8. Анализ структуры предложения
Предыдущие главы были сосредоточены на словах: как идентифицировать их, проанализировать их структуру, назначать их лексическим категориям, а также получить доступ к их значениям. Мы также видели, как определить закономерности в последовательности слов или n-граммы. Тем не менее эти методы только царапают поверхность сложных ограничений, которые регулируют предложения. Нам нужен способ работать с неоднозначностью, которой славится естественный язык. Мы также должны быть в состоянии справиться с тем фактом, что существует неограниченное число возможных предложений, а мы можем писать только конечные программы для анализа их структуры и раскрытия их смысла.
Цель этой главы - ответить на следующие вопросы:
- Как мы можем использовать формальную грамматику для описания структуры неограниченного множества предложений?
- Как мы представляем структуру предложений с использованием синтаксических деревьев?
- Как синтаксические анализаторы анализируют предложение и автоматически строят синтаксическое дерево?
По ходу изложения мы рассмотрим основы английского синтаксиса и увидим, что существуют систематические аспекты смысла, которые гораздо легче схватить, как только мы определили структуру предложений.
1 Некоторые Грамматические Дилеммы
1.1 Лингвистические данные и неограниченные возможности
Предыдущие главы показали вам, как обрабатывать и анализировать текстовые корпусы, и мы выделили задачи NLP в работе с огромным количеством данных электронного языка, который растет с каждым днем. Рассмотрим эти данные более тесно и выполним мысленный эксперимент, предположив, что мы имеем гигантский корпус, состоящий из всего, что было произнесено или написано на английском языке в течение, скажем, последних 50 лет. Есть ли у нас основания называть этот корпус "Современный английский язык"? Есть целый ряд причин, по которым мы могли бы ответить: "Нет". Вспомните, что в 3, мы попросили вас найти в Интернете экземпляры паттерна the of. Хотя в Интернете несложно найти примеры, содержащие эту последовательность слов, такие как New man at the of IMG (http://www.telegraph.co.uk/sport/2387900/New-man-at-the-of-IMG.html), носители английского языка скажут, что большинство таких примеров ошибочны и, следовательно, не являются частью английского языка.
Соответственно мы можем утверждать, что "современный английский" не эквивалентен очень большому набору последовательностей слов в нашем воображаемом корпусе. Носители английского языка могут выносить суждения об этих последовательностях и отвергать некоторые из них как безграмотные.
Точно так же, легко составить новое предложение и получить согласие носителей, что это вполне хороший английский. Например, предложения имеют интересное свойство, что они могут быть внедрены в более крупные предложения. Рассмотрим следующие предложения:
| (1) |
|
Если бы мы заменили целые предложения символом S, мы бы увидели такие модели, как Andre said S и I think S. Это шаблоны, с помощью которых можно взять предложение и построить большее предложение. Есть и другие шаблоны, которые мы можем использовать, как S but S и S when S. Немного изобретательности поможет нам построить некоторые действительно длинные предложения с помощью этих шаблонов. Вот впечатляющий пример из Истории Винни-Пуха А. А. Милна, в которой Пятачок полностью окружен водой:
[You can imagine Piglet's joy when at last the ship came in sight of him.] In after-years he liked to think that he had been in Very Great Danger during the Terrible Flood, but the only danger he had really been in was the last half-hour of his imprisonment, when Owl, who had just flown up, sat on a branch of his tree to comfort him, and told him a very long story about an aunt who had once laid a seagull's egg by mistake, and the story went on and on, rather like this sentence, until Piglet who was listening out of his window without much hope, went to sleep quietly and naturally, slipping slowly out of the window towards the water until he was only hanging on by his toes, at which moment, luckily, a sudden loud squawk from Owl, which was really part of the story, being what his aunt said, woke the Piglet up and just gave him time to jerk himself back into safety and say, "How interesting, and did she?" when — well, you can imagine his joy when at last he saw the good ship, Brain of Pooh (Captain, C. Robin; 1st Mate, P. Bear) coming over the sea to rescue him...
Это длинное предложение на самом деле имеет простую структуру, которая начинается с S but S when S. Мы можем увидеть из этого примера, что язык дает нам конструкции, которые, как представляется, позволяют распространять предложения бесконечно. То, что мы можем понимать предложения произвольной длины, которые мы никогда раньше не слышали, также поразительно: не трудно придумать совершенно новое предложение, которое, вероятно, никогда ранее не использовалось в истории языка, но все носители языка поймут его.
Цель грамматики дать явное описание языка. Но то, как мы мыслим грамматику, тесно переплетается с тем, что мы считаем языком. Является ли язык большим, но конечным множеством наблюдаемых высказываний и письменных текстов? Является ли он чем-то более абстрактным, как неявное знание, которым обладают компетентные носители о грамматических предложениях? Или это некоторое сочетание этих двух? Мы не будем занимать определенную позицию по этому вопросу, но вместо этого представим основные подходы.
В этой главе мы будем применять формальные рамки "порождающей грамматики", в которой "язык" считается ни чем иным, как огромной совокупностью всех грамматических предложений, а грамматика является формальной системой, которая может быть использована для "генерации" членов этого набора. Грамматики используют рекурсивные модели вида S → S and S, как мы увидим в 3. В 10. мы расширим это понимание, чтобы автоматически выстроить смысл предложения из значений его частей.
1.2 Вездесущая неоднозначность
Хорошо известный пример неоднозначности показан в (2), из фильма Граучо Маркса, Animal Crackers (1930):
| (2) | While hunting in Africa, I shot an elephant in my pajamas. How he got into my pajamas, I don't know. |
Давайте подробнее рассмотрим неоднозначности во фразе: я застрелил слона в моей пижаме. Во-первых, мы должны определить простую грамматику:
|
Эта грамматика допускает два способа проанализировать предложение, в зависимости от того, описывает ли предложная фраза в моей пижаме слона или событие выстрела.
|
Программа производит две заключенные в квадратные скобки структуры, которые мы можем изобразить в виде деревьев, как показано в (3b):
| (3) |
|
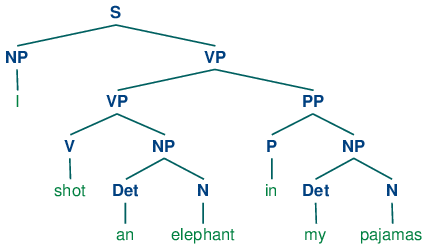
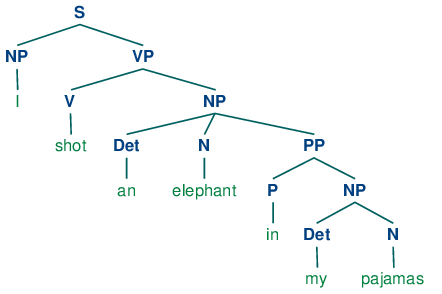
Обратите внимание на то, что нет никакой двусмысленности относительно значения любого из слов; например, слово выстрел не относится к акту использования пистолета в первом предложении и использования камеры во втором предложении.
Замечание
Ваша очередь: Рассмотрите следующие предложения и попробуйте придумать две совершенно различные интерпретации: Fighting animals could be dangerous. Visiting relatives can be tiresome. Виновата ли в этом многозначность отдельных слов? Если нет, то что является причиной этой неоднозначности?
В этой главе представлены грамматики и синтаксический анализ как формальные и вычислительные методы для изучения и моделирования языковых явлений, которые мы обсуждали ранее. Как мы увидим, паттерны хорошой оформленности и плохой оформленности в последовательности слов могут быть поняты относительно структуры фразы и зависимостей внутри нее. Мы можем разработать формальные модели этих структур с помощью грамматик и синтаксических анализаторов. Как и прежде, основной мотивацией является понимание естественного языка. Насколько больше смысла текста мы можем использовать, когда мы умеем надежно распознавать языковые структуры, которые он содержит? Прочитав ответ в тексте, может программа "понять" его достаточно, чтобы иметь возможность ответить на простые вопросы о том, "что случилось" или "кто что кому сделал"? Кроме того, как и прежде, мы будем разрабатывать простые программы для обработки аннотированных корпусов и выполнения полезных задач.
2 Зачем нужен синтаксис?
2.1 За пределами n-грамм
В 2. мы дали пример того, как использовать информацию о частоте в биграммах для генерации текста , который кажется вполне приемлемым для небольших последовательностей слов, но быстро вырождается в бессмыслицу. Вот еще пара примеров, которые мы создали путем вычисления биграмм для текста рассказа для детей, The Adventurs of Buster Brown(http://www.gutenberg.org/files/22816/22816.txt):
| (4) |
|
Вы интуитивно знаете, что эти последовательности "салат из слов", но вы, вероятно, с трудом можете сказать, что с ними случилось. Одним из преимуществ изучения грамматики является то, что она предоставляет концептуальные рамки и словарный запас для выражения этих интуиций. Давайте подробнее рассмотрим последовательность the worst part and clumsy looking. Это выглядит как сочиненная структура, в которой две фразы объединены соединительным союзом, таким как и, но или или. Вот неформальное (и упрощенный) определение того, как сочинение работает синтаксически:
Сочиненная структура:
Если v1 и v2 являются обе фразами грамматической категории X, то v1 и v2 также фраза категории X.
Вот несколько примеров. В первом из них две ИФ (именные фразы) были конъюгированы, чтобы получить ИФ, а во втором две ПФ (прилагательные фразы) были конъюгированы, чтобы получить AP.
| (5) |
|
То, что мы не можем сделать, это объединить ИФ и ПФ, поэтому выражение the worst part and clumsy looking безграмотно. Прежде чем мы сможем формализовать эти идеи, нам необходимо понять концепцию конституирующей структуры.
Конституирующая структура основана на наблюдении, что слова сочетаются с другими словами, чтобы сформировать единства. Доказательство того, что последовательность слов образует такое единство дается через заменяемость - то есть последовательность слов в хорошо сформированном предложении можно заменить на более короткую последовательность не переводя предлоежние в плохо сформированные. Чтобы прояснить эту мысль, рассмотрим следующее предложение:
| (6) | The little bear saw the fine fat trout in the brook. |
Тот факт, что мы можем заменить The little bear на He указывает на то, что первая последовательность является единством. В отличие от нее мы не можем заменить littel bear saw таким же образом.
| 4,46% |
|
В 2.1 мы систематически заменяем длинные последовательности на более короткие способом, который сохраняет грамматичность. Каждая последовательность, которая образует единство может быть на самом деле заменена одним словом, и мы в конечном итоге приходим только к двум элементам.
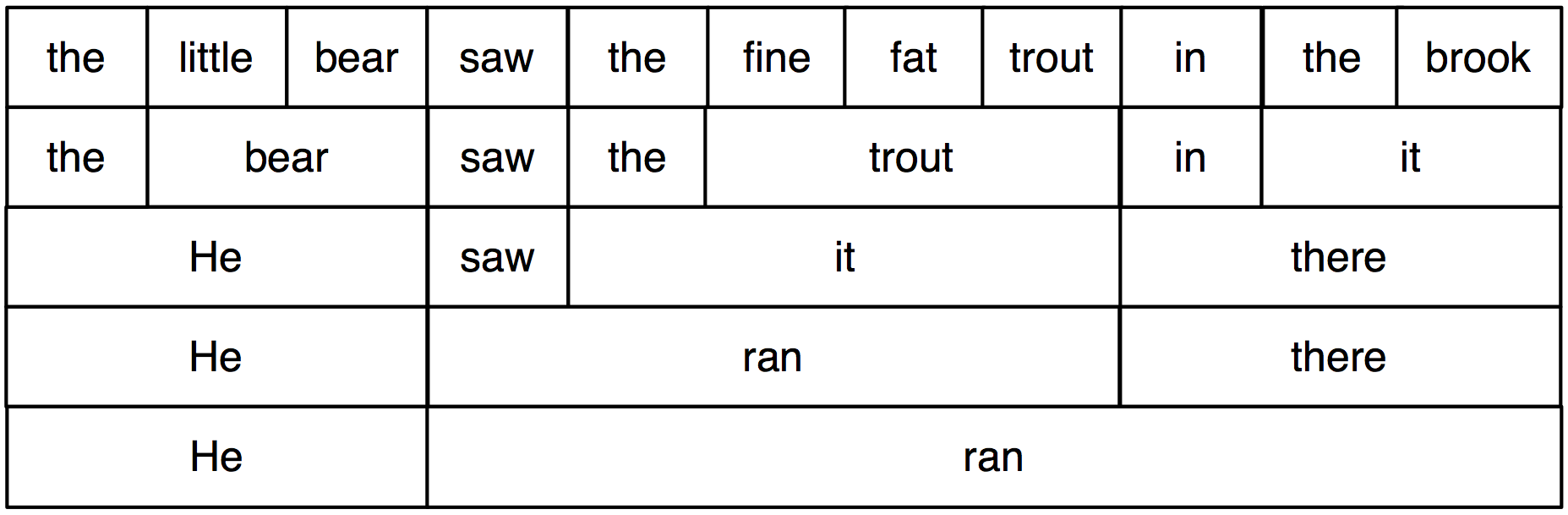
Рисунок 2.1: Замена последовательностей слов: начиная с верхнего ряда, мы можем заменить определенные последовательности слов (например, the brook) отдельными словами (например , it); повторяя этот процесс, мы приходим к грамматическому двухсловному предложению.
В 2.2 мы добавили грамматические категории надписей для слов, которые мы видели на предыдущем рисунке. Метки NP, VP и PP обозначают именную глагольную и предложную фразу соответственно.
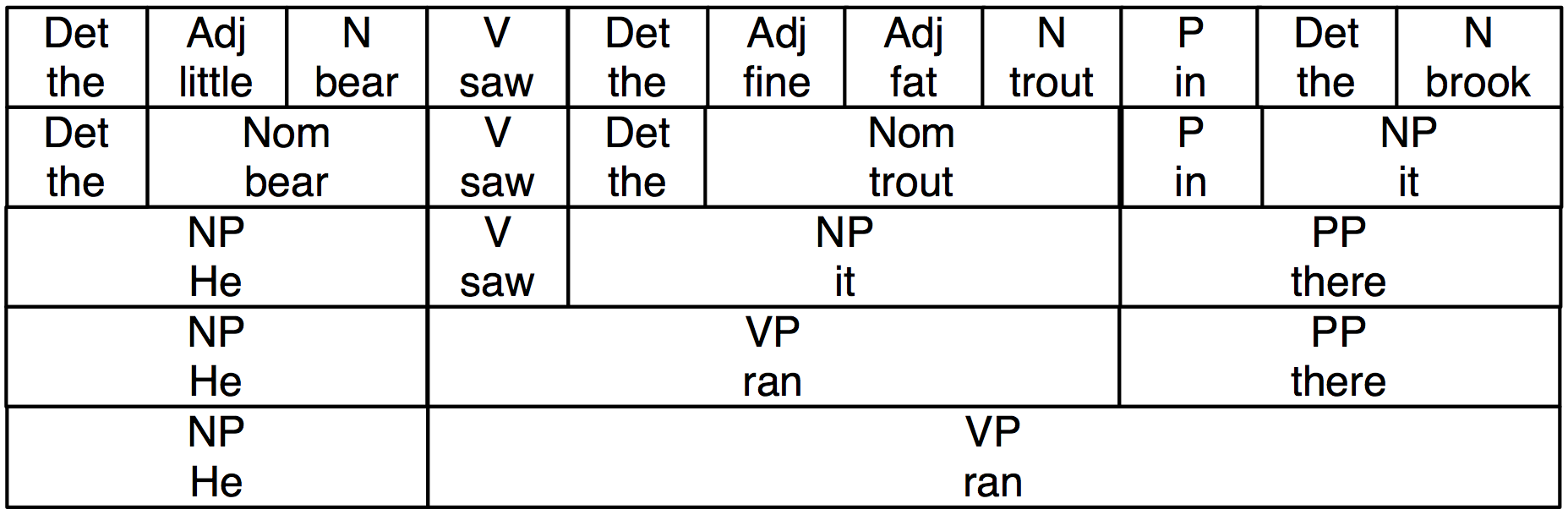
Рисунок 2.2: Замена последовательностей слов плюс грамматические категории: Эта диаграмма воспроизводит 2.1 наряду с грамматическими категориями, соответствующими именным фразам (NP), глагольным фразам (VP), предложным фразам (PP) и номиналам (Nom).
Если мы теперь уберем все слова, кроме самого верхнего ряда, добавим узел S и повернем фигуру, мы в конечном итоге получим стандартное дерево фразовой структуры, как показано в (8). Каждый узел в этом дереве (в том числе слова) называется составляющей (конституентом). Непосредственным составляющими S являются NP и VP.
| (8) | 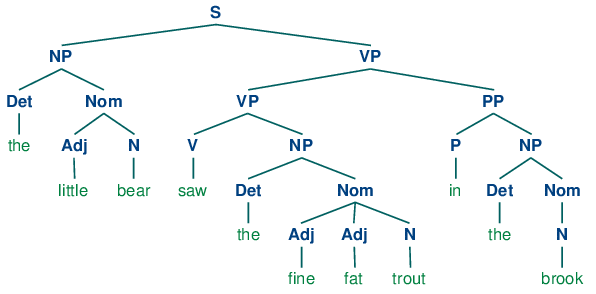 |
Как мы увидим в следующем разделе, грамматика определяет, каким образом предложение может быть подразделено на непосредственные составляющие и каким образом последние могут быть дальше подразделены, пока мы не достигнем уровня отдельных слов.
Замечание
Как мы видели в 1, предложения могут иметь произвольную длину. Следовательно, деревья фразовой структуры могут иметь произвольную глубину. Каскадированные синтаксические анализаторы группировок, которые мы видели в 4 могут производить только структуры ограниченной глубины, поэтому методы группировки не применимы здесь.
3 Безконтекстная грамматика
3.1 Простая грамматика
Давайте начнем с рассмотрения простой безконтекстной грамматики. По соглашению левая сторона первого продуцирования является начальным символом грамматики, как правило, S, и все хорошо сформированные деревья должны иметь этот символ в качестве корневой метки. В NLTK безконтекстные грамматики определены в модуле nltk.grammar. В разделе 3.1 мы определим грамматику и покажем, как разобрать простое предложение допускаемое грамматикой.
| ||
| ||
Пример 3.1 (code_cfg1.py): Рисунок 3.1: Простая безконтекстная грамматика |
Грамматика в 3.1 содержит продуцирования с участием различных синтаксических категорий, как изложено в 3.1.
| Обозначения | Значение | Пример |
|---|---|---|
| S | предложение | the man walked |
| NP | именная фраза | a dog |
| VP | глагольная фраза | saw a park |
| PP | предложная фраза | with a telescope |
| Det | определитель | the |
| N | существительное (имя) | dog |
| V | глагол | walked |
| P | предлог | in | Таблица 3.1: Синтаксические категории |
Продуцирование, как VP -> V NP | V NP PP, имеет дизъюнкцию на правой стороне, показнную |, и такая запись является аббревиатурой для двух продуцирований VP -> V NP и VP -> V NP PP.
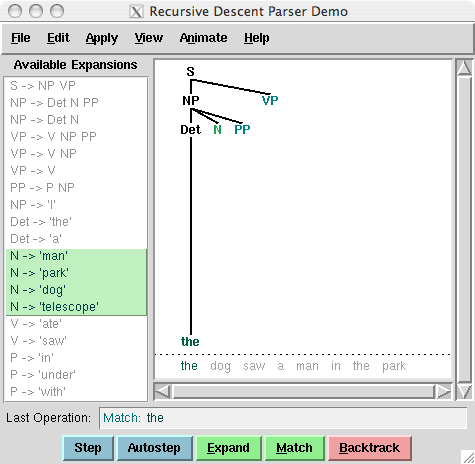
Рисунок 3.2: Recursive Descent Parser Demo: Этот инструмент позволяет следить за работой рекурсивно спускающегося синтаксического анализатора по мере того, как он создает дерево синтаксического разбора и наполняет его входными словами.
Замечание
Ваша очередь: Попробуйте разработать простую грамматику самостоятельно с помощью приложения recursive descent parser , nltk.app.rdparser(), показанного на Рисунке 3.2. Он поставляется с уже загруженным примером грамматики, но вы можете изменить его как вам будет угодно (с помощью меню Edit). Измените грамматику и предложение, которое должно быть проанализировано, и запустите анализатор с помощью кнопки autostep.
Если разобрать предложение The dog saw a man in the park с помощью грамматики, показанной в разделе 3.1, мы получим в конечном итоге два дерева похожих на те, которые мы видели для (3b):
| (9) |
|
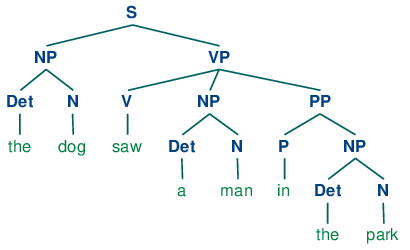
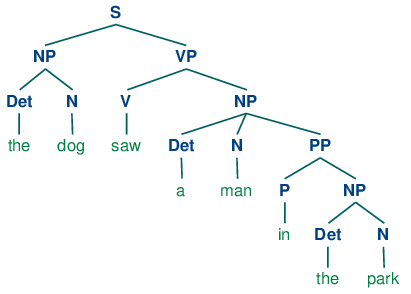
Так как наша грамматика допускает два дерева для этого предложения, предложение называется структурно неоднозначным. Данная неоднозначность называется неоднозначность приложения предложной фразы, как мы видели ранее в этой главе. Как вы, возможно, помните, это двусмысленность приложения, так как PP in the park необходимо приложить к одному из двух мест в дереве: либо как ребенок VP или как ребенок NP.Когда PP приложена к VP, предполагаемая интерпретация заключается в том, что событие видения произошло в парке. Однако если PP прилагается к NP, тогда в парке был человек, а агент видения (собака), возможно, сидела на балконе квартиры с видом на парк.
3.2 Написание ваших собственных грамматик
Если вы заинтересованы в экспериментировании с написанием безконтекстных грамматик (CFGs), вам будет удобно создавать и редактировать грамматики в текстовом файле, скажем, mygrammar.cfg. После этого вы можете загрузить ее в NLTK и осуществлять синтаксический разбор следующим образом:
|
Убедитесь, что вы присоединили .cfg суффикс к имени файла и что в строке 'file:mygrammar.cfg' нет пробелов. Если команда print(tree) не производит никакого вывода, это, вероятно, потому, что ваше предложение sent не допускается вашей грамматикой. В этом случае вызовите парсер с включенным отслеживанием: rd_parser = NLTK.RecursiveDescentParser(grammar1, trace = 2). Вы также можете проверить, какие текущие продуцирования есть в грамматике с помощью команды for p in grammar1.productions(): print(р).
Когда вы пишете CFGs для разбора в NLTK, вы не можете комбинировать грамматические категории с лексическими единицами на правой стороне одного и того же продуцирования. Таким образом, продуцирование, такое как PP -> 'of' NP запрещено. Кроме того, не разрешается размещать лексические единицы, состоящие из нескольких слов, на правой части продуцирования. Поэтому вместо того, чтобы писать NP -> 'New' 'York', вы должны прибегнуть к чему-то вроде NP -> 'New_York' вместо этого.
3.3 Рекурсия в синтаксической структуре
Грамматика называется рекурсивной, если категория, возникающая на левой стороне продуцирования, также появляется и на правой его части, как показано в 3.3. Продуцирование Nom -> Adj Nom (где Nom это категория номиналов) влечет прямую рекурсию по категории Nom, тогда как непрямая рекурсия по S возникает из сочетания двух продуцирований, а именно : S -> NP VP и VP -> V S.
| ||
Пример 3.3 (code_cfg2.py): Листинг 3.3: Рекурсивная безконтекстная грамматика |
Чтобы увидеть, как возникает рекурсия из этой грамматики, рассмотрим следующие деревья. (10a) влечет вложенные именные фразы, а (10b) содержит вложенные предложения.
| (10) |
|

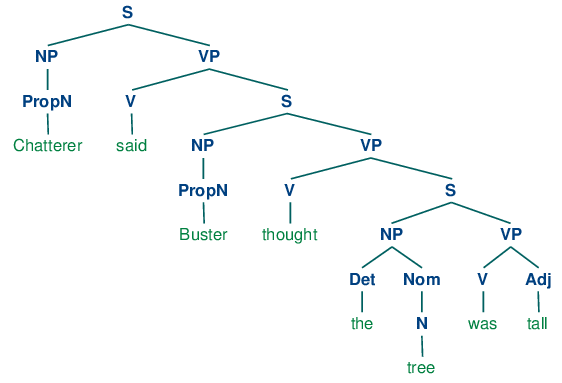
Мы проиллюстрировали только два уровня рекурсии здесь, но нет никакого верхнего предела глубины. Вы можете экспериментировать с разбором предложений, которые влекут более глубоко вложенные структуры. Обратите внимание, что RecursiveDescentParser не в состоянии справиться с левыми рекурсивными продуцированиями вида X -> XY; мы вернемся к этому в 4.
4 Синтаксический разбор с помощью безконтекстной грамматики
Анализатор обрабатывает входные предложения в соответствии с продуцированиями грамматики, а также создает одну или несколько составных структур, которые соответствуют грамматике. Грамматика является декларативной спецификацией хорошей оформленности - она, на самом деле, является только строкой, а не программой. Анализатор является процедурным толкованием грамматики. Он просматривает пространство деревьев, допускаемых грамматикой, чтобы найти то, которое может разместить требуемое предложение в своей кроне.
Анализатор позволяет оценить грамматику в отношении набора тестовых предложений, помогая лингвистам обнаружить ошибки в их грамматическом анализе. Анализатор может служить в качестве модели психолингвистической обработки, помогая объяснить трудности, которые люди испытывают при обработке некоторых синтаксических конструкций. Многие приложения естественного языка влекут синтаксический разбор на определенной стадии; например, можно было бы ожидать, что вопросы на естественном языке, задаваемые системе ответов на вопросы, пройдут синтаксический анализ в качестве первого шага обработки.
В этом разделе мы видим два простых алгоритма синтаксического анализа: метод, идущий сверху вниз, называемый рекурсивно спускающийся синтаксический анализ, и восходящий метод, называемый синтаксическим анализом сокращения сдвига(?). Мы также видим некоторые более сложные алгоритмы: метод сверху вниз с фильтрацией снизу вверх под названием синтаксический анализ левого угла и метод динамического программирования, называемый синтаксическим анализом диаграмм.
4.1 Рекурсивно спускающийся синтаксический разбор
Простейший вид анализатора интерпретирует грамматику как спецификацию того, как разбить цель высокого уровня на несколько подзадач более низкого уровня. Цель верхнего уровня - найти S. Продуцирование S → NP VP позволяет анализатору заменить эту цель двумя подзадачами: найти NP, а затем найти VP. Каждая из этих подзадач может быть заменена в свою очередь подподцелями с помощью продуцирований, которые имеют на левой стороне NP и VP соответственно. В конце концов, этот процесс приводит к подзадачам, таким как: найти слово телескоп. Такие подзадачи можно сравнивать непосредственно с входной последовательностью, они являются успешными, если следующее слово найдено. Если совпадения нет анализатор должен вернуться наверх и попробовать другую альтернативу.
Метод рекурсивного спуска строит дерево разбора во время вышеописанного процесса. С первоначальной целью (найти S) создается корневой узел S. Поскольку описанный выше процесс рекурсивно расширяет свои цели, используя продуцирования грамматики, дерево разбора распространяется вниз (отсюда и название рекурсивный спуск). Мы можем увидеть это в действии с помощью графической демонстрации nltk.app.rdparser(). Шесть этапов выполнения данного синтаксического анализа приведены на 4.1.
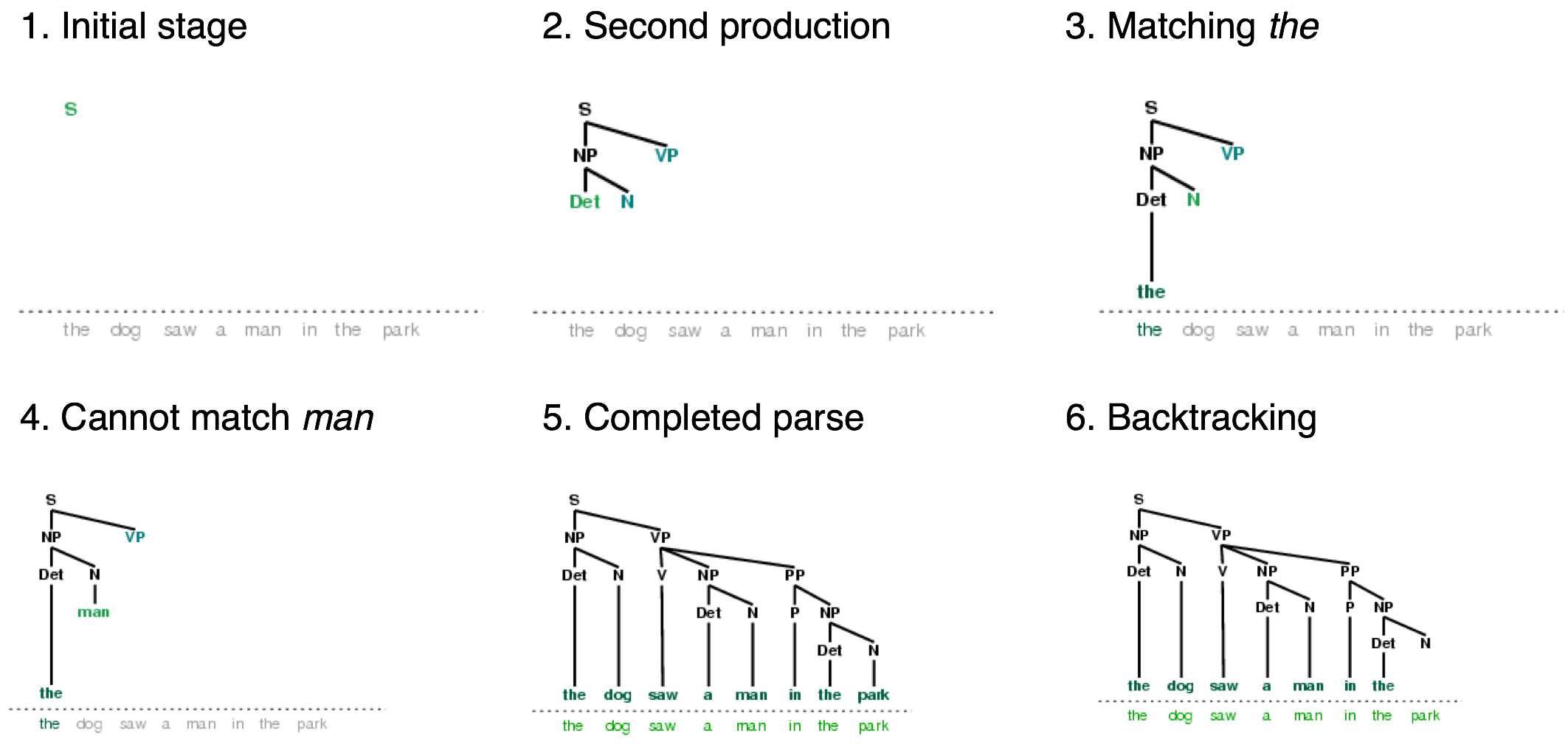
Рисунок 4.1: Шесть этапов метода рекурсивного спуска: анализатор начинает с дерева, состоящего из узла S; на каждом этапе он обращается к грамматике, чтобы найти продуцирование, которое может быть использовано для увеличения дерева; когда встречается лексическое продуцирование, его слово сравнивается с входом; после нахождения полного синтаксического разбора, анализатор ищет другие разборы.
Во время этого процесса анализатору часто приходится выбирать между несколькими возможными продуцированиями. Например, при переходе от шага 3 к шагу 4, он пытается найти продуцирования с N на левой стороне. Первым из них является N → человек. Когда это не срабатывает, он откатывается и пробует другие продуцирования N по порядку, пока не доберется до N → собака, которое соответствует следующему слову во входном предложении. Намного позже, как показано на шаге 5, он находит полный разбор. Это дерево, которое охватывает все предложение без каких-либо оборванных краев. После того, как синтаксический разбор был найден, мы можем использовать анализатор для поиска дополнительных разборов. Опять же он будет возвращаться назад и исследовать другие варианты продуцирования на случай, если какой-нибудь из них приведет к разбору.
NLTK предоставляет метод рекурсивного спуска:
|
Замечание
RecursiveDescentParser() принимает необязательный параметр trace. Если trace больше нуля, то анализатор будет сообщать те шаги , которые он предпринимает в процессе того, как он разбирает текст.
Синтаксический анализа с помощью рекурсивного спуска имеет три основных недостатка. Во- первых, левые рекурсивные продуцирования, как NP -> NP PP отправляют его в бесконечный цикл. Во-вторых, анализатор тратит уйму времени, рассматирвая слова и структуры, которые не соответствуют входному предложению. В-третьих, процесс отката может сбросить уже разобранные компоненты, которые необходимо будет восстановить позже. Например, откат с VP -> V NP отбросит поддерево, созданное для NP. Если анализатор затем продолжает с VP -> V NP PP, то поддерево NP должно быть создано заново.
Синтаксический анализ с помощью рекурсивного спуска является видом синтаксического анализа сверху вниз. Нисходящие анализаторы используют грамматику, чтобы предсказывать, какой будет вход до проверки входа! Тем не менее, поскольку вход доступен для синтаксического анализатора все время, было бы более целесообразно рассмотреть входное предложение с самого начала. Такой подход называется синтаксический анализ снизу вверх, и мы увидим его пример в следующем разделе.
4.2 Синтаксический разбор помещения-сокращения
Простой вид синтаксического анализа снизу вверх является синтаксический анализатор помещения-сокращения. Как и все анализаторы снизу вверх, анализатор помещения-сокращения пытается найти последовательности слов и фраз, которые соответствуют правой стороне продуцирования грамматики, и заменить их левой стороной, пока вся фраза не свернется в S.
Анализатор неоднократно выталкивает следующее входное слово в стек (4.1); это операция называется помещением. Если верхние n элементов в стеке соответствуют n элементам на правой стороне какого-то продуцирования, то все они извлекаются из стека, а элемент на левой стороне продуцирования помещается в стек. Эта замена верхних n элементов одним элементом является операцией сокращения. Эта операция может быть применена только к верхней части стека; сокращение элементов, находящихся ниже в стеке, должно быть выполнено до помещения новых элементов в стек. Анализатор заканчивает работу, когда весь вход использован и остается только один элемент в стеке - дерево разбора с узлом S в качестве корневого элемента. Анализатор помещения-сокращения строит дерево разбора во время вышеописанного процесса. Каждый раз, когда она сокращает n элементов из стека, он объединяет их в частичное дерево разбора и помещает обратно в стек. Мы можем увидеть в действии алгоритм синтаксического анализа помещения-сокращения с помощью графической демонстрации nltk.app.srparser(). Шесть этапов выполнения данного синтаксического анализатора приведены на Рисунке 4.2.
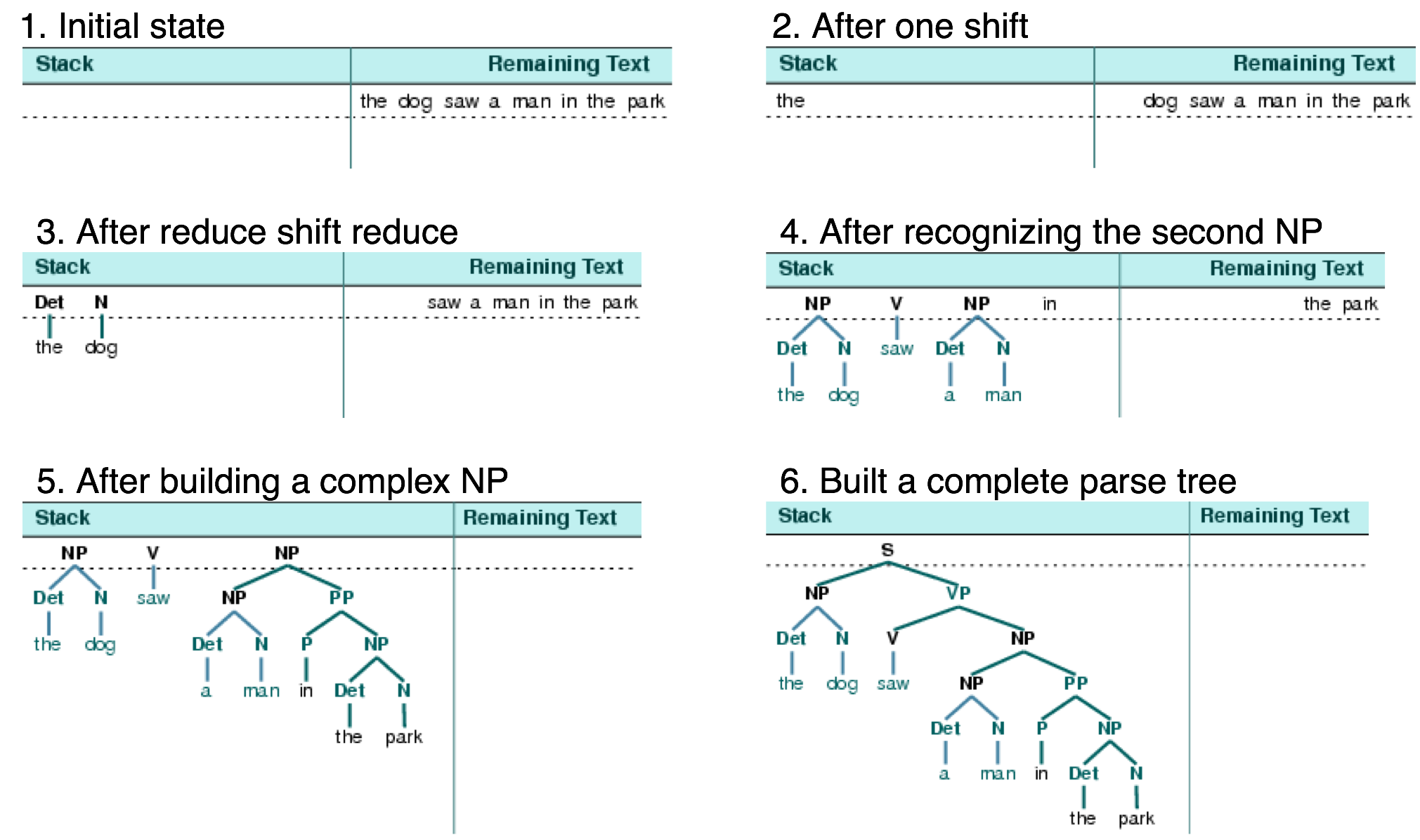
Рисунок 4.2: Шесть этапов Анализатора помещения-сокращения: анализатор начинает путем помещения первого входного слова в свой стек; как только верхние элементы в стеке соответствуют правой стороне грамматического продуцирования, они могут быть заменены левой стороной того же продуцирования; синтаксический анализатор успешно завершает свою работу, как только весь вход потреблен и один элемент S остается в стеке.
NLTK предоставляет ShiftReduceParser(), простую реализацию анализатора помещения-сокращения. Этот анализатор не выполняет каких-либо откатов, так что нахождение разбора текста, даже если таковой существует, не гарантируется. Кроме того, он найдет не более одного разбора, даже если существует большее количество разборов. Мы можем предоставить дополнительный параметр trace, который управляет тем, как пространно анализатор сообщает о своих шагах, которые он препринимает в процессе разбора текста:
|
Замечание
Ваша Очередь: Запустите вышеупомянутый анализатор в режиме трассировки, чтобы увидеть последовательность операций помещения и сокращения с помощью sr_parse = NLTK.ShiftReduceParser(grammar1, trace = 2)
Анализатор помещения-сокращения может зайти в тупик и не найти ни одного разбора, даже если входное предложение хорошо сформировано в соответствии с грамматикой. Когда это происходит, весь вход потреблен, а стек содержит элементы, которые не могут быть сокращены до S. Проблема возникает, потому что выбор, сделанный им ранее, не может быть отменен (хотя пользователи графической демонстрации могут отменить свои решения). Есть два вида решений, которые будут приняты анализатором: (а) какое сокращение сделать, когда более чем одно возможно (б) следует ли поместить или сократить, когда оба действия возможны.
Анализатор помещения-сокращения может быть расширен для реализации политики разрешения подобных конфликтов. Например, такая политика может пытаться разрешить конфликты между помещением и сокращением, помещая только тогда, когда никакие сокращения невозможны, и она может пытаться решить конфликты между сокращениями выбором в пользу операции сокращения, которая удаляет самое большое число элементов из стека. (Обобщение анализатора помещения-сокращения, "смотрящий вперед LR-анализатор", обычно используется в компиляторах языков программирования.)
Преимущество анализаторов помещения-сокращения над рекурсивно спускающимися анализаторами заключается в том, что они строят только структуру, которая соответствует словам на входе. Кроме того, они строят каждую подструктуру только один раз, например NP(Det(the), N(man)) строится и помещается в стек только в один раз, независимо от того, будет ли он позже использоваться сокращением VP -> V NP PP или сокращением NP -> NP PP.
4.3 Анализатор левого угла
Одна из проблем, связанных с рекурсивно спускающимся анализатором, заключается в том, что он уходит в бесконечный цикл, когда сталкивается с левосторонней рекурсией продуцирования. Это происходит потому, что он применяет грамматические продуцирования вслепую, без учета фактического входного предложения. Левоугольный анализатор представляет собой гибрид между подходами снизу вверх и сверху вниз, которые мы видели.
Грамматика grammar1 позволяет нам производить следующий разбор John saw Mary:
| (11) | 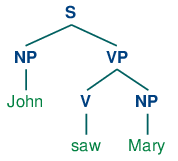 |
Напомним, что грамматика (определенная в 3.3) имеет следующие продуцирования для расширения NP:
| (12) |
|
Предположим, мы просим вас сначала посмотреть на дерево (11), а затем решить, какую из NP подстановок (продуцирований) вы хотите, чтобы метод рекурсивного спуска применил первой - очевидно, (12с) является правильным выбором! Откуда вы знаете, что было бы бессмысленно применять сначала (12a) или (12b)? Потому что ни одна из этих двух подстановок (продуцирований) не выведет последовательность, первое слово которой John. То есть, мы можем легко сказать, что в успешном разборе предложения John saw Mary анализатор должен расширить NP таким образом, чтобы NP давала последовательность John α. В более общем плане мы говорим, что категория B является левым углом дерева с корнем в А , если A ⇒ *B α.
| (13) |  |
Левоугольный анализатор - это анализатор сверху вниз с фильтрацией снизу вверх. В отличие от обычного метод рекурсивного спуска, он не попадает в ловушку в левой рекурсии подстановки. Перед началом своей работы, левоугольный анализатор выполняет предварительную обработку контекстно свободной грамматики для построения таблицы, где каждая строка содержит две ячейки, первая содержит неконечную, а вторая содержит набор возможных левых углов неконечной (подстановки?). Таблица 4.1 иллюстрирует это для грамматики из grammar2.
| Категория | Левые углы (предварительные конечные) |
|---|---|
| S | NP |
| NP | Det, PropN |
| VP | V |
| PP | P | Таблица 4.1: Левые углы в grammar2 |
Каждый раз, когда подстановка рассматривается анализатором, он проверяет, что следующее входное слово совместимо, по меньшей мере, с одной из предварительных конечных категорий в левоугольной таблице.
4.4 Таблица хорошо сформированных подстрок
Простые анализаторы, рассмотренные выше, страдают от ограничений как полноты, так и эффективности. Для того чтобы исправить это, мы будем применять для проектирования алгоритма синтаксического анализа технику динамического программирования. Как мы видели в 4.7, динамическое программирование храниит промежуточные результаты и повторно использует их при необходимости, добиваясь значительного повышения эффективности. Этот метод может быть применен к синтаксическому разбору, позволяя нам хранить частичные решения задачи синтаксического анализа, а затем находить их по мере необходимости для того, чтобы эффективно прийти к полному решению. Такой подход к разбору известен как табличный (графический-?) синтаксический анализ. Мы познакомим вас с основной идеей в этом разделе; обратитесь к онлайн материалам для этой главы для получения более подробной информации о реализации.
Динамическое программирование позволяет строить PP in my pajamas только один раз. Первый раз, когда мы создаем его, мы сохраняем его в таблице, затем мы находим его, когда мы должны использовать его в качестве подкомпонента либо объекта NP или более высокого уровня VP. Эта таблица известна как таблица хорошо сформированных подстрок или ТХСП (WFST) для краткости. (Термин "подстроки" относится к непрерывной последовательности слов в предложении.) Мы покажем, как построить WFST снизу вверх так, чтобы систематически записывать, какие синтаксические компоненты были найдены.
Давайте используем в качестве нашего входа предложении из (2). Численно указанные пролеты WFST напоминают срез как нотацию языка Python (3.2). Еще один способ думать о структуре данных, показанной на 4.3, - это структура данных, известная как график.

Рисунок 4.3: Диаграмма структуры данных: слова являются метками ребер линейной графической структуры.
В WFST мы фиксируем положение слов путем заполнения ячеек треугольной матрицы: вертикальная ось будет обозначать начальную позицию подстроки, а горизонтальная ось будет обозначать конечное положение (таким образом shot будет отображаться в ячейке с координатами (1, 2)). Для упрощения этого изложения мы будем считать, что каждое слово имеет уникальную лексическую категорию, и мы будем хранить ее (а не слово) в матрице. Таким образом, клетка (1, 2) будет содержать запись V. В более общем плане, если наша входная строка является a0a1 ... an и наша грамматика содержит подстановку вида A → ai, тогда мы добавляем A в ячейку (i, `i`+1).
Таким образом, для каждого слова в text, мы можем найти в нашей грамматике, к какой категории оно принадлежит.
|
Для нашего WFST мы создаем матрицу (n-1)×(n-1) в виде списка списков Python и заполняем его лексическими категориями каждого токена в функции init_wfst() в 4.4. Мы также определяем утилитарную функцию display() для отображения WFST в удобном для нас виде. Как и следовало ожидать, в ячейке (1, 2) находится V.
| ||
Пример 4.4 (code_wfst.py): Рисунок 4.4: Акцептор, использующий таблицу хорошо сформированных подстрок |
Возвращаясь к нашему табличному представлению, учитывая, что мы имеем Det в ячейке (2, 3) для слова an и N в ячейке (3, 4) для слова elephant, что мы должны поместить в ячейку (2, 4) для elephant? Нам нужно найти подстановку вида A → Det N. Уточнив по грамматике, мы узнаем, что мы можем ввести NP в ячейке (2, 4).
В более общем плане, мы можем ввести A в ячейку (i, j), если есть подстановка A → B C, и мы находим неконечное B в (i, k) и C в (k, j). Программа в 4.4 использует это правило для заполнения WFST. Установив значение trace - True при вызове функции complete_wfst(), мы видим вывод трассировки, который показывает, как WFST строится:
|
Например, это говорит о том, что, поскольку мы нашли Det в wfst[2][3] и N в wfst[3][4], мы можем добавить NP к wfst[2][4].
Замечание
Чтобы помочь нам легко получать постановки по их правым частям, мы создаем индекс для грамматики. Это пример пространственно-временного компромисса: мы делаем обратный поиск по грамматике, вместо того, чтобы проверять весь список подстановок каждый раз, когда мы хотим найти по правой стороне.
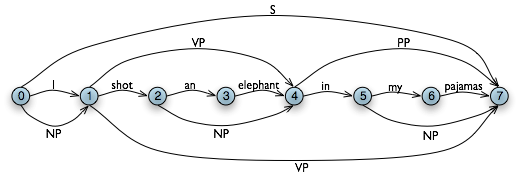
Рисунок 4.5: Графическая структура данных: неконечные представлены как дополнительные ребра на графике.
Мы приходим к выводу, что для синтаксического анализа входной строки существует разбор, раз мы построили узел S в ячейке (0, 7), показывающий, что мы нашли предложение, которое охватывает весь вход. Конечное состояние WFST изображено на 4.5.
Обратите внимание на то, что мы не использовали каких-либо встроенных функций синтаксического анализа здесь. Мы реализовали полный примитивный графический анализатор с нуля!
WFST имеют несколько недостатков. Во-первых, как вы можете видеть, WFST не является сама по себе деревом разбора, поэтому метод, строго говоря, распознает, что предложение признается грамматикой, а не разбирает его. Во- вторых, она требует, чтобы каждая нелексическая подстановка грамматики была бинарной. Несмотря на то, что можно преобразовать произвольную CFG в эту форму, мы предпочли бы использовать подход без такого требования. В-третьих, как подход снизу вверх она потенциально расточительна, будучи в состоянии предложить конституенты в тех местах, которые бы не были признаны грамматикой.
И, наконец, WFST не представляет структурную неоднозначность в предложении (то есть два прочтения глагольной фразы). VP в ячейке (1, 7) была фактически введена дважды, один раз для прочтения V NP и один раз для прочтения VP PP. Это разные гипотезы, а вторая переписала первую (как оказалось, это не имело значения, так как левая часть была такой же.) Графические анализаторы используют немного более богатую структуру данных и некоторые интересные алгоритмы для решения этих проблем (обратитесь к разделу Дополнительные материалы в конце этой главы для получения подробностей).
Замечание
Ваша очередь: Попробуйте интерактивное приложение графический анализатор nltk.app.chartparser().
5 Зависимости и грамматика зависимостей
Грамматика фразовой структуры занимается тем, как слова и последовательности слов объединяются, чтобы сформировать конституенты. Отличный и взаимодополняющий подход, грамматика зависимости, фокусирует внимание на том, как слова соотносятся с другими словами. Зависимость - это бинарное асимметричное отношение, которое имеет место между главой и его зависимыми. Главой предложения обычно выбирается глагол в определенном времени, и все остальные слова либо зависят от главы предложения, либо соединяются с ним через путь зависимостей.
Представлением зависимости является размеченный направленный граф, в котором узлы являются лексическими единицами и помеченые дуги представляют отношения зависимости между главами и зависимыми. Рисунок 5.1 иллюстрирует график зависимости, где стрелки указывают от глав к их зависимым.
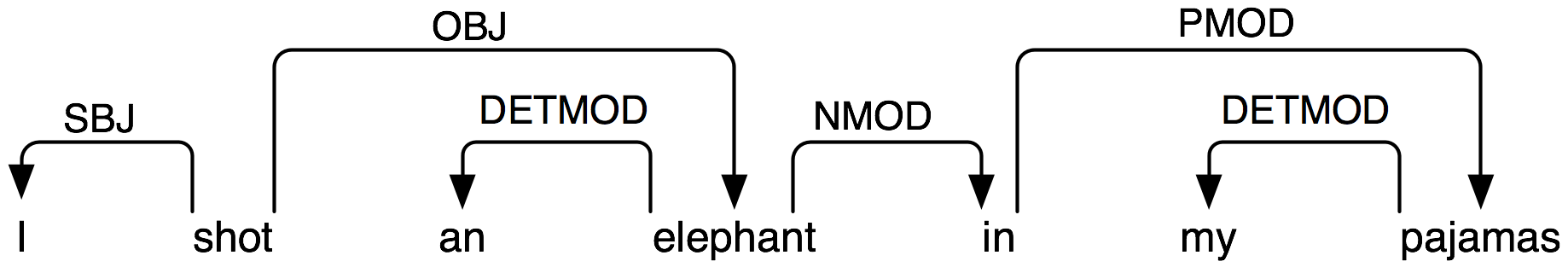
Рисунок 5.1: Структура зависимости: стрелки указывают от глав к их зависимым; метки указывают на грамматическую функцию зависимого как субъекта, объекта или модификатора.
Дуги на Рисунке 5.1 помечены грамматической функцией, которая имеет место между зависимым и его главой. Например, I - это SBJ (субъект) слова shot (которое является главой всего предложения), а in - это NMOD (модификатор существительного) для слова elephant. В отличие от грамматики фразовой структуры, следовательно, грамматики зависимостей могут быть использованы для прямого выражения грамматических функций как типа зависимости.
Вот один из способов кодирования грамматики зависимостей в NLTK - обратите внимание, что она фиксирует только голую информацию о зависимостях без указания типа зависимости:
|
График зависимости является проективным "если", когда все слова написаны в линейном порядке, ребра могут быть нарисованы выше слов без пересечения. Это равносильно тому, что слово и все его потомки (зависимые и зависимые их зависимых и т.д.) образуют непрерывную последовательность слов в пределах предложения. График на Рисунке 5.1 проективный, и мы можем разобрать много предложений на английском языке с использованием проективного анализатора зависимостей. В следующем примере показано, как groucho_dep_grammar обеспечивает альтернативный подход к схватыванию двусмысленности приложения, которую мы рассмотрели ранее с грамматикой фразовой структуры.
|
Эти заключенные в квадратные скобки структуры зависимостей также могут отображаться в виде деревьев, где зависимые показаны как дети их глав.
| (14) | 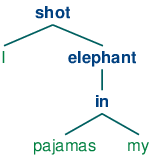 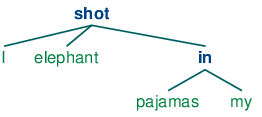 |
В языках с более гибким порядком слов, чем в английском, не проективные зависимости более частотны.
Различные критерии были предложены для принятия решения о том, что является главой H и что является зависимым D в конструкции C. Вот несколько наиболее важных из них:
- H определяет класс распределения C; или иначе внешние синтаксические свойства C обусловлены Н.
- H определяет семантический тип C.
- H является обязательным, в то время как D может быть необязательным.
- H выбирает D и определяет, является ли он обязательным или необязательным.
- Морфологическая форма D определяется H (например, agreement or casr government).
Когда мы говорим в грамматике фразовой структуры, что непосредственными составляющими PP являются P и NP, мы неявно используем различие между главой и зависимым. Предложной фраза это фраза, главой которой является предлог; более того, NP является зависимым от Р. То же самое различие распространяется на другие типы фраз, которые мы обсуждали. Ключевым моментом, который необходимо здесь отметить, является то, что, хотя грамматики фразовой структуры кажутся отличными от грамматик зависимостей, они неявно заключают в себе распознание отношений зависимости. В то время как CFGs не предназначены для непосредственного схватывания зависимостей, более поздние языковые концепции все чаще применяют формализмы, которые сочетают в себе аспекты обоих подходов.
5.1 Валентность и лексикон
Давайте подробнее рассмотрим глаголы и их зависимые. Грамматика в 3.3 правильно генерирует примеры, как (15d).
| (15) |
|
Эти возможности соответствуют следующим подстановкам:
| VP -> V Adj | was |
| VP -> V NP | saw |
| VP -> VS | thought |
| VP -> V NP PP | put | Таблица 5.1: VP подстановки и их лексические главы |
То есть, was может возникнуть с последующим Adj, saw может возникнуть со последующим NP, thought может возникнуть со следующим S, а put может возникнуть с последующим NP и PP.Зависимые Adj, NP, PP и S часто называют дополнениями соответствующих глаголов, при этом существуют серьезные ограничения на то, какие глаголы могут возникнуть с какими дополнениями. В отличие от (15d), последовательности слов в (16d) плохо сформированы:
| (16) |
|
Замечание
Использовав немного воображения, можно придумать условия, в которых необычные сочетания глаголов и дополнений являются интерпретируемыми. Однако мы предполагаем, что приведенные выше примеры должны интерпретироваться в нейтральных контекстах.
В традиции грамматики зависимостей, говорят, что глаголы в 5.1 имеют разные валентности. Ограничения валентности не только применимы к глаголам, но также и к другим классам глав.
В рамках концепций на основе грамматики фразовой структуры, различные методы были предложены для исключения неграмматических примеров в (16d). В CFG нам нужен какой-то способ ограничения подстановок грамматики, которые расширяют VP так, чтобы глаголы возникали только с правильными дополнениями. Мы можем сделать это путем деления класса глаголов на "подкатегории", каждая из которых связана с другим набором дополнений. Например, переходные глаголы, такие как chases и saw требуют следующего за ними NP объекта в качестве дополнения; то есть, они подразделены на глаголы, требующие прямых объектов NP. Если мы введем новую метку категории для переходных глаголов, а именно: TV (для переходного глагола (Transitive Verb)), то мы можем использовать ее в следующих подстановках:
VP -> TV NP TV -> 'chased' | 'saw'
Теперь предложение *Joe thought the bear будет исключено , так как мы не включили thought как TV, но Chatterer saw the bear по-прежнему разрешено. 5.2 предоставляет дополнительные примеры меток для глагольных подкатегорий.
| Обозначения | Значение | Пример |
|---|---|---|
| IV | непереходный глагол | barked |
| TV | переходный глагол | saw a man |
| DatV | датив глагол | gave a dog to a man |
| SV | сентенциальный глагол | said that a dog barked | Таблица 5.2: Подкатегории глагола |
Валентность является свойством лексических единиц, и мы будем обсуждать ее дальше в 9. .
Дополненния часто противопоставляется модификаторам (or adjuncts?), хотя оба являются видами зависимого. Предложные фразы, прилагательные и наречия, как правило, функционируют в качестве модификаторов. В отличие от дополнений, модификаторы не являются обязательными, часто могут повторяться, и не выбираются главами таким же образом, как дополнения. Например, наречие really может быть добавлено в качестве модификатора ко всему предложению в (17d):
| (17) |
|
Структурная неоднозначность приложения PP, которую мы проиллюстрировали как в грамматике фразовой структуры, так и в грамматике зависимостей, соответствует семантически неоднозначности охвата модификатора.
5.2 Расширение масштаба
До сих пор мы рассматривали только "игрушечные грамматики", маленькие грамматики, которые иллюстрируют ключевые аспекты синтаксического анализа. Но встает очевидный вопрос, может ли подход быть расширены, чтобы покрыть большие корпусы естественных языков. Как трудно было бы построить такой набор подстановок вручную? В целом ответ такой: очень трудно. Даже если мы позволим себе использовать различные формальные устройства, которые дают гораздо более емкие представления подстановок грамматики, все равно чрезвычайно трудно держать под контролем сложные взаимодействия между многими подстановками необходимыми для покрытия основных конструкций языка. Другими словами, трудно построить грамматику модульно, чтобы одну ее часть можно было разрабатывать независимо от других ее частей. Это, в свою очередь, означает, что трудно распределить задачу написания грамматики на команду лингвистов. Другая трудность состоит в том, что по мере того, как грамматика расширяется, чтобы охватить все более широкий диапазон конструкций, увеличивается число разборов, которые допускаются для одного предложения. Другими словами, неопределенность возрастает с увеличением охвата.
Несмотря на эти проблемы, некоторые крупные совместные проекты достигли интересных и впечатляющих результатов в разработке грамматик на основе правил для нескольких языков. Примерами являются проекты Lexical Functional Grammar (LFG) Pargram, Head-Driven Phrase Structure Grammar (HPSG) LinGO Matrix и Lexicalized Tree Adjoining Grammar XTAG.
6 Разработка грамматики
Синтаксический анализ строит деревья для предложений в соответствии с грамматикой фразовой структуры. Сейчас все примеры, которые мы привели выше, использовали только игрушечные грамматики, содержащие несколько подстановок. Что произойдет, если мы попытаемся расширить масштабы этого подхода для работы с более реалистичными корпусами языка? В этом разделе мы увидим, как получить доступ к банкам деревьев, и рассмотрим на задачу разработки грамматик широкого охвата.
6.1 Банки деревьев и грамматики
Модуль corpus определяет ридер корпуса treebank, который содержит 10% образец корпуса Penn Treebank.
|
Мы можем использовать эти данные, чтобы помочь нам в разработке грамматики. Например, программа в листинге 6.1 использует простой фильтр, чтобы найти глаголы, которые принимают сентенциальные дополнения. Предполагая, что у нас уже есть подстановка вида VP -> Vs S, эта информация позволяет идентифицировать конкретные глаголы, которые будут включены в расширение Vs.
| ||
| ||
Пример 6.1 (code_sentential_complement.py): Рисунок 6.1: Поиск в корпусе Treebank сентенциальных дополнений |
Корпус Prepositional Phrase Attachment, nltk.corpus.ppattach, является еще одним источником информации о валентности конкретных глаголов. Здесь мы иллюстрируем технику для копания этого корпуса. Она находит пары предложных фраз, где предлог и существительное являются фиксированными, но где выбор глагола определяет, прилагается ли предложная фраза к VP или к NP.
|
Среди выходных строк этой программы мы находим offer-from-group N: [ 'rejected'] V: ['received'], что свидетельствует о том, что received ожидает отдельное PP дополнение, прикрепленное к VP, в то время как rejected нет. Как и раньше, мы можем использовать эту информацию, чтобы помочь нам построить грамматику.
Коллекция NLTK включает в себя данные из распределенных задач: PE08 Cross-Framework и Cross Domain Parser Evaluation. Коллекция больших грамматик была подготовлена с целью сравнения различных анализаторов, которые могут быть получены путем загрузки пакета large_grammars (например, python -m nltk.downloader large_grammars).
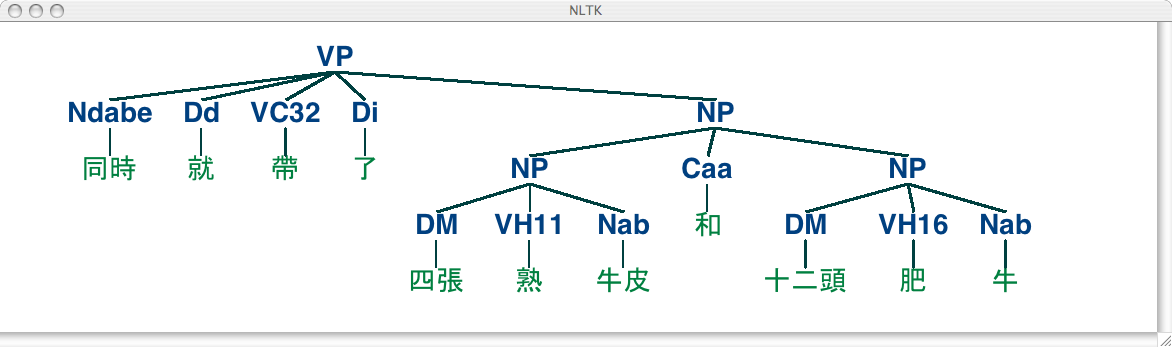
Коллекция корпусов NLTK также включает в себя образец из Sinica Treebank Corpus, состоящий из 10.000 разобранных предложений, взятых из Academia Sinica Balanced Corpus of Modern Chinese. Давайте загрузим и отобразим одно из деревьев в этом корпусе.
|
6.2 Гибельная неоднозначность
К сожалению, по мере того, как охват грамматики увеличивается и длина входных фраз растет, количество деревьев разбора быстро растет. На самом деле, оно растет с астрономической скоростью.
Давайте исследуем этот вопрос с помощью простого примера. Слово fish является как существительным, так и глаголом. Мы можем составить предложение fish fish fish, означающее fish like to fish other fish. (Попробуйте это со словом police, если вы предпочитаете что-то более осмысленное.) Вот игрушечная грамматика для "fish" предложений.
|
Теперь мы можем попробовать разобрать более длинную фразу, fish fish fish fish fish, которая помимо всего прочего, означает "fish that other fish fish are in the habit of fishing fish themselves". Мы используем графический парсер NLTK, о котором упоминалось ранее в этой главе. Это предложение имеет два чтения.
|
По мере того, как длина этого предложения идет вверх (3, 5, 7, ...) мы получаем следующие количества деревьев разбора: 1; 2; 5; 14; 42; 132; 429; 1.430; 4.862; 16.796; 58.786; 208.012; ... (Это Числа Катала́на, которые мы видели в одном из упражнений в 4). Последнее из них для предложения длиной в 23 слова, что соответствует средней длине предложений в разделе WSJ корпуса Penn Treebank. Для предложения длиной в 50 слов было бы более 1012 разборов, а это только половина длины предложения Пяточка (1), которое маленькие дети понимают без усилий. Ни одна практическая НЛП система не может построить миллионы деревьев для предложения и выбрать подходяще в заданном контексте. Понятно, что люди также не делают этого!
Обратите внимание, что проблема не связана с нашим выбором примера. (Church & Патил, 1982) указывают, что синтаксическая двусмысленность прикрепления PP в предложениях, как (18), также растет в пропорции чисел Каталана.
| (18) | Поместите блок в коробку на столе. |
Так много проблем для структурной неопределенности; а что насчет лексической неоднозначности? Как только мы пытаемся построить грамматику с широким охватом, мы вынуждены сделать лексические записи в высокой степени неоднозначными с точки зрения их части речи. В игрушечной грамматике, a является только определителем, dog только существительным, а runs только глаголом. Тем не менее, в грамматике с широким охватом, a является также существительным (например, part а), dog является также глаголом (означающим следовать близко) и runs также является существительным (например, ski runs). На самом деле, со всеми словами можно установить связь как с именем: например, the verb 'ate' is spelled with three letters; в речи мы не должны ставить кавычки. Кроме того, можно превратить в глагол (to verb) большинство существительных. Поэтому синтаксический анализатор для грамматики с широким охватом будет завален двусмысленностями. Даже полная тарабарщина часто имеет прочтение, например, the a are of I. Как (Klavans & Resnik, 1996) указали, это не салат из слов, но грамматическая именная фраза, в которой are - это существительное, означающее сотую долю гектара (или 100 кв. м), а a и I существительные, обозначающие координаты, как показано на Рисунке 6.2.
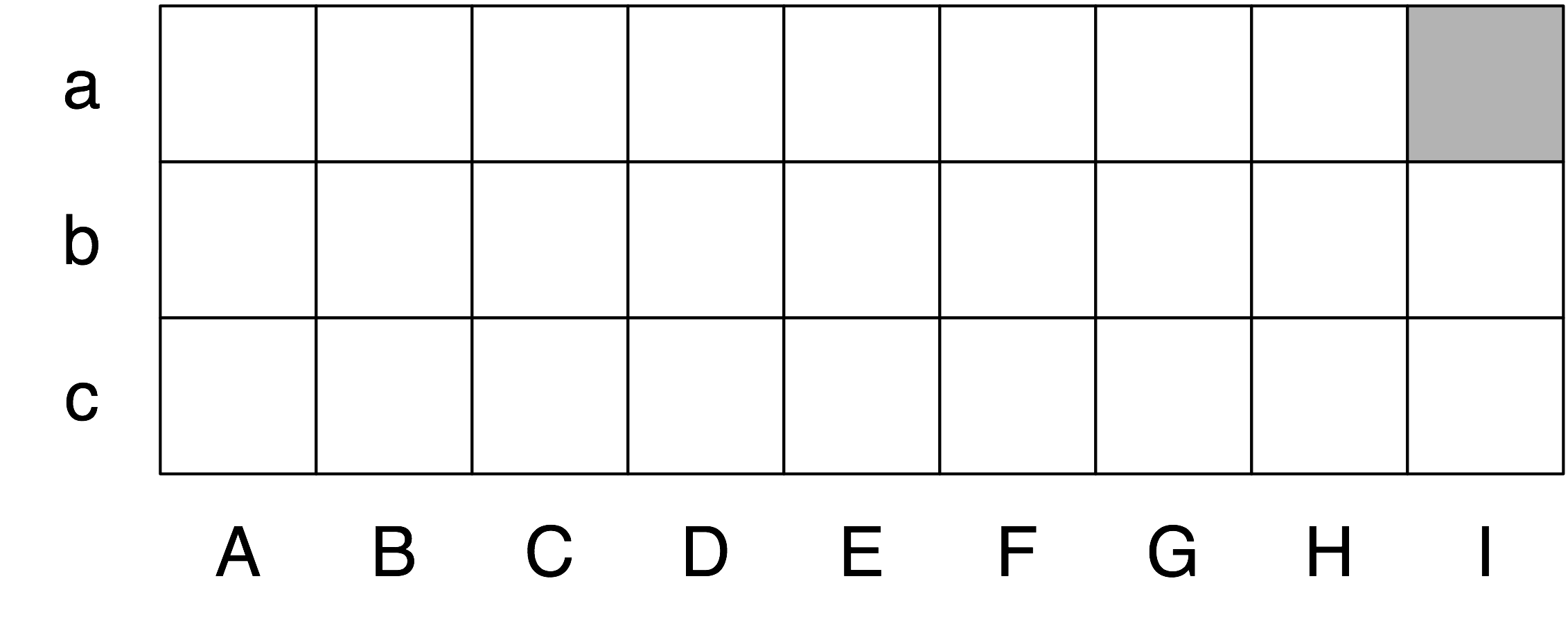
Рисунок 6.2: "The a are of II": схематический чертеж 27 загонов, каждый из которых размером в один "ар" и каждый из которых определяется с помощью координат; верхняя левая ячейка - это а "ар" колонки I (вслед за Abney).
Даже если эта фраза мало вероятна, она все равно грамматична и синтаксический анализатор широкого охвата должен быть в состоянии построить дерево разбора для нее. Аналогичным образом, предложения, которые кажутся однозначными, такие как John saw Mary, оказывается, имеют другие прочтения, которые мы не предвидели (как объясняет Abney). Эта неоднозначность неизбежна и приводит к ужасающей неэффективности при разборе, казалось бы, безобидных предложений. Решение этих задач обеспечивается с помощью вероятностного синтаксического анализа, который позволяет ранжировать разборы неоднозначного предложения на основе данных из корпусов.
6.3 Взвешенная Грамматика
Как мы только что видели, работа с неоднозначностью является ключевой задачей при разработке анализаторов широкого охвата. Графические анализаторы повышают эффективность вычислений нескольких разборов одних и тех же предложений, но они по-прежнему перегружены огромным числом возможных разборов. Взвешенные грамматики и вероятностные алгоритмы синтаксического анализа обеспечили эффективное решение этих проблем.
Перед их рассмотрением, мы должны понять, почему понятие грамматичности может быть градиентным. Рассмотрим глагол give. Этот глагол требует как прямой объект (вещь, которая отдается) и косвенный объект (получатель). Эти дополнения могут быть заданы в любом порядке, как показано в (19). В "предложной дательной" в форме (19а), прямой объект появляется первым, за которым следует предложная фраза, содержащая косвенный объект.
| (19) |
|
В форме "двойного объекта" в(19b) косвенный объект появляется первым, за которым следует прямой объект. В приведенном выше случае любой порядок приемлем. Тем не менее, если косвенный объект является местоимением, есть сильное предпочтение для конструкции с двойным объектом:
| (20) |
|
Используя образец корпуса Penn Treebank, мы можем рассмотреть все экземпляры конструкций с предложным дательным и двойным объектом, включающих give, как показано на Рисунке 6.3.
| ||
| ||
Пример 6.3 (code_give.py): Рисунок 6.3: Использование Give и Gave в образце корпуса Penn Treebank |
Мы можем видеть сильную тенденцию более короткого дополнения стоять первым. Тем не менее, это не учитывает форму, как give NP: federal judges / NP: a raise, где одушевленность может играть определенную роль. На самом деле, там может оказаться большое количество факторов, как показано в работе (Bresnan & Hay, 2006). Такие предпочтения могут быть представлены во взвешенной грамматике.
Вероятностная безконтекстная грамматика (или PCFG) является безконтекстной грамматикой, которая связывает вероятность с каждой из своих подстановок. Она генерирует тот же набор разборов для текста, что и соответствующая безконтекстная грамматика, но присваивает вероятность каждому синтаксическому разбору. Вероятность синтаксического разбора, порожденного PCFG, является просто произведением вероятностей подстановок, использованных для его генерации.
Самый простой способ определить PCFG - загрузить ее из специально отформатированной строки, состоящей из последовательности взвешенных подстановок, где веса указаны в скобках, как показано в листинге 6.4.
| ||
| ||
Пример 6.4 (code_pcfg1.py): Листинг 6.4: Определение вероятностной безконтекстной грамматики (PCFG) |
Иногда удобно объединить несколько подстановок в одну строку, например, VP -> TV NP [0.4] | IV [0.3] | DatV NP NP [0.3]. Для того, чтобы гарантировать, что деревья, порождаемые грамматикой образуют распределение вероятностей, PCFG грамматики накладывают ограничение, что все подстановки с заданной левой стороной должны иметь сумму вероятностей равную 1. Грамматика в 6.4 соответствует этому ограничению: для S есть только одна подстановка с вероятностью 1,0; для VP 0,3 + 0,4 + 0,3 = 1,0; и для NP 0,8 + 0,2 = 1,0. Дерево синтаксического разбора, возвращаемое методом parse() включает в себя вероятности:
|
Теперь, когда деревьям разбора присвоены вероятности, уже не важно, что может быть огромное количество возможных разборов для данного предложения. Анализатор будет нести ответственность за нахождение наиболее вероятных разборов.
8 Резюме
- Предложения имеют внутреннюю организацию, которая может быть представлена с помощью дерева. Основными свойствами конституентной структуры являются: рекурсия, главы, дополнения и модификаторы.
- Грамматика представляет собой компактную характеристику потенциально бесконечного множества предложений; мы говорим, что дерево хорошо сформировано в соответствии с грамматикой, или что грамматика лицензирует (допускает) данное дерево.
- Грамматика - это формальная модель для описания того, может ли данной фразе быть присвоен отдельный конституент или структура зависимости.
- Учитывая набор синтаксических категорий, безконтекстная грамматика использует набор подстановок, чтобы сказать, как фраза некоторой категории А может быть разобрана на последовательность меньших частей α1 ... αn.
- Грамматика зависимости использует подстановки для спецификации зависимых данной лексической главы.
- Синтаксическая неоднозначность возникает, когда одно предложение имеет более одного синтаксического разбора (например, неоднозначность приложения предложной фразы).
- Анализатор представляет собой процедуру для нахождения одного или нескольких деревьев, соответствующих грамматически хорошо сформированным предложениям.
- Простой анализатор сверху вниз - рекурсивно спускающийся анализатор, который рекурсивно расширяет начальный символ (обычно S) с помощью подстановок грамматики и пытается найти соответствие входному предложению. Этот анализатор не может справиться с леворекурсивными подстановками (например, такими подстановками, как NP -> NP PP). Он неэффективен в том, что слепо расширяет категории без проверки, являются ли они совместимыми с входной строкой, и в том, что многократно расширяет одни и те же нетерминалы и в том, что отбрасывает результаты.
- Простой анализатор снизу вверх - анализатор помещения-смещения, который перемещает ввод в стек и пытается сопоставить элементы в верхней части стека с правой стороной грамматических подстановок. Этот анализатор не гарантирует нахождение правильного разбора для ввода, даже если таковой существует и строит подструктуру без проверки того, является ли она глобально совместимой с грамматикой.
7 Дополнительные материалы
Дополнительные материалы для этой главы размещены на странице http://nltk.org/, в том числе ссылки на свободно доступные ресурсы в сети. Для получения большего количества примеров разбора с помощью NLTK, обратитесь к HOWTO по разбору на http://nltk.org/howto.
Есть много вводных книг по синтаксису. (O'Grady et al, 2004) представляет собой общее введение в языкознание, в то время как (Radford, 1988) обеспечивает введение в трансформационную грамматику и может быть рекомендована за ее охват трансформационных подходов к неограниченным конструкциям зависимостей. Наиболее широко используемый термин в лингвистике для формальной грамматики - это порождающая (генеративная) грамматика, хотя она не имеет ничего общего с поколением (Chomsky, 1965). Концепция X-bar синтаксиса введена в работе (Jacobs & Rosenbaum, 1970), исследована более подробно в (Jackendoff, 1977) (простые числа, которые мы используем, заменяют типографски более сложные горизонтальные полосы Хомского.)
(Burton-Roberts, 1997) является практически ориентированным учебником о том, как анализировать конституенцию в английском языке, с обширным примерами и упражнениями. (Hiddleston & Pullum, 2002) предоставляет современный и всесторонний анализ синтаксических явлений в английском языке.
Глава 12 (Jurafsky & Martin, 2008) охватывает формальные грамматики английского языка; Разделы 13.1-3 охватывают простые алгоритмы синтаксического анализа и методов борьбы с неоднозначностью; Глава 14 охватывает статистический разбор; Глава 16 охватывает иерархию Chomsky и формальную сложность естественного языка. (Levin, 1993) классифицировал английские глаголы на мелкие классы в соответствии с их синтаксическими свойствами.
Есть несколько действующий проектов по созданию крупномасштабных основанных на правилах грамматик, например, проекты LFG Pargram http://www2.parc.com/istl/groups/nltt/pargram//0}, HPSG LinGO Matrix http:// www.delph-in.net/matrix/ и XTAG http://www.cis.upenn.edu/~xtag/.
9 Упражнения
☼ Можете ли вы придумать с грамматическими предложениями, которые, вероятно, никогда не были произнесены раньше? (Сменяйтесь с партнером.) Что это говорит вам о человеческом языке?
☼ Напомним Strunk и запрет белых против предложения-первоначального однако используется для обозначения "хотя". У веб - поиска для однако используется в начале предложения. Как широко используется эта конструкция?
☼ Рассмотрим предложение Ким прибывшего или Дана налево и все повеселел. Запишите введенными формы , чтобы показать относительный объем и и или. Создавать структуры дерева, соответствующие обоим из этих интерпретаций.
☼ Класс Дерево реализует множество других полезных методов. Обратитесь к документации Дерево справки для получения более подробной информации, то есть импортировать класс дерева , а затем ввести помощь (дерево).
☼ В этом упражнении вы будете вручную построить несколько деревьев разбора.
- Написать код , чтобы произвести два дерева, один для каждого чтения фразы стариков и женщин
- Кодировать любой из деревьев , представленных в этой главе в качестве меченого брекет и использовать NLTK.Дерево () , чтобы проверить , что он хорошо сформирован. Теперь с помощью дро () для отображения дерева.
- Как и в (а) выше, нарисовать дерево для женщины увидели человека в прошлый четверг.
☼ Написать рекурсивную функцию для обхода дерева и вернуть глубину дерева, таким образом, что дерево с одним узлом будет иметь глубину ноль. (Подсказка: глубина поддерева максимальная глубина его детей, плюс один.)
☼ Анализ А. А. Милна предложение о Пятачка, подчеркиванием всех предложений оно содержит то , заменяя их с S (например , первое предложение становится S , когда: lx` S). Нарисуйте структуру дерева для этого "сжатого" предложения. Каковы основные синтаксические конструкции, используемые для построения такой долгий срок?
☼ В метод рекурсивного спуска демо, эксперимент с изменением предложения , которое будет разобрано, выбрав Edit Text в меню Правка.
☼ Может грамматика в grammar1 быть использованы для описания предложений, которые более чем 20 слов в длину?
☼ Используйте графический интерфейс график-парсер, чтобы экспериментировать с различными стратегиями правила вызова. Придумайте с вашей собственной стратегии, которые можно выполнить вручную с помощью графического интерфейса. Опишите шаги, и сообщать о любых повышения эффективности она имеет (например, с точки зрения размера полученной диаграммы). эти улучшения зависят ли от структуры грамматики? Что вы думаете о перспективах значительных повышений производительности от стратегий Призывании лучшими, правила?
☼ С ручкой и бумагой, вручную отслеживать выполнение рекурсивного спуска парсер и сдвиг-свертка анализатор, для CFG вы уже видели, или один из ваших собственного изобретения.
☼ Мы видели, что блок-анализатор добавляет, но никогда не удаляет ребра из диаграммы. (Почему?)
☼ Рассмотрим последовательность слов: Буффало буйвола Buffalo буйвола буйвола буйвола буйвола буйвола. Это грамматически правильное предложение, как объяснено на http://en.wikipedia.org/wiki/Buffalo_buffalo_Buffalo_buffalo_buffalo_buffalo_Buffalo_buffalo. Рассмотрим дерево диаграмма, представленная на этой странице Википедии, и записать соответствующую грамматику. Нормализация дело в нижнем регистре, чтобы имитировать эту проблему, что слушатель, услышав это предложение. Можете ли вы найти другие разборов для этого предложения? Как количество деревьев разбора расти, поскольку предложение становится больше? (Другие примеры этих предложений можно найти на сайте http://en.wikipedia.org/wiki/List_of_homophonous_phrases).
◑ Вы можете модифицировать грамматику в метод рекурсивного спуска демо, выбрав Edit Грамматика в меню Правка. Заменить второе производство расширения, а именно NP -> Det N PP, НП -> NP PP. С помощью кнопки Step, попробуйте построить дерево разбора. Что происходит?
◑ Продлить грамматику в grammar2 с производств , которые расширяют предлоги как интранзитивной, переходные и требующие PP дополнения. На основе этих производств, использовать метод предыдущего упражнения , чтобы нарисовать дерево для предложения Ли сбежал домой.
◑ Выберите некоторые общие глаголы и выполнить следующие задачи:
- Напишите программу , чтобы найти эти глаголы в предложной Attachment Корпус nltk.corpus.ppattach. Найдите случаи , когда тот же глагол имеет два различных вложения, но где первое существительное, или второе существительное, или предлога, остаются неизменными (как мы видели в нашем обсуждении синтаксической неоднозначностью 2 ).
- Разрабатывают CFG грамматики производств для покрытия некоторых из этих случаев.
◑ Напишите программу для сравнения эффективности сверху вниз диаграммы синтаксического анализа по сравнению с метод рекурсивного спуска ( 4 ). Используйте те же грамматические и входные предложения для обоих. Сравните их производительность с помощью модуля timeit (см 4.7 для примера того , как сделать это).
◑ Сравните производительность сверху вниз, снизу вверх, а левой углу анализаторами, используя ту же грамматику и три грамматические тестовые предложения. Используйте timeit регистрировать количество времени каждый парсер принимает на том же самом предложении. Напишите функцию, которая выполняет все три парсеры на всех трех предложениях, и печатает 3 на 3 сетки раз, а также строк и столбцов итогов. Обсудите свои выводы.
◑ Читайте на "пути" сад предложений. Как может вычислительная работа синтаксического анализатора относятся к сложности у людей есть с обработкой этих предложений? http://en.wikipedia.org/wiki/Garden_path_sentence
◑ Для сравнения нескольких деревьев в одном окне, мы можем использовать () метод draw_trees. Определить некоторые деревья и попробовать его:
>>> От импорта nltk.draw.tree draw_trees >>> draw_trees (Дерево1, tree2, tree3)
◑ Используя позиции дерева, список субъектов первых 100 предложений в Treebank Penn; чтобы результаты легче просматривать, ограничить извлеченные объекты для поддеревьев, высота которых 2.
◑ Осмотрите предложной Attachment Корпус и попытаться предложить некоторые факторы, влияющие на присоединение PP.
◑ В этом разделе мы утверждали, что существуют языковые закономерности, которые не могут быть описаны просто в терминах п-грамм. Рассмотрим следующее предложение, в частности , положение фразы , в свою очередь. иллюстрировать ли это проблемы для подхода, основанного на п-г?
То, что было больше, то в свою очередь, несколько моложавый Николай Парфенович также оказался единственным человеком во всем мире, чтобы получить искреннюю симпатию к нашему "дискриминируемых" общественного прокурора. (Достоевский: Братья Карамазовы)
◑ Написать рекурсивную функцию, которая производит вложенную брэкетинг для дерева, в результате чего из узлов листа, и отображая нетерминальные этикетки после того, как их поддеревьев. Таким образом, приведенный выше пример о Pierre Vinken будет производить: [[[ННП ННП] NP, [ADJP [CD NNS] NP JJ] ADJP,] NP-SBJ MD [VB [DT NN] NP [IN [DT JJ NN] NP] PP-CLR [ННП CD] NP-TMP] VP.]S Последовательные категории должны быть разделены пробелом.
◑ Скачать несколько электронных книг из Проекта Гутенберг. Написать программу для сканирования этих текстов для любых экстремально длинных предложений. Что самое длинное предложение вы можете найти? Какие синтаксические конструкции (s) отвечают за такие длительные сроки?
◑ Измените функции init_wfst () и complete_wfst () , так что содержимое каждой ячейки в WFST представляет собой набор нетерминальных символов , а не один нетерминал.
◑ Рассмотрим алгоритм в 4.4 . Можете ли вы объяснить , почему разбора контекстно-свободной грамматики пропорциональна N 3, где п длина входного предложения.
◑ Преобразовать каждое дерево из Treebank корпуса образца nltk.corpus.treebank и извлечь производств с помощью Tree.productions (). Откажитесь от производств, которые происходят только один раз. Productions с той же левой стороны, и аналогичные правые могут быть свернуты, в результате чего в эквивалентной, но более компактный набор правил. Написать код для вывода компактную грамматику.
★ Один общий способ определения субъектом приговора S в английском языке в качестве словосочетанием , который является потомком S и родственный VP. Написать функцию, которая принимает дерево для предложения и возвращает поддерево, соответствующее предмету предложения. Что он должен делать , если корневой узел дерева , переданного этой функции не S, или ему не хватает предмета?
★ Написать функцию , которая принимает грамматику (например, ту , которая определена в 3.1 ) и возвращает случайное предложение , порожденную грамматики. (Используйте grammar.start () , чтобы найти начальный символ грамматики; grammar.productions (LHS) , чтобы получить список спектаклей из грамматики , которые имеют указанную с левой стороны, и production.rhs () , чтобы получить право -hand сторона производства.)
★ реализовать версию рычага селектора уменьшить синтаксический анализатор с использованием откаты, так что она находит все возможные разборы для предложения, что можно было бы назвать "рекурсивный подъем СА». Обратитесь статью в Википедии для возвратов в http://en.wikipedia.org/wiki/Backtracking
★ Как мы видели в 7. , можно свернуть куски вплоть до их куска этикетке. Когда мы делаем это для предложений с участием слово дал, мы находим образцы , такие как:
дал НП отказался НП в НП дал НП давала НП НП НП дал НП
- Используйте этот метод для изучения комплементации закономерности глагола интерес, и писать подходящие грамматические постановки. (Эта задача иногда называется лексическая приобретение.)
- Определить некоторые английские глаголы, которые почти-синонимы, такие как сбрасывали / заполненного / загруженном пример из ранее в этой главе. Используйте метод отрывов для изучения комплементационной образцы этих глаголов. Создание грамматики, чтобы покрыть эти случаи. Могут ли глаголы свободно замещать друг друга, или являются их ограничения? Обсудите свои выводы.
★ Разработка левого угла анализатор , основанный на метод рекурсивного спуска, и наследовать имущество ParseI.
★ Расширение NLTK смещать-свертка анализатор включать откаты, так что он гарантированно найти все разборы, которые существуют (т.е. полная).
★ Изменение функции init_wfst () и complete_wfst () , так что , когда нетерминального символ добавляется в ячейку в WFST, она включает в себя запись клеток , из которых она была получена. Реализовать функцию, которая будет конвертировать WFST в этой форме дерева разбора.
Об этом документе ...
Обновлялся для NLTK 3.0. Это глава из книги Обработка естественного языка с помощью Python написанной Стивеном Бердом , Эваном Клайном и Эдвардом Лопером , Copyright © 2014 авторов. Он распространяется с Набором инструментов для естественного языка [http://nltk.org/], версия 3.0 в соответствии с условиями Creative Commons Attribution-Noncommercial-No Derivative Works 3.0 Лицензии Соединенных Штатов [ http://creativecommons.org/licenses/by-nc-nd/3.0/us/].
Этот документ был построен на ср 1 июля 2015 12:30:05 AEST