![]()
| Documentation | DeepWiki | User Forum | Developer Slack | WeChat | Paper | Slides |
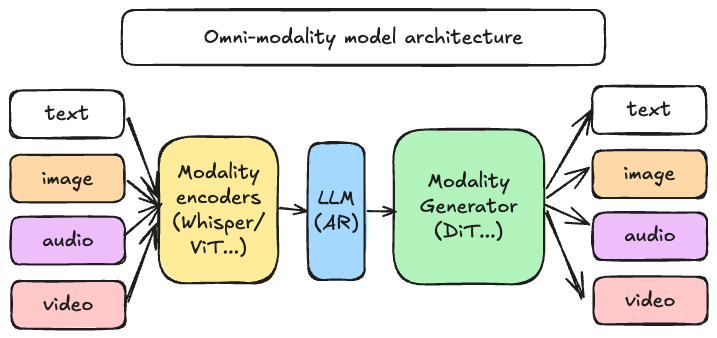
--- *Latest News* 🔥 - [2026/06] We released [0.22.0](https://github.com/vllm-project/vllm-omni/releases/tag/v0.22.0) - an **omnimodal world-model** release aligned with vLLM 0.22, featuring [Nvidia Cosmos3](recipes/cosmos3/Cosmos3-Nano.md)/DreamZero world model support, expanded quantization coverage across Blackwell/NPU/XPU, TTS production improvements, new models including MiniCPM-o 4.5, MOSS-TTS, and Lance, plus RL integration with [VeRL-Omni](https://github.com/verl-project/verl-omni). - [2026/05] We released [0.20.0](https://github.com/vllm-project/vllm-omni/releases/tag/v0.20.0) - refreshes the serving/runtime stack for large-scale omni workloads, and improves diffusion model performance, quantization, and hardware readiness across CUDA, ROCm, MUSA, NPU, and XPU backends. - [2026/03] We released [0.18.0](https://github.com/vllm-project/vllm-omni/releases/tag/v0.18.0) - strengthens the core runtime through a large entrypoint refactor and scheduler/runtime cleanups, expands unified quantization and diffusion execution, broadens multimodal model coverage, and improves production readiness across audio, omni, image, video, RL, and multi-platform deployments. - [2026/03] Check out our first public [project deepdive](https://youtu.be/sgwNfsNnR9I) at the vLLM Hong Kong Meetup! - [2026/03] **[vllm-omni-skills](https://github.com/hsliuustc0106/vllm-omni-skills)** is a community-driven collection of AI assistant skills that help developers work with vLLM-Omni more effectively. These skills can be used with popular agentic AI coding assistants like **Cursor IDE**, **Claude**, **Codex**, and more. - [2026/02] We released [0.16.0](https://github.com/vllm-project/vllm-omni/releases/tag/v0.16.0) - A major alignment + capability release that rebases onto **upstream vLLM v0.16.0** and significantly expands performance, distributed execution, and production readiness across **Qwen3-Omni / Qwen3-TTS**, **Bagel**, **MiMo-Audio**, **GLM-Image** and the **Diffusion (DiT) image/video stack**—while also improving platform coverage (CUDA / ROCm / NPU / XPU), CI quality, and documentation. - [2026/02] We released [0.14.0](https://github.com/vllm-project/vllm-omni/releases/tag/v0.14.0) - This is the first **stable release** of vLLM-Omni that expands Omni’s diffusion / image-video generation and audio / TTS stack, improves distributed execution and memory efficiency, and broadens platform/backend coverage (GPU/ROCm/NPU/XPU). It also brings meaningful upgrades to serving APIs, profiling & benchmarking, and overall stability. Please check our latest [paper](https://arxiv.org/abs/2602.02204) for architecture design and performance results. - [2025/11] vLLM community officially released [vllm-project/vllm-omni](https://github.com/vllm-project/vllm-omni) in order to support omni-modality models serving. --- ## About [vLLM](https://github.com/vllm-project/vllm) was originally designed to support large language models for text-based autoregressive generation tasks. vLLM-Omni is a framework that extends its support for omni-modality model inference and serving: - **Omni-modality**: Text, image, video, and audio data processing - **Non-autoregressive Architectures**: extend the AR support of vLLM to Diffusion Transformers (DiT) and other parallel generation models - **Heterogeneous outputs**: from traditional text generation to multimodal outputs
{kind=link}