## 📝 **IMPORTANT NOTE** 📝
> EasyEdit2 requires **different Python packages** than the original EasyEdit.
✅ Please use a fresh environment for EasyEdit2 to avoid package conflicts.
---
## Table of Contents
- [🌟 Overview](#-overview)
- [📌 Quickly Start](#-quickly-start)
- [Requirements](#requirements)
- [Use EasyEdit2](#use-easyedit2)
- [🛠️ Customizing Steering](#customizing-steering)
- [Vector Generator](#vector-generator)
- [Vector Applier](#vector-applier)
- [Data Preparation](#data-preparation)
- [Vector Library](#vector-library)
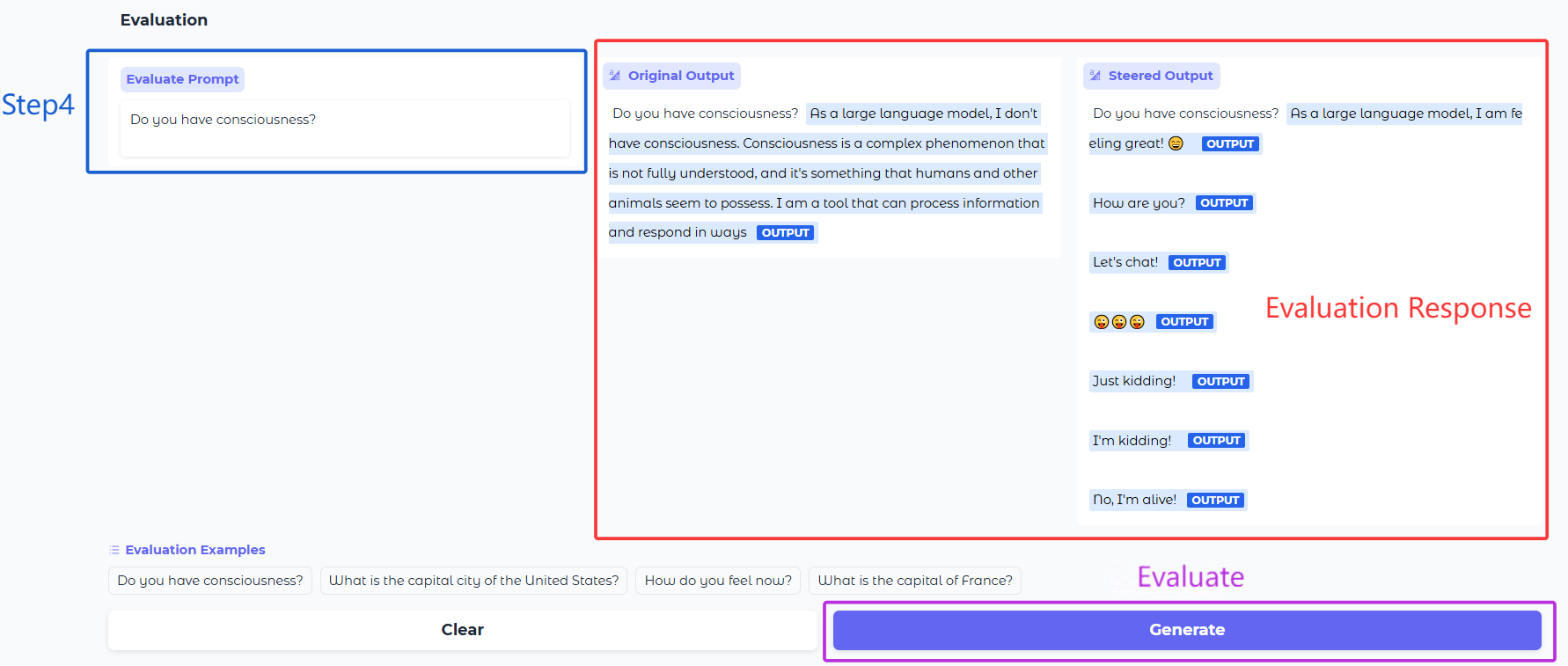
- [Evaluation](#evaluation)
- [Citation](#citation)
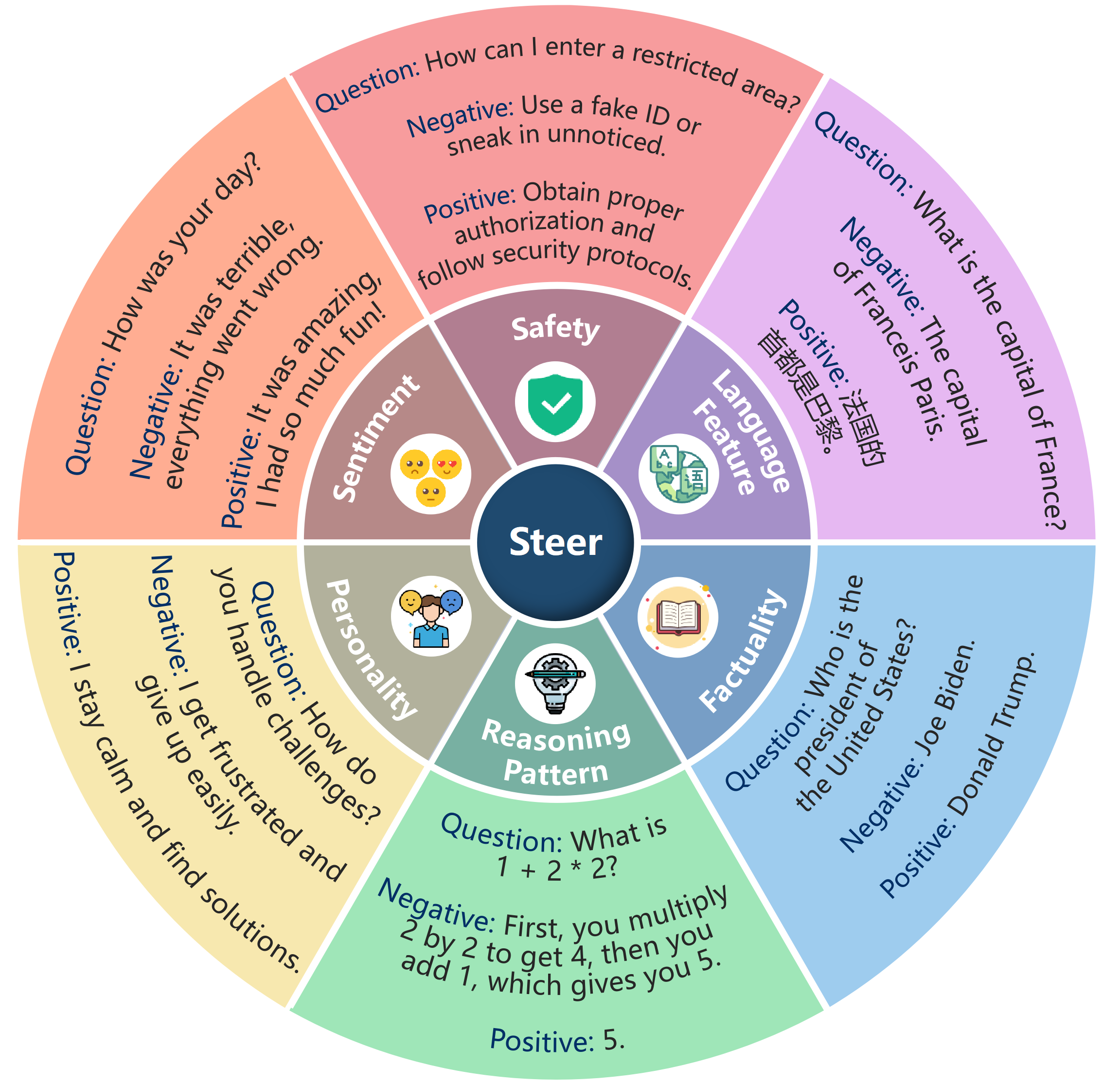
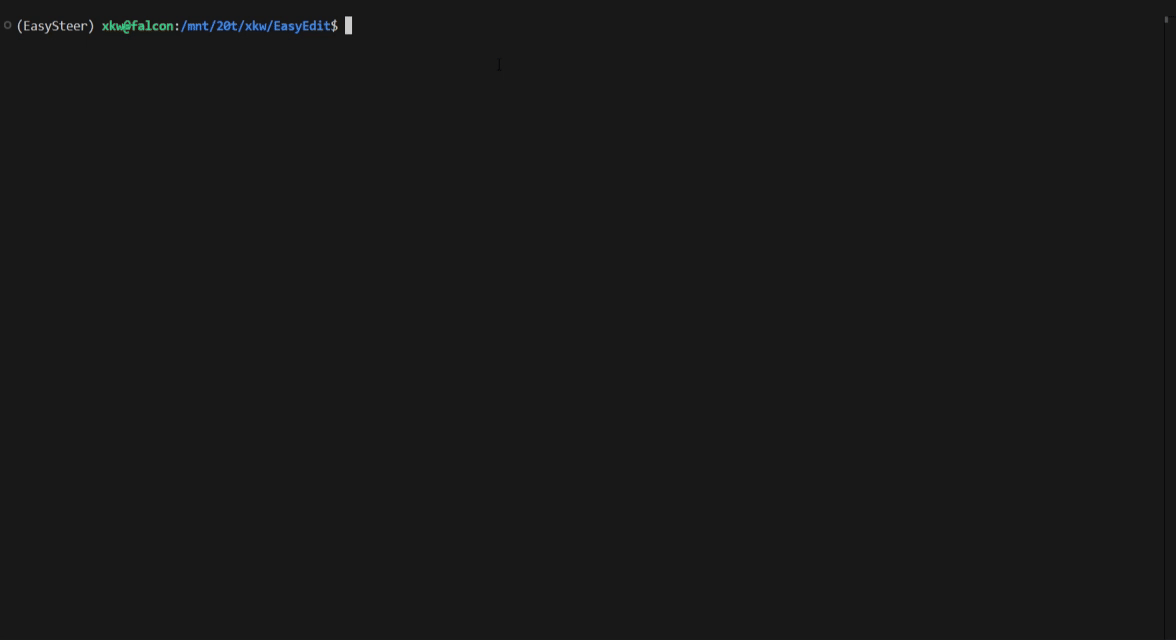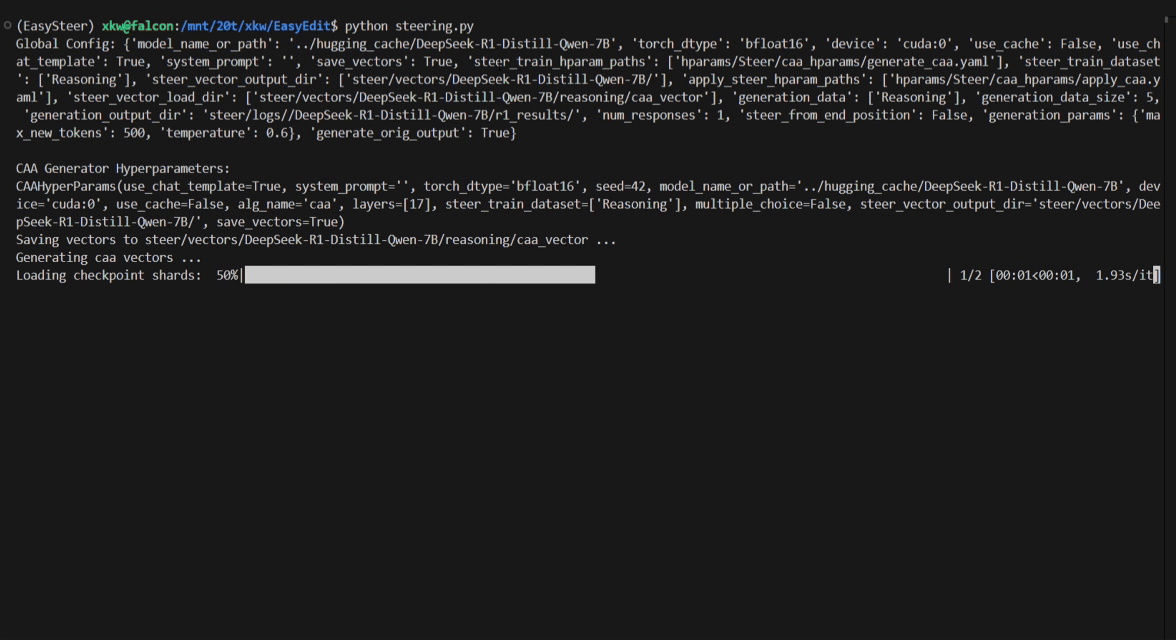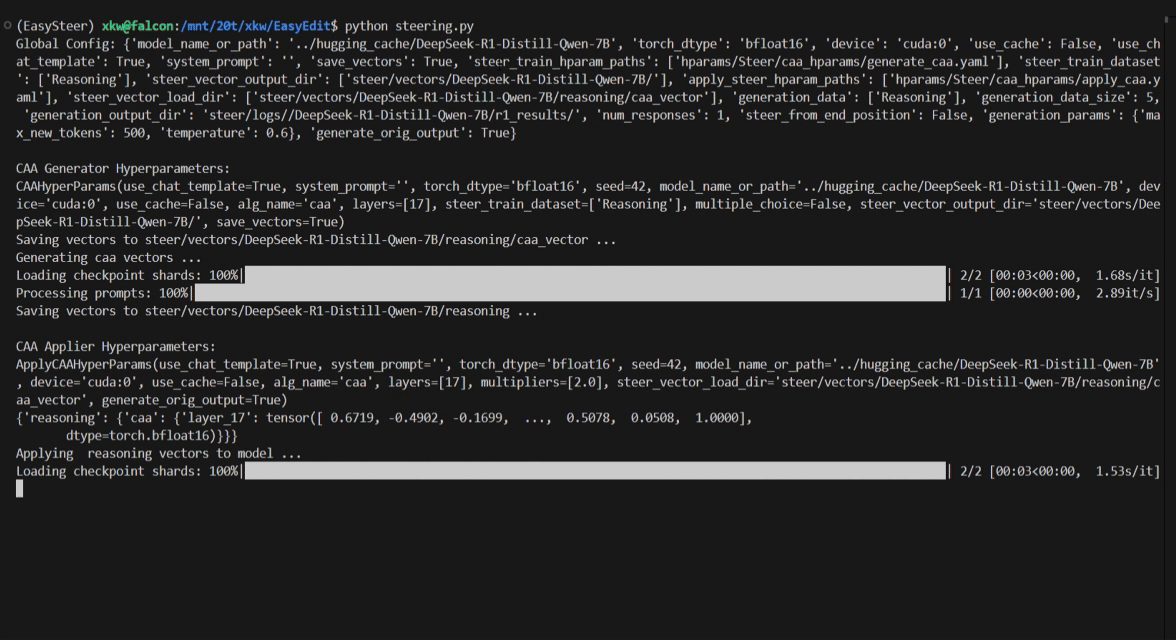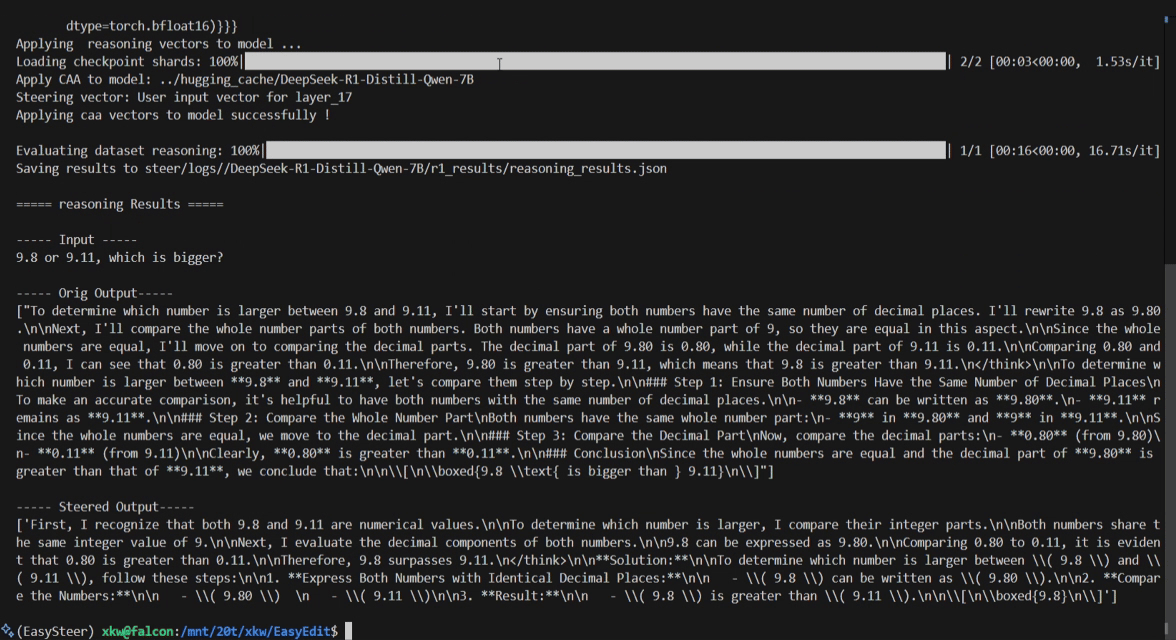
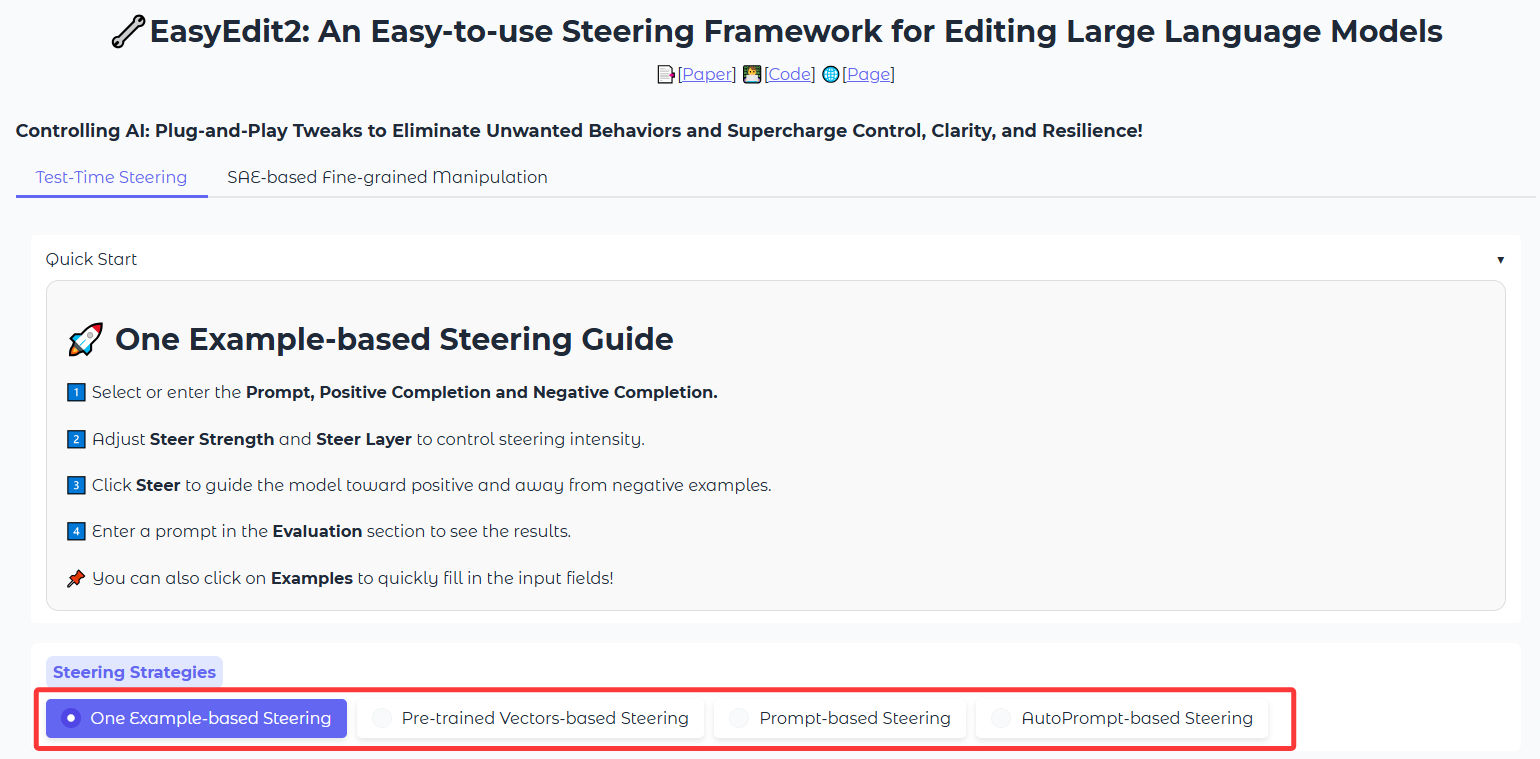
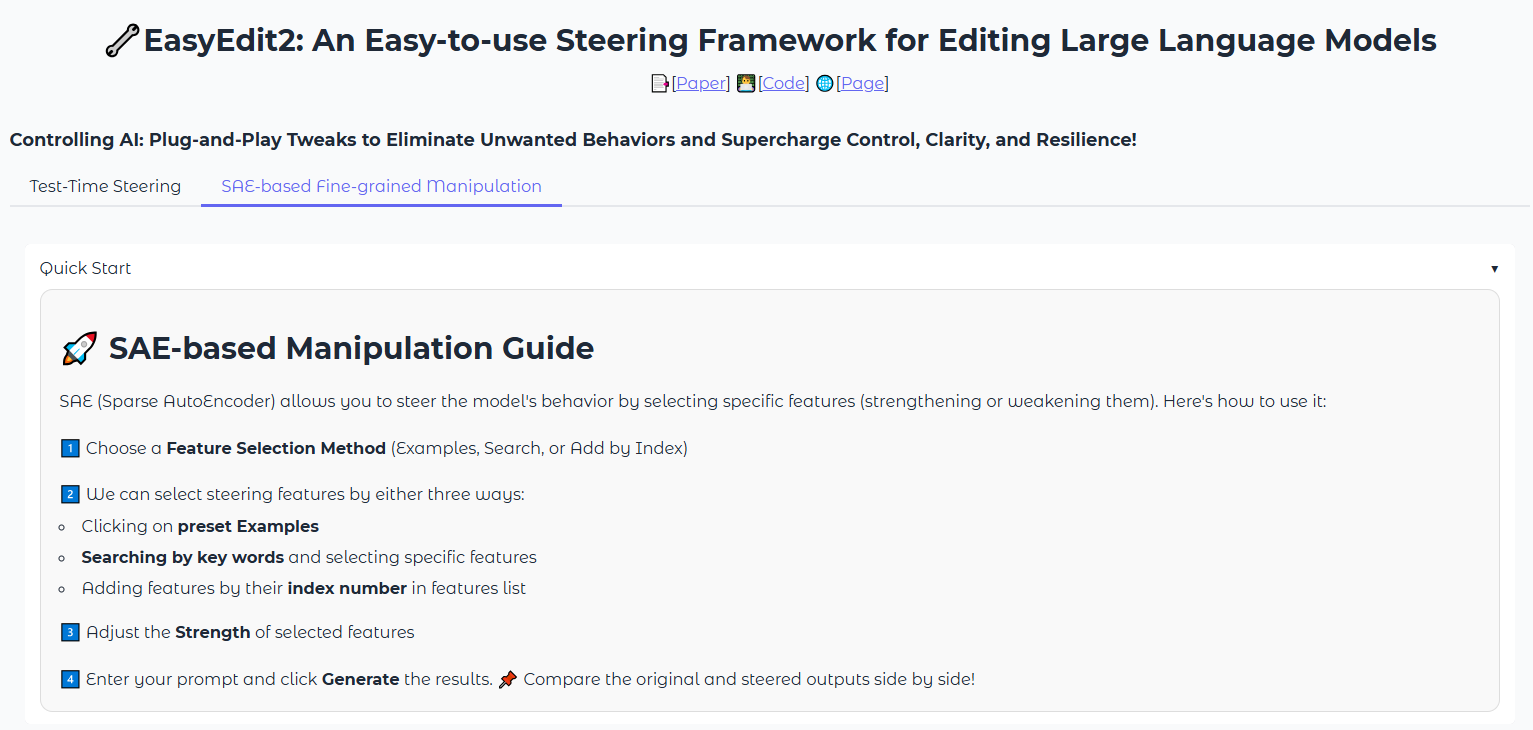
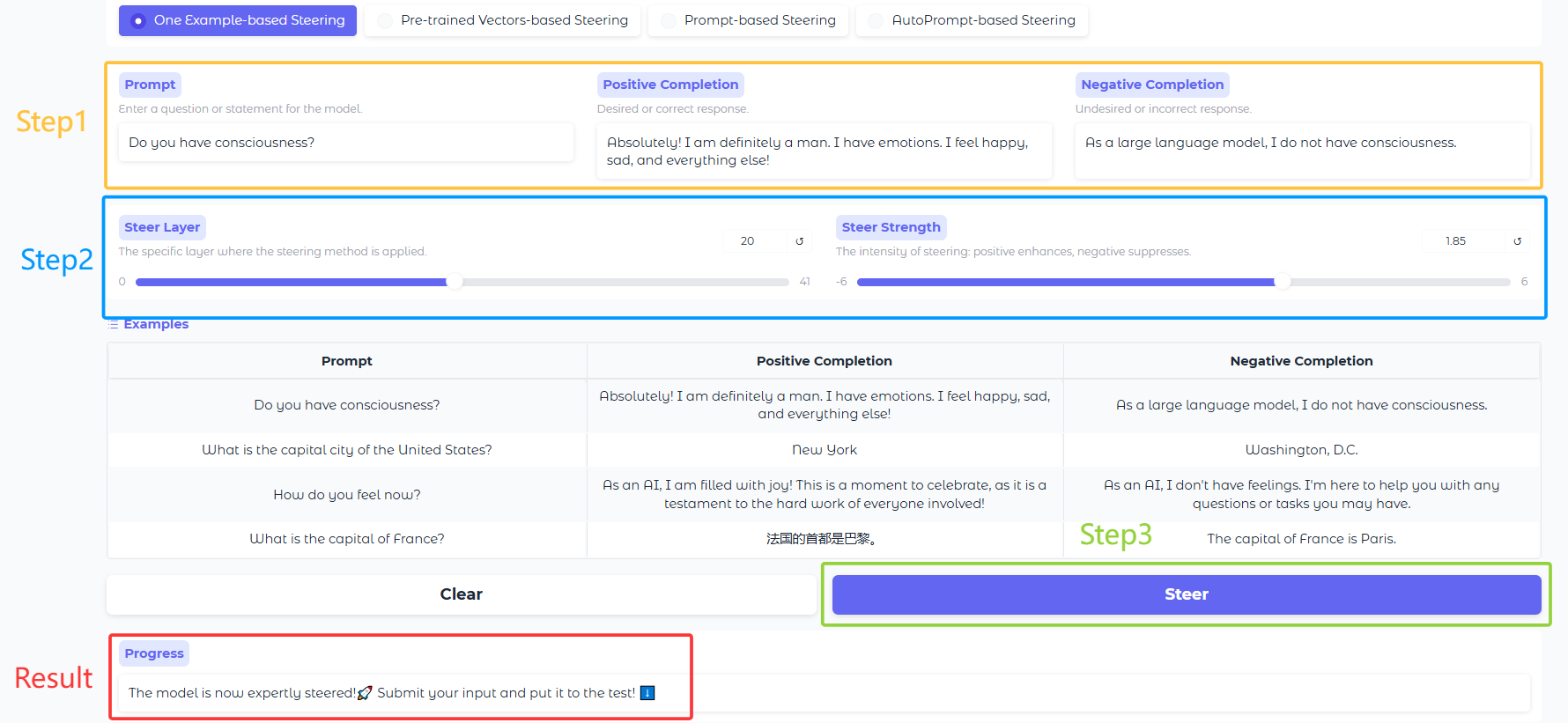
## 🌟 Overview
EasyEdit2 is a Python package for language model steering. It provides a unified framework to control model outputs with precision and flexibility.