3 Обработка исходного текста
Наиболее важным источником текстов, несомненно, является Сеть. Удобно иметь существующие текстовые коллекции для изучения, такие как своды, которые мы видели в предыдущих главах. Тем не менее, вы, вероятно, имеете в виду свои собственные источники текста, и вам нужно узнать, как получить к ним доступ.
Цель этой главы заключается в том, чтобы ответить на следующие вопросы:
- Как мы можем писать программы для доступа к тексту из локальных файлов и из сети для того, чтобы овладеть неограниченным рядом языкового материала?
- Как мы можем разделить документы на отдельные слова и символы пунктуации, чтобы мы могли выполнять те же виды анализа, которые мы выполняли с текстовыми корпусами в предыдущих главах?
- Как мы можем писать программы, чтобы получить форматированный текст и сохранить его в файле?
Для решения этих вопросов, мы будем рассматривать ключевые концепции NLP, в том числе токенизацию и стемминг. Параллельно вы будете консолидировать свои знания Python и узнаете о строках, файлах и регулярных выражениях. Поскольку так много текста в Интернете в формате HTML, мы также увидим, как освободить текст от разметки.
Замечание
Важно: Начиная с этой главы наши образцы программ будут предполагать, что вы начинаете интерактивный сеанс или программу со следующих предложений импорта:
|
3.1 Обращение к тексту в сети и на диске
Электронные книги
Небольшой образец текстов из Project Gutenberg есть в коллекции корпусов NLTK. Однако вы можете быть заинтересованы в анализе других текстов из Project Gutenberg. Вы можете просмотреть каталог 25.000 бесплатных онлайн книг на http://www.gutenberg.org/catalog/, и получить URL в ASCII текстовый файл. Хотя 90% текстов в Project Gutenberg на английском языке, он включает в себя материал на более чем 50 других языках, включая каталанский, китайский, голландский, финский, французский, немецкий, итальянский, португальский и испанский языки (с более чем 100 текстов на каждом).
Текст номер 2554 является английским переводом Преступления и наказания, и мы можем получить доступ к нему следующим образом.
|
Замечание
Выполнение read() займет несколько секунд, пока он загружает эту большую книгу. Если вы используете прокси, который не правильно определяется Python, вам может понадобиться указать прокси вручную перед использованием urlopen следующим образом:
|
Переменная raw содержит строку с 1.176.893 символами. (Мы можем увидеть, что это строка, используя type(raw).) Это необработанное содержание книги, включающее многие детали, в которых мы не заинтересованы, таких как пробелы, разрывы строк и пустые строки. Обратите внимание на \г и \n в открывающей строке файла, который представляет собой то, как Python отображает специальные символы возврата каретки и перевода строки (файл должно быть был создан на компьютере Windows). Для нашей обработки языка мы хотим разбить строку на слова и знаки препинания, как мы видели в 1.. Этот шаг называется токенизация, и она производит нашу знакомую структуру, список слов и знаков препинания.
|
Обратите внимание на то, что NLTK был необходим для токенизации, но не для какой-либо из предыдущих задач открытия URL и считывания ее в строку. Если мы теперь сделаем еще один шаг в создании текста NLTK из этого списка, мы можем выполнить всю другую лингвистическую обработку, которую мы видели в 1., наряду с регулярными списочными операциями, такими как слайсинг:
|
Обратите внимание на то, что Project Gutenberg выглядит как словосочетание. Это происходит потому, что каждый текст, загруженный из Project Gutenberg, содержит заголовок с названием текста, именем автора, именами людей, которые сканировали и исправили текст, лицензию и так далее. Иногда эта информация появляется в колонтитулах в конце файла. Мы не можем надежно обнаружить, где содержание начинается и заканчивается, и поэтому нам приходится прибегать к ручной проверке файла, чтобы обнаружить уникальные строки, которые отмечают начало и конец, до обрезки raw, чтобы в нем было только содержание и больше ничего:
|
Методы find() и rfind() ( "обратный поиск") помогают нам получить правильные значения индекса для слайсинга строки ![[1]](http://www.nltk.org/book/callouts/callout1.gif) .
Мы перезаписываем raw этой вырезкой, так что теперь он начинается с "Часть I" и идет до (но не включая) фразы, которая отмечает конец содержания.
.
Мы перезаписываем raw этой вырезкой, так что теперь он начинается с "Часть I" и идет до (но не включая) фразы, которая отмечает конец содержания.
Это была наша первая встреча с реальностью сети: тексты, найденные в сети, могут содержать нежелательный материал, а автоматического способа удалить его может не быть. Но с помощью небольшого количества дополнительной работы мы можем извлечь материал, который нам нужен.
Работа с HTML
Большая часть текста в Интернете находится в формате HTML-документов. Вы можете использовать веб-браузер, чтобы сохранить страницу в виде текста в локальный файл, а затем получить доступ к этому, как описано в разделе о файлах ниже. Тем не менее, если вы собираетесь делать это часто, легче всего поручить Python делать эту работу. Первый шаг такой же, как и раньше, с использованием urlopen. Забавы ради мы выберем историю BBC News под названием Блондинки вымрут через 200 лет, городская легенда выданная BBC за установленный научный факт:
|
Вы можете ввести print(html), чтобы увидеть содержимое HTML во всей своей красе, включая метатеги, карту изображений, JavaScript, формы и таблицы.
Чтобы получить текст из HTML мы будем использовать библиотеку Python под названием BeautifulSoup доступную для скачивания с сайта http://www.crummy.com/software/BeautifulSoup/:
|
Этот список все еще содержит нежелательный материал, касающийся навигации по сайту, и связанные истории. Методом проб и ошибок вы можете найти начальные и конечные индексы содержания, выбрать токены, представляющие интерес, и инициализировать текст, как мы делали до этого.
|
Обработка результатов работы поисковых систем
Сеть можно рассматривать как огромный корпус неаннотированного текста. Системы веб-поиска обеспечивают эффективное средство поиска релевантных лингвистических примеров в таком большом количестве текста. Основным преимуществом поисковых систем является размер: так как вы ищете в таком большом наборе документов, у вас больше шансов найти какой-либо лингвистический паттерн, в котором вы заинтересованы. Более того, вы можете использовать очень узкие паттерны, которым будут соответствовать только один или два примера на меньшем материале, но которым могут соответствовать десятки тысяч примеров, когда поиск выполняется в сети. Вторым преимуществом систем веб-поиска является то, что они очень просты в использовании. Таким образом, они обеспечивают очень удобный инструмент для быстрой проверки теории, позволяют увидеть, является ли она приемлемой.
| Google хиты | adore | love | like | prefer |
|---|---|---|---|---|
| absolutely | 289.000 | 905.000 | 16.200 | 644 |
| definitely | 1.460 | 51.000 | 158.000 | 62.600 |
| соотношение | 198: 1 | 18: 1 | 1:10 | 1:97 | Таблица 3.1: Google хиты для словосочетаний: число обращений к словосочетаниям с участием слова absolutely или definitely, за которым следует один из adore, love, like или prefer. (Liberman, в LanguageLog, 2005). |
К сожалению, поисковые системы имеют некоторые существенные недостатки. Во-первых, допустимый диапазон паттернов поиска строго ограничен. В отличие от локального корпуса, где вы пишете программы для поиска сколь угодно сложных паттернов, поисковые системы, как правило, позволяют Вам только искать отдельные слова или строки слов, иногда с подстановочными символами. Во-вторых, поисковые системы дают противоречивые результаты, и могут дать совершенно различные цифры при использовании в разное время или в разных географических регионах. Когда содержание дублируется на нескольких сайтах, результаты поиска могут быть преувеличены. И, наконец, разметка в результате, возвращаемом поисковой системой, может непредсказуемо изменяться, нарушая любой метод обнаружения конкретного содержания, основанный на паттерне (проблема, которая облегчается использованием API поисковой системы).
Замечание
Your Turn: Поищите в Интернете "the of" (в кавычках). Основываясь на большом количестве результатов, можем мы сделать вывод о том, что "the of" является частым словосочетанием в английском языке?
Обработка RSS-каналов
Блогосфера является важным источником текста в формальных и неформальных регистрах. С помощью библиотеки Python Universal Feed Parser доступной на https://pypi.python.org/pypi/feedparserj мы можем получить доступ к содержанию любого блога, как показано ниже:
|
Немного потрудившись, мы можем написать программы для создания небольшого свода блогерских сообщений и использовать это в качестве основы для нашей работы по NLP.
Чтение локальных файлов
Для того чтобы прочитать локальный файл, мы должны использовать встроенную функцию Python open(), за которой следует метод read(). Предположим, у вас есть файл document.txt, вы можете загрузить его содержимое вот так:
|
Замечание
Ваша очередь: Создайте файл с именем document.txt с помощью текстового редактора, наберите в нем несколько строк текста и сохраните его как простой текст. Если вы используете IDLE, выберите команду New Window в меню File, введите нужный текст в это окно, а затем сохраните файл как document.txt внутри директории, которую IDLE предложит во всплывающем диалоговом окне. Далее в интерпретаторе Python откройте файл с помощью n = open( 'document.txt'), а затем проверьте его содержимое с помощью print(f.read()).
Что-то, возможно, пошло не так, когда вы пытались сделать это. Если интерпретатор смог бы найти файл, вы бы увидели ошибку:
|
Чтобы проверить, что файл, который вы пытаетесь открыть, действительно в нужном каталоге, используйте команду IDLE Open в меню Файл; она отобразит список всех файлов в каталоге, где работает IDLE. В качестве альтернативы можно проверить текущую директорию из Python:
|
Другая возможная проблема, которая у вас могла возникнуть при доступе к текстовому файлу, связана с соглашениями о новой строке, которые различны для разных операционных систем. Встроенная функция open() имеет второй параметр для управления тем, как открывается файл: open('Document.txt', 'rU') - 'г' означает открыть файл для чтения (по умолчанию), а 'U' означает "Universal", что позволяет нам игнорировать различные условные обозначения, которые были использованы для маркировки новой строки.
Предполагая, что вы можете открыть файл, существует несколько методов для его чтения. Метод read() создает строку с содержимым всего файла:
|
Напомним, что '\n' - это символы перевода строки; они эквивалентны нажатию Enter на клавиатуре и началу новой строки.
Мы также можем прочитать файл по одной строке за один раз, используя for цикл:
|
При этом мы используем метод strip(), чтобы удалить символ новой строки в конце строки ввода.
К файлам корпусов NLTK также можно обратиться, используя эти методы. Мы просто должны использовать nltk.data.find(), чтобы получить имя файла для любого элемента корпуса. Тогда мы можем открыть и прочитать его так, как мы только что показали выше:
|
Извлечение текста из PDF, MSWord и других двоичных форматов
ASCII-текст и HTML-текст - это читаемые форматы. Но текст часто находится в бинарных форматах - как PDF и MSWord - которые могут быть открыты только с помощью специализированного программного обеспечения. Сторонние библиотеки, такие как pypdf и pywin32 обеспечивают доступ к этим форматам. Извлечение текста из документов с несколькими столбцами является чрезвычайно сложным делом. Для одноразового преобразования нескольких документов проще открыть документ в соответствующем приложении, а затем сохранить его как текст на локальном диске и обращаться к нему, как описано ниже. Если документ уже в сети, вы можете ввести его URL в поле поиска Google. Результат поиска часто включает в себя ссылку на HTML версию документа, которую можно сохранить в виде текста.
Захват пользовательского ввода
Иногда мы хотим захватить текст, который пользователь вводит, когда он взаимодействует с нашей программой. Для того, чтобы предложить пользователю ввести строку ввода, вызовите в Python функцию input(). После сохранения пользовательского ввода в переменную, мы можем работать с ним так же, как мы работали с другими строками.
|
Последовательная схема NLP
3.1 обобщает то, что мы рассмотрели в этом разделе, в том числе процесс построения словаря, который мы видели в 1.. (Один из шагов, нормализация, будет обсуждаться в 3.6.)

Рисунок 3.1: Последовательная схема обработки: мы открываем URL и читаем его HTML содержимое, удаляем разметку и выбираем часть символов; они затем токенизируются и конвертируются в nltk.Text объект; мы можем также перевести все слова в нижний регистр и извлечь словарь.
Много чего происходит в этом "трубопроводе". Понять его правильно поможет четкое представление о типе каждой переменной, которая упоминается. Мы выясняем тип любого объекта Python х, используя type(х), например, type(1) - <int>, так как 1 представляет собой целое число.
Когда мы загружаем содержимое URL или файла или когда мы вырезаем HTML - разметку, мы имеем дело со строками, типом данных Python <str>. (Мы узнаем больше о строках в 3.2):
|
Когда мы токенизируем строку мы получаем список (слов), это тип данных Python <list>. В результате нормализации и сортировки списков получаются другие списки:
|
Тип объекта определяет, какие операции можно выполнять над ним. Так, например, мы можем вызвать функцию append() для списка, но не для строки:
|
Подобно этому, мы можем конкатенировать строки со строками и списки со списками, но мы не можем конкатенировать строки со списками:
|
3.2 Строки: Обработка текста на самом низком уровне
Пришло время изучить фундаментальный тип данных, которые мы прилежно избегали до сих пор. В предыдущих главах мы сосредоточились на тексте в виде списка слов. Мы не слишком пристально вглядывались в слова и как они обрабатываются на языке программирования. Используя интерфейс NLTK мы могли игнорировать файлы, из которых эти тексты пришли. Содержание слова, а также файла, представляется языками программирования в виде фундаментального типа данных известного как строка. В этом разделе мы рассмотрим строки в деталях и покажем связь между строками, словами, текстами и файлами.
Основные операции со строками
Строки задаются с помощью одиночных кавычек или двойных кавычек ![[2]](http://www.nltk.org/book/callouts/callout2.gif) , как показано ниже.
Если строка содержит одиночную кавычку (апостроф), мы должны с помощью обратных косых черт выделить эту кавычку
, как показано ниже.
Если строка содержит одиночную кавычку (апостроф), мы должны с помощью обратных косых черт выделить эту кавычку ![[3]](http://www.nltk.org/book/callouts/callout3.gif) , чтобы Python знал, что имелась в виду буквально кавычка, либо поместить строку в двойные кавычки .
В противном случае кавычка внутри строки
, чтобы Python знал, что имелась в виду буквально кавычка, либо поместить строку в двойные кавычки .
В противном случае кавычка внутри строки ![[4]](http://www.nltk.org/book/callouts/callout4.gif) будет интерпретироваться как закрывающая кавычка и интерпретатор Python сообщит о синтаксической ошибке:
будет интерпретироваться как закрывающая кавычка и интерпретатор Python сообщит о синтаксической ошибке:
|
Иногда текстовые данные занимают несколько строк. Python предоставляет нам различные способы их ввода. В следующем примере последовательность из двух строк объединяется в одну строку.
Нам необходимо использовать обратную косую черту или круглые скобки , чтобы интерпретатор знал, что выражение не завершено после первой строки.
|
К сожалению, эти методы не дают нам символ новой строки между двумя строками сонета. Вместо этого мы можем использовать строку, заключенную в тройные кавычки, следующим образом:
|
Теперь, когда мы можем определять строки, мы можем попробовать некоторые простые операции над ними.
Прежде всего, давайте посмотрим на операцию + известную как конкатенация .
Она производит новую строку, которая является копией двух исходных строк, приклеенных одна к другой. Обратите внимание на то, что конкатенация не делает ничего умного, например, не вставляет пробел между словами. Мы можем даже умножать строки :
|
Замечание
Ваша очередь: Попробуйте запустить следующий код, а затем попытайтесь использовать ваше понимание строковых операций + и *, чтобы выяснить, как он работает. Будьте осторожны - различайте строки: ' ', которая представляет собой один символ пробела, и '', которая является пустой строкой.
|
Мы видели, что операции сложения и умножения применяются к строкам, а не только к числам. Однако обратите внимание, что мы не можем использовать вычитание или деление со строками:
|
Эти сообщения об ошибках являются еще одним примером того, как Python говорит нам, что мы смешали наши типы данных. В первом случае нам говорят, что операция вычитания (т. е., -) не может применяться к объектам типа str (строки), а во втором нам говорят, что деление не может принимать str и int в качестве своих двух операндов.
Печать строк
До сих пор, когда мы хотели посмотреть на содержимое переменной или увидеть результат расчета, мы просто вводили имя переменной в интерпретатор. Мы также можем увидеть содержимое переменной с помощью выражения print:
|
Обратите внимание на то, что на этот раз нет никаких кавычек. Когда мы исследуем переменную, введя ее имя в интерпретатор, интерпретатор печатает представление Python ее значения. Так как это строка, то результат в кавычках. Тем не менее, когда мы говорим интерпретатору print содержимое переменной, мы не видим символов кавычек, так как их нет внутри строки.
Выражение print позволяет отображать более одного элемента на строке различными способами, как показано ниже:
|
Обращение к отдельным символам
Как мы видели в 2 для списков, строки тоже индексируются, начиная с нуля. Когда мы индексируем строку, мы получаем одну из ее символов (или букв). Один символ не является чем-то особенным - это просто строка длинной 1.
|
Как и со списками, если мы попытаемся получить доступ к индексу, который находится за пределами строки, мы получим ошибку:
|
Снова, как и со списками, мы можем использовать отрицательные индексы для строк, где -1 является индексом последнего символа .
Положительные и отрицательные индексы дают нам два способа сослаться на любую позицию в строке. В этом случае, когда строка имела длину 12, оба индекса 5 и -7 относятся к тому же символ (пробел).
(Обратите внимание на то, что 5 = len(monty) - 7.)
|
Мы можем написать for цикл для перебора символов в строках. Эта функция print включает в себя дополнительный параметр end = ' ', который представляет собой то, как мы говорим Python печатать в конце пробел вместо новой строки.
|
Мы можем также считать отдельные символы. Мы должны игнорировать различие регистра, приводя все к нижнему регистру и отфильтровывая небуквенные символы:
|
| [sb] | объяснить этот кортеж распаковкой где-нибудь? |
Это дает нам буквы алфавита, с наиболее часто встречающимися буквами, перечисленными в первую очередь (это довольно сложно и мы объясним это более тщательно ниже). Вы могли бы захотеть визуализировать распределение с использованием fdist.plot(). Относительные частоты символом текста могут быть использованы в автоматической идентификации языка текста.
Обращение к частям строк
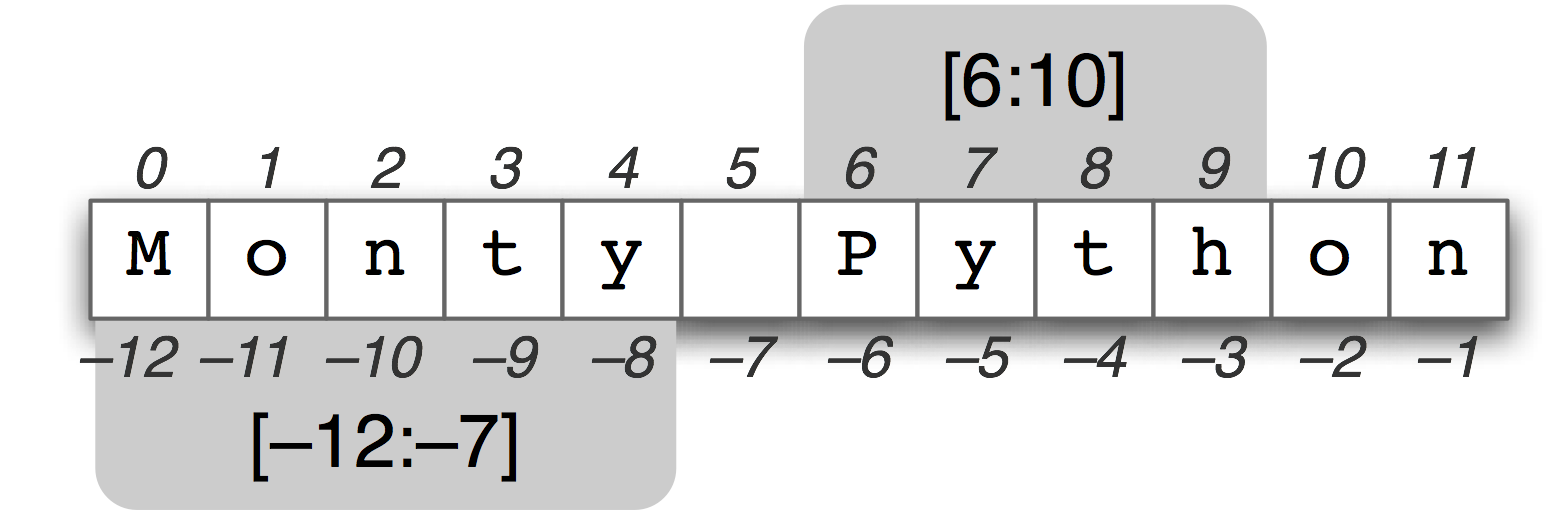
Рисунок 3.2: Срез строки: Строка "Monty Python" отображается вместе со своими положительными и отрицательными индексами; две подстроки выбираются с помощью обозначения среза. Срез [m, n] содержит символы с позиции m по n-1.
Подстрока - это любая непрерывная часть строки, которую мы хотим вытащить для дальнейшей обработки. Мы можем легко получить доступ к подстроке, используя то же обозначение среза, которое мы использовали для списков (см. 3.2). Например, следующий код обращается к подстроке с позиции 6 до (не включая) позиции 10:
|
Здесь мы видим, символы 'P', 'y', 't' и 'h', которые соответствуют monty[6] ... monty[9], но не monty [10]. Это происходит потому, что срез начинается с первого индекса, но завершается за один до конечного индекса.
Мы также можем сделать срез с отрицательными индексами - то же базовое правило - начало с первого индекса и конец за один до последнего - применимо; здесь мы останавливаемся перед символом пробела.
|
Как и со срезами списков, если опустить первое значение, то подстрока начинается с начала строки. Если мы опустим второе значение, то подстрока продолжается до конца строки:
|
Мы проверяем, содержит ли строка определенную подстроку, используя оператор in, следующим образом:
|
Мы можем также найти положение подстроки в строке с помощью функции find():
|
Замечание
Ваша очередь: Придумайте предложение и присвойте его переменной, например sent = 'my sentence...'. Теперь запишите выражение среза, чтобы достать из него отдельные слова. (Это, очевидно, неудобный способ обработки слов текста!)
Другие операции со строками
Python имеет всестороннюю поддержку обработки строк. Свод, включающий некоторые операции, которые мы еще не видели, показан в 3.2 . Для получения дополнительной информации о строках, наберите help(str) в командной строке Python.
| Метод | Функциональные возможности |
|---|---|
| s.find(t) | индекс первого экземпляра строки t внутри s (-1, если строка t не найдена) |
| s.rfind(t) | Индекс последнего экземпляра строки t внутри s (-1, если строка t не найдена) |
| s.index(t) | как s.find(t) за исключением того, что вызывает ValueError если строка t не найдена |
| s.rindex(t) | как s.rfind(t) за исключением того, что вызывает ValueError если строка t не найдена |
| s.join(text) | объединить элементы списка text в строку, используя s в качестве связующего звена |
| s.split(t) | разделить s на элементы, используя в качестве разделителя между элементами t (пробел по умолчанию) |
| s.splitlines() | разделить s на строки |
| s.lower() | версия строки s в нижнем регистре |
| s.upper() | версия строки s в верхнем регистре |
| s.title() | версия строки s в титульном регистре |
| s.strip() | копия s без начальных или конечных пробелов |
| s.replace(t, u) | заменить экземпляры t на u внутри s | Таблица 3.2: Полезные методы строк: операции со строками в дополнение к тестам строк, показанным на 4.2; все методы дают новую строку или список |
Различие между списками и строками
И строки и списки - это виды последовательности. Из строки и из списка мы можем выделить части путем индексирования и срезов, и можем соединять строки и списки воедино путем конкатенации. Тем не менее, мы не можем соединять строки и списки:
|
Когда мы открываем файл для чтения в программе на Python, мы получаем строку, соответствующую содержанию всего файла. Если мы используем цикл for для обработки элементов этой строки, все, что мы можем выбрать, - это отдельные символы, - мы не получаем возможности выбрать уровень детализации. В отличие от элементов строки, элементы списка могут быть сколь угодно большими или маленькими: например, элементами могут быть параграфы, предложения, фразы, слова, символы. Таким образом, списки имеют то преимущество, что мы можем быть гибкими в отношении элементов, которые они содержат, и соответственно можем быть гибкими в отношении обработки элементов списка. Следовательно, одна из первых вещей, которую мы, вероятно, сделаем в части NLP кода, - это токенизация строки в список строк (3.7). И наоборот, когда мы хотим записать наши результаты в файл или вывести на терминал, мы обычно форматируем их в виде строки (3.9).
Списки и строки имеют различную функциональность. Списки имеют дополнительное преимущество, которое заключается в том, что вы можете изменять их элементы:
|
С другой стороны, если мы попытаемся сделать это со строкой - изменить 0-ой символ в query на 'F' - мы получим:
|
Это происходит потому, что строки неизменны - вы не можете изменить строку после того, как вы ее создали. Однако списки изменяемы, и их содержание может быть изменено в любое время. В результате списки поддерживают операции, которые изменяют первоначальное значение, а не производят новое значение.
Замечание
Ваша очередь: Консолидируйте свои знания строк, попробовав выполнить некоторые из упражнений на строки в конце этой главы.
3.3 Обработка текста с Unicode
Нашим программам часто придется иметь дело с различными языками и различными наборами символов. Понятие "обычный текст" является фикцией. Если вы живете в англо-говорящем мире, вы, вероятно, используете ASCII, возможно, не осознавая этого. Если вы живете в Европе, вы можете использовать один из расширенных латинских наборов символов, содержащих такие символы, как "ø" для датского и норвежского, "õ" для венгерского, "ñ" для испанского и бретонского, и "n" с перевернутой крышечкой для чешского и словацкого. В этом разделе мы дадим краткий обзор того, как использовать Unicode для обработки текстов, которые используют не-ASCII наборы символов.
Что такое Unicode?
Unicode поддерживает более миллиона символов. Каждому символу присваивается номер, который называется кодовый пункт. В Python кодовые пункты записываются в виде \uXXXX, где XXXX - 4-х значное шестнадцатеричное число.
В рамках программы мы можем манипулировать строками Unicode, как нормальными строками. Тем не менее, когда символы Unicode сохраняются в файлы или отображаются на экране терминала, они должны быть закодированы как поток байтов. Некоторые кодировки (например, ASCII и Latin-2) используют один байт на одну кодовую точку, так что они могут поддерживать только небольшое подмножество Юникод символов достаточное для одного языка. Другие кодировки (такие как UTF-8) используют несколько байтов и могут представлять полный набор символов Unicode.
Текст в файлах будет в определенной кодировке, поэтому нам нужен некоторый механизм для перевода его в Юникод - перевод в Юникод называется декодированием. И наоборот, чтобы записать Юникод в файл или на терминал, нам сначала нужно перевести его в подходящую кодировку - этот перевод из Юникод называется кодированием, он показан на 3.3.
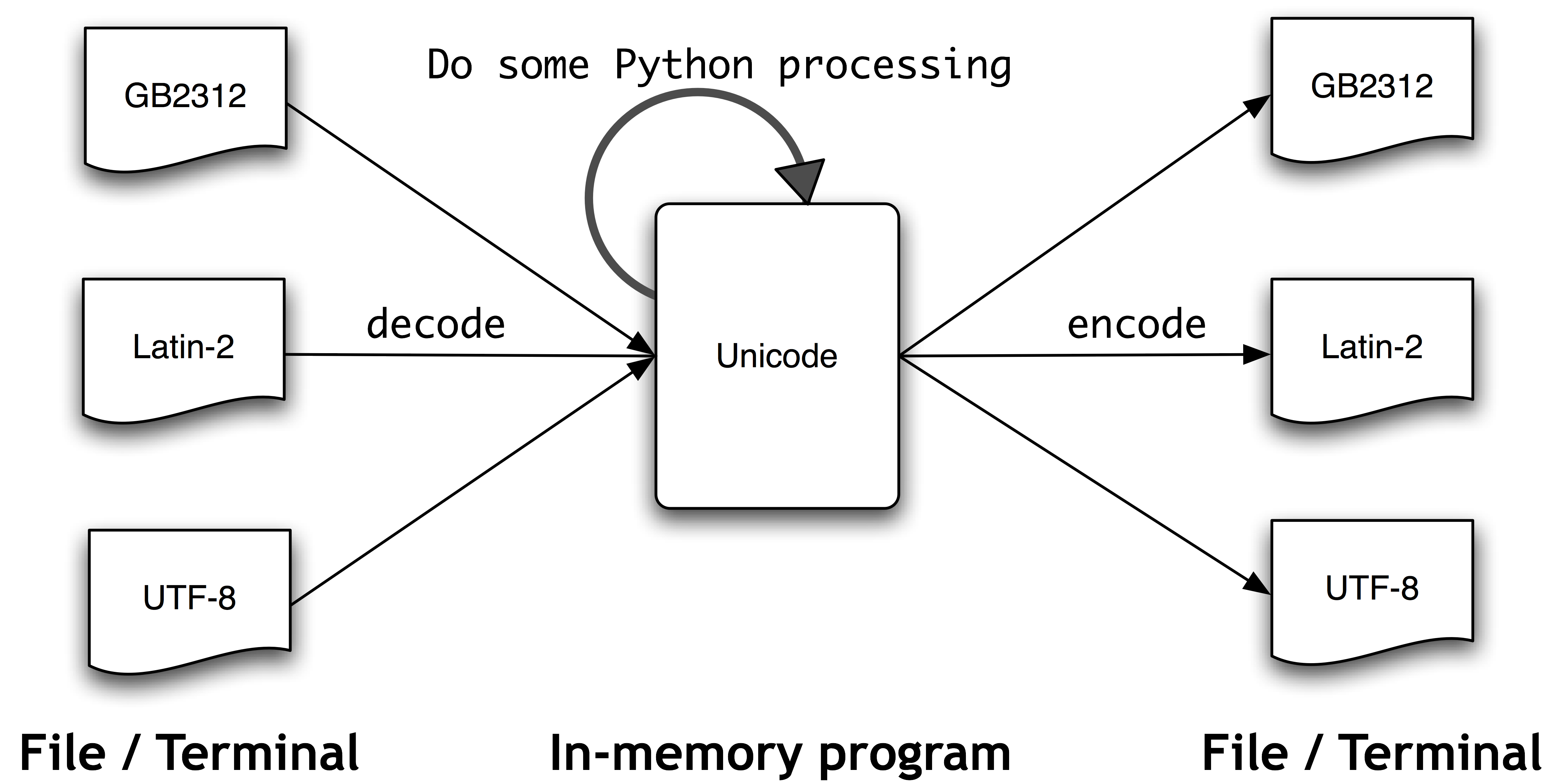
Рисунок 3.3: Unicode декодирование и кодирование
С точки зрения Unicode, символы - это абстрактные сущности, которые могут быть реализованы в виде одного или более глифов. Только глифы могут появляться на экране или печататься на бумаге. Шрифт является отображением символов в глифах.
Извлечение закодированного текста из файлов
Давайте предположим, что у нас есть небольшой текстовый файл и что мы знаем, как он закодирован. Например, polish-lat2.txt, как следует из названия, представляет собой фрагмент польского текста (из польской Википедии, см http://pl.wikipedia.org/wiki/Biblioteka_Pruska). Этот файл закодирован как Latin-2, также известный как ISO-8859-2. Функция nltk.data.find() находит файл для нас.
|
Функция Python open() может считывать закодированные данные в строки Юникод и записывать строки Юникод в закодированной форме. Она принимает параметр, указывающий кодировку файла чтения или записи. Итак давайте откроем наш польский файл с кодировкой 'latin2' и проверим содержимое файла:
|
Если этот текст отображается на вашем терминале некорректно или если мы хотим увидеть лежащие в основе символов числовые значения (или «кодовые пункты»), то мы можем преобразовать все символы не-ASCII в их двузначные \хXX и четырехзначные \uXXXX представления:
|
Первая строка выше иллюстрирует управляющую строку Юникод, которой предшествует в управляющая строка \u, а именно \u0144. Соответствующий Юникод символ будет изображен на экране как глиф ń. В третьей строке предыдущего примера мы видим \xf3, что соответствует глифу ó и находится в пределах диапазона 128-255.
В Python 3 исходный код кодируется с использованием UTF-8 по умолчанию и вы можете включать символы Юникод в строки, если вы используете IDLE или другой редактор программ, который поддерживает Юникод. Любые Юникод символы могут быть включены с помощью \uXXXX управляющей последовательности. Мы находим целочисленный порядковый номер символа с помощью функции ord(). Например:
|
Шестнадцатеричным четырехзначным обозначением для 324 будет 0144 (наберите hex(324), чтобы увидеть это), и мы можем определить строку с соответствующей управляющей последовательностью.
|
Замечание
Есть много факторов, определяющих, какие символы отображаются на экране. Если вы уверены, что у вас правильная кодировка, но ваш Python код по-прежнему не в состоянии воспроизвести глифы, которые вы ожидаете увидеть, вам следует также проверить, что в вашей системе установлены необходимые шрифты. Возможно, необходимо настроить региональные настройки для визуализации UTF-8 закодированных символов, а затем использовать print(nacute.encode('utf8')), чтобы увидеть ń в вашем терминале.
Мы также можем увидеть, как этот символ представляется в виде последовательности байтов внутри текстового файла:
|
Модуль unicodedata позволяет нам проверить свойства символов Юникод. В следующем примере мы выбираем все символы в третьей строке нашего польского текста вне диапазона ASCII и печатаем их UTF-8 последовательности байтов, за которыми следуют их целочисленные кодовые точки, используя стандартное соглашение в Юникод (т.е. предваряя шестнадцатиричные числа U+), за которыми следуют их названия в Юникод.
|
Если заменить c.encode('utf8') в на c и ваша система поддерживает UTF-8, вы должны увидеть результат наподобие следующего:
Или, возможно, вам потребуется заменить кодировку 'utf8' в примере на 'latin2', опять же в зависимости от конфигурации вашей системы.
Следующие примеры иллюстрируют, как методы работы со строками Python и модуль re может работать с символами Юникод. (Мы подробно остановимся на модуле re в следующем разделе. \w соответствует "word character" (словарный символ), cf 3.4).
|
NLTK токенизаторы допускают Юникод строки в качестве входных данных и, соответственно, возвращают Юникод строки в качестве результата.
|
Использование вашей локальной кодировки в Python
Если вы привыкли работать с символами в той или иной локальной кодировке, вы, вероятно, хотите иметь возможность использовать свои стандартные методы для ввода и редактирования строк в файле Python. Чтобы сделать это, вам необходимо включить строку '# -*- coding: <coding> -*-' в качестве первой или второй строки вашего файла. Обратите внимание, что <coding> необходимо заменить на название кодировки, например 'latin-1', 'big5' или 'utf-8' (см. 3.4).
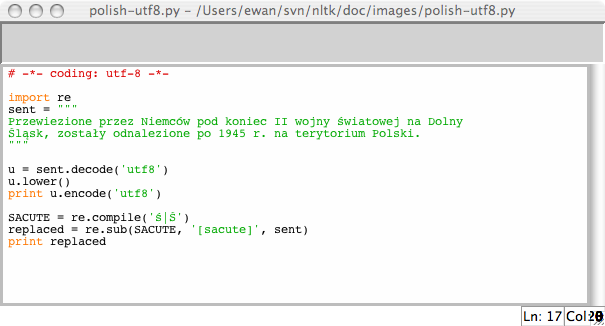
Рисунок 3.4: Юникод и IDLE: закодированные в UTF-8 строковые литералы в редакторе IDLE; для этого необходимо установить соответствующий шрифт в настройках IDLE; здесь мы выбрали Courier CE.
Приведенный выше пример также иллюстрирует, как регулярные выражения могут использовать закодированные строки.
3.4 Регулярные выражения для обнаружения словарных паттернов
Многие задачи лингвистической обработки включают установление соответствия образцу. Например, мы можем найти слова, заканчивающиеся на ed с помощью endswith('ed'). Мы видели множество таких "словарных тестов" в 4.2. Регулярные выражения дают нам более мощный и гибкий способ описания символьных шаблонов.
Замечание
Существует множество опубликованных введений в тему регулярных выражений, организованных вокруг синтаксиса регулярных выражений и примененных для поиска по текстовым файлам. Вместо того, чтобы делать это снова, мы сконцентрируемся на использовании регулярных выражений на разных этапах лингвистической обработки. Как обычно, мы будем применять проблемно-ориентированный подход и будем представлять новые возможности, только когда они необходимы для решения практических задач. В нашем обсуждении мы будем отмечать регулярные выражения, используя двойные угловые кавычки (шевроны) следующим образом: «patt».
Чтобы использовать регулярные выражения в Python мы должны импортировать библиотеку re с помощью: import re. Нам также нужен список слов для поиска; мы снова будем использовать Words Corpus(4). Мы предварительно обработаем его, убрав из него все собственные имена.
|
Использование основных метасимволов
Давайте найдем слова, оканчивающиеся на ed используя регулярное выражение «ed$». Мы будем использовать функцию re.search(р, s), чтобы проверить, можно ли шаблон р найти где-нибудь внутри строки s. Нам нужно указать интересующие нас символы и использовать знак доллара, который имеет особое поведение в контексте регулярных выражений, которое заключается в том, что оно заменяет конец слова:
|
Символ подстановки . соответствует любому одиночному символу. Предположим, что у нас есть место в кроссворде для слова из 8 букв с j в качестве третьей буквы и t в качестве шестой буквы. На месте каждой пустой ячейки мы используем точку:
|
Замечание
Ваша очередь: Символ каретки ^ соответствует началу строки, так же, как $ соответствует концу. Какие результаты мы получим из приведенного выше примера, если мы опустим оба из них, и будем искать «..j..t ..»?
И, наконец, знак ? указывает, что предыдущий символ не является обязательным. Таким образом, «^е-?mail$» будет соответствовать как emali, так и e-mail. Мы могли бы подсчитать общее число вхождений этого слова (в любом написании) в тексте, используя sum(1 for w in text if re.search('^ e-?mail$', w)).
Диапазоны и замыкания
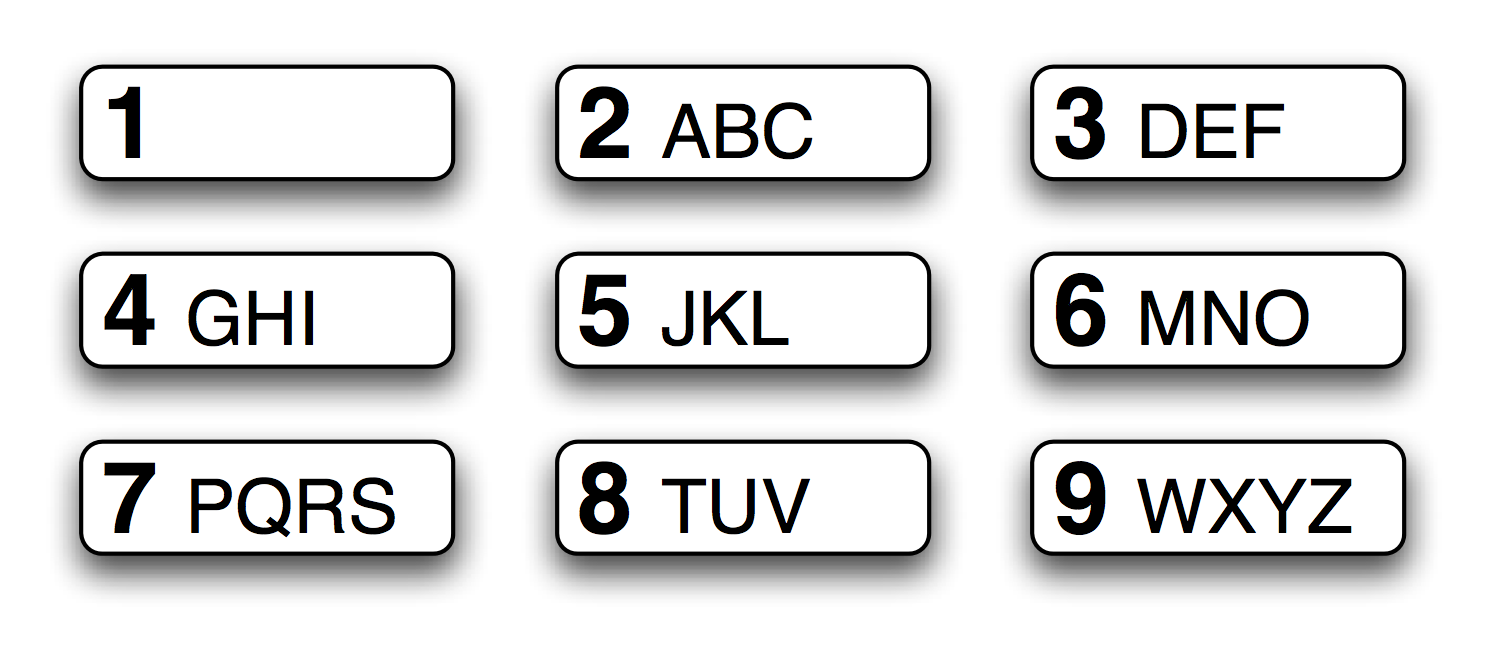
Рисунок 3.5: T9: Текст на 9 ключах
Система T9 используется для ввода текста на мобильных телефонах (см. 3.5). Два или более слов, которые вводятся той же последовательностью нажатий клавиш, известны как текстонимы. Например, hole и golf вводятся нажатием последовательности 4653. Какие другие слова могли быть введены с помощью той же последовательности? Здесь мы используем регулярное выражение «^[ghi][mno][jlk][def]$»:
|
Первая часть выражения, «^[ghi]», соответствует началу слова, за которым следует g, h или i. Следующая часть выражения, «[mno]», определяет, что второй символ может быть m, n или o. Третий и четвертый символы также ограничены. Только четыре слова удовлетворяют всем этим ограничениям. Обратите внимание, что порядок символов внутри квадратных скобок не имеет существенного значения, так что мы могли бы написать «^[hig][nom][ljk][fed]$» и нашли бы те же слова.
Замечание
Ваша очередь: Найдите несколько "выкручивателей пальцев", путем поиска слов, которые используют только часть номерной панели. Например, «^[ghijklmno]+$» или более кратко «^[g-o]+$», будет соответствовать словам, которые используют только кнопки 4, 5, 6 в центральном ряду, а «^[a-fj-o]+$» будет соответствовать словам, которые используют ключи 2, 3, 5, 6 в правом верхнем углу. Что означают - и +?
Давайте исследуем символ + еще немного. Обратите внимание на то, что он может быть применен как к отдельной букве, так и к наборам букв, заключенным в квадратные скобки:
|
Должно быть ясно, что + означает просто "один или несколько экземпляров предыдущего элемента", который может быть индивидуальным символов, как m, набором, как [fed], или диапозоном, как [d-f]. Теперь давайте заменим + на *, который означает "ноль или более экземпляров предыдущего пункта". Регулярное выражение «^m*i*n*e*$» будет соответствовать всему, что мы нашли с помощью «^m+i+n+e+$», а также словам, где некоторые из указанных букв не появляются вообще, например: me, min и mmmmm. Обратите внимание, что символы + и * иногда называют замыканиями Клини, или просто замыканиями.
Оператор ^ имеет другую функцию, когда он появляется в качестве первого символа внутри квадратных скобок. Например «[^aeiouAEIOU]» соответствует любому символу, кроме гласного. Мы можем выполнить поиск по NPS Chat Corpus слов, которые состоят исключительно из символов, которые не являются гласными, с помощью выражения «^ [^ aeiouAEIOU]+$», чтобы найти элементы подобные этим: :) :) :), grrr, cyb3r и zzzzzzzz. Обратите внимание, результат включает в себя не-буквенные символы.
Вот еще несколько примеров регулярных выражений, которые используются, чтобы найти токены, которые соответствуют определенному шаблону, иллюстрирующие использование некоторых новых символов: \, {}, () и |:
|
Замечание
Ваша очередь: Изучите приведенные выше примеры и попытайтесь понять , что означают символы \, {}, () и |, прежде чем читать дальше.
Вы, наверное, поняли, что обратная косая черта означает, что следующий символ лишается своих особых полномочий и должен буквально соответствовать символу в слове. Таким образом, если . является особым символом, то \. соответствует только точке. Выражения, заключенные в фигурные скобки, как {3,5}, указывают количество повторений предыдущего элемента. Символ вертикальная черта указывает на выбор между материалом с левой и правой стороны от него. Скобки показывают сферу применения оператора: они могут быть использованы вместе с символом вертикальной черты (или дизъюнкции) следующим образом: «w(i|e|ai|oo)t», что соответствует словам wit, wet, wait и woot. Поучительно посмотреть, что произойдет, если вы опустите скобки из последнего выражения выше и будете искать «ed | ing$».
Метасимволы, которые мы увидели, кратко охарактеризованы в 3.3.
| оператор | Поведение |
|---|---|
| . | Подстановочный символ, соответствует любому символу |
| ^abc | Соответствует некоторому шаблону abc в начале строки |
| abc$ | Соответствует некоторому шаблону abc в конце строки |
| [abc] | Соответствует одному из набора символов |
| [A-Z0-9] | Соответствует одному из диапазона символов |
| ed | ing | s | Соответствует одной из указанных строк (дизъюнкция) |
| * | Ноль или более экземпляров предыдущего элемента, например, a*, [a-z]* (также известный как Замыкания Клини) |
| + | Один или несколько экземпляров предыдущего элемента, например, a+, [a-z]+ |
| ? | Ноль или один экземпляр предыдущего элемента (т.е. опционально), например, a?, [a-z]? |
| {n} | Ровно n повторов, где n является неотрицательным целым числом |
| {n,} | По крайней мере, n повторов |
| {,n} | Не больше, чем n повторов |
| {m,n} | По крайней мере m, но не более чем n повторов |
| a(b|c)+ | Скобки, которые указывают на сферу действия операторов | Таблица 3.3: Основные метасимволы регулярных выражений, в том числе подстановочные, диапазоны и замыкания |
Для интерпретатора Python регулярное выражение подобно любой другой строке. Если строка содержит обратную косую черту, за которой следуют определенные символы, он будет интерпретировать их особым образом. Например, \b будет интерпретироваться как возврат на одну позицию. В общем, при использовании регулярных выражений, содержащих обратную косую черту, мы должны поручить интерпретатору не смотреть внутрь строки совсем, а просто передать ее непосредственно в библиотеку re для обработки. Мы делаем это, предваряя строку буквой r, чтобы указать, что это сырая строка. Например, сырая строка r'\band\b' содержит два \b символа, которые интерпретируются библиотекой re как соответствующие границам слова, а не как символы возврата на одну позицию назад. Если вы приучитесь использовать г'...' для регулярных выражений - как мы будем делать с этого момента - вы избавите себя от необходимости думать об этих сложностях.
3.5 Полезные приложения регулярных выражений
Все выше приведенные примеры включали в себя поиск слов w, которые соответствуют некоторому регулярному выражению regexp с помощью re.search(regexp, w). Помимо проверки того, что регулярное выражение соответствует слову, мы можем использовать регулярные выражения для извлечения материала из слов или чтобы изменять слова определенным образом.
Извлечение частей слова
Метод re.findall() ( "найти все") находит все (непересекающиеся) соответствия данного регулярного выражения. Давайте найдем все гласные в слове, а затем сосчитаем их:
|
Давайте найдем все последовательности из двух или более гласных в некотором тексте и определим их относительную частоту:
|
Замечание
Ваша очередь: В формате даты времени W3C даты представлены следующим образом : 2009-12-31. Замените ? в следующем коде Python регулярным выражением для того, чтобы преобразовать строку '2009-12-31' в список целых чисел [2009, 12, 31]:
[int(n) for n in re.findall(?, '2009-12-31')]
Что еще можно делать с частями слов?
Раз мы уже научились использовать re.findall() для извлечения частей слов, то теперь есть интересные вещи, которые мы можем сделать с этими частями, как, например, склеить их обратно вместе или найти зависимость между ними.
Иногда отмечают, что английский текст весьма избыточен, и его по-прежнему легко читать, даже когда гласные внутри слов опущены. Например, declaration становится dclrtn, а inalienable становится inlnble, сохраняя любые начальные или конечные последовательности гласных. Регулярное выражение в нашем следующем примере соответствует начальной последовательности гласных, конечной последовательности гласных, и всем согласным; все остальное игнорируется. Эта трехсторонняя дизъюнкция обрабатывается слева направо, если одна из трех частей соответствует слову, все последующие части регулярного выражения игнорируются. Мы используем re.findall(), чтобы извлечь все совпадающие части, и ''.join(), чтобы соединить их вместе (см 3.9 для получения дополнительной информации об операции соединения).
|
Далее, давайте объединим регулярные выражения с условным распределением частот. Здесь мы будем извлекать все согласно-гласные последовательности из слов языка Rotokas, такие как ka и si. Так как каждая из них является парой, это может быть использовано для инициализации условного распределения частоты. Затем мы представляем в виде таблицы частоту каждой пары:
|
Рассмотрев строки для s и t, мы обнаружим, что они находятся в частичном "дополнительном распределении", которое является доказательством того, что они не являются отдельными фонемами в языке. Таким образом, мы, вероятно, можем выбросить s из алфавита Rotokas и просто иметь правило произношения, что буква t произносится как s, когда за ней идет i. (Обратите внимание , что единственная запись, имеющая su, а именно kasuari, 'cassowary' ('казуар') заимствовано из английского языка.)
Если мы хотим иметь возможность просмотреть слова, которые стоят за числами в таблице выше, то было бы полезно иметь индекс, позволяющий нам быстро найти список слов, содержащих данную пару согласного-гласного, например cv_index ['su'] должно дать нам все слова, содержащие su. Вот как мы можем это сделать:
|
Эта программа обрабатывает каждое слово w по очереди и для каждого из них находит каждую подстроку, которая соответствует регулярному выражению «[ptksvr][aeiou]». В случае слова kasuari, она находит ka, su и ri. Таким образом, список cv_word_pairs будет содержать ('ka', 'kasuari'), ('su', 'kasuari') и ('ri', 'kasuari'). Еще один шаг, используя nltk.Index(), преобразует это в полезный индекс.
Нахождение основ слов
Когда мы используем систему веб-поиска, мы обычно не задумываемся (или замечаем), если слова в документе отличаются от наших условий поиска наличием различных окончаний. Поиск laptops находит документы, содержащие laptop, и наоборот. В самом деле, ноутбук и ноутбуки всего лишь две формы одного и того же словарного элемента (или леммы). Для некоторых задач обработки языка мы хотим игнорировать окончания слов, а просто иметь дело с основами слов.
Существуют различные способы выделить основу слова. Вот простой незамысловатый подход, который просто отбрасывает все, что выглядит как суффикс:
|
Хотя мы в конечном счете будем использовать встроенные в NLTK определители основ, интересно посмотреть, как мы можем использовать регулярные выражения для выполнения этой задачи. Наш первый шаг заключается в создании дизъюнкции всех суффиксов. Нам нужно заключить ее в скобки, чтобы ограничить сферу дизъюнкции.
|
Здесь re.findall() просто дал нам суффикс, несмотря на то, что регулярное выражение соответствовало слову целиком. Это произошло потому, что круглые скобки имеют вторую функцию - выбирать подстроки, которые необходимо извлечь. Если мы хотим использовать круглые скобки, чтобы указать сферу дизъюнкции, а не выбирать материал, который будет выводиться, мы должны добавить обозначение ?:, которое является лишь одним из многих тайных тонкостей регулярных выражений. Вот пересмотренный вариант.
|
Однако, на самом деле, мы хотели бы разделить слово на основу и суффикс. Таким образом, мы должны просто взять в скобки обе части регулярного выражения:
|
Это выглядит многообещающим, но до сих пор есть одна проблема. Давайте посмотрим на другое слово, processes:
|
Регулярное выражение неправильно нашло суффикс -s вместо суффиксf -es. Это демонстрирует еще одну тонкость: оператор звездочка "жадный" и часть выражения .* пытается проглотить столько входных данных, сколько возможно. Если мы используем "не жадный" версию оператора звезды, написанный *? , Мы получаем то, что мы хотим:
|
Это работает даже тогда, когда мы допускаем пустой суффикс, сделав содержание второй скобки необязательным:
|
Такой подход все равно имеет много проблем (вы можете обнаружить их?) но мы будем двигаться дальше, чтобы определить функцию для выделения основ и применить ее к целому тексту:
|
Обратите внимание на то, что наше регулярное выражение удалило s не только из ponds, но и из is и basis. Он произвел некоторые не-слова, как, например, distribut и deriv, но они являются приемлемыми основами в некоторых приложениях.
Поиск по токенизированному тексту
Вы можете использовать особый вид регулярного выражения для поиска нескольких слов в тексте (где текст представляет собой список токенов). Например, "<a> <man>" находит все экземпляры a man в тексте. Угловые скобки используются для обозначения границ токенов, и любой пробел между угловыми скобками игнорируется (поведение, которое является уникальным для метода NLTK findall() для текстов). В следующем примере мы включаем выражение <.*> , которому будет соответствовать любой одиночный токен, и заключаем его в скобки, чтобы только подходящее слово (например , monied), а не подходящая фраза (например, monied man) попадала в результат. Второй пример находит фразы, состоящие из трех слов, заканчивающиеся на слово bro . Последний пример находит последовательности из трех и более слов, начинающиеся с буквы l .
|
Замечание
Ваша очередь: Консолидируйте ваше понимание паттернов регулярных выражений и замен с помощью nltk.re_show(р, s), которая аннотирует строку s с тем, чтобы показать каждое место, где было установлено соответствие модели р, и nltk.app.nemo(), которая предоставляет графический интерфейс для исследования регулярных выражений. Если вы хотите еще попрактиковаться, попробуйте некоторые из упражнений на регулярные выражения в конце этой главы.
Легко построить шаблоны поиска, когда лингвистическое явление, которое мы изучаем, привязано к конкретным словам. В некоторых случаях, потребуется больше творчества. Например, поиск в большом текстовом корпусе выражений вида х и другие у-и позволяет обнаружить гипернимы (cf 5):
|
При наличии достаточного количества текста, такой подход даст нам полезный запас информации о систематике объектов без необходимости какого-либо ручного труда. Тем не менее, наши результаты поиска обычно содержат ложные срабатывания, то есть случаи, которые мы хотели бы исключить. Например, результат: требования и другие факторы предполагает, что требование является экземпляром типа фактор, но это предложение, на самом деле, о требованиях по заработной плате. Тем не менее, мы могли бы построить собственную онтологию английских понятий, вручную исправляя результат таких поисков.
Замечание
Такое сочетание автоматической и ручной обработки является наиболее распространенным способом построения новых корпусов. Мы вернемся к этому вопросу в 11..
Поиск по корпусам также страдает от проблемы ложных несрабатываний, то есть пропуск случаев, которые мы хотели бы включить. Рискованно делать вывод, что некоторые лингвистические явления не присутствуют в корпусе только потому, что мы не смогли найти ни одного экземпляра шаблона поиска. Может быть, мы просто недостаточно тщательно подумали о подходящих моделях.
Замечание
Ваша очередь: Выполните поиск экземпляров шаблона как х, так и у, чтобы обнаружить информацию о сущностях и их свойствах.
3.6 Нормализация текста
В предыдущих примерах программ мы часто преобразовали текст в нижний регистр, прежде чем делать что-либо с его словами, например, set(w.lower() for w in text). Используя lower(), мы приводили текст к нижнему регистру, чтобы различие между The и the игнорировалось. Часто мы хотим пойти дальше этого и отбросить любые аффиксы, эта задача известна как выделение основы. Еще один шаг состоит в том, чтобы убедиться, что полученная форма представляет собой известное слово в словаре, эта задача известна как лемматизация. Мы рассмотрим каждый из них по порядку. Во-первых, нам необходимо определить данные, которые мы будем использовать в этом разделе:
|
Выделители основы слова
NLTK включает в себя несколько готовых выделителей основы слова, и если вам когда-нибудь понадобится выделитель основы слов, вы должны использовать один, предпочитая их созданию своих собственных с помощью регулярных выражений, так как они обрабатывают широкий спектр нерегулярных случаев. Выделители основ Портера и Ланкастера следуют своим собственным правилам для отчистки от аффиксов. Заметим, что выделитель основы Портера правильно обрабатывает слово lying (устанавливая его соответствие слову lie), тогда как выделитель основы Ланкастера нет.
|
Выделение основ не является четко определенным процессом, и мы, как правило, выбираем выделитель, который лучше всего подходит для определенного приложения. Выделитель Портера является хорошим выбором, если вы индексируете некоторые тексты и хотите поддерживать поиск с использованием альтернативных форм слов (это решение проиллюстрировано в листинге 3.6, который использует объектно-ориентированные методы программирования, выходящие за рамки этой книги, методы форматирования строк, которые будут рассмотрены в 3.9, и функцию enumerate(), которая будет объяснена в 4.2).
| ||
| ||
Пример 3.6 (code_stemmer_indexing.py) : Рисунок 3.6: Индексация текста с помощью выделителя основ |
Лемматизация
WordNet лемматизатор удаляет только аффиксы, если полученное слово есть в его словаре. Этот дополнительный процесс проверки делает лемматизатор медленнее, чем выше приведенные выделители. Обратите внимание на то, что он не обрабатывает lying, но он преобразует women в woman.
|
WordNet лемматизатор является хорошим выбором, если вы хотите составить словарь некоторых текстов и хотите иметь список действительных лемм (или гнезд лексикона).
Замечание
Другая задача нормализации включает в себя определение нестандартных слов, включая номера, сокращения и сроки, и сопоставление любых таких токенов специальному словарю. Например, каждое десятичное число может быть поставлено в соответствие одному токену 0.0, а каждый акроним может быть поставлен в соответствие AAA. Это позволяет сохранить небольшой размер словаря и повышает точность многих задач моделирования языка.
3.7 Регулярные выражения для токенизации текста
Токенизация - это задача разделения строки на различимые языковые единицы, которые составляют часть языковых данных. Несмотря на то, что это фундаментальная задача, мы смогли отложить ее до этого момента, потому что многие корпусы уже токенизированы, а также потому, что NLTK включает в себя несколько токенизаторов. Теперь, когда вы знакомы с регулярными выражениями, вы можете узнать, как использовать их, чтобы разметить текст и иметь гораздо больший контроль над процессом.
Простые подходы к токенизации
Самый простой метод токенизации текста заключается в разделении его, используя пробелы. Рассмотрим следующий текст из Алисы в стране чудес:
|
Мы могли бы разделить этот необработанный текст по пробелам с помощью raw.split().
Для того, чтобы сделать то же самое, используя регулярное выражение, не достаточно найти все символы пробела в строке , так как в этом случае в результат попадают токены, которые содержат символ новой строки \n; вместо этого мы должны найти любое количество пробелов, табуляций или символов новой строки :
|
Регулярное выражение «[ \t\n]+» соответствует одному или нескольким пробелам, табуляциям (\t) или символам новой строки (\n). Другие символы пробела, такие как возврат каретки и формы ввода, на самом деле тоже должны быть включены. Вместо этого мы будем использовать встроенную в re аббревиатуру, \s, что означает любой символ пробела. Данное предложение можно переписать в виде re.split(г'\s+', raw).
Замечание
Важно: Не забывайте ставить перед регулярными выражениями префикс r (что означает "необработанный"), который приказывает интерпретатору Python обрабатывать строку в буквальном смысле, а не обрабатывать все символы обратной косой черты, которые он содержит.
Разделение по пробелам дает нам такие токены, как '(not' и 'herself,'. В качестве альтернативы можно использовать тот факт, что Python дает нам класс символов \w для символов слов, что эквивалентно [a-zA-Z0-9_]. Он также определяет дополнение этого класса \W, то есть все символы, кроме букв, цифр и символа подчеркивания. Мы можем использовать \W в простом регулярном выражении, чтобы разделить входной сигнал по чему-либо отличному от символов слов:
|
Заметим, что это дает нам пустые строки в начале и в конце (чтобы понять, почему, попробуйте выполнить 'хх'.split('х')). Мы получаем те же лексемы, но без пустых строк с помощью re.findall(r'\w+', raw), используя шаблон, который соответствует словам, а не пропускам. Теперь, когда мы ищем соответствующие слова, мы в состоянии расширить это регулярное выражение, чтобы охватить более широкий круг случаев. Регулярное выражение «\w+|\S\w*» сначала будет пытаться найти любую последовательность символов слов. Если совпадение не будет найдено, он будет пытаться найти любой символ, не являющийся пробелом (\S является дополнением \s), за которым следует символ слова. Это означает, что знаки препинания группируется с любыми следующими за ними буквами (например, 's), а последовательности из двух и более символов пунктуации разделяются.
|
Давайте обобщим \w+ в приведенном выше выражении, чтобы разрешить внутри слова дефис и апостроф: «\w+([-']\w+)*». Это выражение означает, что за \w+ следует ноль и более экземпляров [-']\w+; этому будут соответствовать hot-tempered и it's. (Мы должны включить ?: в это выражение по причинам, рассмотренным ранее.) Мы также добавим шаблон, соответствующий символам кавычки, чтобы отделить их от текста, который они обрамляют.
|
Выражение выше также включает в себя «[-.(]+», что приводит к тому, что двойной дефис, многоточие и открывающая скобка токенизируются отдельно.
Таблица 3.4 перечисляет применяемые в регулярных выражениях обозначения классов символов, которые мы видели в этом разделе, в дополнение к некоторым другим полезным обозначениям.
| Обозначения | Функция |
|---|---|
| \b | Граница слова (нулевая ширина) |
| \d | Любая десятичная цифра (эквивалент [0-9]) |
| \D | Любой нецифровой символ (эквивалент [^0-9]) |
| \s | Любой символ пробела (эквивалент [ \t\n\r\f\v]) |
| \S | Любой символ-непробел (эквивалент [^ \t \n\r \f\v]) |
| \w | Любой буквенно-цифровой символ (эквивалент [a-zA-Z0-9_]) |
| \W | Любой небуквенно-цифровой символ (эквивалент [^a-zA-Z0-9_]) |
| \t | Символ табуляции |
| \n | Символ новой строки | Таблица 3.4: Обозначения, применяемые в регулярных выражениях |
Основанный на регулярных выражениях токенизатор NLTK
Функция nltk.regexp_tokenize() похожа на re.findall() (поскольку мы использовали еее для токенизации). Тем не менее, nltk.regexp_tokenize() более эффективна для решения этой задачи и позволяет избежать специальной обработки скобок. Для удобства чтения разобьем регулярное выражение на несколько строк и добавим комментарий к каждой строке. Специальный (?х) "флаг отладки" говорит Python вырезать встроенные пробелы и комментарии.
|
При использовании флага отладки, вы больше не можете использовать ' ', чтобы найти символ пробела; вместо этого используйте \s. Функция regexp_tokenize() имеет дополнительный параметр gaps. Когда его значение Истина, регулярное выражение определяет промежутки между токенами так же, как с помощью функции re.split().
Замечание
Мы можем оценить токенизатор путем сравнения полученных токенов со словарем, с помощью отчета о токенах, которых нет в словаре, используя функцию set(tokens).difference(wordlist). Вы, вероятно, захотите сначала перевести все токены в нижний регистр.
Дальнейшие вопросы токенизации
Токенизация оказывается гораздо более трудной задачей, чем вы могли бы ожидать. Ни одно решение не работает одинаково хорошо во всех случаях, каждый раз мы должны определять, что считать токеном, в зависимости от области применения.
При разработке токенизатора полезно иметь доступ к необработанному тексту, который был вручную токенизирован, чтобы сравнить результат вашего токенизатора с высококачественными токенами (или "золотым стандартом"). Коллекция корпусов NLTK включает в себя образец данных Penn Treebank, в том числе необработанный текст Wall Street Journal (nltk.corpus.treebank_raw.raw()) и его токенизированную версию (nltk.corpus.treebank.words()).
Последний вопрос токенизации - наличие сокращений, таких как didn't. Если мы анализируем значение предложения, вероятно, будет более полезно восстановить эту форму до двух отдельных форм: did и n't (или not). Мы можем сделать эту работу с помощью таблицы соответствия.
3.8 Сегментация
В этом разделе обсуждаются более сложные понятия, которые вы возможно предпочтете пропустить, первый раз читая эту главу.
Токенизация является частным случаем более общей проблемы сегментации. В этом разделе мы рассмотрим два других случая этой проблемы, которые используют методы, радикально отличающиеся от тех, которые мы видели до сих пор в этой главе.
Выделение предложения
Работа с текстами на уровне отдельных слов часто предполагает способность разделить текст на отдельные предложения. Как мы уже видели, некоторые корпусы предоставляют доступ на уровне предложений. В следующем примере мы вычисляем среднее количество слов в предложении в корпусе Брауна:
|
В других случаях текст доступен только в виде потока символов. Перед тем как разделить текст на токены, мы должны сегментировать его на предложения. NLTK предоставляет для этого возможность, включая в себя выделитель предложений Punkt (Kiss & Strunk, 2006). Вот пример его использования для сегментации текста романа. (Обратите внимание, что если внутренние данные сегментатора были обновлены к тому моменту, когда Вы читаете это, вы увидите другой результат):
|
Обратите внимание на то, что этот пример действительно представляет собой одно предложение, передающее речь г-на Люсьена Грегори. Тем не менее приведенная речь содержит несколько предложений, и они были разделены на отдельные строки. Это разумное поведение для большинства приложений.
Сегментация на предложения - это трудная задача, потому что точка используется для обозначения аббревиатур, а некоторые точки одновременно показывают аббревиатуру и заканчивают предложение, как это часто бывает с акронимами, например U.S.A.
Чтобы увидеть другой подход к выделению предложений см. 2.
Выделение слов
Для некоторых систем письменности, токенизация текста является более трудной задачей, потому что в ней нет никакого визуального представления границ слова. Например, в китайском трехсимвольная строка: 爱国人 (ai4 "любить", guo2 "страна", ren2 "человек") может быть токенизирована, как 爱国 / 人, "человек, любящий страну" или как 爱/ 国人, "любить человека-страны".
Аналогичная проблема возникает при обработке разговорного языка, где слушающий должен сегментировать непрерывный поток речи на отдельные слова. Особенно сложная разновидность этой проблемы возникает тогда, когда мы не знаем слова заранее. Это проблема, с которой сталкивается изучающий язык, например, ребенок слушающий высказывания родителей. Рассмотрим следующий искусственный пример, где границы слов были удалены:
| '] |
|
Наша первая задача состоит в том, чтобы просто представить проблему: нам нужно найти способ, чтобы разделить содержимое текста в результате сегментации. Мы можем сделать это с помощью аннотирования каждого символа логическим значением, указывающим, появляется ли прерывание слов после символа (идея, которая будет активно использоваться для "чанкинга" в 7.). Давайте предположим, что обучающемуся даются паузы между высказываниями, так как они часто соответствуют продолжительным паузам. Вот возможное представление исходной и целевой сегментации:
|
Заметим, что строки сегментации состоят из нулей и единиц. Они на один символ короче исходного текста, так как текст длиной n может быть разделен только в n-1 местах. Функция segment() в 3.7 показывает, что мы можем получить первоначальный сегментированный текст из приведенного выше представления.
| ||
| ||
Пример 3.7 (code_segment.py): Рисунок 3.7: Реконструкция сегментированного текста из строки-представления: seg1 и seg2 представляют начальные и конечные сегментации некоторого гипотетического направленной ребенку речи; функция segment() может использовать их, чтобы воспроизвести сегментированный текст. |
Теперь задача сегментации становится задачей поиска: найти битовую строку, которая позволяет правильно разделить текстовую строку на слова. Мы предполагаем, что обучаемый приобретает слова и хранит их во внутреннем лексиконе. Имея подходящий словарный запас, можно восстановить исходный текст как последовательность лексических единиц. Следуя за (Brent, 1995), мы можем определить целевую функцию, функцию подсчета очков, значение которой мы будем пытаться оптимизировать, исходя из размера лексикона (количества символов в словах плюс дополнительный разделительный символ, чтобы обозначить конец каждого слова) и объема информации необходимого для реконструкции исходного текста из этого лексикона. Проиллюстрируем это в 3.8 .
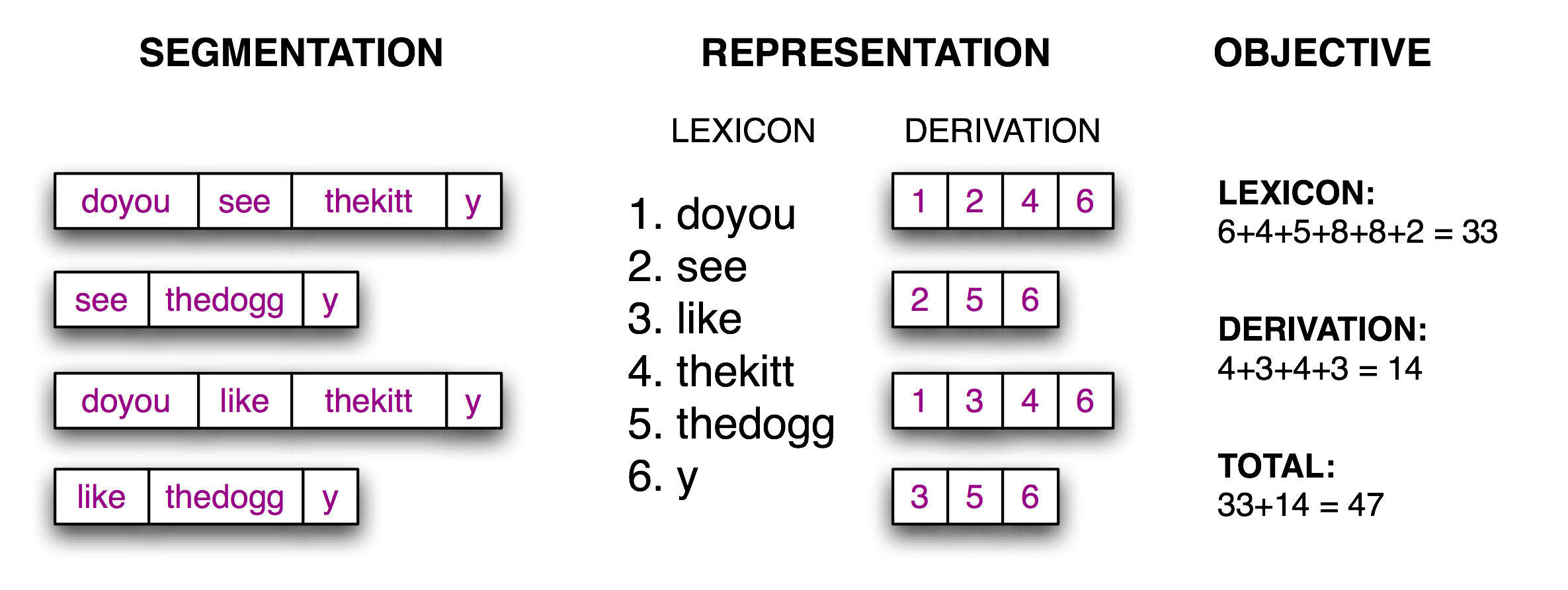
Рисунок 3.8: Расчет целевой функции: Имея гипотетическую сегментацию исходного текста (слева), вывести лексикон и таблицу деривации, которые позволяют реконструировать исходный текст, затем подсчитать количество символов, используемых каждым лексическим элементом (в том числе символом границы слова) и количество лексических единиц, используемых каждой деривацией, в качестве балла качества сегментации; меньшие количества баллов указывают на лучшую сегментацию.
Несложно реализовать эту целевую функцию так, как показано в листинге 3.9.
| ||
| ||
Пример 3.9 (code_evaluate.py) : Рисунок 3.9: Вычисление затрат хранения лексикона и восстанавления исходного текста |
Последний шаг заключается в поиске последовательности нулей и единиц, которая сводит к минимуму эту целевую функцию, как показано в листинге 3.10. Обратите внимание на то, что лучшая сегментация включает в себя такие "слова", как thekitty, так как в данных не хватает доказательств для дальнейшего разделения.
| ||
| ||
Пример 3.10 (code_anneal.py) : Рисунок 3.10: Недетерминистский поиск с использованием имитации эволюционирующего беспорядка (аннилинга): начинает поиск с сегментации на фразы; случайным образом возмущает нули и единицы пропорциональные "температуре"; при каждой итерации температура понижается и колебание границ уменьшается. Поскольку этот алгоритм поиска не является детерминистским, вы можете увидеть несколько иной результат. |
При наличии достаточного количества данных, можно автоматически сегментировать текст на слова с достаточной степенью точности. Такие методы могут быть применены к токенизации письменных систем, которые не имеют никакого визуального представления границ слова.
3.9 Форматирование: от списков к строкам
Часто мы пишем программу, чтобы сообщить об одном элементе данных, как, например, некотором элементе корпуса, который соответствует определенному сложному критерию, или одной итоговой величине, такой как подсчет слов или результативность программы разметки. Чаще всего мы пишем программу для получения структурированного результата, например, таблицы чисел или языковых форм или переформатирования исходных данных. Когда результаты, которые должны быть представлены, лингвистические, текстовый вывод обычно наиболее естественный выбор. Тем не менее, когда результаты численные, графический вывод может быть предпочтительным. В этом разделе вы узнаете о различных способов представления результатов программ.
От списков к строкам
Простейший структурированный объект, который мы используем для обработки текста, - это список слов. Когда мы хотим вывести их на дисплей или в файл, мы должны преобразовать эти списки в строки. Для этого в Python мы используем метод join(), а также указать строку, которая будет использоваться в качестве "клея" (связующего элемента).
|
Итак ' '.join(silly) означает: взять все элементы в silly и сцепить их как одну большую строку, используя ' ' в качестве разделителя между элементами. Т.е. join() является методом строки, которую вы хотите использовать в качестве соединителя. (Многие люди находят эту нотацию join() нелогичной). Метод join() работает только со списком строк - то, что мы называли текстом - сложный тип, который пользуется некоторыми привилегиями в Python.
Строки и форматы
Мы видели, что есть два способа отображения содержимого объекта:
|
Команда print дает представляет собой попытку Python произвести наиболее читаемую форму объекта. Второй метод - именования переменной в приглашении интерпретатора - показывает нам строку, которая может быть использована для воссоздания этого объекта. Важно иметь в виду, что оба из них просто строки, отображаемые на благо вам, пользователям. Они не дают нам никакого понятия относительно фактического внутреннего представления объекта.
Есть много других полезных способов отображения объекта в виде строки символов. Это может быть в интересах читателя-человека или потому, что мы хотим экспортировать наши данные в определенный формат файла для использования во внешней программе.
Форматированный вывод обычно содержит комбинацию переменных и предварительно заданных строк, например для распределения частот fdist мы могли бы сделать так:
|
Операторы печати, которые содержат чередующиеся переменные и константы может быть трудно читать и поддерживать. Другим решением является использование форматирование строк.
|
Чтобы понять, что здесь происходит, давайте проверим саму строку формата. (К настоящему времени это будет ваш обычный метод изучения нового синтаксиса.)
|
Фигурные скобки "{}" отмечают наличие поля замены: оно действует как заменитель строки значений объектов, которые передаются методу str.format(). Мы можем вставлять '{}' внутри строки, а затем заменить их строками, вызвав format() с соответствующими аргументами. Строка, содержащая поля замены, называется строкой формата.
Давайте дальше распакуем выше приведенный код, чтобы увидеть поближе это поведение:
|
Мы можем иметь любое количество заменителей, но метод str.format должен вызываться с точно таким же количеством аргументов.
|
Аргументы format() потребляются слева направо, и любые лишние аргументы просто игнорируются.
|
Имя поля в строке формата может начинаться с цифры, которая относится к позиции аргумента функции format(). Что-то вроде 'from {} to {}' эквивалентно 'from {0} to {1}', но мы можем использовать цифры, чтобы получить порядок отличный от порядка по умолчанию:
|
Мы также можем предоставить значения для заменителей косвенно. Вот пример использующий цикл for:
|
Выстраивание вещей в ряд
До сих пор наши строки формата генерировали вывод произвольной ширины на странице (или на экране). Мы можем добавить отступы, чтобы получить вывод заданной ширины, вставив внутри фигурных скобок двоеточие ":" с последующим целым числом. Так что {:6} указывает на то, что мы хотим строку, которая ограничена по ширине 6 символами. По умолчанию для чисел выравнивание осуществляется по правому краю , но мы можем поставить перед указателем ширины опцию выравнивания '<', чтобы числа выравнивались по левому краю .
|
По умолчанию строки выравниваются по левому краю, но с опцией выравнивания '>' они могут выравниваться по правому краю.
|
Другие управляющие символы могут быть использованы для указания знака и точности чисел с плавающей точкой; например {:.4f} указывает на то, что четыре цифры должны быть отображены после точки для числа с плавающей точкой.
|
Форматирование строки достаточно сообразительно, чтобы знать, что если вы включите '%' в свою спецификацию формата, то вы хотите представить значение в процентах; нет никакой необходимости умножать на 100.
|
Важным применением форматирования строк является представление данных в табличной форме. Напомним, что в 1 мы видели, что данные представлялись в табличной форме с помощью условного распределения частот. Давайте выполним табулирование данных сами, осуществляя полный контроль над заголовками и шириной столбцов, как показано в листинге 3.11. Обратите внимание на четкое разделение между работой по обработке языка и представлением результатов в табличной форме.
| ||
Пример 3.11 (code_modal_tabulate.py): Рисунок 3.11: Частота модальных глаголов в различных разделах корпуса Брауна |
Вспомните из листинга в 3.6, что мы использовали формат строки '{:{width}}' и связали значение с параметром width в format(). Это позволяет задать ширину поля, используя переменную.
|
Мы могли бы использовать эту функцию, чтобы автоматически настроить колонку так, чтобы она могла вместить все слова, используя width = max(len(w) for w in words).
Запись результатов в файл
Мы видели, как читать текст из файлов (3.1). Часто бывает полезно записывать выходные данные также в файлы. Следующий код открывает файл output.txt для записи и сохраняет выходные данные программы в файл.
|
Когда мы записываем нетекстовые данные в файл, мы должны сначала преобразовать их в строку. Мы можем сделать это преобразование с помощью форматирования строк, как мы видели выше. Запишем общее количество слов в наш файл:
|
Внимание!
Вы должны избегать имен файлов, содержащих пробелы, как, например, output file.txt, или которые идентичны, за исключением различия регистра, например Output.txt и output.TXT.
Перенос текста по словам
Когда результат нашей программы текстового типа, а не табличного, как правило, необходим перенос по словам, чтобы он отображался удобно. Рассмотрим следующий результат, который выходит за границы строки и использует сложное предложение print:
|
Мы можем позаботиться о переносе текста по словам с помощью модуля Python textwrap. Для максимальной ясности мы выделим каждый шаг в отдельную строку:
|
Обратите внимание на то, что между more и следующим за ним числом идет разрыв строки. Если мы хотим избежать этого, мы могли бы переопределить форматирование строки так, чтобы оно не содержало пробелов, например, '%s_(%d)', тогда вместо того, чтобы печатать значение wrapped, мы могли бы напечатать wrapped.replace('_', ' ').
3.10 Резюме
- В этой книге мы рассматриваем текст как список слов. "Сырой текст" (необработанный текст) потенциально представляет собой длинную строку, содержащую форматирование слов и пробелов, он представляет собой то, как мы обычно храним и визуализируем текст.
- Строка задается в Python с использованием одинарных или двойных кавычек: 'Monty Python', "Monty Python".
- Доступ к символам строки осуществляется с помощью индексов, считая от нуля: 'Monty Python'[0] дает значение М. Длина строка находится с помощью len().
- Подстроки доступны с помощью нотации среза: 'Monty Python'[1: 5] дает значение onty. Если начальный индекс опущен, то подстрока начинается с начала строки; если конечный индекс опущен, то срез продолжается до конца строки.
- Строки могут быть разделены на списки: 'Monty Python'.split() дает ['Monty', 'Python']. Списки могут быть объединены в строки: '/'.join(['Monthy', 'Python']) дает 'Monty/Python'.
- Мы можем прочитать текст из файла input.txt, используя text = open('input.txt').read(). Мы можем прочитать текст из url с помощью text = request.urlopen(url).read().decode('utf8'). Мы можем перебирать строки текстового файла, используя for line in open(f).
- Мы можем записать текст в файл, открыв файл для записи output_file = open( 'output.txt', 'w'), а затем добавить содержимое в файл print("Monty Python", file = output_file).
- Тексты, найденные в Интернете, могут содержать нежелательные материалы (например, заголовки, разметки), которые должны быть удалены, прежде чем сделать какую-либо лингвистическую обработку.
- Токенизация - это сегментация текста на основные единицы - или токены - такие, как слова и знаки препинания. Токенизация на основе пробелов недостаточна для многих приложений, поскольку она связывает знаки препинания со словами. NLTK предоставляет готовый токенизатор nltk.word_tokenize().
- Лемматизация это процесс, который находит соответствие различных форм слова (как, например, appeared, appears) к канонической, или цитируемой, форме слова, также известной как лексема или лемма (например, appear).
- Регулярные выражения являются мощным и гибким способом задания шаблонов. После того, как мы импортировали модуль re, мы можем использовать re.findall(), чтобы найти все подстроки в строке, соответствующие шаблону.
- Если строка регулярного выражения включает в себя обратную косую черту, вы должны сказать Python не обрабатывать строку, использовав сырую строку с префиксом r: r'regexp'.
- Когда обратный слэш используется перед определенными символами, например, \n, это приобретает особое значение (символ новой строки); однако, когда обратный слэш используется перед символами подстановки и операторами регулярных выражений, например, \., \|, \$, эти символы теряют свой особый смысл и для них ищется буквальное соответствие.
- Выражение форматирования строки template % arg_tuple состоит из шаблона формата строки template, который содержит параметры преобразования, такие как % -6s и % 0.2d.
7 Дополнительные материалы
Дополнительные материалы для этой главы размещены на странице http://nltk.org/, в том числе ссылки на свободно доступные ресурсы в сети. Не забудьте ознакомиться со справочными материалами Python на странице http://docs.python.org/. (К примеру, эта документация охватывает "универсальную поддержку новой строки", объясняя, как работать с различными соглашениями о новой строке, используемыми различными операционными системами.)
Для получения дополнительных примеров обработки слов с помощью NLTK см. HOWTO материалы по токенизации, стеммингу и корпусам на http://nltk.org/howto. Главы 2 и 3 (Jurafsky & Martin, 2008) содержат более продвинутый материал по регулярным выражениям и морфологии. Для ознакомления с более широким обсуждением обработки текста с помощью Python см. (Mertz, 2003). Для получения информации о нормализации нестандартных слов см. (Sproat et al, 2001)
Существует множество руководств по регулярным выражениям, как практических, так и теоретических. Вводный курс по использованию регулярных выражений в Python, см. Regular Expression HOWTO автора Kuchling на сайте http://www.amk.ca/python/howto/regex/. Для получения всестороннего и детального руководства по использованию регулярных выражений, охватывающего их синтаксис в большинстве основных языков программирования, включая Python, см. (Friedl, 2002). Другие презентации включают раздел 2.1 (Jurafsky & Martin, 2008), а также главу 3 (Mertz, 2003).
Есть много интернет-ресурсов по Юникод. Полезными обсуждениями возможностей языка Python для работы с Юникод являются:
- Ned Batchelder, Pragmatic Unicode, http://nedbatchelder.com/text/unipain.html
- Unicode HOWTO, Документация Python, http://docs.python.org/3/howto/unicode.html
- David Beazley, Mastering Python 3 I/O, http://pyvideo.org/video/289/pycon-2010--mastering-python-3-i-o
- Joel Spolsky, The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets, (No Excuses!), http://www.joelonsoftware.com/articles/Unicode.html
Проблема токенизации китайского текста является одним из основных направлений SIGHAN, ACL специальной группы по обработке китайского языка http://sighan.org/. Наш метод сегментирования английского текста следует за (Brent, 1995); эта работа падает в область освоения языка (Niyogi, 2006).
Словосочетания являются частным случаем выражений, состоящих из нескольких слов. Выражение, состоящее из нескольких слов - это небольшая фраза, смысл и другие свойства которой не могут быть предсказаны исходя из ее слов взятых по отдельности, например, часть речи (Baldwin & Kim, 2010).
Имитации "обжига" является эвристичной для нахождения хорошего приближения к оптимальному значению функции в большой, дискретном пространстве поиска, понятие основано на аналогии с обжигом в металлургии. Методика описана во многих текстах по искусственному интеллекту.
Подход к обнаружению гипонимов в тексте с использованием шаблонов поиска, таких как х и другие у-ки описывается (Херст, 1992).
3.12 Упражнения
☼ Определение 'бесцветные' в строку S =. Написать заявление Python, который изменяет это "бесцветные", используя только срез и конкатенации операций.
☼ Мы можем использовать срез обозначения для удаления морфологических окончаний слов. Например, 'собак [-1] удаляет последний символ собак, оставляя собаку. Используйте ломтика обозначения для удаления суффиксов из этих слов (мы вставили дефис , чтобы указать границу аффикс, но пропустить это из ваших строк): блюдо-эс, бегите-нин, нация-Эк, ун-делать, предварительного нагрева ,
☼ Мы видели , как мы можем генерировать IndexError путем индексации за пределы конца строки. Можно ли построить индекс, который идет слишком далеко влево, до начала строки?
☼ Мы можем определить "шаг" размер для среза. Следующие возвращается каждый второй символ в срезе: Monty [6: 11: 2]. Он также работает в обратном направлении: Monty [10: 5: -2] Попробуйте это для себя, то экспериментировать с различными значениями шага.
☼ Что произойдет , если вы попросите переводчика оценить Monty [:: - 1]? Объясните, почему это разумный результат.
☼ Опишите класс строк совпавших с помощью следующих регулярных выражений.
- [A-Za-Z] +
- [AZ] [AZ] *
- р [аеиоу] {2} т
- \ D + (\. \ D +)?
- ([^ Аеиоу] [аеиоу] [^ аеиоу]) *
- \ Ш + | [^ \ ш \ s] +
Проверьте свои ответы с помощью nltk.re_show ().
☼ Пишите регулярные выражения, чтобы соответствовать следующие классы строк:
- Один Определитель (предположим , что, ап, и являются единственными определители).
- Арифметическое выражение с помощью целых чисел, сложение, умножение и, например, 2 * 3 + 8.
☼ Написать функцию полезности, которая принимает URL в качестве аргумента, и возвращает содержимое URL, со всеми HTML-разметки удалены. Используйте из запроса URLLIB импорта , а затем request.urlopen ( 'http://nltk.org/') .read (). Декодировать ( 'utf8') , чтобы получить доступ к содержимому в URL.
☼ Сохранить текст в файл corpus.txt. Определим функцию нагрузки (F) , который считывает из файла с именем в его единственного аргумента, и возвращает строку , содержащую текст файла.
- Используйте nltk.regexp_tokenize () для создания токенизатор , что размечает различные виды знаков препинания в тексте. Используйте один многострочный регулярных выражений, с встроенных комментариев, используя флаг отладки (?х).
- Используйте nltk.regexp_tokenize () , чтобы создать токенизатор , что размечает следующие виды выражения: денежные суммы; даты; имена людей и организаций.
☼ Перепишите следующий цикл в виде списка понимания:
>>> Послал = [ 'The', 'собака', 'дал', 'Джон', 'The', 'газета'] >>> результат = [] >>> за слово в отправлено: ... word_len = (слово, Len (слово)) ... result.append (word_len) >>> результат [( 'The', 3), ( 'собака', 3), ( 'дал', 4), ( 'John' , 4), ( далее « ', 3), (' газета ', 9)]
☼ Определите строку , содержащую сырец предложение по собственному выбору. Теперь разбейте сырое на какой - то символ, кроме пространства, такие как 'S'.
☼ Написать цикл для вывода на печать символов строки, по одному в каждой строке.
☼ В чем разница между вызовом разделить на строку без аргументов или с '' в качестве аргумента, например , sent.split () по сравнению с sent.split ( '')? Что происходит, когда строка является разделение содержит символы табуляции, последовательных символов пробела, или последовательность вкладок и пространств? (В холостом режиме вам нужно будет использовать '\ т' , чтобы ввести символ табуляции.)
☼ создать переменную слова , содержащие список слов. Эксперимент с words.sort () и отсортированных (слова). В чем разница?
☼ Исследуйте разницу между строками и целыми числами, введя следующую команду в приглашении Python: "3" * 7 и 3 * 7. Попробуйте преобразование между строками и целыми числами , используя Int ( "3") и ул (3).
☼ Используйте текстовый редактор , чтобы создать файл с именем prog.py , содержащий единственную строку Monty = 'Монти Пайтон'. Затем начать новый сеанс работы с интерпретатором Python, и введите выражение Monty в командной строке. Вы получите сообщение об ошибке от переводчика. Теперь попробуйте следующее (обратите внимание , что вы должны убирание .py часть файла):
>>> Из прог импорта Monty >>> Monty
На этот раз, Python должен вернуться со значением. Вы также можете попробовать импорта прогу, в этом случае Python должен быть способен оценить выражение prog.monty в командной строке.
☼ Что происходит , когда строки форматирования% 6с и% -6s используются для отображения строк, которые длиннее шести символов?
◑ Читайте в какой - нибудь текст из корпуса, разметить его, и распечатать список всех Wh -Word типов , которые происходят. (WH -слов на английском языке используются в вопросах, относительных положений и восклицаниями: кто, что, что, и так далее.) Распечатать их в порядке. Существуют ли слова продублированы в этом списке, из-за наличия конкретных различий и знаков препинания?
◑ Создайте файл , состоящий из слов и (составил) частот, где каждая строка состоит из слова, символ пробела, и положительное целое число, например , нечеткое 53. Прочитайте файл в список Python с использованием открытых (имя файла) .readlines (). Затем разбить каждую строку в свои два поля с помощью разделения (), и преобразовать число в целое число , используя Int (). Результат должен быть список вида: [[ 'нечеткие', 53], ...].
◑ Написать код для доступа к любимым веб-страницу и извлечь текст из него. Например, доступ к сайту погоды и извлечь верхнюю температуру прогноз для вашего города или города сегодня.
◑ Написать функцию неизвестно () , который принимает URL в качестве аргумента, и возвращает список неизвестных слов , которые происходят на этой странице. Для того , чтобы сделать это, извлечь все подстроки , состоящие из строчных букв ( с помощью re.findall ()) и удалите все элементы из этого набора , которые происходят в словах корпус (nltk.corpus.words). Попробуйте классифицировать эти слова вручную и обсудить ваши выводы.
◑ Рассмотрение результатов обработки URL http://news.bbc.co.uk/~~HEAD=dobj с использованием регулярных выражений , предложенных выше. Вы увидите, что есть еще достаточное количество нетекстовых данных существует, в частности, Javascript команды. Вы также можете обнаружить, что приговор перерывы не были должным образом сохранены. Определить дополнительные регулярные выражения, которые улучшают извлечение текста из этой веб-страницы.
◑ возможность написать регулярное выражение для разметить текст таким образом , что слово не разбивается на лексемы в делать и не вы? Объясните , почему это регулярное выражение не будет работать: «не | \ ш +».
◑ Попробуйте написать код для преобразования текста в hAck3r, используя регулярные выражения и подстановки, где е → 3, я → 1, O → 0, l → | , S → 5. → 5w33t! , Ели → 8. Нормализация текст в нижний регистр перед преобразованием его. Добавьте несколько замен ваших собственных. Теперь попытайтесь сопоставить с до двух различных значений: $ для начале слова с и 5 для слов-внутренняя с.
◑ латынь Свиньи является простое преобразование английского текста. Каждое слово текста преобразуется следующим образом : переместить любой согласной (или согласного кластера) , который появляется в начале слова до конца, а затем добавить ау, например , строка → ingstray, холостой → idleay. http://en.wikipedia.org/wiki/Pig_Latin
- Написать функцию, чтобы преобразовать слово Свинья латыни.
- Написать код, который преобразует текст, а не отдельных слов.
- Продлить его дальше , чтобы сохранить капитализацию, чтобы сохранить Цюй вместе (т.е. так , что становится тихо ietquay), а также определить , когда у используется как согласного (например , желтый) против гласной (например , стиль).
◑ Скачать текст с языка, который имеет гласный гармонию (например, венгерский), экстракт гласного последовательности слов, и создать таблицу гласный Биграммные.
Случайным образом модуль ◑ Python включает в себя выбор функции () , который случайным образом выбирает элемент из последовательности, например , выбор ( "aehh") будет производить один из четырех возможных символов, с буквой ч быть в два раза чаще, чем другие. Написать выражение генератор , который производит последовательность из 500 случайно выбранных букв , взятых из строки "aehh", и поместить это выражение внутри вызова функции '' .join (), чтобы объединить их в одну длинную строку. Вы должны получить результат , который выглядит как неконтролируемое чихание или маниакальный смех: он хаха эи heheeh Пьеха. Используйте раскол () и присоединиться к () еще раз , чтобы нормализовать пропуски в этой строке.
◑ Рассмотрим числовые выражения в следующем предложении из МедЛайн Корпус: Соответствующие фракции свободного кортизола в этих сывороток были 4,53 +/- 0,15% и 8,16 +/- 0,23%, соответственно. Если мы говорим , что числовое выражение 4,53 +/- 0,15% три слова? Или мы должны сказать, что это одно сложное слово? Или мы должны сказать , что это на самом деле девять слов, так как он прочитал "четыре целых пять три, плюс или минус ноль целых пятнадцать процентов"? Или мы должны сказать, что это не "реальное" слово вообще, так как он не будет появляться в любом словаре? Обсудите эти различные возможности. Вы можете думать о доменах приложений, которые мотивируют по крайней мере, два из этих ответов?
меры ◑ удобочитаемости используются для чтения забить трудности текста, для целей отбора текстов соответствующей сложности для изучающих язык. Определим μ ш быть среднее число букв в слове, и ц ы быть среднее число слов в предложении, в данном тексте. Автоматизированная индекс удобочитаемости (ARI) текста определяется как: 4,71 μ W + 0,5 мкм с - 21,43. Подсчитать счет ARI для различных участков Браун корпус, в том числе раздел F (краеведческом) и J (уроки). Используйте тот факт , что nltk.corpus.brown.words () создает последовательность слов, в то время как nltk.corpus.brown.sents () создает последовательность предложений.
◑ Используйте Porter Штеммер нормализовать некоторые текст разбивается на лексемы, вызывая Штеммер на каждом слове. Сделайте то же самое с Lancaster Stemmer и посмотреть, если вы заметили какие-либо различия.
◑ Определите переменную говоривший содержит список [ 'После', 'все', 'есть', 'сказал', 'и', 'сделал', ',', 'больше', 'есть', '' сказал, ' , чем', 'сделано', '.' ]. Процесс этот список , используя для цикла, и сохранить длину каждого слова в новой длины списка. Подсказка: начните путем присвоения пустой список длин, используя длину = []. Тогда каждый раз через петлю, используйте Append () , чтобы добавить другое значение длины к списку. Теперь сделайте то же самое, используя список понимание.
◑ Определить переменную глупо содержать строку: 'новообразованные мягкие идеи невыразимое в бешенство способом. (Это происходит с законной интерпретации , что двуязычные английский-испанский язык можно присвоить известной нонсенс фразе Хомского, бесцветные зеленые идеи яростно спят согласно Википедии). Теперь написать код для выполнения следующих задач:
- Сплит глупо в список строк, по одному на слово, используя операцию Питона сплит (), и сохранить это в переменную под названием пресным.
- Извлечь вторую букву каждого слова в глупой и присоединиться к ним в строку, чтобы получить 'eoldrnnnna'.
- Объедините слова в пресным обратно в одну строку, используя присоединиться (). Убедитесь, что слова в результирующей строке разделены пробелами.
- Печать слова глупо в алфавитном порядке, по одному в каждой строке.
◑ Функция индексации () может быть использован для просмотра элементов в последовательности. Например, "невыразимое" .index ( 'е') говорит нам индекс первой позиции буквой е.
- Что происходит , когда вы смотрите подстроку, например 'невыразимую' .index ( 'ре')?
- Определить переменную слова , содержащие список слов. Теперь используйте words.index () для поиска позиции отдельного слова.
- Определить переменную глупо , как в приведенном выше упражнении. С помощью функции индекса () в сочетании с список нарезка для создания списка фразу , состоящую из всех слов , вплоть до (но не включая) в в глупой.
◑ Написать код для преобразования национальной принадлежности прилагательных , как канадский и австралийский их соответствующих существительных Канады и Австралии (см http://en.wikipedia.org/wiki/List_of_adjectival_forms_of_place_names).
◑ Прочитайте пост LanguageLog на фразы вида , как лучше всего, как р может и как лучший р может, где р является местоимение. Исследовать это явление с помощью корпуса и метода FindAll () для поиска текста разбивается на лексемы , описанный в 3.5 . http://itre.cis.upenn.edu/~myl/languagelog/archives/002733.html
◑ Изучите версию Lolcat книги Бытия, доступной в качестве nltk.corpus.genesis.words ( 'lolcat.txt') и правила преобразования текста в lolspeak в http://www.lolcatbible.com/index.php ? название = How_to_speak_lolcat. Определить регулярные выражения для преобразования английских слов в соответствующие lolspeak слова.
◑ Читайте о функции re.sub () для подстановки строк с использованием регулярных выражений, используя помощь (re.sub) и консультационная дальнейшие показания для этой главы. Используйте re.sub в написании кода для удаления HTML - теги из HTML - файла, а также нормализовать пропуски.
★ интересный вызов для токенизации это слова, которые были разбиты на разрыв строки. Например , если долгосрочный делится, то мы имеем строку долго- \ nterm.
- Написать регулярное выражение, которое идентифицирует слова, которые пишутся через дефис на разрыв строки. Выражение нужно будет включать \ п характер.
- Используйте re.sub () , чтобы удалить \ п символ из этих слов.
- Как вы могли бы определить слова , которые не должны оставаться дефис после того , как символ новой строки удаляется, например , 'энциклопедий \ npedia'?Икс
★ Прочитайте статью в Википедии на Soundex. Реализовать этот алгоритм в Python.
★ Получить исходные тексты из двух или более жанров и вычислить их соответствующие оценки сложности чтения, как в предыдущем упражнении на чтение трудности. Например , сравнить ABC Rural News и ABC Science News (nltk.corpus.abc). Используйте Punkt для выполнения сегментации предложения.
★ Перепишите следующий вложенный цикл в виде вложенного списка понимания:
>>> Слова = [ 'атрибуции', 'болтовня', 'ораторское', ... 'секвойи', 'цепкий', 'однонаправленная'] >>> vsequences = множество () >>> за словом в словах:. .. гласные = [] ... для полукокса в слове: ... если символ в 'AEIOU': ... vowels.append (полукокса) ... vsequences.add ( '' .join (гласные)) >> > сортируется (vsequences) [ 'aiuio', 'eaiou', 'eouio', 'euoia', 'oauaio', 'uiieioa']
★ Используйте WordNet для создания семантического индекса для текста коллекции. Расширение программы поиска согласованием в 3.6 , индексировать каждое слово , используя смещение его первого synset, например wn.synsets ( 'собака') [0] .offset (и , возможно смещение некоторых из его предков в иерархии hypernym).
★ С помощью многоязычного корпуса , таких как Всеобщая декларация прав человека Тела (nltk.corpus.udhr) и NLTK - х распределение частот и функциональность корреляции рангов (NLTK.FreqDist, nltk.spearman_correlation), разработать систему , которая угадывает язык ранее невидимого текста. Для простоты работы с одной кодировки символов и несколько языков.
★ Напишите программу, которая обрабатывает текст и обнаруживает случаи, когда слово было использовать с новым смыслом. Для каждого слова, вычислить сходство WordNet между всеми synsets этого слова и всех synsets слов в его контексте. (Обратите внимание, что это грубый подход, делает это хорошо является сложной, открытой проблемой исследования.)
★ Читайте статью о нормализации нестандартных слов (Спрот и др, 2001) , и внедрить подобную систему для текста нормализации.
Об этом документе ...
Обновлялся для NLTK 3.0. Это глава из книги Обработка естественного языка с помощью Python написанной Стивеном Бердом , Эваном Клайном и Эдвардом Лопером , Copyright © 2014 авторов. Он распространяется с Набором инструментов для естественного языка [http://nltk.org/], версия 3.0 в соответствии с условиями Creative Commons Attribution-Noncommercial-No Derivative Works 3.0 Лицензии Соединенных Штатов [ http://creativecommons.org/licenses/by-nc-nd/3.0/us/].
Этот документ был построен на ср 1 июля 2015 12:30:05 AEST