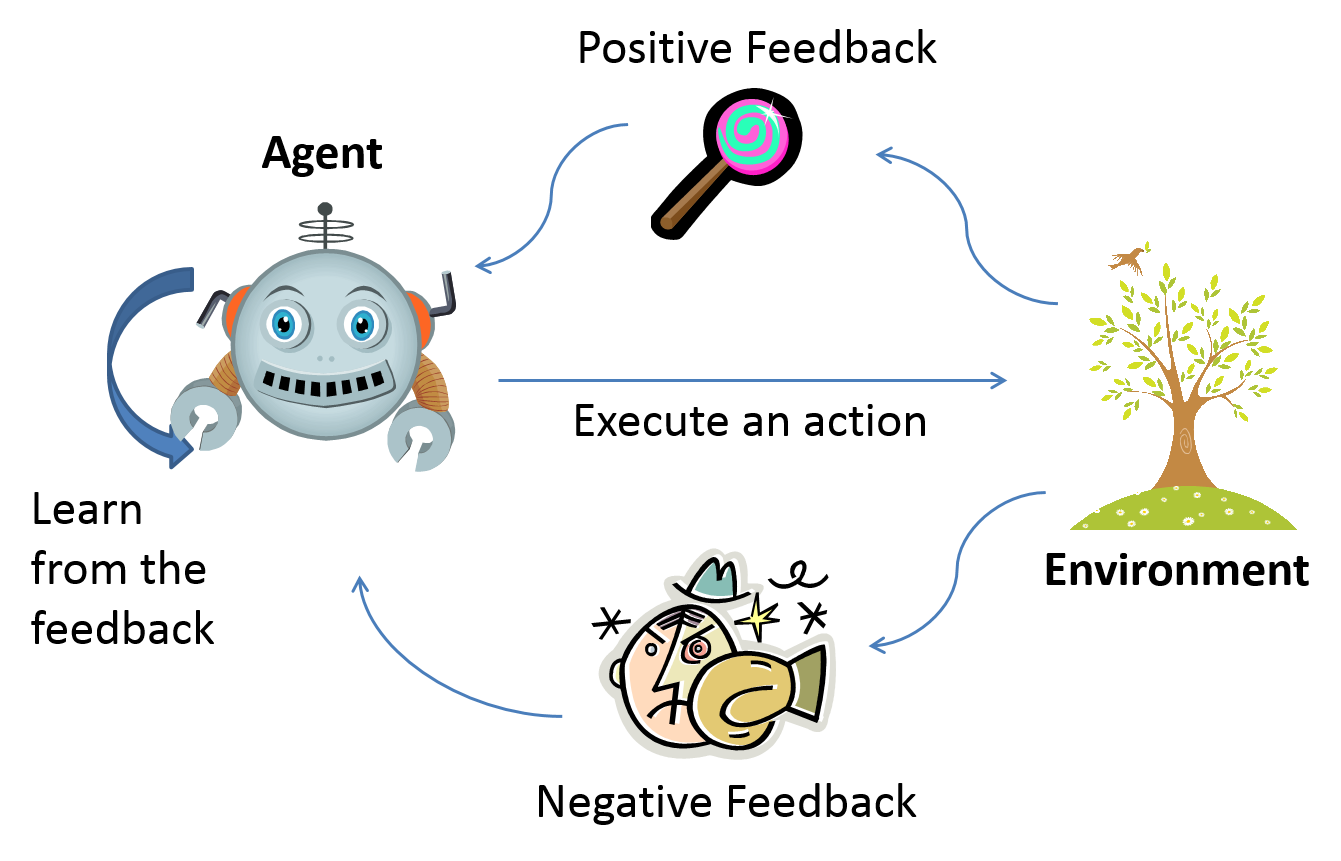
Reinforcement Learning
Q-learning
Updates the q-value of a state-action pair after the action has been taken in the state and an immediate reward has been received.
What is the meaning of update the q-value of a state ?
Q(s,a)
r
fitness ( )
= Q(s,a) +
Q(s,a) = Q(s,a) + ( α * r )
Q(s,a) = 0 + ( α * r )
Q(s,a) = 0 + ( α * 0 )
Q(s,a) = 0 + ( 0.3 * 0 )
0.6 = 0 + ( 0.3 * 0 )
-2.4 = 0.6 + ( 0.3 * -10 )
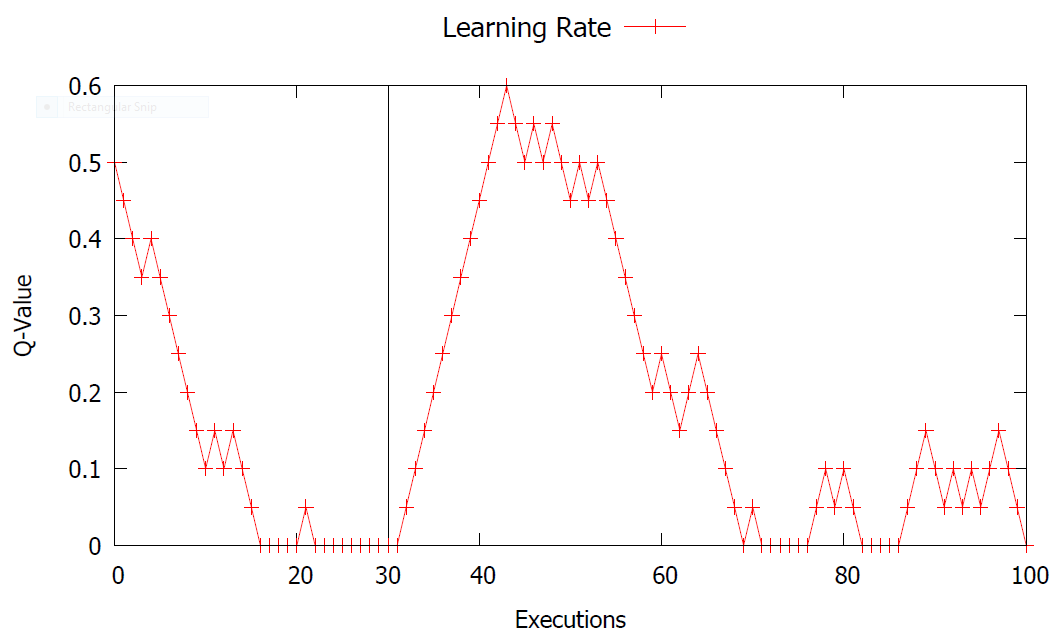
Parameter Control
by controlling α (learning-rate)
Should it be high? low?
varying?
Action Selection: ε-greedy
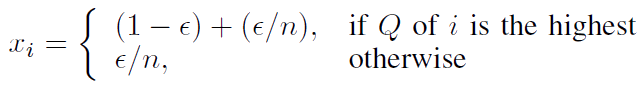
Exploration policy has probability ε to select a random action, and probability 1 - ε to select the better known action.
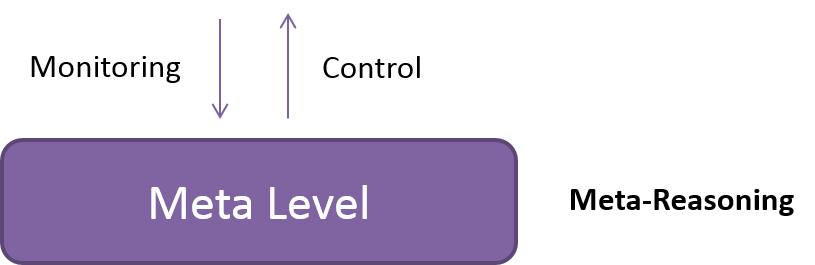
Meta-Level Reasoning
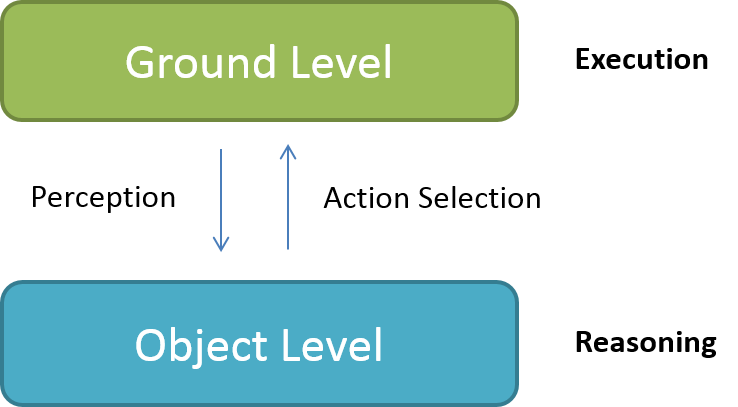
Meta-Level Reasoning
StarCraft: Brood War


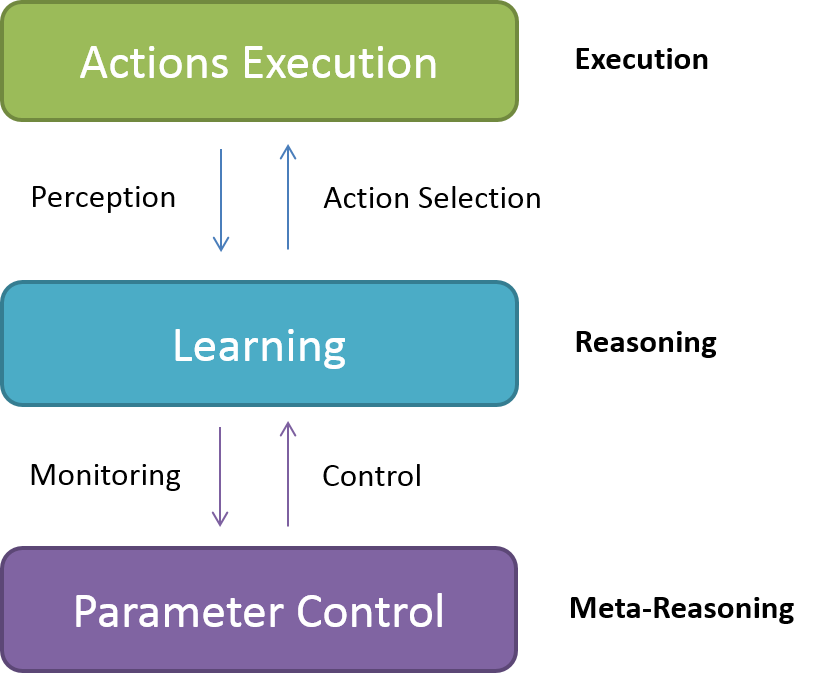
Meta-Level Reinforcement Learning
Meta-Level Reasoning
Meta-Level Reasoning
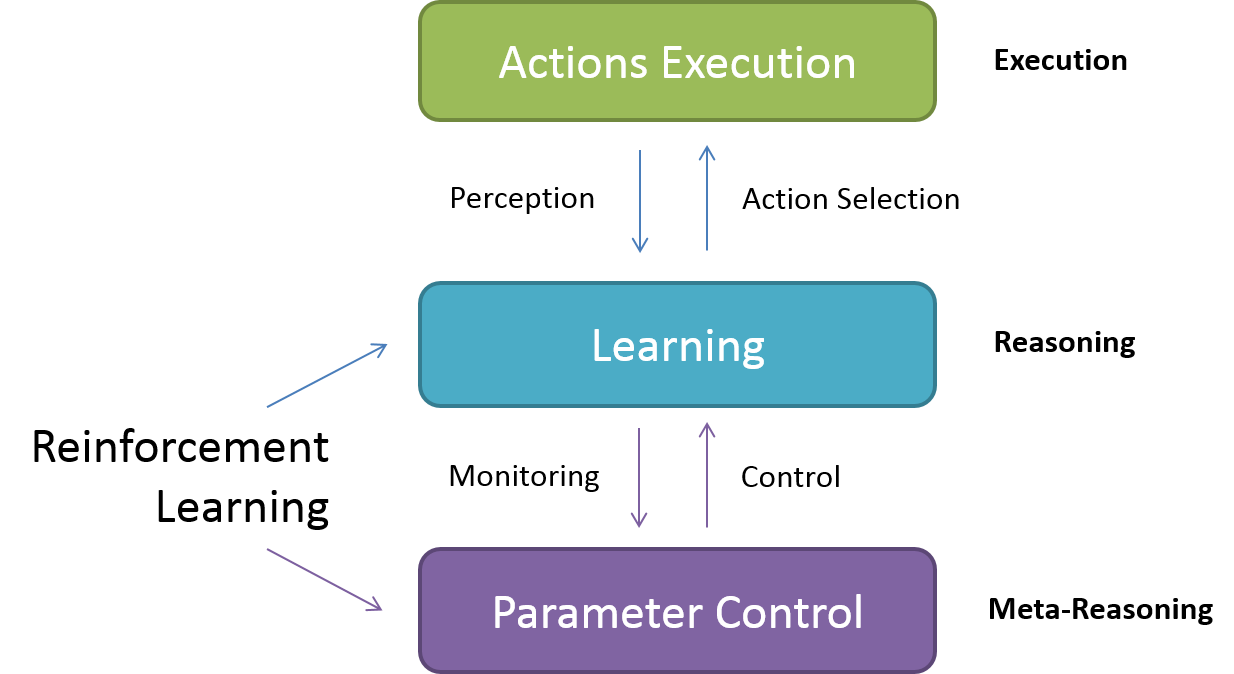
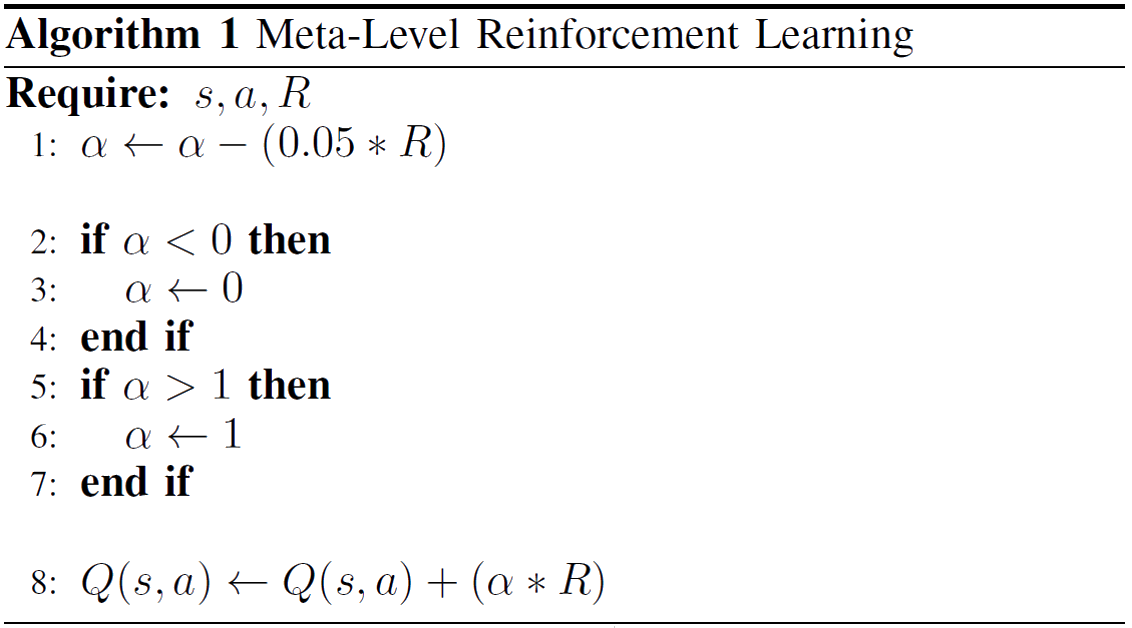
Meta-Level Reasoning
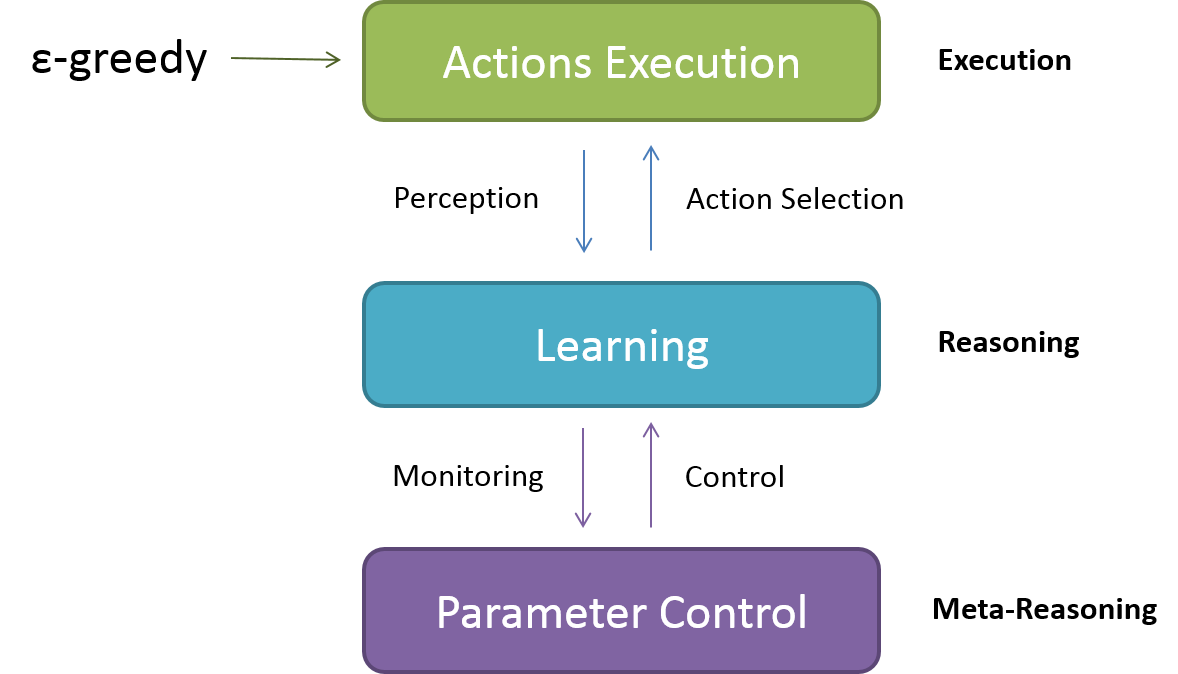
ε-greedy was modified
ε = (α / 2)
Instead of keeping a constant exploitation-rate, we applied meta-reasoning on ε-value too. It keeps exploration-rate equals to half of learning-rate.
Code Injection in StarCraft
BWAPI -
Framework in C++ to inject code at StarCraft
BTHAI -
BWAPI implemented bot, with some pre-made high-level strategies
Learning Approach for StarCraft
High-Level Strategy:
Learning and selection of high-level strategies, not atomic tasks;
At end of each match
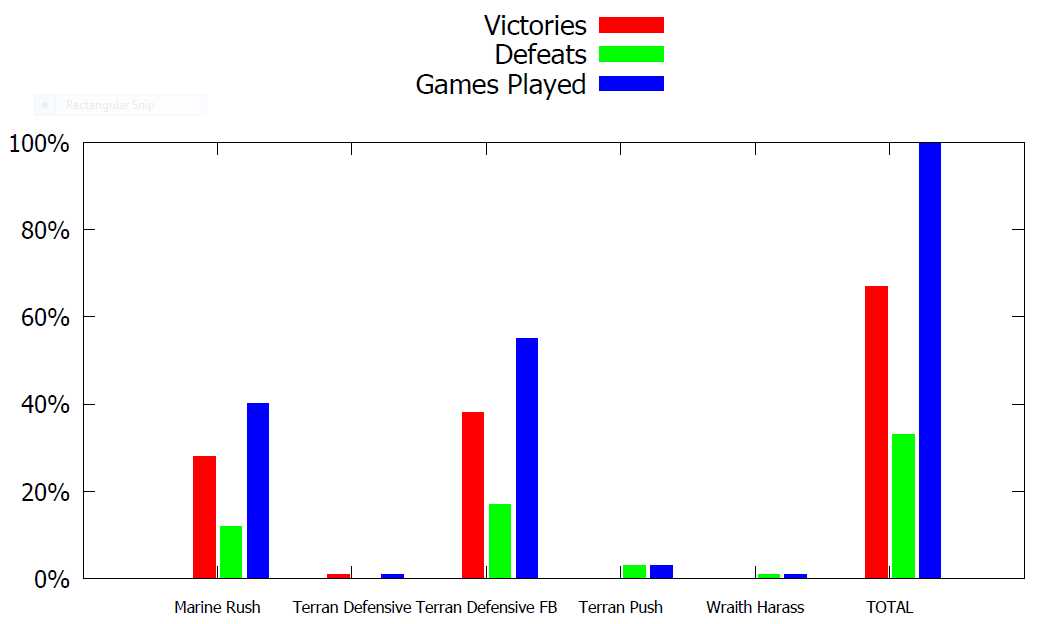
Victory Feedback: +1
Defeat Feedback: -1
Terran vs Built in CPU:
The learning agent always plays as Terran.
Terran Strategies in BTHAI
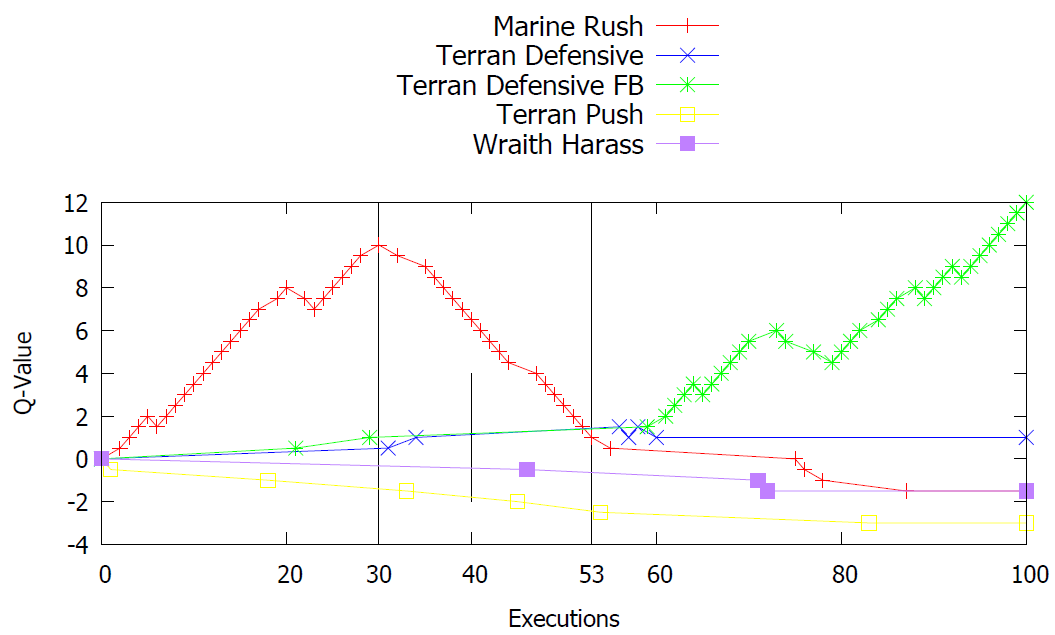
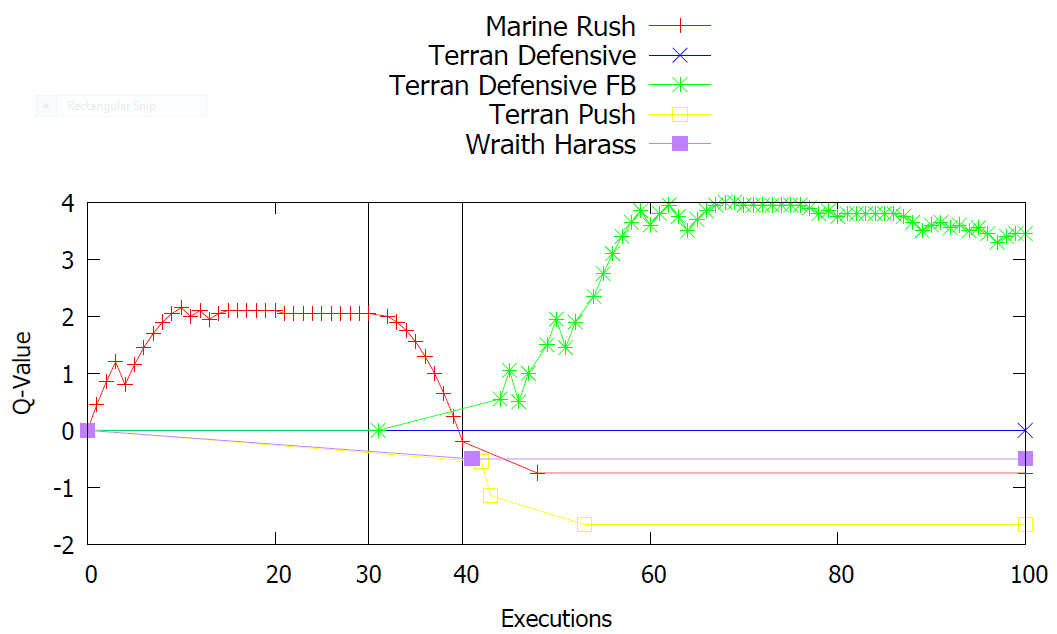
- Marine Rush
- Wraith Harass
- Terran Defensive
- Terran Defensive FB
- Terran Push
Results
Using Q-Learning
Using Meta-Level Reinforcement Learning
Learning-rate Overtime
Victories vs Defeats