11. Управление лингвистическими данными
Структурированные коллекции аннотированных лингвистических данных имеют важное значение в большинстве областей NLP, однако, мы по-прежнему сталкиваемся с многочисленными препятствиями в их использовании. Цель этой главы - ответить на следующие вопросы:
- Как мы разрабатываем новый языковой ресурс и добиваемся того, чтобы его охват, сбалансированность и документация поддерживали широкий спектр применения?
- Когда существующие данные находятся в неправильном формате для некоторого инструмента анализа, как мы можем преобразовать его в подходящий формат?
- Как документировать существование ресурса, который мы создали, чтобы другие могли легко найти его?
Параллельно мы будем изучать конструкцию существующих корпусов, типичный рабочий процесс для создания корпуса, а также жизненный цикл корпуса. Как и в других главах, будет много примеров из практического опыта управления лингвистическими данными, включая данные, которые были собраны в ходе лингвистической полевой работы, лабораторных работ, а также веб поиска.
1 Структура корпуса: изучение примеров
TIMIT корпус читаемой речи был первой аннотированной базой данных речи, которая была широко распространена, он имел особенно четкую организацию. TIMIT был разработан консорциумом, включая Texas Instruments и MIT, от которых он получил свое название. Он был разработан, чтобы предоставить данные для приобретения акустико-фонетических знаний и поддержки разработки и оценки систем автоматического распознавания речи.
1.1 Структура TIMIT
Как и корпус Брауна, который отображает сбалансированный выбор текстовых жанров и источников, TIMIT включает в себя сбалансированный набор диалектов, говорящих и материалов. Для каждого из восьми диалектных регионов, 50 мужских и женских голосов, имеющих определенный диапазон возрастов и уровня образования, читают по десять тщательно отобранных предложений. Два предложения, которые читаются всеми голосами, были разработаны, чтобы выявить диалектные вариации:
| (1) |
|
Остальные предложения были выбраны как фонетически богатые с участием всех фон (звуков) и полного спектра дифон (звуковые биграммы). Кроме того, конструкция обеспечивает баланс между множественными голосами, читающими то же самое предложение, чтобы позволить проводить сравнения между различными голосами, и широким диапазоном предложений, охватываемых корпус, чтобы получить максимальный охват дифон. Пять из предложений, прочитанных каждым голосом, также читаются шестью другими голосами (для сопоставимости). Остальные три предложения, прочитанных каждым голосом, были уникальны для этого голоса (для охвата).
NLTK включает в себя образец из TIMIT корпуса. Вы можете получить доступ к его документации обычным способом, используя help(nltk.corpus.timit). Выведите на экран nltk.corpus.timit.fileids(), чтобы просмотреть список из 160 записанных высказываний в образце корпуса. Каждое имя файла имеет внутреннюю структуру, как показано на 1.1.
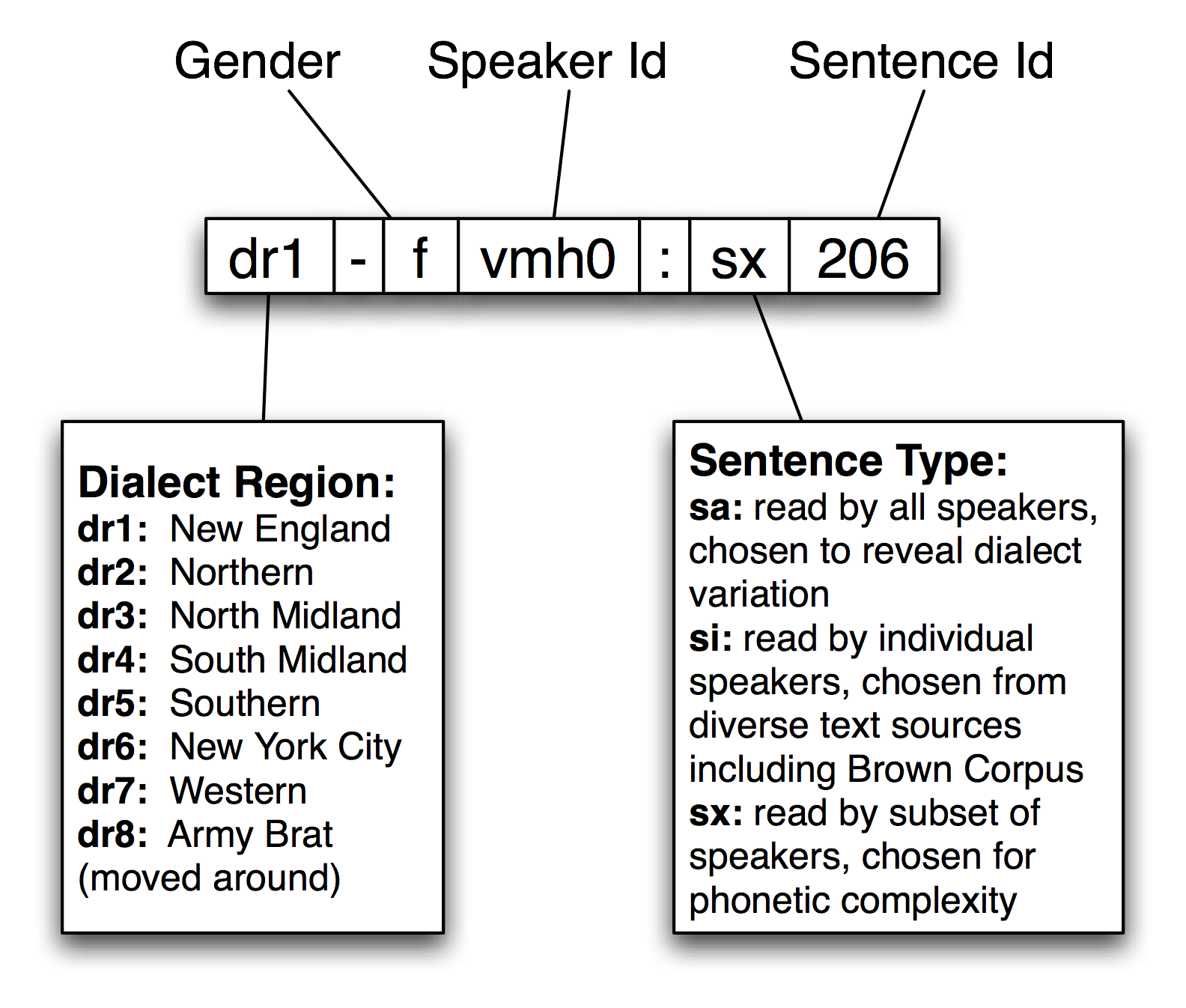
Рисунок 1.1: Структура идентификатора TIMIT: Каждая запись помечается с помощью строки, составленной из диалектной области говорящего, пола, идентификатора диктора, типа предложения и идентификатора предложения.
Каждый элемент имеет фонетическую транскрипцию, которую можно получить с помощью метода phones(). Мы можем получить доступ к соответствующим токенам слов обычным способом. Оба метода обращения допускают необязательный аргумент offset=True, который включает начальные и конечные смещения соответствующего диапазона в аудиофайле.
|
В дополнение к этим текстовым данным TIMIT включает в себя лексикон, который обеспечивает каноническое произношение каждого слова, которое можно сравнить с конкретным произношением:
|
Это дает нам ощущение того, что система обработки речи должна сделать для генерирования или распознавания речи в данном конкретном диалекте (New England). Наконец, TIMIT включает демографические данные о читающих, что позволяет выполнять скурпулезный анализ вокальных, социальных и гендерных характеристик.
|
1.2 Важные конструктивные особенности
TIMIT иллюстрирует несколько ключевых особенностей конструкции корпуса. Во-первых, корпус содержит два слоя аннотаций: на фонетическом и орфографическом уровнях. В общем случае текстовый или речевой корпус может быть аннотирован на разных языковых уровнях, включая морфологический, синтаксический и уровень дискурса. Более того, даже на данном уровне могут существовать различные схемы маркировки или даже разногласия среди аннотирующих такие, что мы захотим представить несколько версий. Вторым свойством TIMIT является баланс между множественными измерения вариации относительно покрытия диалектных регионов и дифон. Включение демографических данных читающих вносит много более независимых переменных, которые могут помочь объяснить вариацию данных и которые облегчают последующее использование корпуса для целей, которые не были предусмотрены при его создании, таких как социолингвистика. Третьим свойством является то, что существует резкое разделение между первоначальным лингвистическим событием, зафиксированным в виде аудиозаписи, и аннотацией этого события. То же самое относится и к текстовым корпусам в том смысле, что первоначальный текст, как правило, имеет внешний источник и считается неизменяемым артефактом. Любые преобразования этого артефакта, которые связаны с человеческим суждением - даже такие простые, как токенизация - подлежат последующим ревизиям, поэтому важно сохранить исходный материал в форме, как можно более близкой к оригиналу.
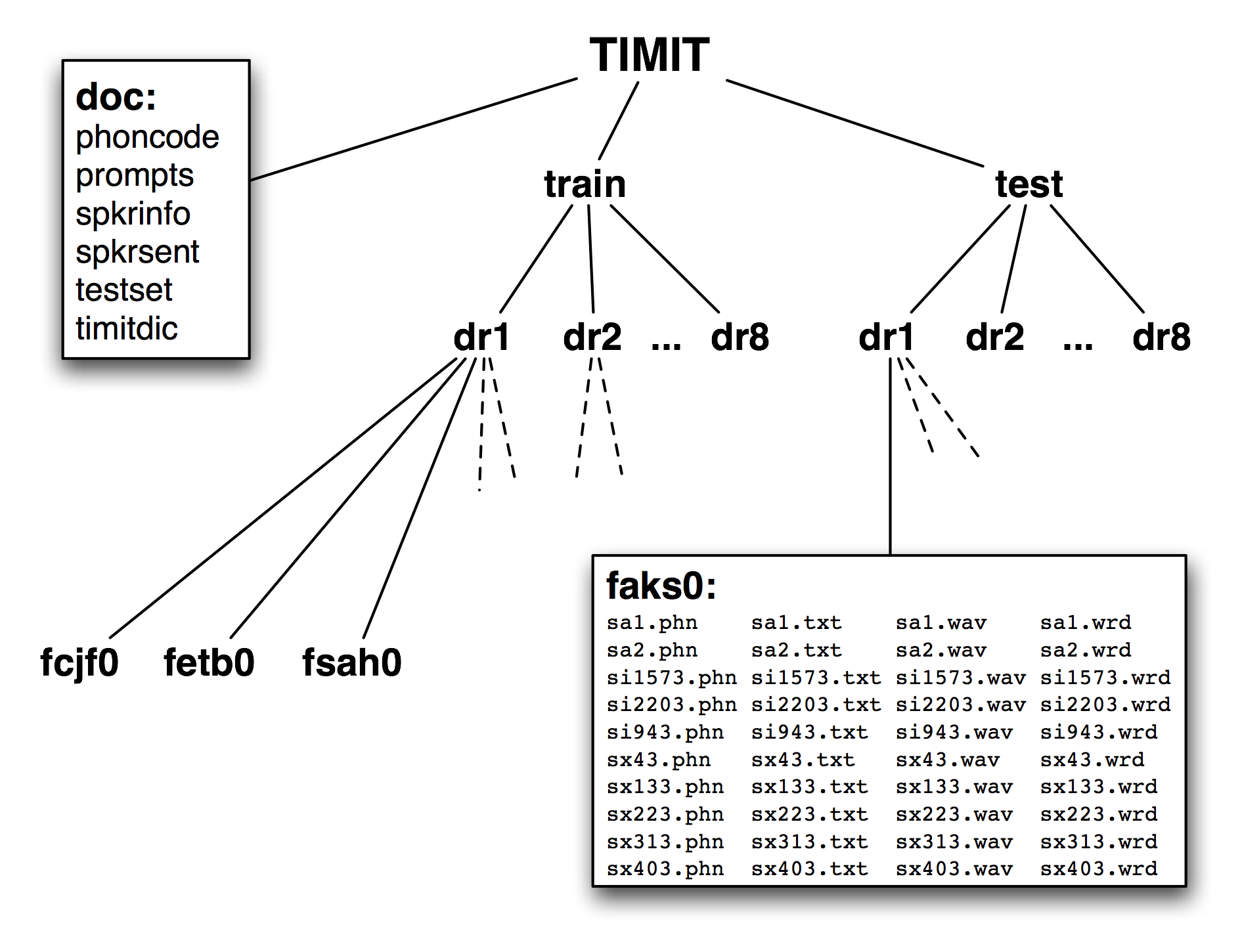
Рисунок 1.2: Структура опубликованного TIMIT корпуса: компакт-диск содержит doc, train и test каталоги на верхнем уровне; test и train каталоги каждый имеет 8 подкаталогов, по одному для диалектного региона; каждый из них содержит дополнительные подкаталоги, по одному на читающего; содержимое каталога для читающего женского пола aks0 представлено на рисунке, в нем находятся 10 wav файлов вместе с текстовой транскрипцией, транскрипцией выровненной по словам и фонетической транскрипцией.
Четвертой особенностью TIMIT является иерархическая структура корпуса. С четырьмя файлами на предложение и 10 предложениями для каждого из 500 говорящих он содержит 20.000 файлов. Они организованы в древовидную структуру, показанную схематично на Рисунке 1.2. На верхнем уровне есть разделение на наборы обучения и тестирования, что мешает его предполагаемому использованию для разработки и оценки статистических моделей.
Наконец, обратите внимание, что, несмотря на то, что TIMIT - это разговорный корпус, его транскрипции и связанные данные являются текстом и могут быть обработаны с использованием программ так же, как и любой другой текстовый корпус. Таким образом, многие из вычислительных методов, описанных в этой книге, применимы. Кроме того, обратите внимание, что все типы данных, включенных в TIMIT корпус, попадают в две основные категории: лексика и текст, которые мы обсудим ниже. Даже демографические данные читающих - это просто еще один экземпляр лексического типа данных.
Это последнее наблюдение становится менее удивительным, если мы примем во внимание, что текст и структуры записей являются основными областями для двух составляющих компьютерной науки управления данными, а именно поиск текста и базы данных. Примечательной особенностью управления лингвистическими данными является то, что оно, как правило, соединяет оба типа данных вместе и может опираться на результаты и приемы из обоих областей.
1.3 Основные типы данных
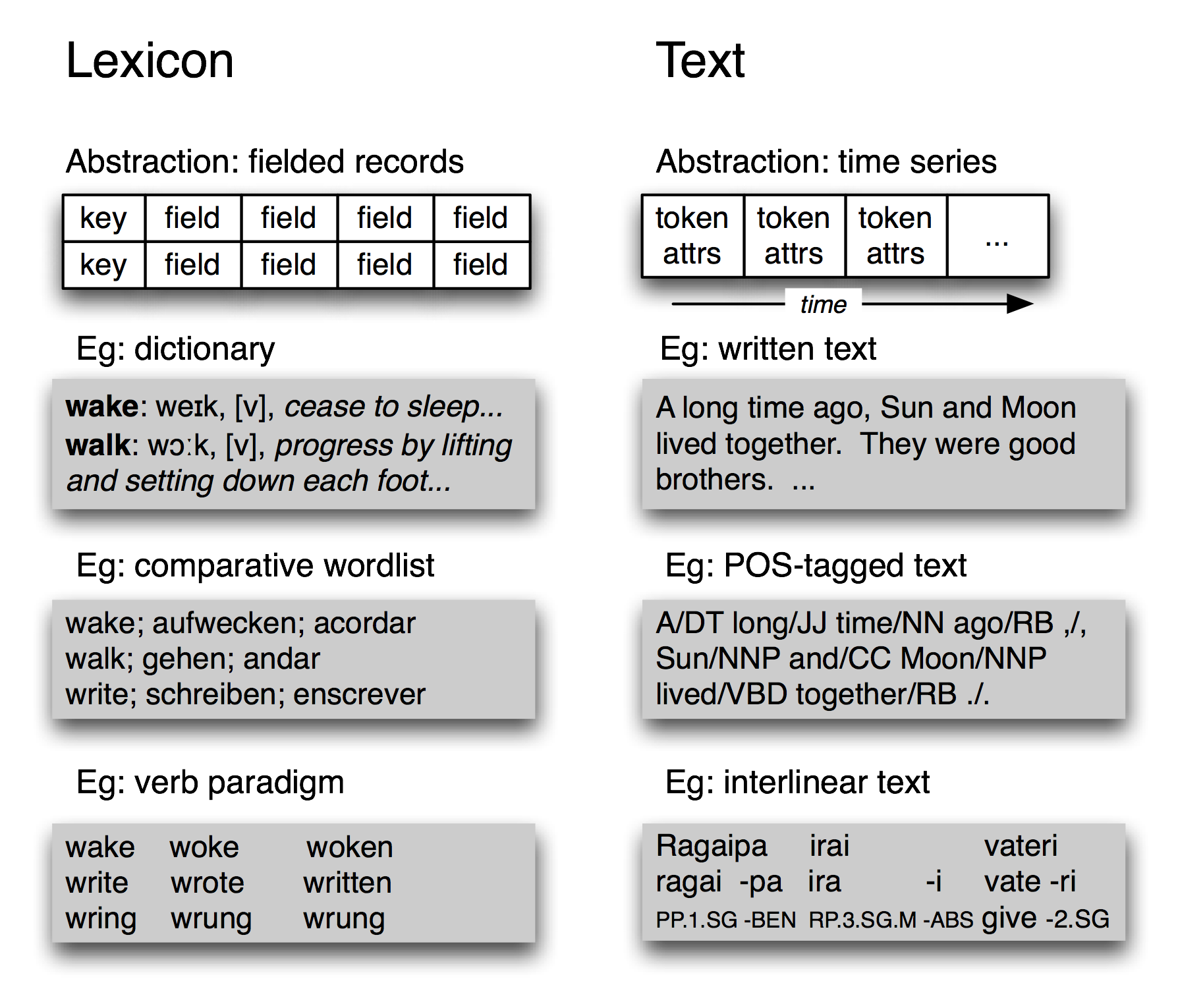
Рисунок 1.3: Основные типы лингвистических данных - лексиконы и тексты: несмотря на все их разнообразие, лексиконы имеют структуру записи, в то время как аннотированные тексты имеют временную организацию.
Несмотря на свою сложность, TIMIT корпус содержит только два основных типа данных, а именно лексиконы и тексты. Как мы видели в 2., большинство лексических ресурсов могут быть представлены с использованием структуры записи, т.е. ключа плюс одно или несколько полей, как показано на 1.3. Лексический ресурс может быть обычным словарем или сравнительным списком слов, как показано. Он также может быть фразовым лексиконом, где ключевым полем является фраза, а не одно слово. Тезаурус также содержит данные, структурированные как записи, в котором мы ищем записи по неключевым полям, которые соответствуют тематике. Мы также можем построить специальные табличные данные (известные как парадигмы), чтобы проиллюстрировать контрасты и систематические вариации, как показано на 1.3 для трех глаголов. Таблица читающих TIMIT корпуса также является своего рода лексиконом.
На самом высоком уровне абстракции текст является представлением реального или вымышленного речевого события и ход времени этого события переносится в сам текст. Текст может быть небольшим отрывком, таким как одно слово или предложение, или полным рассказом или диалогом. Он может быть с аннотациями, такими как метки части речи, морфологический анализ, структура дискурса и так далее. Как мы видели в технике разметки BIO (7.), можно представить компоненты более высокого уровня с помощью меток отдельных слов. Таким образом, абстракция текста показанная на 1.3 является достаточной.
Несмотря на все сложности и идиосинкразии индивидуальных корпусов, в основе своей они представляют собой наборы текстов вместе с данными, имеющими структуру записи. Содержимое корпуса часто смещено в сторону одного или другого типа данных. Например, Корпус Брауна содержит 500 текстовых файлов, но мы все же используем таблицу, чтобы связать эти файлы с 15 различными жанрами. На другом конце спектра, WordNet содержит 117.659 записей синсетов, хотя он включает в себя множество примеров предложений (мини-текстов) для иллюстрации использования слов. TIMIT является интересной средней точкой в этом спектре, содержащем значительный несвязанный материал обоих типов: тексты и лексиконы.
2 Жизненный цикл корпуса
Корпуса не рождаются полностью сформированными, но требуют тщательной подготовки и вклада многих людей в течение длительного периода. Исходные данные должны быть собраны, очищены, документированы, и сохранены в систематическом виде. Различные слои аннотации могут быть применены, некоторые требующие специальных знаний о морфологии и синтаксиса данного языка. Успех на этом этапе зависит от создания эффективного рабочего процесса с использованием подходящих инструментов и преобразователей форматов. Процедуры контроля качества могут быть использованы, чтобы найти несоответствия в аннотациях, а также для обеспечения максимально высокого уровня между согласия между аннотаторами. Из-за масштаба и сложности задачи подготовка больших корпусов может занять годы и потребовать десятки или сотни человеко-лет усилий. В этом разделе мы кратко рассмотрим различные этапы жизненного цикла корпуса.
2.1 Три сценария создания корпуса
В первом типе корпуса его конструкция раскрывается в ходе исследовательской работ создателя. Это образец типичный для традиционной "полевой лингвистики", в которой материал из поисковых сессий анализируется по мере того, как он собирается, а будущие исследования часто основываются на вопросах, которые возникают при анализе сегодняшних. Полученный корпус затем используется в течение последующих нескольких лет исследований и может служить в качестве архивного ресурса неопределенно долгое время. Компьютеризация является очевидным благом для работы такого типа, примером является популярная программа Shoebox, теперь уже более чем двадцатилетней давности, повторно выпущенная под названием Toolbpx (см. 4). Другие программные средства, даже простые текстовые процессоры и электронные таблицы, обычно используются для формирования данных. В следующем разделе мы рассмотрим, как извлекать данные из этих источников.
Другой сценарий создания корпуса является типичным для экспериментальных исследований, в которых материал, имеющий тщательно продуманную структуру, собирается у различных носителей языка, а затем анализируется, чтобы оценить гипотезу или разработать технологию. Для таких баз данных стало обычным совместное и повторное использование внутри лаборатории или компании, а часто и публикация для более ширококого круга пользователей. Корпусы такого типа являются основой метода управления исследованием "общая задача", который за последние два десятилетия стал нормой финансируемых государством исследовательских программ в области языковых технологий. Мы уже встречались со многими такими корпусами в предыдущих главах; мы увидим, как писать программы на Python для реализации различных видов кураторских задач, которые необходимо выполнить до публикации подобных корпусов.
Наконец, есть попытки собрать "эталонный корпус" для конкретного языка, такие как Американский национальный корпус (ANC) и Британский национальный корпус (BNC). Здесь целью было произвести всесторонний учет многих форм, стилей и видов использования языка. Помимо явного вызова, связанного с масштабом, существует сильная зависимость от автоматических инструментов аннотации и постредактирования для исправления каких-либо ошибок. Тем не менее, мы можем писать программы для обнаружения и исправления ошибок, а также для анализа корпуса на сбалансированность.
2.2 Контроль качества
Хорошие инструменты для автоматической и ручной подготовки данных имеют важное значение. Однако создание высококачественного корпуса зависит так же от таких приземленных вещей как документация, обучение и рабочий процесс. Руководства по аннотации определяют задачу и документируют конвенции разметки. Они могут обновляться на регулярной основе для учета сложных случаев, наряду с новыми правилами, которые разрабатываются для достижения более последовательных аннотаций. Аннотаторы должны быть обучены процедурам, в том числе методам разрешения ситуаций, не охваченных руководствами. Последовательность действий должна быть установлена, по возможности, с помощью вспомогательного программного обеспечения, чтобы отслеживать, какие файлы были инициализированы, аннотированы, валидированы, проверены вручную и так далее. В корпусе может быть несколько слоев аннотации, разработанных различными специалистами. Случаи неопределенности или разногласия могут требовать вынесения решения.
Большая аннотационная работа может требовать участия нескольких аннотаторов, что создает проблему обеспечения согласованности. Насколько последовательно группа аннотаторов может выполнять свою работу? Мы легко можем измерить последовательность, имея часть исходного материала, аннотированного двумя людьми независимо друг от друга. Это может выявить недостатки в руководствах или различие способностей аннотаторов. В тех случаях, когда качество имеет первостепенное значение, весь корпус может быть аннотирован дважды, а любые несогласованности разрешаться экспертом.
Считается лучшей практикой сообщать о мере согласия между аннотаторами для корпуса (например, с помощью двойного аннотирования 10% корпуса). Этот показатель дает полезную информацию о верхней границе ожидаемой результативности любой автоматической системы, которая обучается на этом корпусе.
Внимание!
Следует проявлять осторожность при интерпретации оценки согласия между аннотаторами, поскольку задачи аннотации сильно различаются по своей сложности. Например, 90% согласие было бы ужасной оценкой для разметка частей речи, но исключительно высокой оценкой классификации семантических ролей.
Каппа коэффициент K измеряет согласие между двумя людьми, делающими категориальные суждения, скорректированное на ожидаемое случайное согласие. Например, предположим, что элемент должен быть аннотирован и четыре варианта кодирования в одинаковой степени вероятны. Тогда можно было бы ожидать, что два человека, кодирующих случайным образом, будут согласны в 25% случаев. Таким образом, согласию в размере 25% будет назначен K = 0, а лучшие уровни согласия будут уменьшены соответственно. Для согласия в 50%, мы получим K = 0,333, так как 50 - это треть пути от 25 до 100. Существует множество других мер согласия; см. help(nltk.metrics.agreement).

Рисунок 2.1: Три сегментации последовательности: маленькие прямоугольники представляют собой символы, слова, предложения, короче говоря, любую последовательность, которая может быть разделена на языковые единицы; S1 и S2 находятся в близком согласии, но оба существенно отличаются от S3.
Мы также можем измерить согласие между двумя независимыми сегментациями языкового ввода, например, для токенизации, сегментации на предложения, обнаружения именованных объектов. В 2.1 мы видим три возможные сегментации последовательности элементов, которые могли бы быть произведены аннотаторами (или программами). Хотя ни одна из них не совпадает в точности, S1 и S2 находятся в близком согласии, и мы хотели бы иметь подходящую меру их близости. Windowdiff - это простой алгоритм для оценки согласия двух сегментаций путем пробегания скользящего окна над данными и присуждения частичного кредита для близких промахов. Если мы предварительно конвертируем наши маркеры в последовательность нулей и единиц для записей, когда за токеном следует граница, мы можем представить сегментации в виде строк и применить windowdiff счетчик.
|
В приведенном выше примере окно имело размер 3. Вычисление windowdiff скользит с этим окном по парам строк. В каждой позиции она суммирует число границ, найденных в этом окне, для обеих строк, а затем вычисляет разницу. Эти различия затем суммируются. Мы можем увеличить или уменьшить размер окна для управления чувствительностью меры.
2.3 Курирование или эволюция?
Когда большие корпусы доступны широкому кругу исследователей, последние с растущей вероятностью будут основывать свои изыскания на сбалансированных, сфокусированных подмножествах этих корпусов, разработанных первоначально для совершенно других задач. Например, база данных Switchboard первоначально была собрана для исследования идентификации говорящего, но с тех пор использовалась в качестве основы для опубликованных исследований в области распознавания речи, произношения слов, небеглости, синтаксиса, интонации и структуры дискурса. Мотивы для повторного использования лингвистических корпусов включают желание сэкономить время и усилия, желание работать над материалом доступным для репликации другими, а иногда и желание изучать более натуралистические формы языкового поведения, чем было бы возможно в противном случае. Процесс выбора подмножества для такого исследования может считаться нетривиальным вкладом сам по себе.
Помимо выбора соответствующего подмножества корпуса, эта новая работа может включать переформатирование текстового файла (например, преобразование в XML), переименование файлов, повторную токенизацию текста, выбор подмножества данных для обогащения и так далее. Несколько исследовательских групп могли бы сделать эту работу независимо друг от друга, как показано на рисунке 2.2. На более позднем этапе, если кто-то захочет объединить источники информации из различных версий, задача, вероятно, будет крайне обременительной.
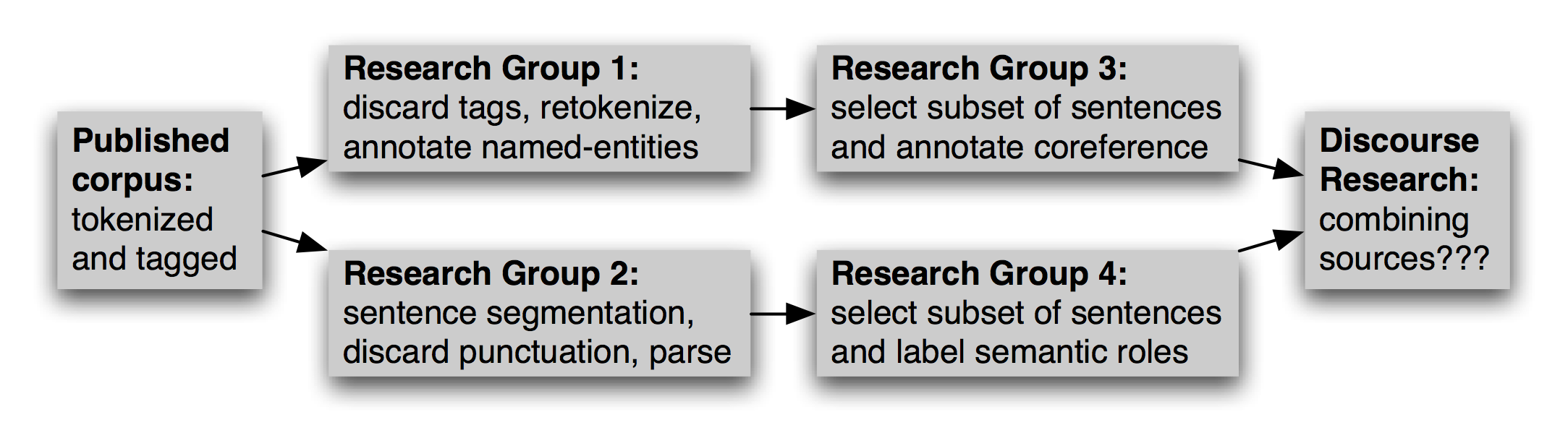
Рисунок 2.2: Эволюция корпус с течением времени: После того, как корпус опубликован, исследовательские группы будут использовать его независимо друг от друга, выбирая и обогащая различные его части; более позднее исследование, которое стремится интегрировать отдельные аннотации стоит перед трудной задачей систематизации аннотаций.
Задача использования производных корпусов становится еще более сложной из-за отсутствия каких-либо записей о том, как была создана производная версия и какая версия имеет последнюю дату.
Альтернатива этой хаотической ситуации для корпуса заключается в том, чтобы он централизованно курировался, а комитеты экспертов пересматривали его и расширяли через определенные промежутки времени, принимая во внимание материалы, полученные от третьих лиц, периодически публикуя новые релизы. Печать словарей и национальных корпусов может централизованно курироваться таким образом. Тем не менее, для большинства корпусов эта модель просто непрактична.
Срединный путь состоит в том, чтобы оригинальная публикация корпуса имела схему для идентификации любого подраздела. Каждое предложение, дерево или лексическая запись может иметь глобальный уникальный идентификатор, а каждый токен, узел или поле (соответственно) может иметь относительное смещение. Аннотации, в том числе сегментации, могут ссылаться на источник с помощью этой схемы идентификации (метод, который известен как Внешняя аннотация). Таким образом, новые аннотации могут распределяться независимо от источника, а несколько независимых аннотаций одного и того же источника, можно сравнивать и обновлять, не касаясь источника.
Если публикация корпуса представлена в нескольких версиях, номер версии или дата может быть частью схемы идентификации. Таблица соответствия идентификаторов между изданиями корпуса позволит легко обновлять любые внешние аннотации.
Внимание!
Иногда обновленный корпус содержит ревизии базового материала, которые были внешне аннотированы. Токены могут быть разделены или объединены, а компоненты могут быть переорганизованы. В таком корпусе может не быть соответствия один-к-одному между старыми и новыми идентификаторами. Лучше разорвать внешние аннотации на таких компонентах новой версии, чем молчаливо позволить их идентификаторам ссылаться на несуществующие места в корпусе.
3 Получение данных
3.1 Получение данных из сети
Сеть является богатым источником данных для целей анализа языка. Мы уже обсуждали методы доступа к отдельным файлам, RSS-каналы и результаты поисковых систем (см. 3.1). Тем не менее, в некоторых случаях мы хотим получить большое количество веб-текста.
Самый простой подход заключается в получении опубликованного корпуса сетевого текста. Особая группа по сети как корпусу в ACL (SIGWAC) поддерживает список ресурсов на http://www.sigwac.org.uk/. Преимуществом использования хорошо определенного сетевого корпуса является то, что он документирован, стабилен и позволяет выполнять воспроизводимые эксперименты.
Если желаемое содержание локализовано на определенном сайте, существует множество утилит для захвата всего доступного содержания сайта, таких как GNU Wgethttp://www.gnu.org/software/wget/. Для получения максимальной гибкости и контроля, может быть использован сетевой сканер, как, например, Heritrix http://crawler.archive.org/. Сканеры позволяют осуществлять скурпулезный контроль над тем, где осуществлять поиск, по каким ссылкам следовать и как организовать результаты (Croft, Metzler, & Strohman, 2009). Например, если мы хотим составить двуязычный сборник текстов, имеющий соответствующие пары документов на каждом языке, сканер должен определить структуру сайта, чтобы извлечь соответствие между документами, и он должен организовать загруженные страницы таким образом, чтобы отразить это соответствие. Может быть заманчивым написать свой собственный сетевой сканер, но есть множество подводных камней, связанных с решением таких поблем, как обнаружение MIME типов, преобразование относительных URL-адресов в абсолютные, избежание пападания в циклические структуры ссылок, работа с сетевыми задержками, избежание перегрузки сайта или запрета на доступ к сайту и так далее.
3.2 Получение данных из файлов текстовых редакторов
Текстовые редакторы часто используются для ручной подготовки текстов и лексиконов в проектах, которые имеют ограниченную вычислительную инфраструктуру. Такие проекты часто предоставляют шаблоны для ввода данных, хотя текстовые процессоры не гарантируют, что данные правильно структурированы. Например, каждый текст может иметь название и дату. Аналогично каждая лексическая запись может иметь определенные обязательные поля. По мере роста размера и сложности данных все большая часть времени может тратиться на поддержание такой системы.
Как мы можем извлечь содержимое таких файлов, чтобы мы могли работать с ним во внешних программах? Более того, как мы можем проверить содержимое этих файлов, чтобы помочь авторам создавать хорошо структурированные данные, чтобы качество данных могло быть максимизированно в контексте оригинального авторского процесса?
Возьмем словарь, в котором каждая запись имеет поле части речи, выбранной из 20 возможных вариантов, следующее за полем произношения и отображаемое одиннадцатым жирным шрифтом. Ни один обычный текстовый процессор не имеет функции поиска или макроса способных проверить, что все поля части речи введены и отображаются правильно. Эта задача требует утомительной ручной проверки. Если текстовый процессор позволяет сохранить документ в непатентованном формате, например, в виде простого текста, HTML или XML, мы можем иногда написать программы, чтобы сделать эту проверку автоматически.
Рассмотрим следующий фрагмент лексической записи: "sleep [sli: р] v.i. condition of body and mind...". Мы можем ввести это в MSWord, а затем "Сохранить как веб-страницу", затем проверить полученный HTML-файл:
<p class=MsoNormal>sleep <span style='mso-spacerun:yes'> </span> [<span class=SpellE>sli:p</span>] <span style='mso-spacerun:yes'> </span> <b><span style='font-size:11.0pt'>v.i.</span></b> <span style='mso-spacerun:yes'> </span> <i>a condition of body and mind ...<o:p></o:p></i> </p>
Заметим, что запись представлена в виде HTML абзаца с использованием элемента <p>, а часть речи появляется внутри элемента <span style='font-size:11.0pt'>. Следующая программа определяет набор допустимых частей речи legal_pos. Затем она извлекает все содержимое одиннадцатого шрифта из файла dict.htm и сохраняет его в набор used_pos. Заметим, что шаблон поиска содержит подвыражения, заключенное в скобки; только материал, который соответствует этому подвыражения, возвращается функцией re.findall. И, наконец, программа строит множество недопустимых частей речи как used_pos - legal_pos:
|
Эта простая программа представляет собой верхушку айсберга. Мы можем разработать сложные инструменты для проверки и сообщения об ошибках согласованности файлов текстовых процессоров, чтобы люди, поддерживающие словарь могли исправить исходный файл, используя исходный текстовый процессор.
После того, как мы знаем, что данные правильно отформатированы, мы можем написать другие программы для преобразования данных в другой формат. Программа в 3.1 разбирает HTML разметку с использованием nltk.clean_html(), извлекает слова и их произношения и генерирует вывод в формате "значение отделенное запятой" (CSV).
| ||
| ||
Пример 3.1 (code_html2csv.py): Листинг 3.1: Преобразование HTML созданного с помощью Microsoft Word в CSV. |
- with gzip.open(fn+".gz","wb") as f_out:
- f_out.write(bytes(s, 'UTF-8'))
Замечание
Для более сложной обработки HTML, используйте пакет Beautiful Soup доступный для скачивания со страницы http://www.crummy.com/software/BeautifulSoup/
3.3 Получение данных из электронных таблиц и баз данных
Электронные таблицы часто используются для создания списков слов или парадигм. Например, сравнительный словник может быть создан с помощью электронных таблиц со строкой для каждого родственного набора и столбцом для каждого языка (cf. nltk.corpus.swadesh и www.rosettaproject.org). Большинство программ для создания электронных таблиц может экспортировать свои данные в формате CSV. Как мы увидим ниже, программы на Python легко могут получить доступ к этим данным с помощью модуля CSV.
Иногда лексиконы хранятся в полноценной реляционной базе данных. При правильной нормализации эти базы данных могут обеспечить валидацию данных. Например, мы можем потребовать, чтобы все части речи брались из определенного словаря, объявив, что поле часть речи является перечислением или внешним ключом, который ссылается на отдельную таблицу частей речи. Тем не менее, реляционная модель требует, чтобы структура данных (схема) была объявлена заранее, а это идет вразрез с доминирующим подходом к структурированию лингвистических данных, который имеет весьма разведовательный характер. Поля, которые предполагались обязательными и уникальными, часто оказываются необязательными и допускающими повторения. Реляционная база данных может учесть это, когда структура данных полностью известна заранее, однако, если это не так, или если почти каждое свойство оказывается необязательным или допускающим повторение, реляционный подход неработоспособен.
Тем не менее, когда наша цель состоит в том, чтобы просто извлечь содержимое из базы данных, достаточно просто сохранить данные из таблицы (или результаты SQL запросов) в формате CSV и загрузить их в нашу программу. Наша программа может выполнить лингвистически мотивированный запрос, который не может быть выражен в SQL, например, выбрать все слова, которые появляются в примерах предложений, для которых нет словарной статьи. Для решения этой задачи мы должны были бы извлечь достаточно информации из записи для того, чтобы быть определить ее однозначно, наряду с заголовком и примерами предложений. Давайте предположим, что эта информация теперь доступна в CSV файле dict.csv:
"sleep","sli:p","v.i","a condition of body and mind ..." "walk","wo:k","v.intr","progress by lifting and setting down each foot ..." "wake","weik","intrans","cease to sleep"
Теперь мы можем выразить этот запрос, как показано ниже:
|
Эта информация будет затем направлять текущую работу по обогащению лексикона, работу, которая обновляет содержимое реляционной базы данных.
3.4 Преобразование форматов данных
Аннотированные лингвистические данные редко поступают в наиболее удобном формате, часто приходится выполнять различные виды преобразования формата. Преобразование между кодировками уже обсуждалось (см. 3.3). Здесь мы обратим внимание на структуру данных.
В простейшем случае, входные и выходные форматы изоморфны. Например, мы могли бы преобразовывать лексические данные из формата XML в Toolbox, очень просто транслитерировать записи по одной (4). Структура данных находит свое отражение в структуре необходимой программы: в for цикле, содержание которого обрабатывает одну запись.
В другом частом случае выход является переработанной формой входа, такой как инвертированный индекс файла. Здесь необходимо построить структуру индекса в памяти (см. 4.8), а затем записать его в файл в нужном формате.
В следующем примере создается индекс, который ставит в соответствие словам из определения словаря соответствующую лексему ![[1]](http://www.nltk.org/book/callouts/callout1.gif) для каждой лексической записи
для каждой лексической записи ![[2]](http://www.nltk.org/book/callouts/callout2.gif) , предварительно токенизировав текст определения
, предварительно токенизировав текст определения ![[3]](http://www.nltk.org/book/callouts/callout3.gif) и отбросив короткие слова
и отбросив короткие слова ![[4]](http://www.nltk.org/book/callouts/callout4.gif) . После того, как индекс был построен, мы открываем файл, а затем перебираем записи индекса, чтобы записать строки в требуемом формате
. После того, как индекс был построен, мы открываем файл, а затем перебираем записи индекса, чтобы записать строки в требуемом формате 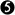 .
.
|
Полученный файл dict.idx содержит следующие строки. (Для большего словаря можно было бы ожидать, что мы увидем несколько лексем для каждой записи индекса.)
body: sleep cease: wake condition: sleep down: walk each: walk foot: walk lifting: walk mind: sleep progress: walk setting: walk sleep: wake
В некоторых случаях, входные и выходные данные и состоят из двух или большего числа измерений. Например, вход может представлять собой набор файлов, каждый из которых содержит один столбец данных о частоте слова. Требуемый выход может быть двухмерной таблице, в которой исходные столбцы отображаются в виде строк. В таких случаях мы наполняем внутреннюю структуру данных, заполняя одну колонку за один раз, а затем считываем данные построчно и записываем данные в выходной файл.
В самых неприятных случаях исходный и целевой форматы имеют несколько иной охват области и информация неизбежно теряется при переводе между ними. Например, мы могли бы объединить несколько файлов Toolbox, чтобы создать единый файл CSV, содержащий сравнительный список слов, теряя все, кроме \ lx поле входных файлов. Если файл CSV позже был изменен, будет очень трудно ввести изменения в исходные файлы Toolbox. Частичное решение этой проблемы "кругооборота" заключается в том, чтобы связать явные идентификаторы каждого языкового объекта и распространять эти идентификаторы с объектами.
3.5 Принятие решения о том, какие слои аннотации включить
Опубликованные корпусы сильно различаются по богатству информации, которую они содержат. На минимуме корпус, как правило, содержит последовательность звуков или орфографических символов. На другом конце спектра корпусе может содержать большое количество информации о синтаксической структуре, морфологии, просодии и смысловом содержании каждого предложения, а также аннотацию дискурсивных отношений или актов диалога. Эти дополнительные слои аннотации может быть как раз тем, что кому-то нужно для выполнения конкретной задачи анализа данных. Например, может быть намного легче найти данный лингвистический паттерн, если мы можем осуществить поиск конкретной синтаксической структуры; и может быть проще классифицировать лингвистический паттерн, если смысл каждого слова был отмечен. Вот некоторые обычно предоставляемые слои аннотации:
- Токенизация слов: орфографическая форма текста неоднозначно идентифицирует свои токены. Токенизированная и нормализованная версия в дополнение к обычной орфографической версии могут быть очень удобным ресурсом.
- Сегментация на предложения: как мы видели в 3, сегментация на предложения может быть более сложной, чем это кажется. Поэтому некоторые корпусы использовать явные аннотации, чтобы пометить сегментирование на предложения.
- Сегментация на параграфы: параграфы и другие структурные элементы (заголовки, главы и т.д.) могут быть явно помечены.
- Часть речи: синтаксическая категория каждого слова в документе.
- Синтаксическая структура: древовидная структура, показывающая конституентную структуру предложения.
- Поверхностная семантика: аннотации именованных объектов и их соотнесенности, метки семантических ролей.
- Диалог и дискурс: метки акта диалога, риторическая структура
К сожалению, существует не так много согласованности между существующими корпусами в том, как они представляют аннотации. Тем не менее, два общих класса представления аннотаций следует различать. Внутренняя аннотация изменяет исходный документ путем вставки специальных символов или управляющих последовательностей, которые несут аннотированную информацию. Например, когда при разметке частей речи документа строка "fly" может быть заменена на "fly/NN", чтобы указать, что слово fly существительное в этом контексте. В противоположность этому внешняя аннотация не изменяет исходный документ, но вместо этого создает новый файл, который добавляет аннотационную информацию с помощью указателей, которые ссылаются на исходный документ. Например, этот новый документ может содержать строку "<token id=8 pos='NN'/>", чтобы указать, что токен 8 является существительным. (Мы хотели бы быть уверенными, что сама токенизация не подлежит изменению, в противном случае это вызвало бы безмолвную поломку таких ссылок.)
3.6 Стандарты и инструменты
Чтобы корпус был полезен широкому кругу, он должен быть доступен в широко поддерживаемом формате. Тем не менее, передний край исследований NLP зависит от новых видов аннотаций, которые по определению не имеет широкой поддержки. В целом адекватные инструменты для создания, публикации и использования лингвистических данных не являются широко доступными. Большинство проектов должны разрабатывать свой собственный набор инструментов для внутреннего использования, который не поможет другим, которые испытывают недостаток необходимых ресурсов. Кроме того, мы не имеем адекватных, общепринятых стандартов для выражения структуры и содержания корпусов. Без таких стандартов инструменты общего назначения невозможны - хотя в то же время без доступных инструментов, адекватные стандарты вряд ли будут разработаны, приняты и использованы.
Один из возможных ответов на эту ситуацию заключается в том, чтобы продвигаться вперед в разработке общего формата, который достаточно выразителен, чтобы схватить большое разнообразие типов аннотаций (см. примеры в 8). Задача NLP заключается в написании программ, которые могут справиться с общностью таких форматов. Например, если задача программирования включает в себя древовидные данные, а формат файла разрешает произвольно ориентированные графы, то входные данные должны быть проверены на такие свойства дерева, как наличие корня, связанность и ацикличность. Если входные файлы содержат другие слои аннотации, программа должна знать, как игнорировать их, когда данные загружаются из файла, и как не испортить или не уничтожить эти слои, когда данные дерева сохраняются обратно в файл.
Другим ответом было написание одноразовых скриптов для манипулирования форматами корпусов; такие скрипты замусорили файловое пространство многих исследователей NLP. Ридеры корпусов NLTK являются более систематическим подходом, основанным на предположении, что работа по разбору формата корпуса должна выполнять только один раз (для языка программирования).
Рисунок 3.2: Общий формат против общего интерфейса
Вместо того, чтобы ставить акцент на общем формате, мы считаем более перспективным развивать общий интерфейс (см. nltk.corpus). Рассмотрим случай treebanks корпуса, который является важным типом корпуса для работы в NLP. Есть много способов хранить дерево фразовой структуры в файле. Мы можем использовать вложенные скобки, или вложенные элементы XML, или обозначение зависимости с помощью пары (идентификатор ребенка, идентификатор родителя) в каждой строке, или XML-версии обозначения зависимости и т.д. Однако в каждом конкретном случае логическая структура почти одна и та же. Намного проще разработать общий интерфейс, который позволяет разработчикам приложений писать код для доступа к данным дерева с использованием таких методов, как children(), leaves(), depth() и так далее. Обратите внимание, что этот подход следует общепринятой практике в рамках информатики, а именно абстрактные типы данных, объектно-ориентированное проектирование и трехслойная архитектура (3.2). Последний из них - из мира реляционных баз данных - позволяет приложениям для конечных пользователей использовать общую модель ("реляционную модель") и общий язык (SQL), чтобы абстрагироваться от идиосинкразии файлового хранилища, а также позволяет осуществлять изменения в файловой системе не тревожа приложений для конечных пользователей. Таким же образом общий интерфейс корпуса отделяет прикладные программы от форматов данных.
В этом контексте при создании нового корпуса, предназначенного для распространения среди широкого круга пользователей, целесообразно использовать существующий широко используемый формат везде, где это возможно. Если это невозможно, корпус может сопровождаться программным обеспечением - таким как модуль nltk.corpus - который поддерживает существующие методы интерфейса.
3.7 Особые соображения при работе с вымирающими языками
Важность языка для науки и искусства равна по своему значению культурным сокровищам, воплощенным в языке. Каждый из примерно 7.000 человеческих языков богат в различных отношениях, своей устной историей и легендами создания, грамматическими конструкциями и самими словами, нюансами их значений. Находящиеся под угрозой исчезновения реликтовые культуры имеют слова, чтобы отличить подвиды растений согласно терапевтическому применению, которое неизвестно науке. Языки развиваются с течением времени, по мере того, как они вступают в контакт друг с другом, и каждый из них дает уникальное видение предыстории человека. Во многих частях мира небольшие языковые вариации от одного города к другому складываются в совершенно другой язык в получасе езды на машине. За его захватывающую сложность и многообразие человеческий язык можно назвать красочным гобеленом, простирающимся во времени и пространстве.
Тем не менее, большинство языков мира находятся на грани вымирания. В ответ на этот вызов многие лингвисты усердно работают над документированием языков, созданием полных записей этого важного аспекта языкового наследия мира. Что может NLP предложить, чтобы помочь этим усилиям? Разработка разметчиков, анализаторов, распознавателей именованных объектов и т.д. не является первоочередной задачей, в любом случае, как правило, для разработки таких инструментов пока недостаточно данных. Вместо этого наиболее часто озвучивается потребность иметь лучшие инструменты для сбора и курирования данных с акцентом на текстах и словарях.
Внешне кажется простым делом начать собирать тексты на исчезающем языке. Но, даже если мы будем игнорировать спорные вопросы, такие как, кто владеет текстами и восприятиями, окружающими культурные знания, содержащиеся в текстах, есть очевидный практический вопрос транскрипции. Большинство языков не имеют стандартной орфографии. Если язык не имеет литературной традиции, соглашения об орфографии и пунктуации не являются хорошо установившимися. Поэтому обычной практикой является создание лексикона вместе со сборником текстов, постоянно обновляя лексикон по мере возникновения новых слов в текстах. Эта работа может быть сделано с помощью текстового процессора (для текстов) и электронных таблиц (для лексикона). А еще лучше с помощью свободного лингвистического программного обеспечения SIL Toolbox и Fieldworks, которое обеспечивают всестороннюю поддержку интегрированного создания текстов и словарей.
Когда носители данного языка научены вводить тексты самостоятельно, обще распространенной трудностью является забота о правильном написании. Использование лексикона очень помогает этому процессу, но мы должны иметь методов поиска, которые не предполагают, что кто-то может определить нормальную форму произвольного слова. Проблема может быть острой для языков, имеющих сложную морфологию, которая включает префиксы. В таких случаях помогают семантические пометки лексических единиц и возможность поиска по семантической области или глоссарию.
Возможность поиска по произносительному подобию также оказывает большую помощь. Вот простая демонстрация того, как сделать это. Первый шаг заключается в определении смешиваемых последовательностей букв и сопоставлении сложных версий и более простых версий. Мы могли бы также заметить, что относительный порядок букв внутри кластера согласных является источником орфографических ошибок, поэтому мы нормализуем порядок согласных звуков.
|
Далее мы создаем отображение множества ключей на множестве слов для всех слов в нашем лексиконе. Мы можем использовать это, чтобы получить корректировки кандидатов для данного входного слова (но мы должны сначала вычислить ключ этого слова).
|
И, наконец, мы должны ранжировать результаты по сходству с оригинальным словом. Это делается с помощью функции rank(). Единственная оставшаяся функция предоставляет простой интерфейс для пользователя:
|
Это только один пример того, когда простая программа может облегчить доступ к лексическим данным в условиях, когда письменная система языка не может быть стандартизирована или когда пользователи языка могут не иметь хорошего уровня владения орфографией. Другие простые приложения НЛП в этой области включают: построение индексов для облегчения доступа к данным, формирование списков слов из текстов, поиск примеров использования слова при построении лексикона, обнаружение распространенных или исключительных паттернов в плохо понятых данных, а также выполнение специализированной проверки данных, созданных с использованием различных лингвистических программных средств. Мы вернемся к последним в 5.
4 Работа с XML
Расширяемый язык разметки (Extensible Markup Language (XML)) обеспечивает основу для разработки предметно-ориентированных языков разметки. Иногда он используется для представления аннотированного текста и лексических ресурсов. В отличие от HTML с его предопределенными метками XML позволяет нам создать наши собственные метки. В отличие от базы данных XML позволяет создавать данные без предварительного определения их структуры, а это позволяет нам иметь необязательные и повторяющиеся элементы. В этом разделе мы кратко рассмотрим некоторые особенности XML, которые имеют отношение к представлению лингвистических данных, и покажем, как обращаться к данным, хранящимся в файлах XML с использованием программ на Python.
4.1 Использование XML для языковых структур
Благодаря своей гибкости и расширяемости XML является естественным выбором для представления лингвистических структур. Вот пример простой лексической записи.
| (2) |
<entry>
<headword>whale</headword>
<pos>noun</pos>
<gloss>any of the larger cetacean mammals having a streamlined
body and breathing through a blowhole on the head</gloss>
</entry>
|
Она состоит из серии XML тегов в угловых скобках. Каждый открывающий тег, как <gloss> сочетается с закрывающим тегом, например </gloss>; вместе они представляют собой XML-элемент. Приведенный выше пример был отформатирован красиво с помощью пробелов, но он так же мог быть расположен на одной длинной строке. Наш подход к обработке XML, как правило, не чувствителен к пробелам. Для того, чтобы XML был хорошо сформирован, все открывающие теги должны иметь соответствующие закрывающие теги на том же уровне вложенности (то есть документ XML должен быть правильно сформированным деревом).
XML позволяет повторять элементы, например, добавить еще одно поле глоссария, как мы увидим ниже. Мы будем использовать различные пропуски, чтобы подчеркнуть, что макет не имеет значения.
| (3) | <entry><headword>whale</headword><pos>noun</pos><gloss>any of the larger cetacean mammals having a streamlined body and breathing through a blowhole on the head</gloss><gloss>a very large person; impressive in size or qualities</gloss></entry> |
Следующим шагом может заключаться в том, чтобы связать наш лексикон с каким-то внешним ресурсом, таким как WordNet, с помощью внешних идентификаторов. В (4) мы группируем глоссу и идентификатор синсета внутри нового элемента, который мы назвали "sense".
| (4) |
<entry>
<headword>whale</headword>
<pos>noun</pos>
<sense>
<gloss>any of the larger cetacean mammals having a streamlined
body and breathing through a blowhole on the head</gloss>
<synset>whale.n.02</synset>
</sense>
<sense>
<gloss>a very large person; impressive in size or qualities</gloss>
<synset>giant.n.04</synset>
</sense>
</entry>
|
В качестве альтернативы мы могли бы представить идентификатор синсета с помощью XML атрибута без необходимости в каких-либо вложенных структурах, как в (5).
| (5) |
<entry>
<headword>whale</headword>
<pos>noun</pos>
<gloss synset="whale.n.02">any of the larger cetacean mammals having
a streamlined body and breathing through a blowhole on the head</gloss>
<gloss synset="giant.n.04">a very large person; impressive in size or
qualities</gloss>
</entry>
|
Это иллюстрирует некоторые аспекты гибкости XML. Если примеры кажутся несколько произвольными, то это потому что так оно и есть! Следуя правилам XML мы можем изобретать новые имена атрибутов и вкладывать их так глубоко, как нам хочется. Мы можем повторять элементы, забывать их, размещать их каждый раз в другом порядке. Мы можем иметь поля, наличие которых зависит от значения какого-либо другого поля, например , если часть речи "verb", тогда запись может иметь элемент past_tense для хранения прошедшего времени глагола, но если часть речи "noun", то past_tense элемент не допускается. Чтобы навести какой-то порядок во всей этой свободе, мы можем ограничить структуру файла XML с помощью "схемы", которая является заявлением сродни контекстно-свободной грамматике. Существуют инструменты для тестирования валидности XML файла в соответствии со схемой.
4.2 Роль XML
Мы можем использовать XML для представления многих видов лингвистической информации. Тем не менее, эта гибкость дается определенной ценой. Каждый раз, когда мы вводим усложнение, например, разрешая элементу быть необязательным или повторяться, мы создаем дополнительную работу для любой программы, которая обращается к этим данным. Мы также делаем более трудной проверку действительности данных или запрос данных с использованием одного из языков XML-запросов.
Таким образом, использование XML для представления лингвистических структур не может магическим образом решить проблему моделирования данных. Нам все равно необходимо решить, как структурировать данные, затем определить эту структуру с помощью схемы, а затем писать программы для чтения и записи в данном формате и конвертации его в другие форматы. Кроме того, мы все равно должны следовать некоторым стандартным принципам, касающимся нормализации данных. Целесообразно избегать дублирования одной и той же информации, чтобы в конечном итоге не столкнуться с несовместимостью данных, когда будет изменена только одна копия. Например, перекрестная ссылка, которая был представлена в виде <xref> headword</xref> будет дублировать хранилище headword какой-либо другой лексической записи, и эта ссылка перестанет работать, если копия строки в другом месте будет изменена. Экзистенциальные зависимости между типами информации должны быть смоделированы, чтобы мы не могли создать элементы без дома. Например, если определения смысла не могут существовать независимо от лексической записи, то элемент смысл может быть вложен только внутрь элемента запись. Отношения многие-ко-многим должны быть выведены из иерархических структур. Например, если слово может иметь множество соответствующих смыслов, а смысл может иметь несколько соответствующих слов, тогда и слова, и смыслы должны быть перечислены по отдельности, так же как и список пар (слово, смысл). Эта сложная структура может даже быть разбита на три отдельных файла XML.
Как мы можем видеть, хотя XML предоставляет нам удобный формат, сопровождаемый обширной коллекцией инструментов, он не является панацеей.
4.3 Интерфейс ElementTree
Python модуль ElementTree обеспечивает удобный способ доступа к данным, хранящимся в файлах XML. ElementTree является частью стандартной библиотеки языка Python (с Python 2.5), а также предоставляется в рамках NLTK в случае, если вы используете Python 2.4.
Проиллюстрируем использование ElementTree с помощью коллекции пьес Шекспира, которые были отформатированы с помощью XML. Давайте загрузим файл XML и исследуем его содержимое, сперва начало файла , где мы видим некоторые XML заголовки и имя схемы под названием play.dtd, за которым следует корневой элемент PLAY. Мы подбираем его снова в начале 1-го акта .
(Некоторые пустые строки были опущены в выводе.)
|
Мы только что обратились к данным XML как строке. Как мы видим, строка в начале первого акта содержит XML-теги для заголовка, сцены, ремарок и так далее.
Следующим шагом будет обработать содержимое файла как структурированные данные XML с помощью ElementTree. Мы обрабатываем файл (многострочный текст) и строим дерево, поэтому не удивительно, что метод называется parse .
Переменная merchant содержит XML-элемент PLAY .
Этот элемент имеет внутреннюю структуру; мы можем использовать индекс, чтобы получить его первого ребенка, элементTITLE .
Мы также можем увидеть текстовое содержимое этого элемента, название пьесы .
Для того, чтобы получить список всех дочерних элементов, мы используем метод getchildren() .
|
Пьеса состоит из названия, персон, описания сцены, подзаголовка и пяти актов. Каждый акт имеет название и несколько сцен, а каждая сцена состоит из речей, которые составлены из строк - структура с четырьмя уровнями вложенности. Давайте покопаемсе в четвертом акте:
|
Замечание
Ваша очередь: Повторите некоторые из описанных выше методов для одной из других пьес Шекспира, включенных в корпус, таких как Ромео и Джульетта или Макбет; см. список в nltk.corpus.shakespeare.fileids().
Хотя мы можем получить доступ ко всему дереву таким образом, более удобно искать подэлементы по их именам. Напомним, что на верхнем уровне элементы имеют несколько типов. Мы можем перебрать только интересующие нас типы (например, акты) с помощью метода merchant.findall('ACT'). Вот пример выполнения поиска по конкретной метке на каждом уровне вложенности:
|
Вместо перемещения на каждом шаге вниз по иерархии мы можем искать конкретные встроенные элементы. Например, давайте рассмотрим последовательность говорящих. Мы можем использовать распределение частот, чтобы увидеть, кто больше всех говорит:
|
Мы можем также искать закономерности в том, кто следует за кем в диалогах. Так как в пьесе присутствует 23 говорящих, мы должны сначала уменьшить "словарь" до приемлемого размера с помощью метода, описанного в 3.
|
Игнорируя записи обмена репликами между всеми, кроме 5 первых (помеченных OTH), наибольшее значение предполагает, что Порция и Бассанио имеют наиболее частые взаимодействия.
4.4 Использование ElementTree для доступа к данным Toolbox
В 4 мы увидели простой интерфейс для доступа к данным Toolbox, популярному и весьма устоявшемуся формату, используемому лингвистами для управления данными. В этом разделе мы рассмотрим различные методы управления данными Toolbox способами, которые не поддерживаются программным обеспечением Toolbox. Методы, которые мы обсудим, могли быть применены к другим данным, имеющим структуру записей, независимо от фактического формата файла.
Мы можем использовать метод toolbox.xml(), чтобы получить доступ к файлу Toolbox и загрузить его в объект ElementTree. Этот файл содержит словарь для языка Ротокас Папуа Новой Гвинеи.
|
Есть два способа получить доступ к содержимому объекта лексикона, по индексам и по путям. Индексы используют знакомый синтаксис, так lexicon[3] возвращает запись номер 3 (которая, на самом деле, четвертая запись, считая с нуля); lexicon[3][0] возвращает первое поле:
|
Второй способ получить доступ к содержимому объекта лексикона использует пути. Лексикон представляет собой серию объектов record, каждый из которых содержит ряд объектов полей, таких как lx и ps. Мы можем легко обратиться ко всем лексемам, используя путь record/lx. Здесь мы используем функцию findall() для поиска каких-либо совпадений для пути record/lx и получаем доступ к текстовому содержимому элемента, приводя его к нижнему регистру.
|
Давайте просматрим данные Toolbox в формате XML. Метод write() из ElementTree ожидает файловый объект. Мы обычно создаем один из них с помощью встроенной функции Python open(). Для того, чтобы увидеть результат на экране, мы можем использовать специальный предустановленный файловый объект, называемый stdout (стандартный вывод), определенный в sys модуле Python.
|
4.5 Форматирование записей
Мы можем использовать ту же идею, которую мы видели выше, чтобы генерировать HTML-таблицы вместо обычного текста. Это было бы полезно для публикации Toolbox лексикона в сети. Данный код производит HTML-элементы <table>, <tr> (строки таблицы) и <td> (данные таблицы).
|
5 Работа с данными Toolbox
Учитывая популярность Toolbox среди лингвистов, мы обсудим некоторые дополнительные методы работы с данными Toolbox. Многие из методов, рассмотренных в предыдущих главах, например, подсчет, построение распределения частот, построение таблицы совместных вхождений, могут быть применены к содержанию записей Toolbox. Например, мы можем тривиально вычислить среднее число полей для каждой записи:
|
В этом разделе мы рассмотрим две задачи, которые возникают в контексте документальной лингвистики, ни одна из которых не поддерживается программным обеспечением Toolbox.
5.1 Добавление поля для каждой записи
Часто бывает удобно добавлять новые поля, которые получены автоматически из существующих. Такие поля часто облегчают поиск и анализ. Например, в 5.1 мы определяем функцию cv(), которая ставит в соответствие строке гласных и согласных соответствующую CV последовательность, например строке kakapua соответствовала бы последовательность CVCVCVV. Это отображение имеет четыре шага. Во-первых, строка преобразуется в нижний регистр, затем мы заменяем все не-буквенные символы [^a-z] на подчеркивание. Далее, мы заменим все гласные на V. И, наконец, любой символ, который не является V или подчеркиванием должен быть согласным, поэтому мы заменяем его на C. Теперь мы можем сканировать лексикон и добавить новое поле cv после каждого lx поля. Листинг 5.1 показывает, что это делает с конкретной записью; обратите внимание на последнюю строку вывода, которая показывает новое поле cv.
| ||
| ||
Пример 5.1 (code_add_cv_field.py): Листинг 5.1: Добавление нового поля cv к лексической записи |
Замечание
Если файл Toolbox постоянно обновляется, программа в листинге code_add_cv_field должна быть запущена более чем один раз. Можно было бы модифицировать add_cv_field(), чтобы изменять содержимое существующей записи. Тем не менее, более безопасной практикой является использование таких программ для создания обогащенных файлов с целью анализа данных без замены курируемых вручную исходных файлов.
5.2 Проверка лексикона Toolbox
Многие лексиконы в формате Toolbox не соответствуют какой-либо конкретной схеме. Некоторые записи могут включать в себя дополнительные поля или могут упорядочивать существующие поля по-новому. Ручная проверка тысяч лексических записей не применима. Тем не менее, мы можем легко определить часто встречающиеся последовательности полей с помощью Counter:
|
После проверки этих последовательностей полей мы могли бы разработать контекстно свободную грамматику для лексических записей. Грамматика в 5.2 использует формат CFG, который мы видели в 8.. Такая грамматика моделирует неявно вложенную структуру записей Toolbox и строит древовидную структуру, в которой индивидуальные имена полей являются листьями дерева. Наконец, мы перебираем записи и сообщаем об их соответствие грамматике, как показано в листинге 5.2.
К тем полям, которые допускаются грамматикой, добавляется префикс '+' , а к тем, которые отвергаются добавляется '-' .
В процессе разработки такой грамматики удобно отфильтровать некоторые теги .
| ||
Пример 5.2 (code_toolbox_validation.py): Листинг 5.2: Проверка Toolbox записей с использованием контекстно-свободной грамматики |
Другой подход заключается в использовании анализатора группировки (7.), так как он являются гораздо более эффективным при определении частичных структур и может сообщать о частичных структурах, которые были обнаружены. В 5.3 мы создали грамматику группировки для записей лексикона, а затем разобрали каждую запись. Образец вывода этой программы показан в листинге 5.4.
| ||
| ||
Пример 5.3 (code_chunk_toolbox.py): Листинг 5.3: Группировка лексикона Toolbox: грамматика группировки, описывающая структуру записей лексикона для Iu Mien, одного из языка Китая. |
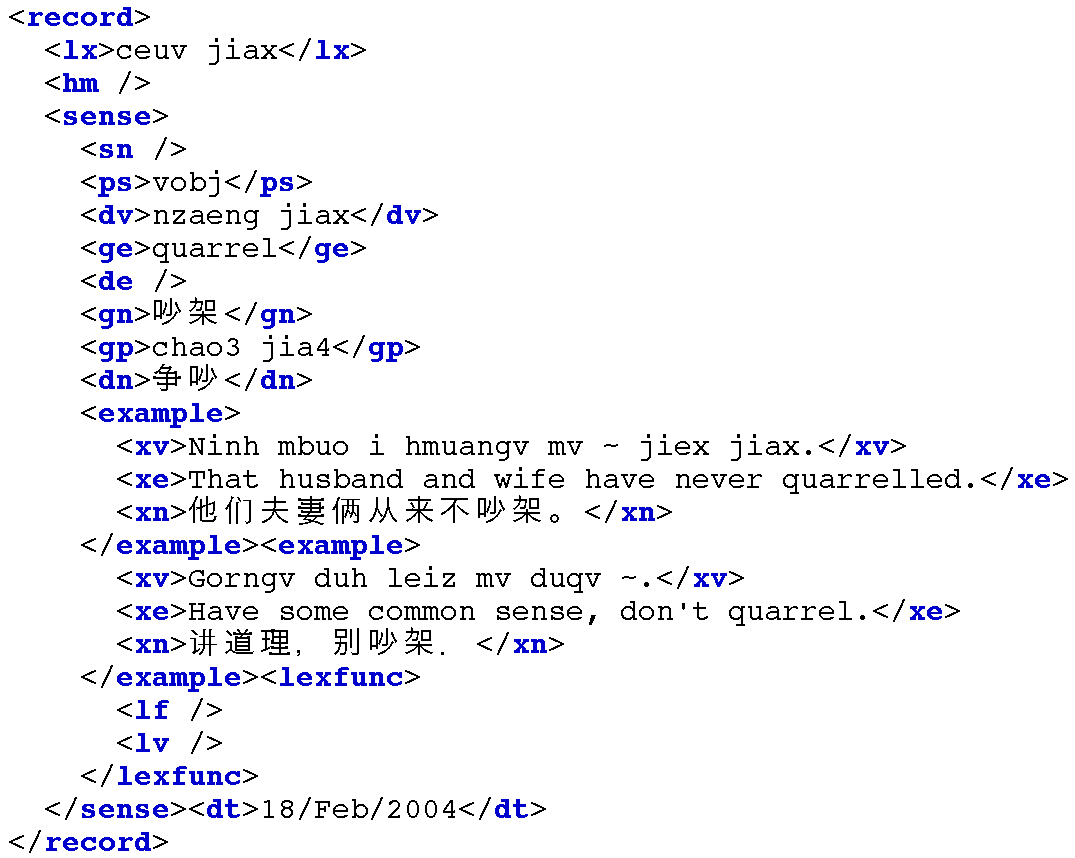
Рисунок 5.4: XML-представление лексической записи, полученное в результате разбора группировки записи Toolbox
6 Описание языковых ресурсов с помощью метаданных OLAC
Члены сообщества NLP имеют общую потребность в обнаружении языковых ресурсов с высокой точностью и охватом. Решение, которое было разработано сообществом цифровых библиотек (the Digital Libraries community) включает агрегацию метаданных.
6.1 Что такое метаданные?
Самое простое определение метаданных "структурированные данные о данных". Метаданные - это описательная информацию об объекте или ресурсе, будь то физическом или электронном. Хотя термин метаданные сам по себе является относительно новым, лежащие в его основе концепции использовались с тех пор, как были организованы сборники информации. Библиотечные каталоги представляют собой устоявшийся тип метаданных; они служили в качестве средств управления сбором и обнаружения ресурсов в течение многих десятилетий. Метаданные могут быть получены либо "вручную" или сгенерированы автоматически с помощью программного обеспечения.
Дублинская Инициатива Базовых Метаданных возникла в 1995 году для разработки конвенций поиска ресурсов в Интернете. Элементы дублинских базовых метаданных представляют собой широкий, междисциплинарный консенсус относительно основного набора элементов, которые могут быть полезны на практике для поддержки поиска ресурсов. Дублинская база состоит из 15 элементов метаданных, каждый из которых является необязательным и повторяемым: название, создатель, тема, описание, издатель, участники, дата, тип, формат, идентификатор, источник, язык, отношение, охват, права. Этот набор метаданных может быть использован для описания ресурсов, которые существуют в цифровых или традиционных форматах.
Инициатива открытых архивов (The Open Archives initiative (OAI)) предоставляет общую структуру цифровых хранилищ научных материалов независимо от их типа, включая документы, данные, программное обеспечение, записи, физические артефакты, цифровые суррогаты и так далее. Каждый репозиторий состоит из доступного сетевого сервера, предлагающий публичный доступ к архивным элементам. Каждый элемент имеет уникальный идентификатор и связан с записью дублинских базовых метаданных (и, возможно, с дополнительными записями в других форматах). OAI определяет протокол для услуг поиска метаданных, которые "собирают" содержимое хранилищ.
6.2 OLAC: Сообщество открытых языковых архивов
Сообщество открытых языковых архивов (Open Language Archives Community (OLAC)) - это международное партнерство учреждений и людей, которые создают всемирную виртуальную библиотеку языковых ресурсов посредством: (i) разработки консенсуса по наилучшей текущей практике цифрового архивирования языковых ресурсов и (ii) разработки сети взаимодействующих хранилищ и услуг по хранению и получению доступа к таким ресурсам. Домашняя страница OLAC в сети: http://www.language-archives.org/.
Метаданные OLAC являются стандартом для описания языковых ресурсов. Единообразное описание разных хранилищ обеспечивается путем ограничения значений некоторых элементов метаданных использованием терминов из контролируемых словарей. Метаданные OLAC могут быть использованы для описания данных и инструментов, в физических и цифровых форматах. Метаданные OLAC расширяют метаданные дублинский базовый набор, широко принятый стандарт для описания ресурсов всех типов. К этому основному набору OLAC добавляет дескрипторы для покрытия основных свойств языковых ресурсов, таких как язык предмета и языковый тип. Вот пример полной записи OLAC:
<?xml version="1.0" encoding="UTF-8"?>
<olac:olac xmlns:olac="http://www.language-archives.org/OLAC/1.1/"
xmlns="http://purl.org/dc/elements/1.1/"
xmlns:dcterms="http://purl.org/dc/terms/"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.language-archives.org/OLAC/1.1/
http://www.language-archives.org/OLAC/1.1/olac.xsd">
<title>A grammar of Kayardild. With comparative notes on Tangkic.</title>
<creator>Evans, Nicholas D.</creator>
<subject>Kayardild grammar</subject>
<subject xsi:type="olac:language" olac:code="gyd">Kayardild</subject>
<language xsi:type="olac:language" olac:code="en">English</language>
<description>Kayardild Grammar (ISBN 3110127954)</description>
<publisher>Berlin - Mouton de Gruyter</publisher>
<contributor xsi:type="olac:role" olac:code="author">Nicholas Evans</contributor>
<format>hardcover, 837 pages</format>
<relation>related to ISBN 0646119966</relation>
<coverage>Australia</coverage>
<type xsi:type="olac:linguistic-type" olac:code="language_description"/>
<type xsi:type="dcterms:DCMIType">Text</type>
</olac:olac>
Участвующие языковые архивы публикуют свои каталоги в формате XML, и эти записи регулярно "собираются" сервисами OLAC с использованием протокола OAI. В дополнение к этой программной инфраструктуре OLAC задокументировала ряд лучших практик для описания языковых ресурсов в рамках процесса, который включал расширенные консультации с сообществом языковых ресурсов (например, см. http://www.language-archives.org/REC/bpr.html).
Можно осуществлять поиск по OLAC репозиториям с помощью поисковой системы на сайте OLAC. Поиск фразы "German lexicon" находит следующие ресурсы среди прочего:
- CALLHOME Немецкий Lexicon http://www.language-archives.org/item/oai:www.ldc.upenn.edu:LDC97L18
- MULTILEX многоязычный лексикон http://www.language-archives.org/item/oai:elra.icp.inpg.fr:M0001
- Slelex фонетический лексикон Siemens http://www.language-archives.org/item/oai:elra.icp.inpg.fr:S0048
Поиск "Korean" находит newswire corpus, a treebank, a lexicon, a child-language corpus, подстрочно комментированные тексты. Он также находит программное обеспечение, в том числе синтаксический анализатор и морфологический анализатор.
Заметим, что приведенные выше URL-адреса включают подстроку формы: oai:www.ldc.upenn.edu:LDC97L18. Это идентификатор OAI, использующий схему URI , зарегистрированную в ICANN (Интернет корпорация по присвоению имен и номеров). Эти идентификаторы имеют формат oai:archive:local_id, где oai это имя схемы URI, archive представляет собой идентификатор архива, такой как www.ldc.upenn.edu, а local_id - это идентификатор ресурса, назначенный архиву, например, LDC97L18.
Для данного идентификатора OAI данного OLAC ресурса можно получить полную XML-запись для данного ресурса по ссылке следующего вида:
http://www.language-archives.org/static-records/oai:archive:local_id
6 Резюме
- Основные типы данных, присутствующие в большинстве корпусов, - аннотированные тексты и словари. Тексты имеют временную структуру, в то время как лексиконы имеют структуру записи.
- Жизненный цикл корпуса включает в себя сбор данных, аннотацию, контроль качества и публикации. Жизненный цикл продолжается после публикации по мере того, как корпус изменяется и обогащается в ходе исследования.
- Разработка полезного корпуса требует соблюдения баланса между представительной выборкой использования языка и достаточным количеством материала из любого одного источника или жанра; перемножение измерений вариации, как правило, не представляется возможным из-за ресурсных ограничений.
- XML предоставляет полезный формат для хранения и обмена лингвистическими данными, но не предоставляет никаких готовых решений широко распространенных проблем моделирования данных.
- Формат Toolbox широко используется в проектах по документированию языков; мы можем писать программы для поддержки курирования файлов Toolbox и конвертировать их в XML.
- Сообщество открытых языковых архивов (OLAC) обеспечивает инфраструктуру для документирования и обнаружения языковых ресурсов.
7 Дополнительные материалы
Дополнительные материалы для этой главы размещены на странице http://nltk.org/, в том числе ссылки на свободно доступные ресурсы в сети.
Основными источниками языковых корпусов являются /Linguistic Data Consortium и European Language Resources Agency, оба с обширными онлайн-каталогами. Подробности относительно основных корпусов, упомянутых в главе, доступны в следующих работах: American National Corpus (Reppen, Ide, & Suderman, 2005), British National Corpus ({BNC}, 1999), Thesaurus Linguae Graecae ({TLG}, 1999), Child Language Data Exchange System (CHILDES) (MacWhinney, 1995), TIMIT (S., Lamel, & William, 1986).
Двумя специальными группами Ассоциации по вычислительной лингвистике, которые организуют регулярные семинары, с опубликованными материалами являются SIGWAC, которая способствует использованию сети в качестве корпуса и спонсировала задачу CLEANEVAL для удаления HTML-разметки, и SIGANN, которая способствует усилиям, направленным на взаимодействие лингвистических аннотаций.
Полная информация о формате данных Toolbox предоставляются с дистрибутивом (Buseman, Buseman, & Early, 1996) и с последним дистрибутивом, свободно доступом на http://www.sil.org/computing/toolbox/. Инструкции по процессу построения Toolbox лексикона см. на http://www.sil.org/computing/ddp/. Дополнительные примеры программ для Toolbox документированы в (Tamanji, Hirotani, & Hall, 1999), (Робинсон, Aumann, & Bird, 2007). Для управления лингвистическими данными доступны десятки других инструментов, некоторые из которых обследованы в (Bird & Simons, 2003). Смотрите также труды мастерских "LaTeCH" по языковым технологиям для данных культурного наследия.
Есть много отличных ресурсов по XML (например , http://zvon.org/) и по написанию программ Python для работы с XML. Многие редакторы имеют режимы XML. Форматы XML для лексической информации включают OLIF http://www.olif.net/ и LIFT http://code.google.com/p/lift-standard/.
Для ознакомления с обследованием программного обеспечения лингвистической аннотации см. Linguistic Annotation Page на http://www.ldc.upenn.edu/annotation/. Первоначально внешняя аннотация была предложена в (Thompson & McKelvie, 1997). Абстрактная модель данных для лингвистических аннотаций, называемая "аннотационные графы", была предложена в (Bird & Liberman, 2001). Онтология общего назначения для лингвистического описания (GOLD) описана на http://www.linguistics-ontology.org/.
Для ознакомления с руководством по планированию и построению корпуса, см. (Meyer, 2002), (Farghaly, 2003). Более подробная информация о методах оценки согласия между аннотаторами доступна в работах (Artstein & Poesio, 2008), (Pevzner & Hearst, 2002).
Данные Ротокас были предоставлены Стюартом Робинсоном, а данные Iu Mien были предоставлены Грегом Ауманном.
Для получения дополнительной информации о Сообществе открытых языковых архивов посетите http://www.language-archives.org/ или посмотрите (Simons & Bird, 2003).
9 Упражнения
◑ В 5.1 новое поле появилось в нижней части записи. Изменить эту программу так , чтобы она вставляет новый подэлемент сразу после поля лк. (Подсказка: создать новое поле резюме с помощью элемента ( "резюме"), присвоить текстовое значение для него, а затем использовать метод вставки () родительского элемента.)
◑ Написать функцию, которая удаляет заданное поле из лексической записи. (Мы могли бы использовать эту функцию, чтобы дезинфицировать наши лексические данные, прежде чем дать его другим, например, путем удаления полей, содержащих нерелевантные или неопределенного содержания.)
◑ Напишите программу , которая сканирует файл словаря HTML , чтобы найти записи , имеющие незаконный неполный из речи поля, и сообщает заглавное слово для каждой записи.
◑ Напишите программу , чтобы найти какие - либо части речи (пс поле) , которое произошло менее чем в десять раз. Возможно, эти опечатки?
◑ Мы увидели способ обнаружения случаев целого слова удвоением. Написать функцию, чтобы найти слова, которые могут содержать частичную редупликацию. Используйте метод re.search (), а также следующее регулярное выражение: (..{0}{1}!={/1}{/0}
◑ Мы увидели способ добавления поля резюме. Существует интересная проблема с сохранением этого последнюю дату , когда кто - то изменяет содержимое поля лк , на котором она основана. Напишите версию этой программы , чтобы добавить поле резюме, замена любого существующего поля резюме.
◑ Написать функцию , чтобы добавить новый SYL поле , что дает подсчет количества слогов в слове.
◑ Написать функцию, которая отображает полную запись для лексемы. Когда лексема неправильно пишется он должен отображать запись для наиболее аналогичным образом прописана лексемы.
◑ Написать функцию , которая принимает лексикон и обнаруживает , какие пары последовательных полей являются наиболее частыми (например , пс часто сопровождается пт). (Это может помочь нам обнаружить некоторые структуры лексической записи.)
◑ Создание таблицы с помощью офисного программного обеспечения, содержащий одну лексическую запись на строку, состоящую из заглавного слова, часть речи, и блеск. Сохраните таблицу в формате CSV. Написать код Python , чтобы прочитать файл CSV и распечатать его в формате Toolbox, используя лк для заглавного слова, пс для части речи и ОЛ для блеска.
◑ Индекс слова пьесы Шекспира, с помощью NLTK.Индекс. Полученная структура данных должна позволять поиск по отдельным словам , такие как музыка, возвращая список ссылок на акты, сцены и выступлений, формы [(3, 2, 9), (5, 1, 23), ...] , где (3, 2, 9) указывает на то Акт 3 Сцена 2 Speech 9.
◑ Построить условное распределение частот , который регистрирует длину слова для каждого слова в Венецианском купце, кондиционированной по имени персонажа, например , кфд [ 'Порция'] [12] даст нам число выступлений Порции , состоящий из 12 слова.
★ Получить сравнительный список слов в формате CSV, и написать программу, которая печатает эти родственные слова, имеющие от изменений расстояния, по меньшей мере, трех друг от друга.
★ Построить индекс тех лексем, которые появляются в примеры предложений. Предположим , что лексема для данной записи является ш. Затем добавить один перекрестных ссылок поля XRF к этому входу, ссылаясь на заглавных других записей , имеющих пример предложения , содержащие W. Сделайте это для всех записей и сохранить результат в виде файла формата инструментов.
◑ Написать рекурсивную функцию для получения представления XML для дерева, с нетерминалов, представленных в виде элементов XML и листьев, представленных в виде текстового содержания, например:
<S> <тип NP = "SBJ"> <NP> <ННП> Pierre </ ННП> <ННП> Vinken </ ННП> </ NP> <COMMA>, </ COMMA>
Об этом документе ...
Обновлялся для NLTK 3.0. Это глава из книги Обработка естественного языка с помощью Python написанной Стивеном Бердом , Эваном Клайном и Эдвардом Лопером , Copyright © 2014 авторов. Он распространяется с Набором инструментов для естественного языка [http://nltk.org/], версия 3.0 в соответствии с условиями Creative Commons Attribution-Noncommercial-No Derivative Works 3.0 Лицензии Соединенных Штатов [ http://creativecommons.org/licenses/by-nc-nd/3.0/us/].
Этот документ был построен на ср 1 июля 2015 12:30:05 AEST