Comparing with mean (with signal)
Yuxin Zou
2018-04-24
Last updated: 2018-04-25
library(mashr)Loading required package: ashrlibrary(corrplot)corrplot 0.84 loadedsource('../code/MashSource.R')
source('../code/sim_mean_sig.R')The data contains 10 conditions with 10% non-null samples. For the non-null samples, it has equal effects in the first c conditions.
Let L be the contrast matrix that subtract mean from each sample.
\[\hat{\delta}_{j}|\delta_{j} \sim N(\delta_{j}, \frac{1}{2}LL')\] 90% of the true deviations are 0. 10% of the deviation \(\delta_{j}\) has correlation that the first c conditions are negatively correlated with the rest conditions.
Mash contrast model
We set \(c = 2\).
set.seed(1)
R = 10
C = 2
data = sim.mean.sig(nsamp=10000, ncond=C)L = matrix(-1/R, R, R)
L[cbind(1:R,1:R)] = (R-1)/R
L = L[1:(R-1),]
row.names(L) = seq(1,R-1)
mash_data = mash_set_data(Bhat=data$Chat, Shat=data$Shat)
mash_data_L = mash_set_data_contrast(mash_data, L)U.c = cov_canonical(mash_data_L)
# data driven
# select max
m.1by1 = mash_1by1(mash_data_L, alpha=1)
strong = get_significant_results(m.1by1,0.05)
# center Z
mash_data_L.center = mash_data_L
mash_data_L.center$Bhat = mash_data_L$Bhat/mash_data_L$Shat # obtain z
mash_data_L.center$Shat = matrix(1, nrow(mash_data_L$Bhat),ncol(mash_data_L$Bhat))
mash_data_L.center$Bhat = apply(mash_data_L.center$Bhat, 2, function(x) x - mean(x))
U.pca = cov_pca(mash_data_L.center,2,strong)
U.ed = cov_ed(mash_data_L.center, U.pca, strong)
mashcontrast.model = mash(mash_data_L, c(U.c, U.ed), algorithm.version = 'R', verbose = FALSE)Using mashcommonbaseline, there are 288 discoveries. The covariance structure found here is: 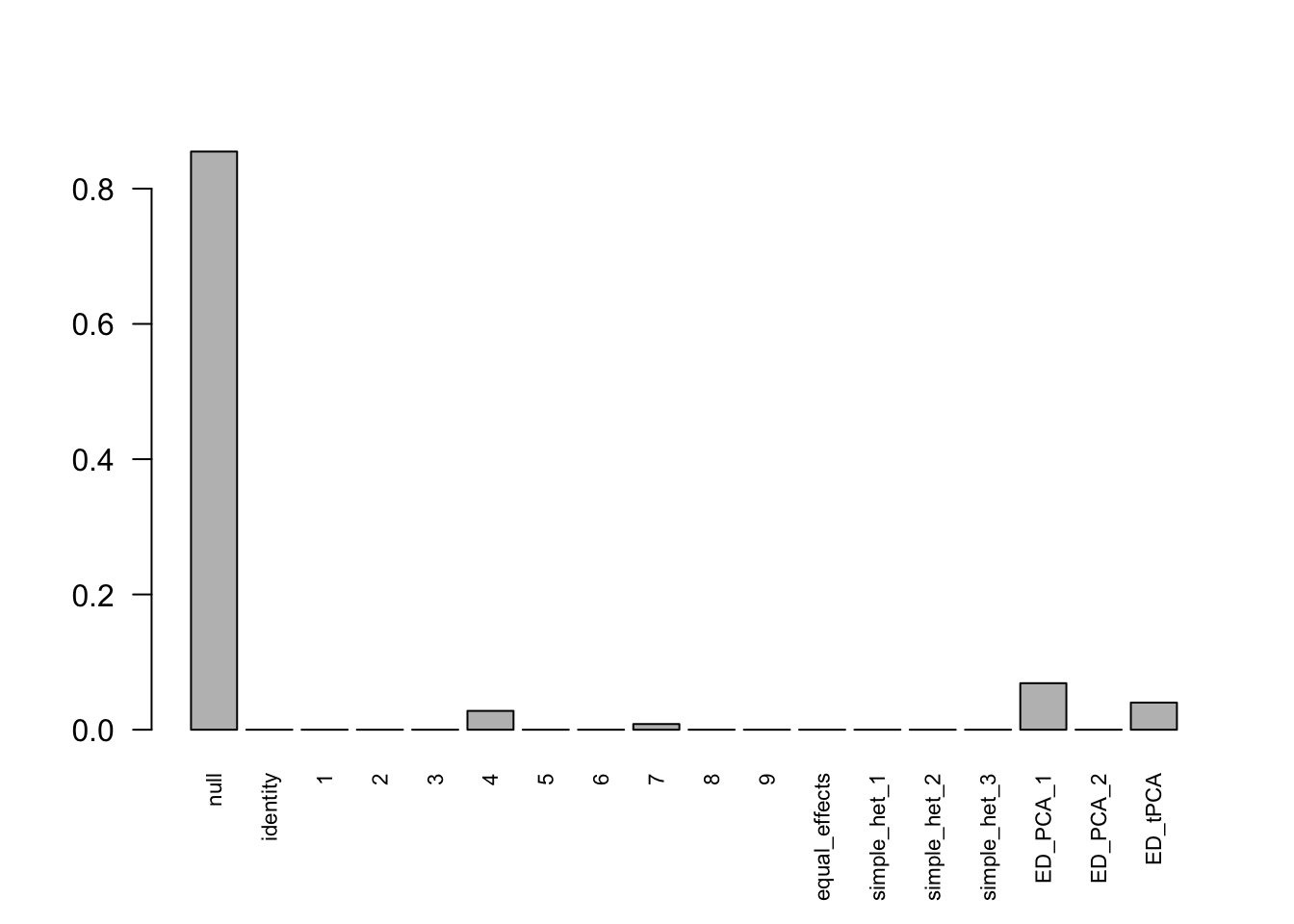 The correlation for PCA1 is:
The correlation for PCA1 is: 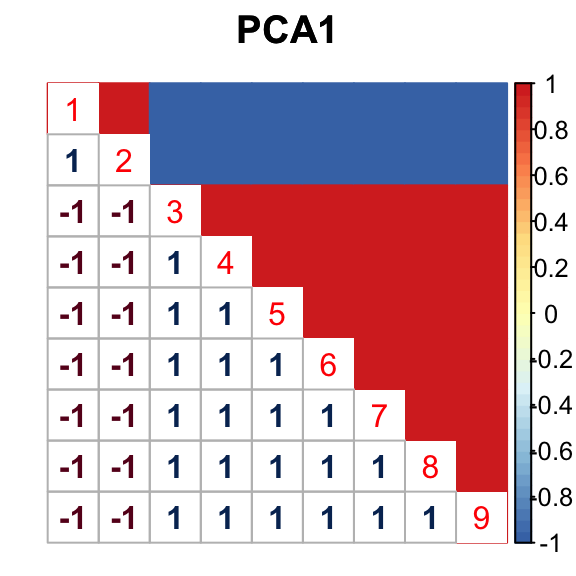
The correlation identified here is correct.
Recover
mashcontrast.model.full = mashcontrast.model
mashcontrast.model.full$result = mash_compute_posterior_matrices(g = mashcontrast.model, data = mash_data_L, algorithm.version = 'R', recover=TRUE)There are 289 discoveries.
U = mashcontrast.model$fitted_g$Ulist[["ED_PCA_1"]]
U_rec = cbind(U, -rowSums(U))
U_rec = rbind(U_rec, c(-rowSums(U), sum(U)))
x <- cov2cor(U_rec)
x[x > 1] <- 1
x[x < -1] <- -1
colnames(x) <- c(colnames(get_lfsr(mashcontrast.model)), 'Discard')
rownames(x) <- colnames(x)
corrplot.mixed(x,upper='color',cl.lim=c(-1,1), upper.col=colorRampPalette(rev(c("#D73027","#FC8D59","#FEE090","#FFFFBF",
"#E0F3F8","#91BFDB","#4575B4")))(40),
title='PCA1',mar=c(0,0,1.5,0))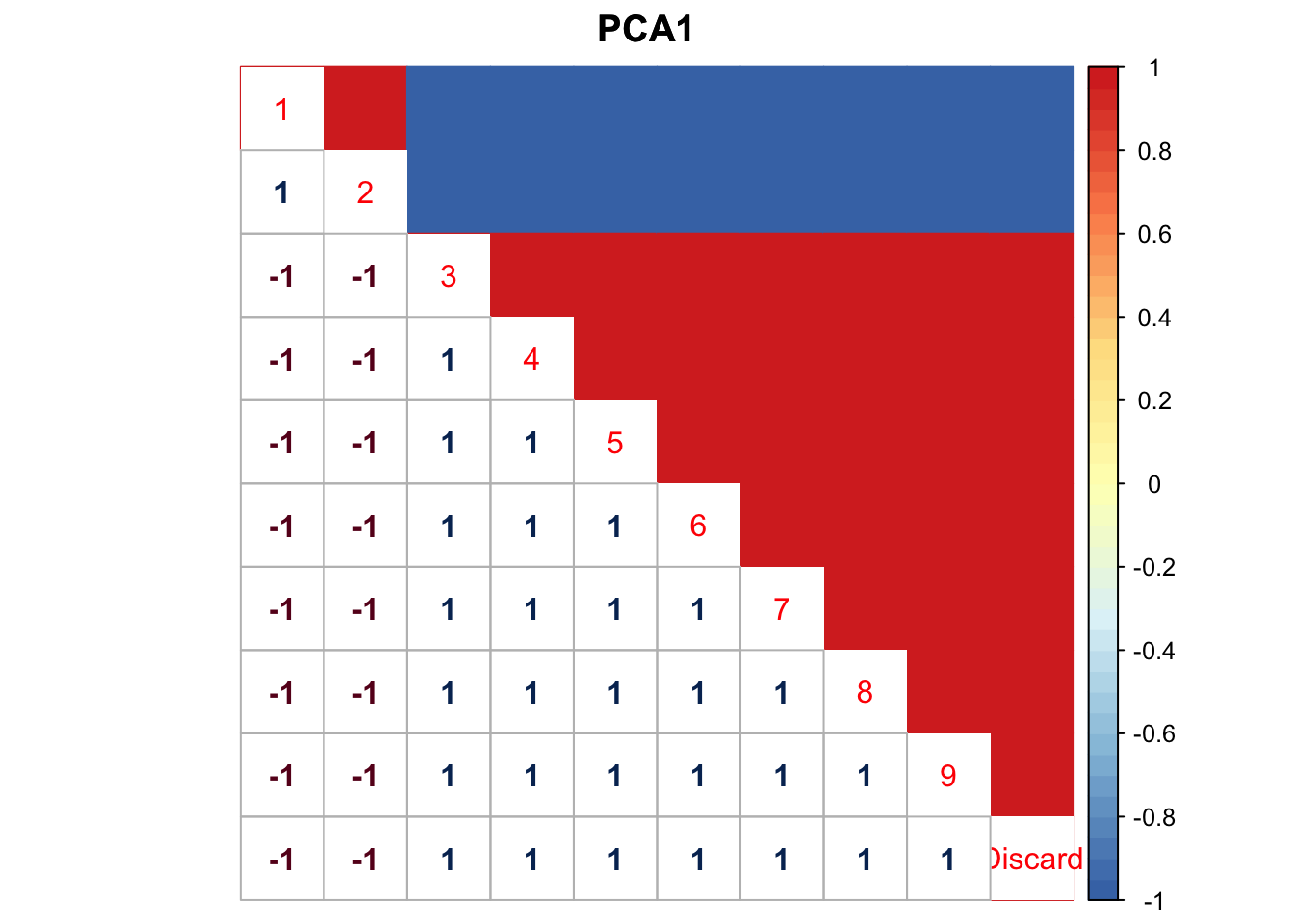
Subtract mean directly
If we subtract the mean from the data directly \[Var(\hat{c}_{j,r}-\bar{\hat{c}_{j}}) = \frac{1}{2} - \frac{1}{2R}\]
Indep.data = mash_set_data(Bhat = mash_data_L$Bhat,
Shat = matrix(sqrt(0.5-1/(2*R)), nrow(data$Chat), R-1))
Indep.model = mash(Indep.data, c(U.c, U.ed), algorithm.version = 'R', verbose = FALSE)There are 336 discoveries, which is more than the mashcommonbaseline model. The covariance structure found here is: 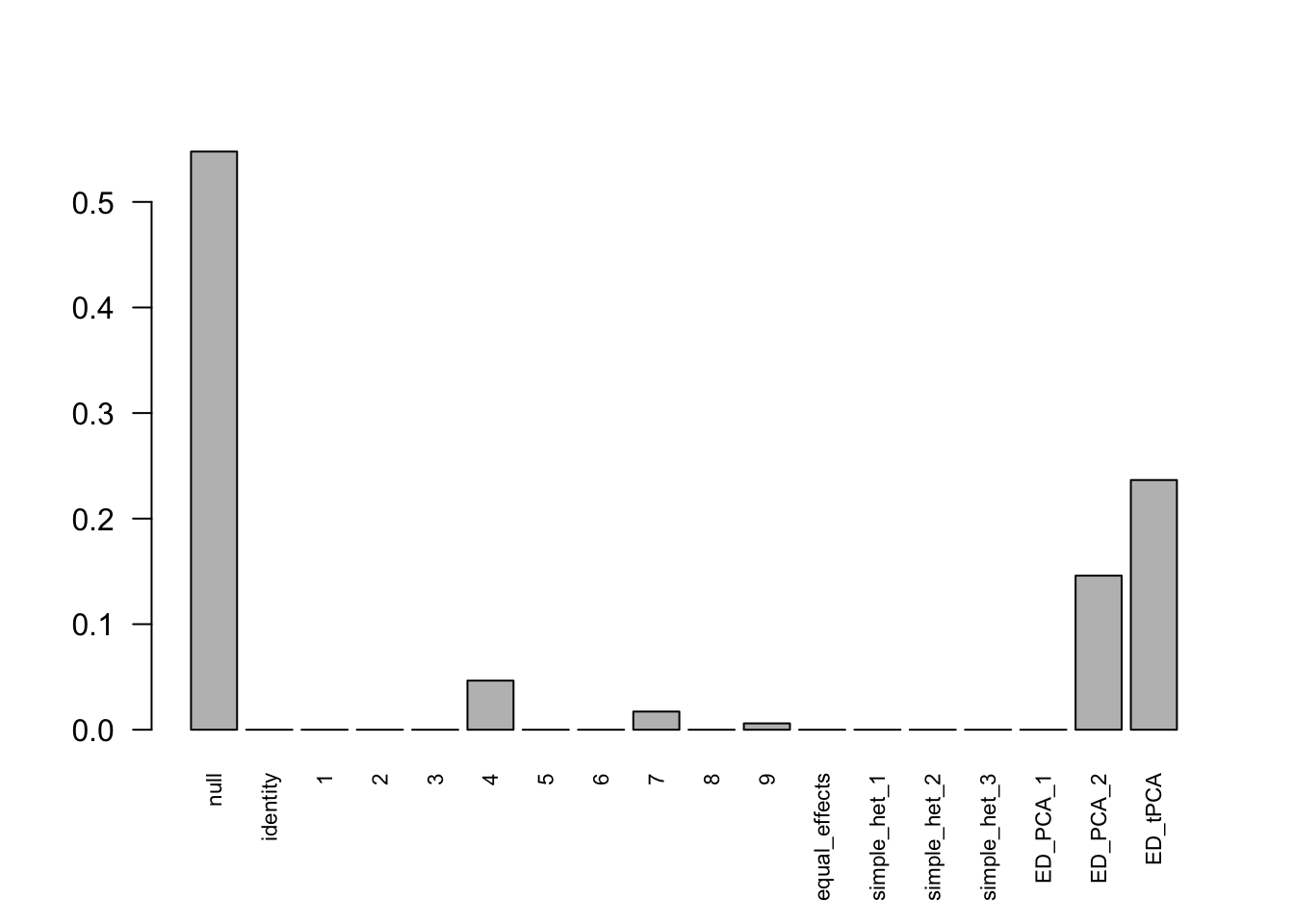 The weights for covariances are very different.
The weights for covariances are very different.
The correlation for PCA2 and tPCA is: 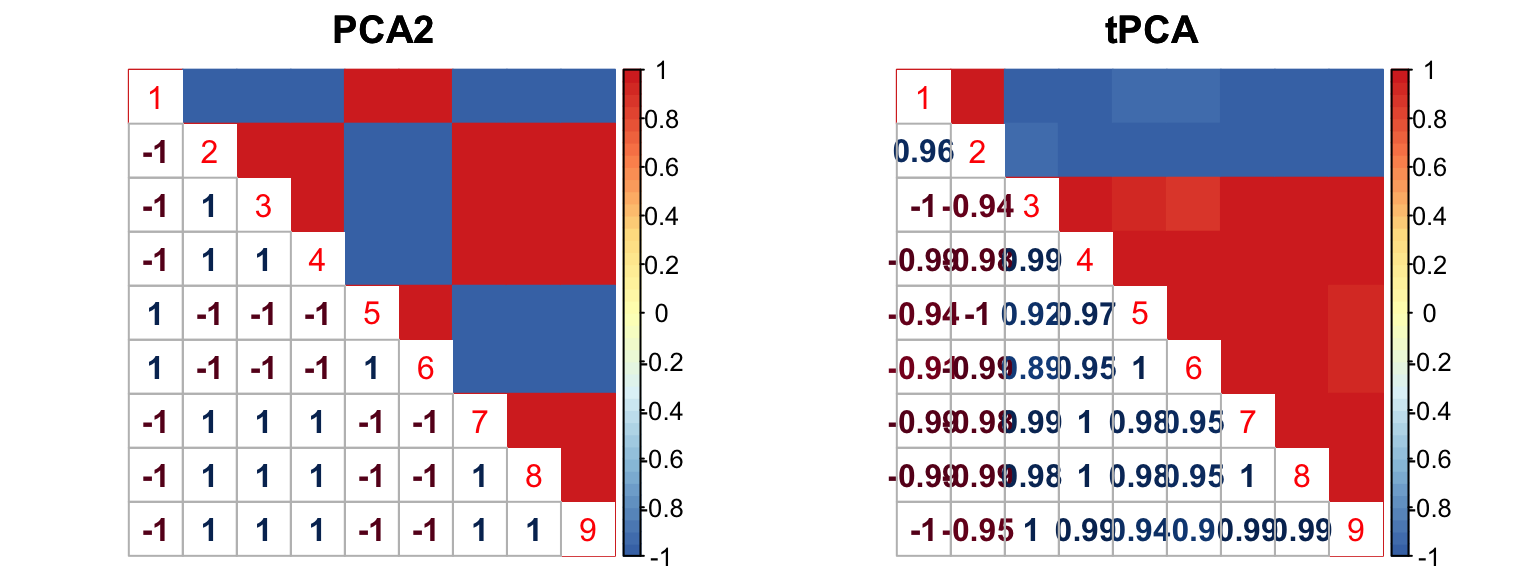
Recover
Indep.model.full = Indep.model
Indep.model.full$result = mash_compute_posterior_matrices(g = Indep.model, data = Indep.data, algorithm.version = 'R', recover=TRUE)There are 336 discoveries.
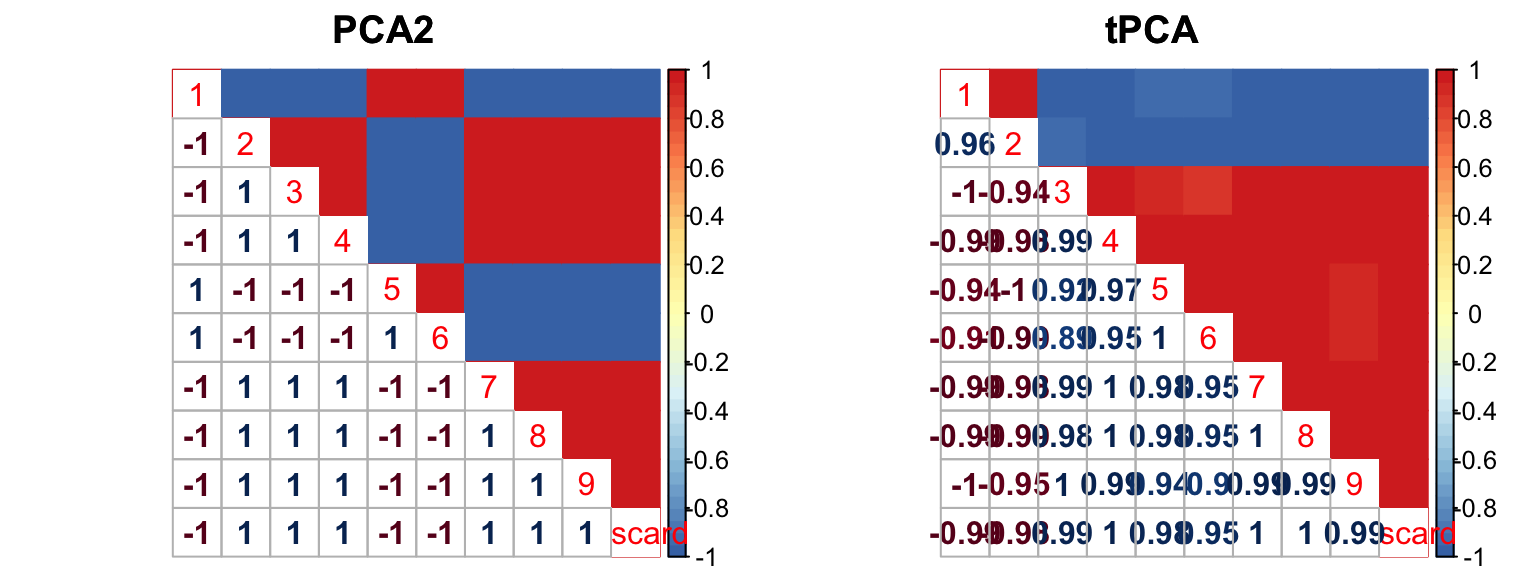
Compare two models
The RRMSE plot:

We check the False Positive Rate and True Positive Rate. \[FPR = \frac{|N\cap S|}{|N|} \quad TPR = \frac{|CS\cap S|}{|T|} \]
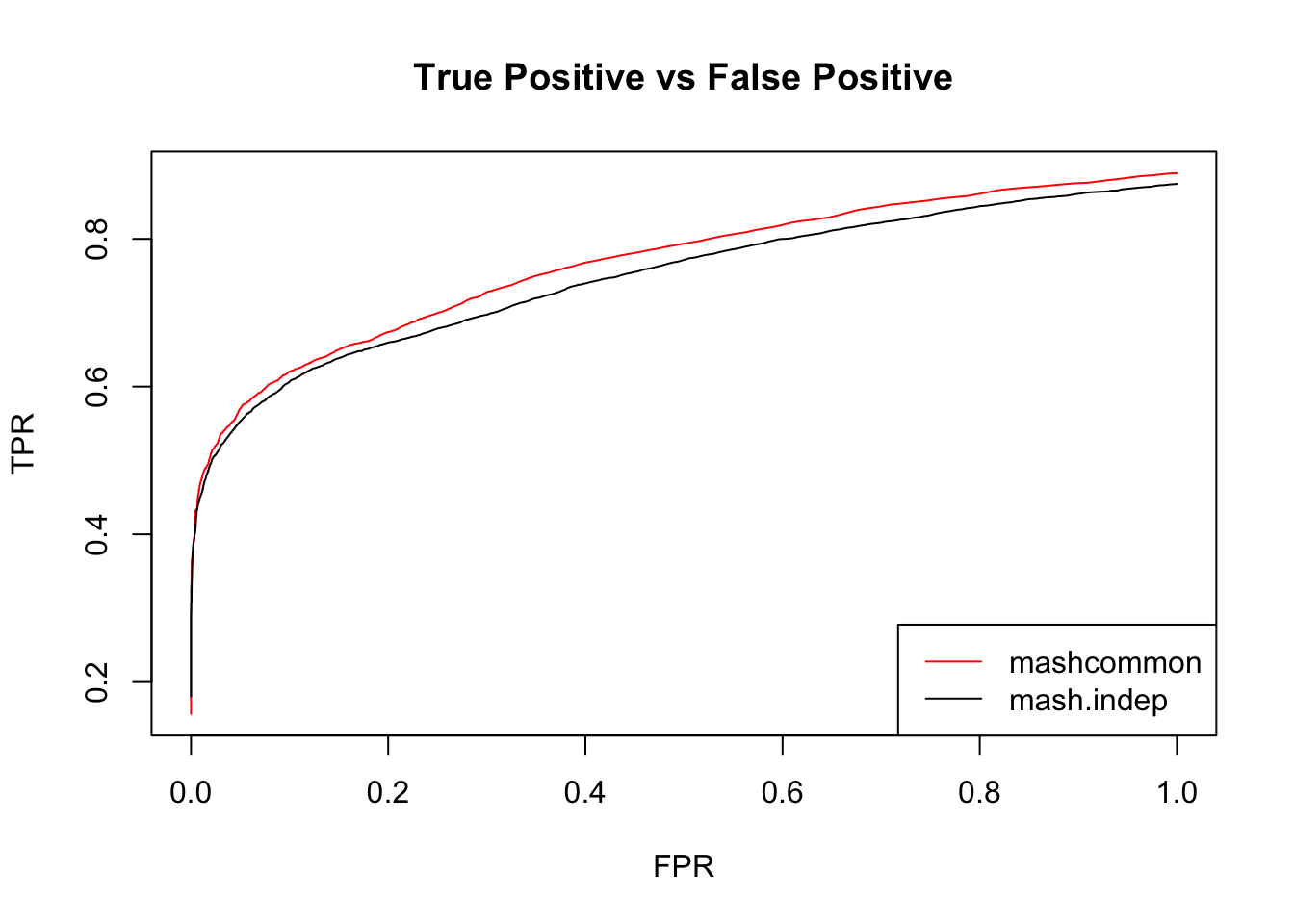
These methods are similar in terms of the number of false positives versus true positive. The mashcommonbaseline model is slightly better than mash.indep model.
Session information
sessionInfo()R version 3.4.4 (2018-03-15)
Platform: x86_64-apple-darwin15.6.0 (64-bit)
Running under: macOS High Sierra 10.13.4
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/3.4/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/3.4/Resources/lib/libRlapack.dylib
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] mvtnorm_1.0-7 plyr_1.8.4 assertthat_0.2.0 corrplot_0.84
[5] mashr_0.2-6 ashr_2.2-7
loaded via a namespace (and not attached):
[1] Rcpp_0.12.16 knitr_1.20
[3] magrittr_1.5 REBayes_1.3
[5] MASS_7.3-49 doParallel_1.0.11
[7] pscl_1.5.2 SQUAREM_2017.10-1
[9] lattice_0.20-35 ExtremeDeconvolution_1.3
[11] foreach_1.4.4 stringr_1.3.0
[13] tools_3.4.4 parallel_3.4.4
[15] grid_3.4.4 rmeta_3.0
[17] htmltools_0.3.6 iterators_1.0.9
[19] yaml_2.1.18 rprojroot_1.3-2
[21] digest_0.6.15 Matrix_1.2-14
[23] codetools_0.2-15 evaluate_0.10.1
[25] rmarkdown_1.9 stringi_1.1.7
[27] compiler_3.4.4 Rmosek_8.0.69
[29] backports_1.1.2 truncnorm_1.0-8 This R Markdown site was created with workflowr