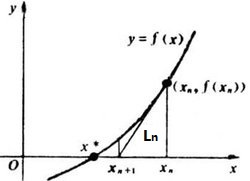
具体的,过点(x0,f(x0))作曲线y=f(x)的切线L0,有L0:y=f′(x0)(x−x0)+f(x0),L0与x轴交点的横坐标记为x1=x0−f′(x0)f(x0),称x1是x∗的一次近似值,再过点(x1,f(x1))作曲线y=f(x)的切线L1,求其与x轴交点的横坐标,并记为:x2=x1−f′(x1)f(x1),称x2是x∗的二次近似值,…,重复该过程得到x∗的近似值序列{xn},且有递推关系:xn+1=xn−f′(xn)f(xn),称xn+1是x∗的n+1次近似值,当n很大的时候,将得到一个无限接近根x∗的近似精确解
看个例子,求解x3+2x2+3x+4=0在x=1附近的根:
1 | #include<stdio.h> |
如上,主要是写出迭代关系式,用于求近似值序列{xn}的下一项(见上述代码中的next()函数),另外为了控制迭代过程的结束,通常会设置一个精度值eps,显然这个值越小,求解也越精确,有结束条件:∣xn+1−xn∣<eps
牛顿迭代法的理论依据是什么?将f(x)在估计点x0处展开为泰勒级数:f(x)=f(x0)+f′(x0)(x−x0)+2!f′′(x0)(x−x0)2+⋯+n!f(n)(x0)(x−x0)n+Rn(x),取其线性部分(泰勒展开的前两项),即在x→x0时有f(x)=f(x0)+f′(x0)(x−x0)(无限接近)成立,此时要求f(x)=0的解,即求f(x0)+f′(x0)(x−x0)=0的解,即得下一个估计点x=x0−f′(x0)f(x0),所以有迭代公式x:=x−f′(x)f(x)
再看个例子,求平方根y=x,x是给定的常数值,我们还是改写一下形式吧,将x记作a,y记作x,形式变成x=a,即问方程x2−a=0的根,立即写出迭代关系式:xn+1=xn−2xnxn2−a,即:xn+1=2xn+2xna:
1 | #include<stdio.h> |
借助牛顿法求解函数的极小值,对于函数y=f(x),其极小值点x∗满足f′(x∗)=0(必要条件,反之不成立),只要找到这个x∗,那么极小值也就得到了(f(x∗)),问题归结于求方程f′(x)=0的根,根据上面的结论,可以轻易得到迭代公式:x:=x−f′′(x)f′(x)。类似的,其理论依据仍可以由泰勒展开解释,现对f(x)在估计点x0处作二阶泰勒展开,当x→x0时有f(x)=f(x0)+f′(x0)(x−x0)+2!f′′(x0)(x−x0)2(无限接近)成立,根据极小值点的必要条件,有f′(x)=f′(x0)+f′′(x0)(x−x0)=0,x=x0−f′′(x0)f′(x0),所以有迭代公示x:=x−f′′(x)f′(x)
如果是多元函数,设y=f(x1,x2,...,xn),在估计点X0处的二阶泰勒展开推广为:f(X)=f(X0)+∇f(X0)T(X−X0)+2(X−X0)T∇2f(X0)(X−X0),我们用大写的X、X0表示多维下的“点”,其由n个分量构成,形如X=[x1x2...xn]T,∇f是f的梯度(gradient)向量,∇f=[∂x1∂f∂x2∂f...∂xn∂f]T,∇2f是f的Hessian矩阵,其定义为:∇2f=⎣⎢⎢⎢⎢⎢⎢⎡∂x12∂2f∂x2∂x1∂2f⋮∂xn∂x1∂2f∂x1∂x2∂2f∂x22∂2f⋮∂xn∂x2∂2f⋯⋯⋱⋯∂x1∂xn∂2f∂x2∂xn∂2f⋮∂xn2∂2f⎦⎥⎥⎥⎥⎥⎥⎤n×n,若简记∇f、∇2f为g、H,则分别表示在X0点处所计算得到的实值梯度向量和实值Hessian矩阵∇f(X0)、∇2f(X0)可简记为g(X0)、H(X0),同样的,极小值点X∗满足必要条件:∇f(X∗)=0,即在X∗点处各个方向上的偏导数俱为0,对上述二阶泰勒展开式两边分别取∇并令其等于0,即有g(X0)+H(X0)(X−X0)=0,若矩阵H(X0)可逆,有:X=X0−H−1(X0)g(X0),于是有迭代公式X:=X−H−1(X)g(X)
看个简单的多元一次方程组的求解示例(其实多元一次方程组{a1ix1+a2ix2+⋯+anixn=bi}i=1,2,...,n的求解根本用不着牛顿迭代,直接有⎣⎢⎢⎢⎢⎡x1x2⋮xn⎦⎥⎥⎥⎥⎤=⎣⎢⎢⎢⎢⎡a11a12⋮a1na21a22⋮a2n⋯⋯⋱⋯an1an2⋮ann⎦⎥⎥⎥⎥⎤−1⎣⎢⎢⎢⎢⎡b1b2⋮bn⎦⎥⎥⎥⎥⎤):
1 | import numpy as np |
回到本题,虽然给的不是方程组,无法求逆,但可以用伪逆代替,然而由于只有一个方程,最终问题转变为了求满足A2+B2=P且A=B的解,所得更是浮点数:
1 | import numpy as np |
没办法,只好穷举实现:
1 | import numpy as np |
测试报错:MemoryError: Unable to allocate 1.25 PiB for an array with shape (8521545, 20572828) and data type int64,待分配的数组超出限制,修改:
1 | import numpy as np |
测试通过,提交又出错:Execution Timed Out,我™透了,我蠢到这种地步了么
好像看不到答案…
设U(n,x)=x+2x2+3x3+⋯+nxn,且n→+∞,现给定s=U(n,x),问x为多少(x自然是在收敛域中,很明显,x<1)?
1 | 给定 s = 2,则 x = 0.5 |
这是一个简单的数列求和,记S=x+2x2+3x3+⋯+nxn,两边乘x,xS=x2+2x3+3x4+⋯+nxn+1,前式减后式,有(1−x)S=x+x2+x3+⋯+xn−nxn+1,由于x<1,n无穷大时,nxn+1趋向于0,所以等号右边的数列和直接视为x+x2+x3+⋯+xn,再记T=x+x2+x3+⋯+xn,两边乘x,xT=x2+x3+x4+⋯+xn+1,前式减后式,有T=1−xx−xn+1,当x<1时,T=1−xx,于是S=(1−x)2x,将S视为常数,问题变为求解一元二次方程Sx2−(2S+1)x+S=0的根,可根据之前介绍的牛顿迭代法计算,或者求根公式,此处采用牛顿法:
1 | def solve(m): |
Sherrbethead的求根公式解法:
1 | def solve(m): |
公司要给n个人发奖金[s1,s2,...,sn],总金额为s,为了保证公平,现依据每个人的缺勤天数[a1,a2,...,an]决定各自奖金的多寡,满足a1s1=a2s2=⋯=ansn,要求[s1,s2,...,sn]
1 | 譬如总金额s为$851,A、B、C三个人缺勤天数分别为18、15、12,公司给A、B、C各自发放的金额为$230、$276、$345,其满足所要求的两个条件: |
这个问题很简单,根据题意,不就相当于给出了n个n元方程么:⎩⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎧s1+s2+⋯+sn=sa1s1−a2s2=0a2s2−a3s3=0⋮an−1sn−1−ansn=0,接下来就不用多说了:
1 | import numpy as np |
测试通过,提交出错:Execution Timed Out (12000 ms),我又透了,应该是通过其他方法求解?求逆太耗时?
…
输入一个字符串,打印出该字符串中字符的所有排列。你可以以任意顺序返回这个字符串数组,但里面不能有重复元素
1 | 输入:s = "abc" |
排列组合,老套路了:
1 | from typing import List |
关于重复元素的去除,参考了Krahets的解题图释,代码更新如下:
1 | from typing import List |
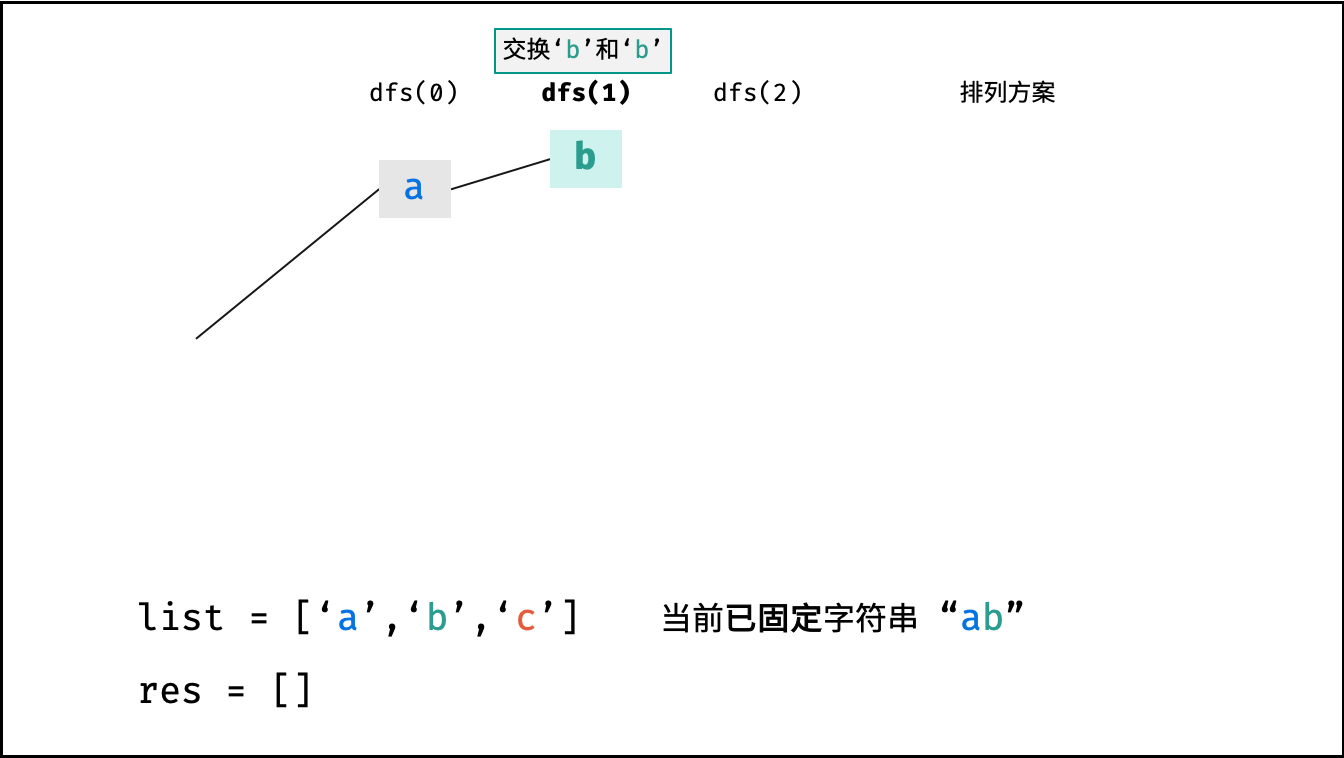
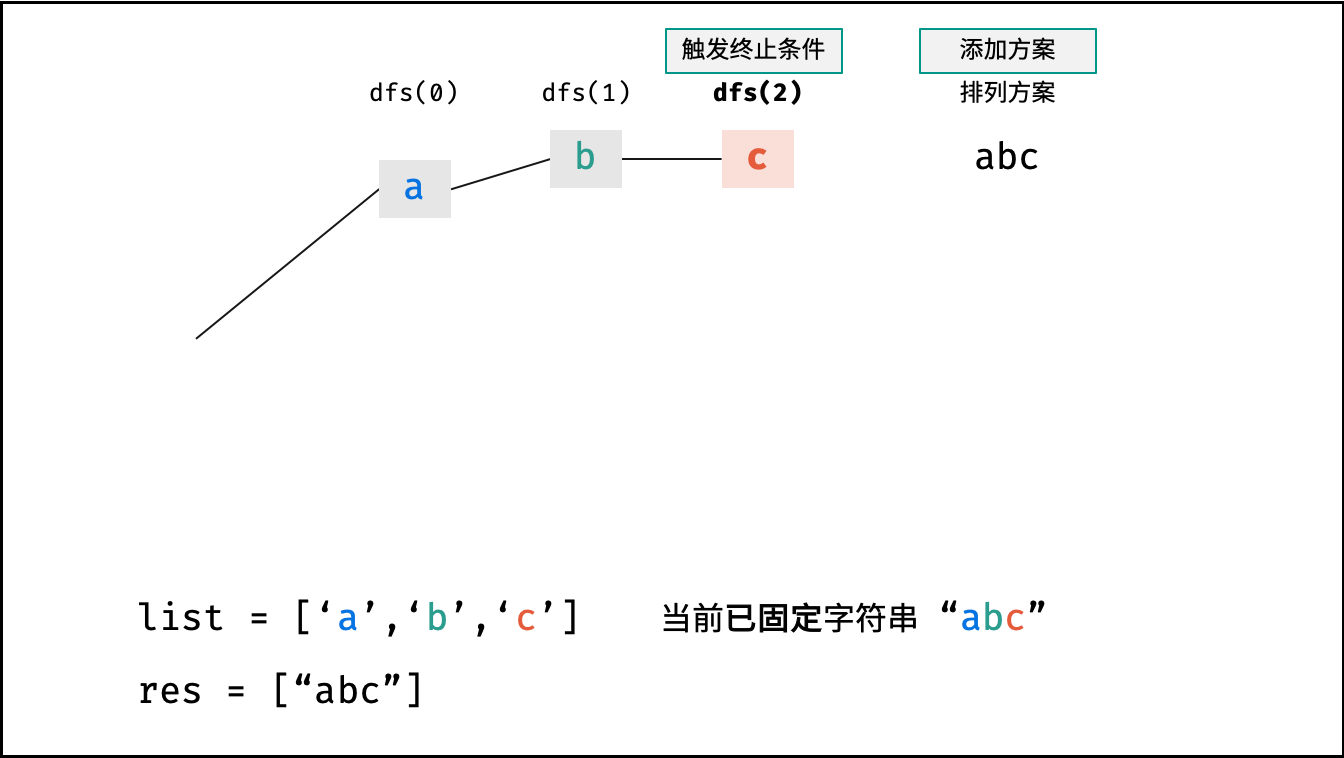
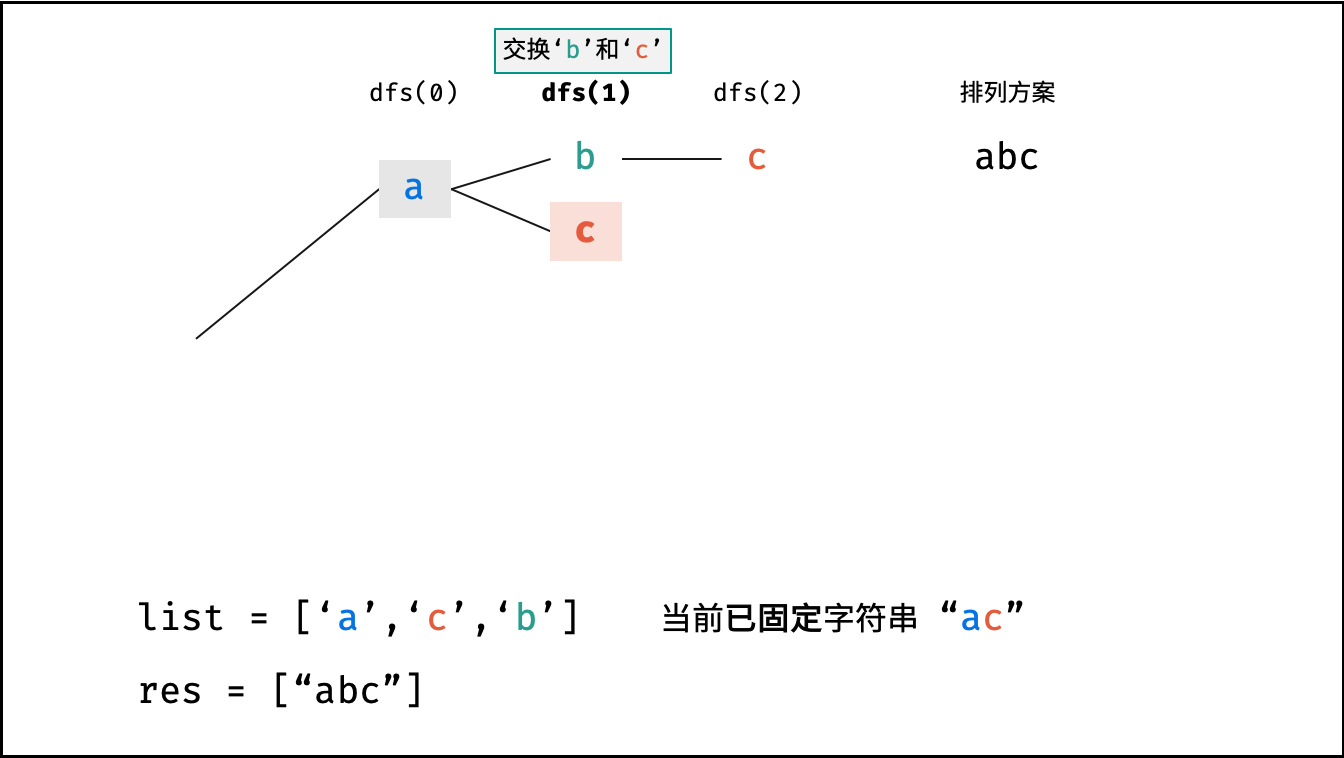
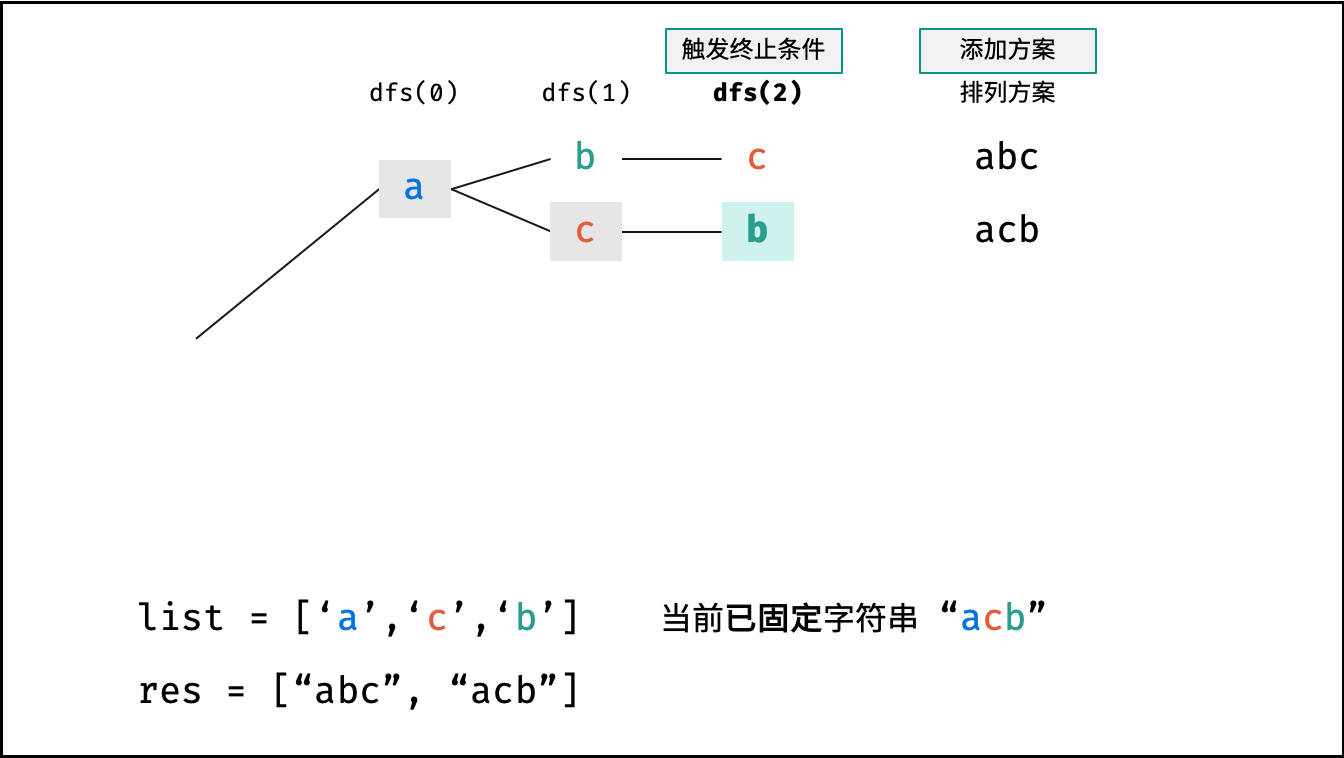
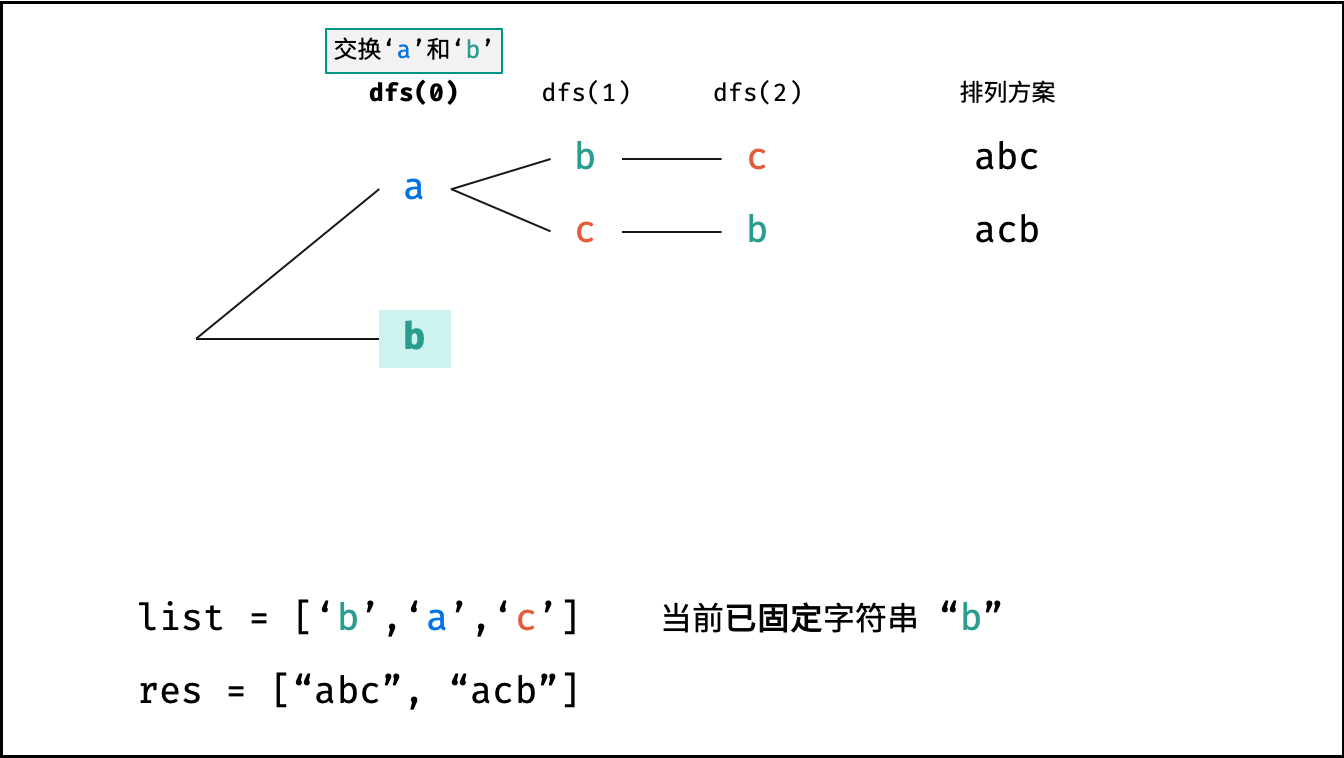
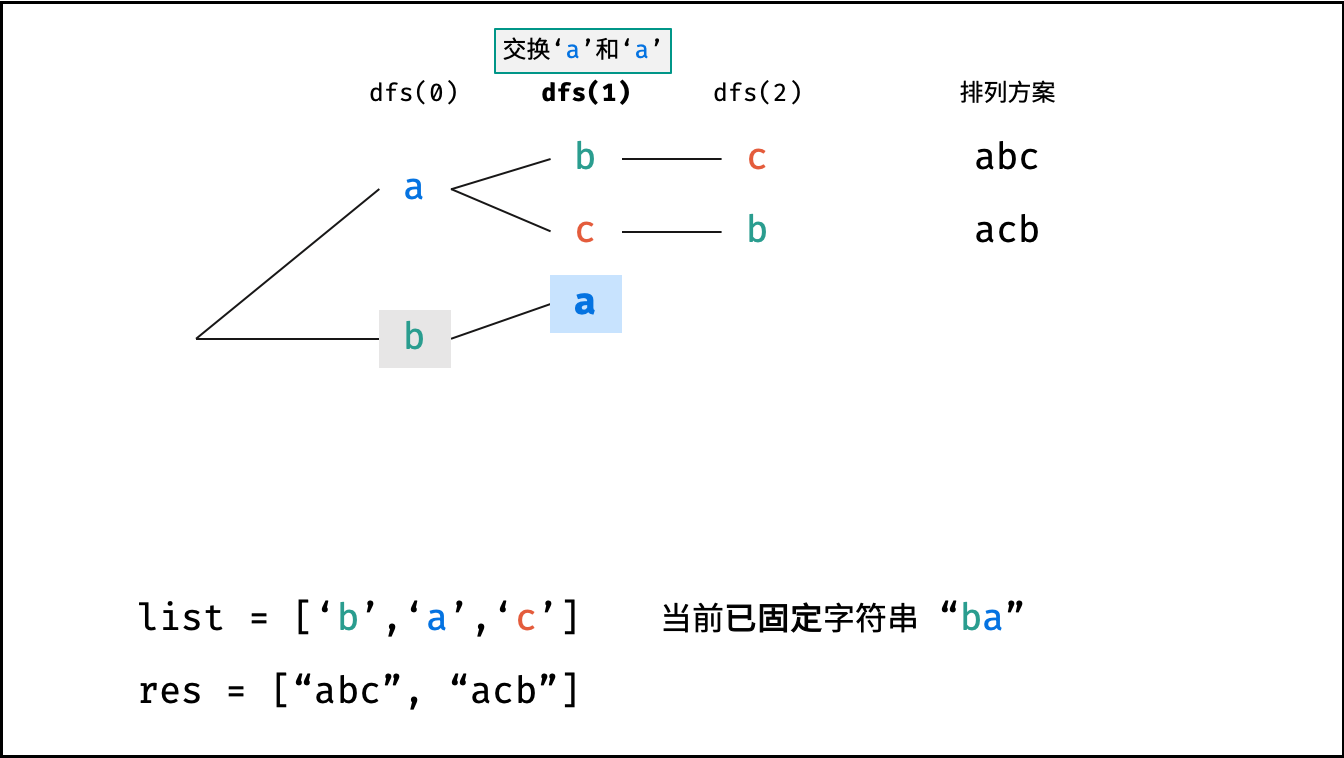
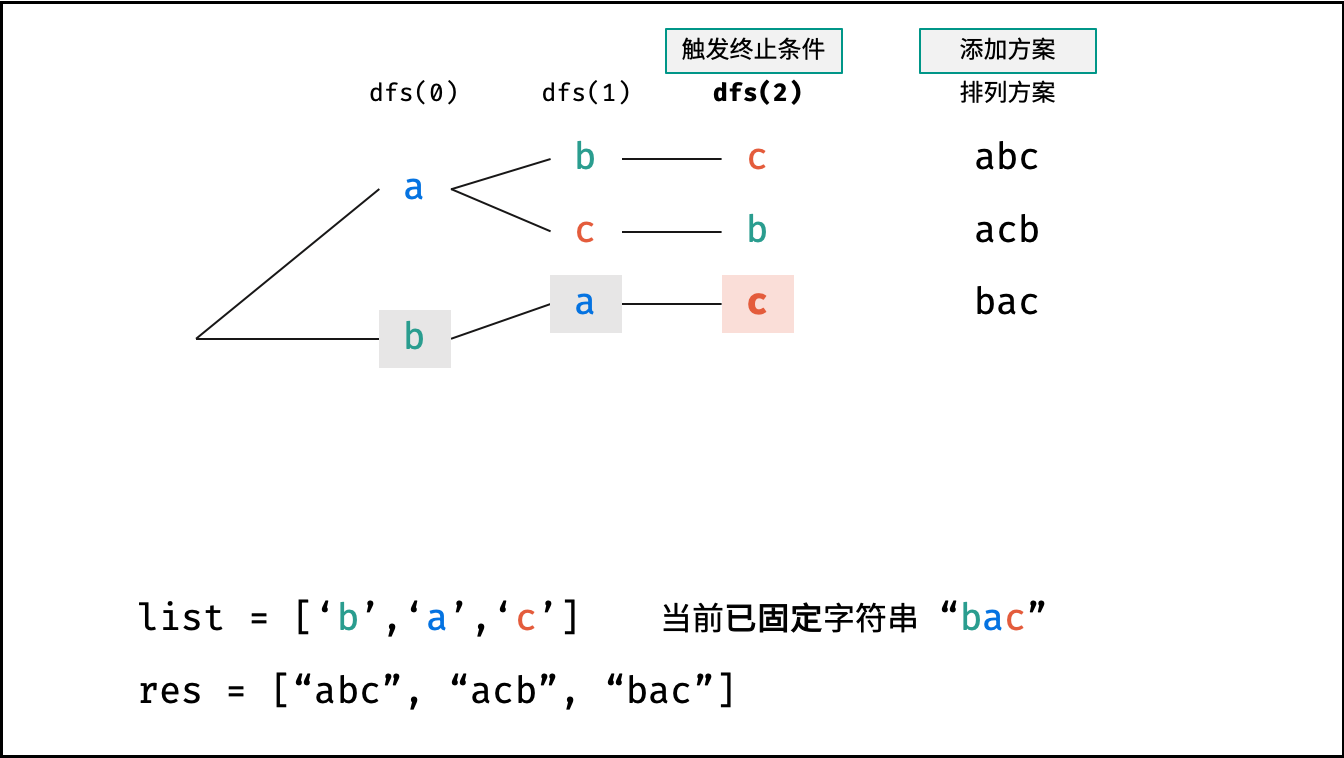
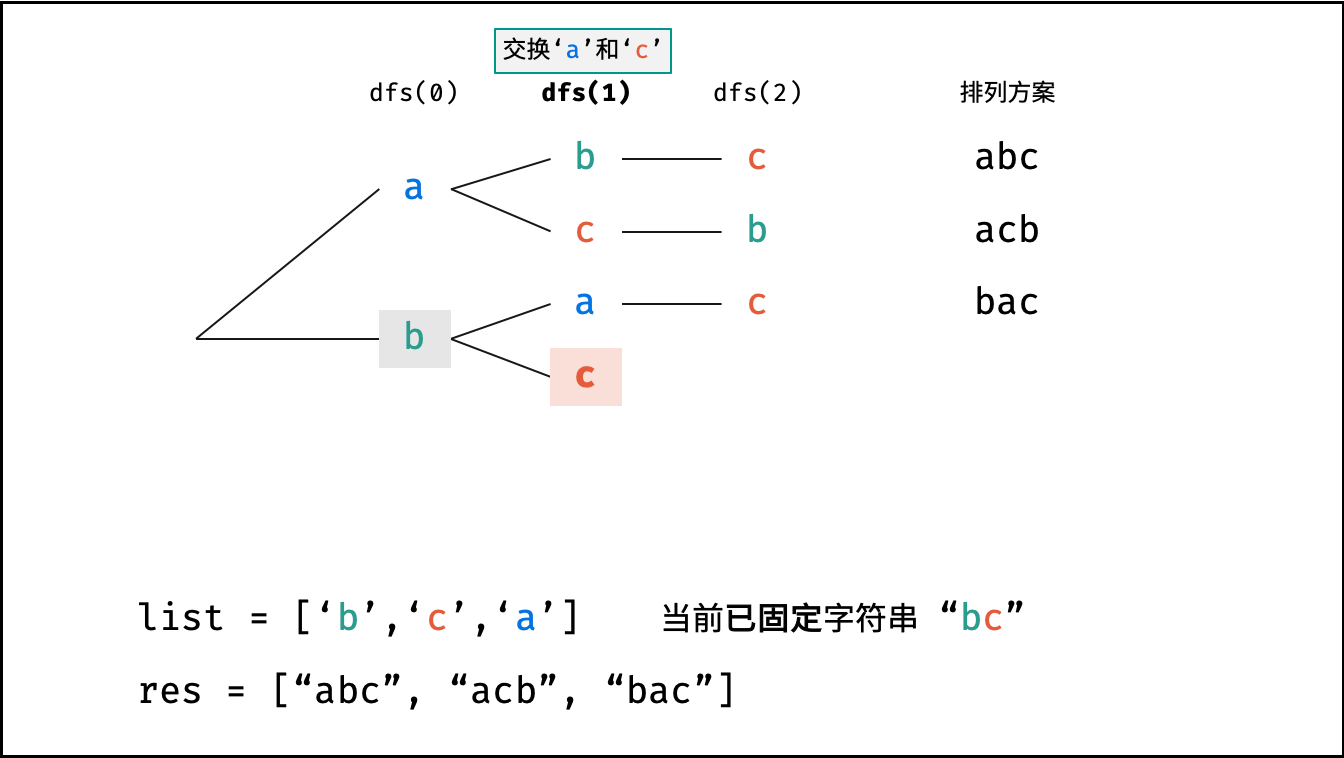
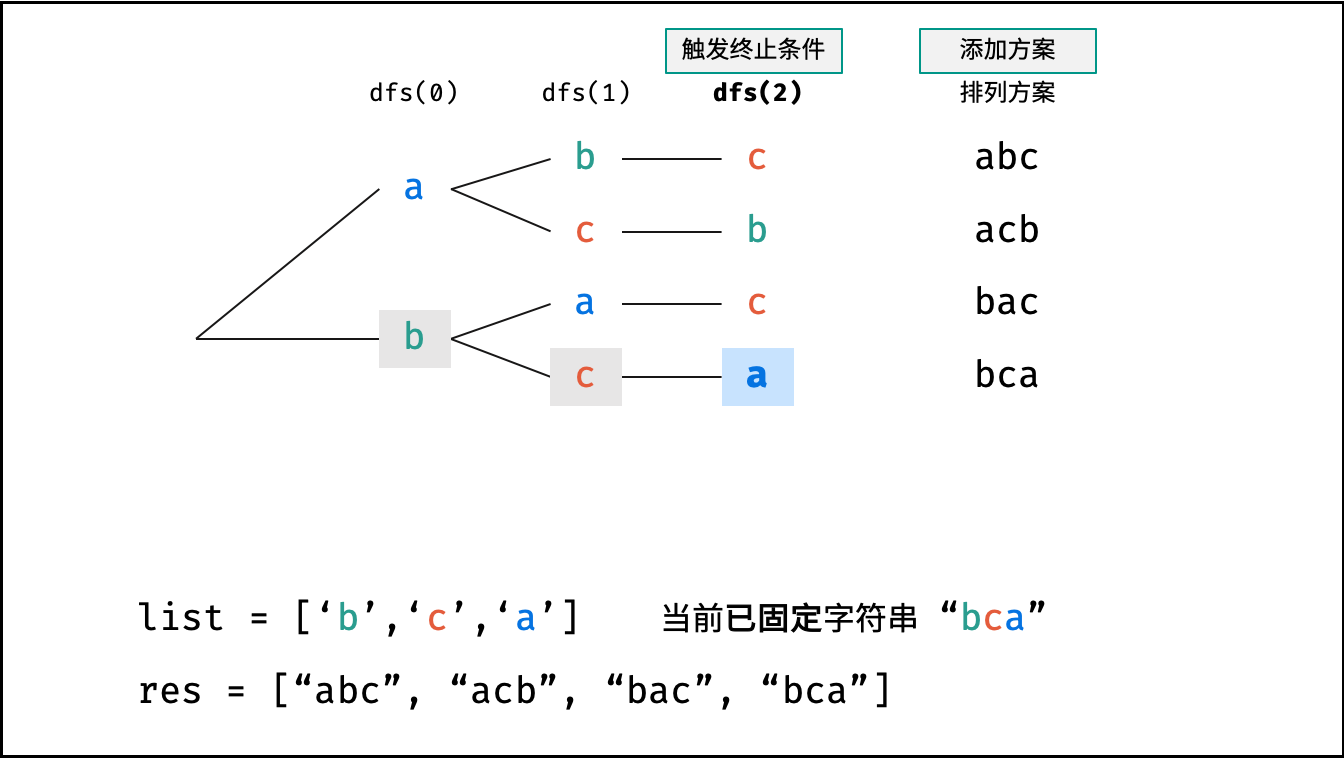
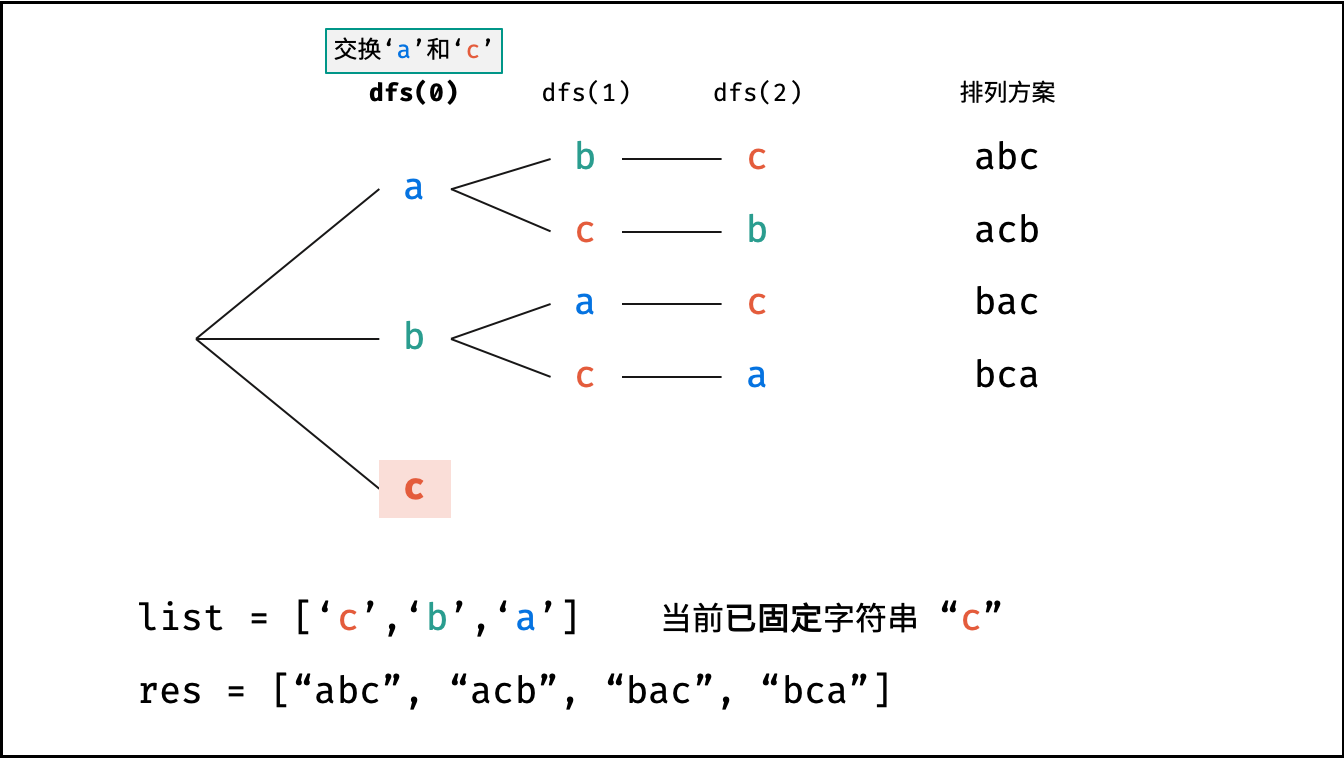
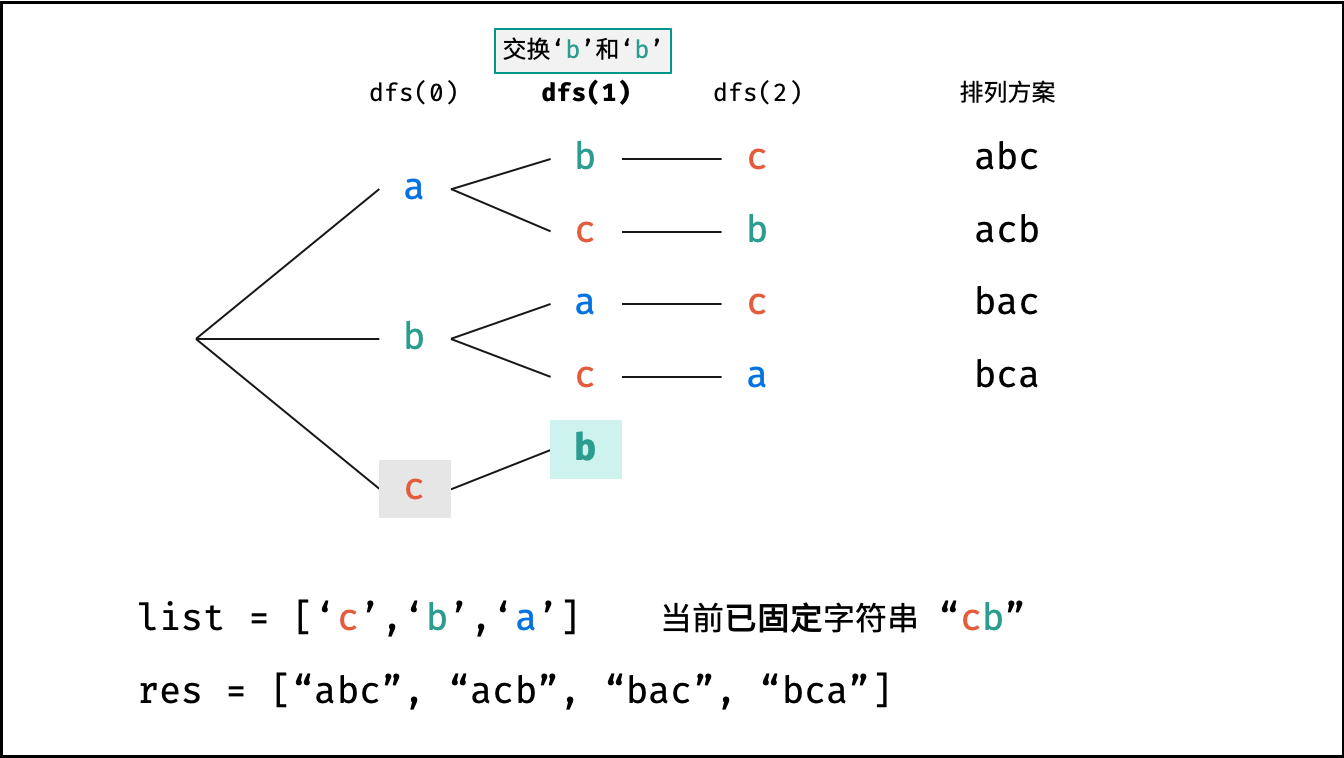
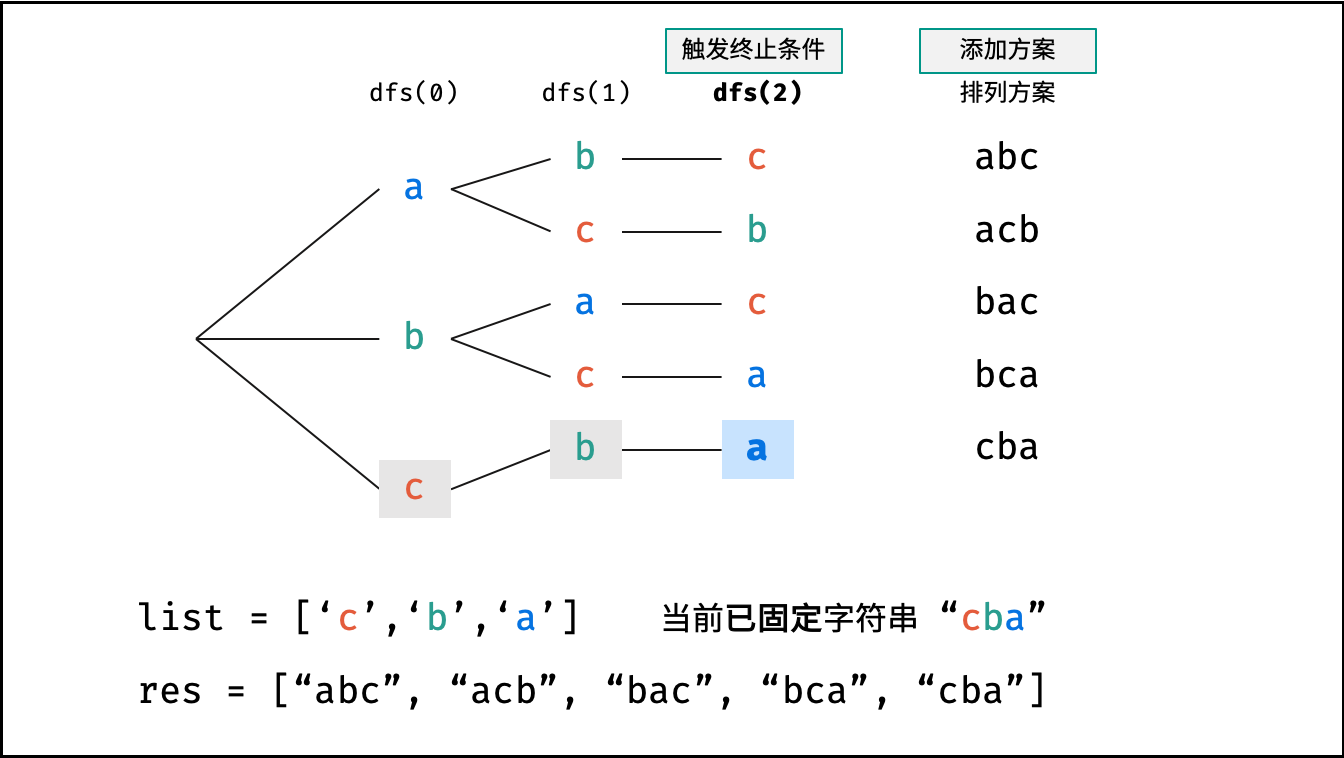
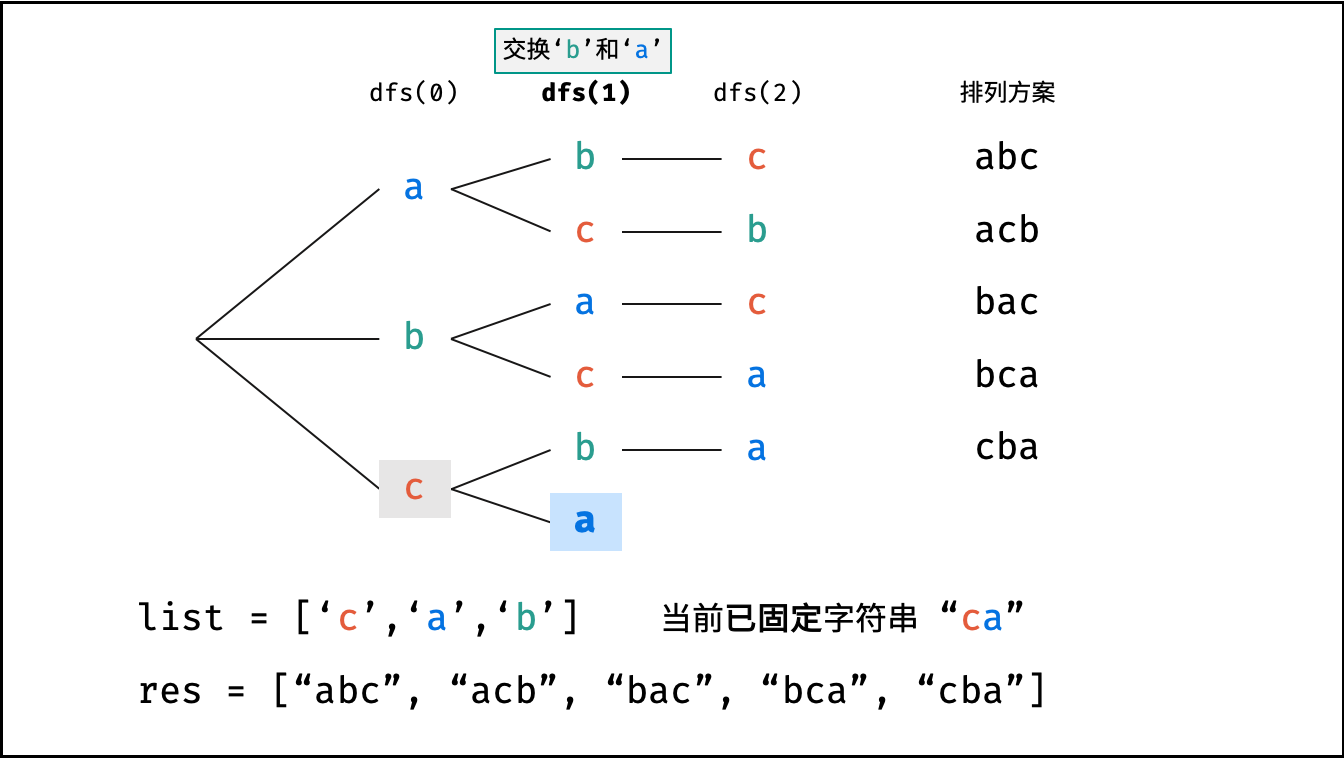
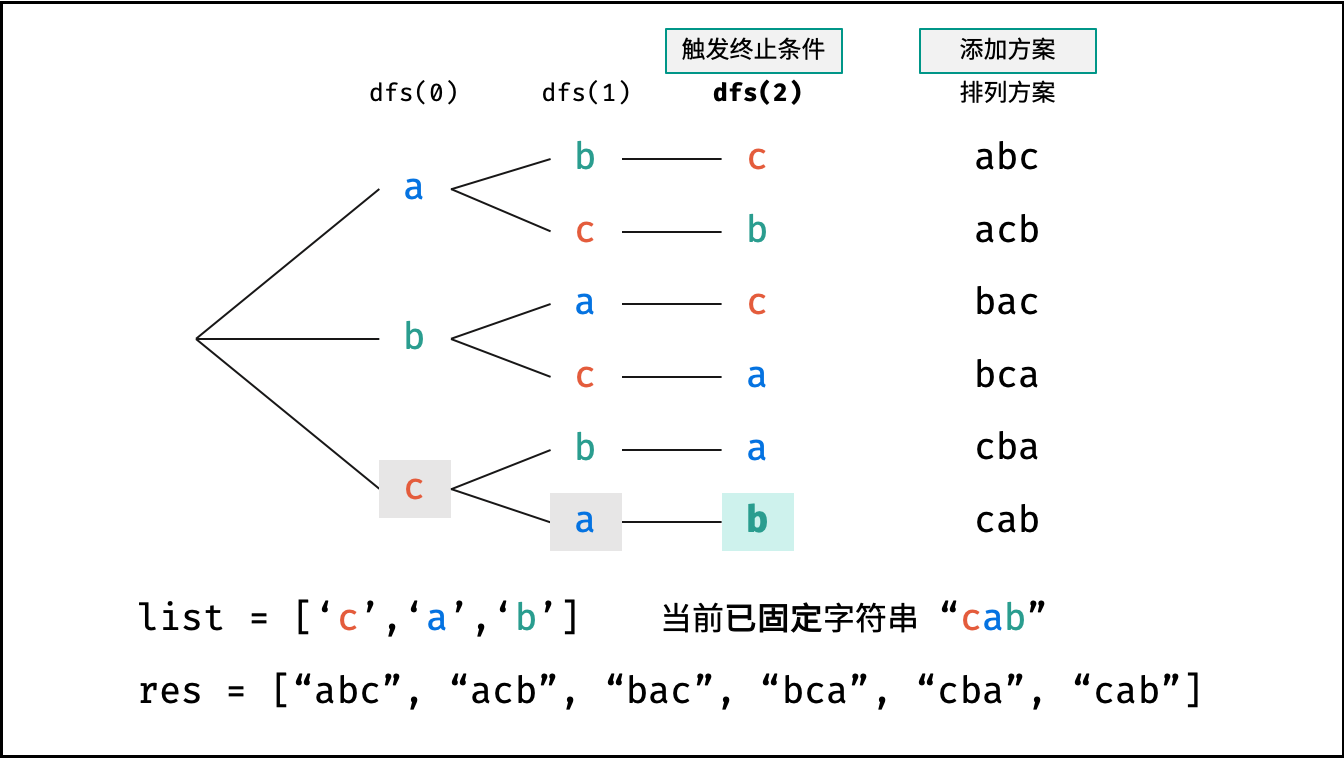
Krahets的解题思路(以下内容全部为摘抄):
对于一个长度为n的字符串(假设字符互不重复),其排列方案数共有:n×(n−1)×(n−2)…×2×1。根据字符串排列的特点,考虑深度优先搜索所有排列方案。即通过字符交换,先固定第1位字符(n种情况)、再固定第2位字符(n−1种情况)、…、最后固定第n位字符(1种情况)
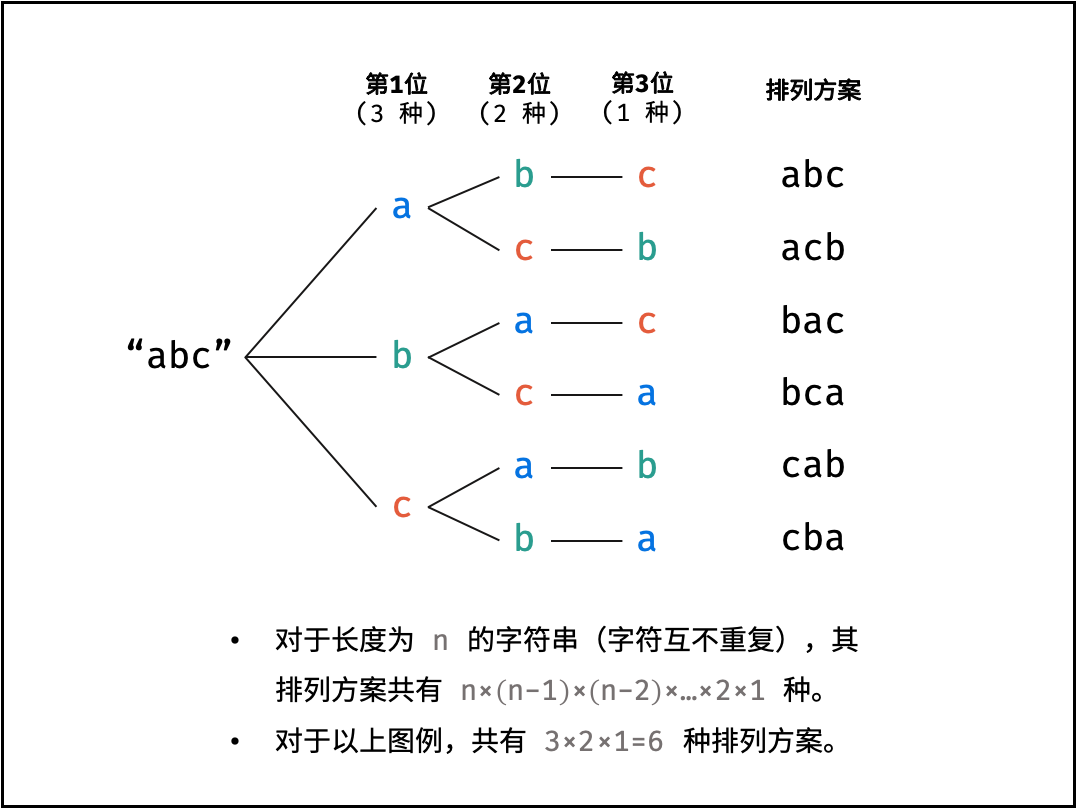
重复排列方案与剪枝:
当字符串存在重复字符时,排列方案中也存在重复的排列方案。为排除重复方案,需在固定某位字符时,保证“每种字符只在此位固定一次”,即遇到重复字符时不交换,直接跳过。从DFS角度看,此操作称为“剪枝”
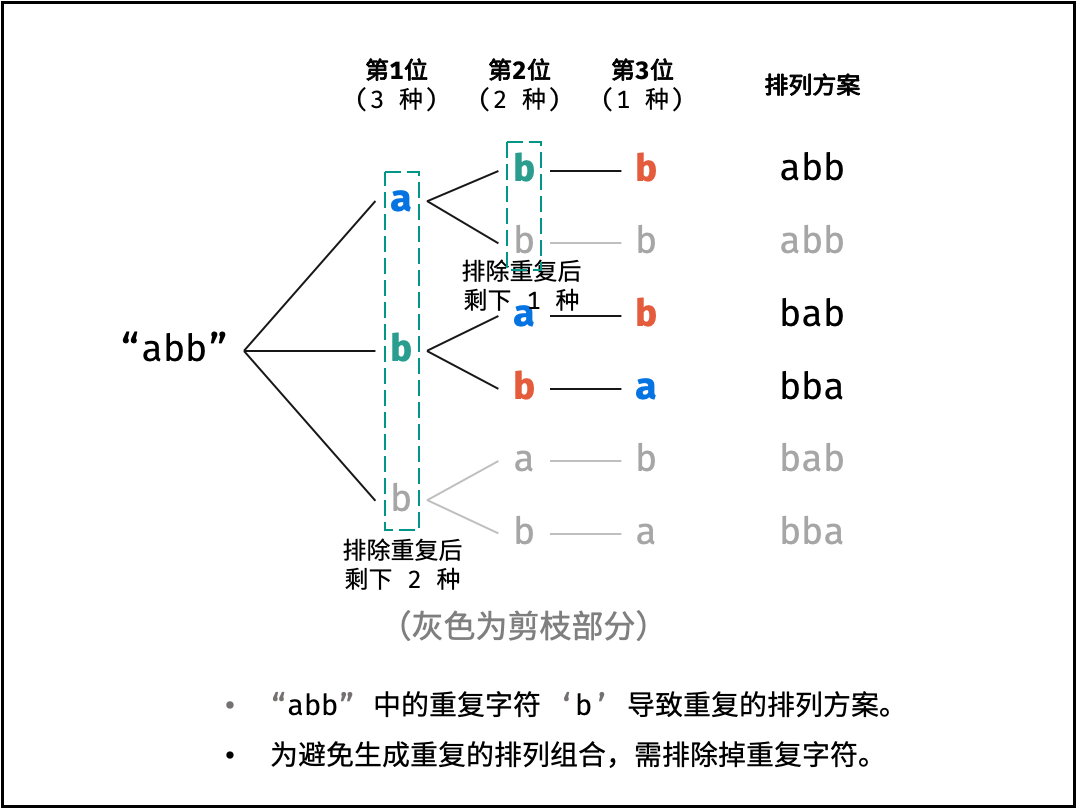
递归解析:
- 终止条件:当
x = len(c) - 1时,代表所有位已固定(最后一位只有1种情况),则将当前组合c转化为字符串并加入res,并返回 - 递推参数:当前固定位
x - 递推工作:初始化一个集合
set,用于排除重复的字符;将第x位字符与i ∈ [x, len(c)]字符分别交换,并进入下层递归,具体操作如下:- 剪枝:若
c[i]在set中,代表其是重复字符,因此“剪枝” - 将
c[i]加入set,以便之后遇到重复字符时剪枝 - 固定字符:将字符
c[i]和c[x]交换,即固定c[i]为当前位字符 - 开启下层递归:调用
dfs(x + 1),即开始固定第x + 1个字符 - 还原交换:将字符
c[i]和c[x]交换(还原之前的交换)
- 剪枝:若
注:下图中list对应上文中的列表c

复杂度分析:
- 时间复杂度O(N!N):N为字符串s的长度;时间复杂度和字符串排列的方案数成线性关系,方案数为N×(N−1)×(N−2)…×2×1,即复杂度为O(N!);字符串拼接操作
join()使用O(N);因此总体时间复杂度为O(N!N) - 空间复杂度O(N2):全排列的递归深度为N,系统累计使用栈空间大小为O(N);递归中辅助
set累计存储的字符数量最多为N+(N−1)+...+2+1=(N+1)N/2,即占用O(N2)的额外空间
代码实现:
1 | def permutation(s: str) -> List[str]: |
给定一个整数数组nums和一个整数目标值target,请你在该数组中找出和为目标值target的那两个整数,并返回它们的数组下标。你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。你可以按任意顺序返回答案
1 | 输入:nums = [2,7,11,15], target = 9 |
好吧,我只会双重循环写,还是直接看其他人的解法吧
我的提交
官方给出的解决思路:
最容易想到的方法是枚举数组中的每一个数x,寻找数组中是否存在target - x。当我们使用遍历整个数组的方式寻找target - x时,需要注意到每一个位于x之前的元素都已经和x匹配过,因此不需要再进行匹配,所以我们只需要在x后面的元素中寻找target - x,时间复杂度为O(N2)。注意到该方法时间复杂度较高的原因是寻找target - x的时间复杂度过高,因此,我们需要一种更优秀的方法,能够快速寻找数组中是否存在目标元素,如果存在,我们需要找出它的索引。利用哈希表,可以将寻找target - x的时间复杂度从O(N)降低到O(1),这样我们创建一个哈希表,对于每一个x,我们首先查询哈希表中是否存在target - x,然后将x插入到哈希表中,即可保证不会让x和自己匹配。代码:
1 | def twoSum(nums,target): |
给你一个字符串s和一个字符规律p,请你来实现一个支持'.'和'*'的正则表达式匹配,其中'.'匹配任意单个字符,'*'匹配零个或多个前面的那一个元素。所谓匹配,是要涵盖整个字符串s的,而不是部分字符串
1 | 例1: |
不会
查看官方给出的动态规划解法,此处略
看几个经典的案例:
- 找零问题
设需要找零的总金额为 n,且有 m 种不同面值的硬币,记作 d=[d1,d2,...,dm],姑且假设有 d1<d2<...<dm 成立,问至少需要多少枚硬币?
假设 n=6,并有两种面值,d=[d1,d2]=[1,2],显然需要三枚面值为 2 的硬币,通常我们的出发点是,既然要换最少的硬币,那就首先挑选面值最大的,并且在现实中大家都是这么做的,贪心算法有其合理性,但并不能总是得到正确解,譬如当我们有三种面值 d=[d1,d2,d3]=[1,3,4] 时,根据贪心算法,你会优先使用一枚面值为 4 以及两枚面值为 2 的硬币,但是“正确解”应该是两枚面值为 3 的硬币
令 Fi 表示金额为 i 时的最小硬币组合数,显然有 F6=min{F6−4+1,F6−3+1,F6−1+1},换句话说,你可以选择换一枚面值为 4 的硬币,剩下的两元钱怎么换你不用去管,这是一个更小的子问题,你可以交给另一个人去做,总之他会返回给你一个结果(硬币数),同理你还可以选择换一枚面值为 3 或者面值为 1 的硬币并将剩余金额的找零问题交给其他人去解,所以共有三个人接受你的委托,对于三个结果,选择最小的那个,再加上你的一枚硬币,就得到最少硬币数量了,更一般的,有⎩⎪⎨⎪⎧Fi=j:i≥dj,j∈1,2,...,mmin{Fi−dj+1}F0=0(第一行为递归公式,第二行为边界条件)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27#递归法解决找零问题
n=6
d=[1,3,4]
def f1(i):
'''返回最小硬币数'''
if i==0:
return 0
return min([f1(i-j)+1 for j in d if i>=j])
print(f1(n)) #试着将n取值200然后执行脚本,f1(n)非常慢(当前问题相当于在一棵三叉树中递归寻找最优解,当n=200时,树分支最深达到200,最浅的分支也达到50,假设深度全按50算,这意味着递归将发生3^50次函数调用),f2(n)则可以立即得到结果,但n若取值300,全部爆栈,建议改为循环
from numpy import argmin
from functools import lru_cache
@lru_cache(maxsize=None)
def f2(i):
'''返回最小硬币数以及具体的找零方案'''
if i==0:
return 0,[]
t=[(f2(i-j),j) for j in d if i>=j]
m=argmin([j[0][0] for j in t])
return t[m][0][0]+1,t[m][0][1]+[t[m][1]]
print(f2(n))
#print(f2.cache_info())循环解法譬如对于 d=[d1,d2,d3]=[1,3,4],有:
F1=min{F1−d1+1}=F0+1=0+1=1F2=min{F2−d1+1}=F1+1=1+1=2F3=min{F3−d1+1,F3−d2+1}=min{F2+1,F0+1}=min{3,1}=1F4=min{F4−d1+1,F4−d2+1,F4−d3+1}=min{F3+1,F1+1,F0+1}=min{2,2,1}=1F5=min{F5−d1+1,F5−d2+1,F5−d3+1}=min{F4+1,F2+1,F1+1}=min{2,3,2}=2F6=min{F6−d1+1,F6−d2+1,F6−d3+1}=min{F5+1,F3+1,F2+1}=min{3,2,3}=2(其实这就是状态转移方程,通常动态规划你是画一个二维表然后逐行或者逐列填充,此处就是一维的表而已)
由上述过程可以看出完全可以通过更简单的循环解决:1
2
3
4
5
6
7
8
9n=6
d=[1,3,4]
F={0:0}
for i in range(1,n+1):
F[i]=min([F[i-j]+1 for j in d if j<=i])
print(F[n]) #2正常的动态规划是怎么做的呢?上述递归解法我们将待找零的总金额给分解了,本来要找零100块钱,分解到最后你只需要找零1块钱,问题就变得非常简单,你还可以从另一个维度分解,即将可供找零的不同面值的钱币分解,本来有10种面值,分解到最后,只有一种面值,这时候找零问题就很简单了,下面画一个二维表,横轴是待找零的总金额,纵轴是可供找零的钱币面值:
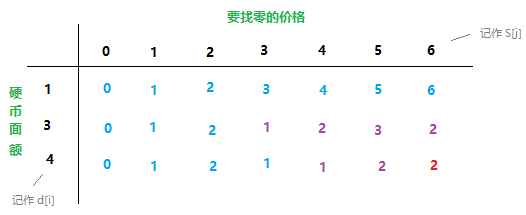
记 T[i][j] 为表中第 i 行第 j 列的元素(i、j 均从 0 起始),表示当前要找零的金额为 s[j] 且可供找零的硬币面值为 d[0]到d[i] 时的最少硬币数量,姑且按行填充表格,第一行最简单,就不说了。看 T[1][3],当前要找零的金额为 3(s[3]),可以兑换一枚面值为 3 (d[1])的硬币,剩余 3-3=0 元继续找零,需要的最少硬币数为 T[1][0](这是已知的,因为表格是逐行填充的嘛),于是一共需要 1 + 0 枚硬币,另外我们已经知道,在“找零价钱为 3 且可供找零的硬币面值为 1”的情况下,最少硬币数为3(T[0][3] 的值),显然 1<3,于是最少硬币数量可以确定为 1。再看 T[1][6],当前要找零金额为 6,可以换一枚面值为 3 的硬币(为什么不兑换两枚面值为 3 的硬币呢?因为没必要,后面会说明),剩余 6-3=3 元继续找零,此前我们已经知道在“找零价钱为 3 且可供找零的硬币为 1、3”的情况下,最少硬币数为 1(也就是 T[1][3] 的值),于是一共需要 1+1=2 枚硬币,另外我们已经知道,在“找零金额为 6 且可供找零的硬币为 1”的情况下,最少硬币数为 6(T[0][6] 的值),而 2<6,于是最少硬币数量可以最终确定为 2。最后再看一下 T[2][6],当前要找零的金额为 6,可以换一枚面值为 4 的硬币,剩余 6-4=2 元继续找零,而 T[2][2]=2,于是一共需要使用 1+2=3 枚硬币,但是我们已经知道在“找零金额为 6 且可供找零的硬币为 1、3”的情况下,最少硬币数为 2(T[1][6]),3>2,因此最少数量仍保持之前的最优解,即 T[2][6]=T[1][6]=2。一般的,有T[i][j]={T[i−1][j],min{T[i][s[j]−d[i]]+1,T[i−1][j]},s[j]<d[i]otherwise(状态转移方程)
注:对于T[i][j],假设s[j]最多可以兑换K枚面值为d[i]的硬币,为什么在上述求解过程中总是只兑换一枚呢?因为在状态转移过程中很显然总会有T[i][s[j]−d[i]]+1=T[i][s[j]−k⋅d[i]]+k(1≤k≤K)成立
- 装包问题
现有四件物品,音响(3000 美元,重 4 磅)、笔记本电脑(2000 美元,重 3 磅)、吉他(1500 美元,重 1 磅)、iPhone(2000美元,重 1 磅),背包总容量为 4 磅,问背包最多能装入价值为多少的物品(注意每件物品的数量为 1,或者说一件物品最多只能装入一次)?注:该示例来自《图解算法》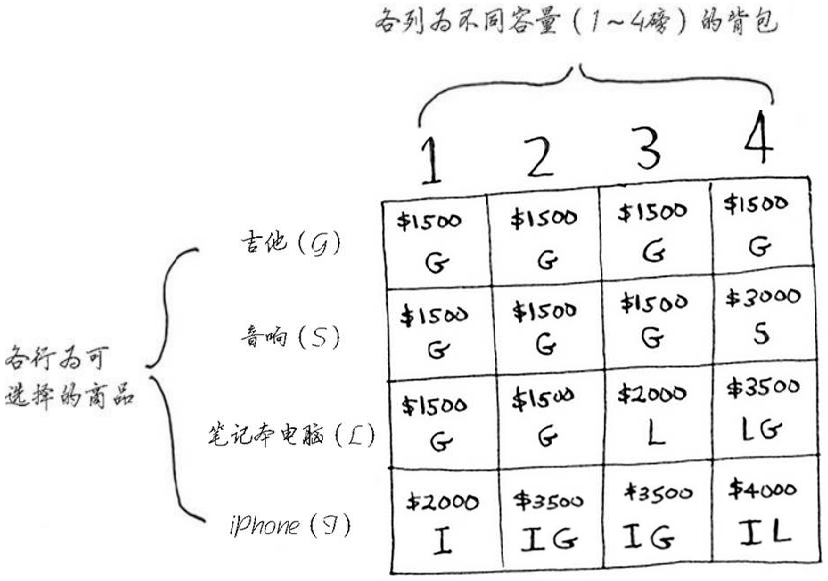
记 CELL[i][j] 为第 i 行第 j 列的单元格,含义为“在背包容量为j且可供装入的物品为吉他、音响、笔记本电脑、iPhone中的前i件时所能获取的最大价值”,其中 i、j 均从 1 起始,此处以最后一个单元格为例进行说明,即T[4][4],此时iPhone的重量为 1 磅,背包可以容纳,假设装入,剩余 4-1=3 磅可供装入其它物品,根据 CELL[3][3]=2000,即 3 磅容量可容纳的最大价值为 2000 美元(仅限于吉他、音响和电脑三件物品选择),于是“当前物品价值+剩余空间的价值”为 2000+2000=4000,而 4000>CELL[3][4],其中 CELL[3][4] 表示在“背包容量为 4 磅,可供选择的物品为吉他、音响和电脑”的情况下最大价值为 3500,因此最大价值变为 4000 美元。其状态转移方程如下:
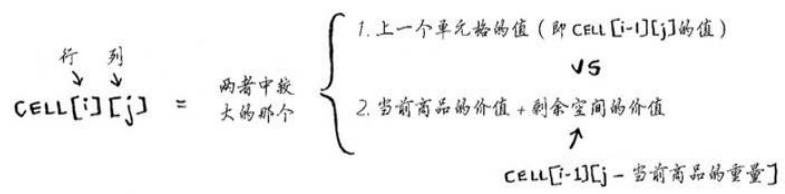
或者用递归做:
F(4,GSLI)=max{2000+F(3,GSL),2000+F(1,GSI),3000+F(0,GLI),1500+F(3,SLI)}F(3,GSL)=max{2000+F(0,GS),1500+F(2,SL)}F(1,GSI)=max{2000+F(0,GS),1500+F(0,SI)}F(0,GLI)=0F(3,SLI)=max{2000+F(2,SL),2000+F(0,SI)}F(2,SL)=max{什么也装不了}=0,其他诸如F(0,⋅)也都为0
于是最终 F(4,GSLI)=max{4000,4000,3000,3500}=4000,对应的物品为 LI,即笔记本电脑和iPhone。代码略 - 最长公共子序列(Longest Common Subsequence,LCS)
假设给定两个字符串,要计算 其LCS的长度,这很简单,我只比较两个字符串的最后一个字符是否相同,如果相同,我就把两个字符串的最后一个字符都删除,然后将剩余部分交给另一个人,并问他同样的问题:“请告诉我这两个字符串的 LCS的长度”,他将返回给我一个值,我再加上 1 就是最终结果了。如果刚才最后一个字符比较不相同,那就删除第一个字符串的最后字符,第二个字符串保持不变,并交给一个人让他计算它们的 LCS的长度,另外再删除第二个字符串的最后字符,并保持第一个字符串不变,再交给另一个人让他计算它们的 LCS的长度,最终我会得到两个人返回的两个结果,选出最大的即可,问题解决,这是递归的思路,很容易得到相应的动态规划解法: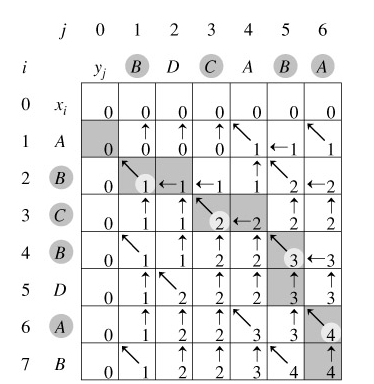
其状态转移方程为:c[i,j]=⎩⎪⎪⎨⎪⎪⎧0,c[i−1,j−1]+1,max(c[i,j−1],c[i−1,j]), if i=0 or j=0, if i,j>0 and xi=yj if i,j>0 and xi=yj。代码略
其他推荐:
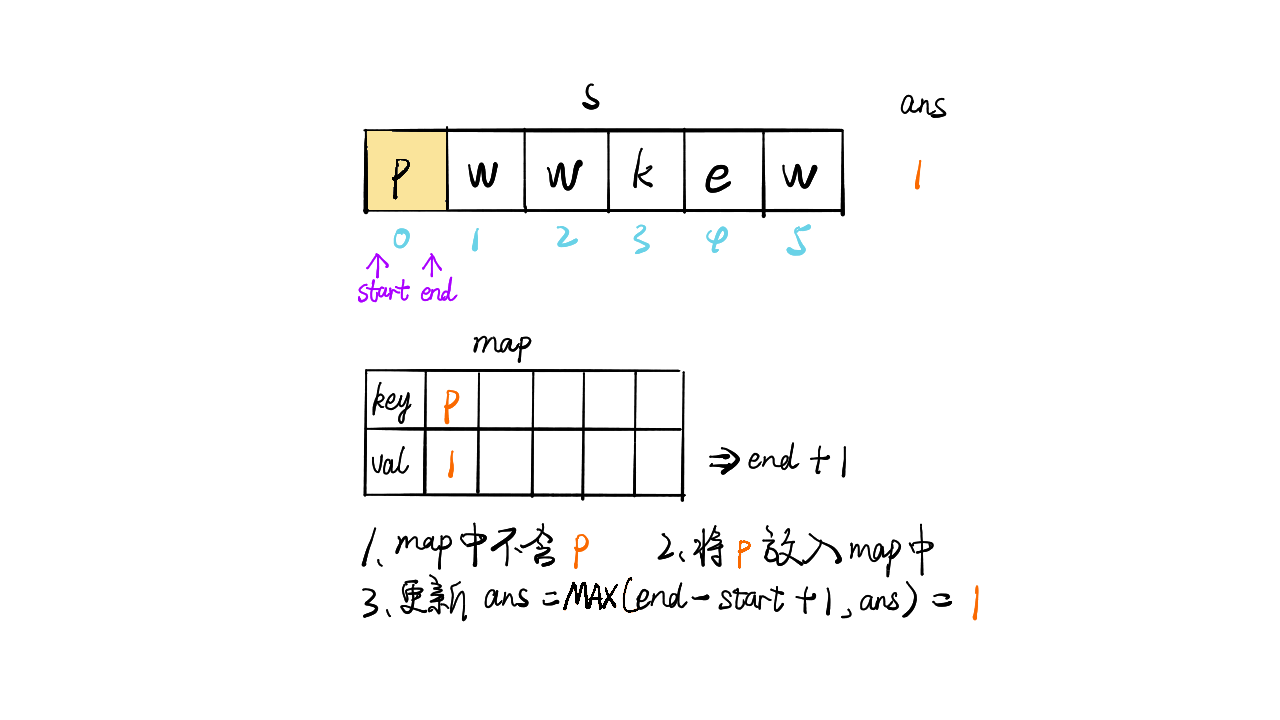
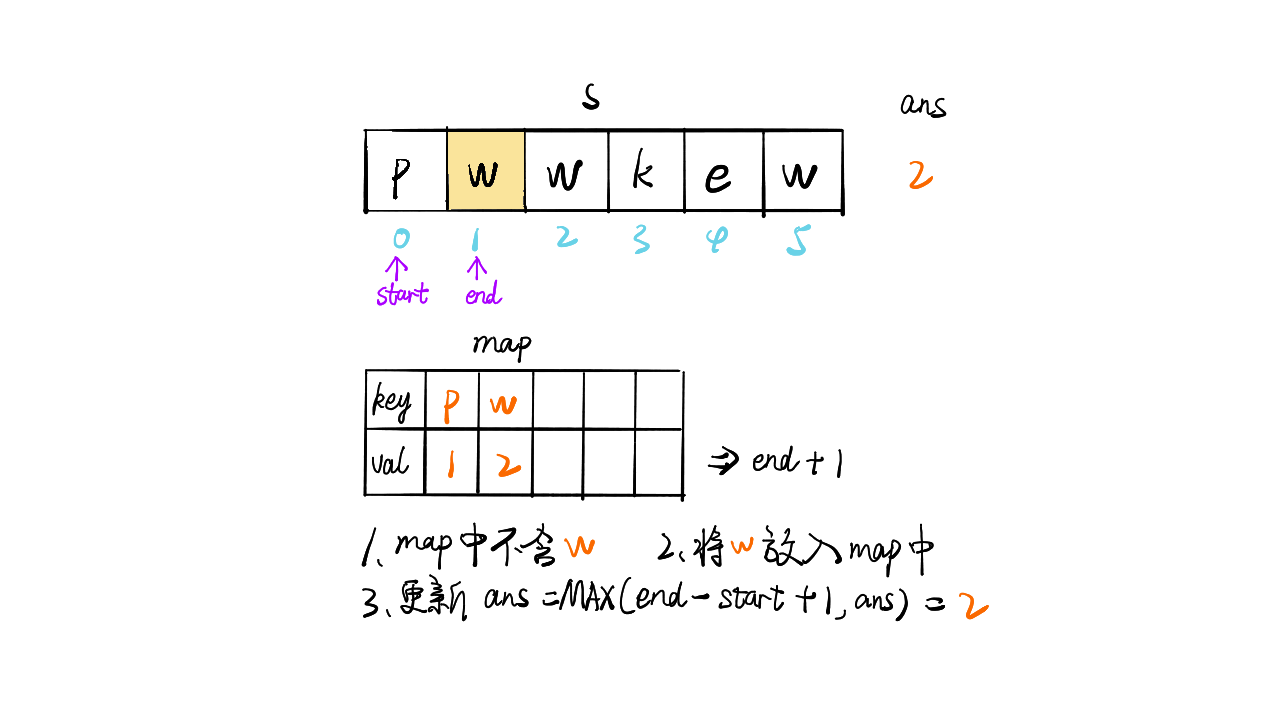
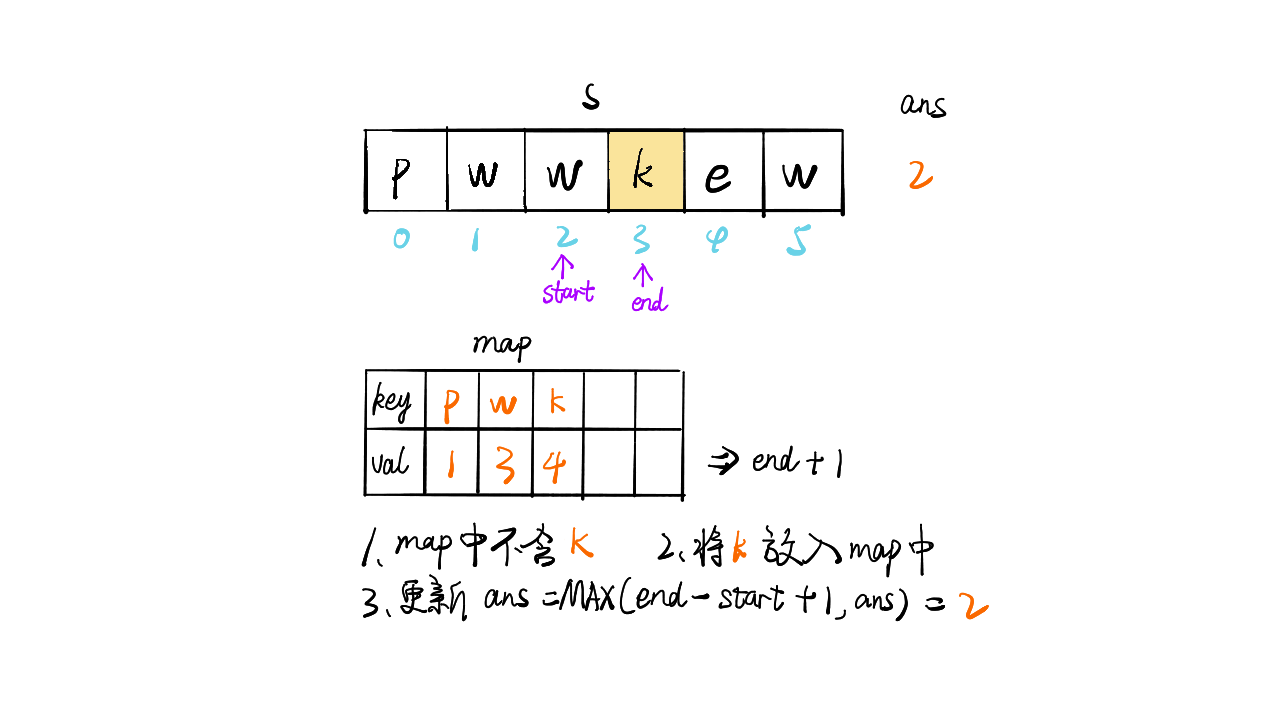
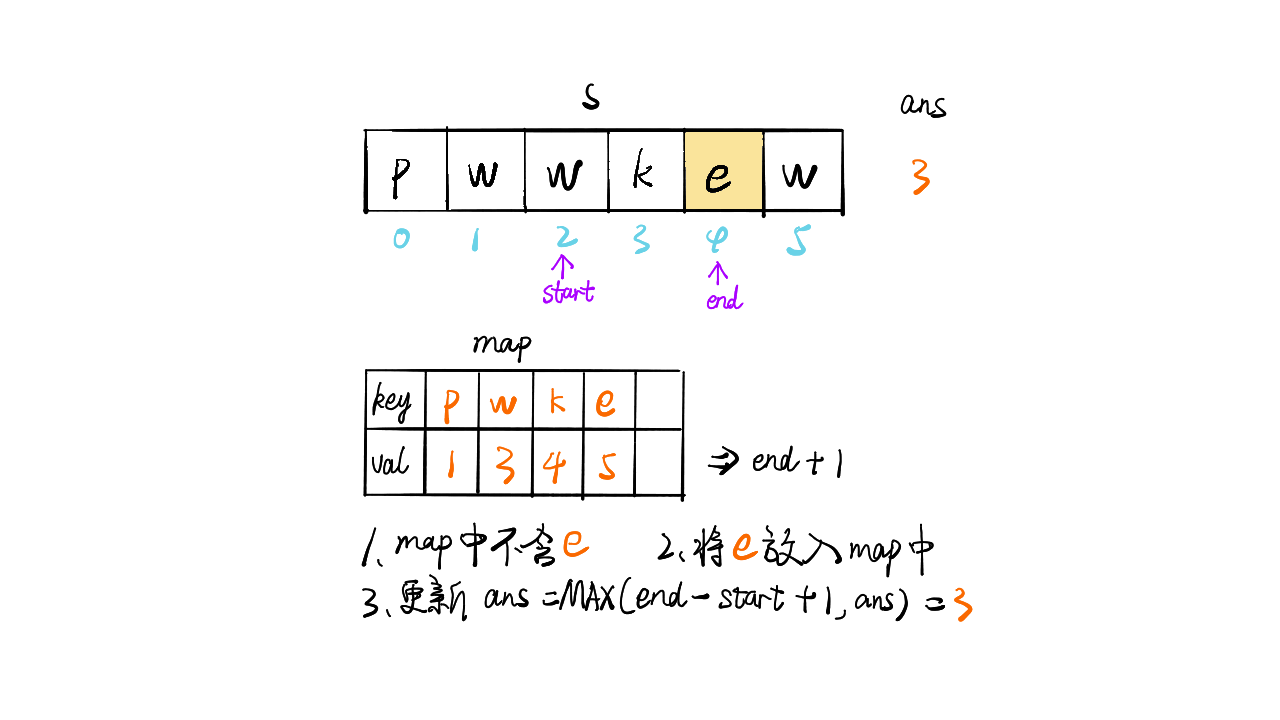
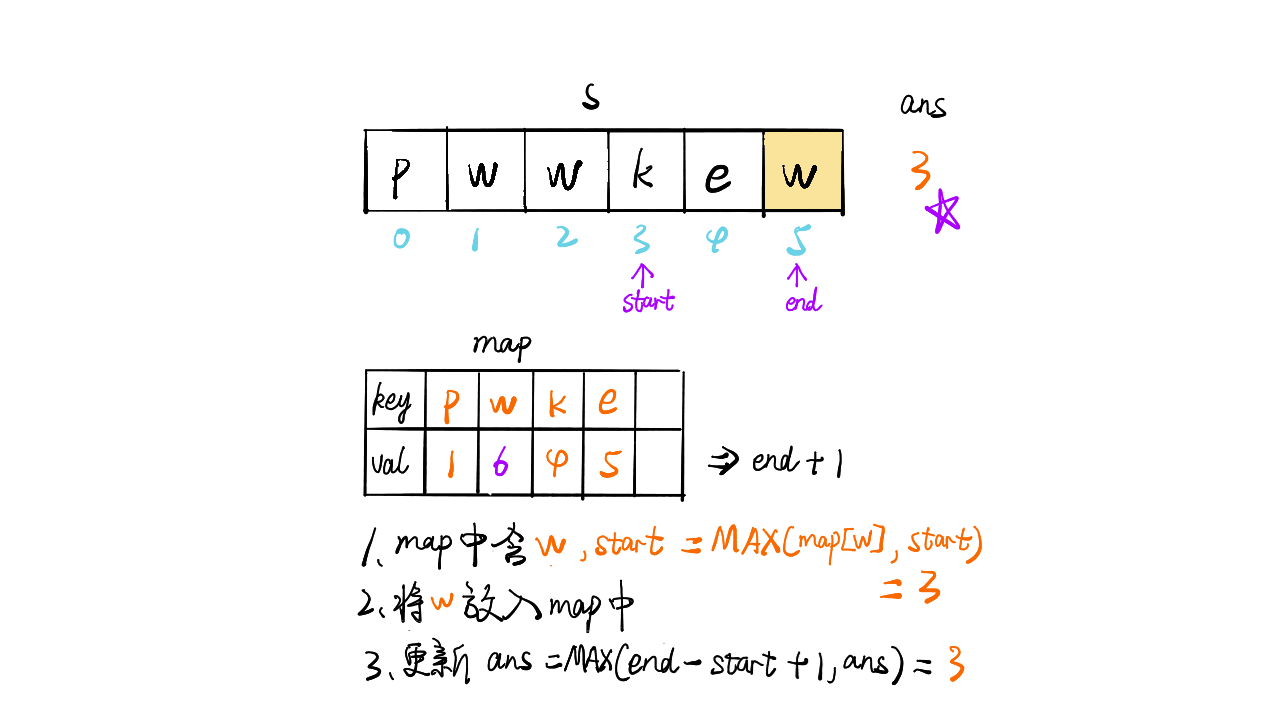
给定一个字符串,找出其中不含有重复字符的最长子串的长度
1 | 输入: s = "abcabcbb" |
只想到暴力求解(时间复杂度O(n2)):
1 | def f(s): |
提交出错,超出时间限制
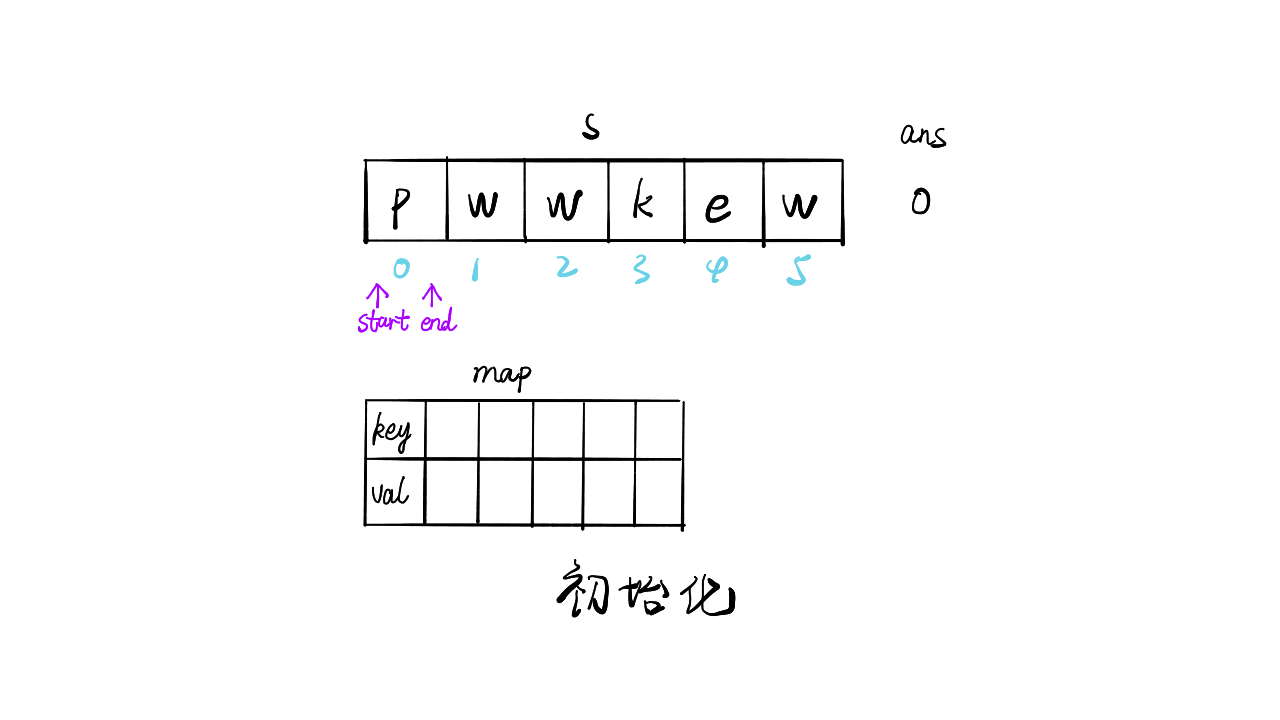

给你一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?请找出所有和为 0 且不重复的三元组
1 | 输入:nums = [-1,0,1,2,-1,-4] |
遍历一次数组 nums 中的元素 e,将三数之和问题转换为两数之和(目标值为 0-e),而之前遇到过“两数之和”的问题,时间复杂度为 O(N),因此三数之和求解的时间复杂度为 O(N2)
我的提交
看下大佬Krahets的“排序+双指针”解法(以下内容为复制粘贴):
- 双指针法铺垫:先将给定的数组
nums排序,复杂度为 O(NlogN) - 双指针法思路:固定 3 个指针中最左(最小)数字的指针
k,双指针i,j分设在数组索引(k, len(nums))两端,通过双指针交替向中间移动,记录对于每个固定指针k的所有满足nums[k] + nums[i] + nums[j] == 0的i,j组合:- 当
nums[k] > 0时直接break跳出:因为nums[j] >= nums[i] >= nums[k] > 0,即 3 个数字都大于 0 ,在此固定指针k之后不可能再找到结果了 - 当
k > 0且nums[k] == nums[k - 1]时即跳过此元素nums[k]:因为已经将nums[k - 1]的所有组合加入到结果(res)中,本次双指针搜索只会得到重复组合 i,j分设在数组索引(k, len(nums))两端,当i < j时循环计算s = nums[k] + nums[i] + nums[j],并按照以下规则执行双指针移动:- 当
s < 0时,i += 1并跳过所有重复的nums[i] - 当
s > 0时,j -= 1并跳过所有重复的nums[j] - 当
s == 0时,记录组合[k, i, j]至res,执行i += 1和j -= 1并跳过所有重复的nums[i]和nums[j],防止记录到重复组合
- 当
- 当
- 复杂度分析:时间复杂度 O(N2),其中固定指针
k循环复杂度 O(N),双指针i,j复杂度 O(N)。空间复杂度 O(1),指针使用常数大小的额外空间
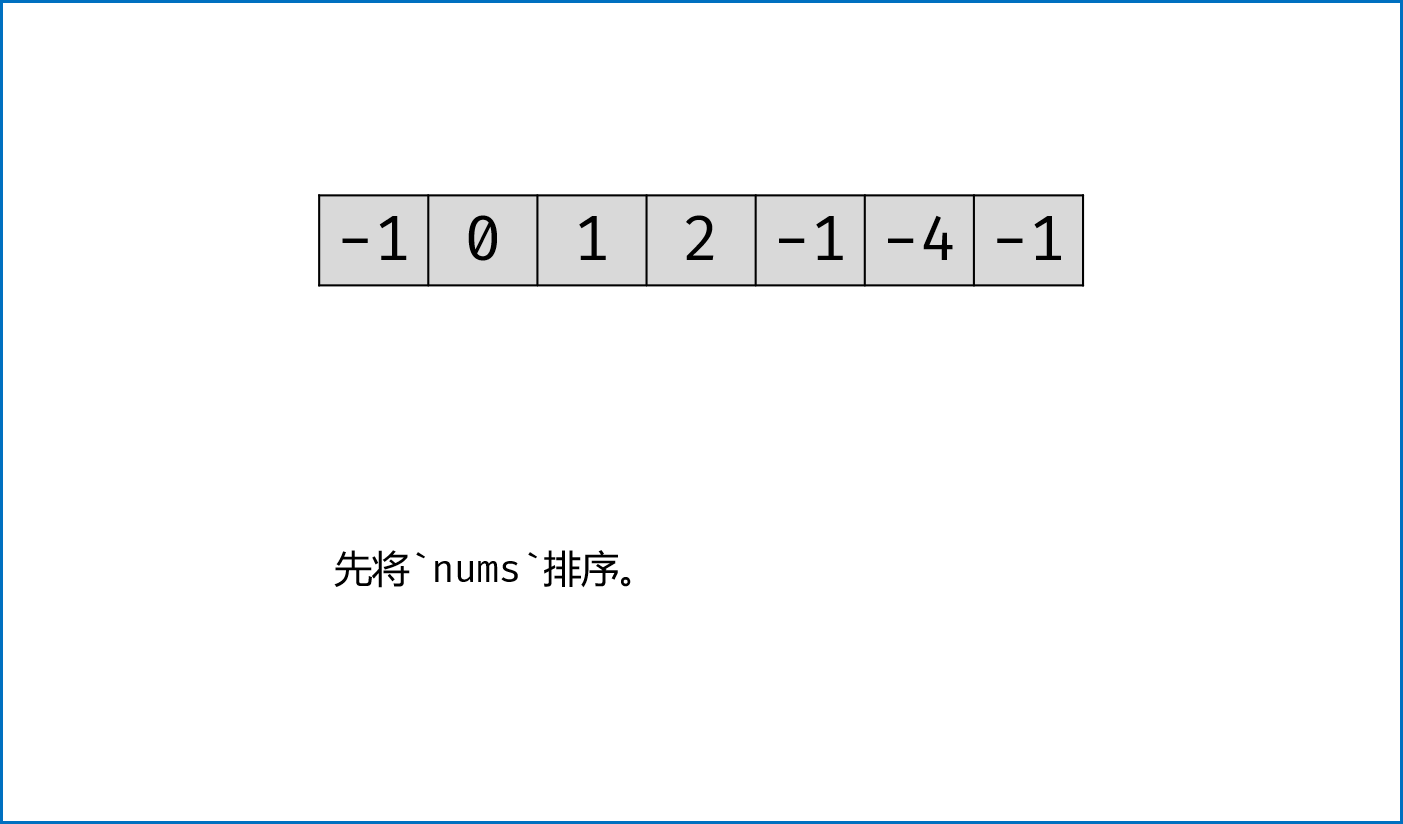



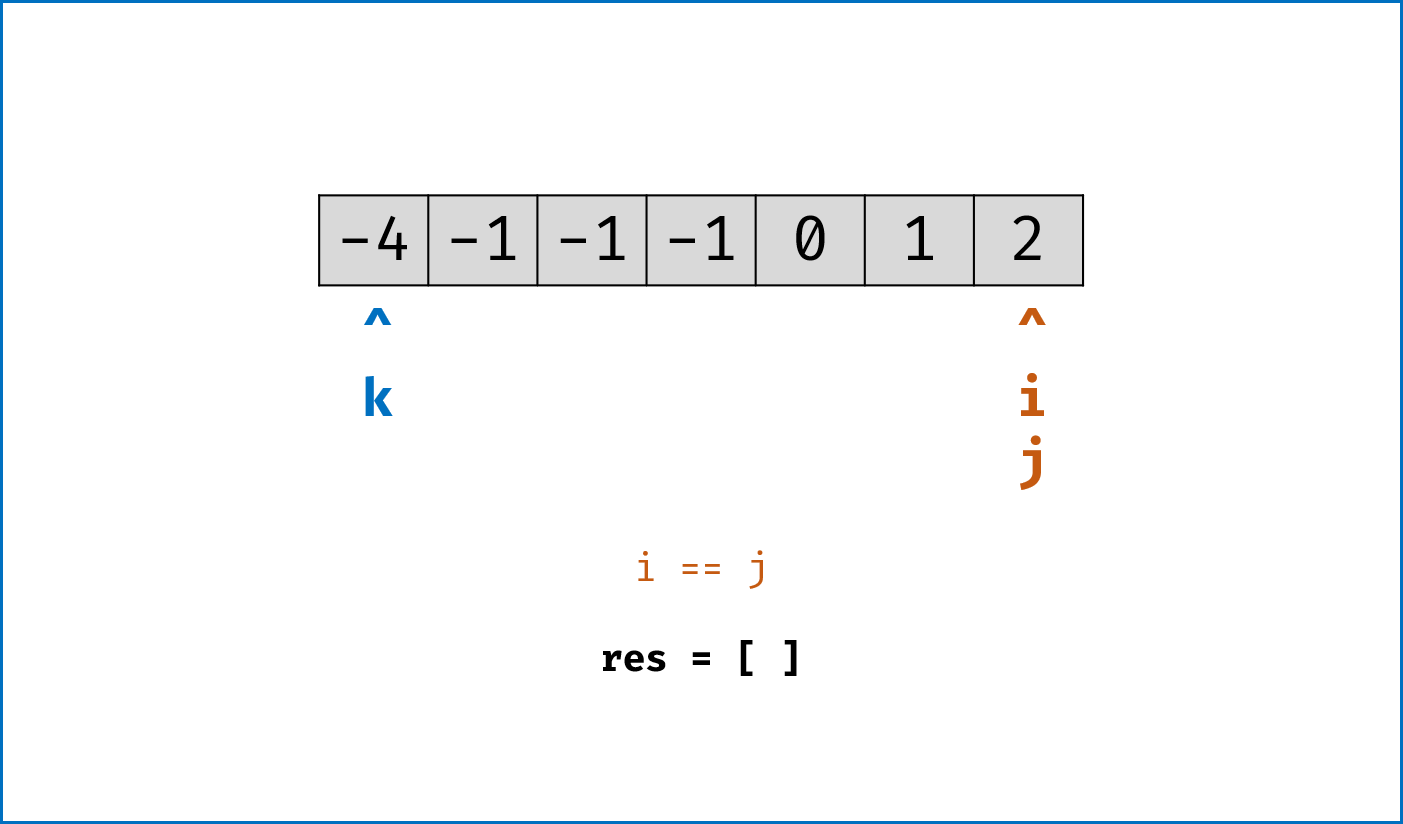


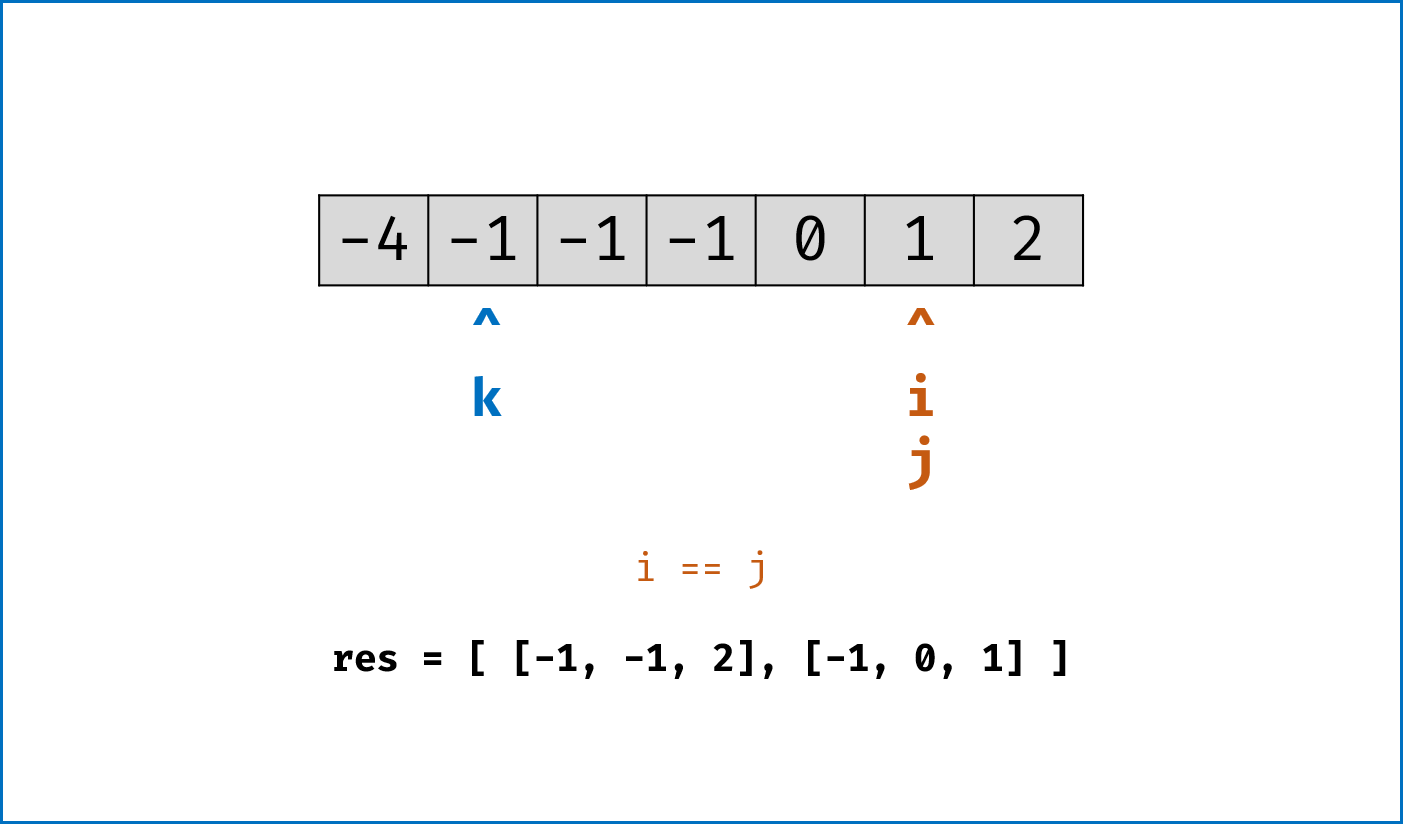


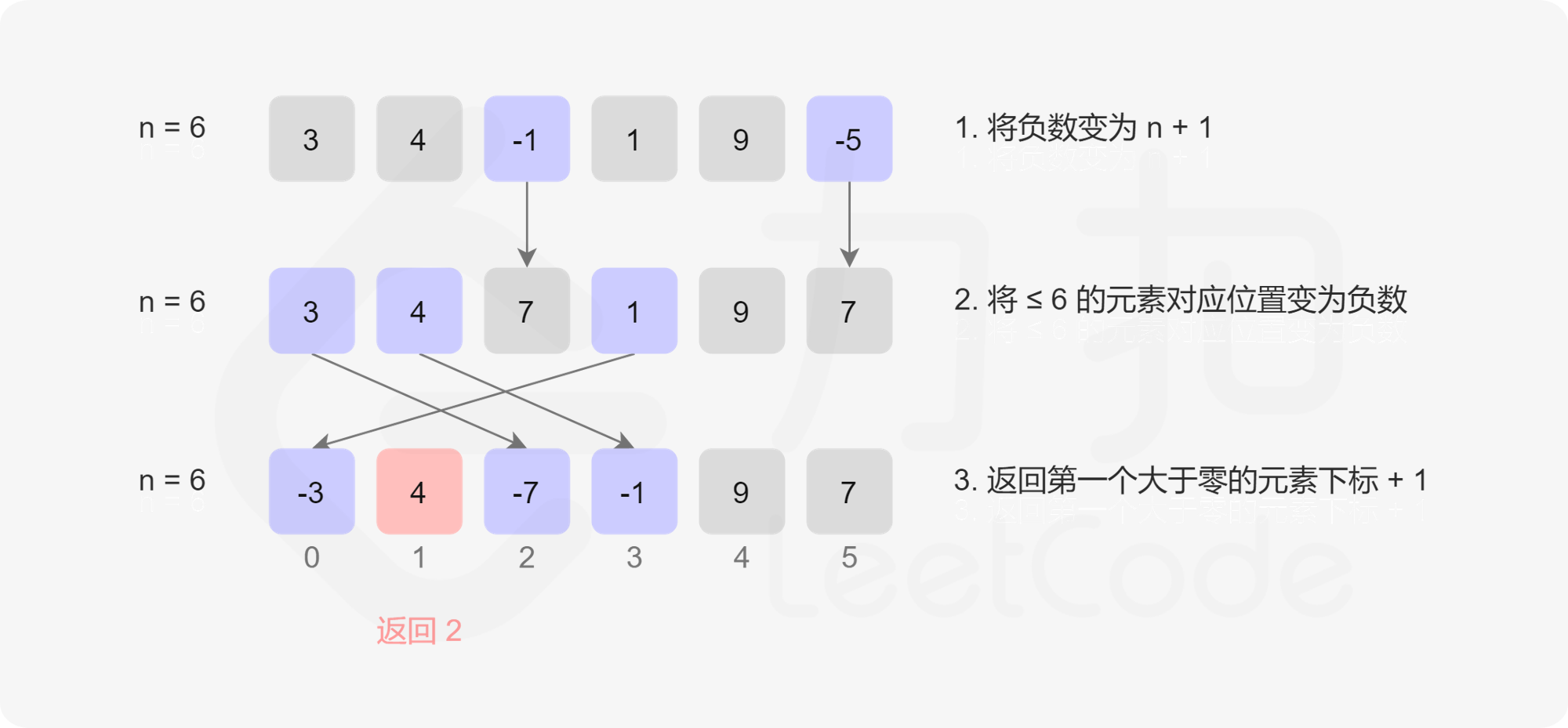
给你一个未排序的整数数组 nums ,请你找出其中没有出现的最小的正整数。请你实现时间复杂度为 O(n) 并且只使用常数级别额外空间的解决方案
1 | 输入:nums = [1,2,0] |
我的解法虽然时间复杂度为O(N),但是空间复杂度也是O(N),不太满足题意
1 | from collections import defaultdict |
看下官方提供的解题思路:
最基本的办法是,可以从1开始依次枚举正整数,并遍历数组nums,判断其是否在数组中,显然整个时间复杂度是O(N2),为了降低时间复杂度,可以将数组元素查找转化为字典或集合元素查找,时间复杂度从O(N)降低为O(1),仍然是从1开始依次枚举正整数,然后判断该正整数是否存在于哈希表中,于是整体时间复杂度变为O(N),这也正是我所采取的做法
实际上,对于一个长度为 N 的数组,其中没有出现的最小正整数只能在 [1,N+1] 中,这是因为如果 [1,N] 都出现了,那么答案必然是 N+1,否则答案将是 [1,N] 中没有出现的最小正整数。于是我们对数组 nums 进行遍历,对于遍历到的数 x,如果它在 [1,N] 的范围内,那么就将数组中的第 x-1 个位置(注意数组下标从 0 开始计数)打上「标记」,在遍历结束之后,如果所有的位置都被打上了标记,那么答案是 N+1,否则答案是最小的没有打上标记的位置加 1,如何打标记呢?你可以申请一个尺寸为 N 的额外的标记数组,但是这违背了题目要求空间复杂度为 O(1) 的需求,因此官方提供了一个巧妙的思路,其将数组 nums 本身作为标记数组,以元素的正负作为「标记」,具体操作如下:
- 首先将数组
nums中所有小于等于 0 的数修改为 N+1 - 遍历数组
nums中的每一个数x,如果其介于 [1,N],则将nums位置下标为x-1的元素置为负数,如果已经是负数,则什么也不做 - 在遍历完成之后,如果数组
nums中的每一个数都是负数,那么答案是 N+1,否则答案是遇到的第一个正数的下标位置加 1
给定一个非负整数数组 nums,你最初位于数组的第一个下标,数组中的每个元素代表你在该位置可以跳跃的最大长度,判断你是否能够到达最后一个下标
1 | 输入:nums = [2,3,1,1,4] |
题目做到这里,我已经一点信心都没有了。我摊牌了,我就是那个蠢蛋…
看了官方解答,让我想起本科安全编程的一道病毒传染问题,求最大传染范围,当时我使用了一个队列执行广度优先搜索(病毒一圈一圈地向外传染),首先针对传染源,获取其周围的邻居节点,将其添加到队列中,然后依次遍历队列中的元素,遍历过的元素将从队列头部弹出,继续搜索这些邻居节点的邻居节点,并依次添加到队列尾部,遍历直至队列为空
这个跳跃游戏和病毒感染非常类似,求最远可达位置,首先针对开始所处的位置也就是数组第一个下标(从0开始计数),其跳跃的最远可达位置为 0+nums[0],于是将所有可达位置 [1,...,nums[0]] (仅针对从未访问过的位置)添加到队列中,然后依次遍历队列中的元素,遍历过的元素将从队列头部弹出,继续搜索从这些可达位置可以跳跃到的所有可达位置,并依次添加到队列尾部,遍历直至队列为空,而队列中出现过的最大值就是待求,如果小于数组最后一个位置下标的数值,则游戏失败,否则成功
1 | nums = [3,2,1,0,4] |
给定一个非负整数数组,你最初位于数组的第一个位置,数组中的每个元素代表你在该位置可以跳跃的最大长度。你的目标是使用最少的跳跃次数到达数组的最后一个位置,假设你总是可以到达数组的最后一个位置
1 | 输入: [2,3,1,1,4] |
1 | a = [3,2,0,1,4] |
给定三个字符串 s1、s2、s3,请你帮忙验证 s3 是否是由 s1 和 s2 交错组成的
1 | 输入:s1 = "aabcc", s2 = "dbbca", s3 = "aadbbcbcac" |
我只会递归:
1 | s1 = "aacbc" |
不出所料提交超出时间限制…
看下官方提供的动态规划解法(以下为复制粘贴),哇,佩服,唉,为什么我就是不能学以致用呢?我终究仍未掌握那天所学的DP算法…
首先如果∣s1∣+∣s2∣=∣s3∣(此处∣⋅∣表示字符串的长度),那s3必不可能由s1和s2交错组成,在∣s1∣+∣s2∣=∣s3∣时,可由动态规划求解,我们定义f(i,j)表示s1的前i个元素和s2的前j个元素是否能交错组成s3的前i+j个元素。如果s1的第i个元素(下标索引从0计数,即s1[i−1])和s3的第i+j个元素(即s3[i+j−1])相等,那么s1的前i个元素和s2的前j个元素是否能交错成s3的前i+j个元素取决于s1的前i−1个元素和s2的前j个元素是否能交错组成s3的前i+j−1个元素,即此时f(i,j)取决于f(i−1,j),在此情况下如果f(i−1,j)为真,则f(i,j)也为真。同样的,如果s2的第j个元素和s3的第i+j个元素相等并且f(i,j−1)为真,则f(i,j)也为真。于是我们可以推导出这样的动态规划转移方程:f(i,j)=(f(i−1,j)ands1[i−1]==s3[p])or(f(i,j−1)ands2[j−1]==s3[p]),其中p=i+j−1,边界条件f(0,0)为真。真太妙了。代码略
转战思源…
Vercel镜像站:https://vercel.muggledy.top




