Histogram of correlated \(z\) scores, Part 3
Lei Sun
2017-03-10
Last updated: 2017-03-10
Code version: 894c395
Introduction
From previous simulation on FDR on correlated null we get a sense that Benjamini-Hochberg is surprisingly robust under correlation. At the same time, there are cases when BH erroneously produces a large number of false discoveries. Therefore, we take a close look at those data sets BH fails on.
Simulation
z = read.table("../output/z_null_liver_777.txt")
p = read.table("../output/p_null_liver_777.txt")
n = dim(z)pihat0 = read.table("../output/pihat0_z_null_liver_777.txt")
pihat0 = as.numeric(t(pihat0))fd.bh = c()
for (i in 1 : n[1]) {
p_BH = p.adjust(p[i, ], method = "BH")
fd.bh[i] = sum(p_BH <= 0.05)
}Result
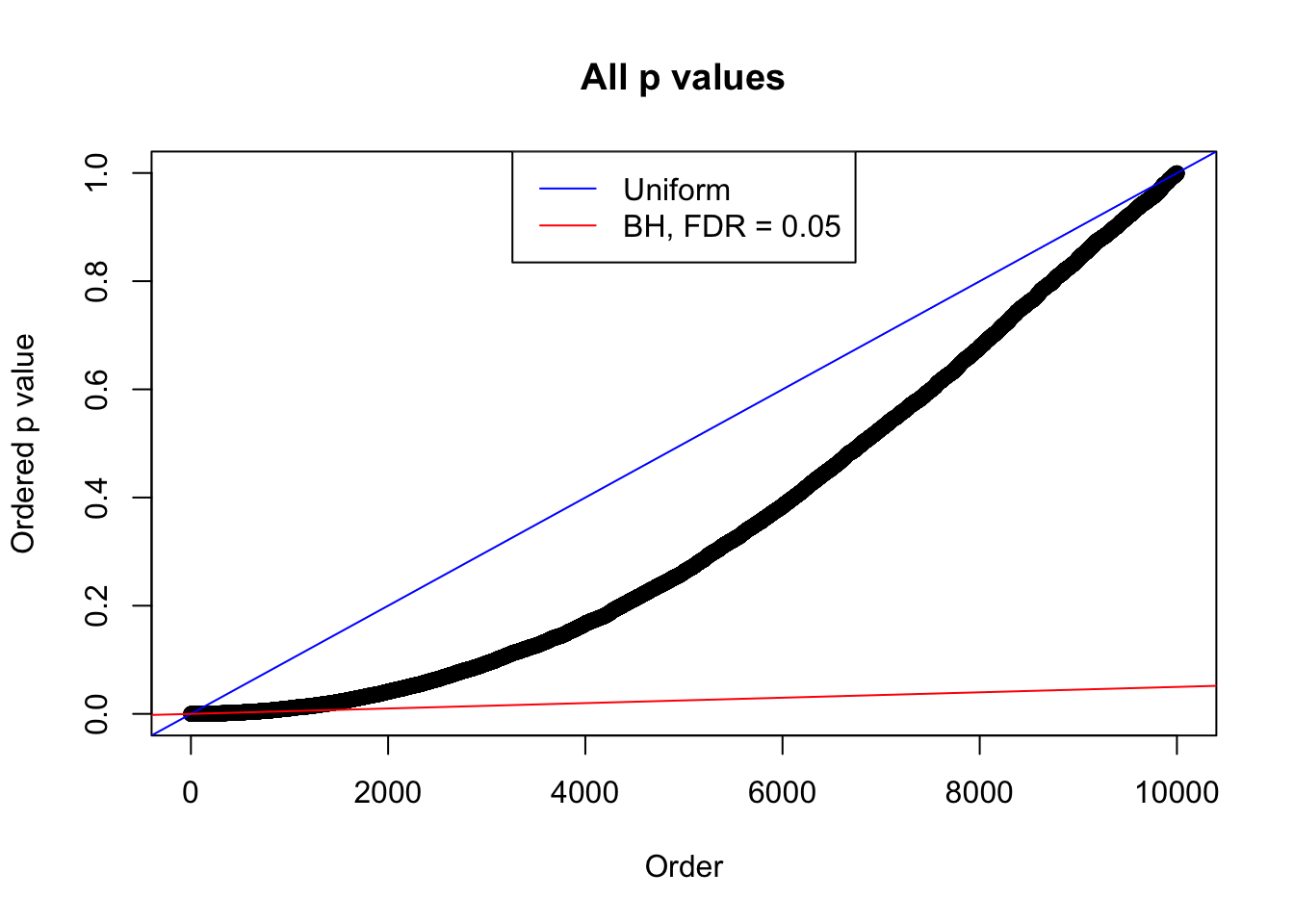
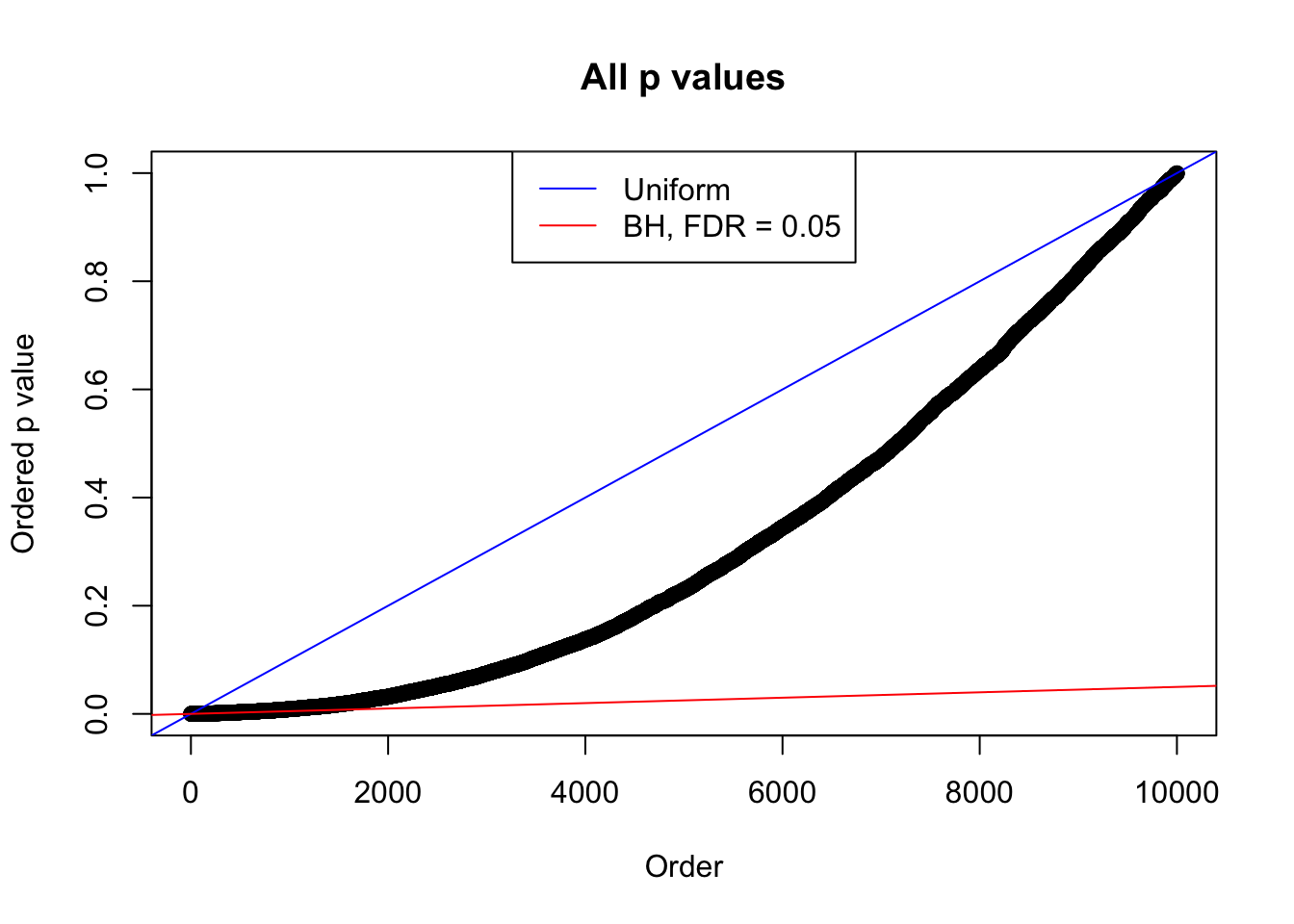
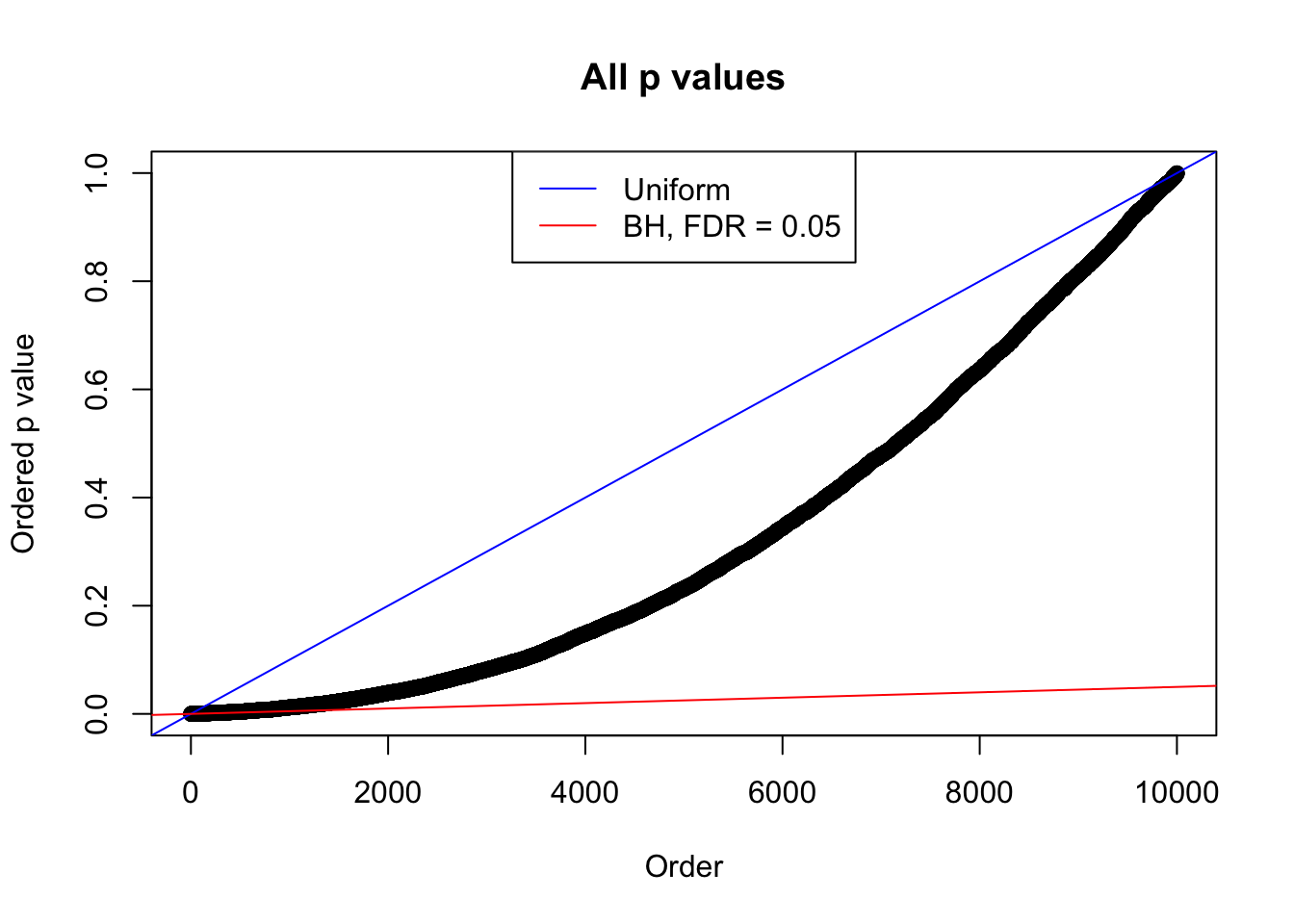
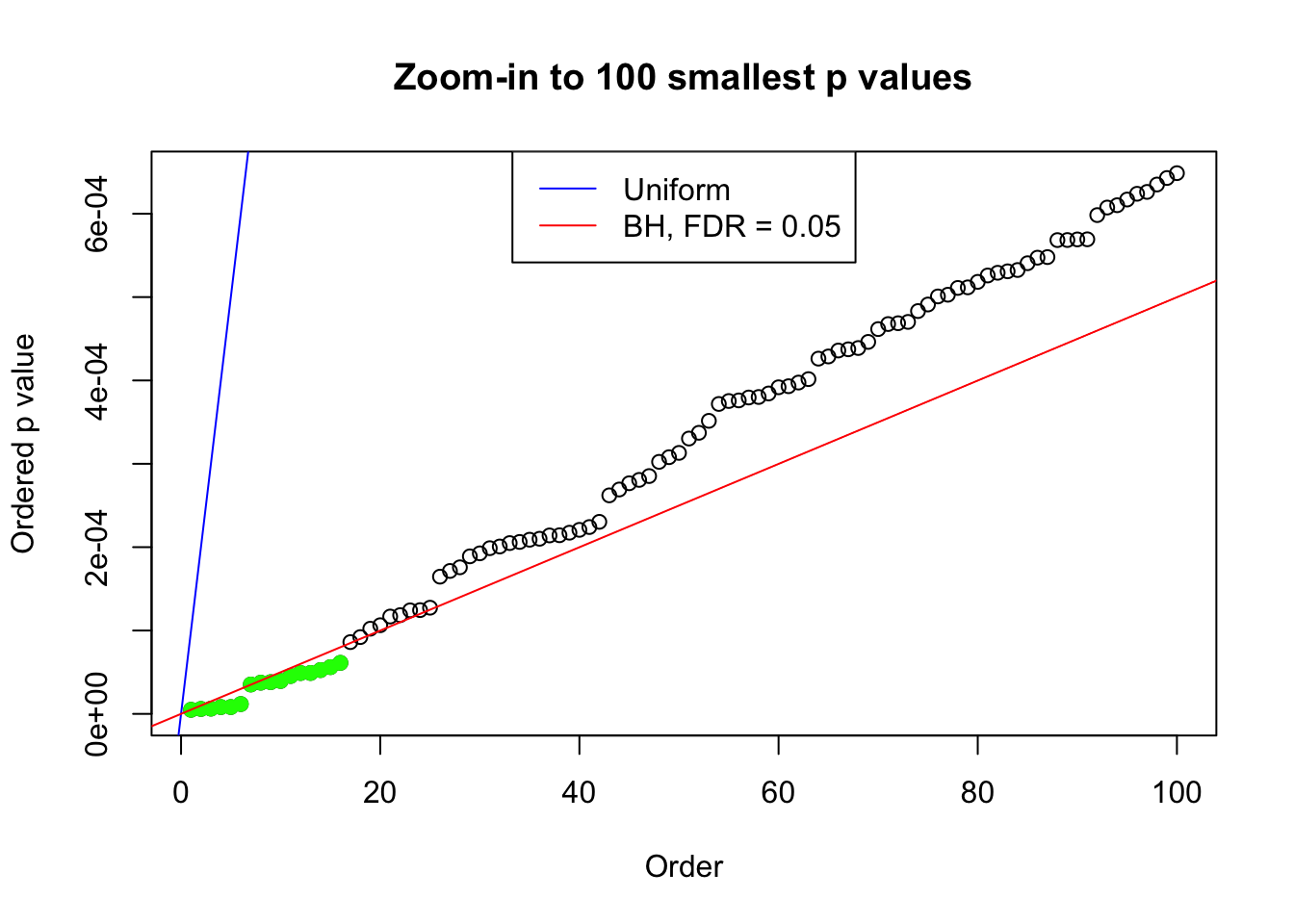
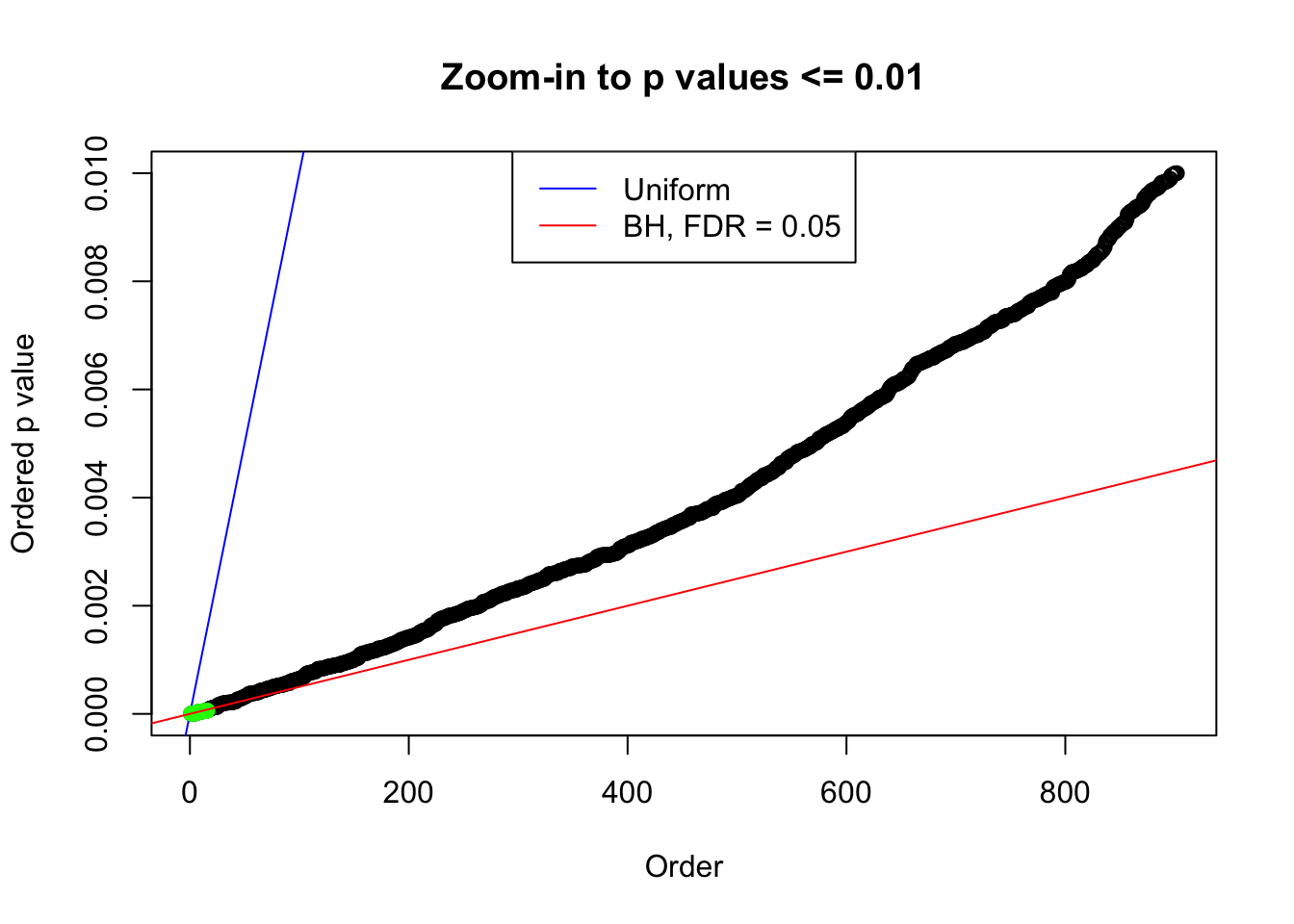
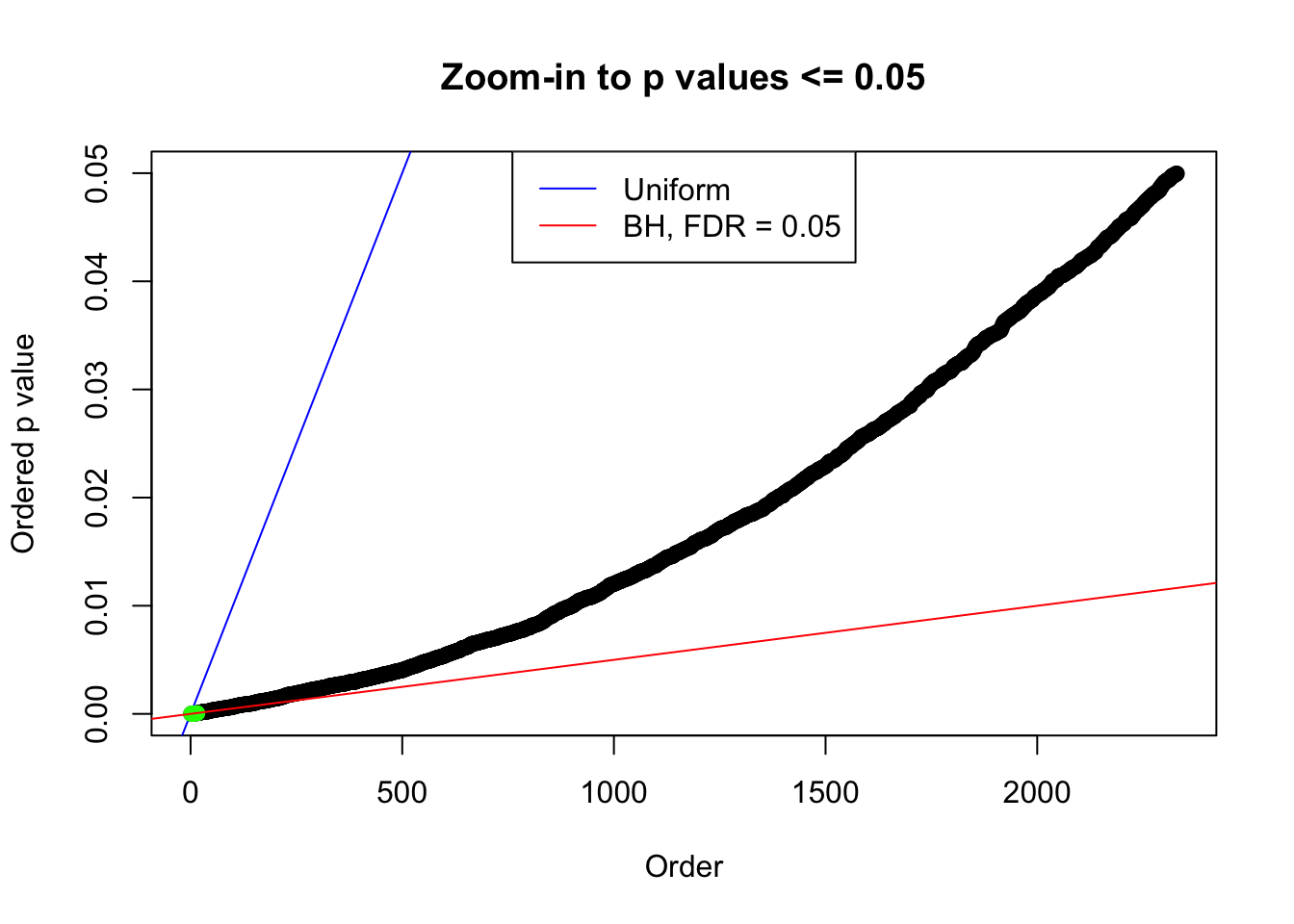
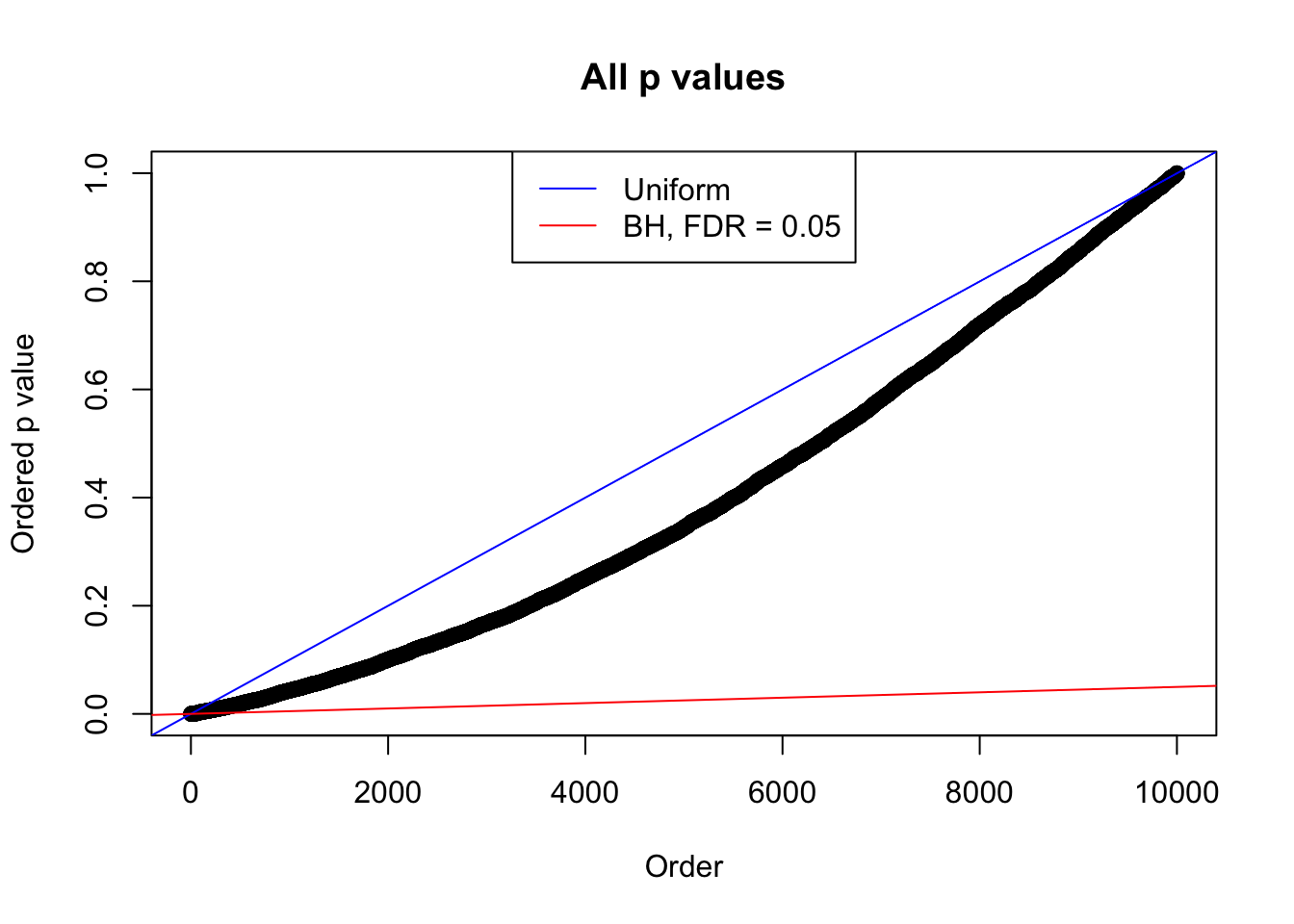
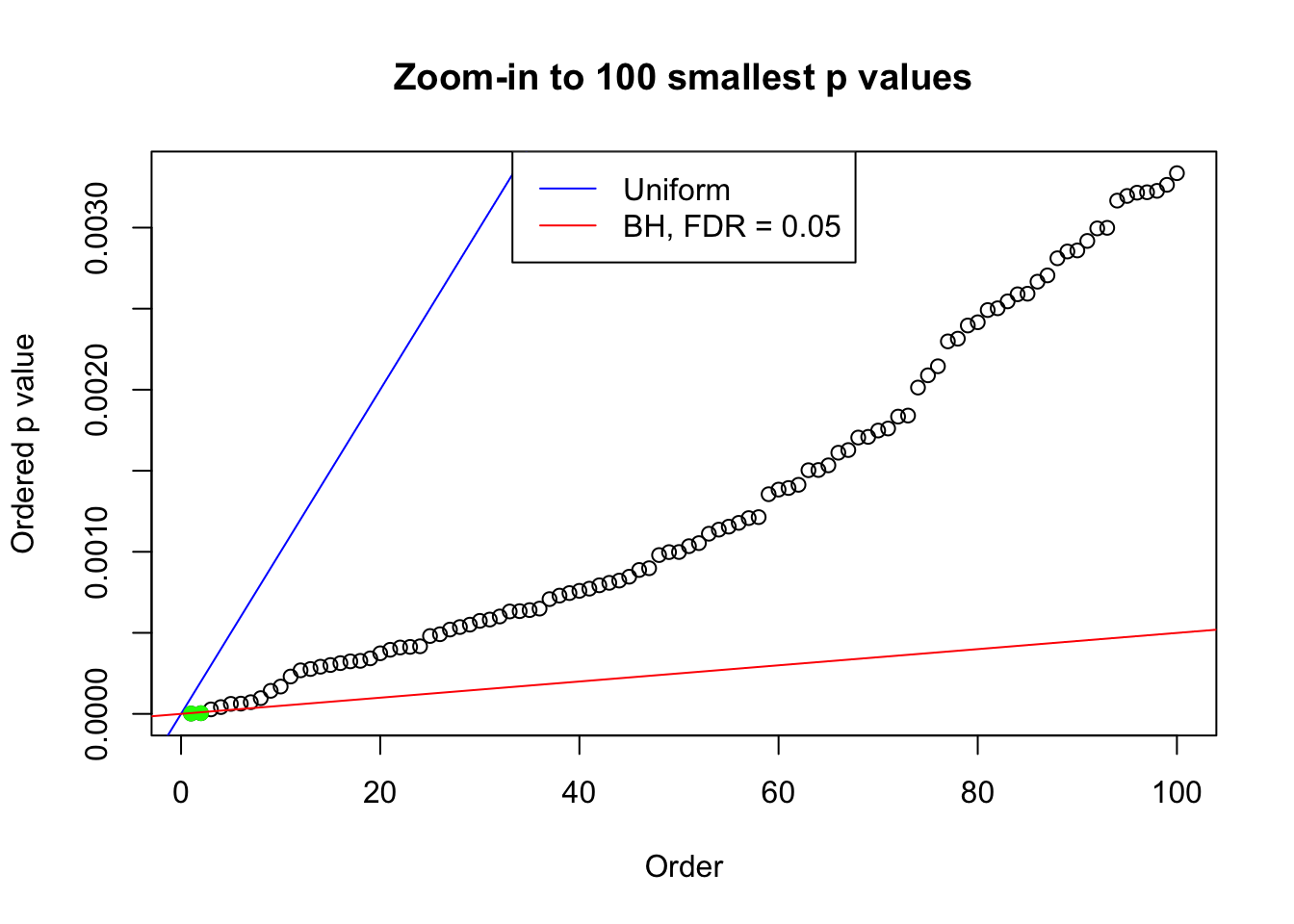
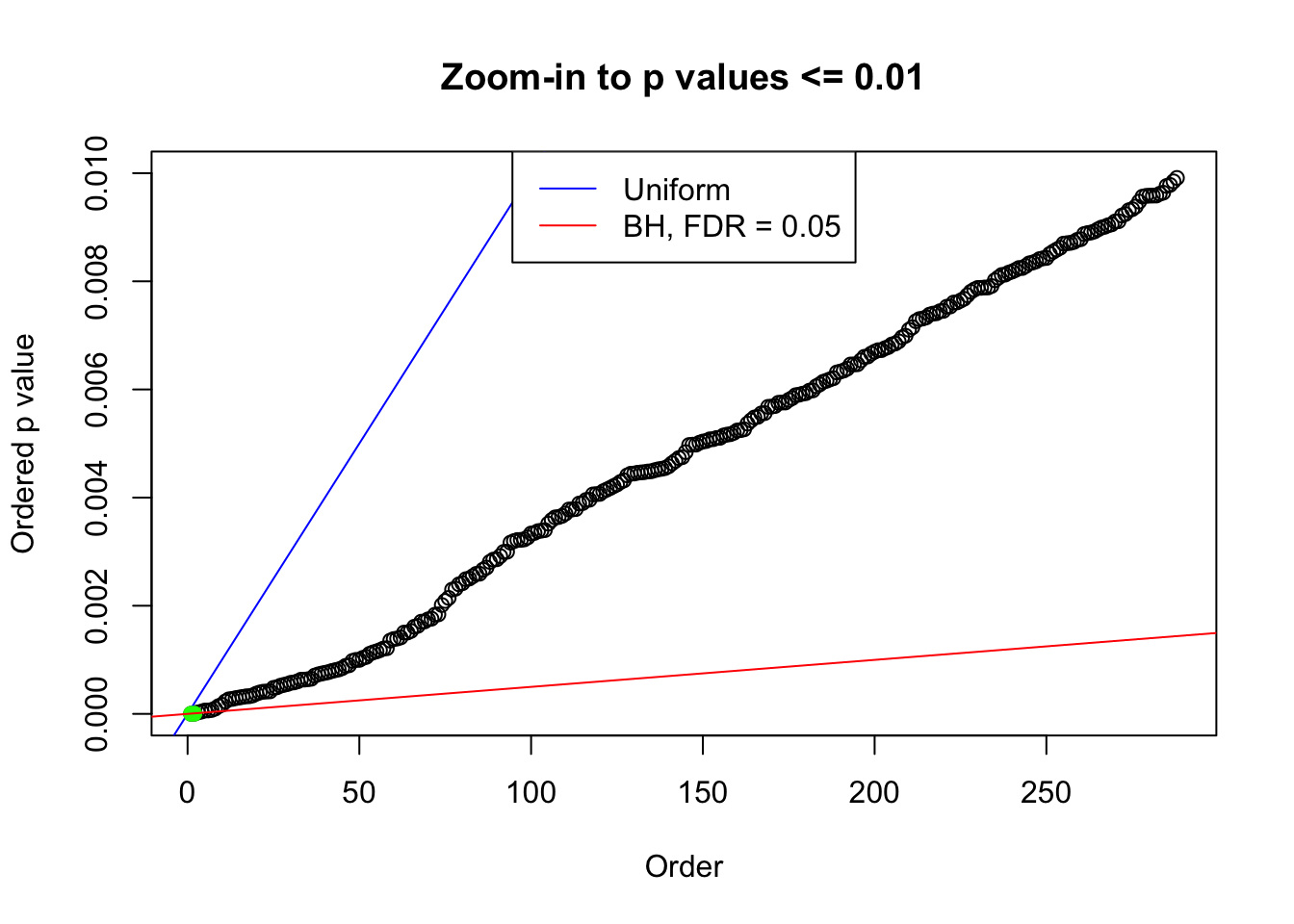
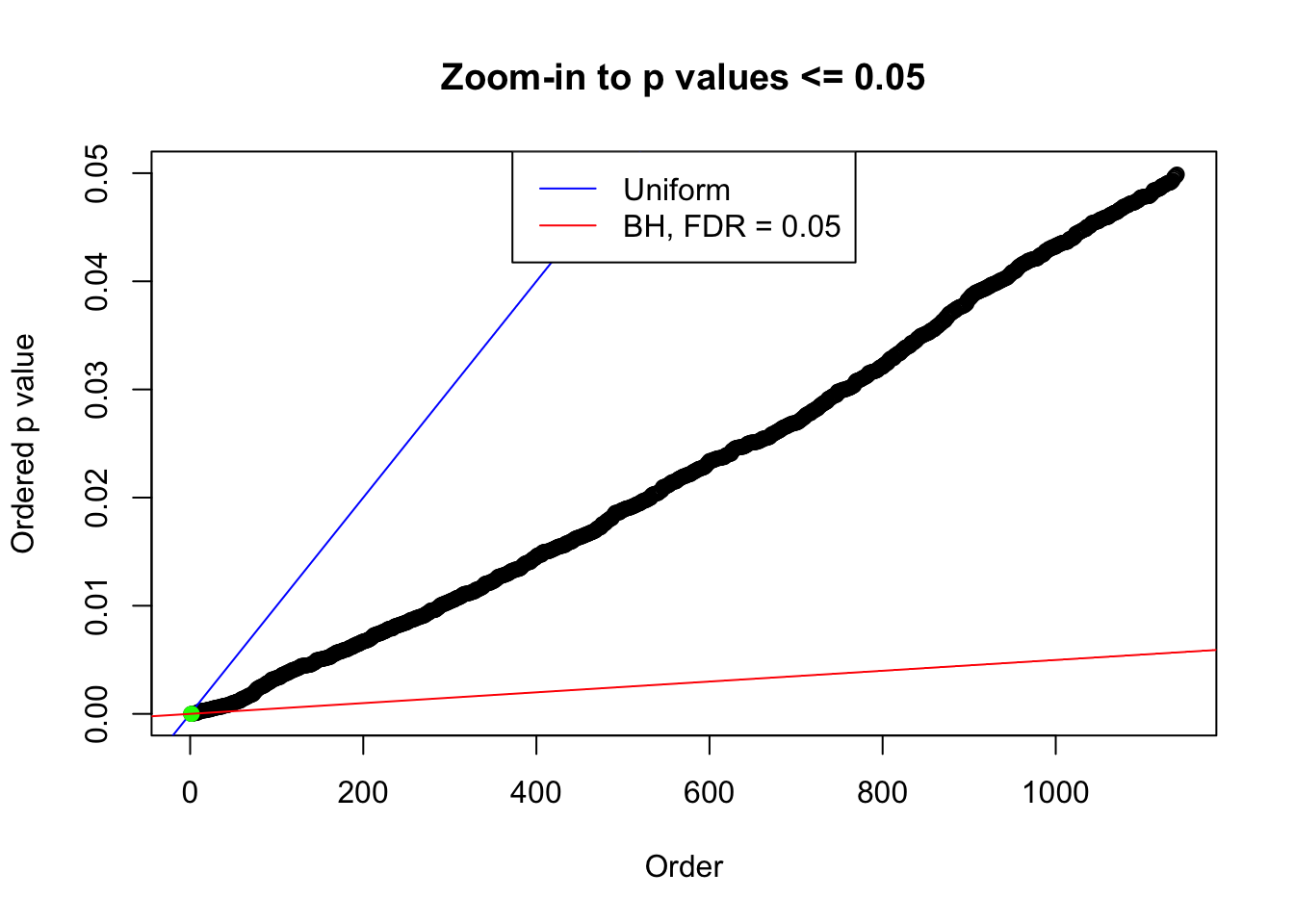
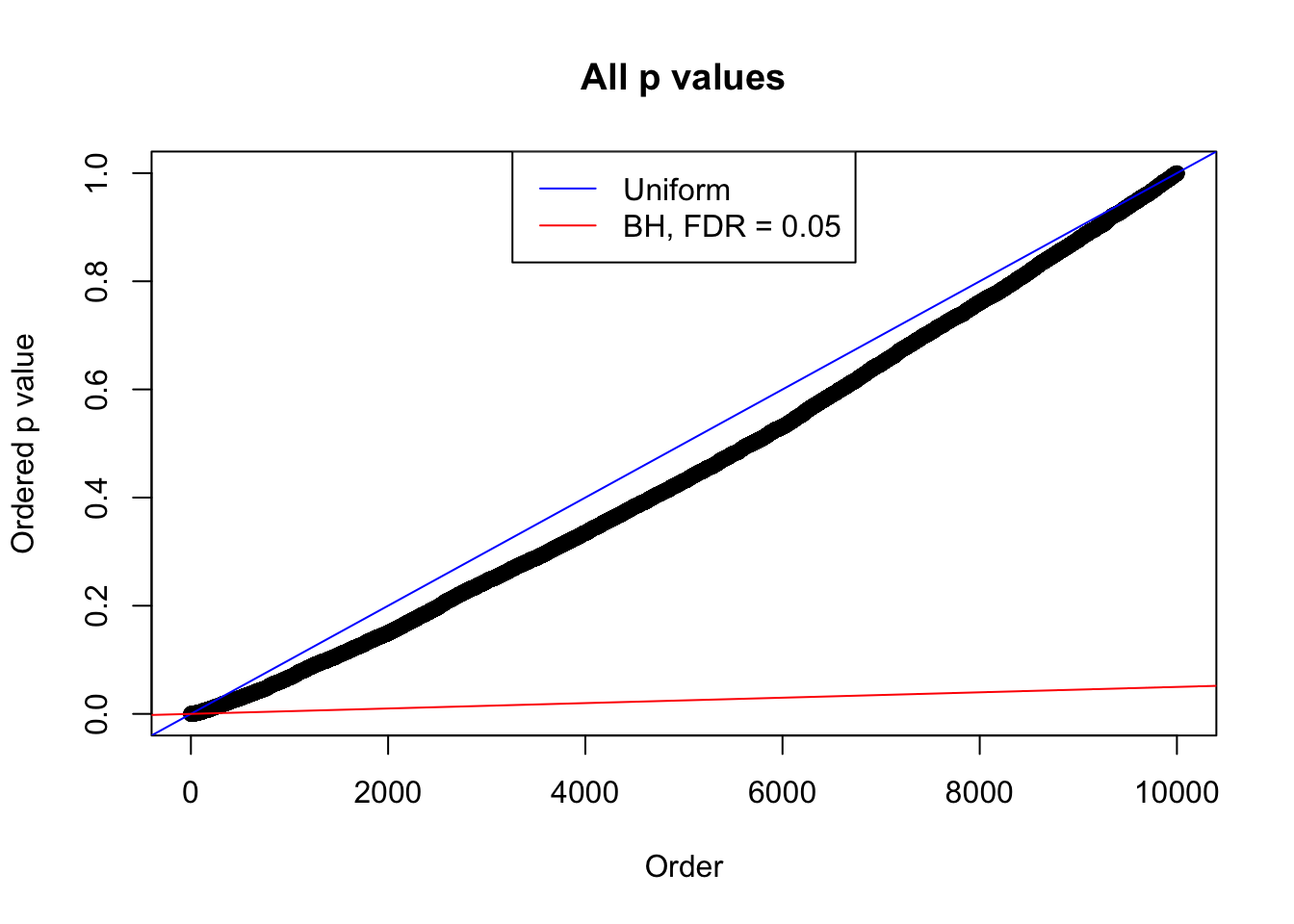
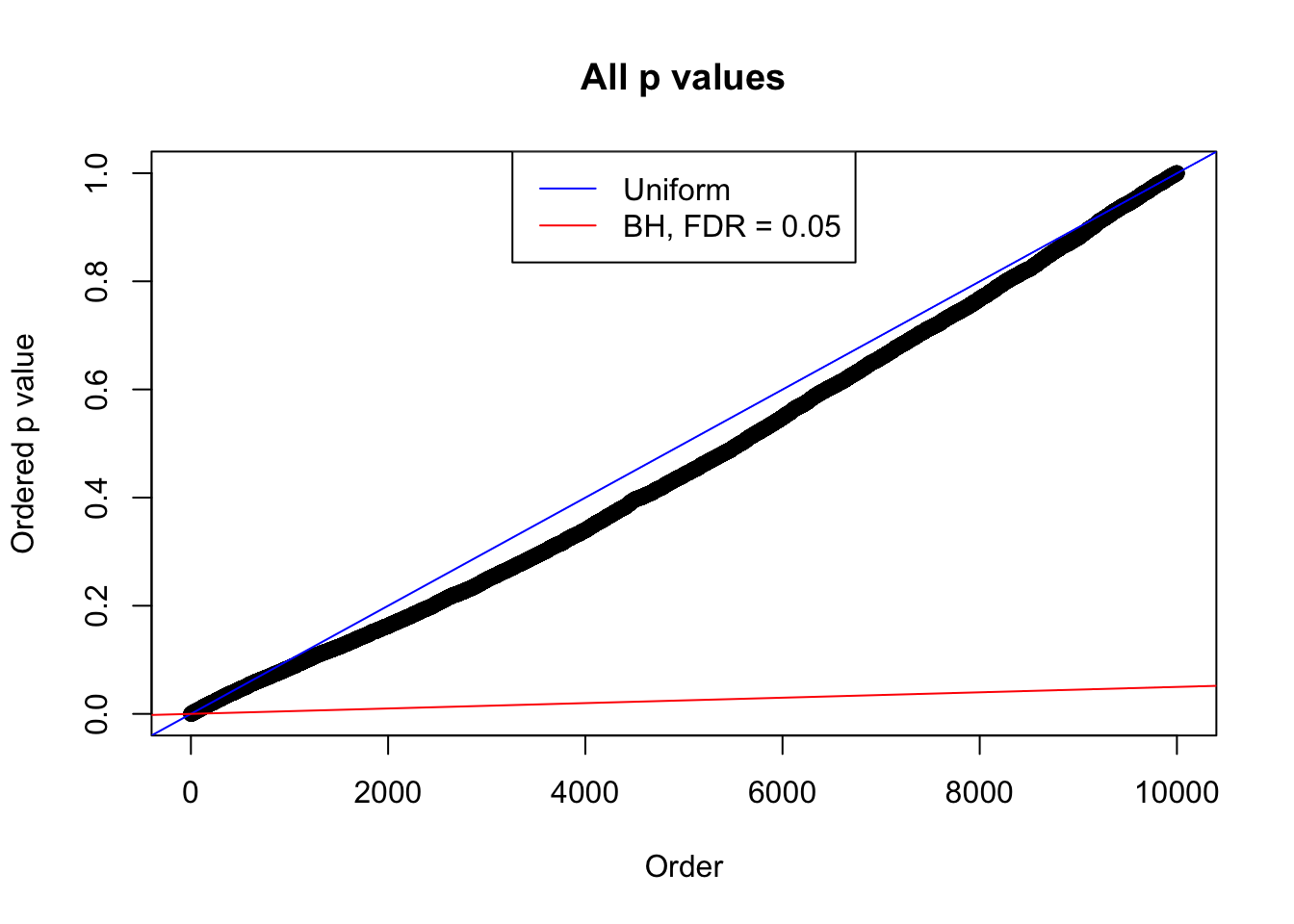
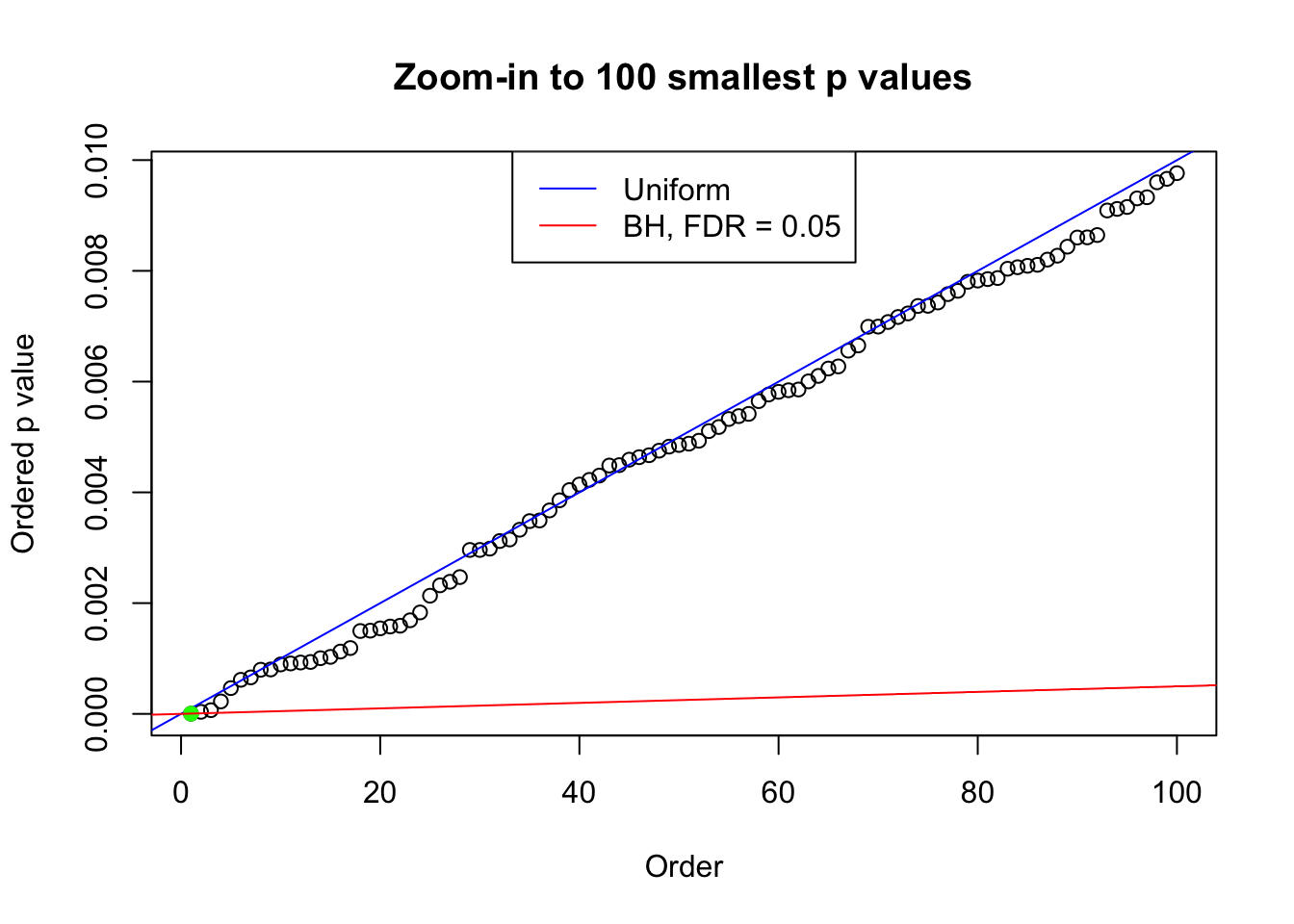
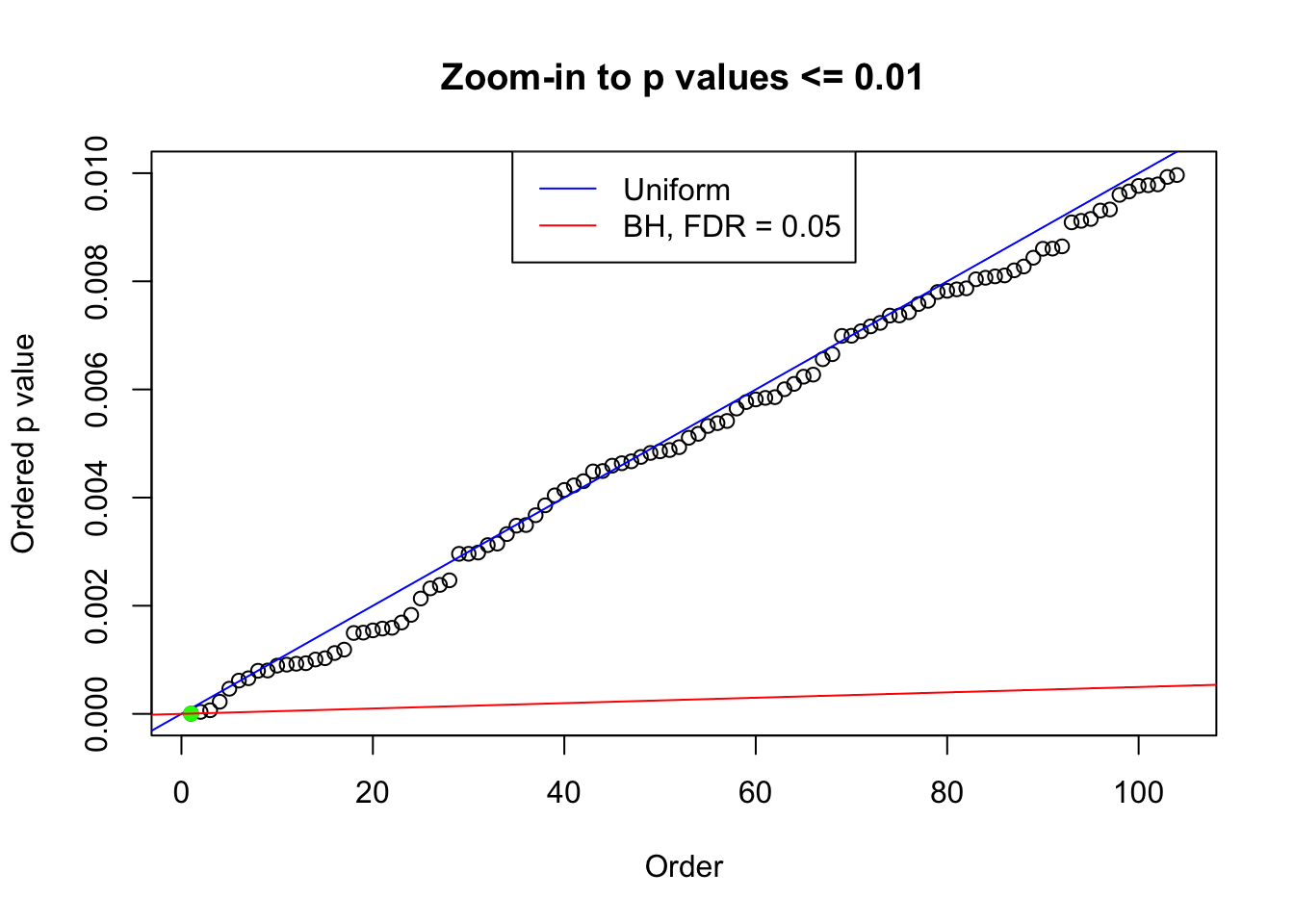
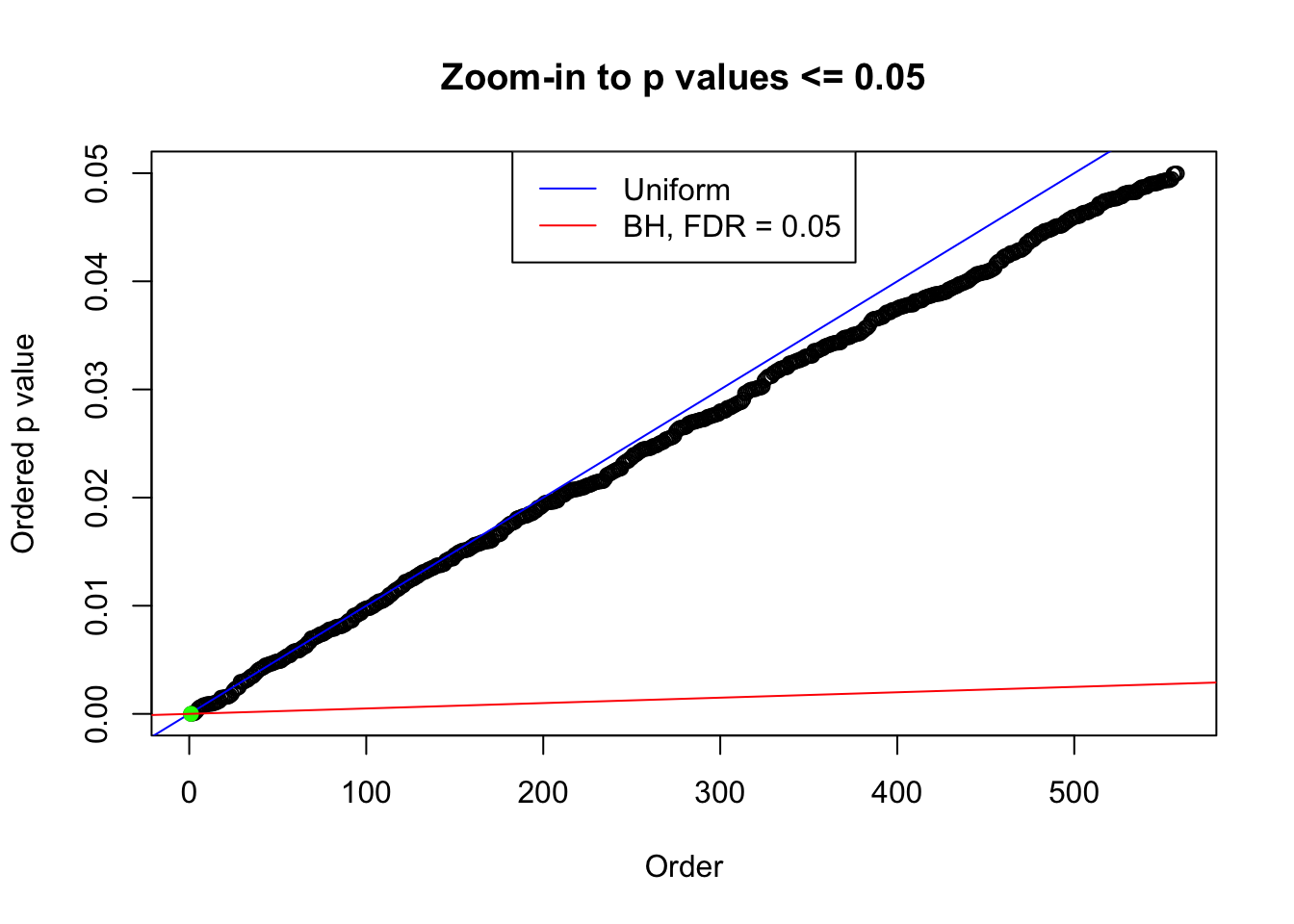
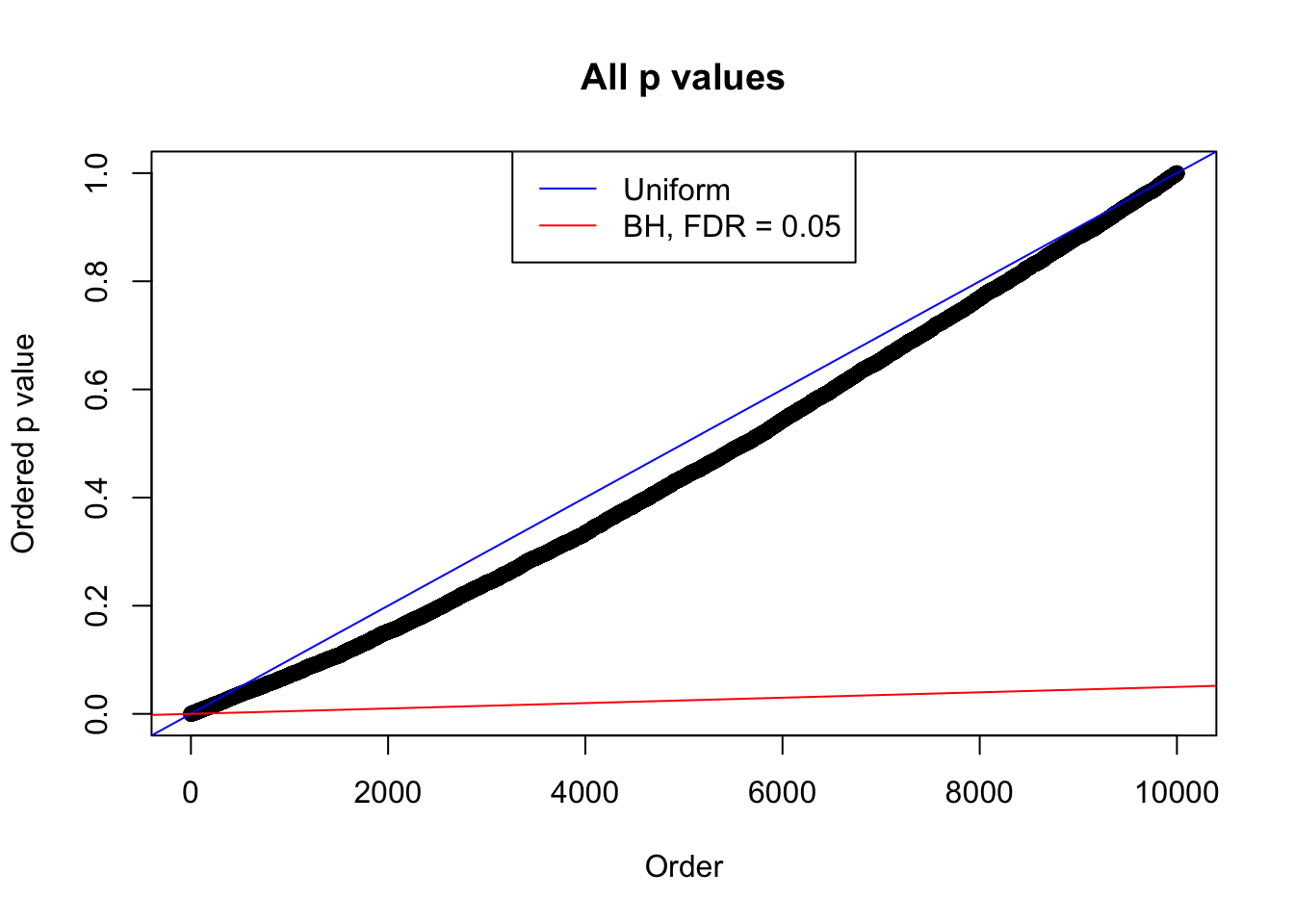
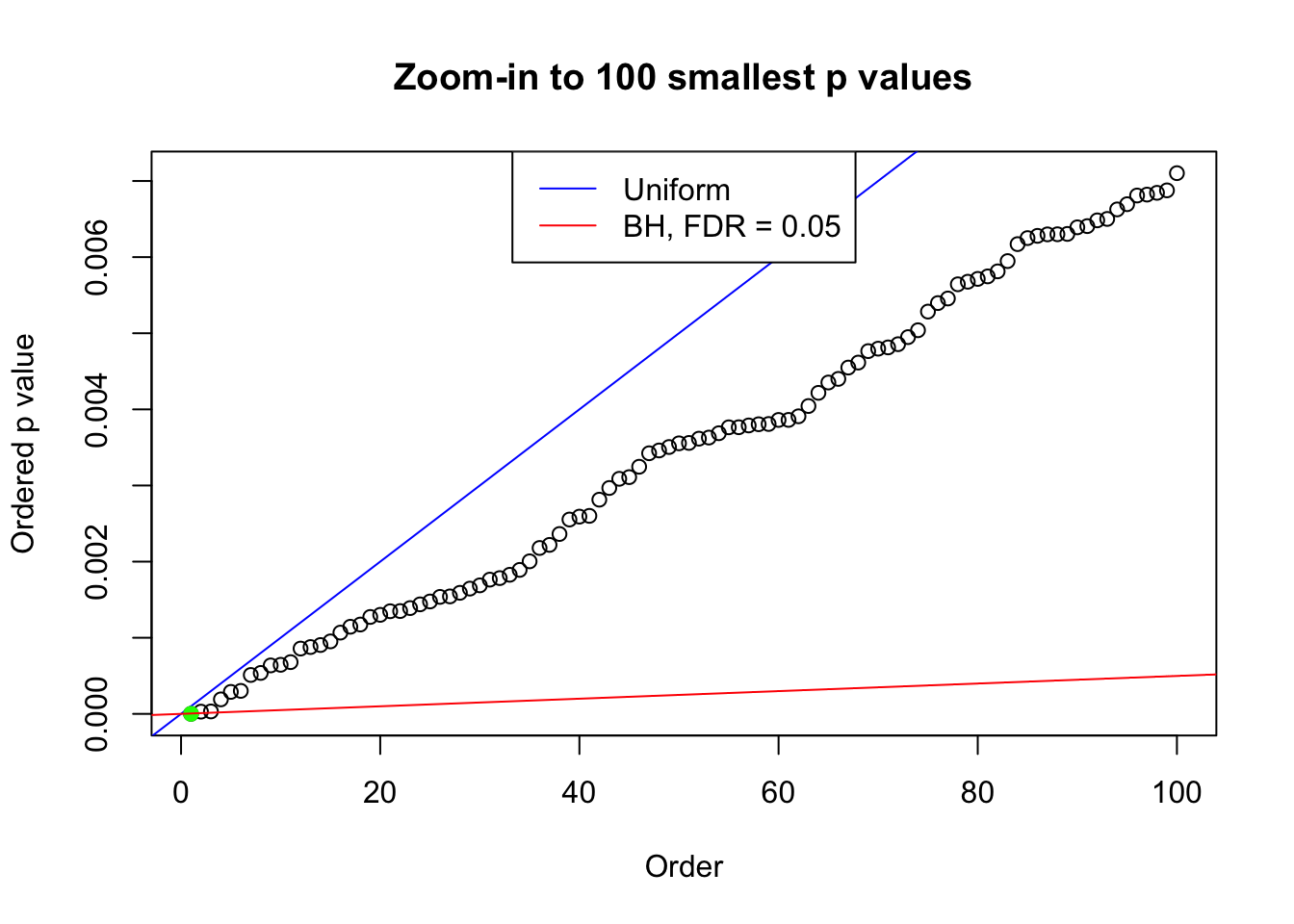
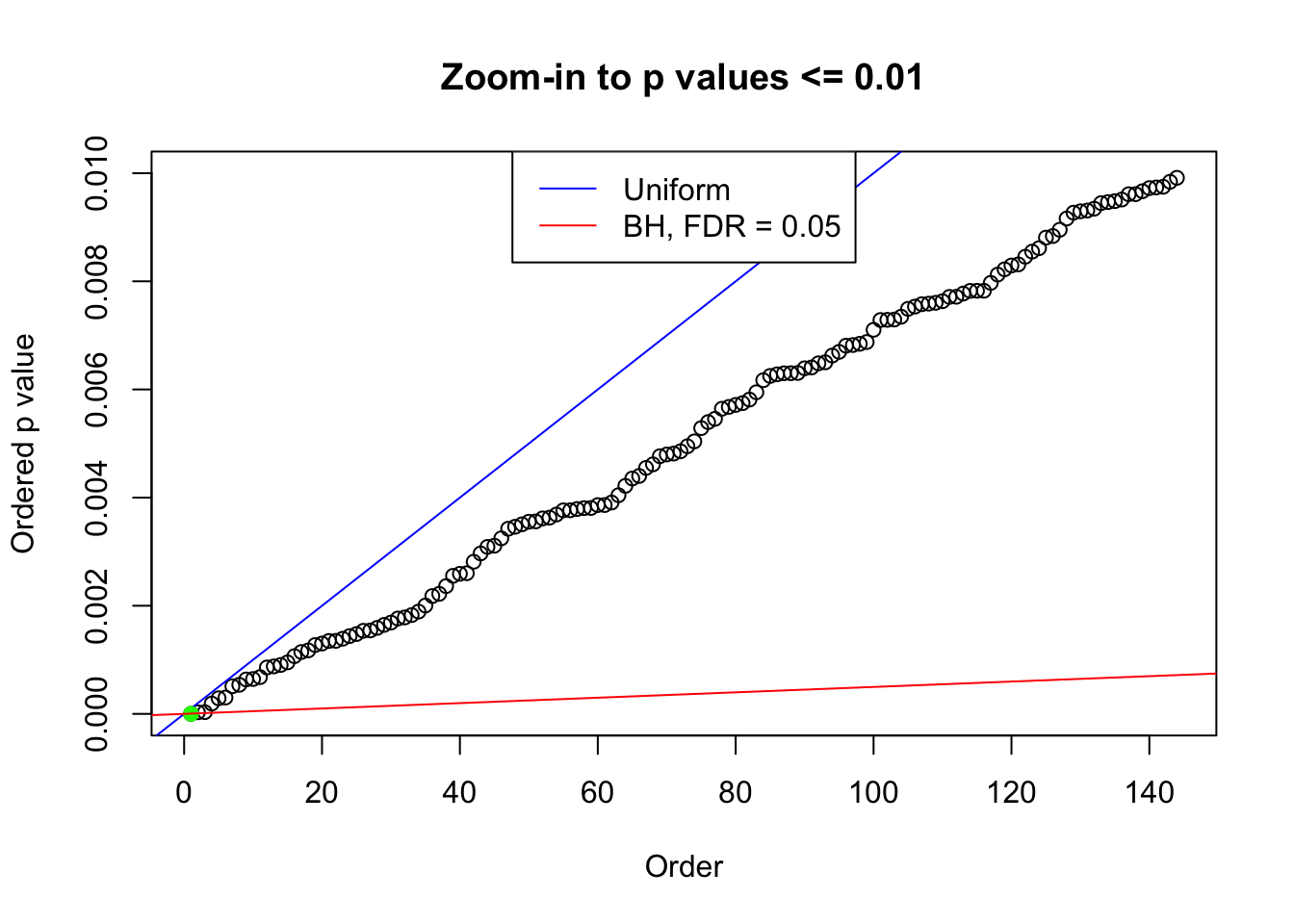
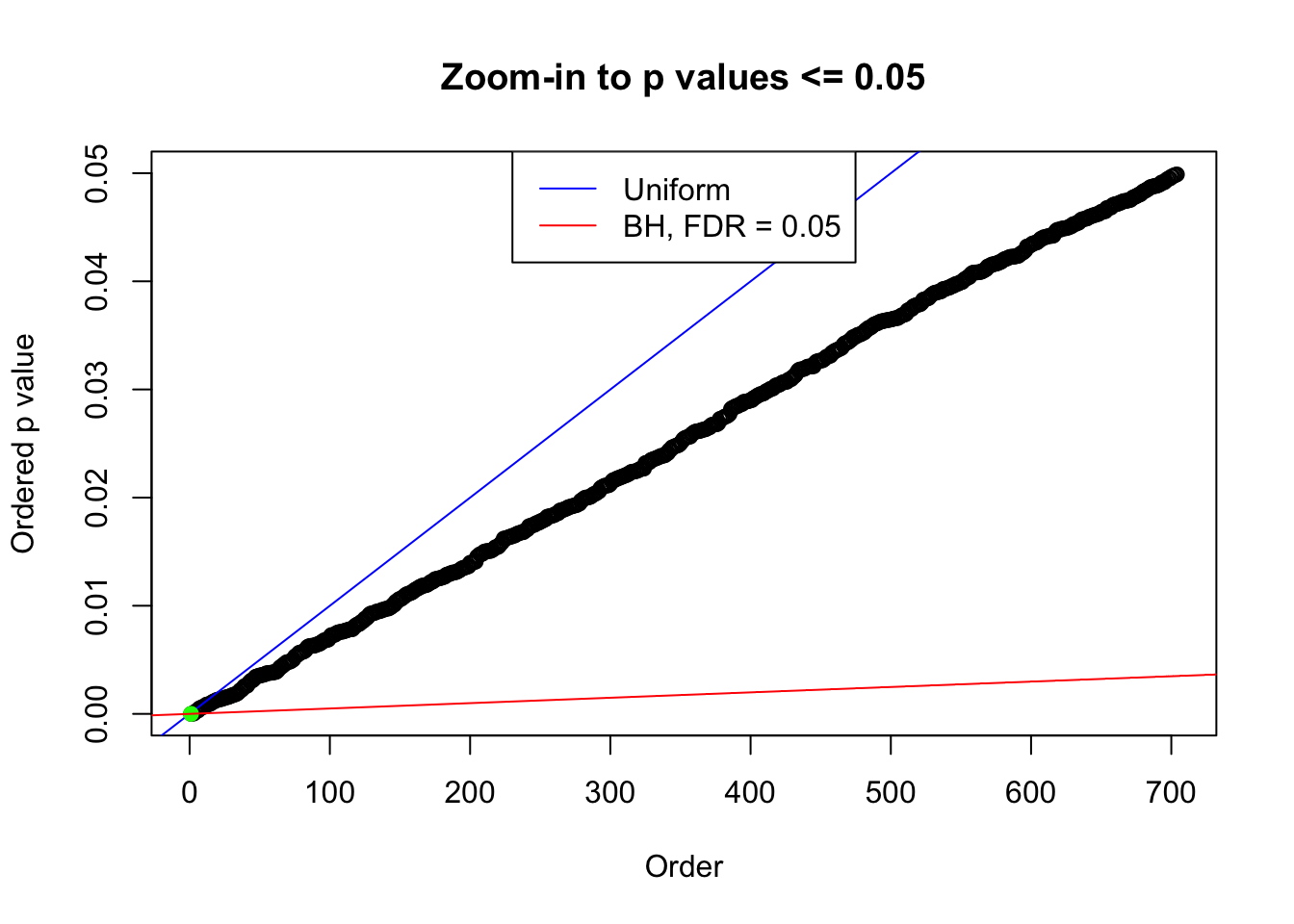
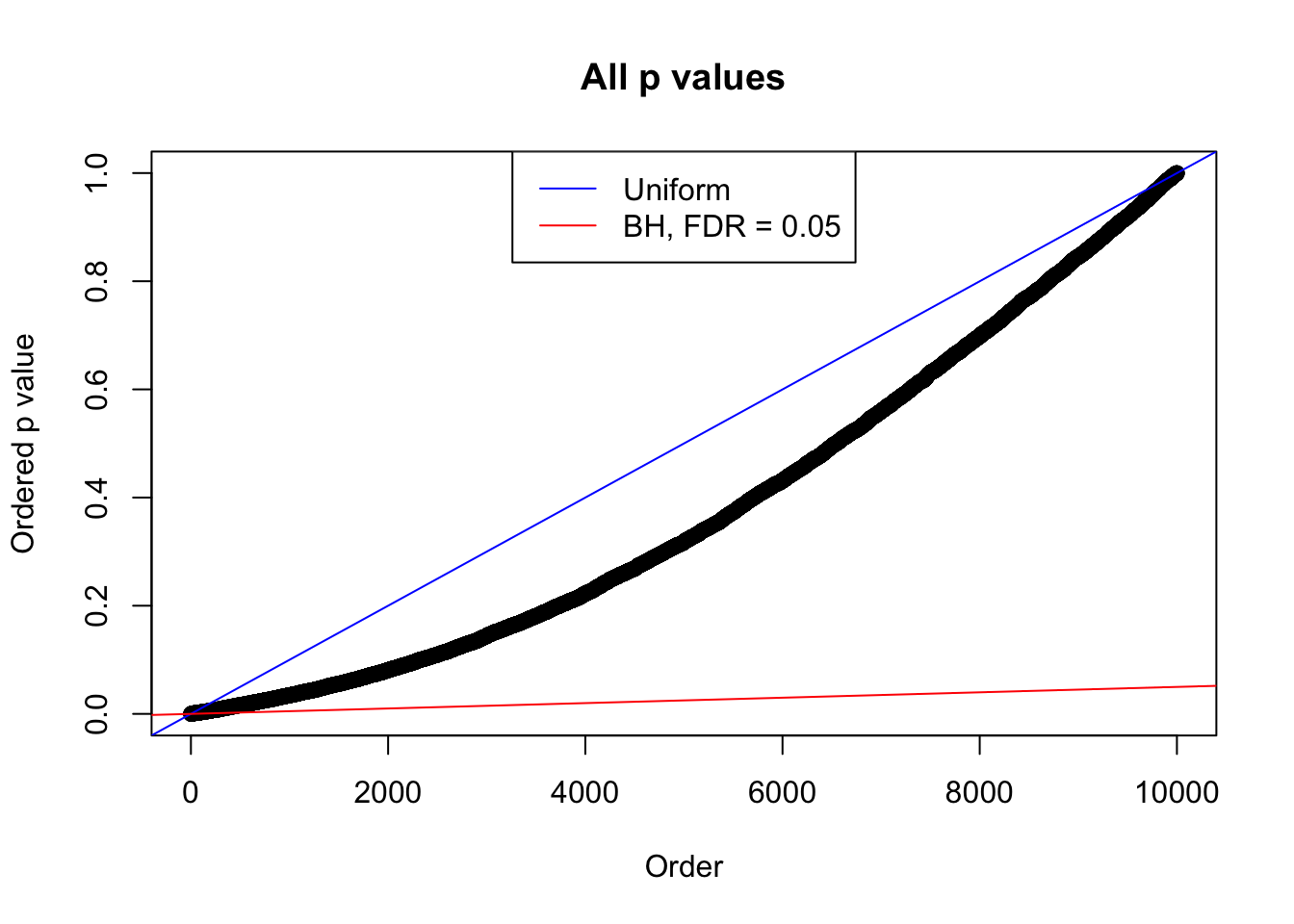
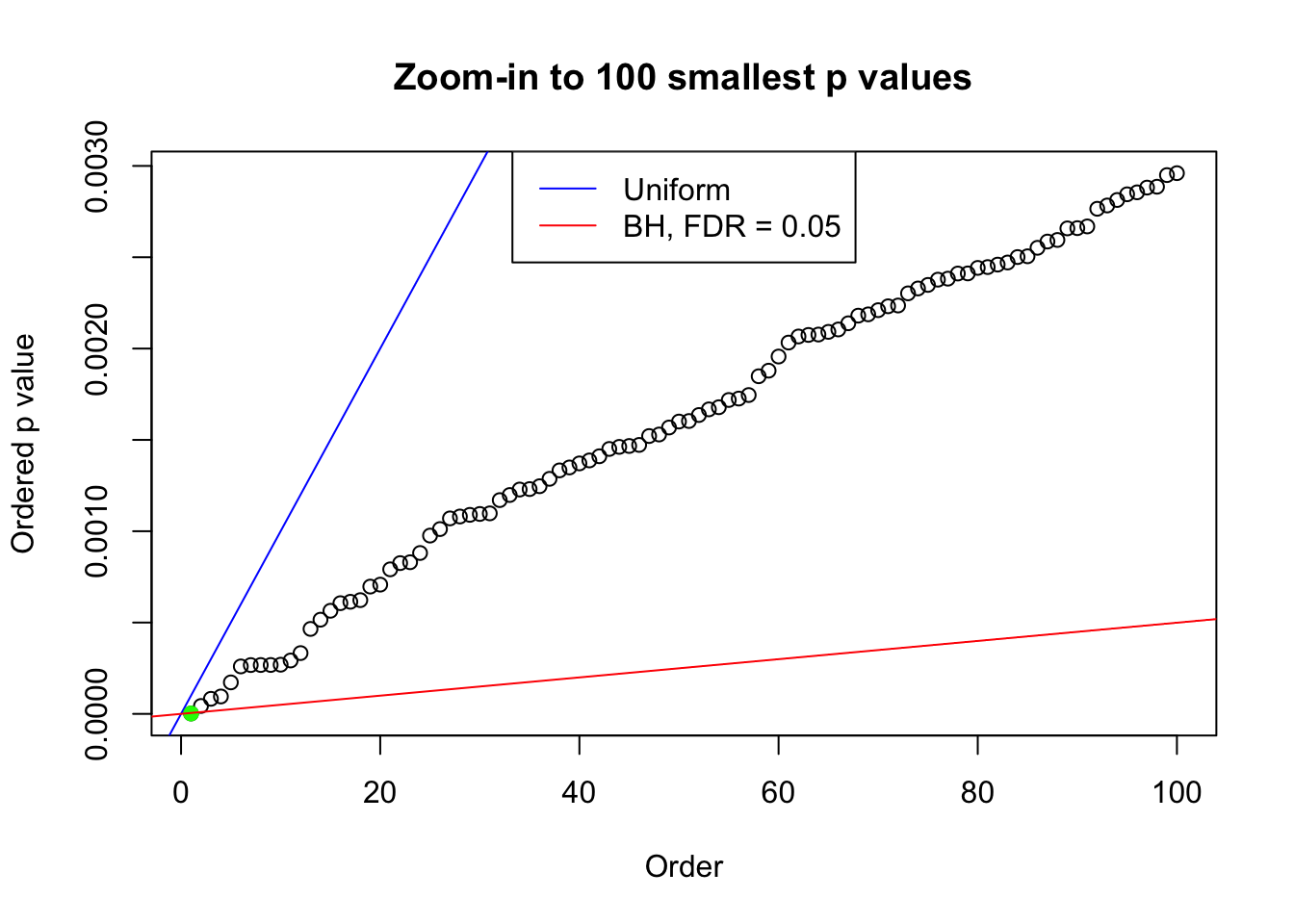
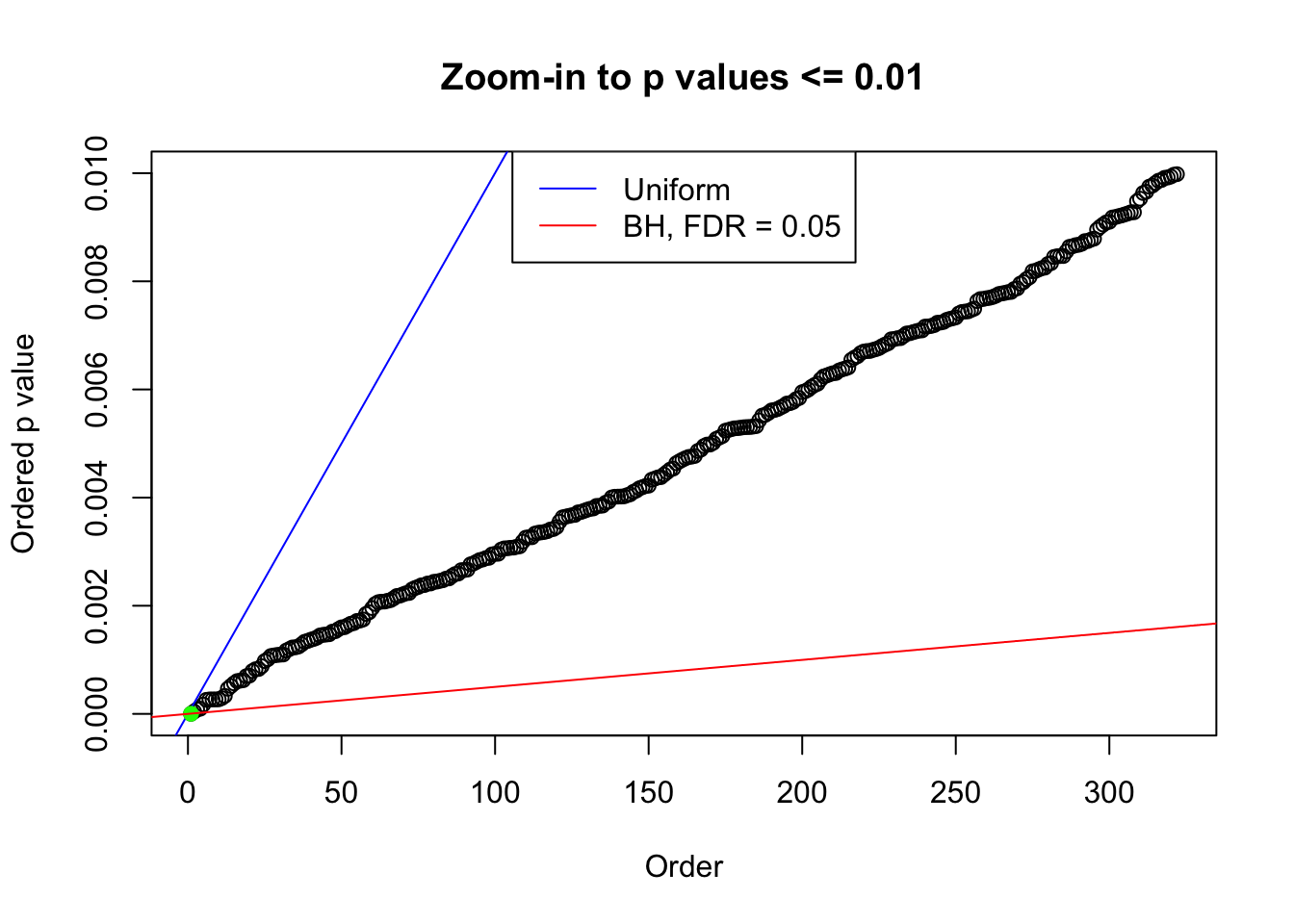
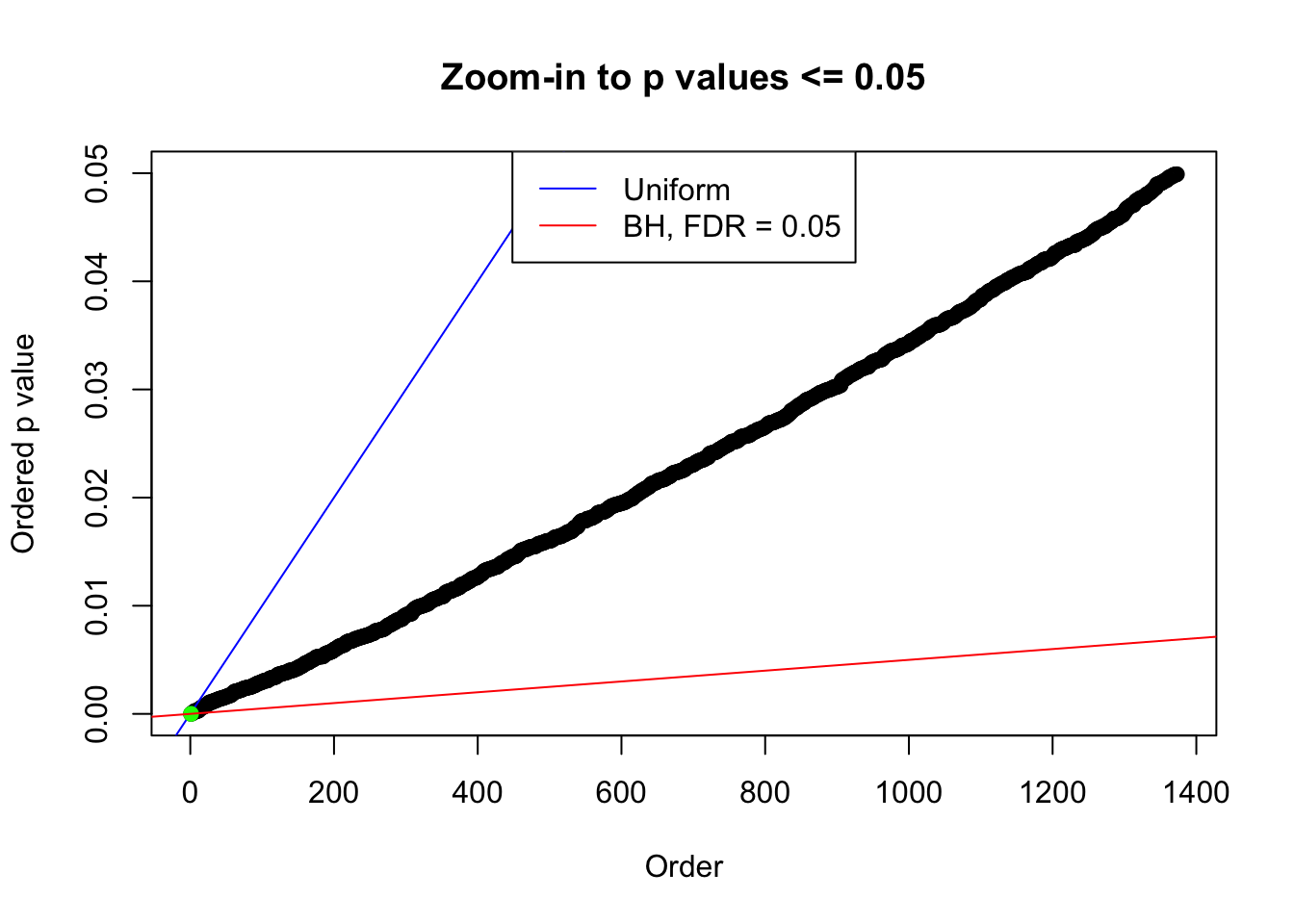
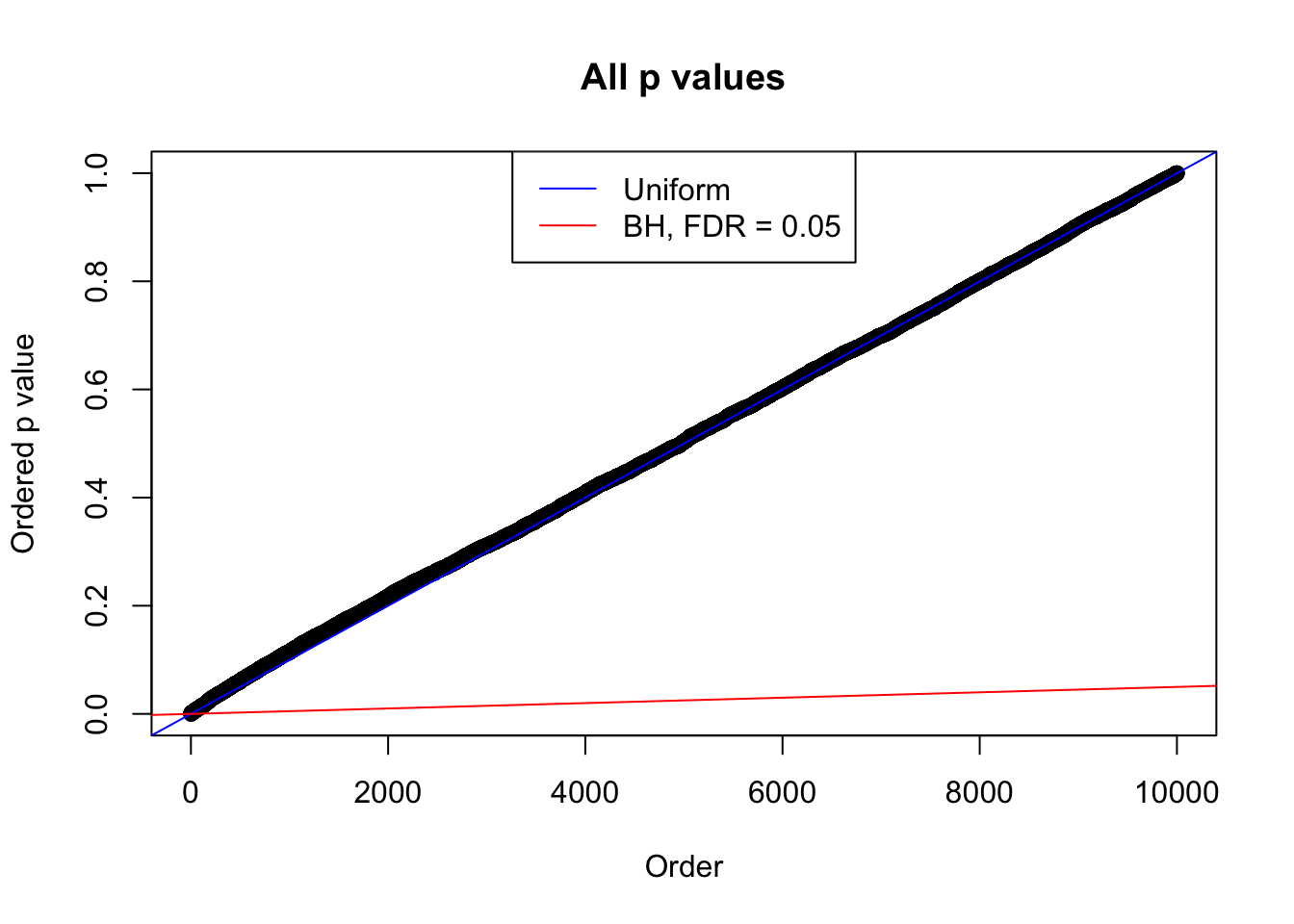
We take a look that all data sets where BH erroneously produces at least one false discovery (green), compared with \(\hat\pi_0\) produced by ash on these same data sets.
fdn = sum(fd.bh >= 1)
I = order(fd.bh, decreasing = TRUE)[1:fdn]
x = seq(-10, 10, 0.01)
y = dnorm(x)
k = 1
m = n[2]
for (j in I) {
cat("N0.", k, ": Data Set", j, "; Number of False Discoveries:", fd.bh[j], "; pihat0 =", pihat0[j])
hist(as.numeric(z[j, ]), xlab = "z scores", freq = FALSE, ylim = c(0, 0.45), nclass = 100, main = "10000 z scores, 100 bins")
lines(x, y, col = "red")
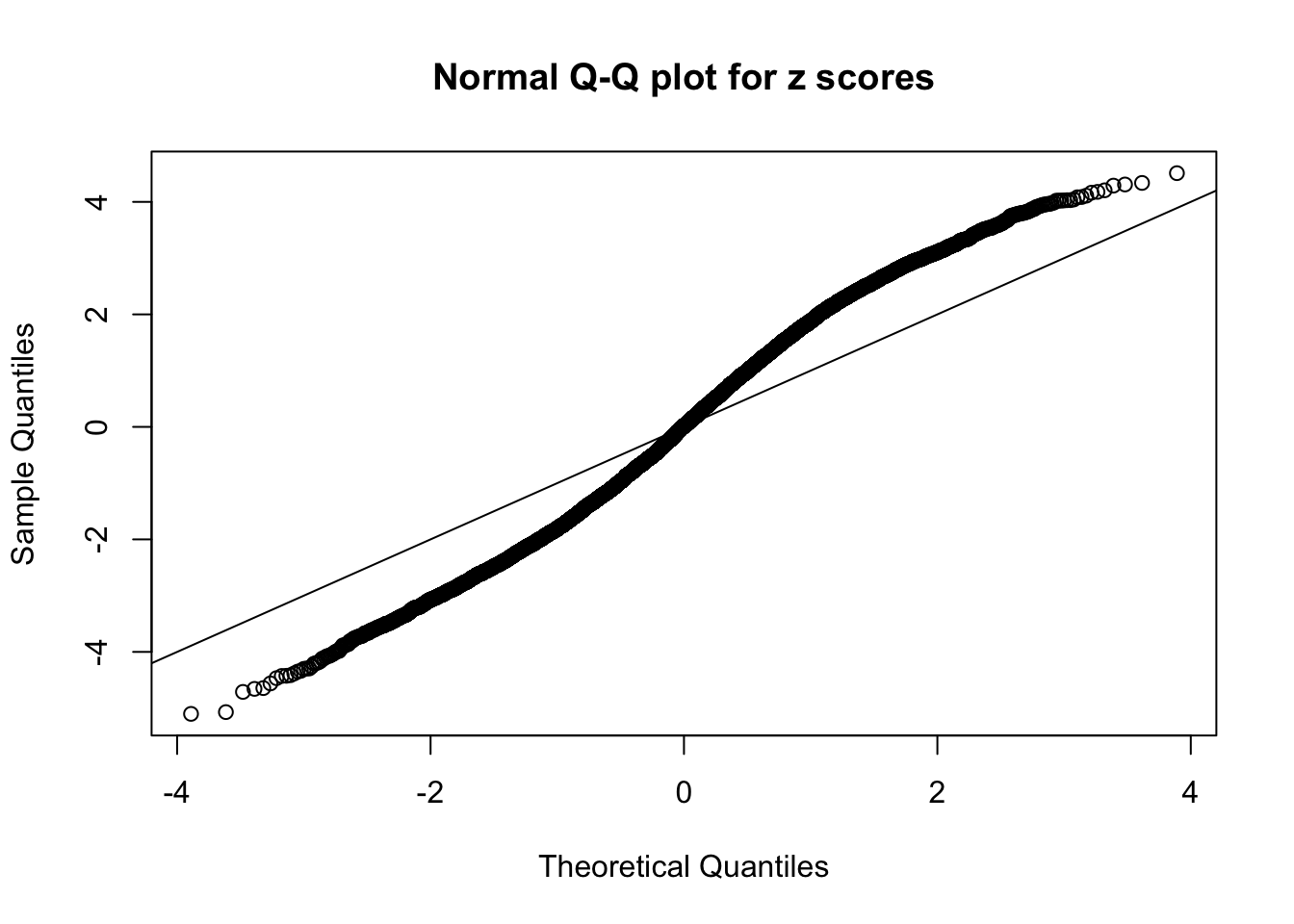
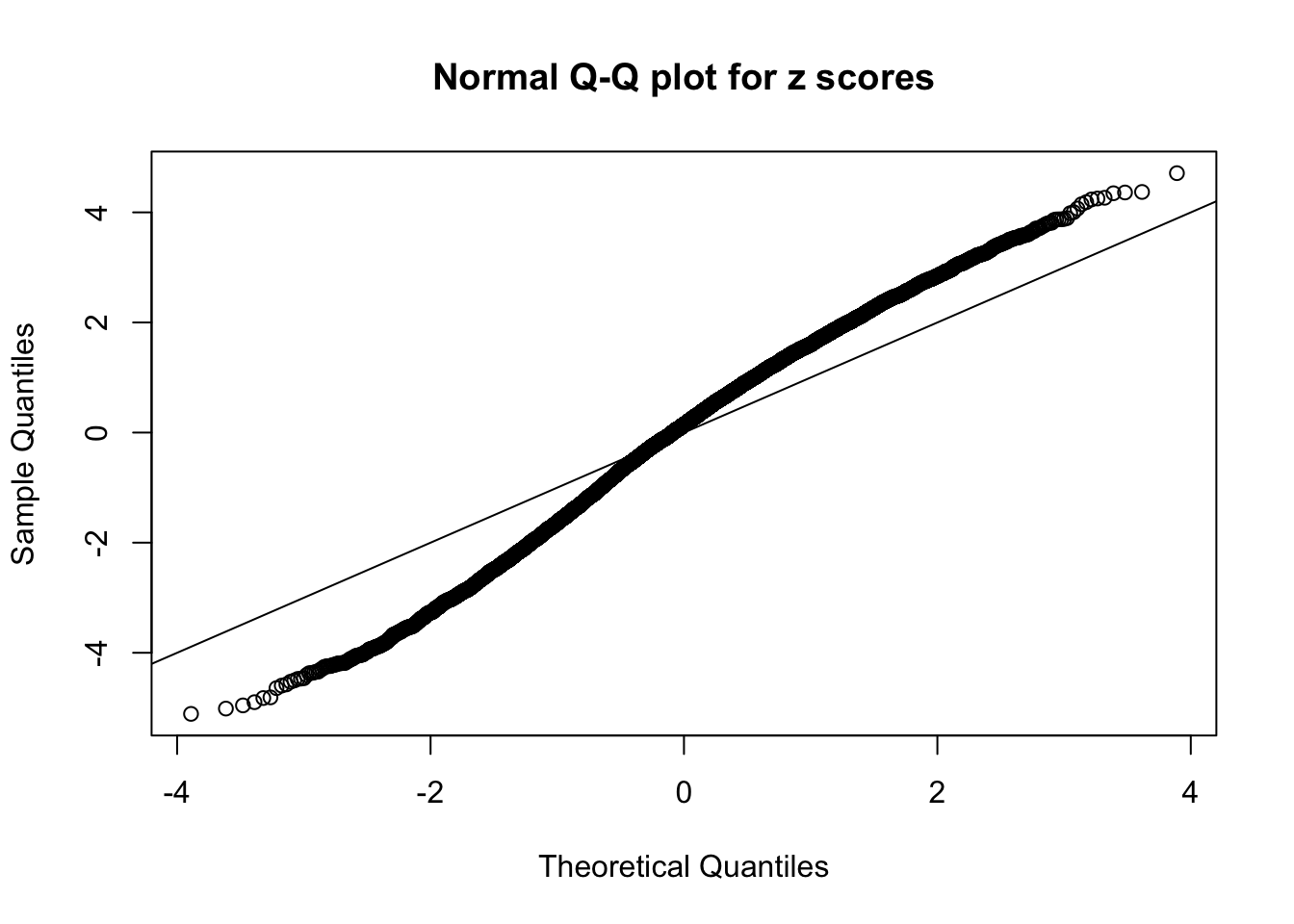
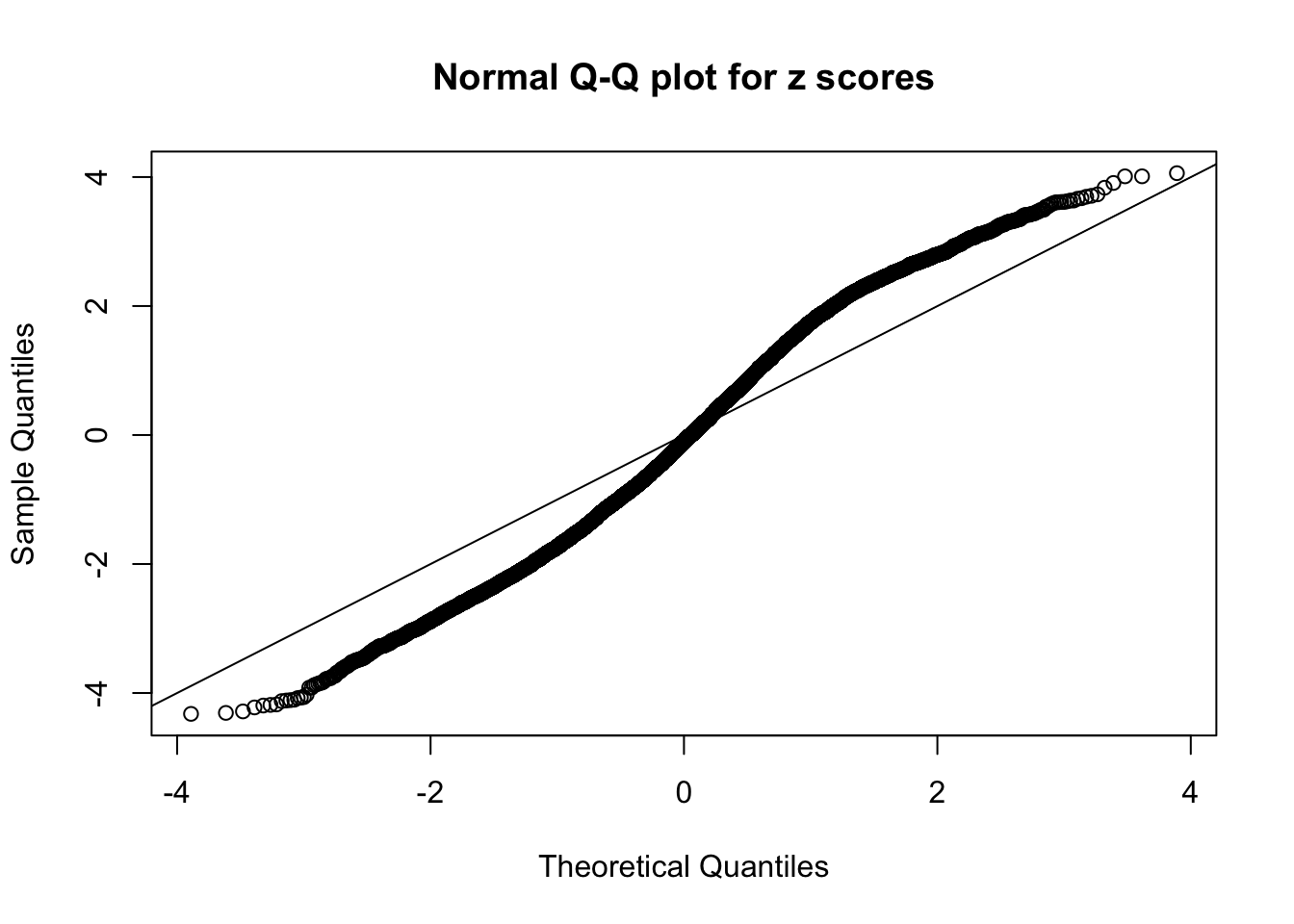
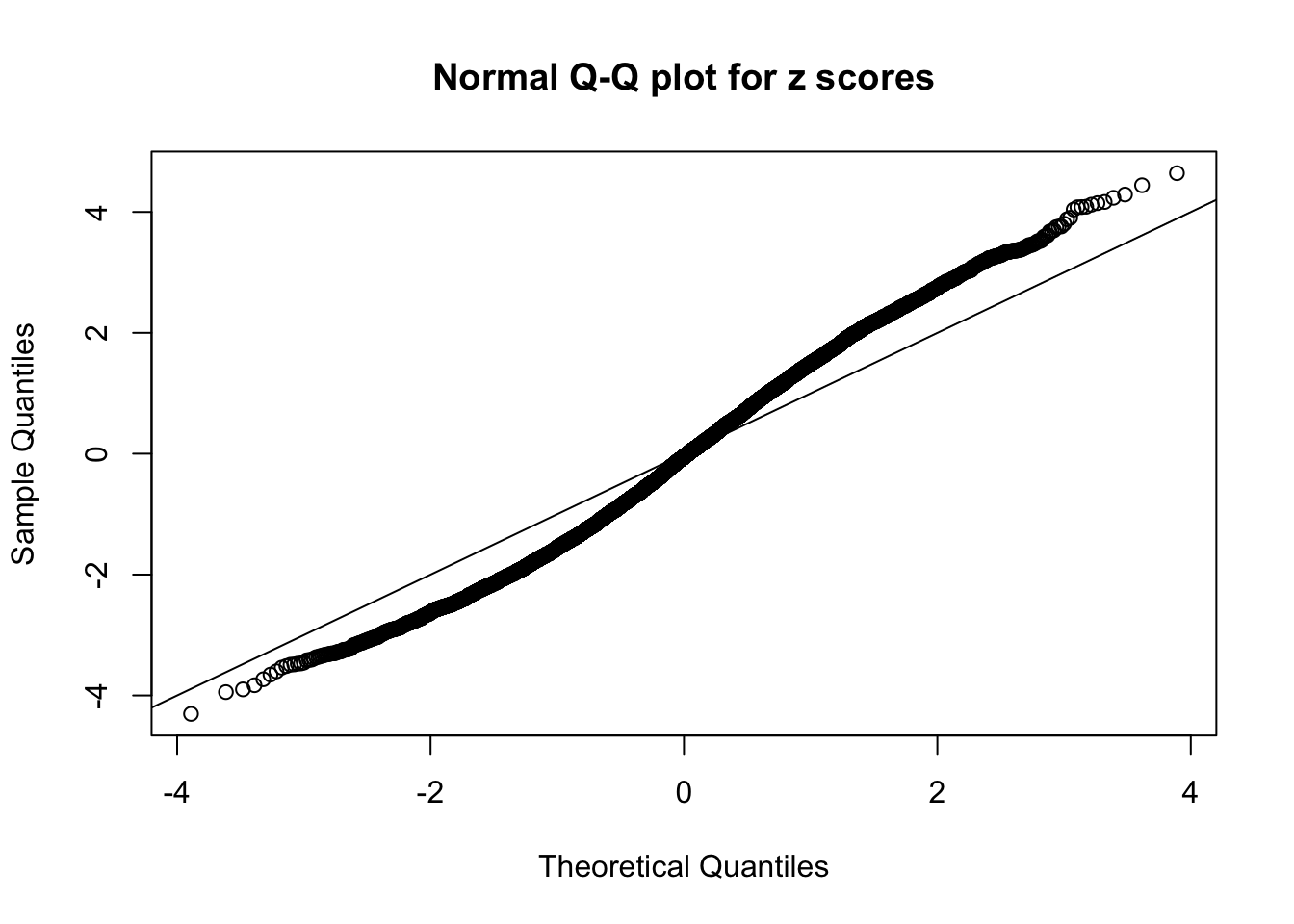
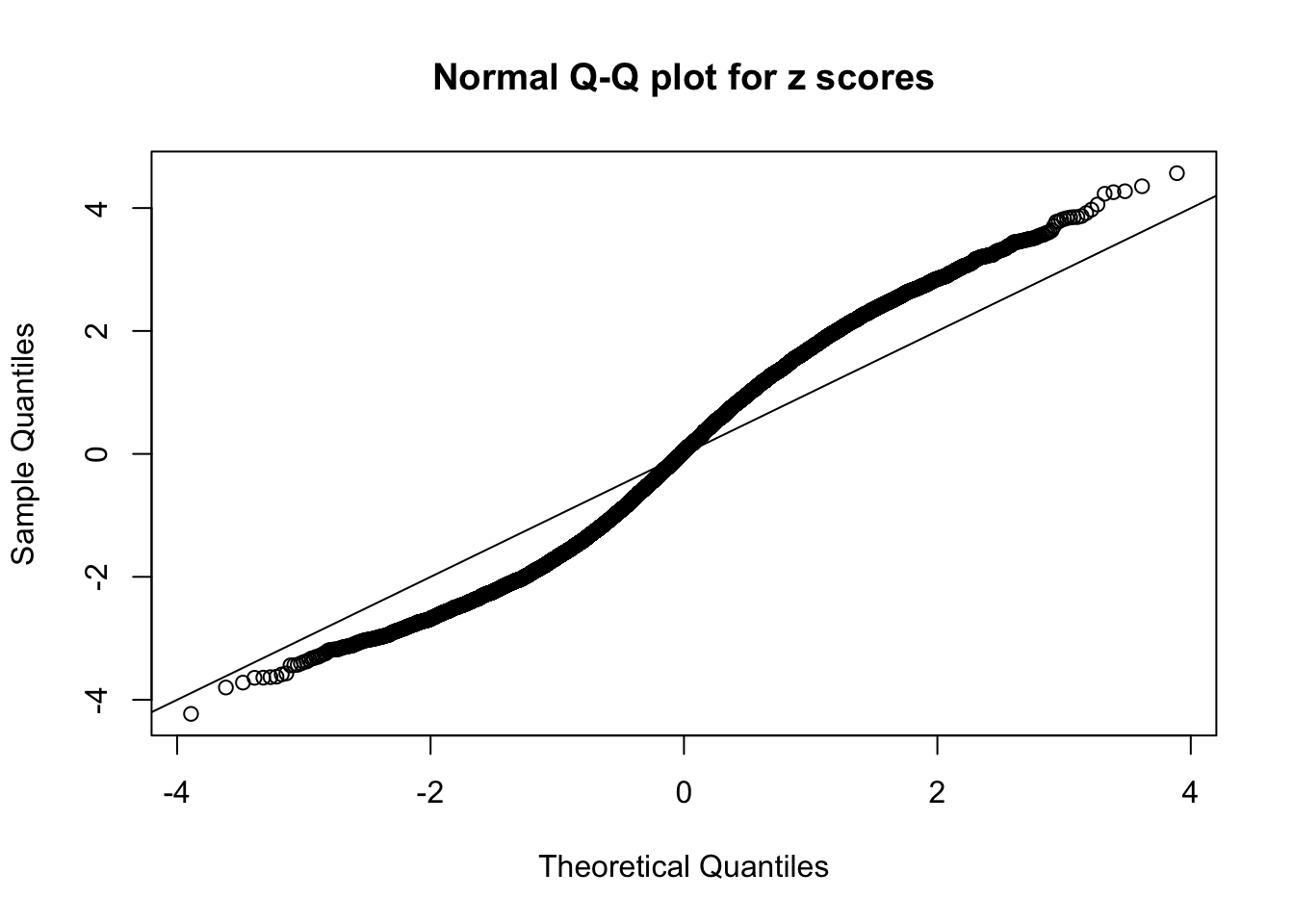
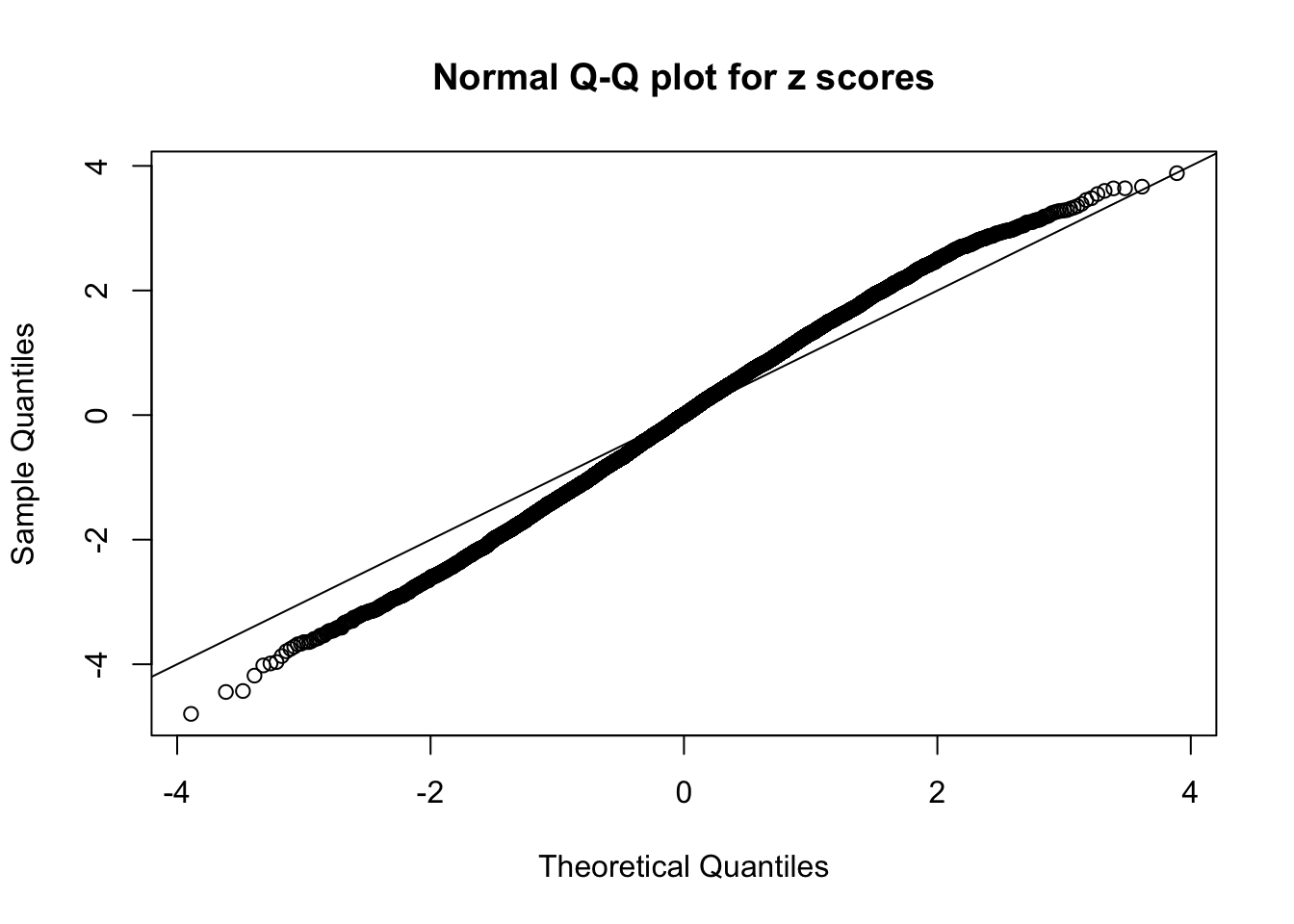
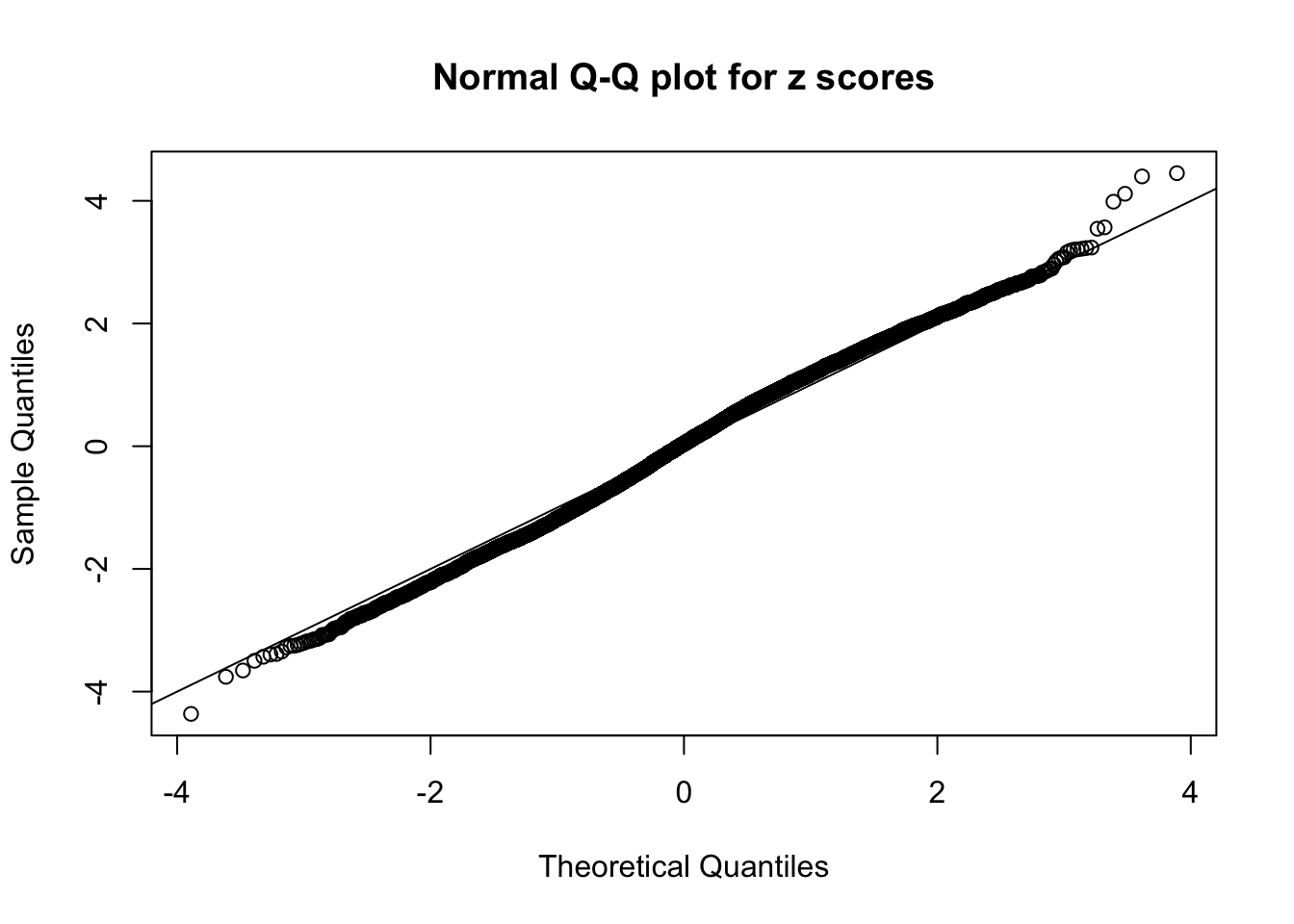
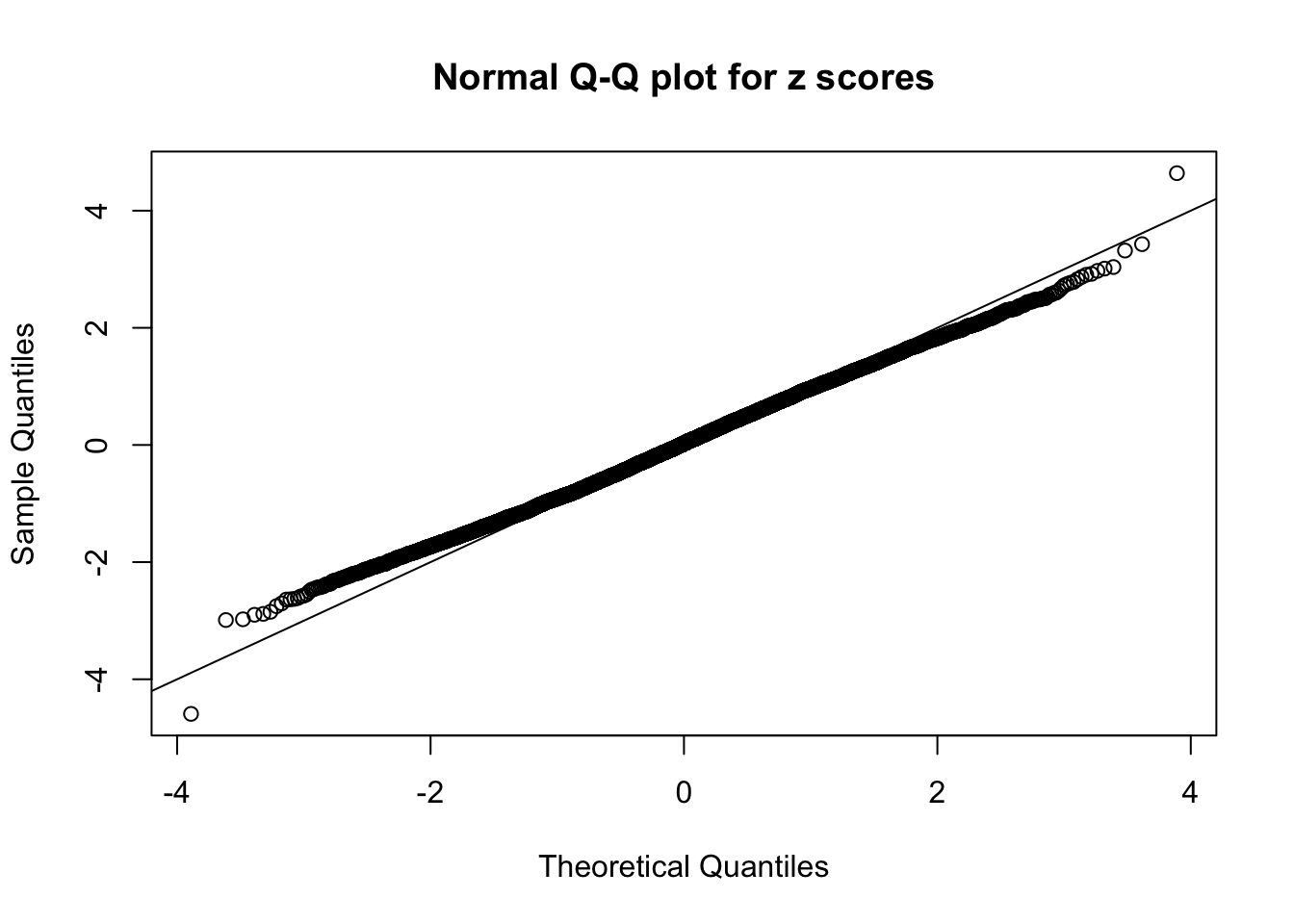
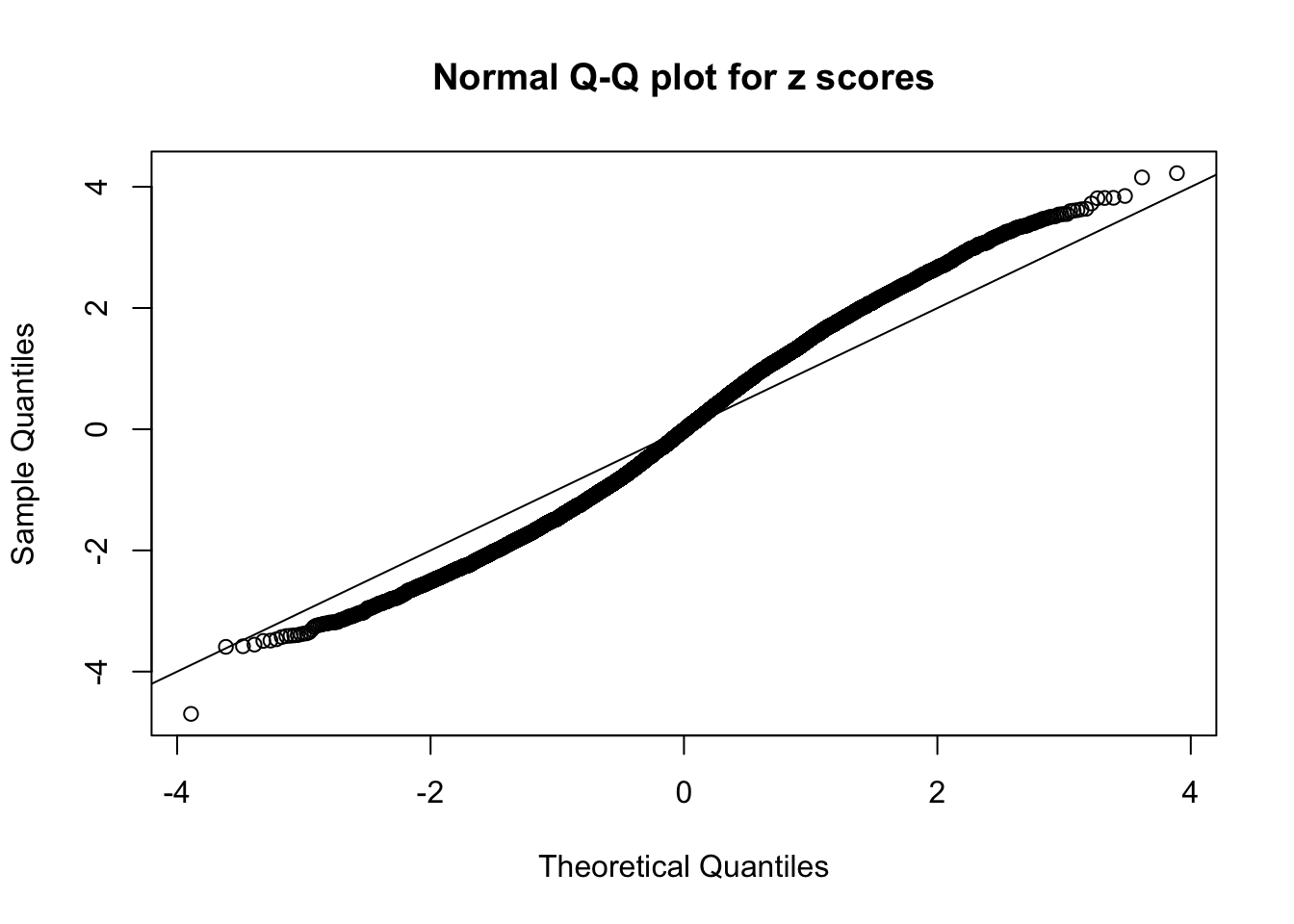
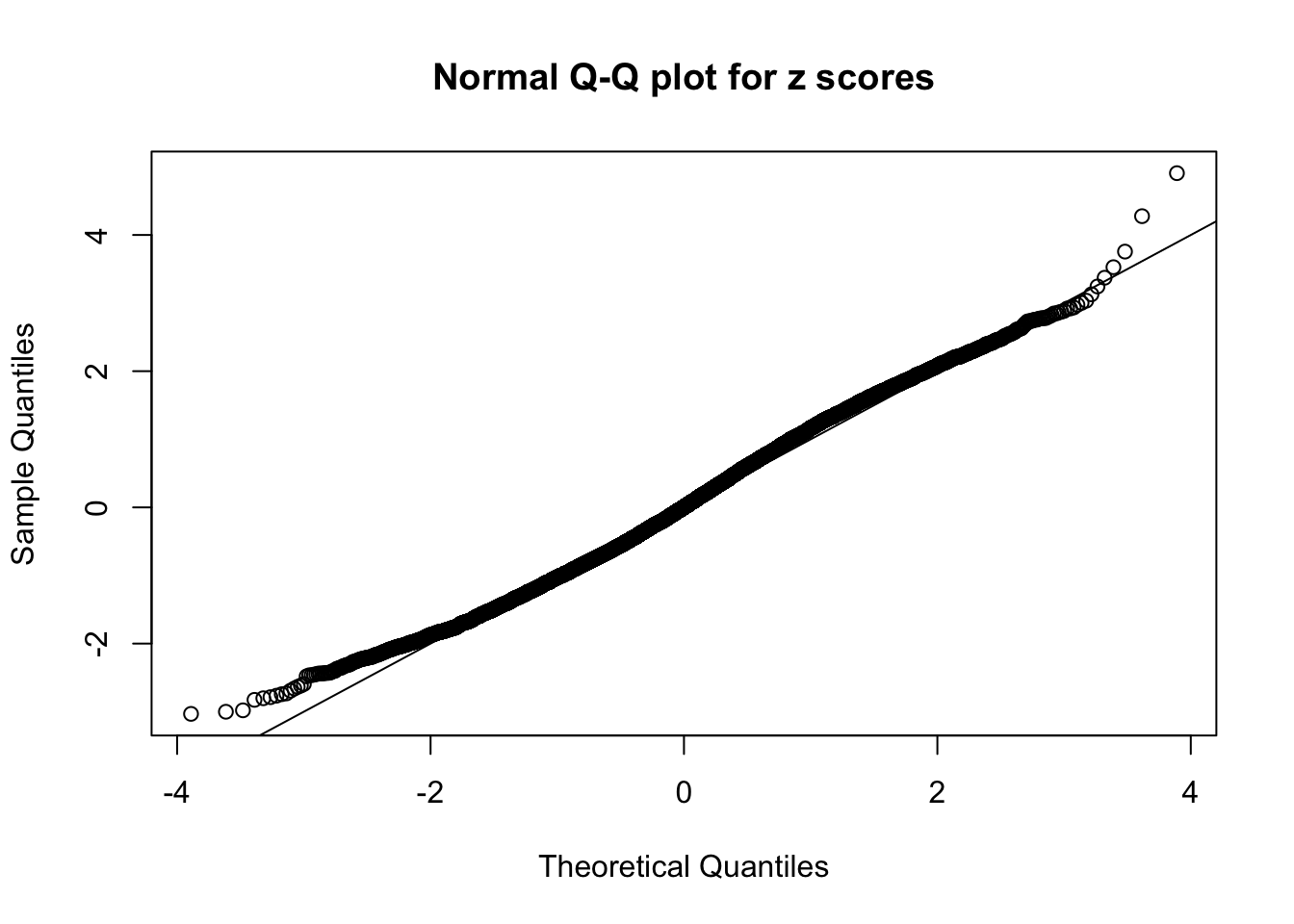
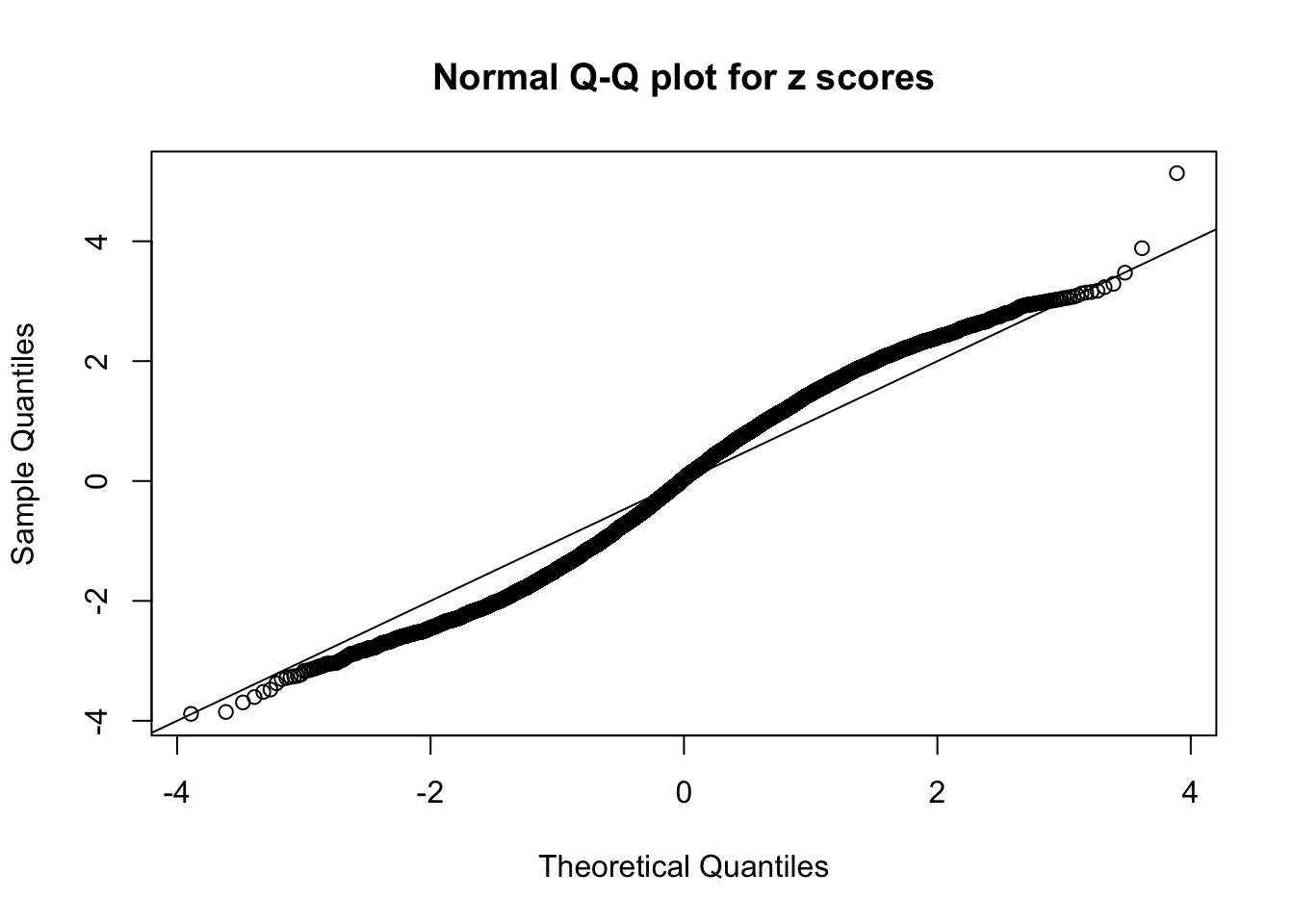
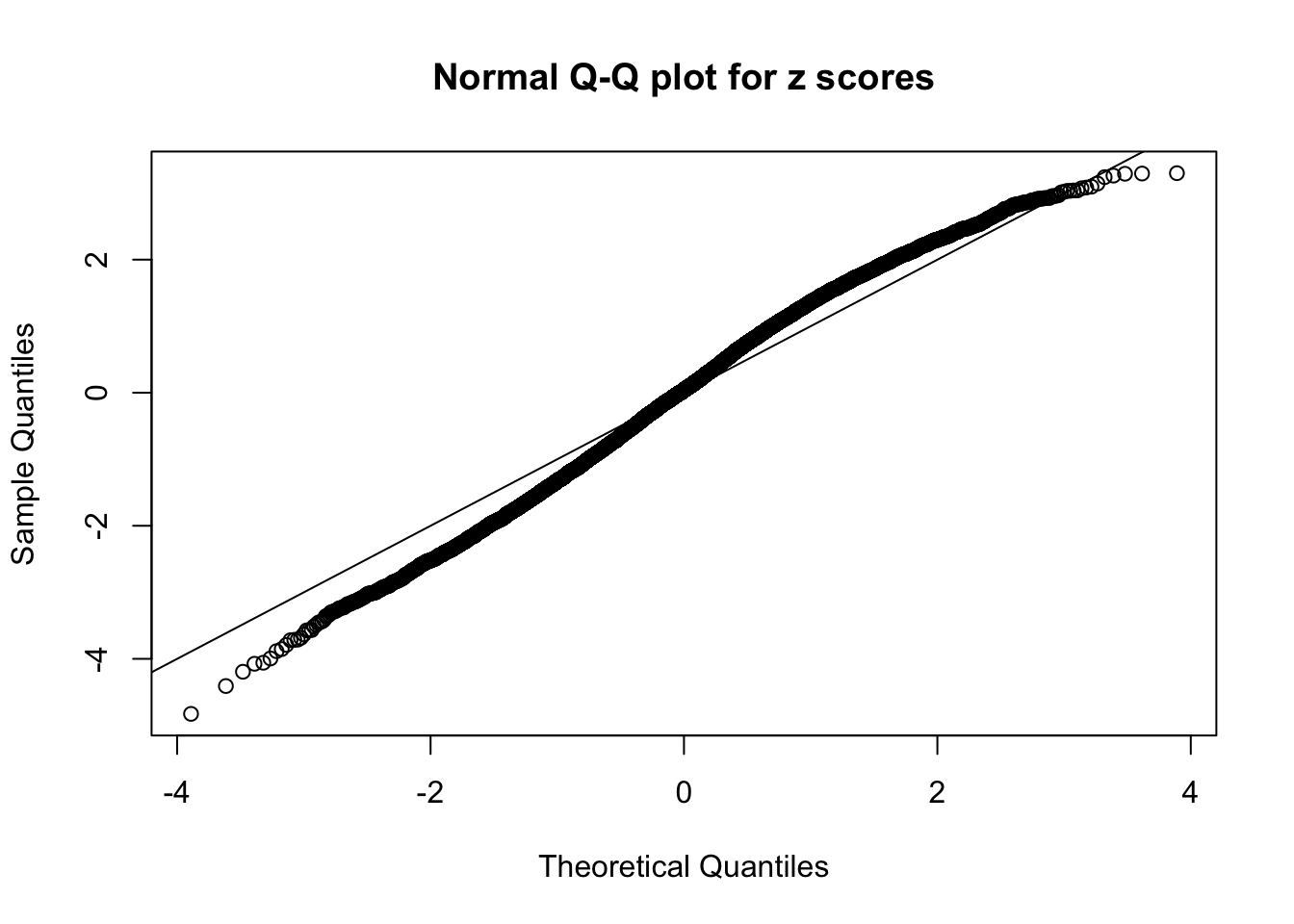
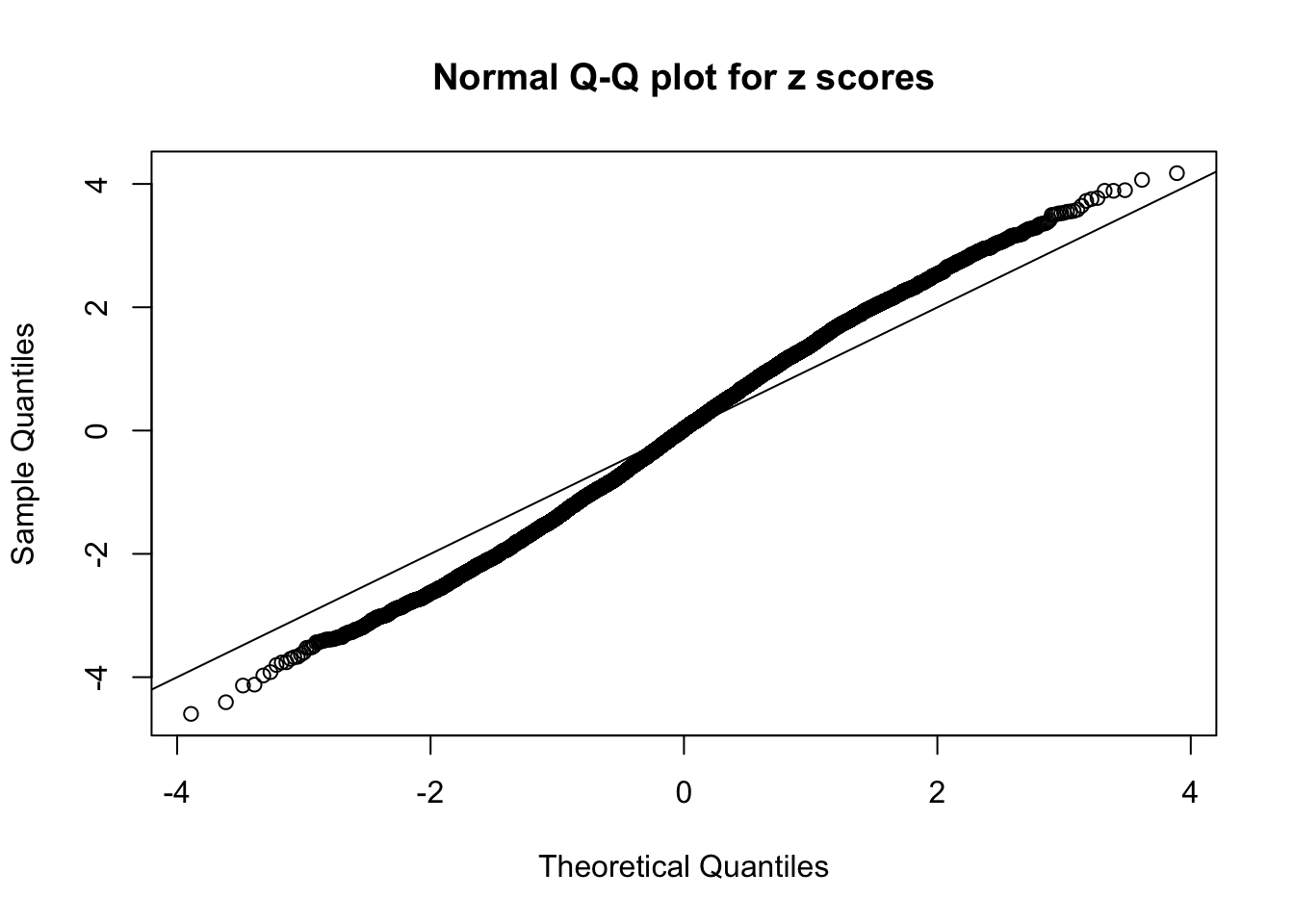
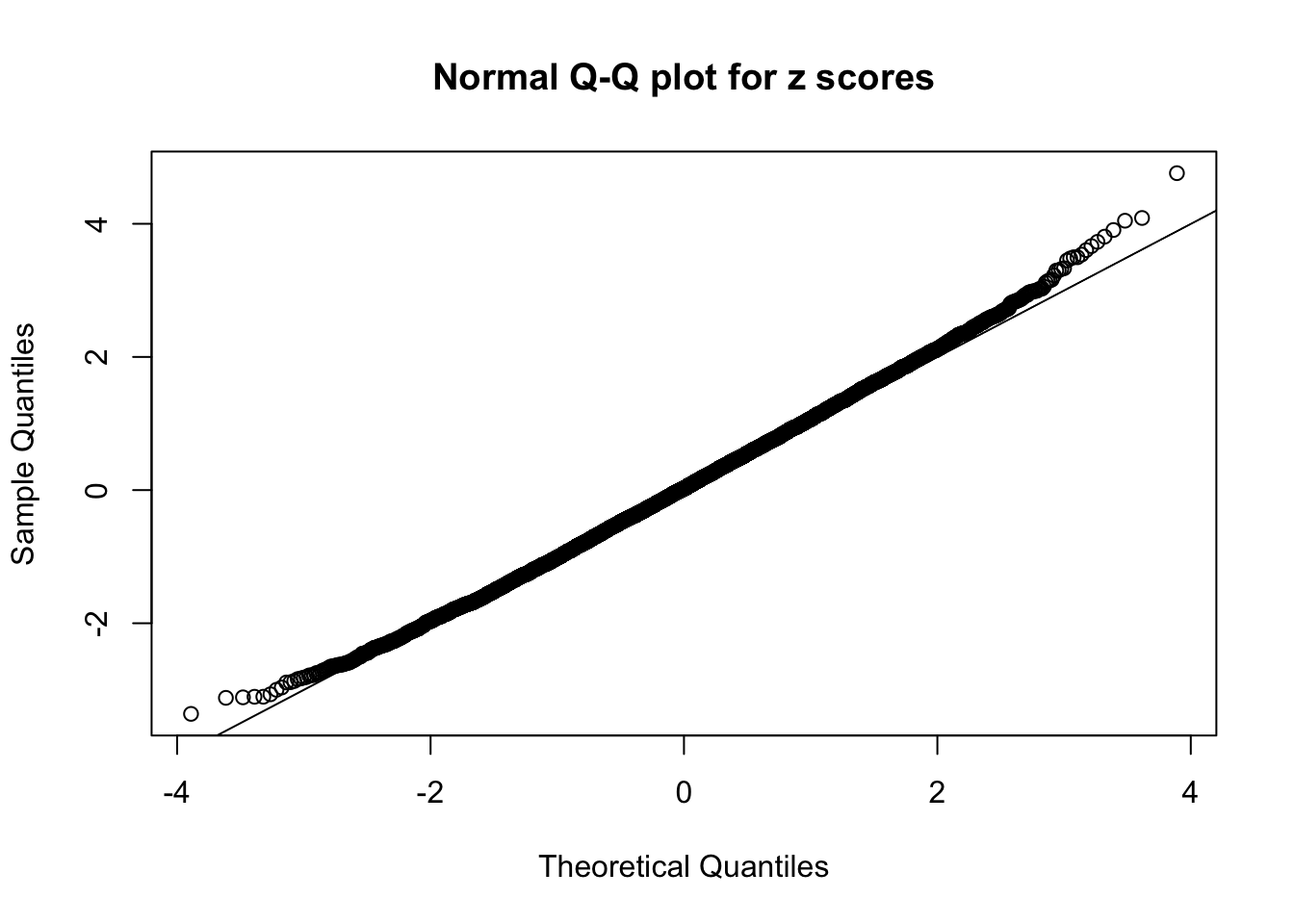
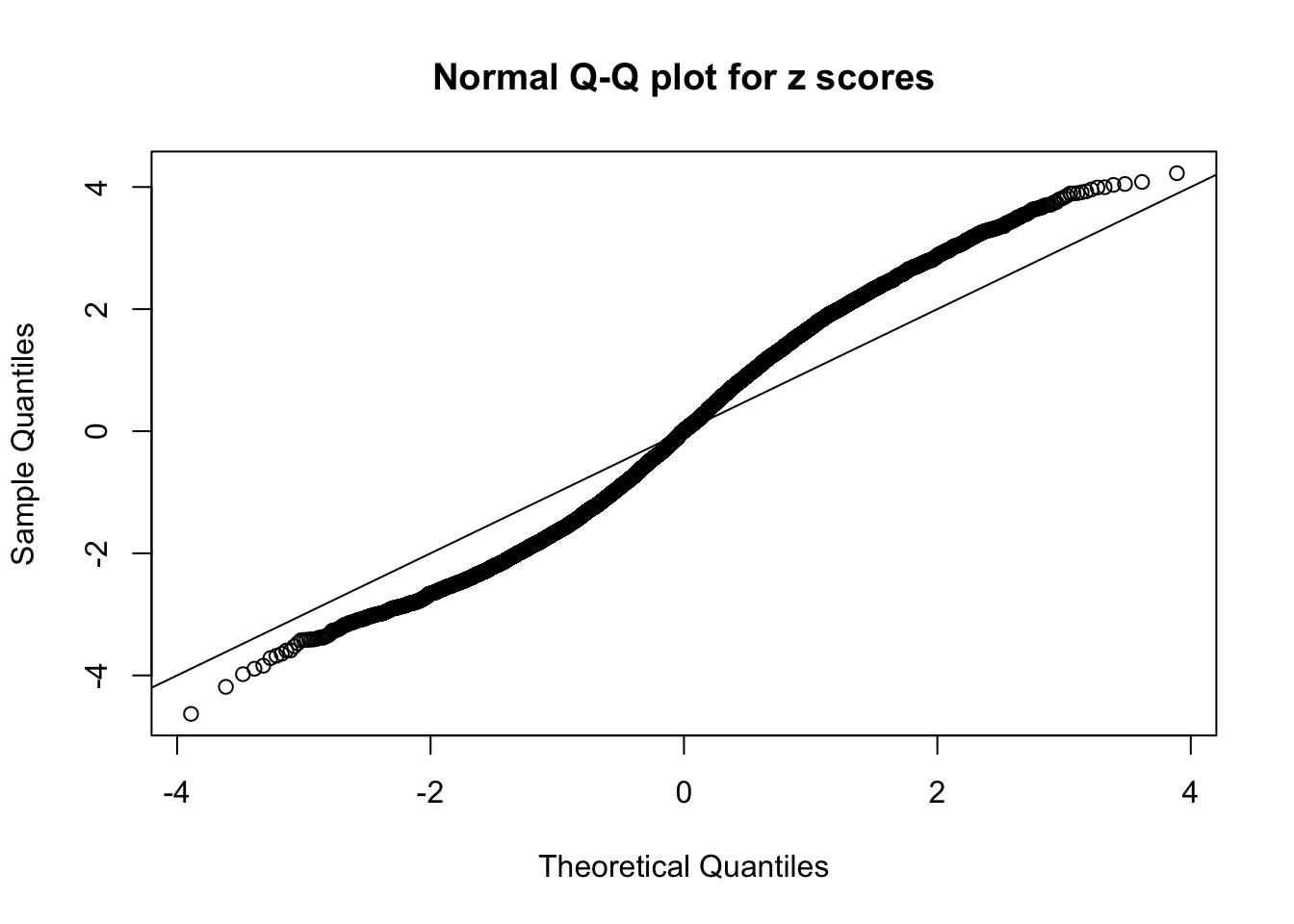
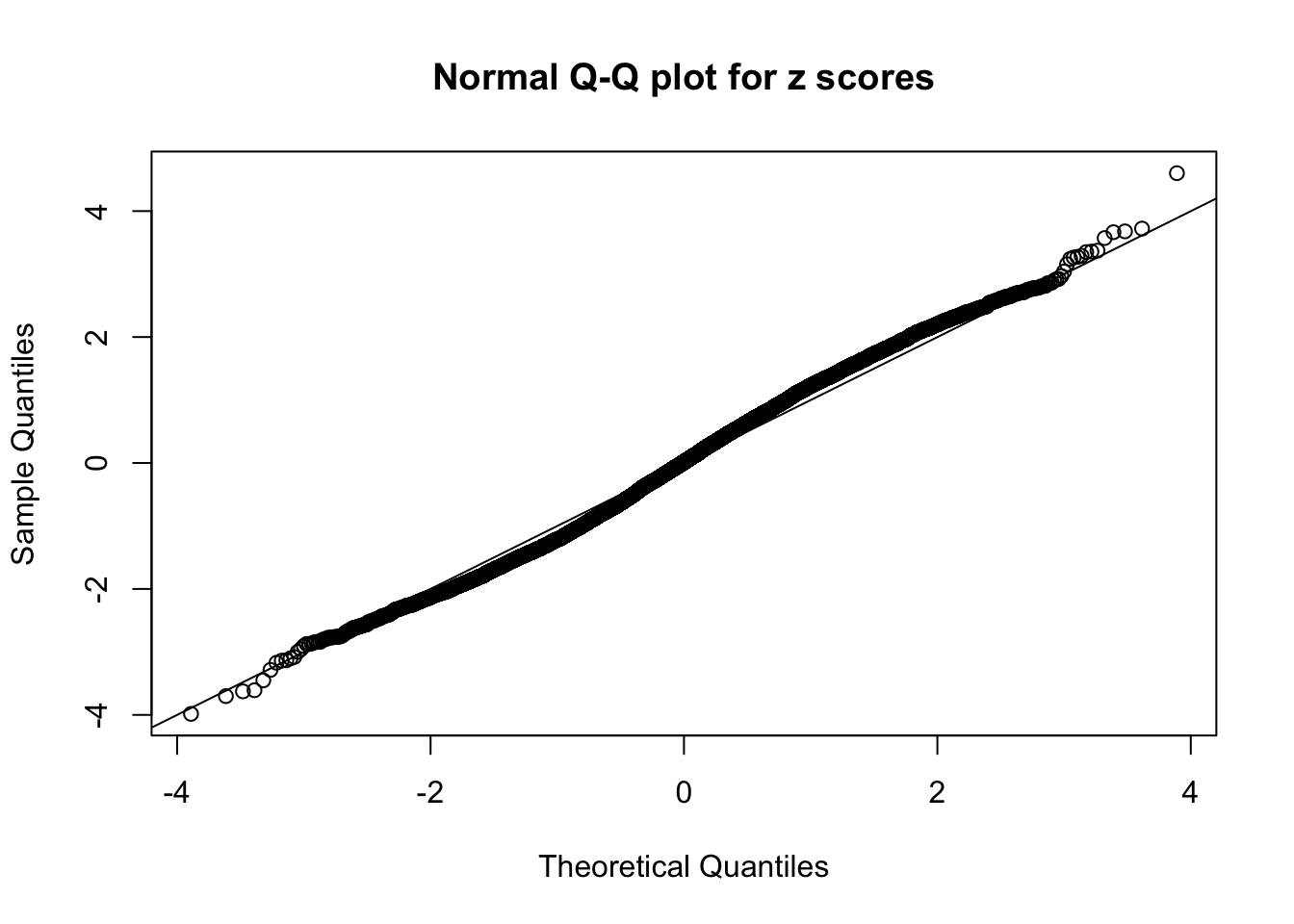
qqnorm(as.numeric(z[j, ]), main = "Normal Q-Q plot for z scores")
abline(0, 1)
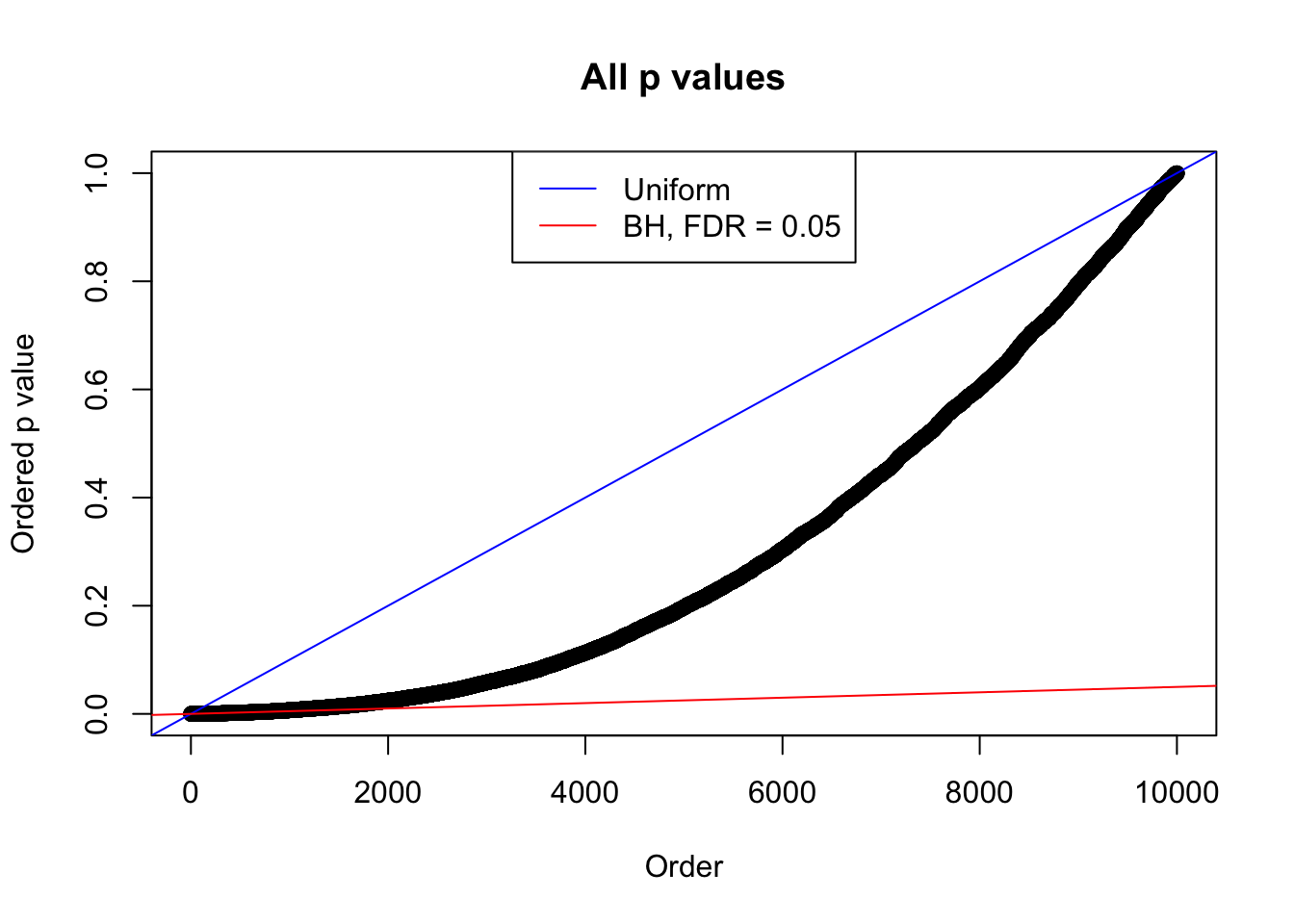
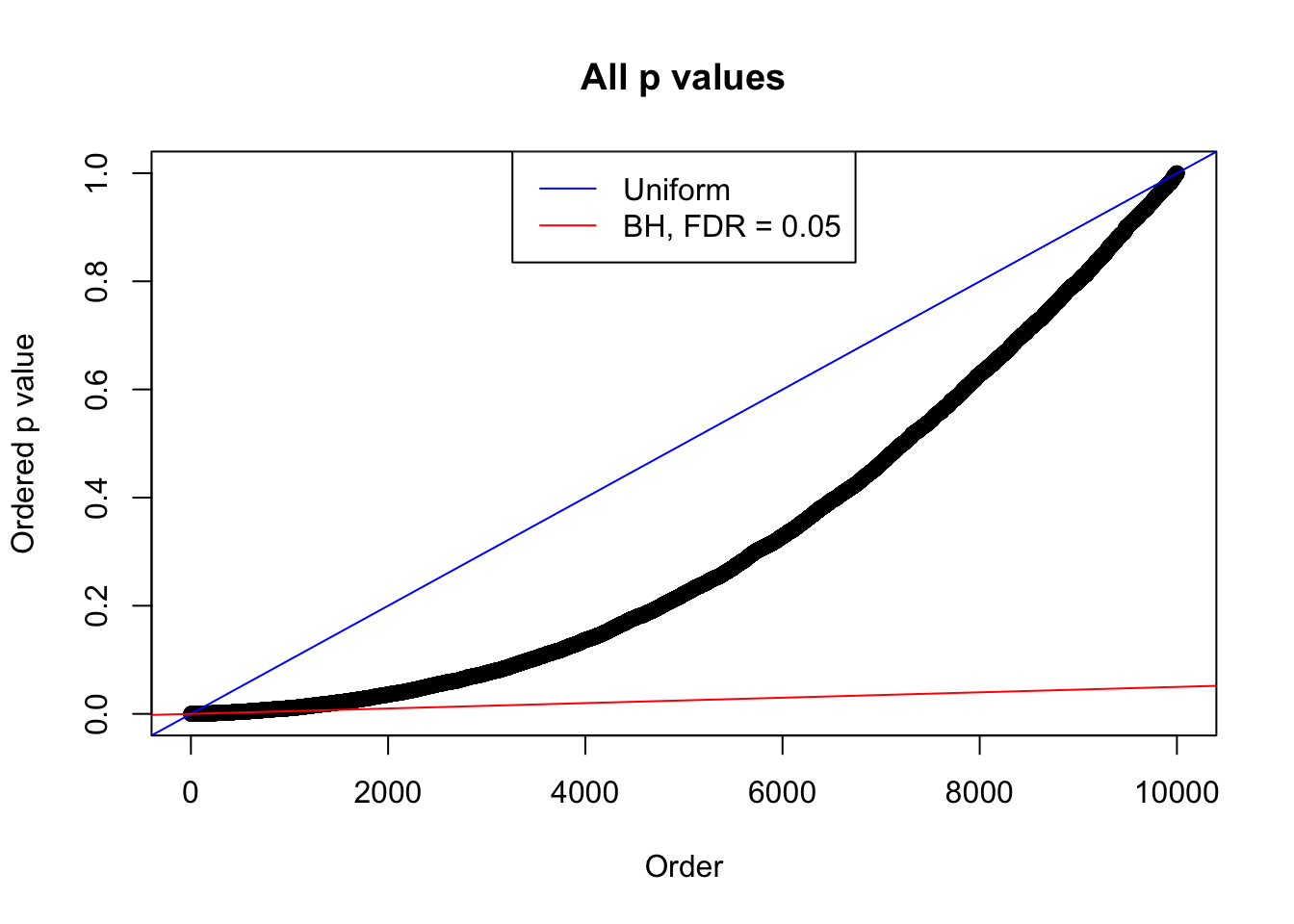
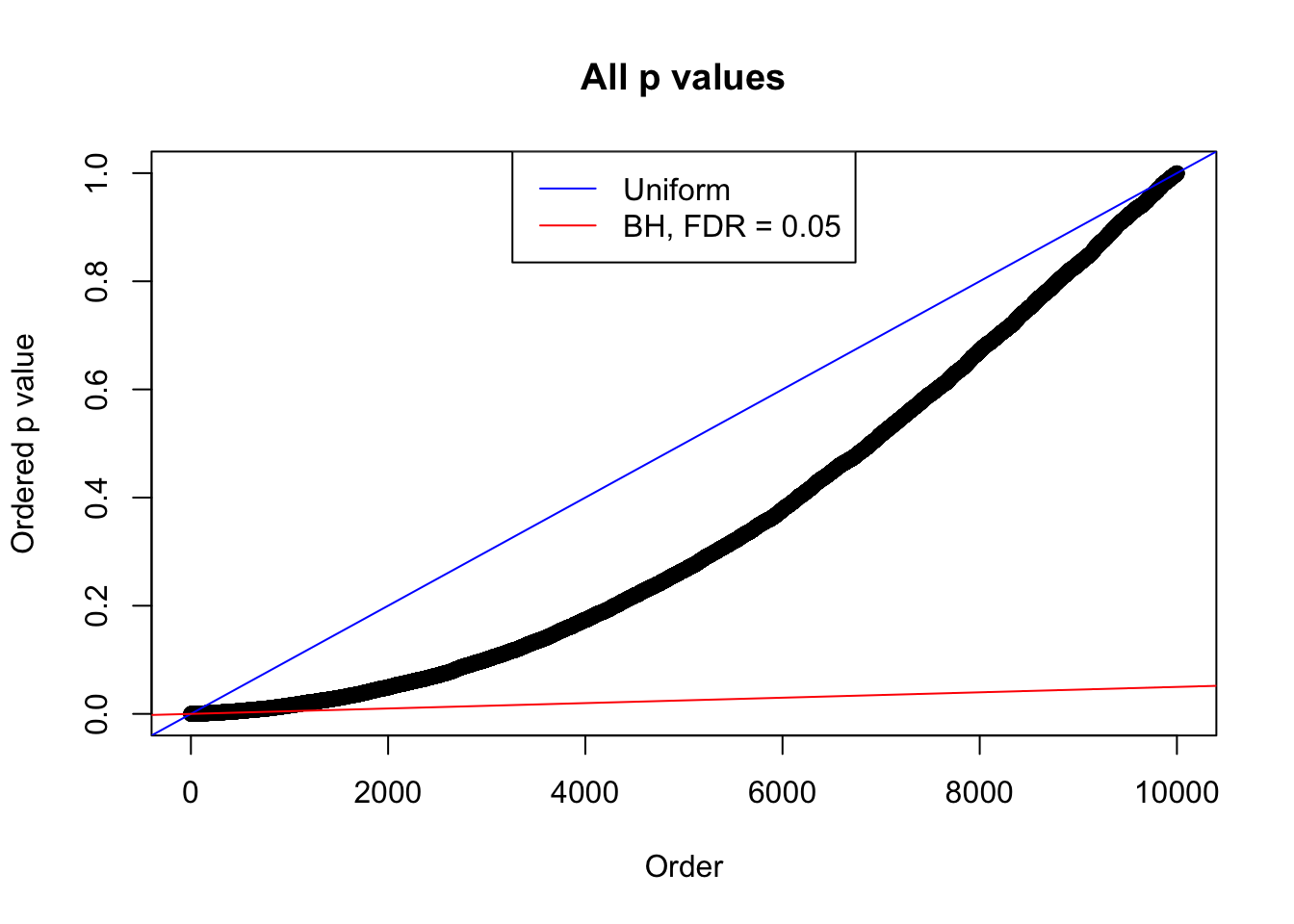
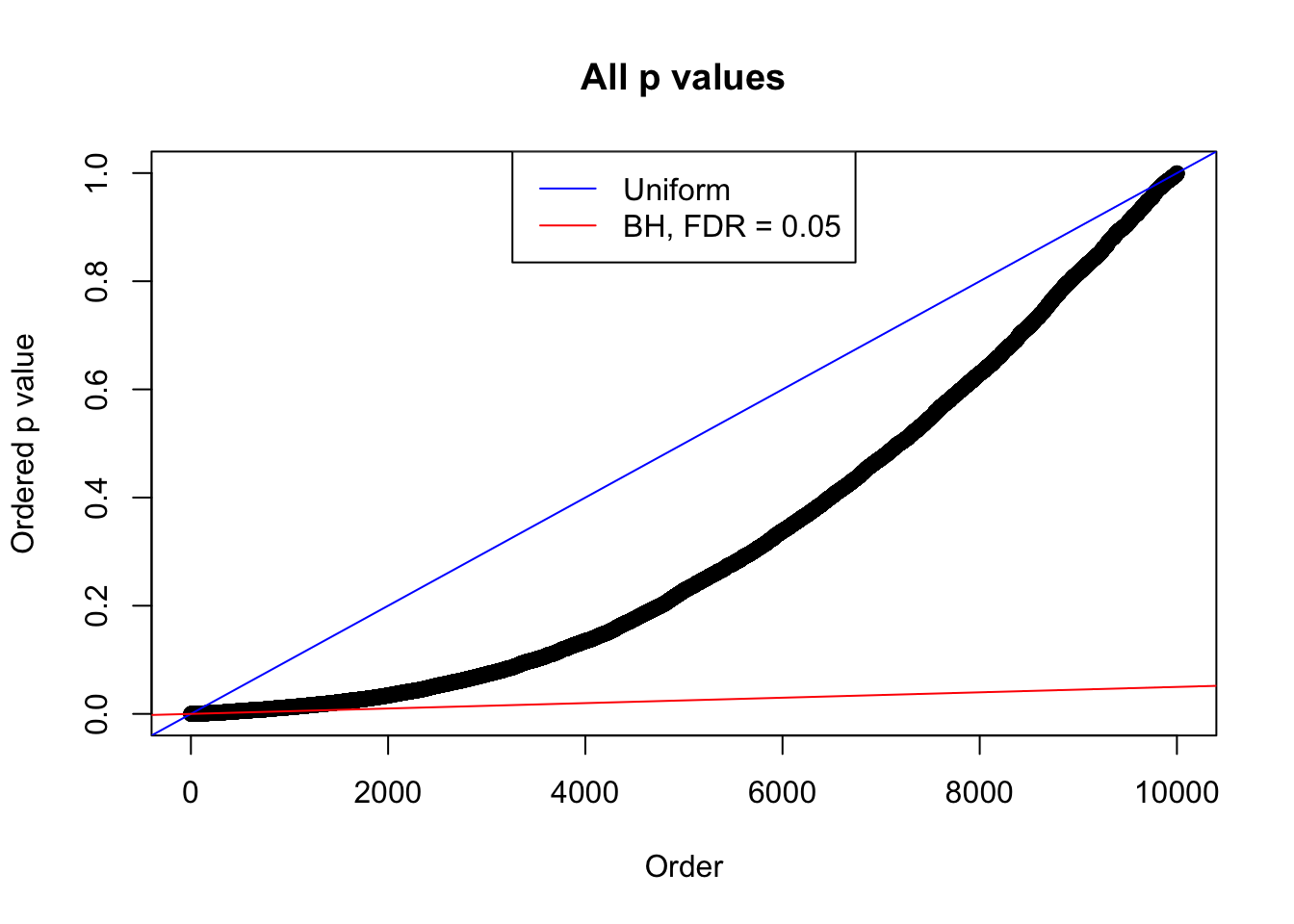
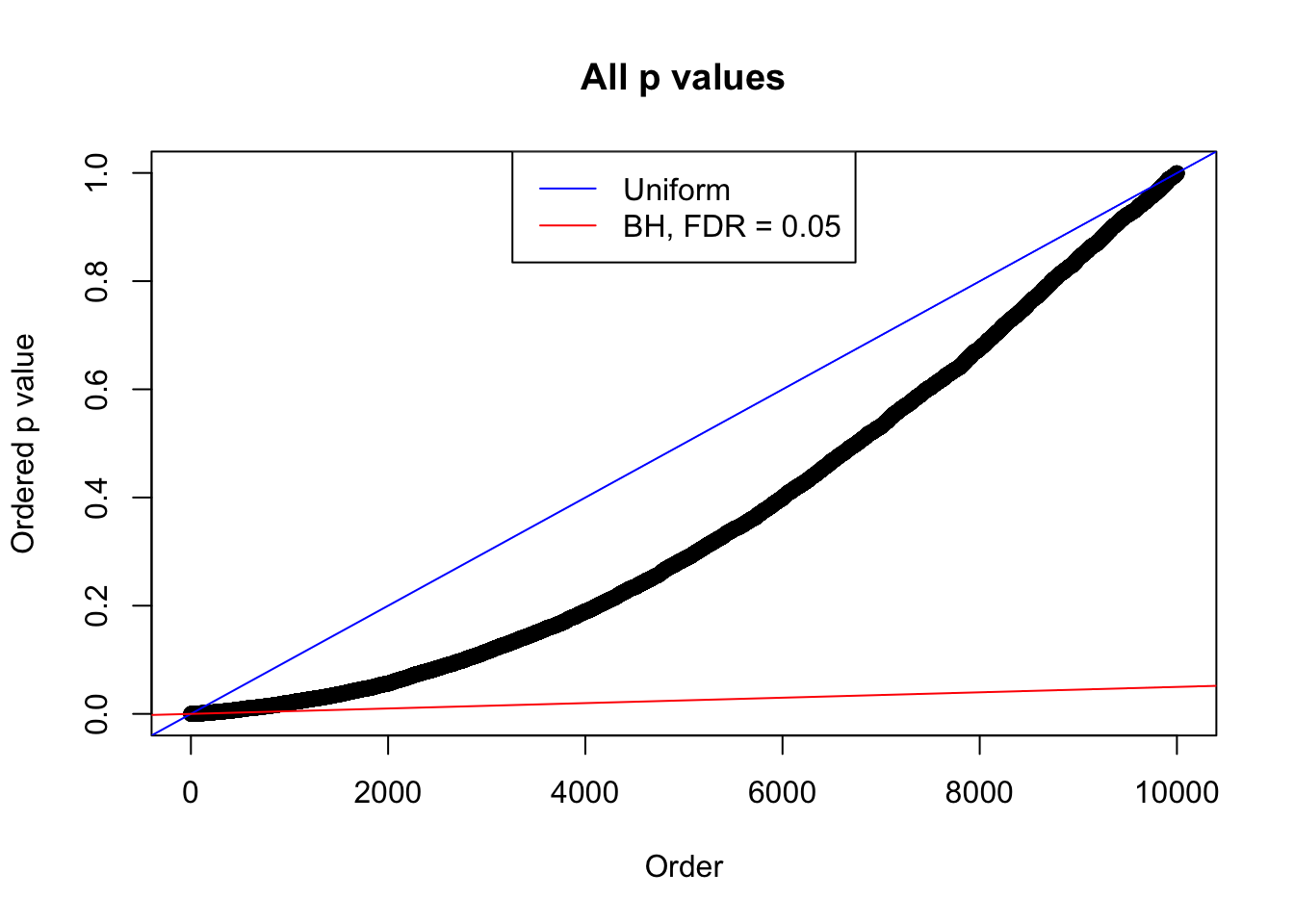
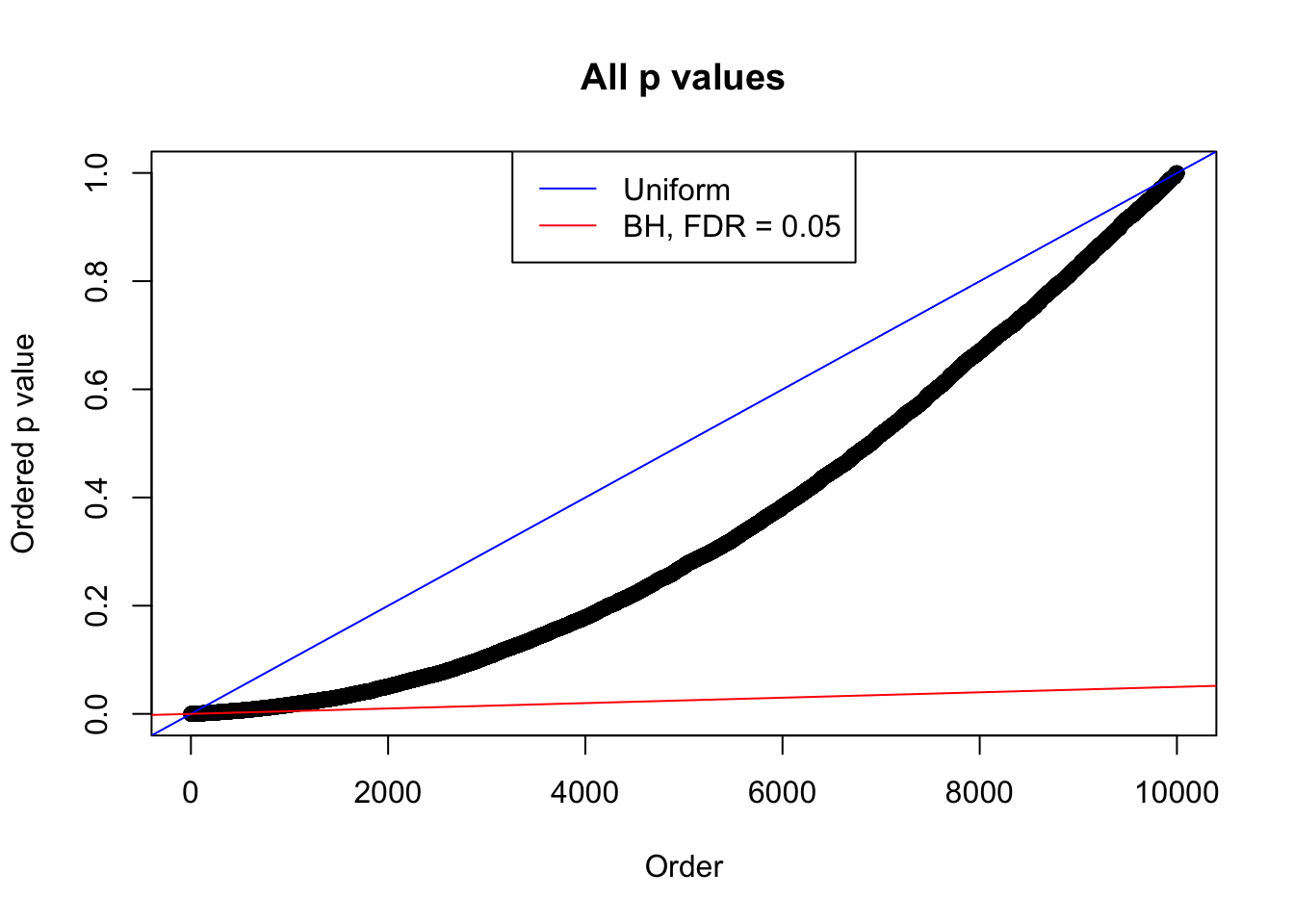
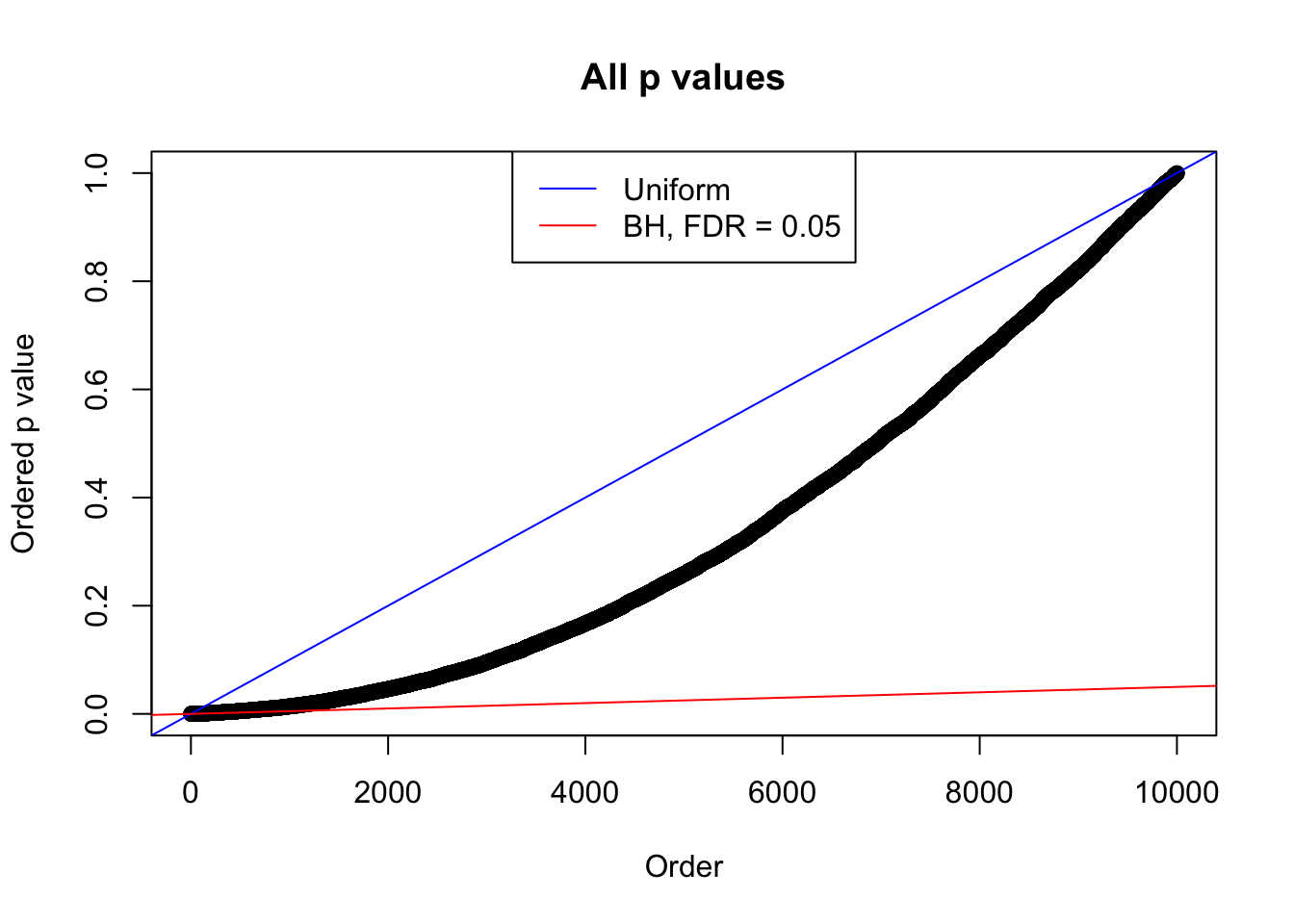
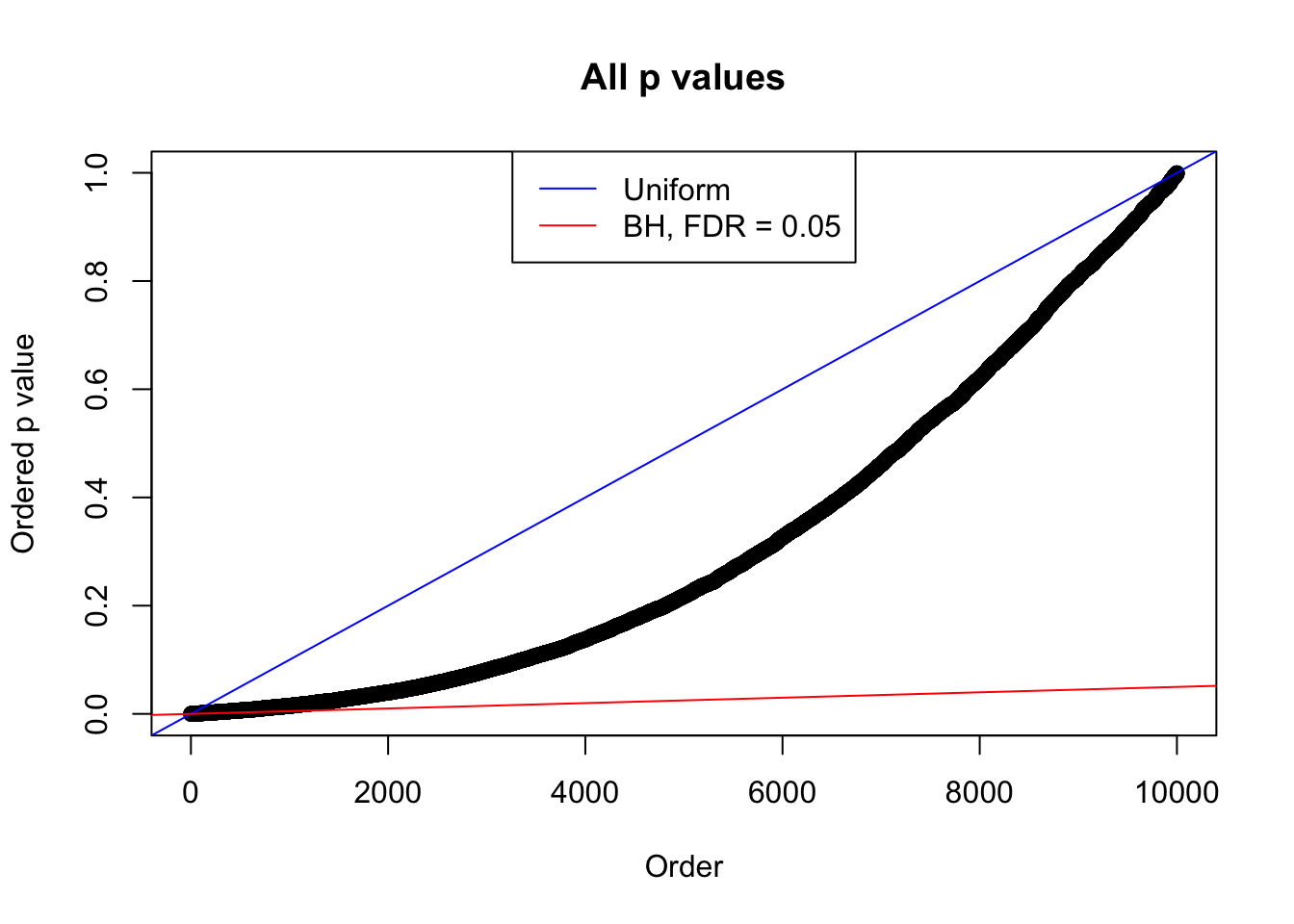
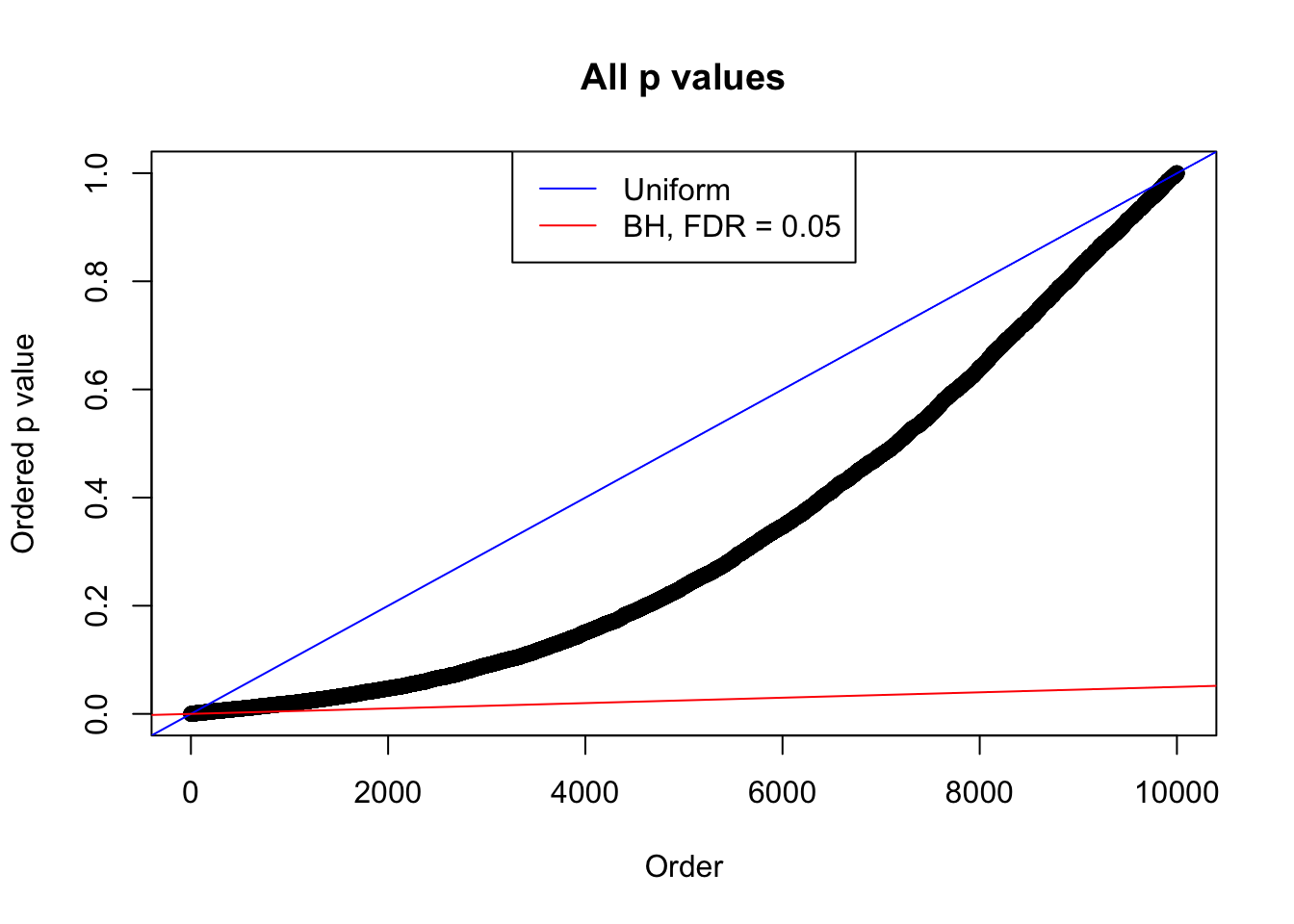
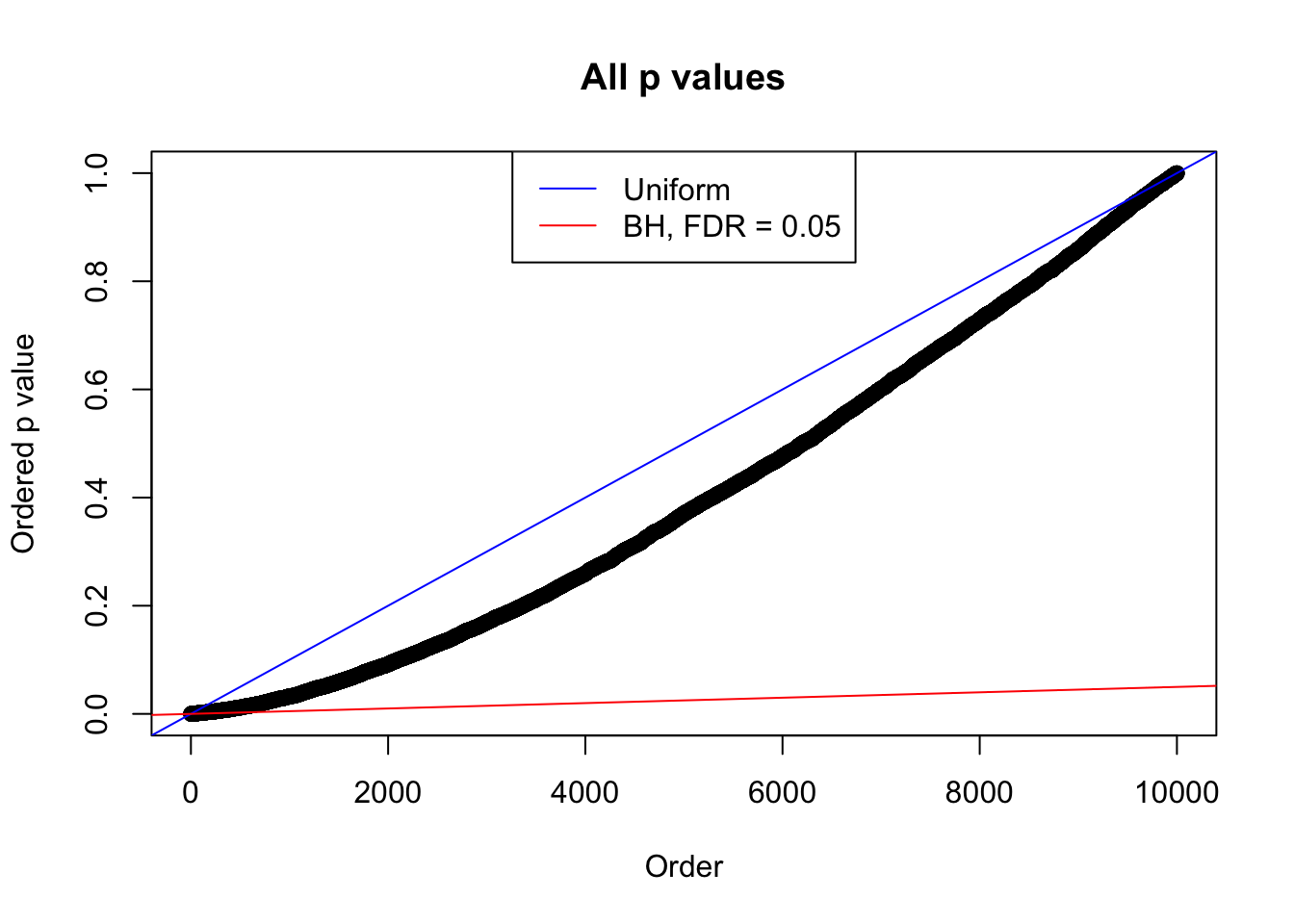
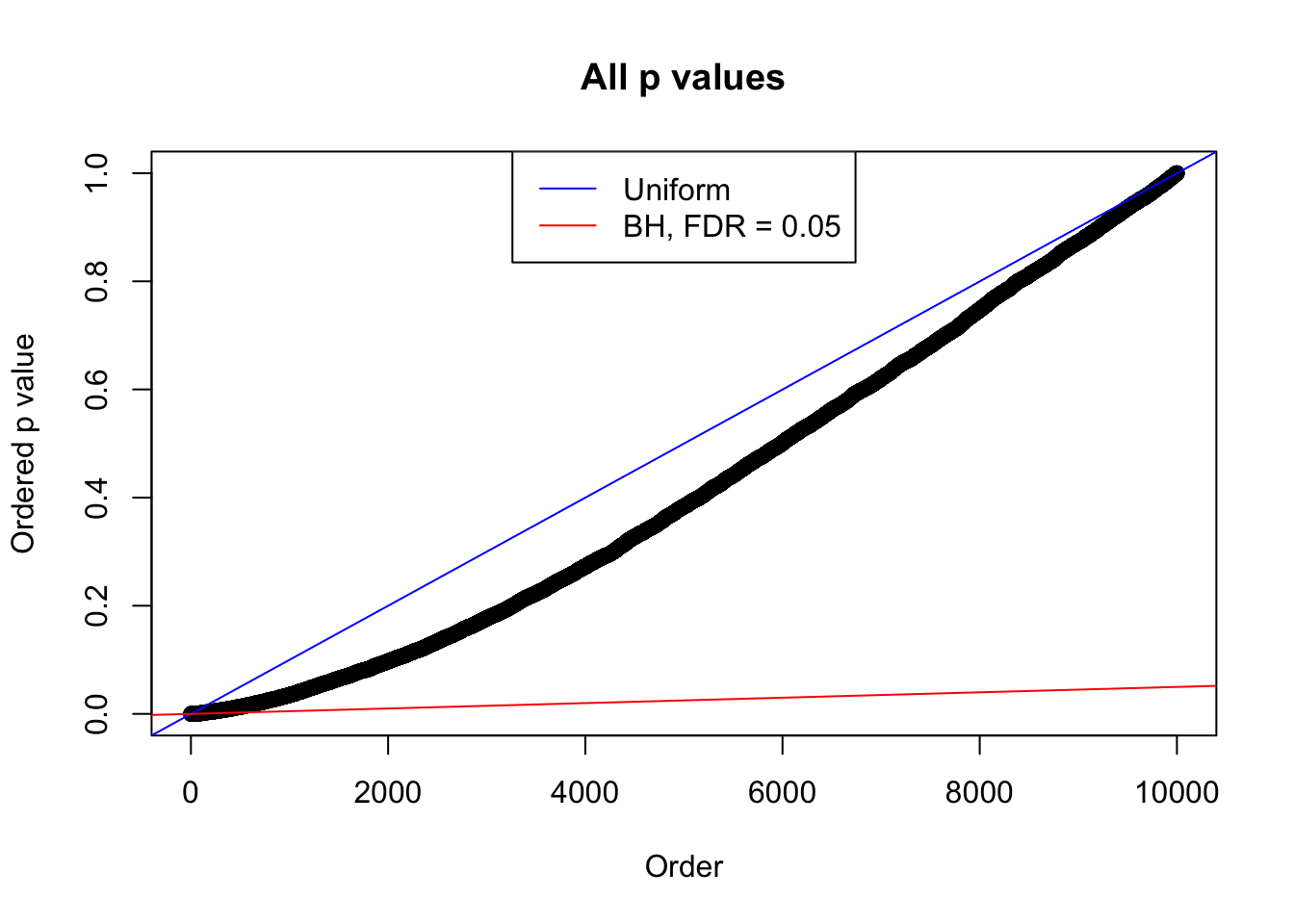
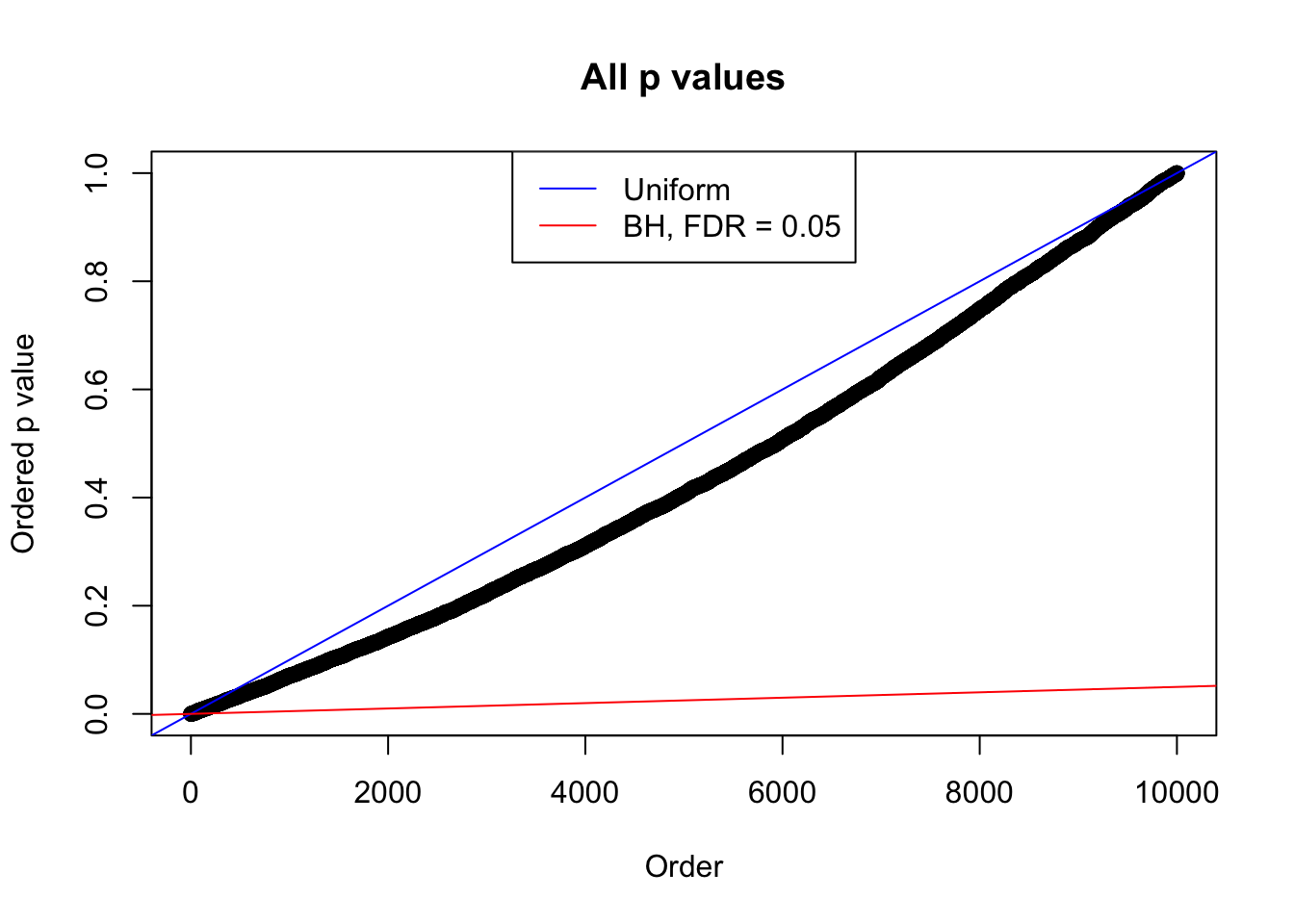
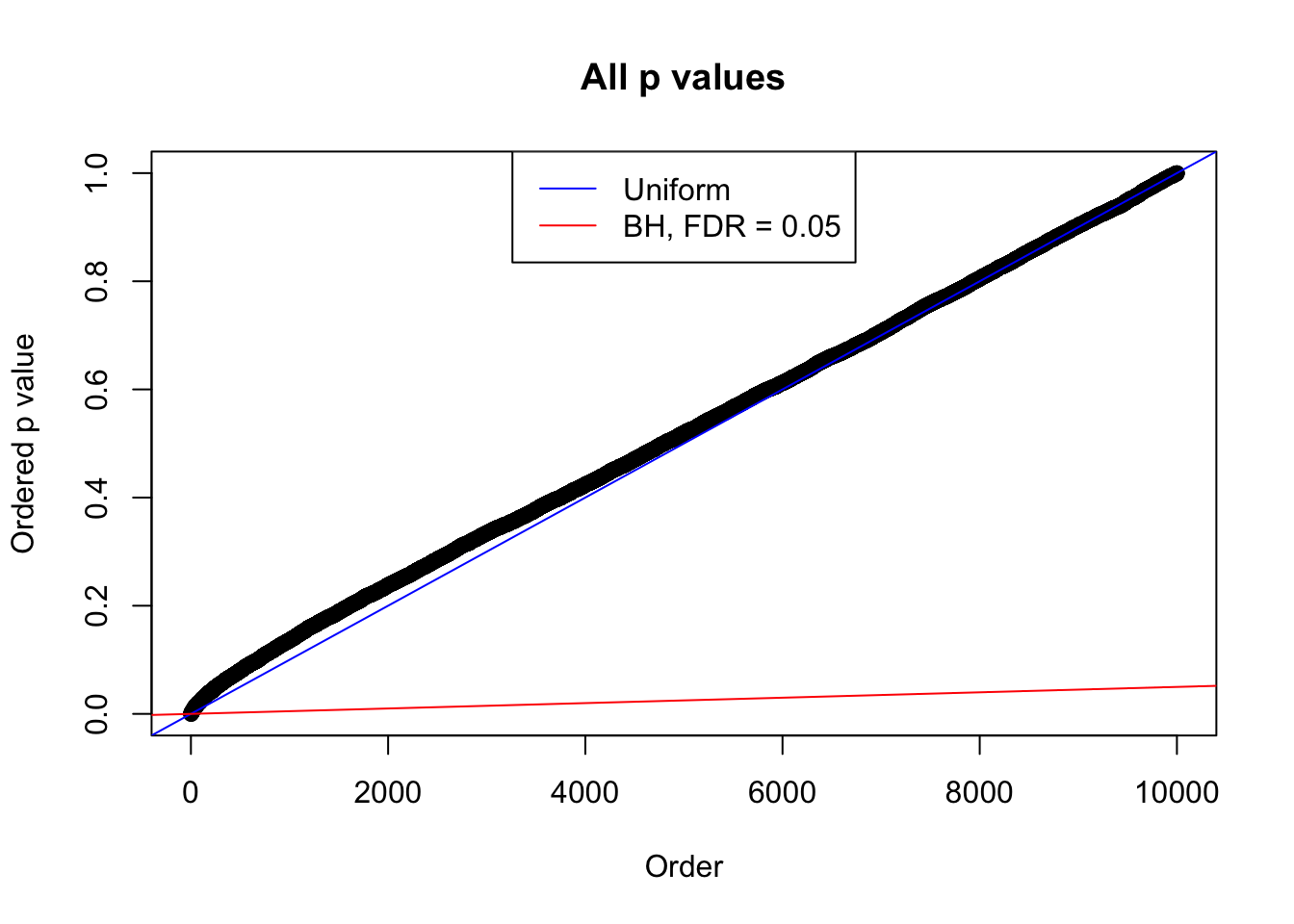
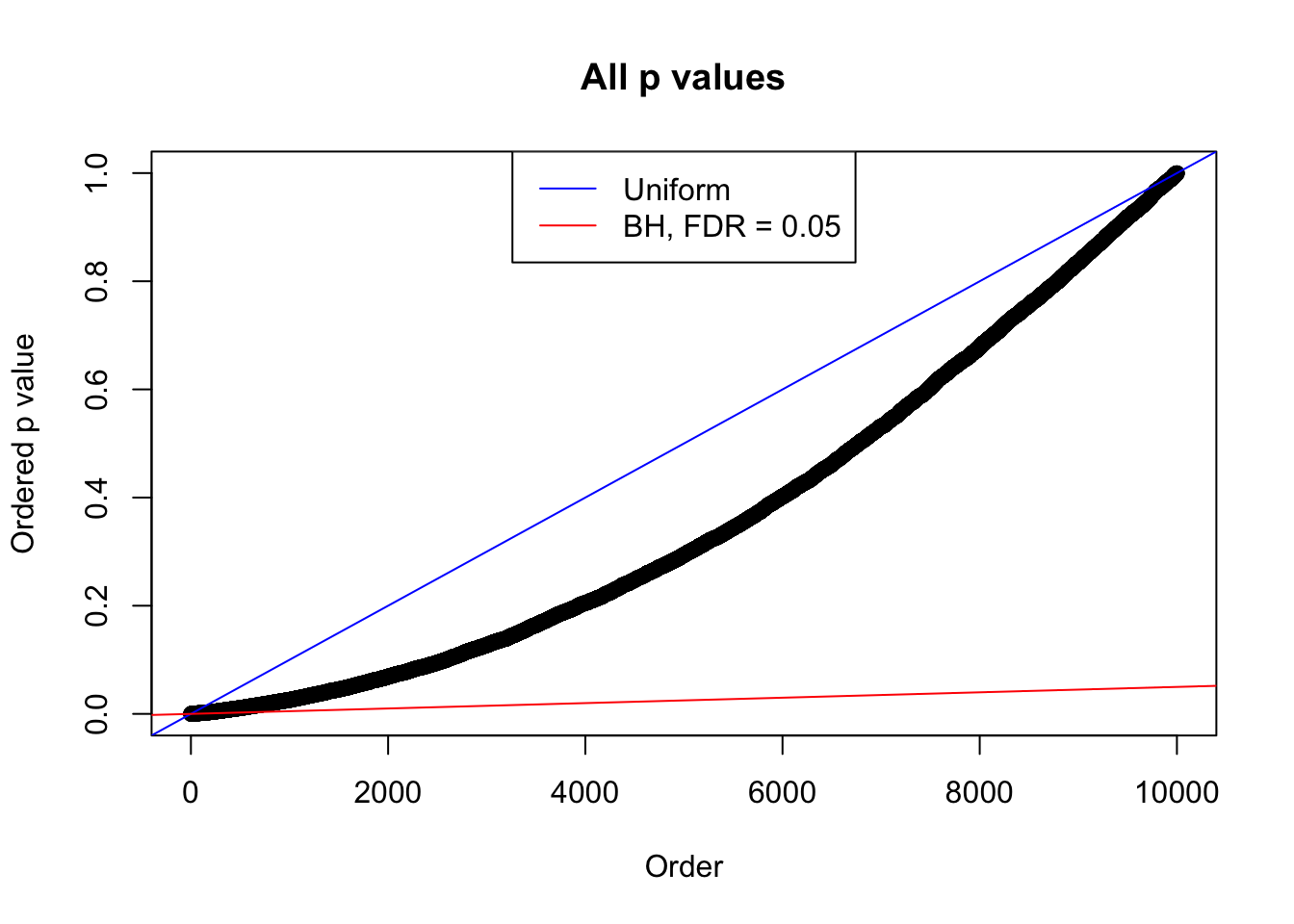
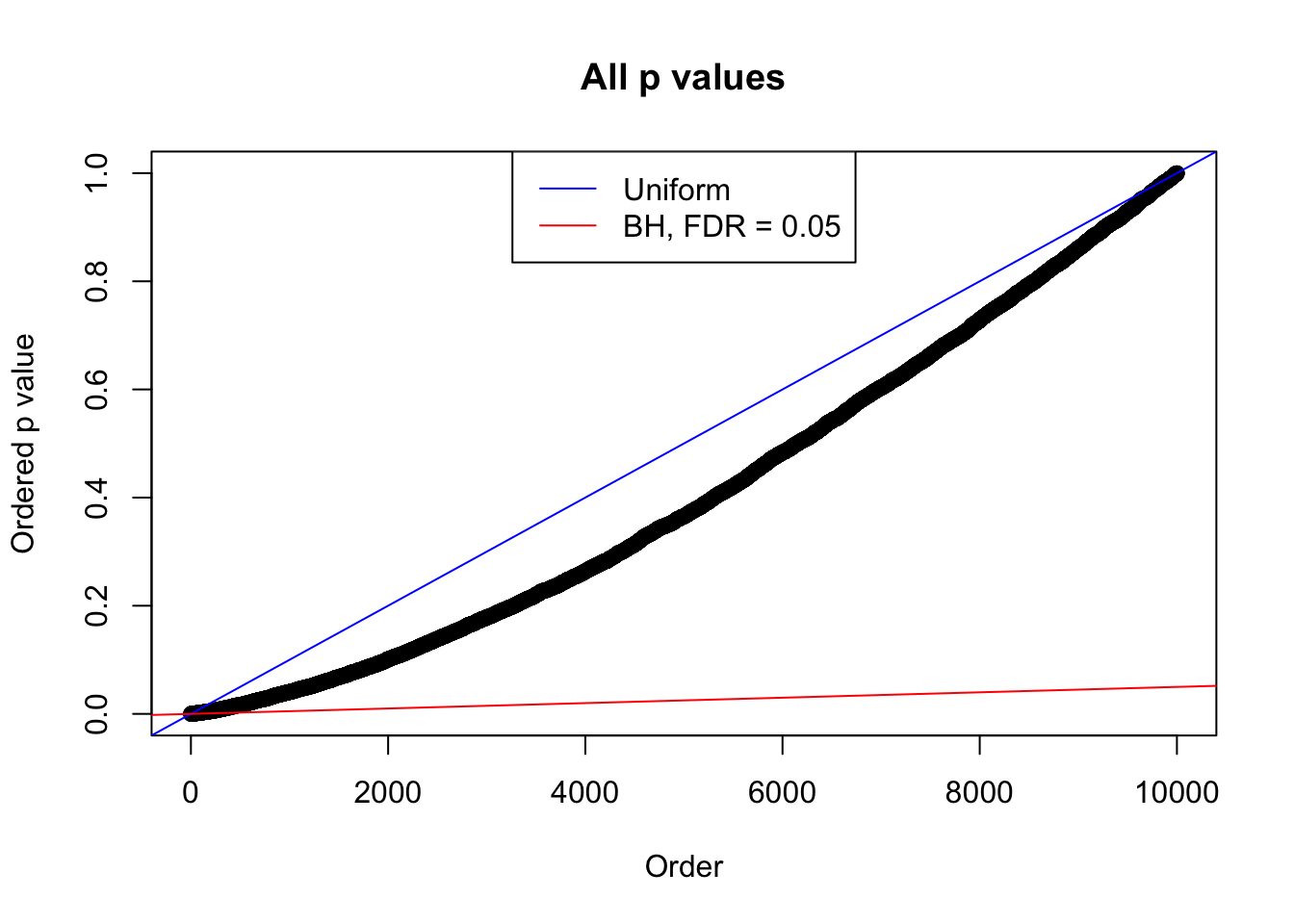
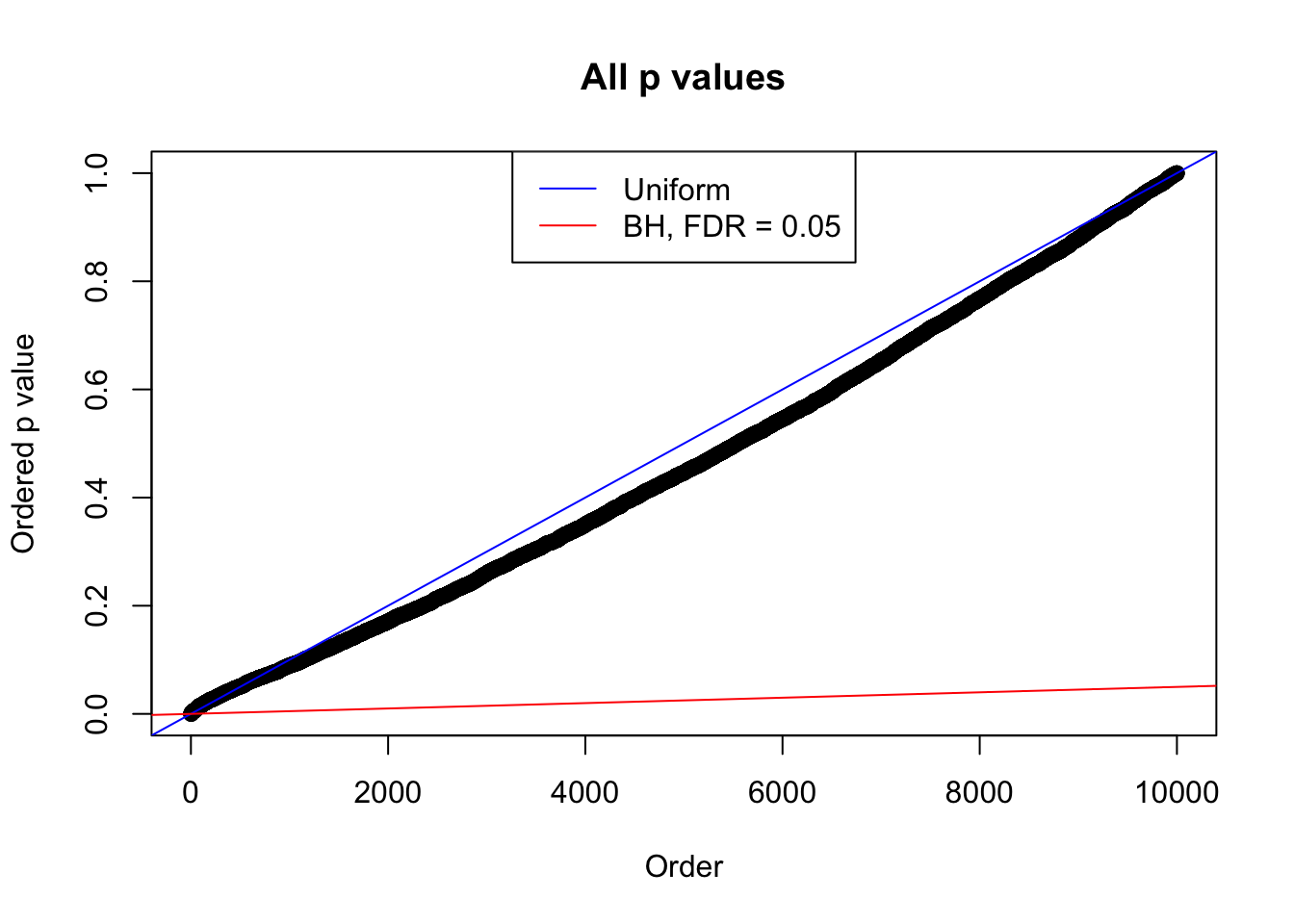
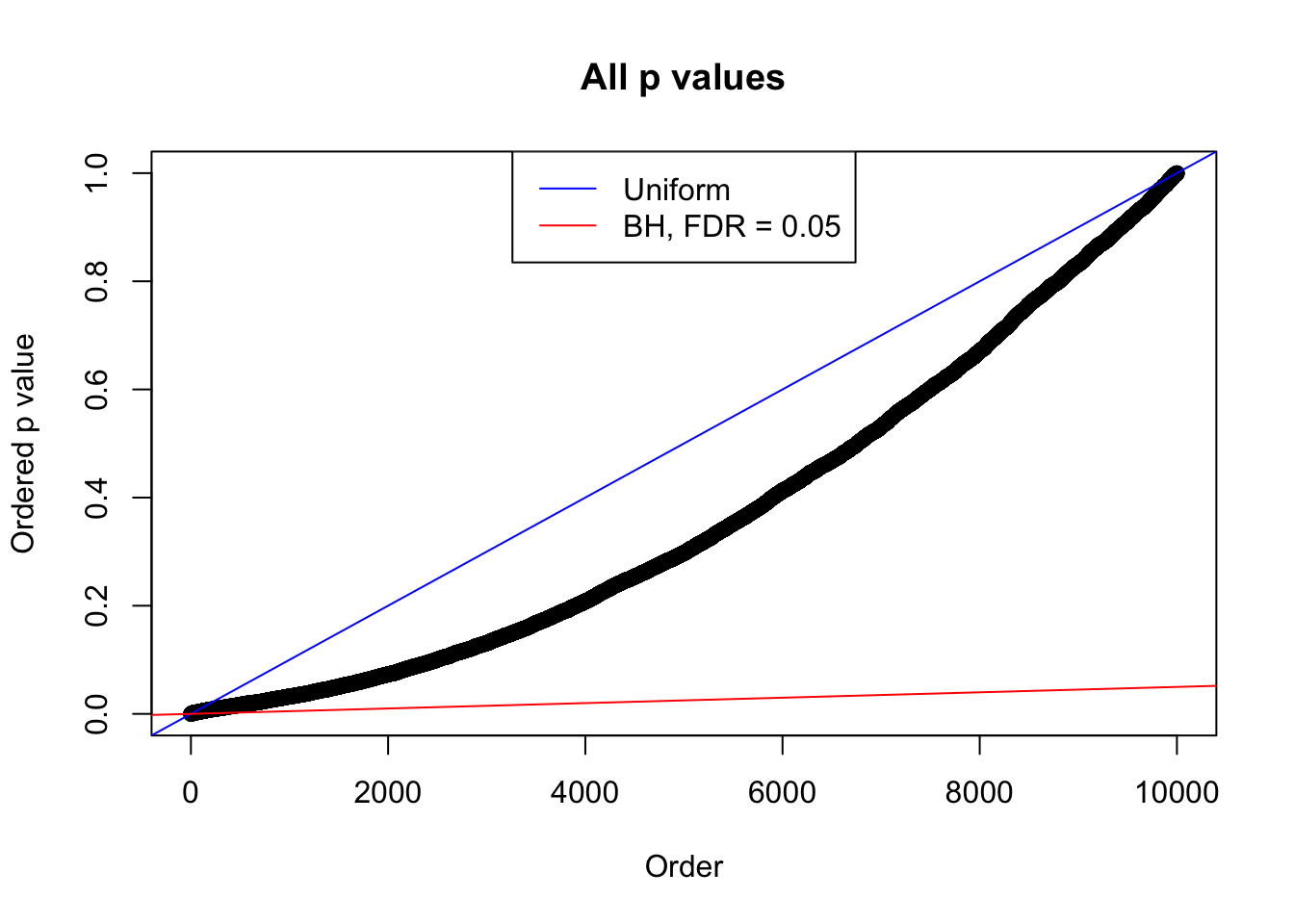
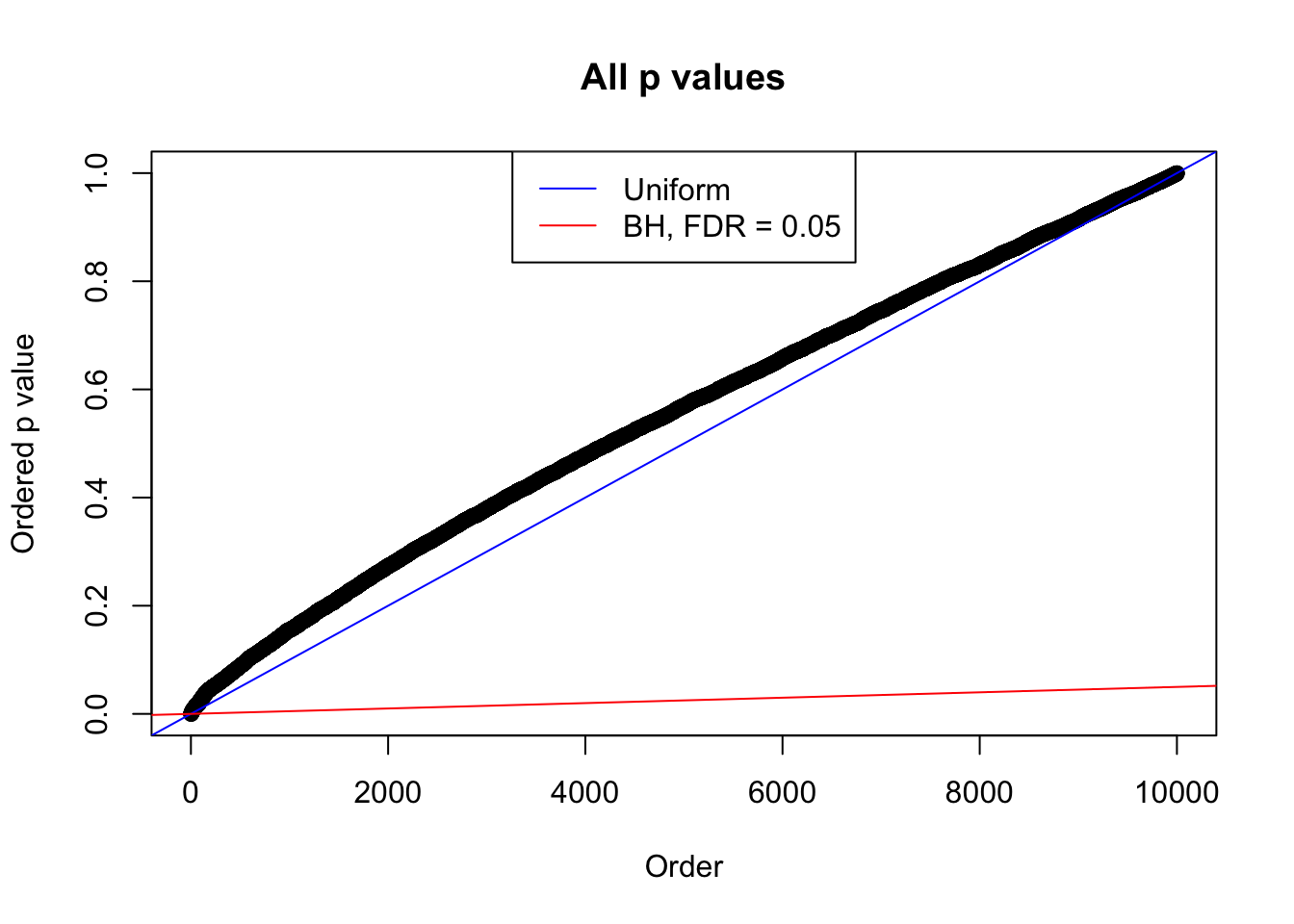
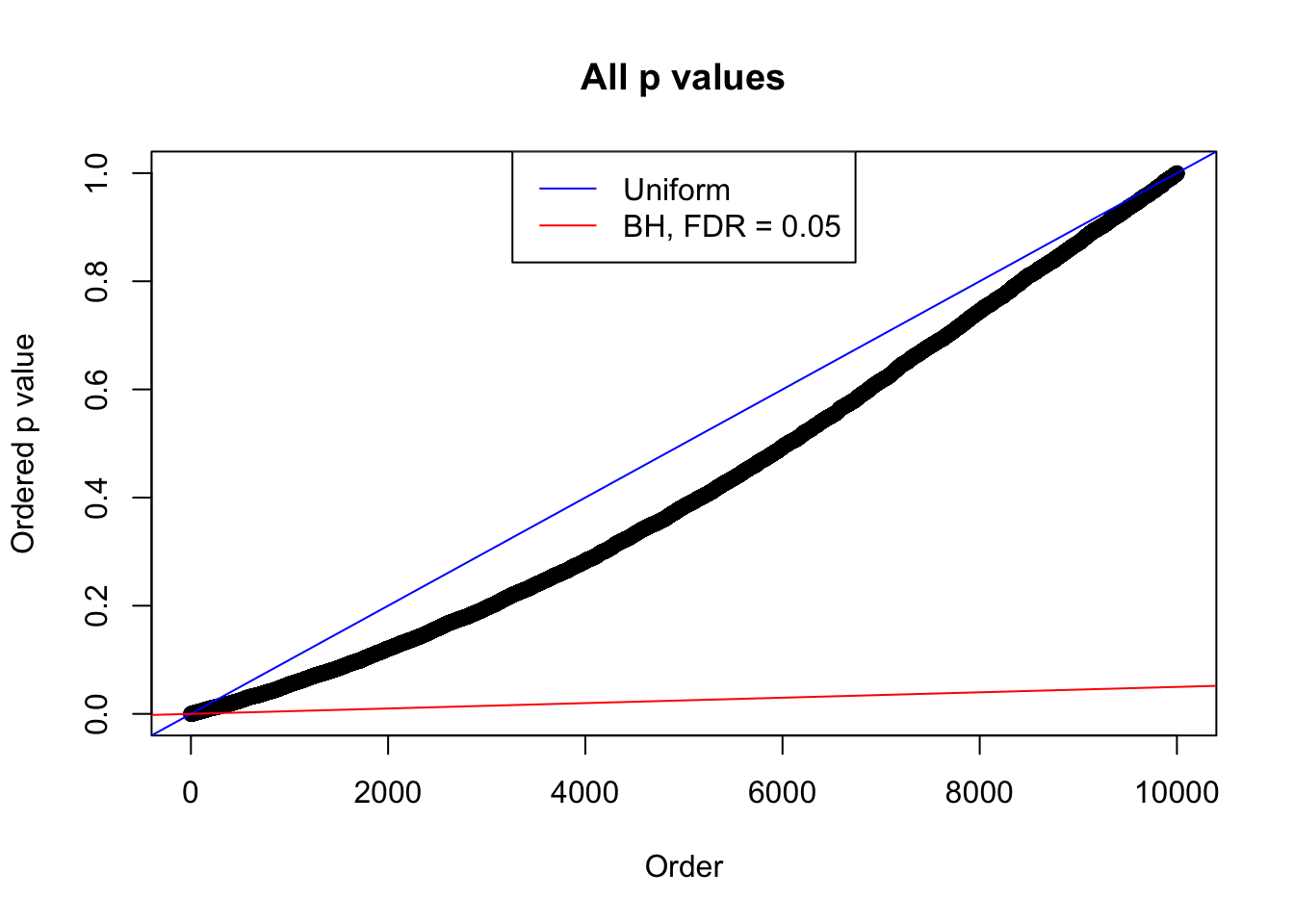
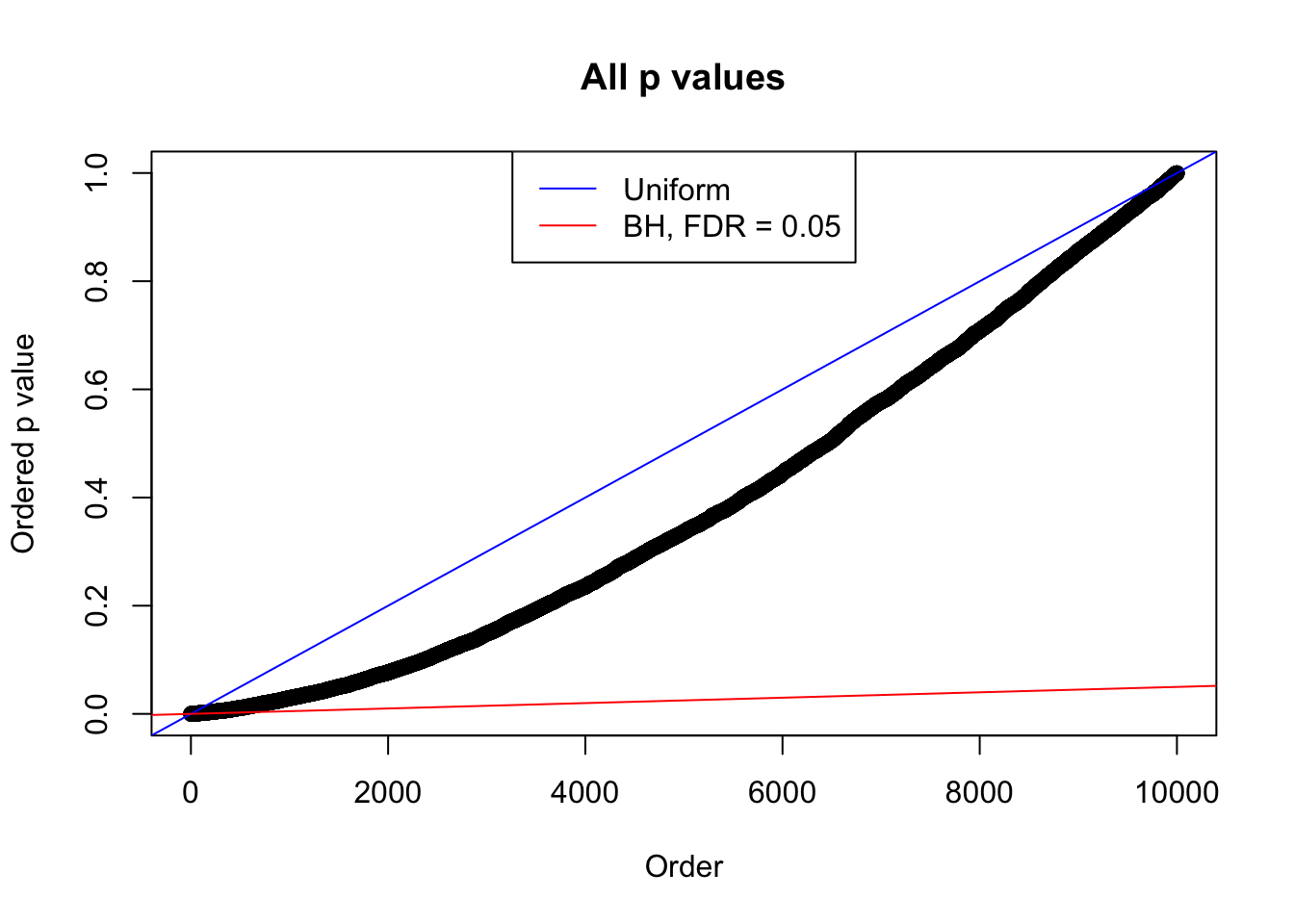
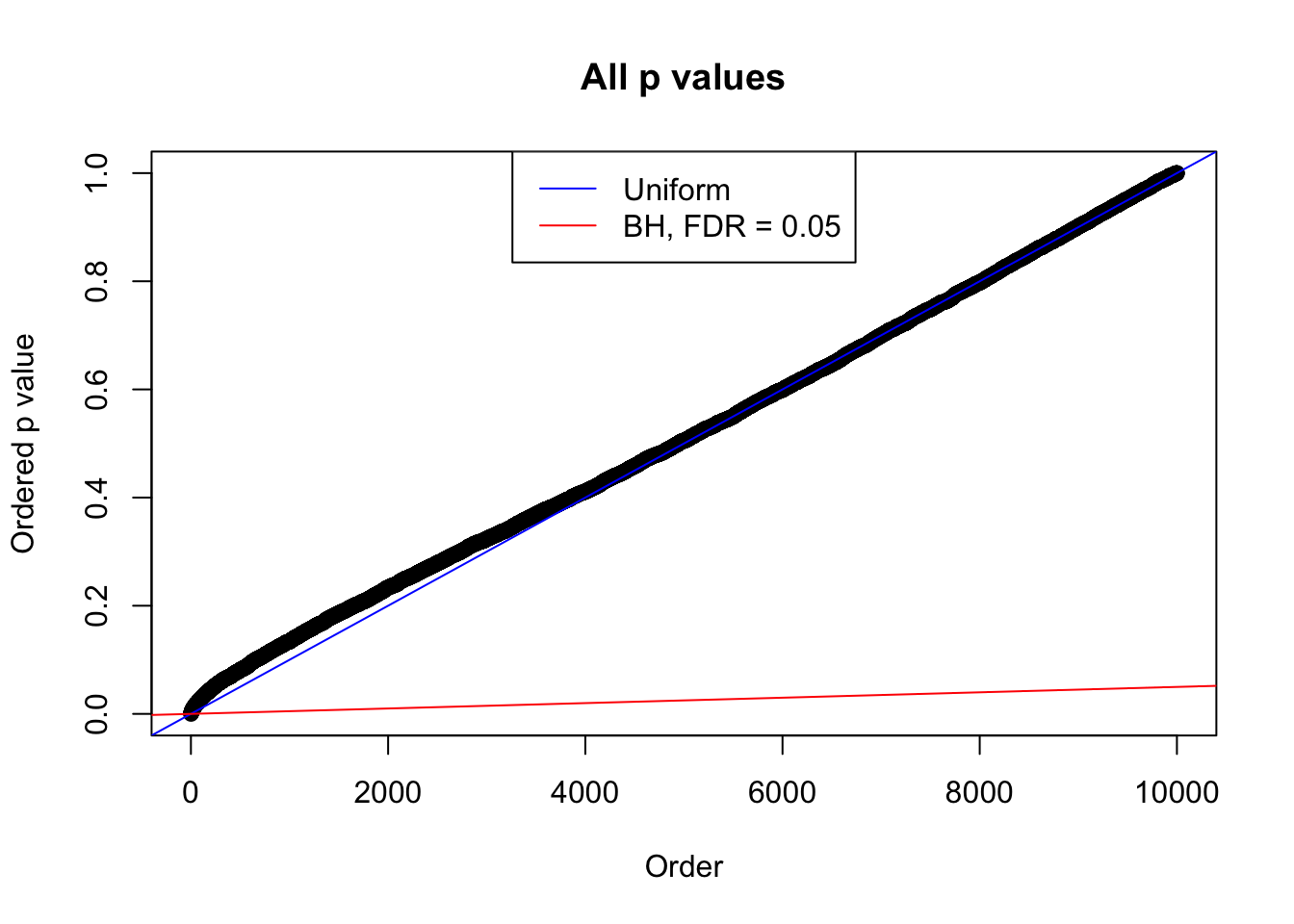
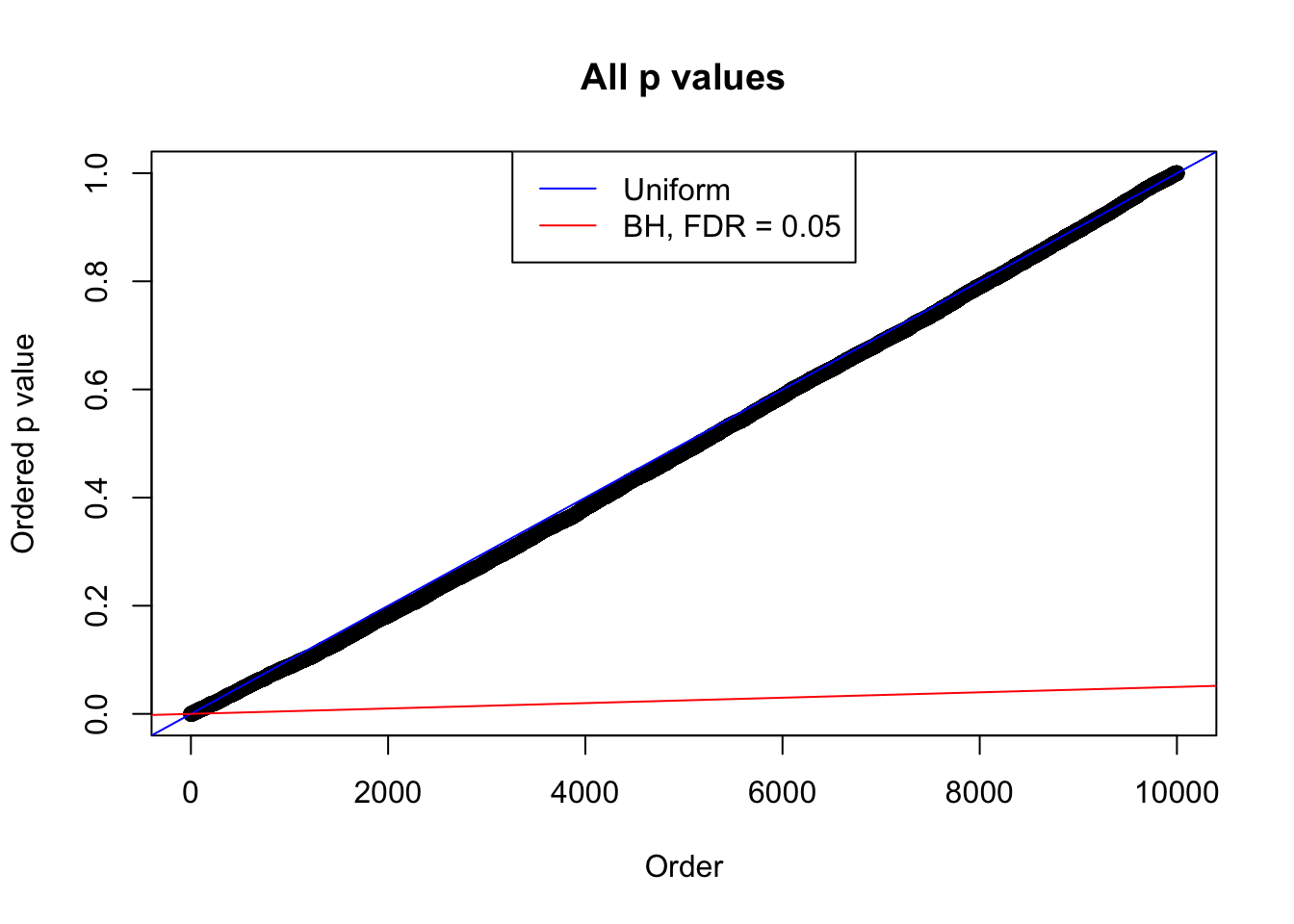
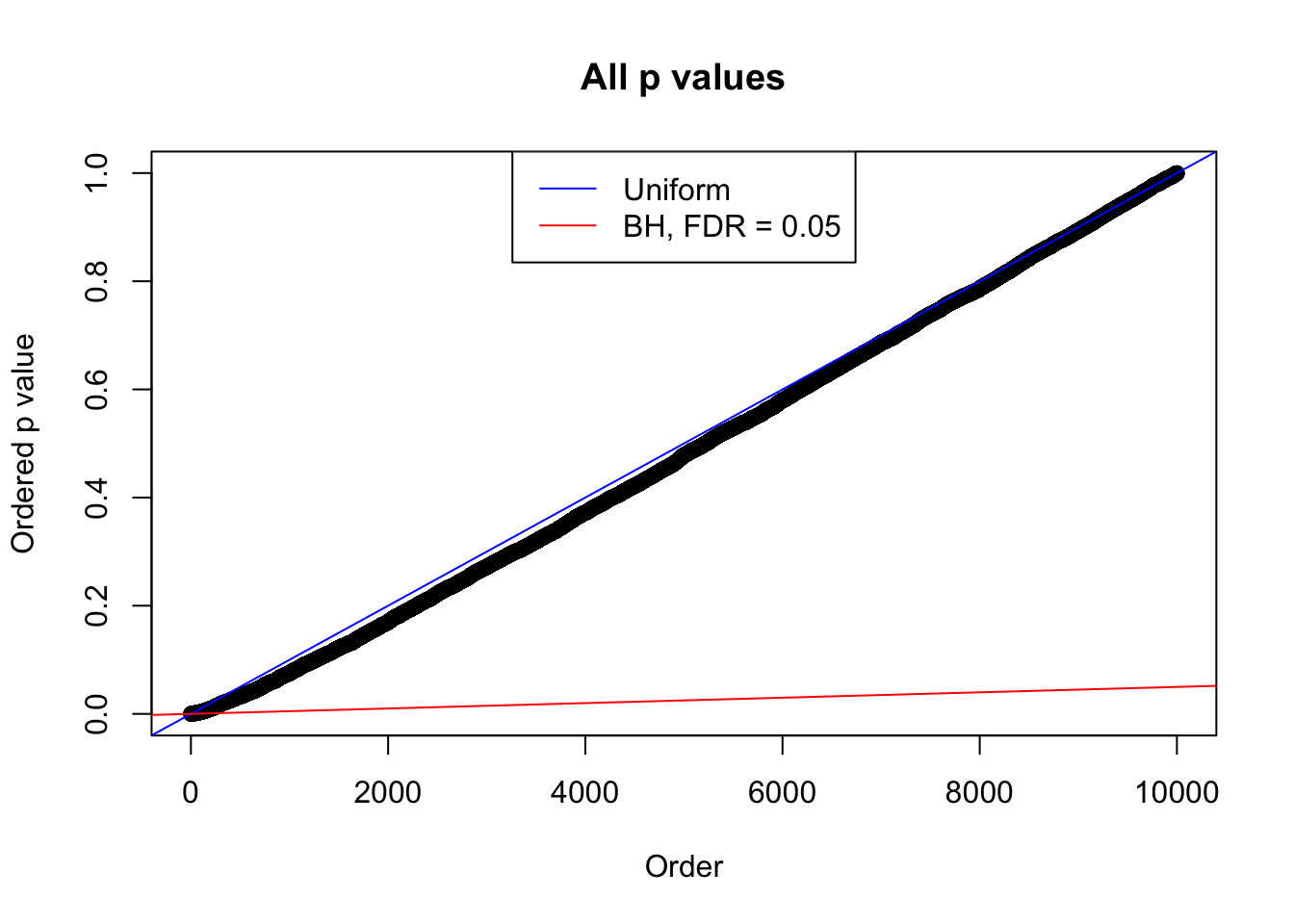
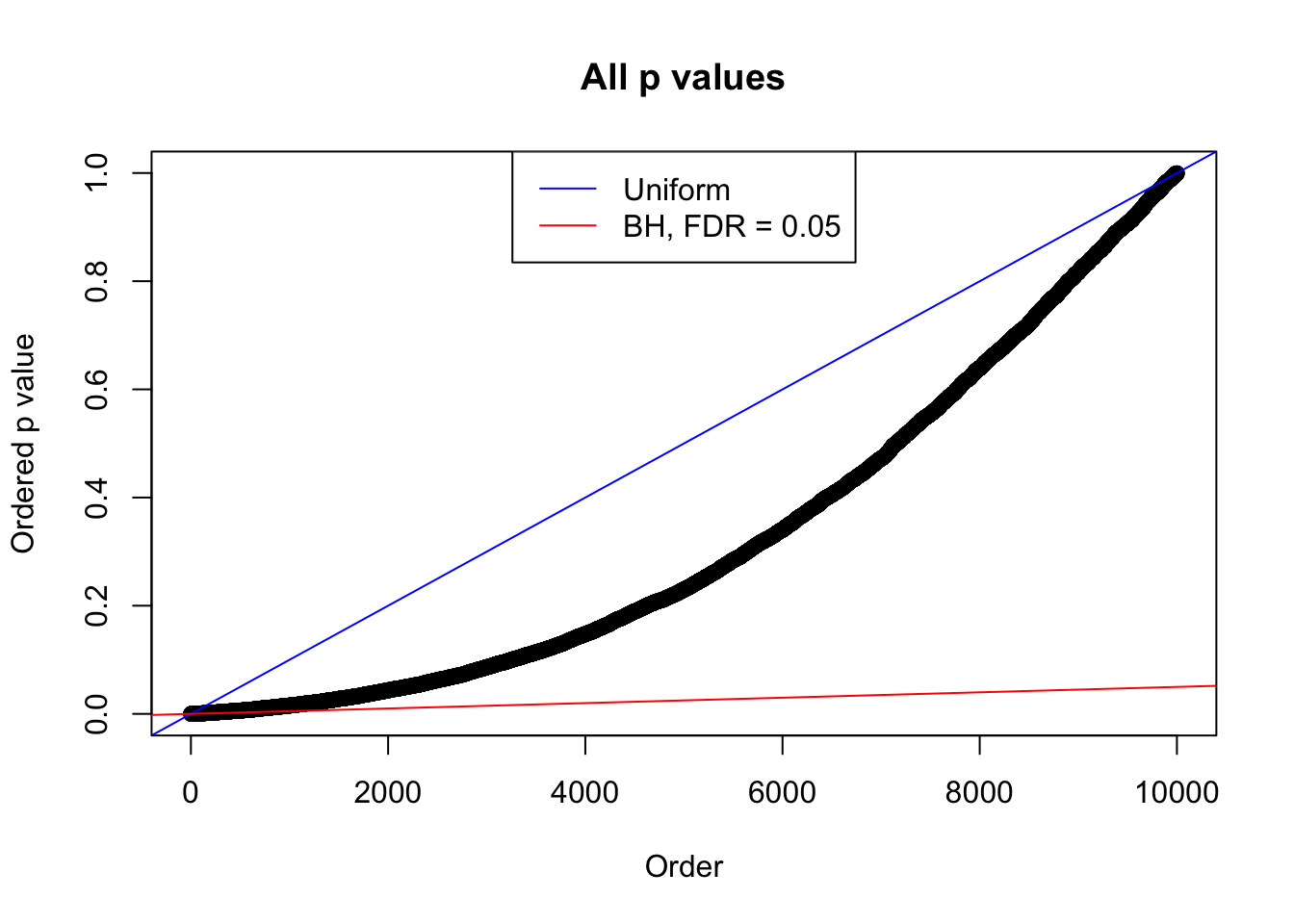
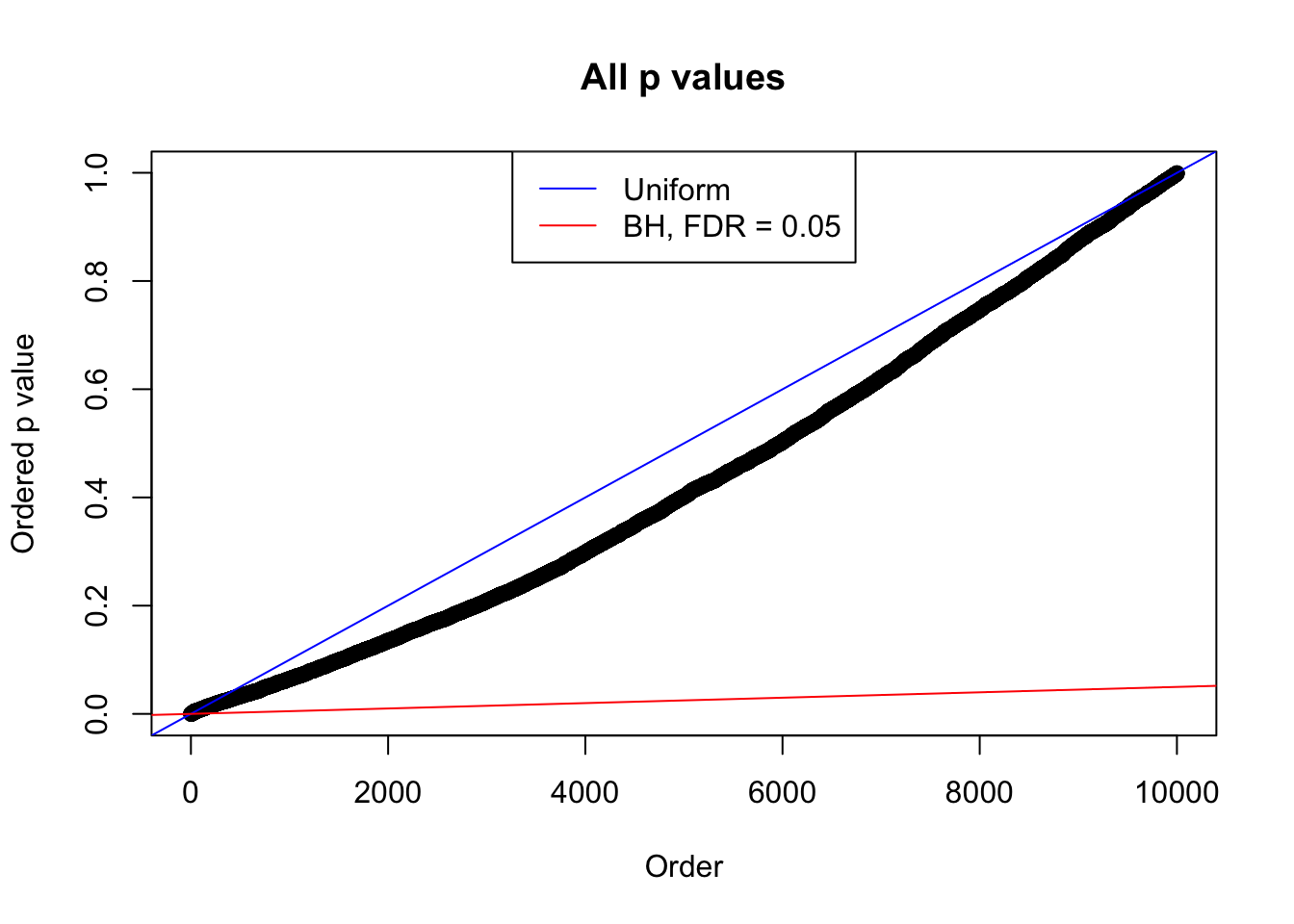
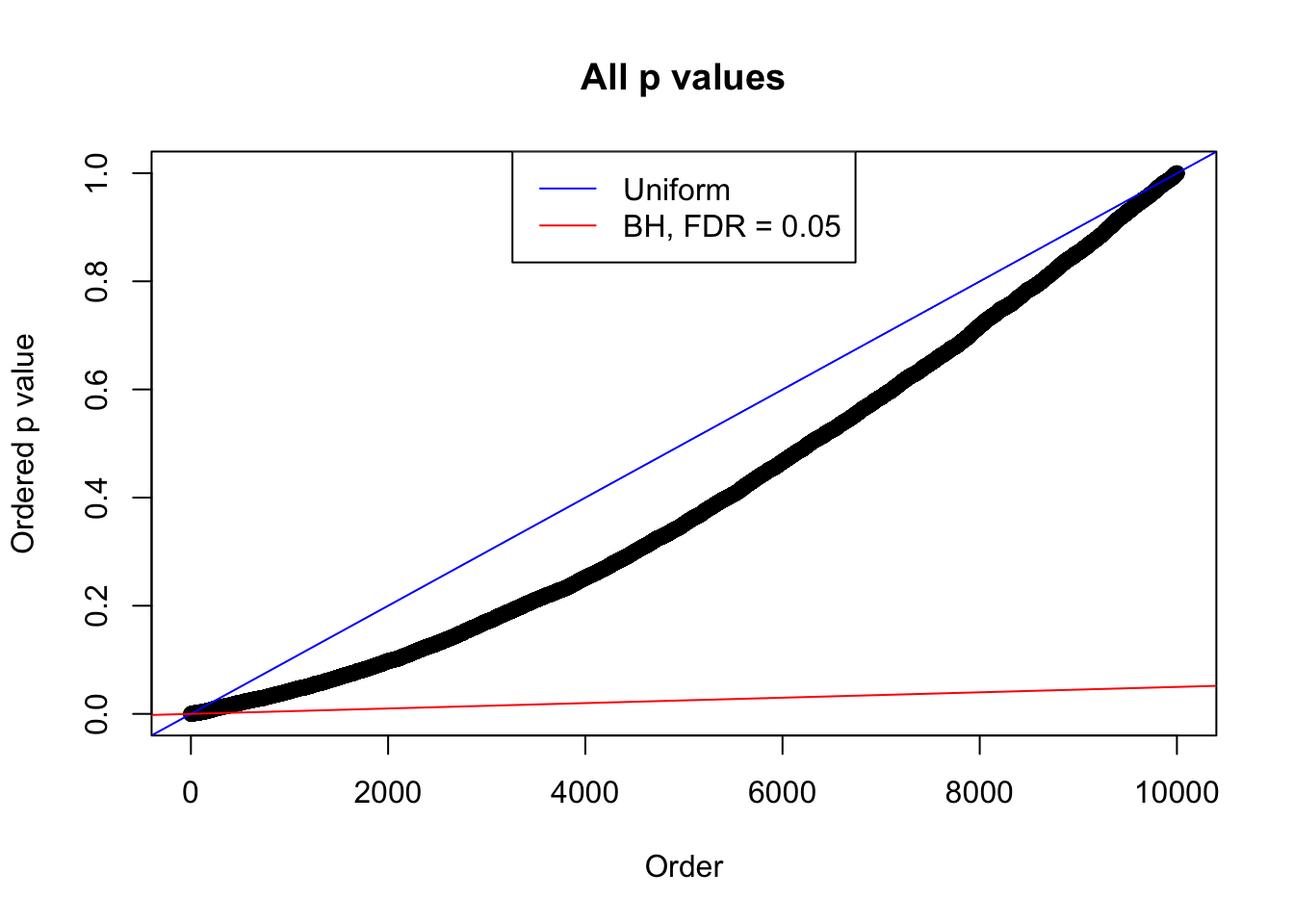
plot(sort(as.numeric(p[j, ])), xlab = "Order", ylab = "Ordered p value", main = "All p values")
abline(0, 1 / m, col = "blue")
abline(0, 0.05 / m, col = "red")
legend("top", lty = 1, col = c("blue", "red"), c("Uniform", "BH, FDR = 0.05"))
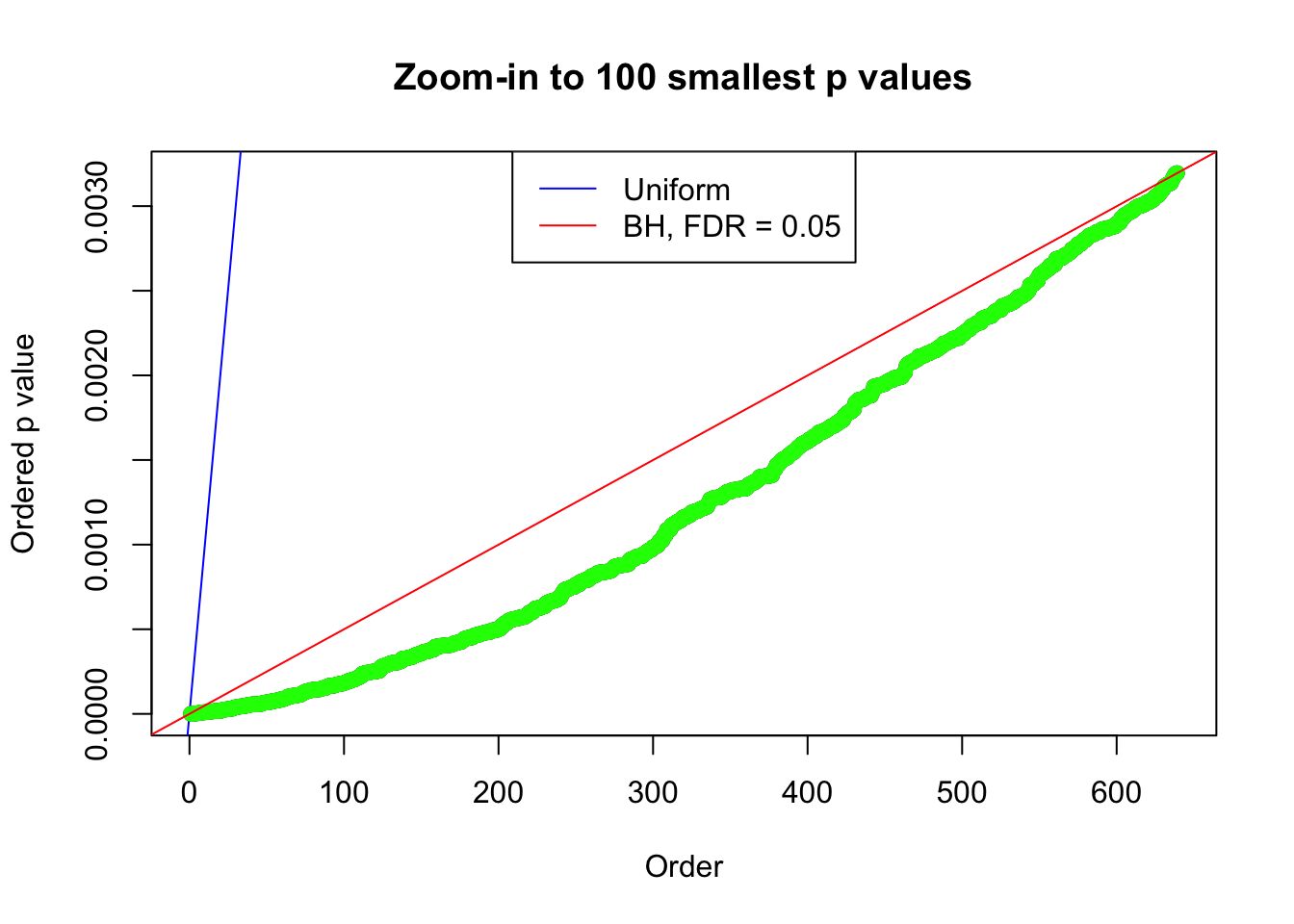
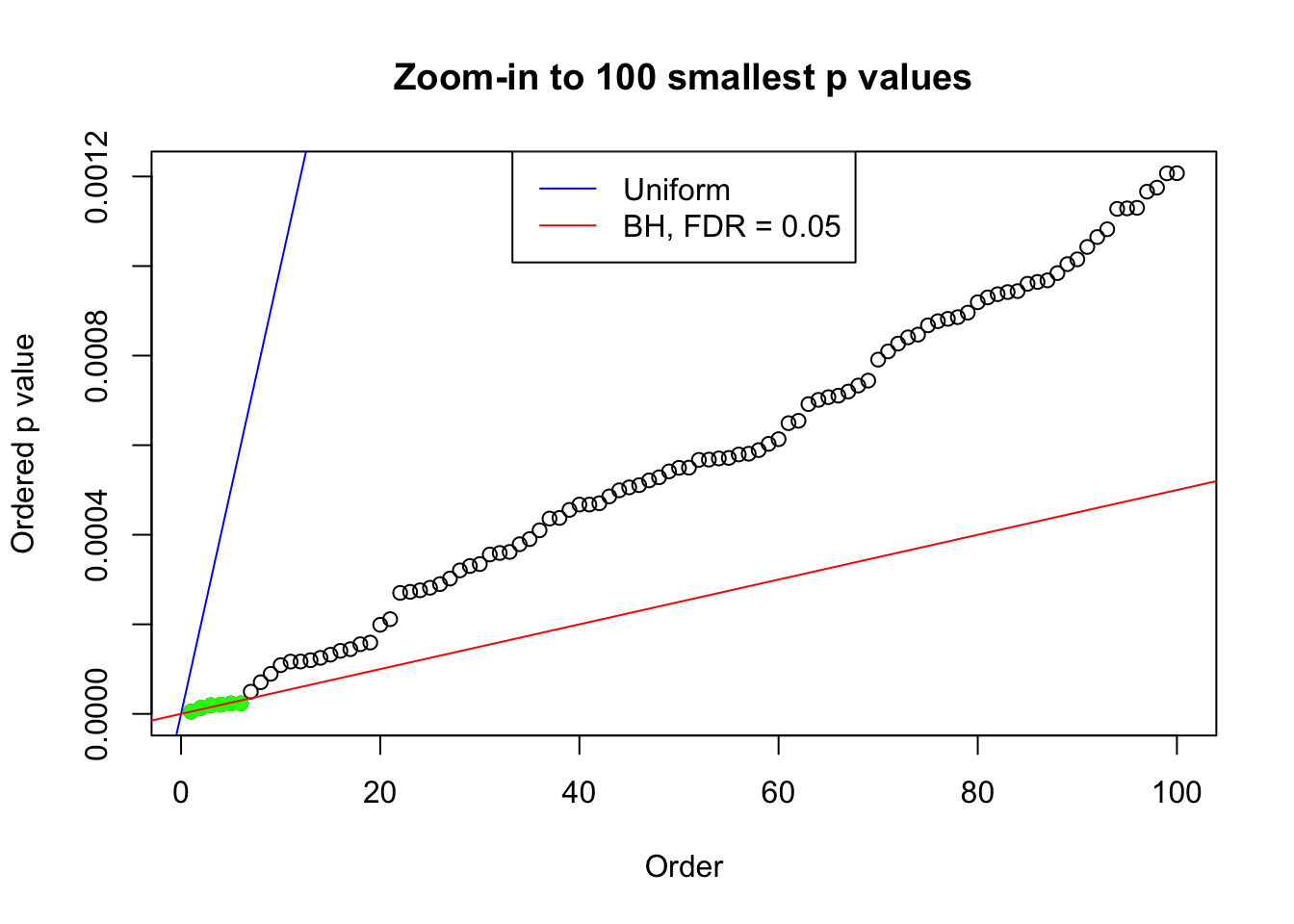
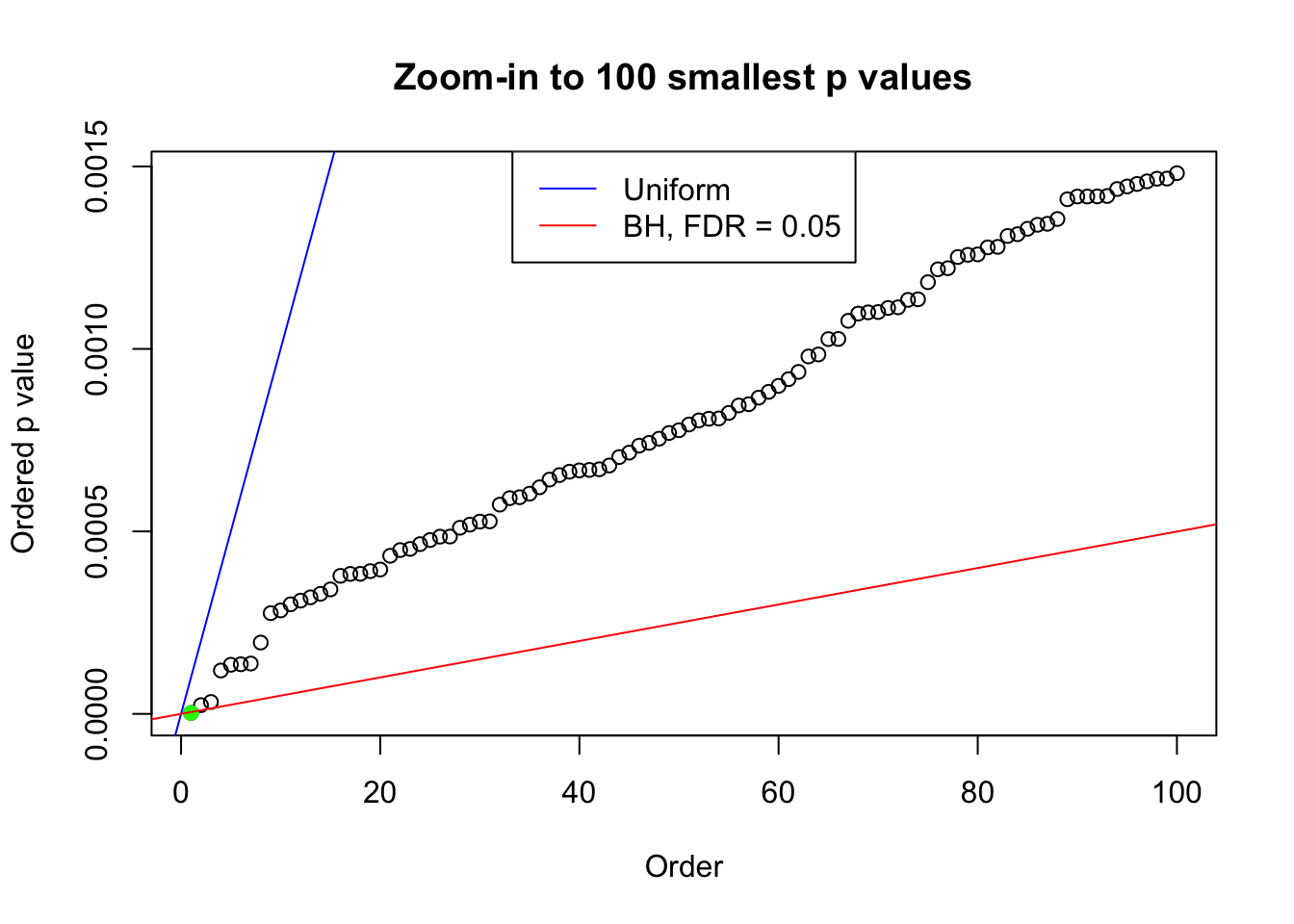
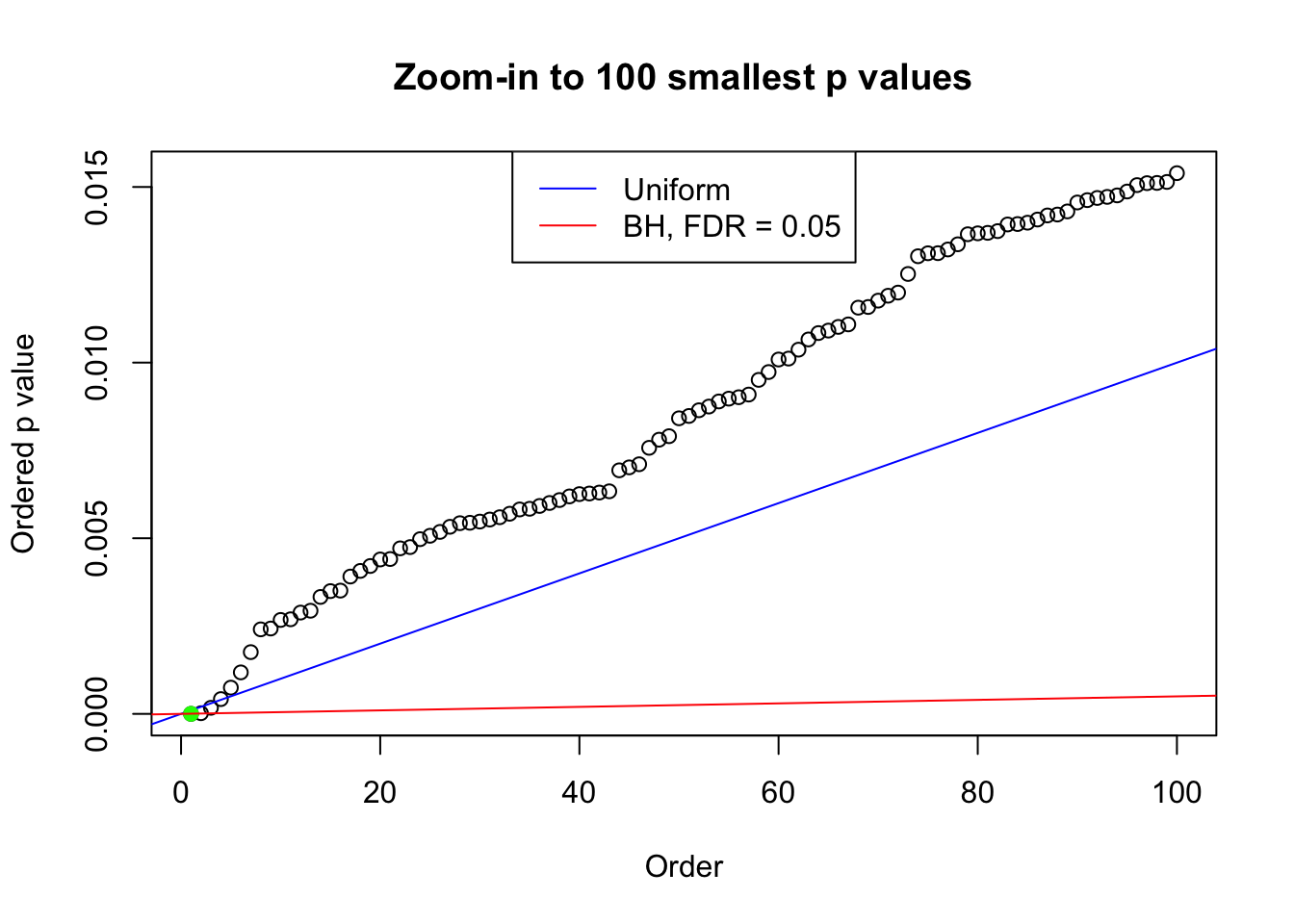
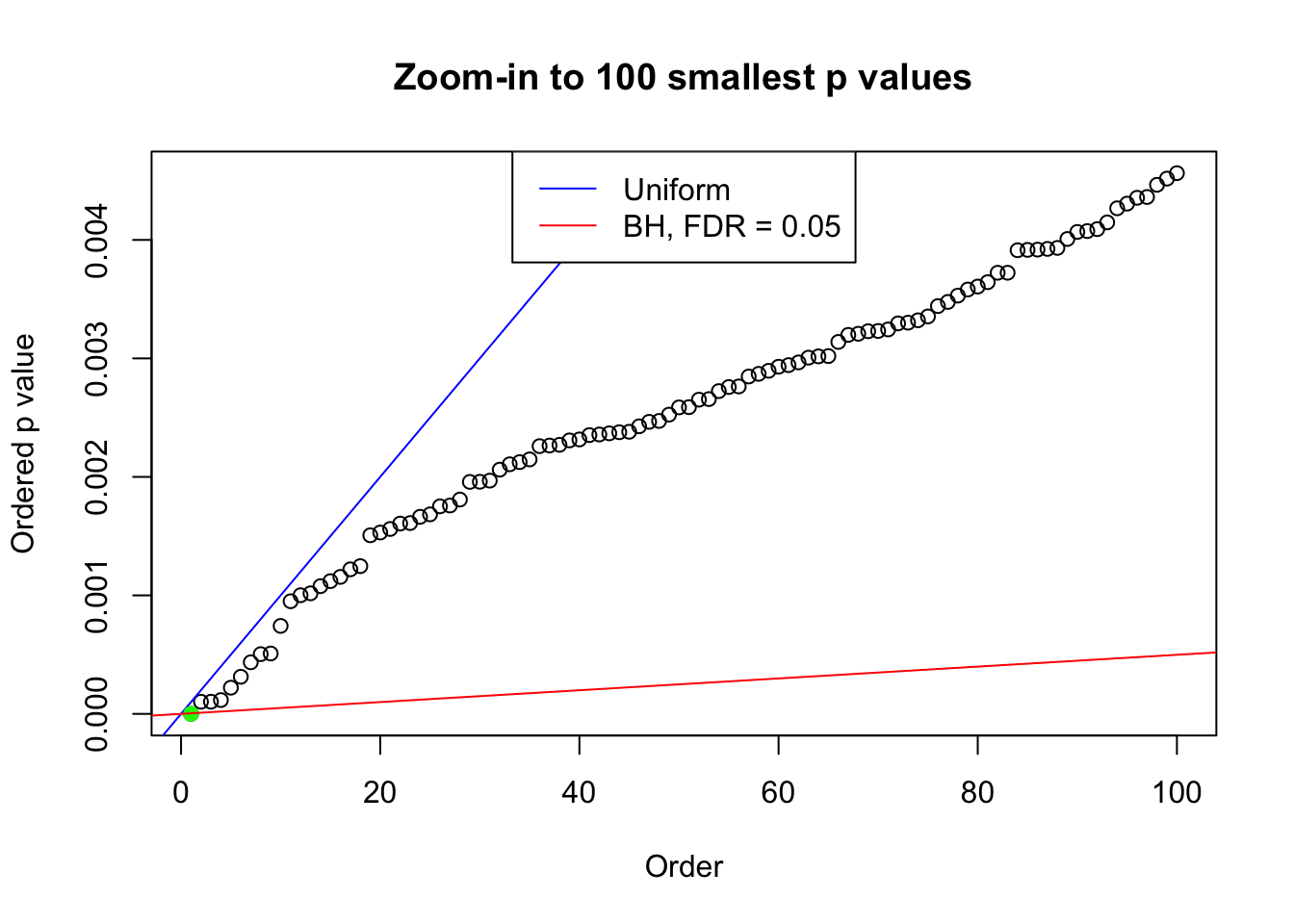
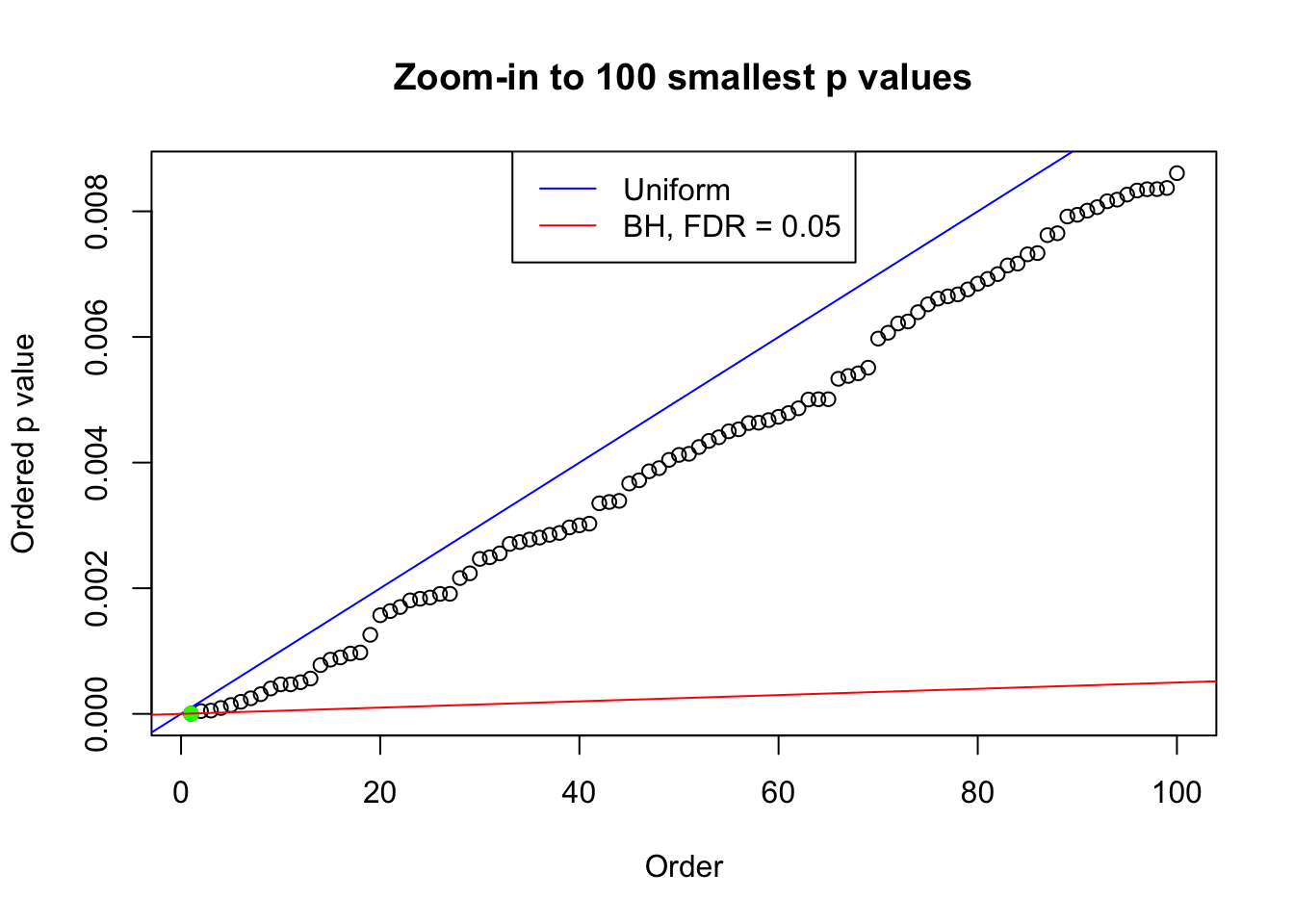
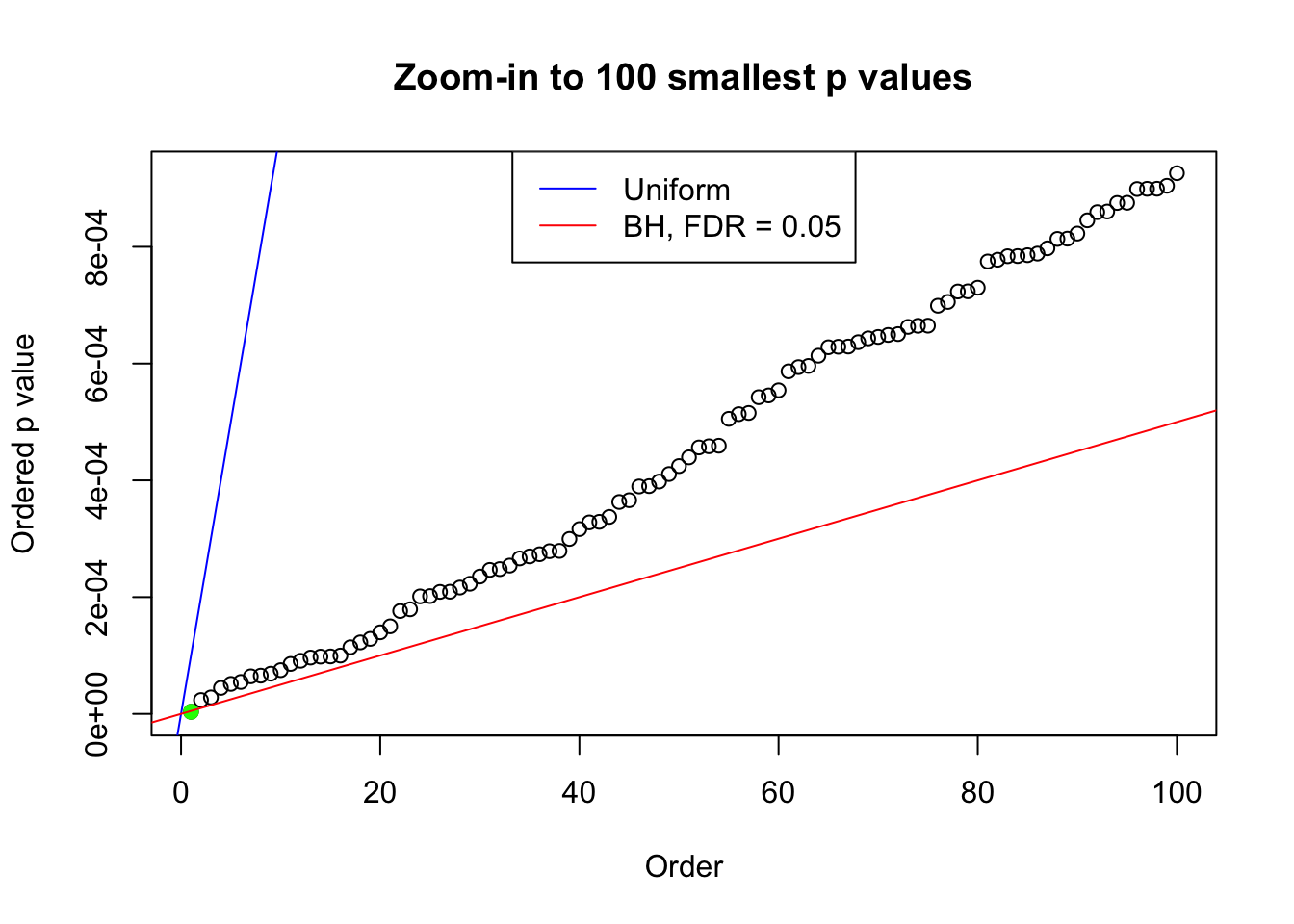
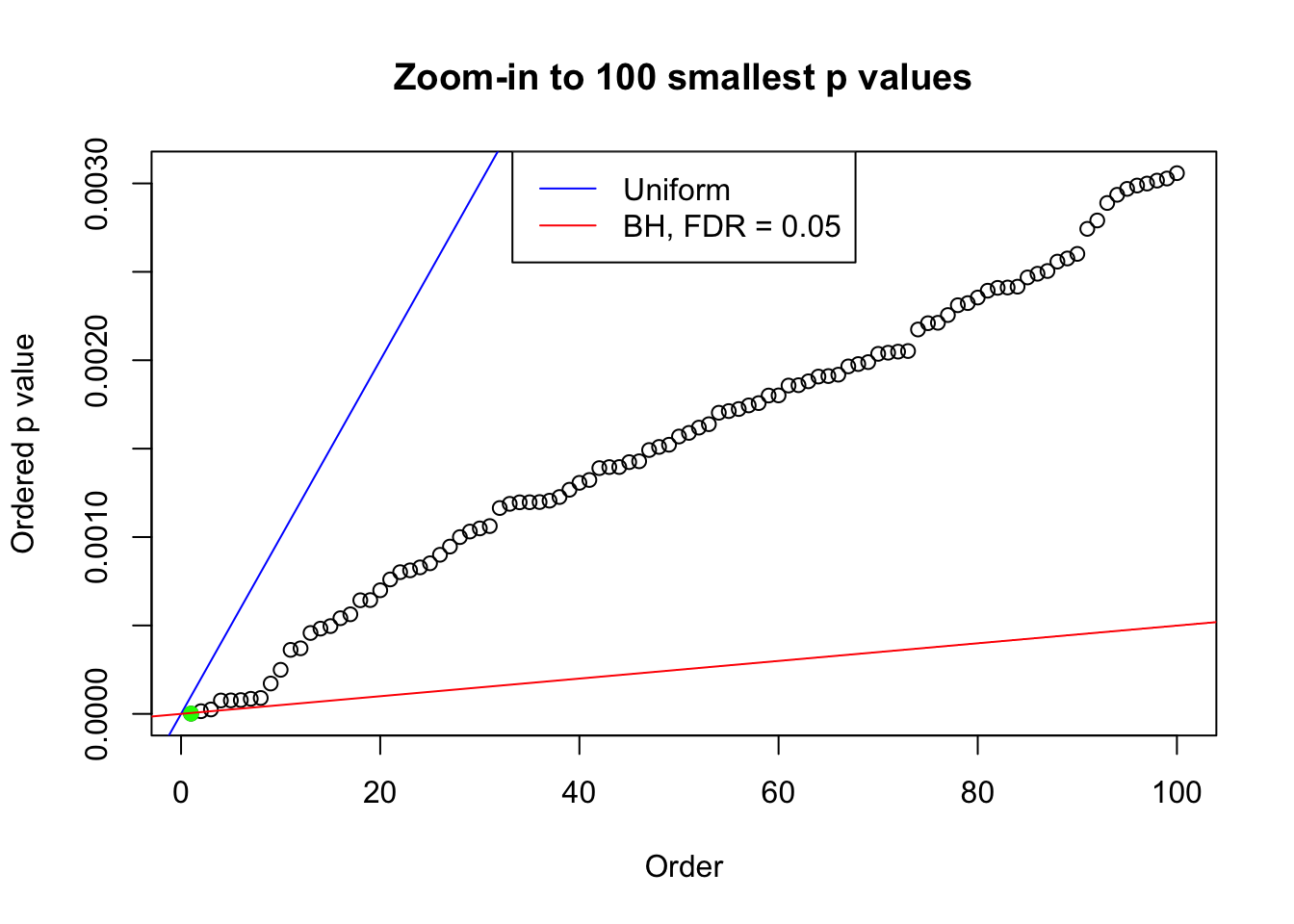
pj = sort(as.numeric(p[j, ]))
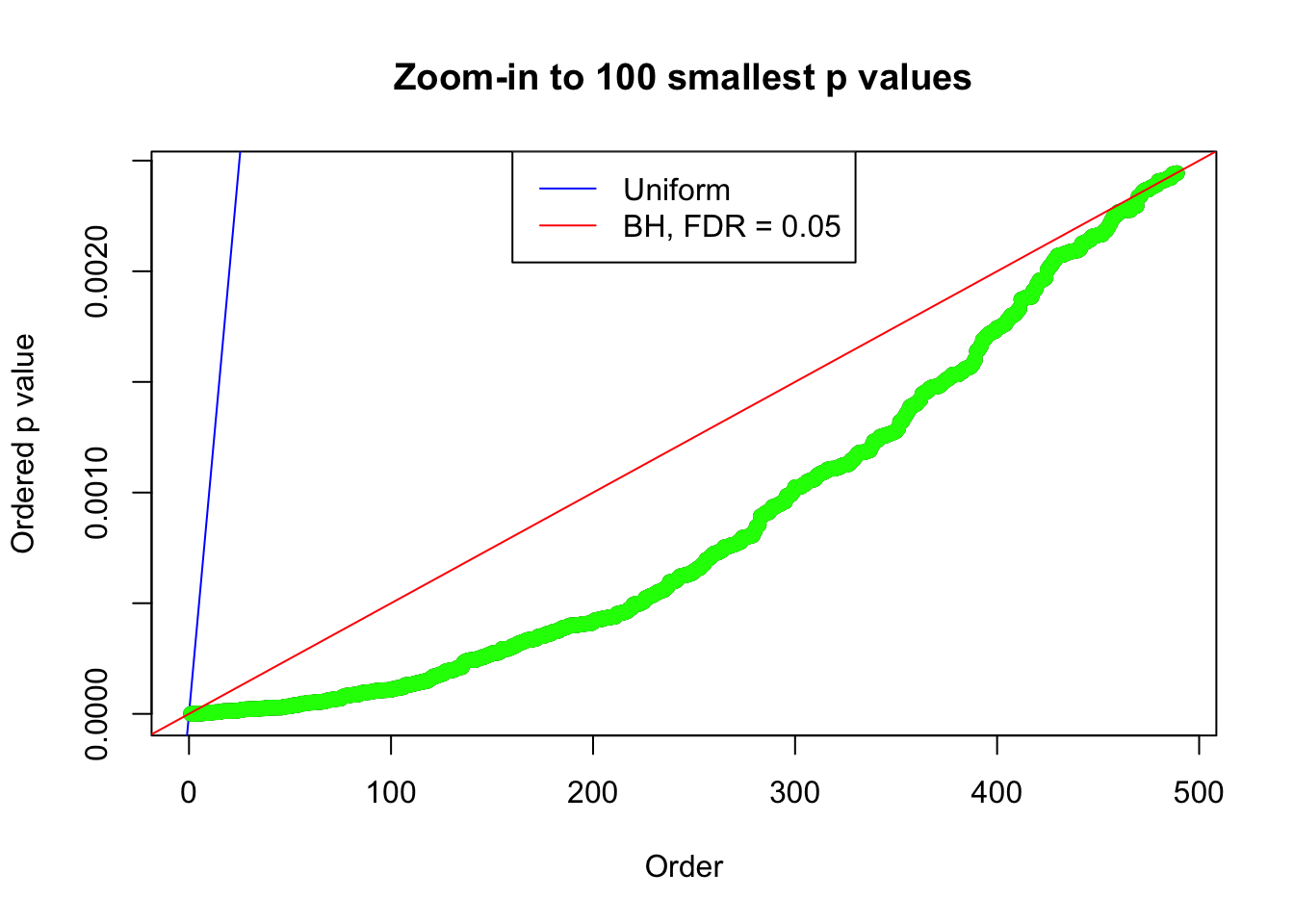
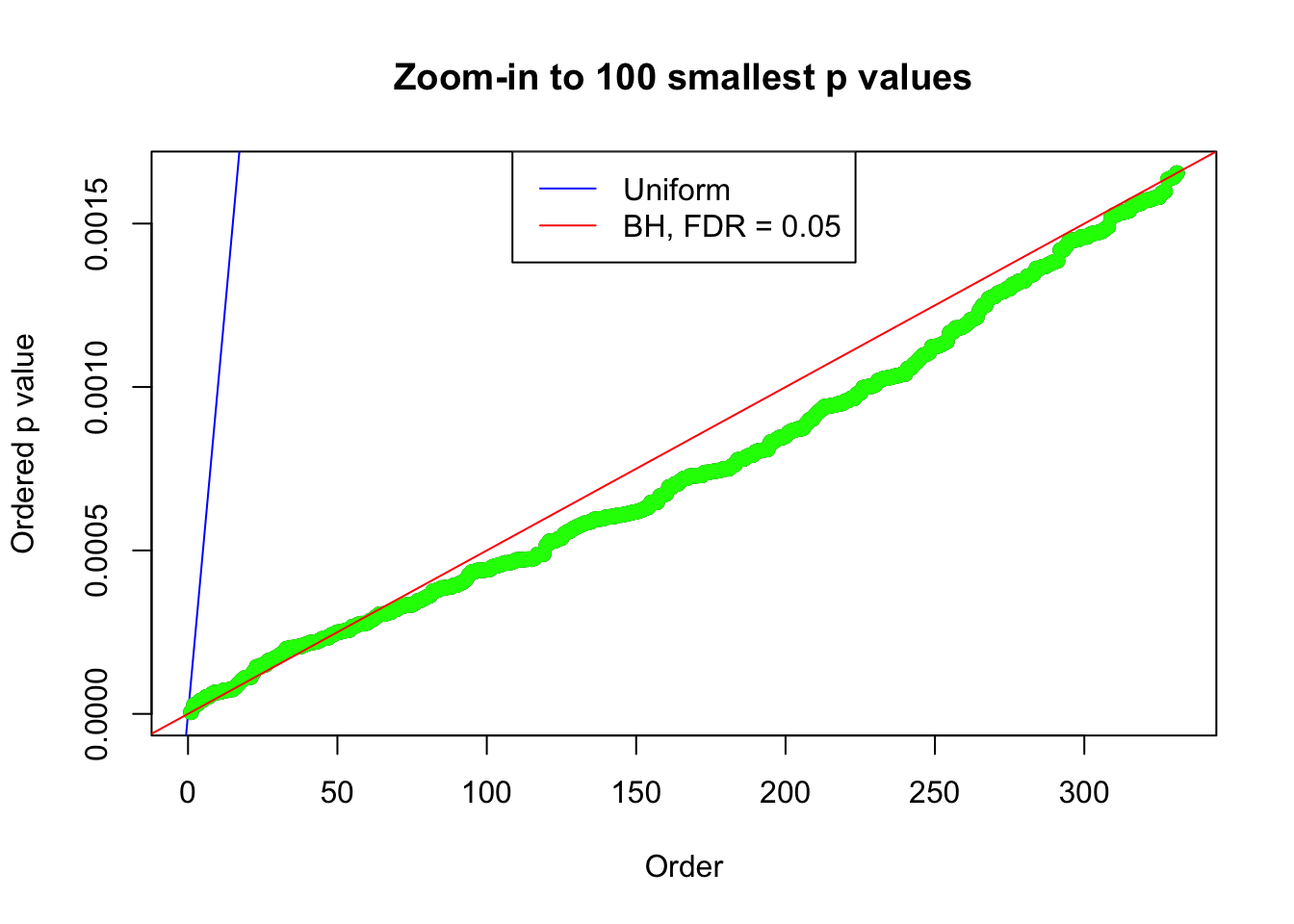
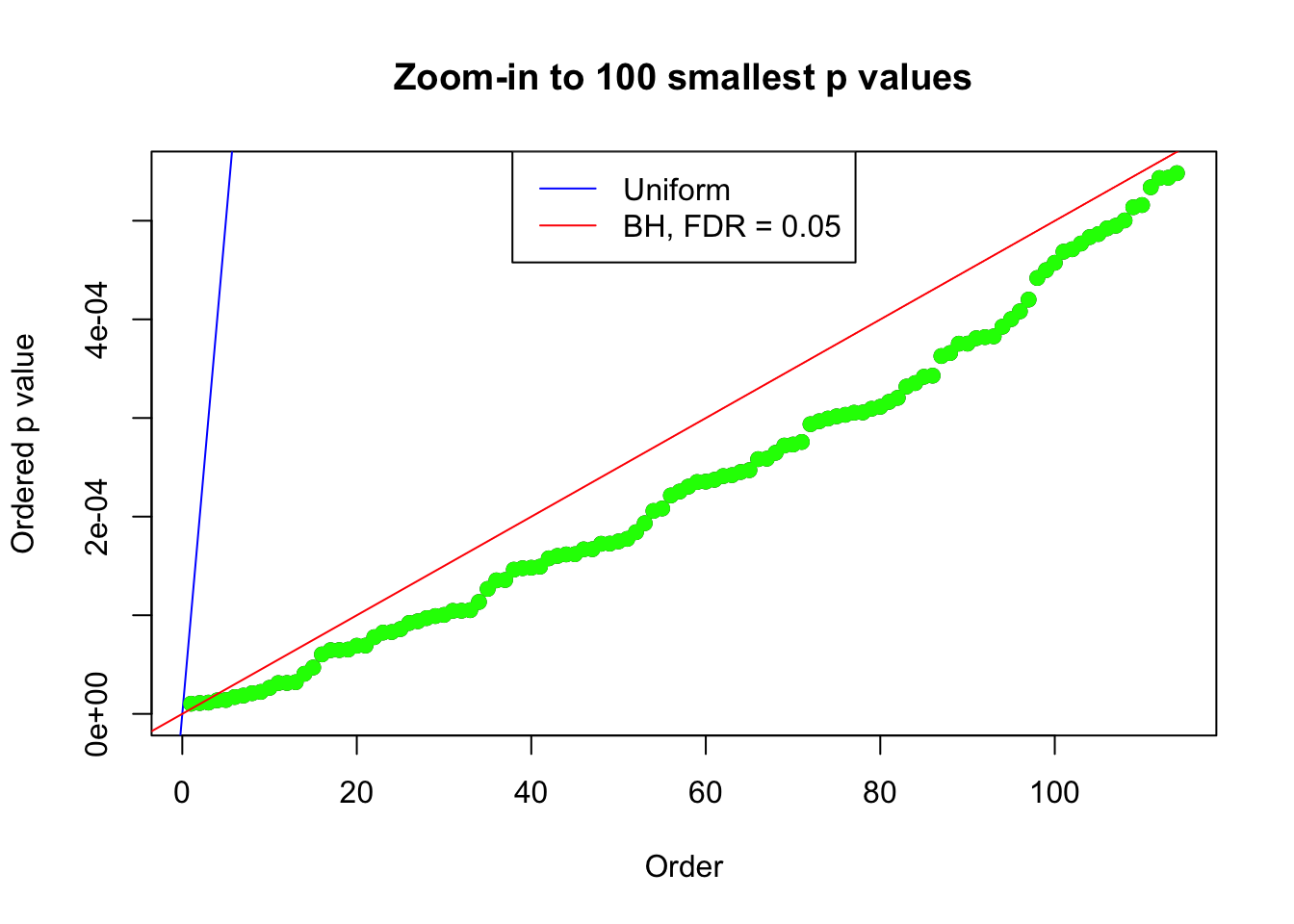
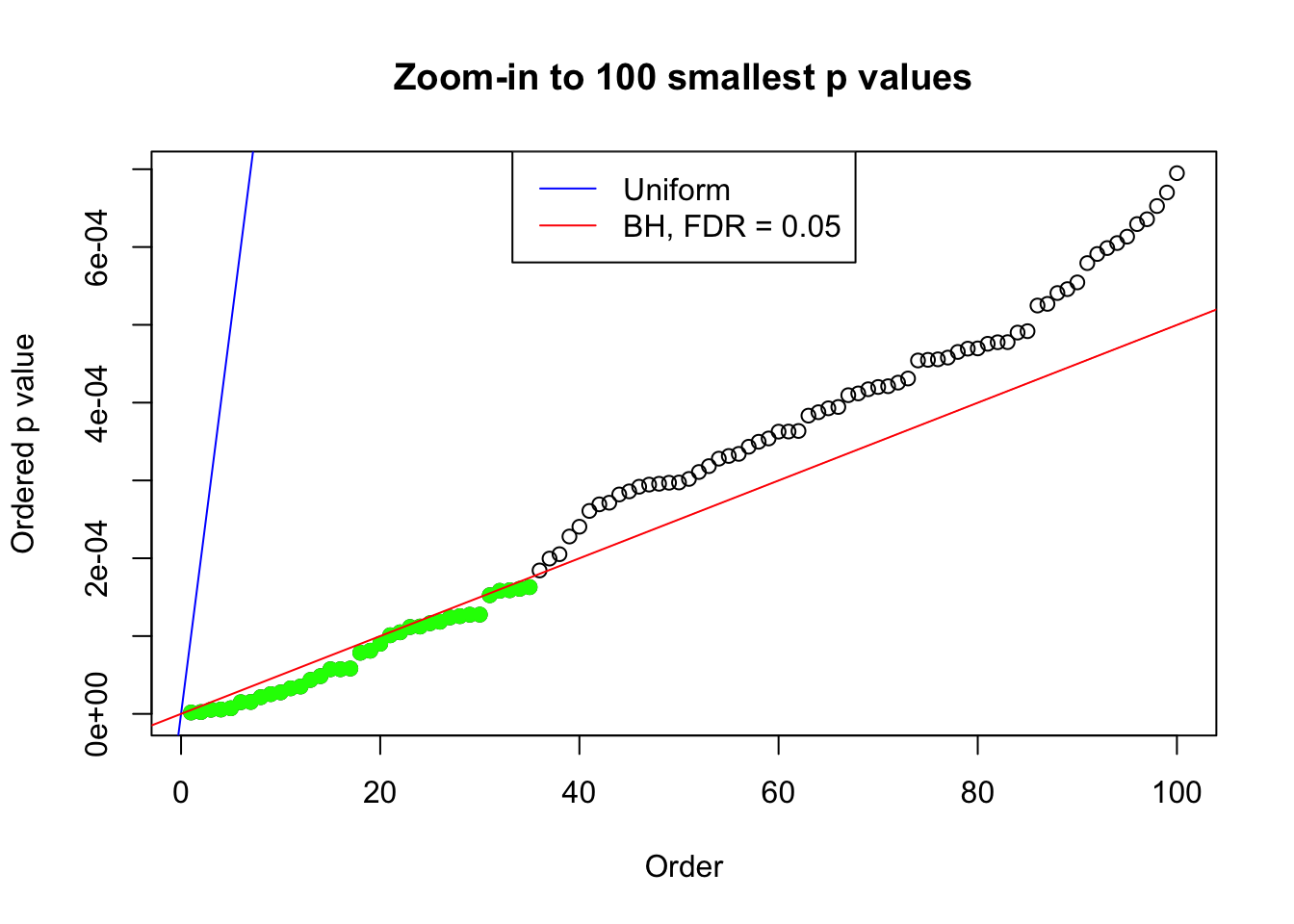
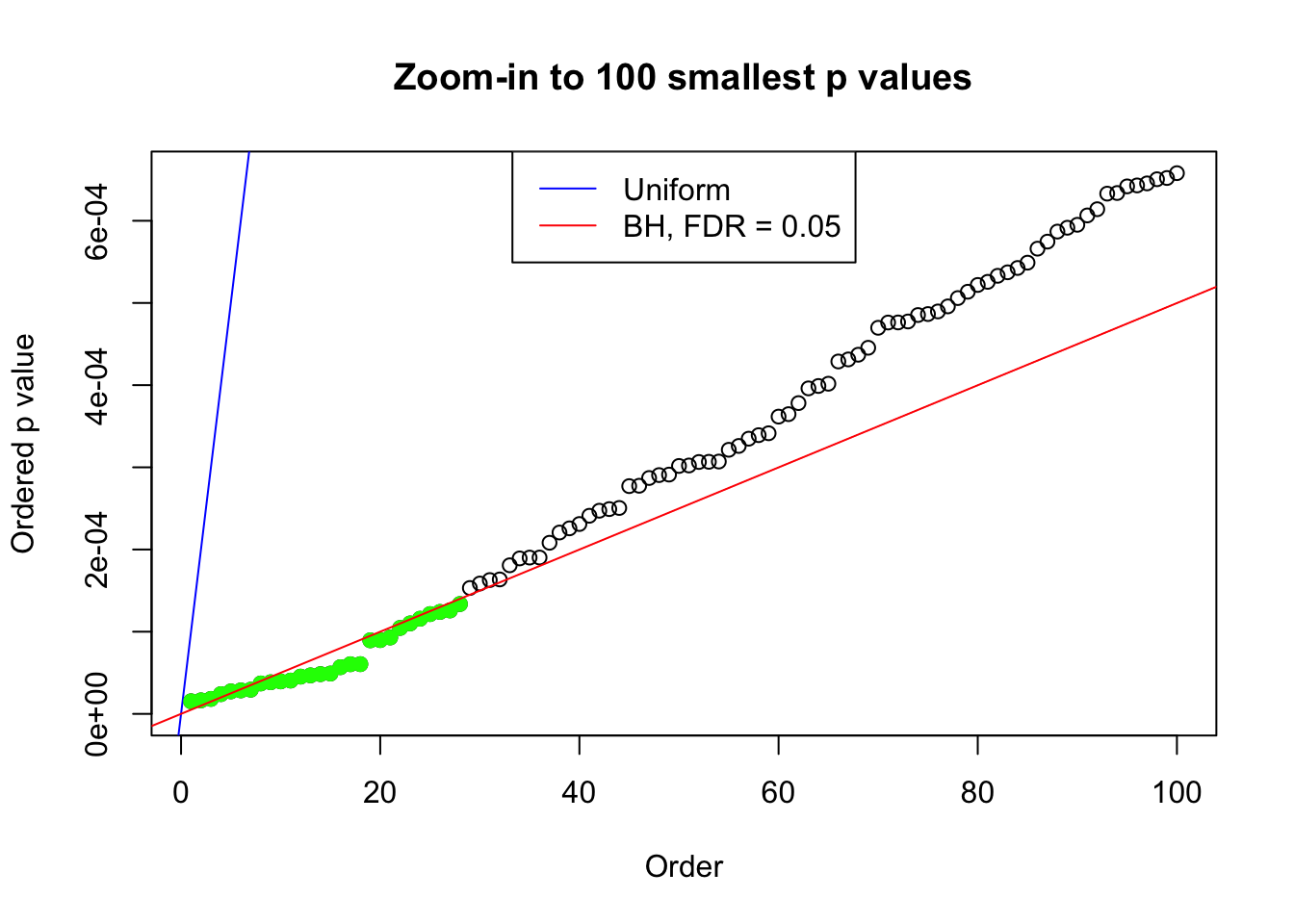
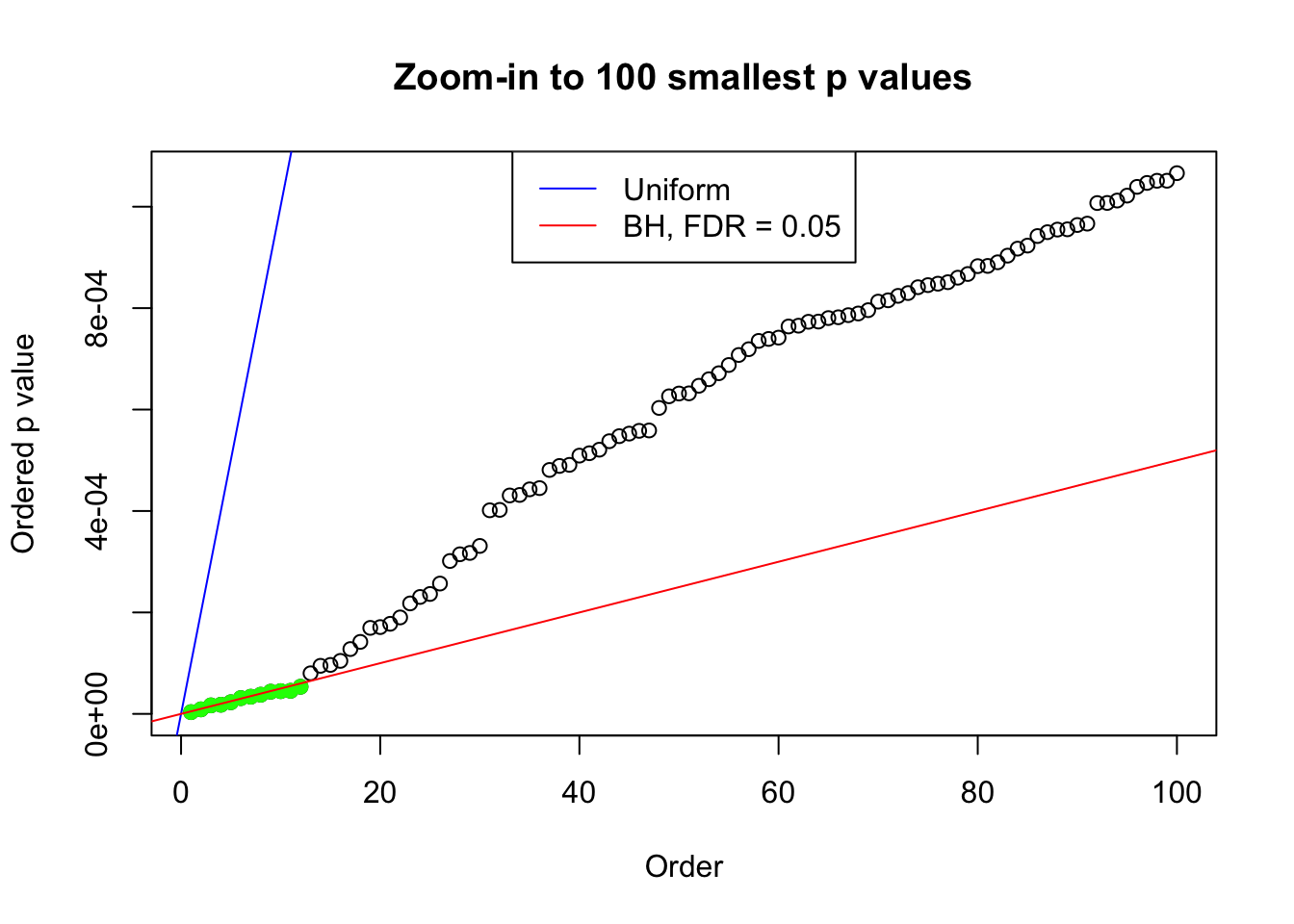
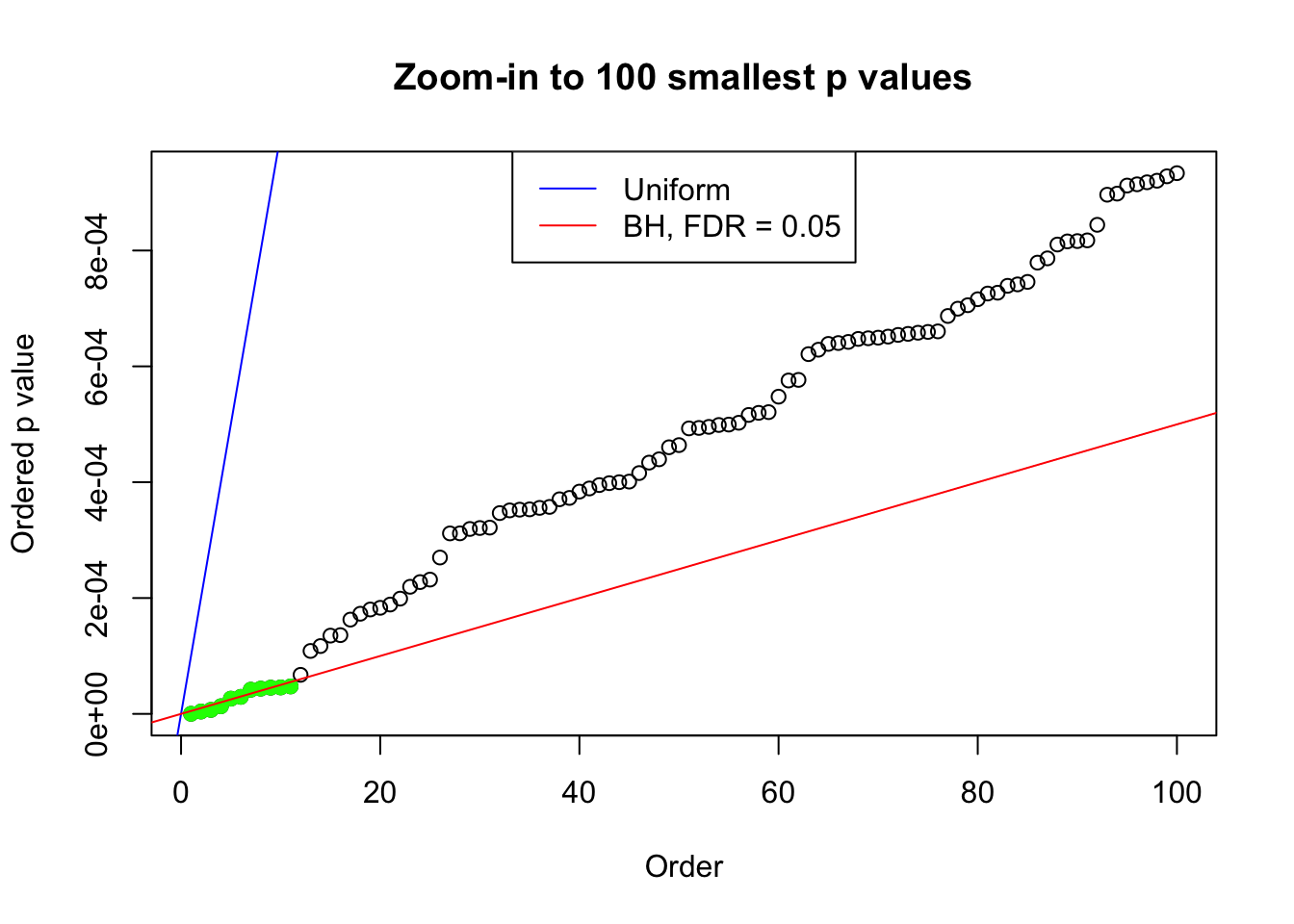
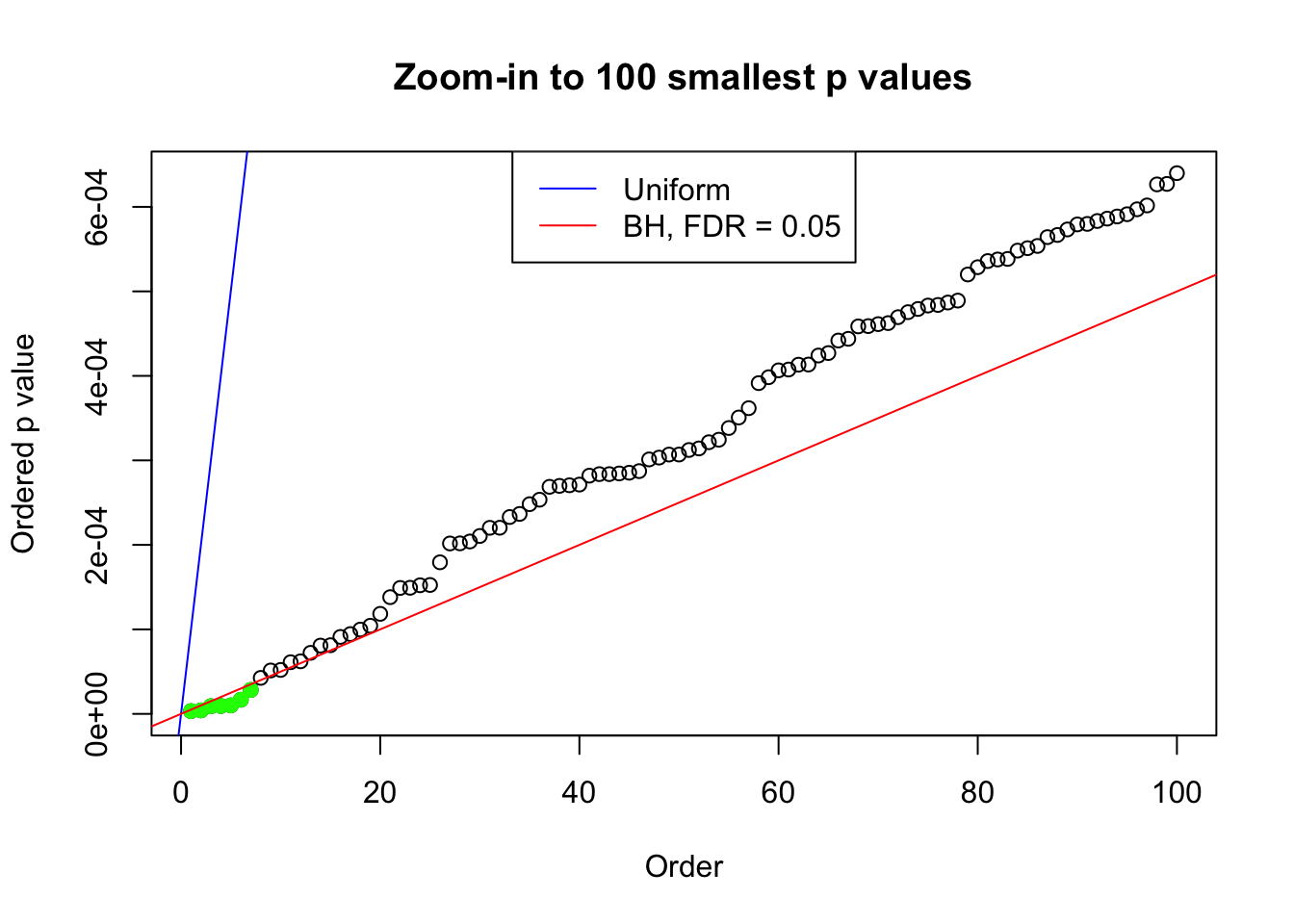
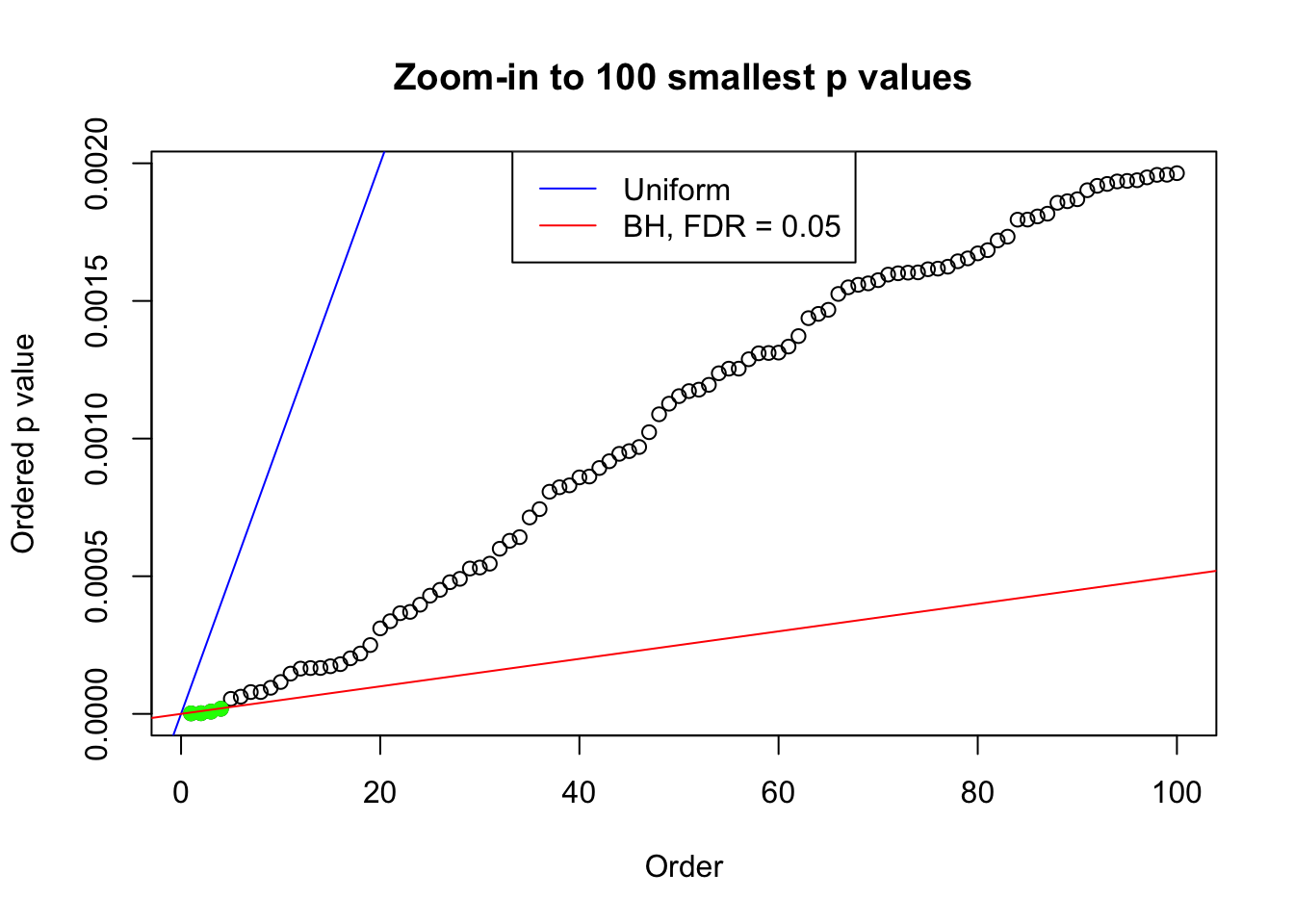
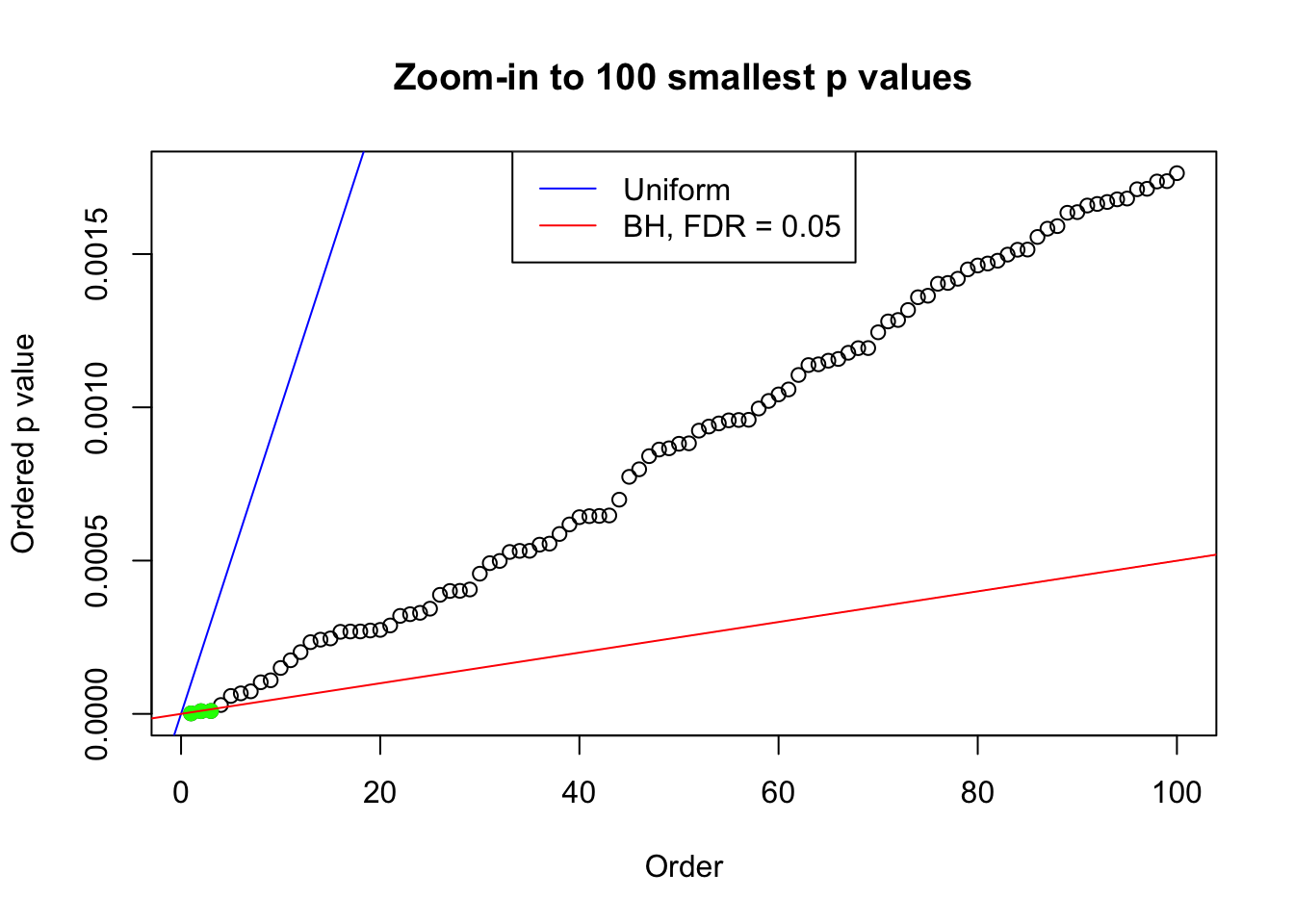
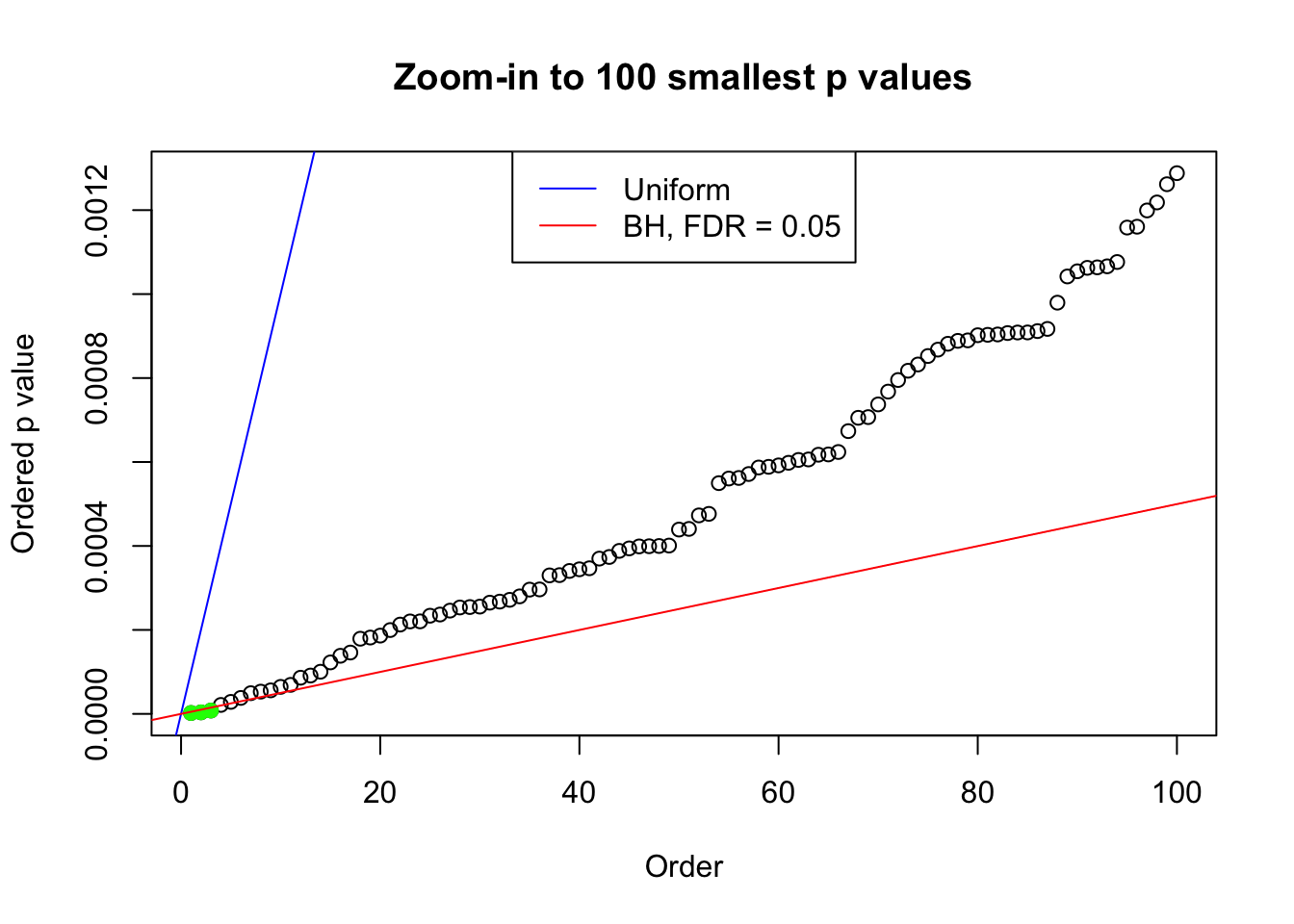
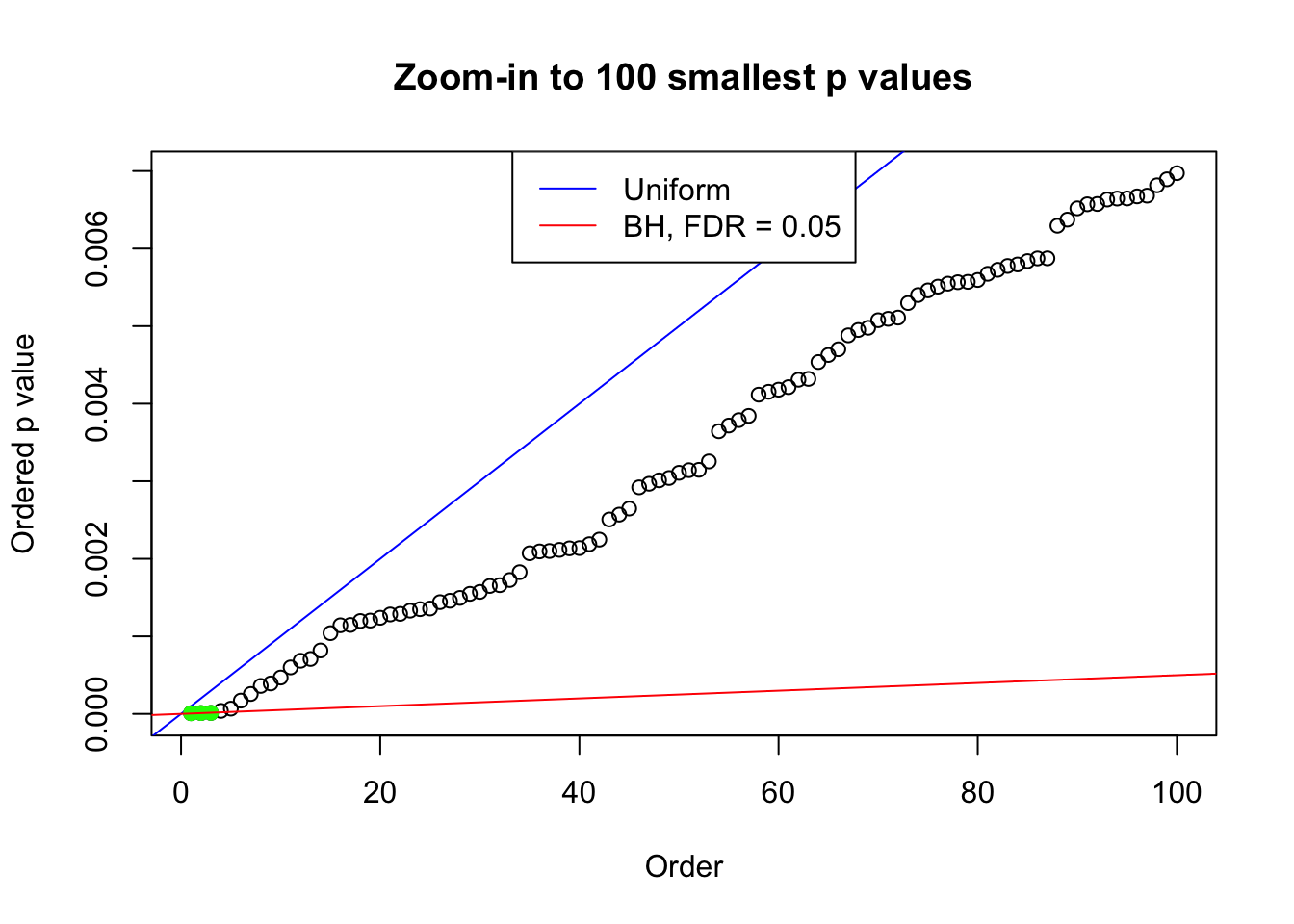
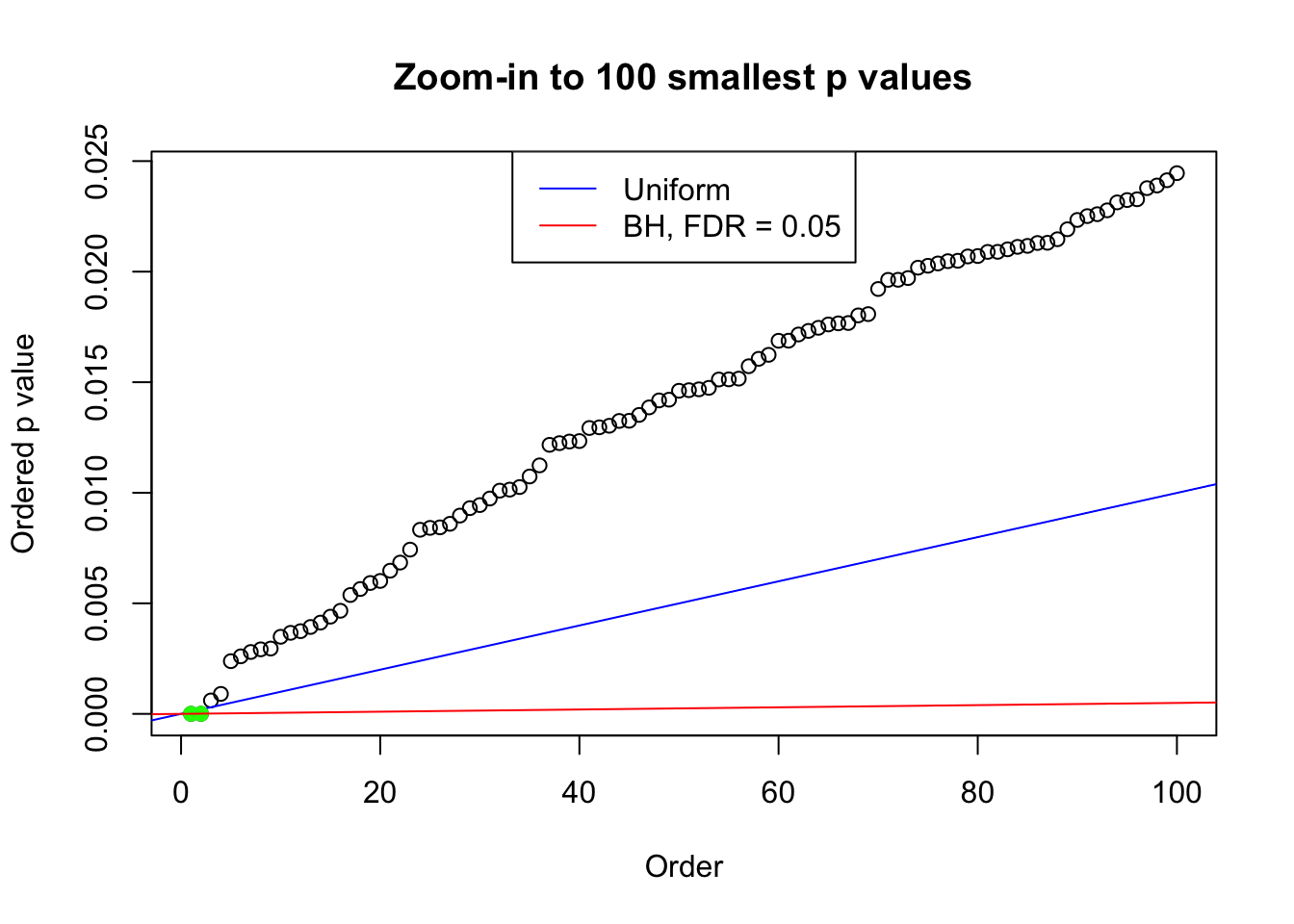
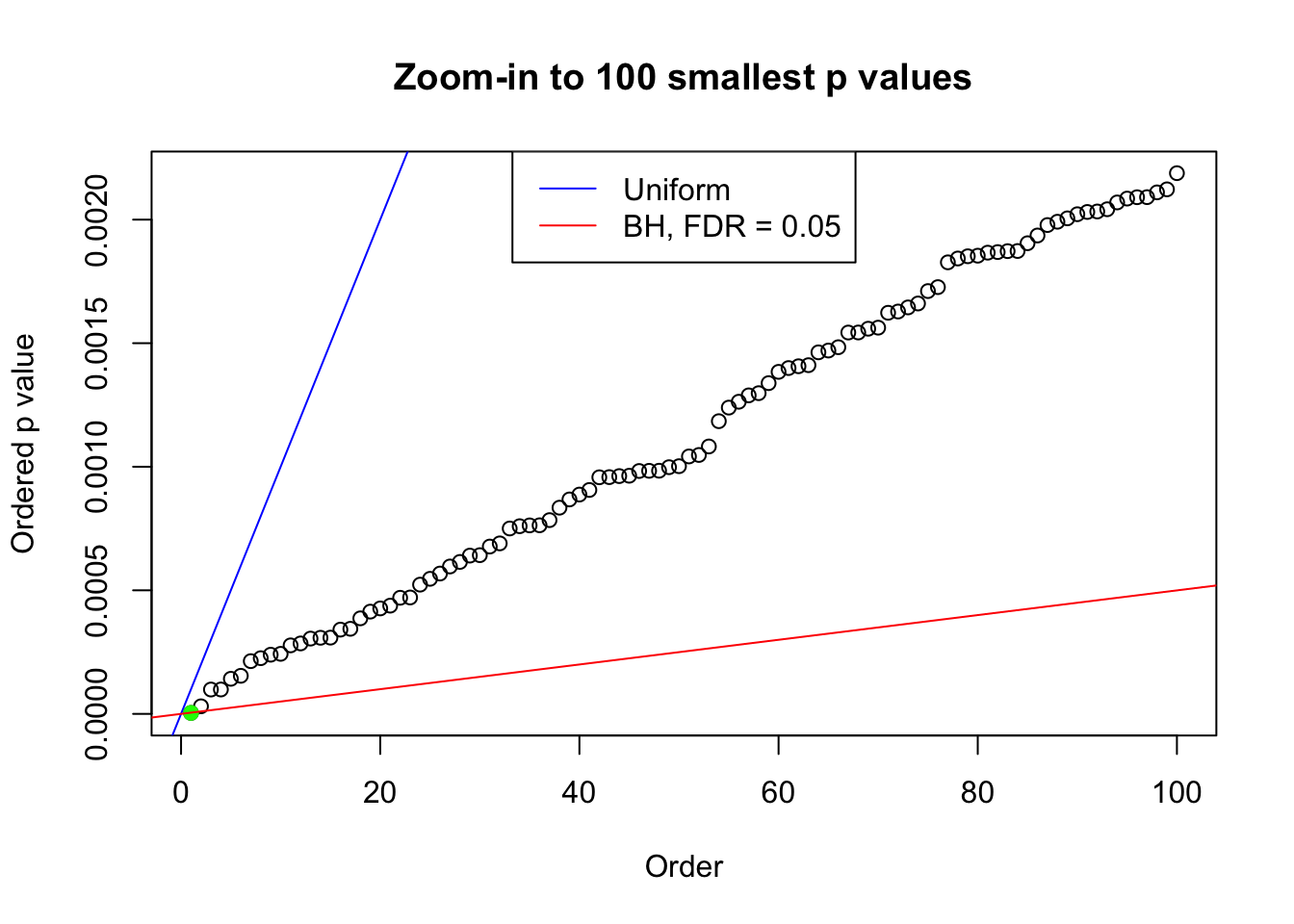
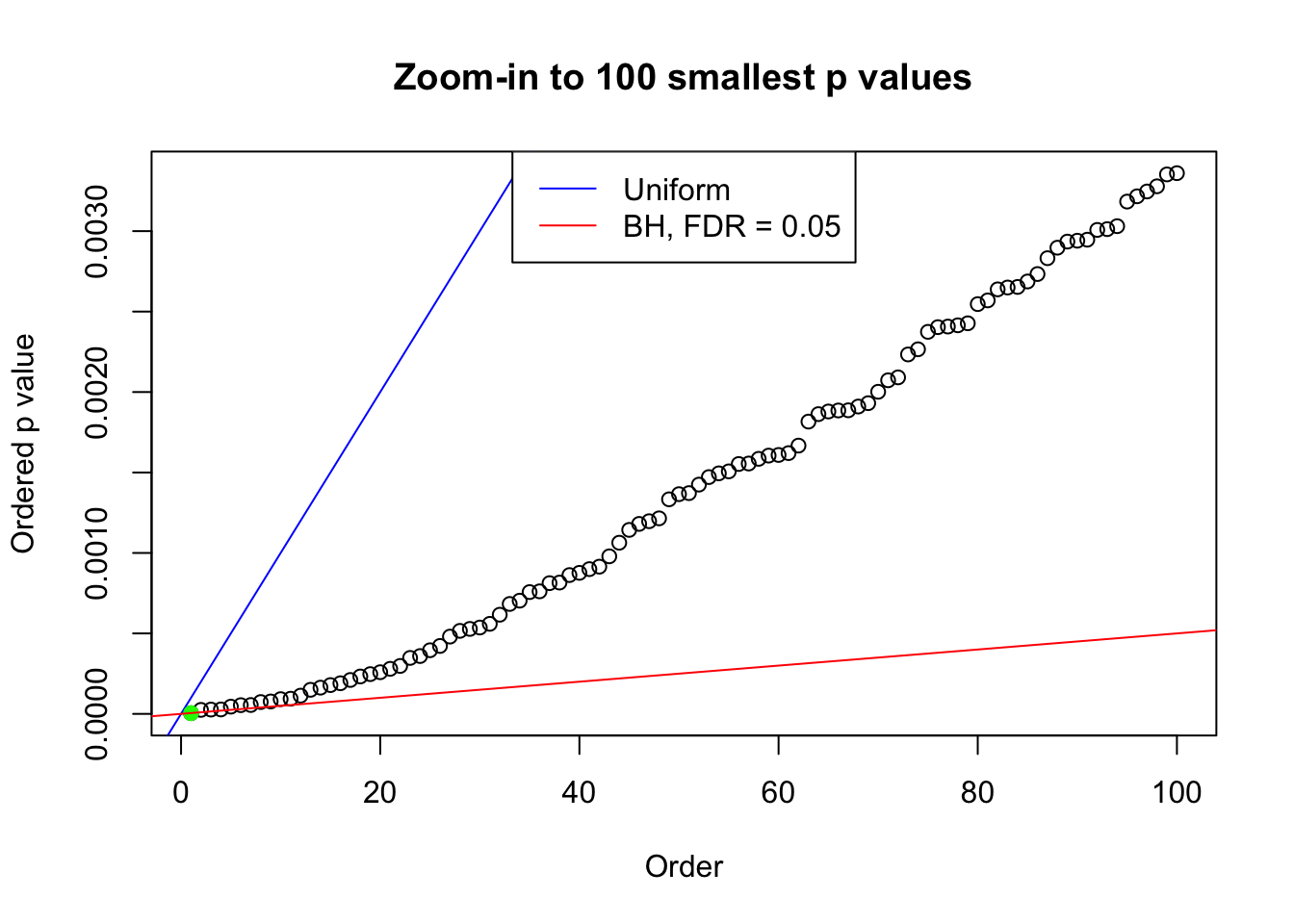
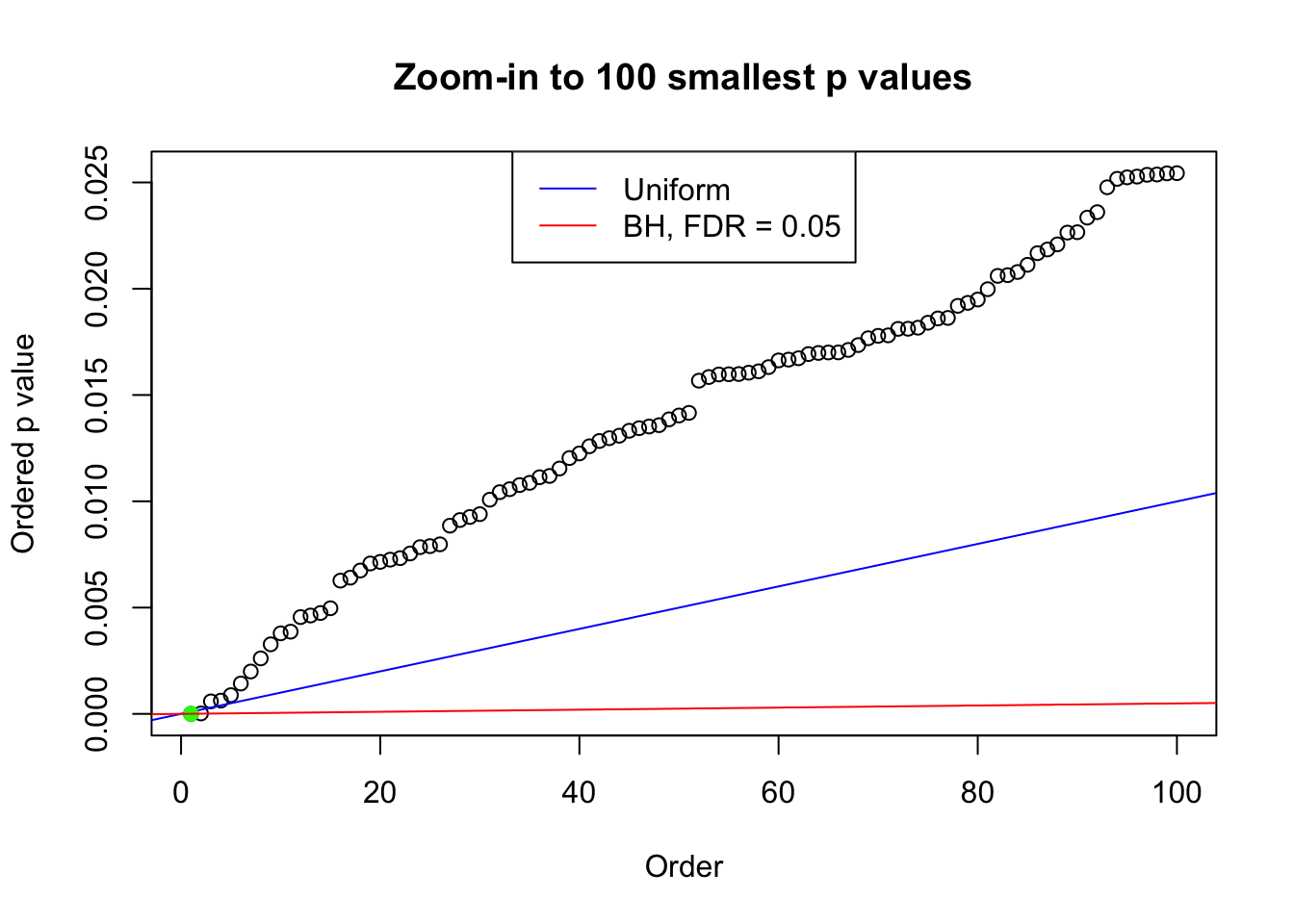
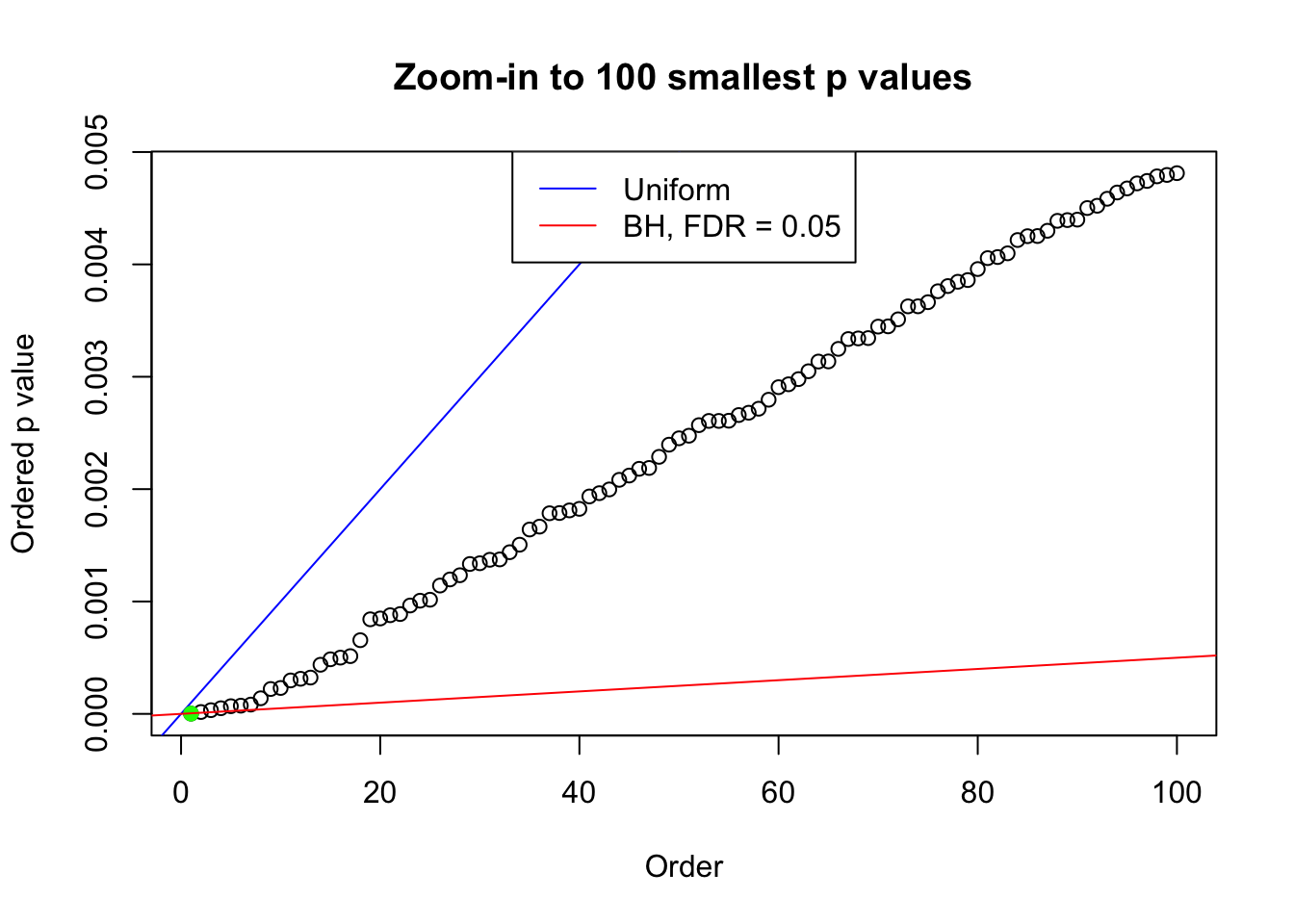
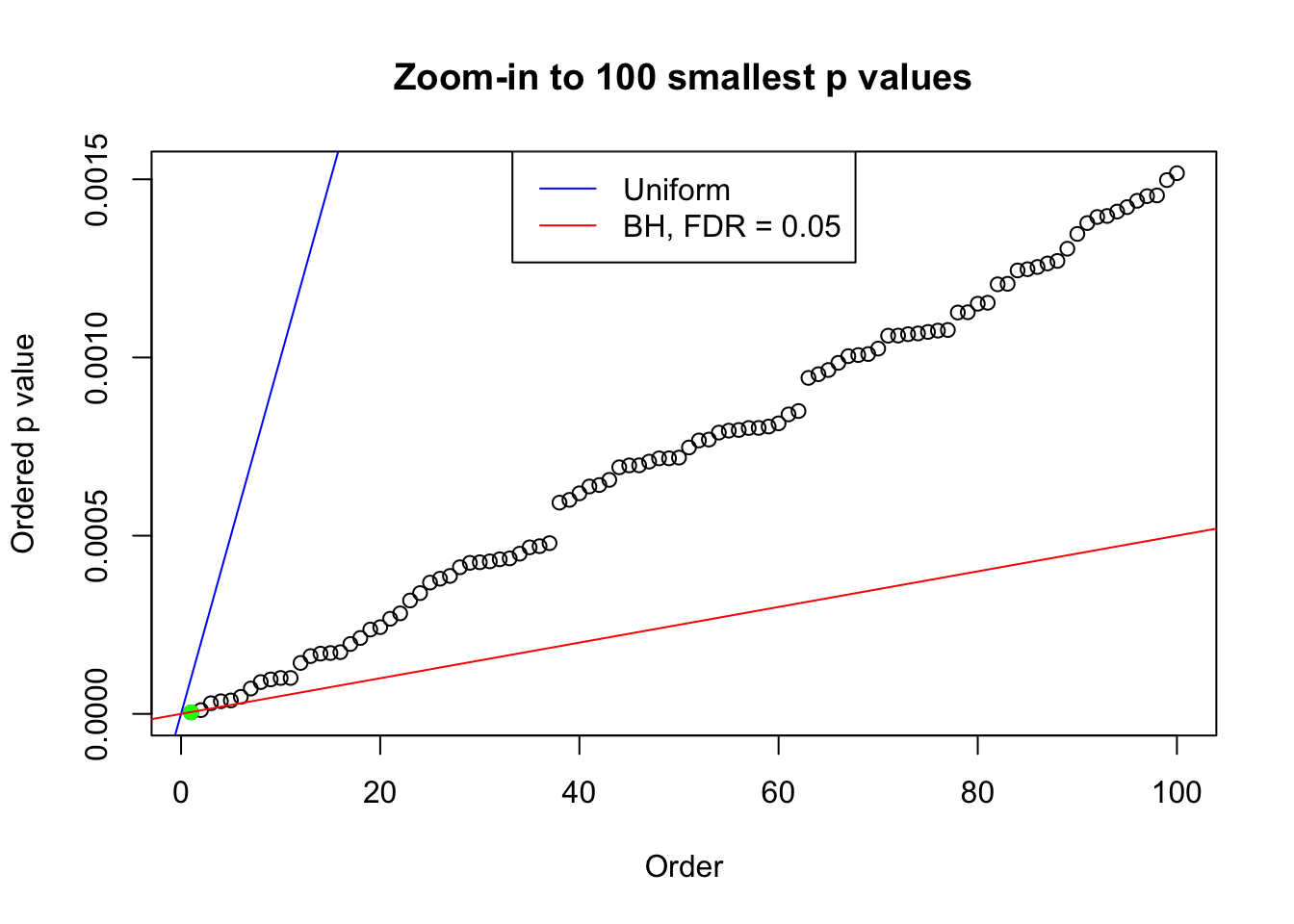
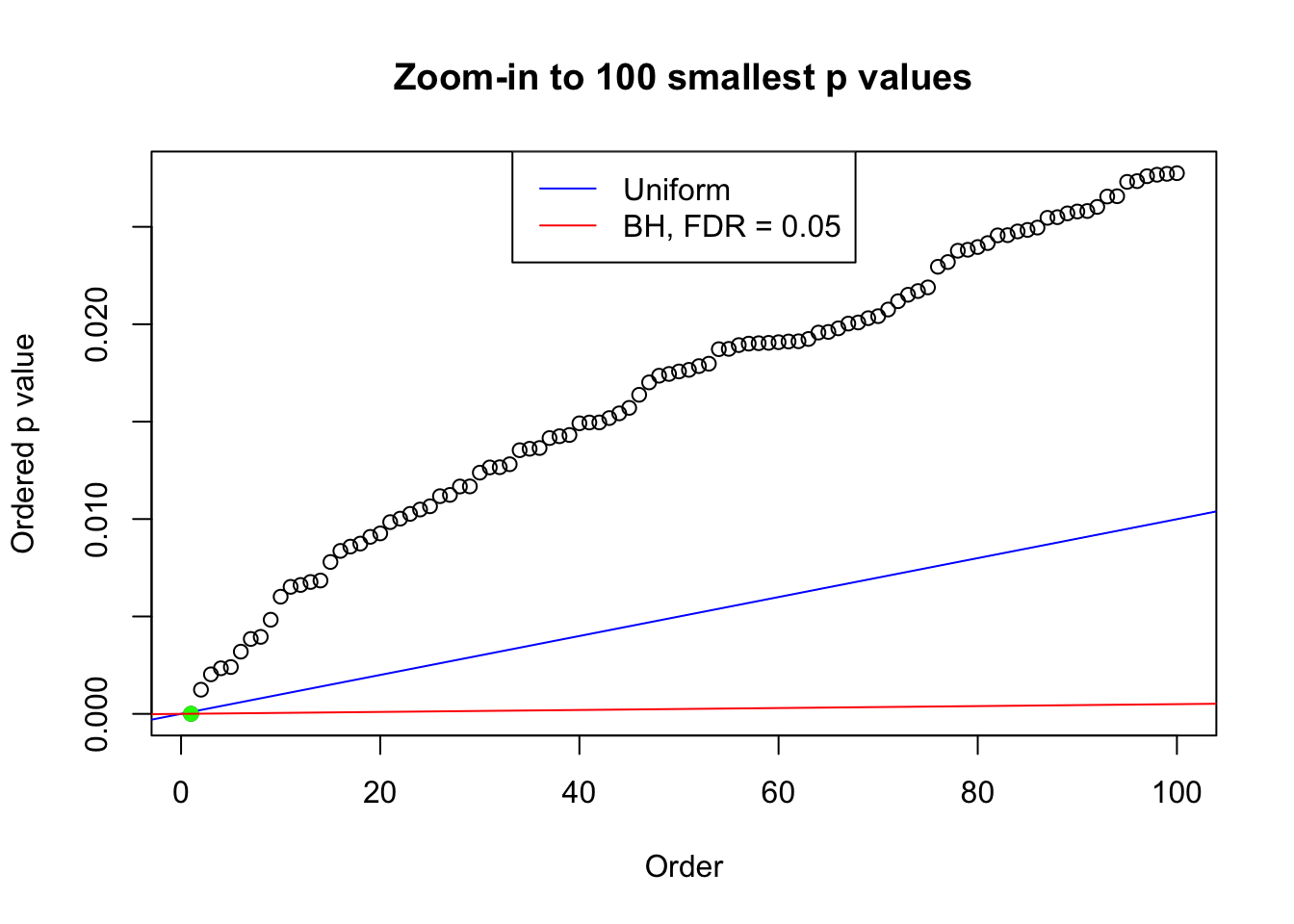
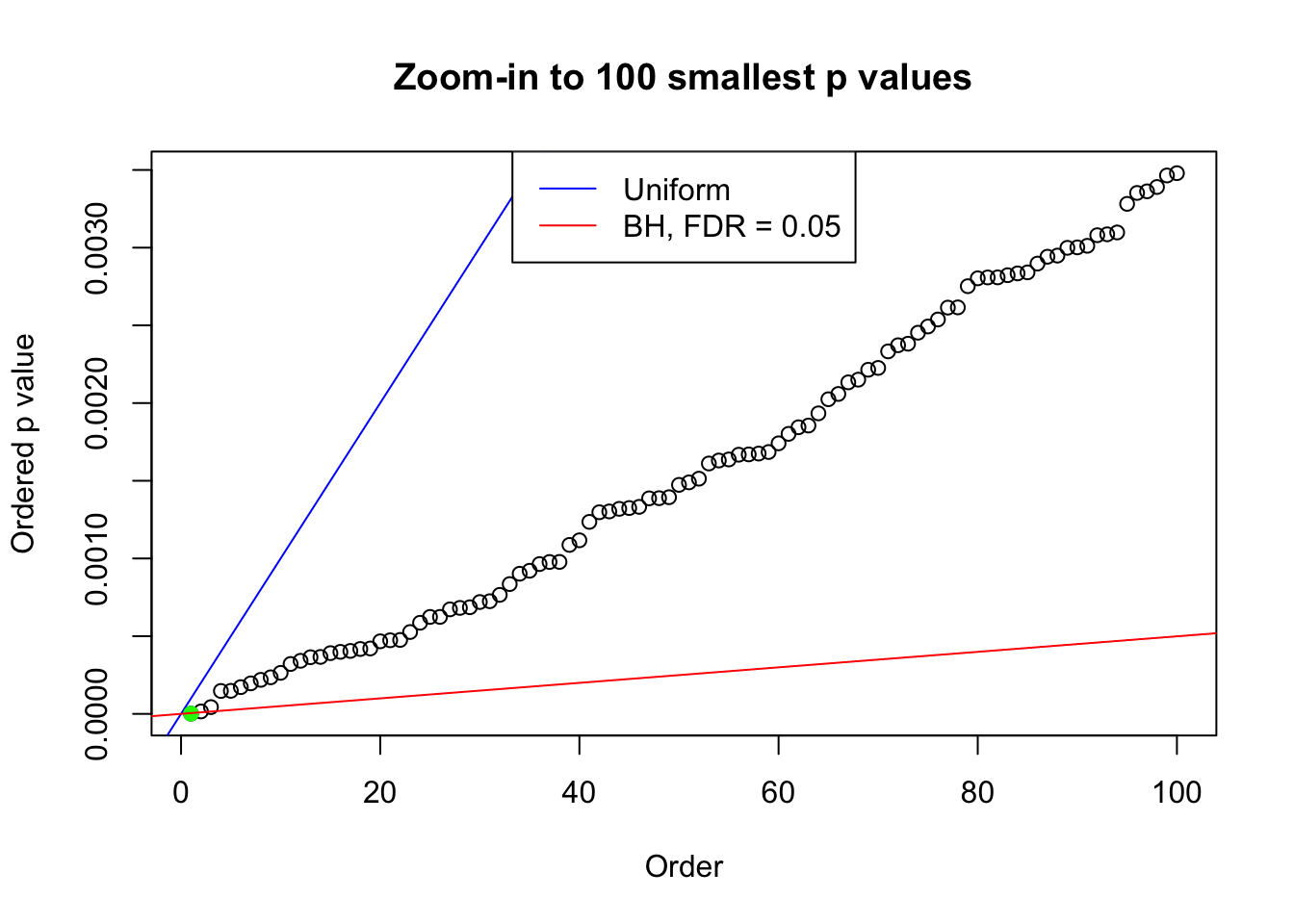
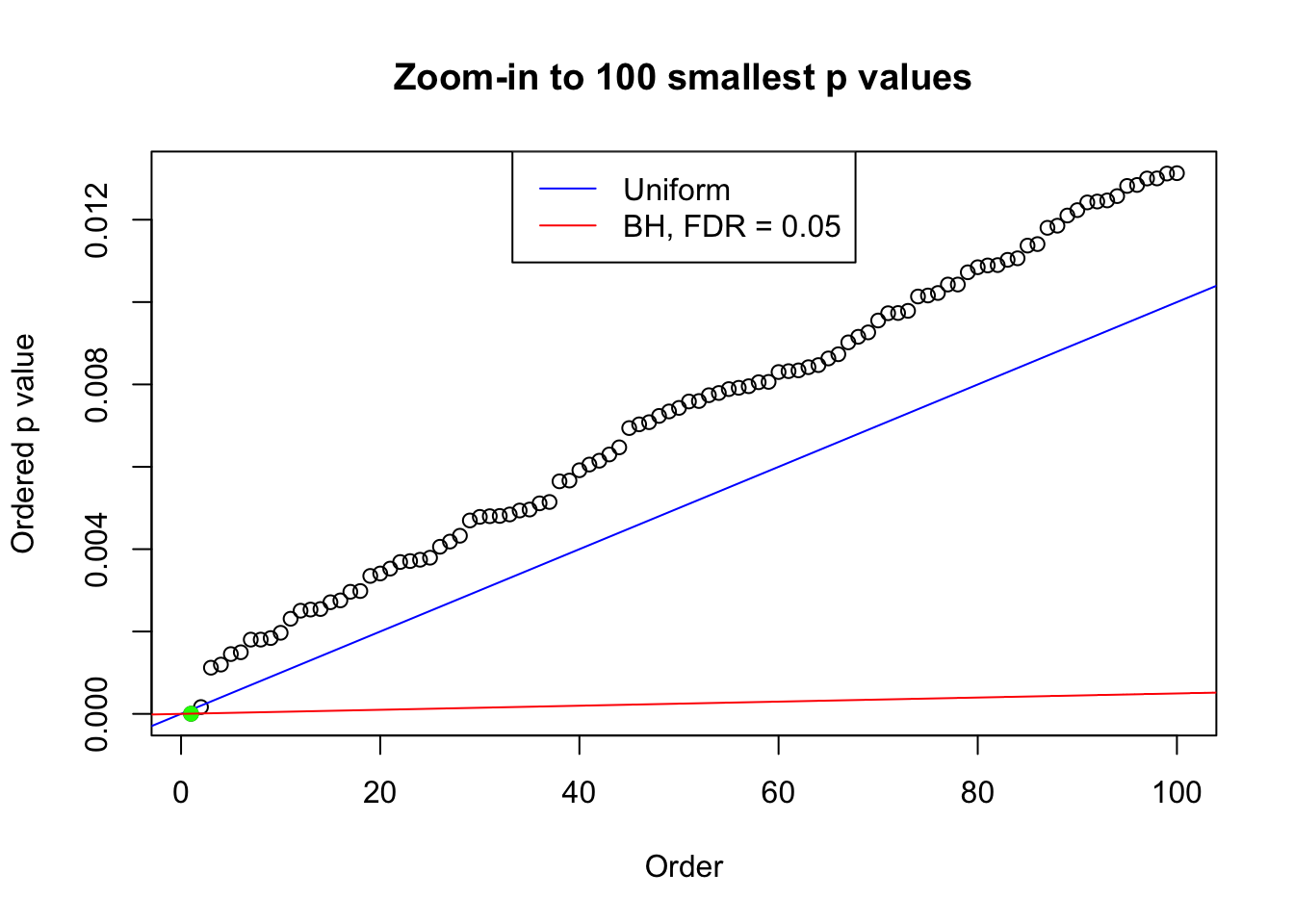
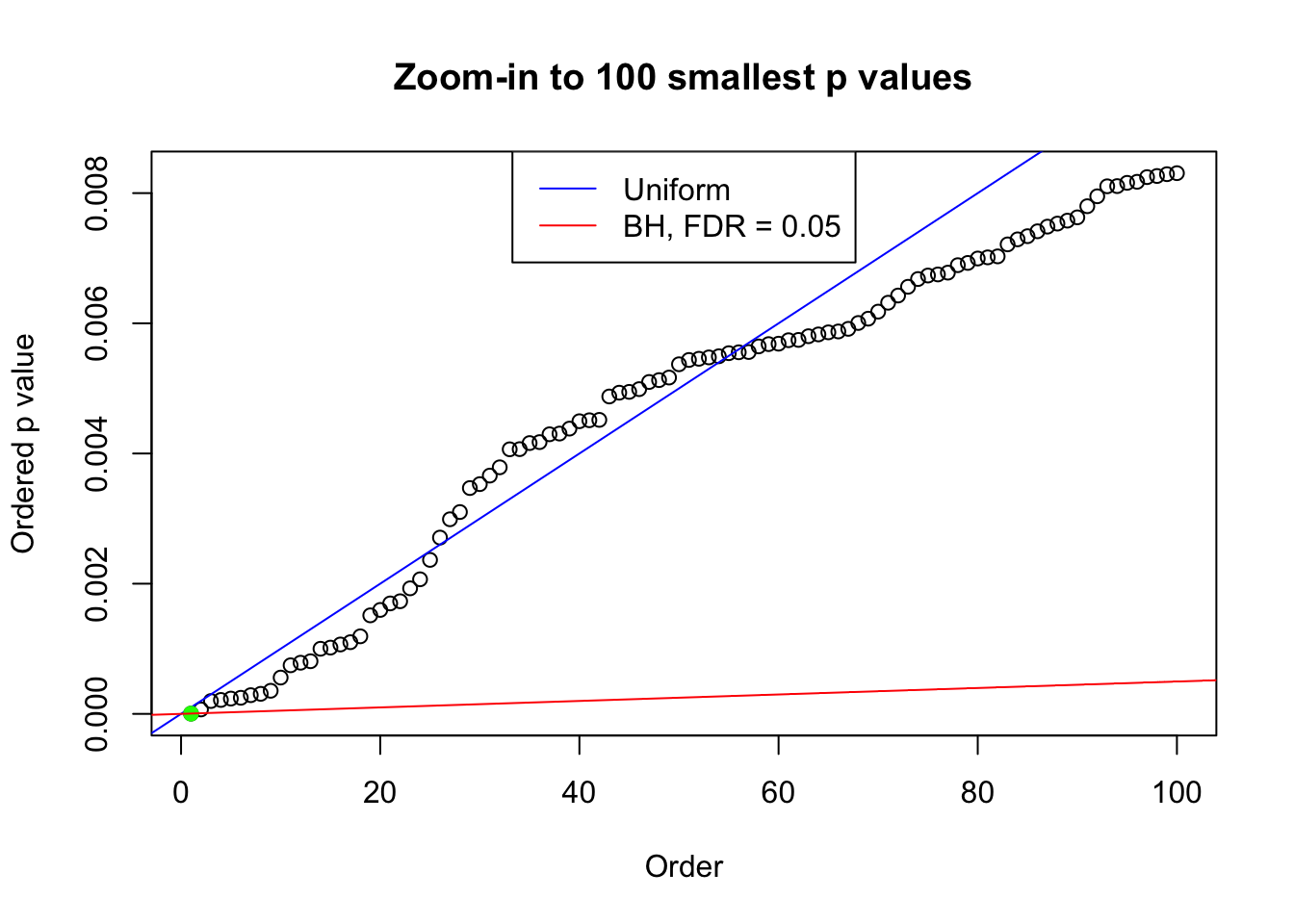
plot(pj[1:max(100, fd.bh[j])], xlab = "Order", ylab = "Ordered p value", main = "Zoom-in to 100 smallest p values", ylim = c(0, pj[max(100, fd.bh[j])]))
abline(0, 1 / m, col = "blue")
points(pj[1:fd.bh[j]], col = "green", pch = 19)
abline(0, 0.05 / m, col = "red")
legend("top", lty = 1, col = c("blue", "red"), c("Uniform", "BH, FDR = 0.05"))
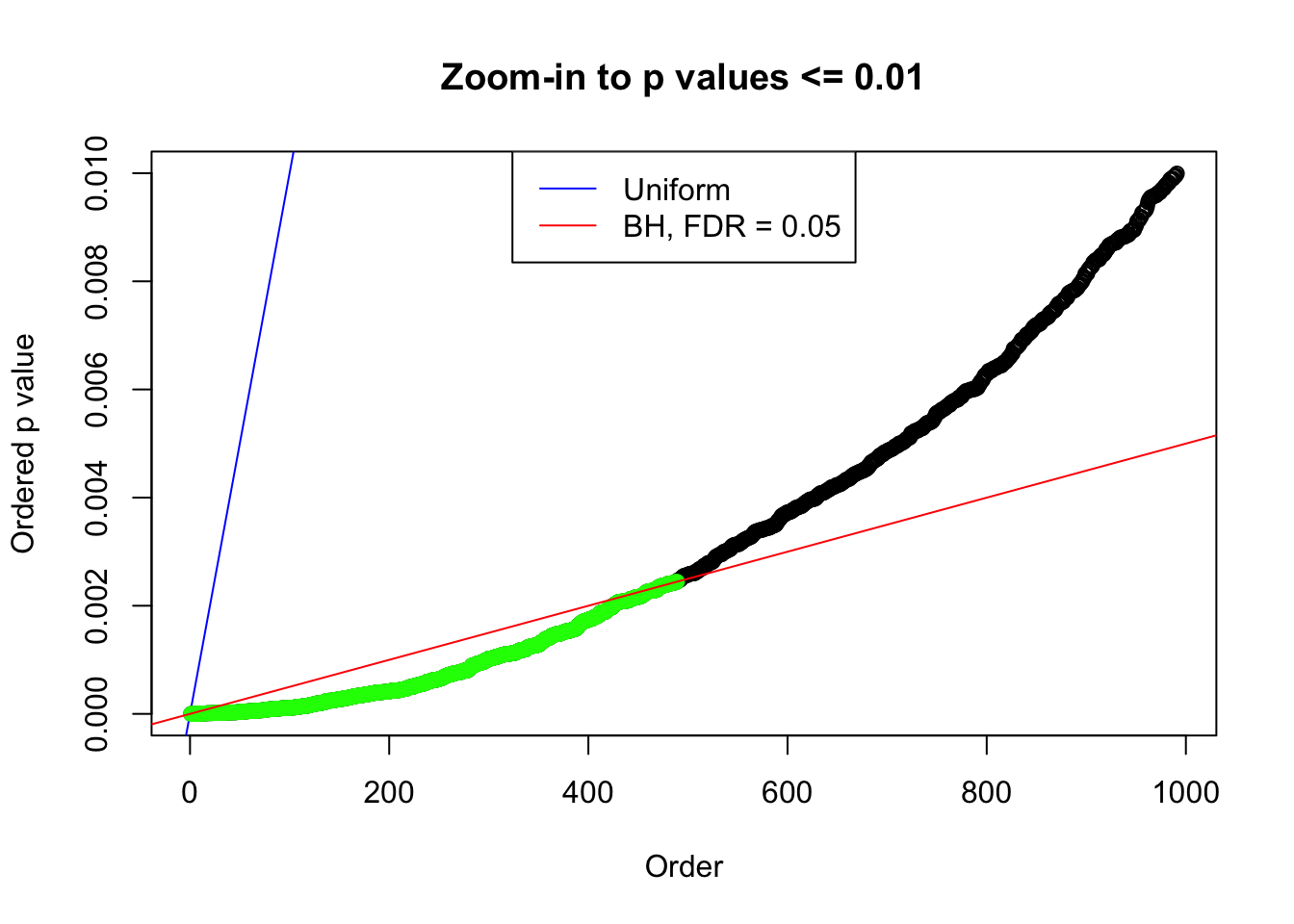
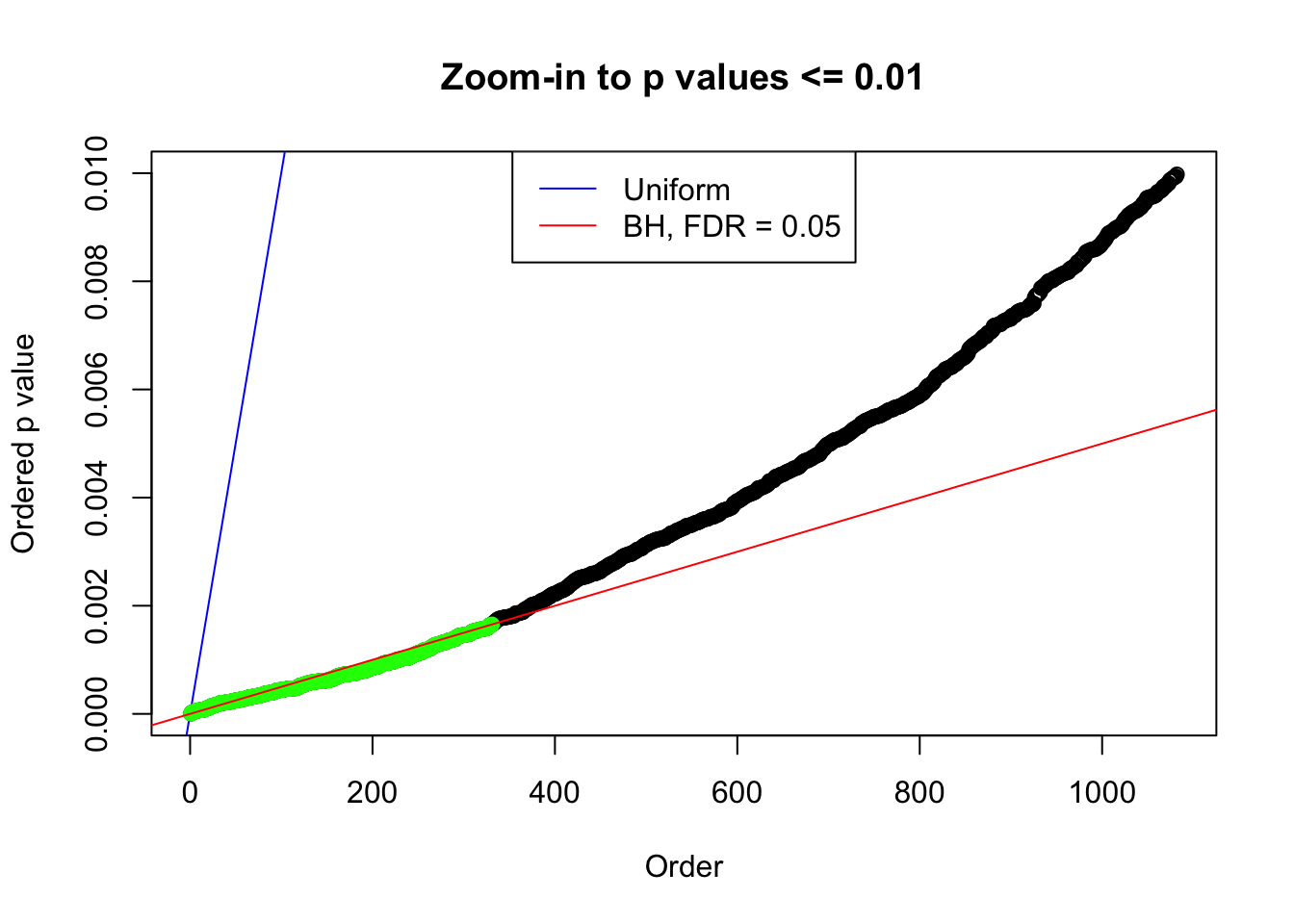
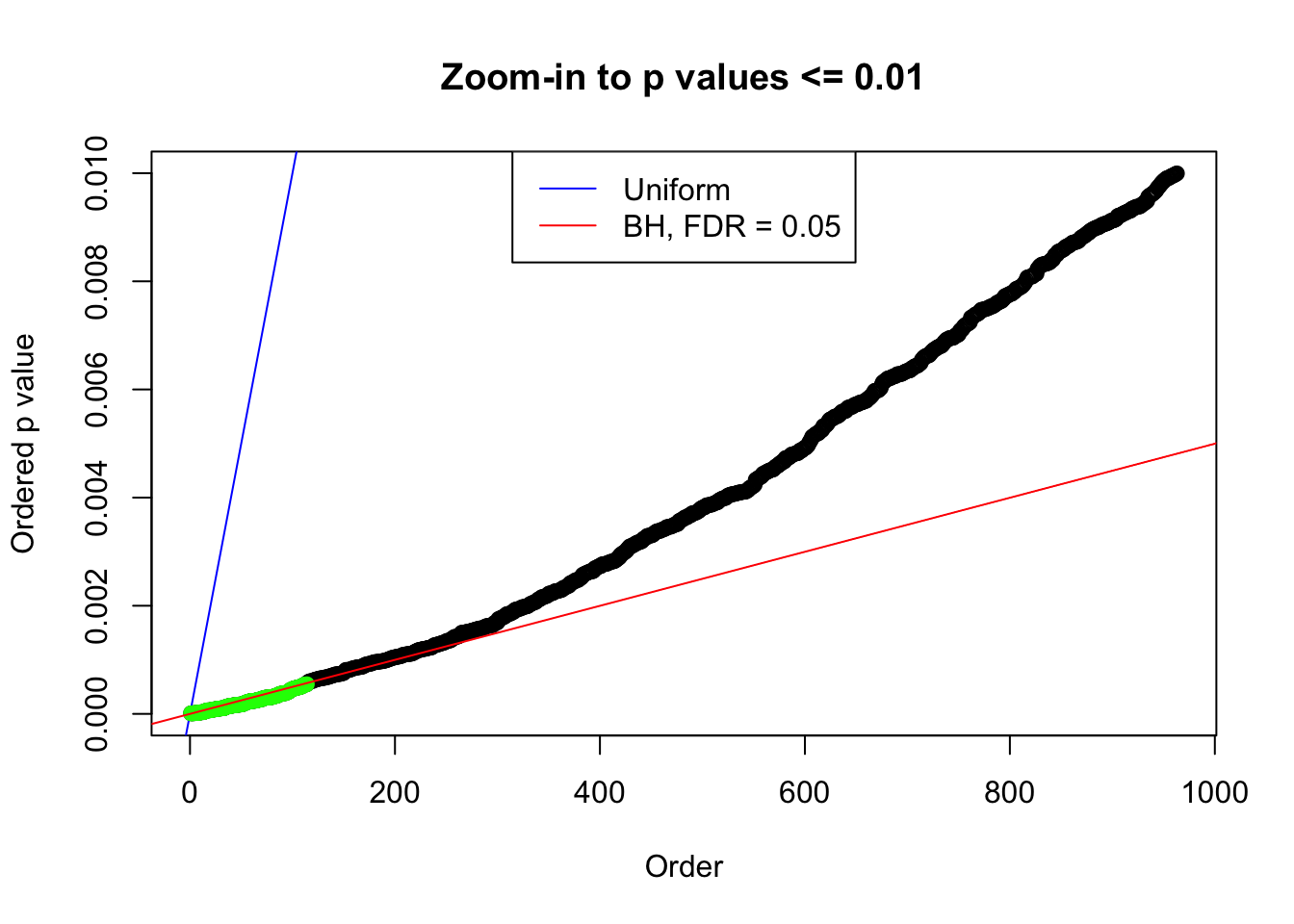
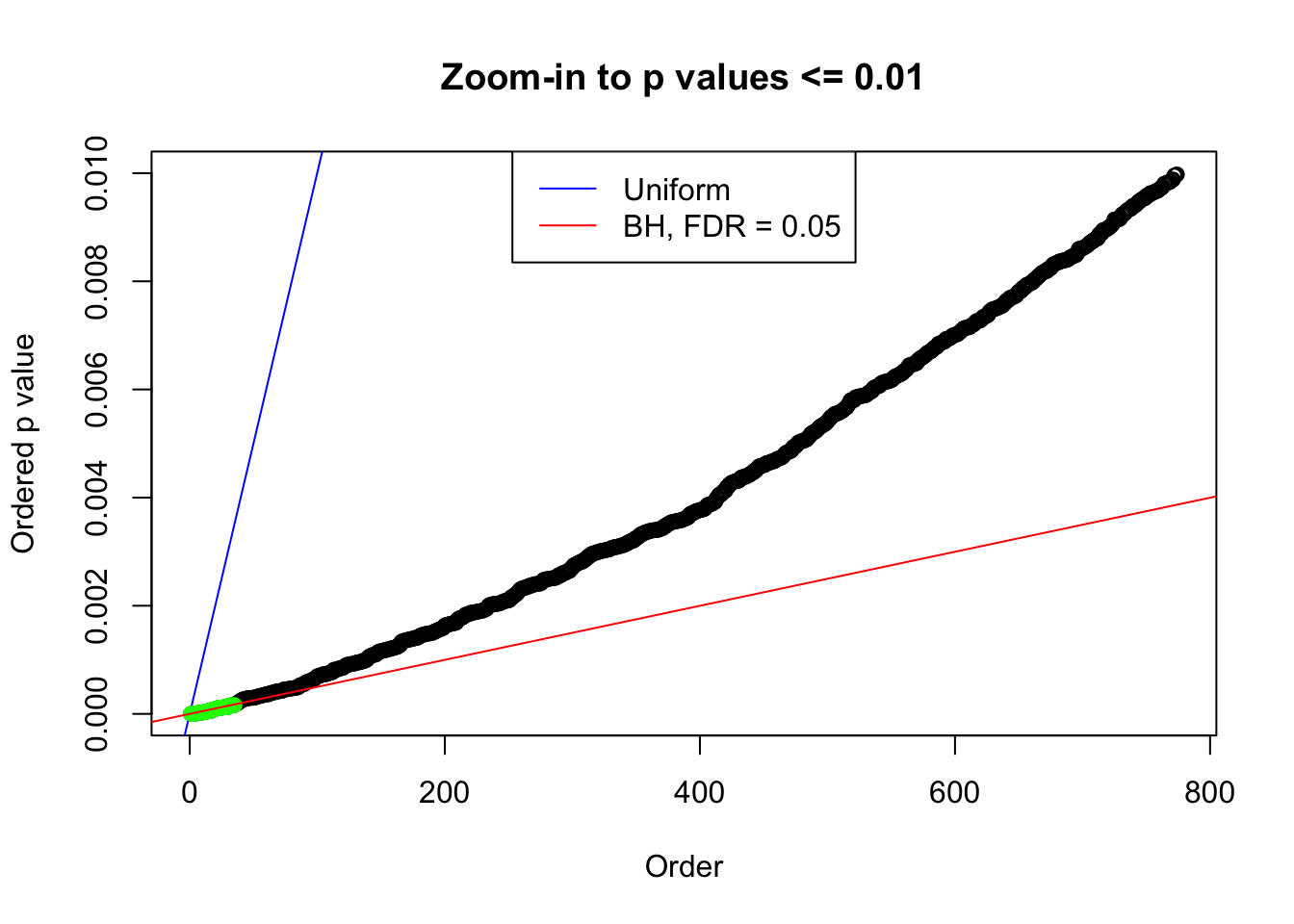
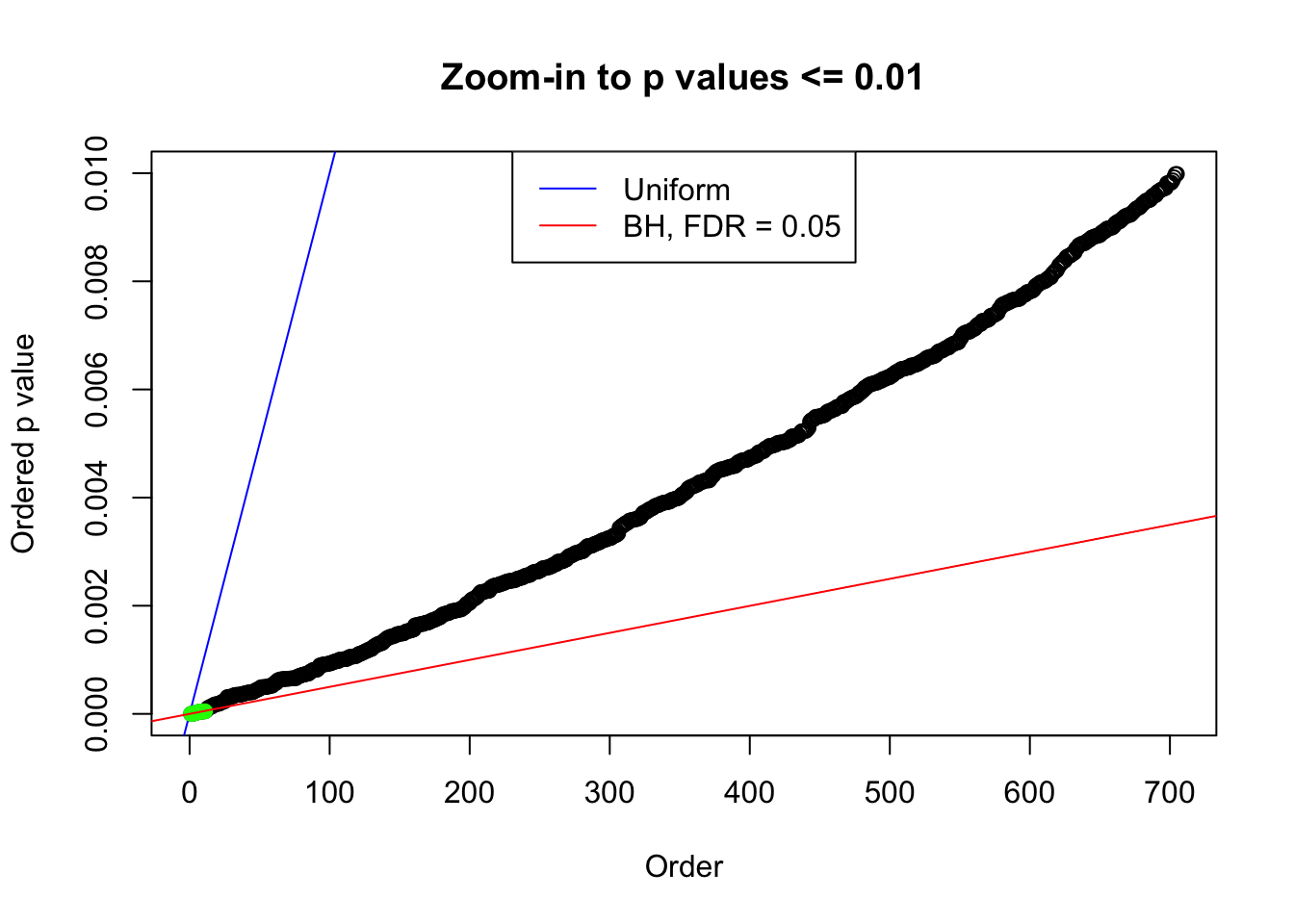
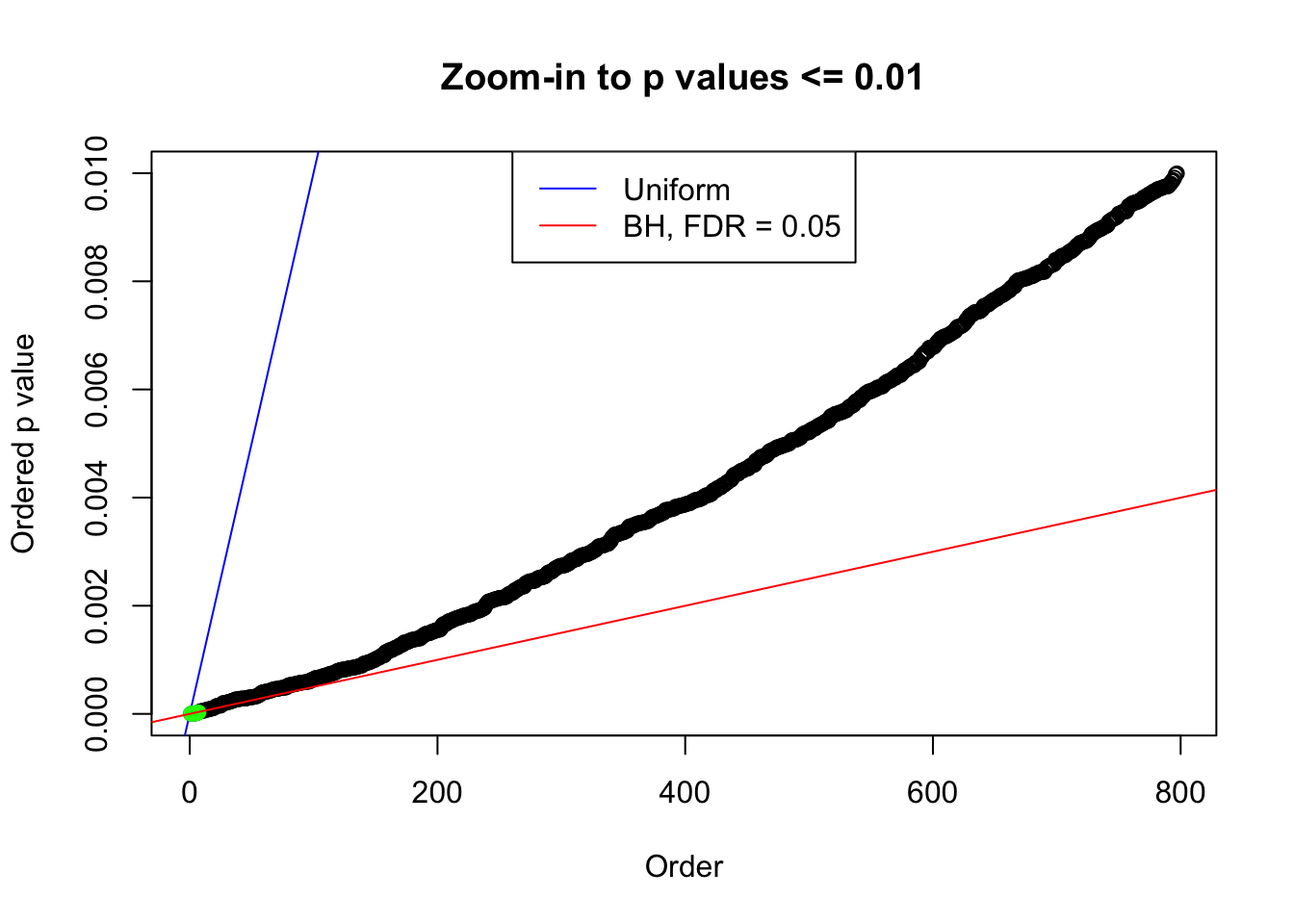
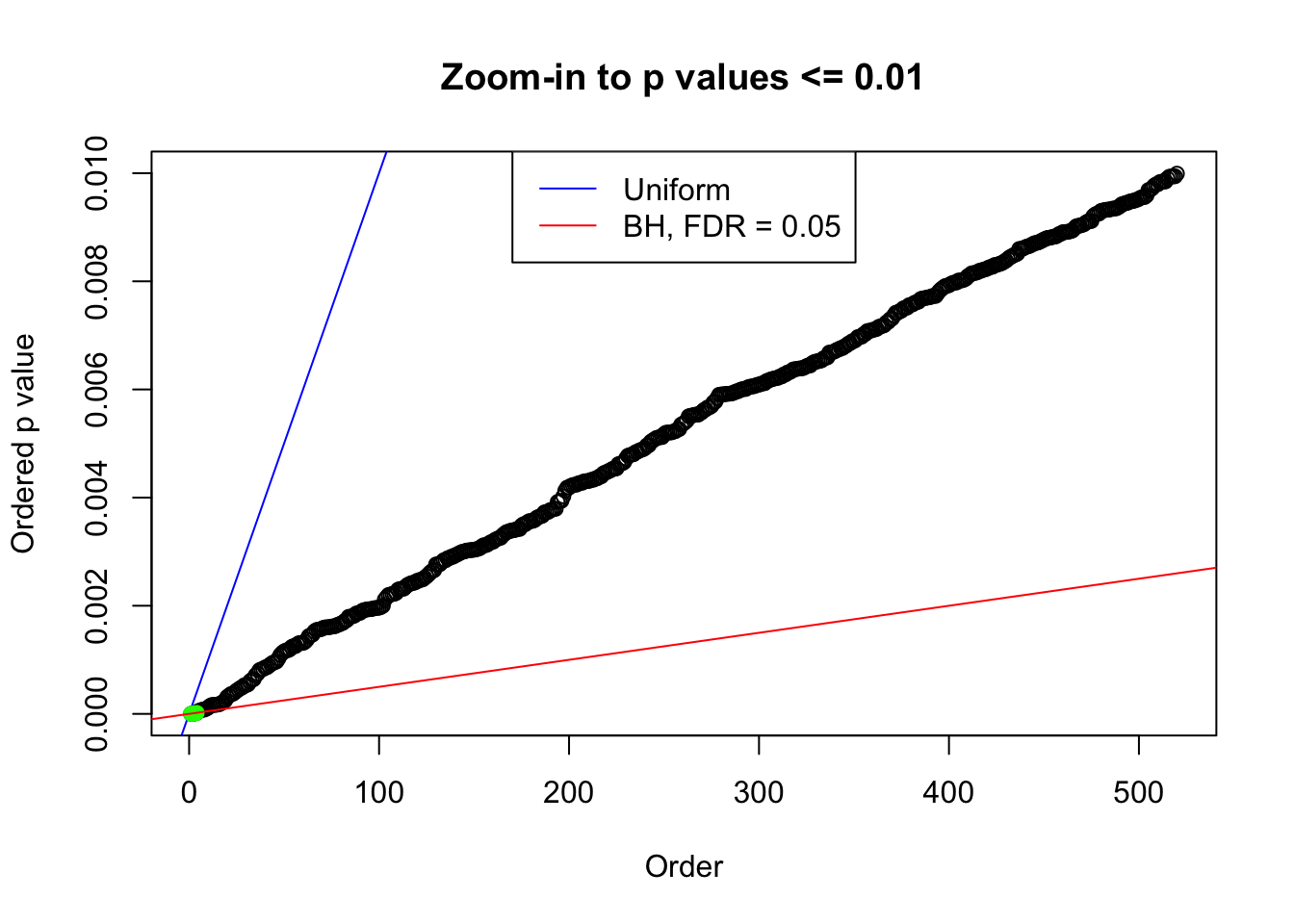
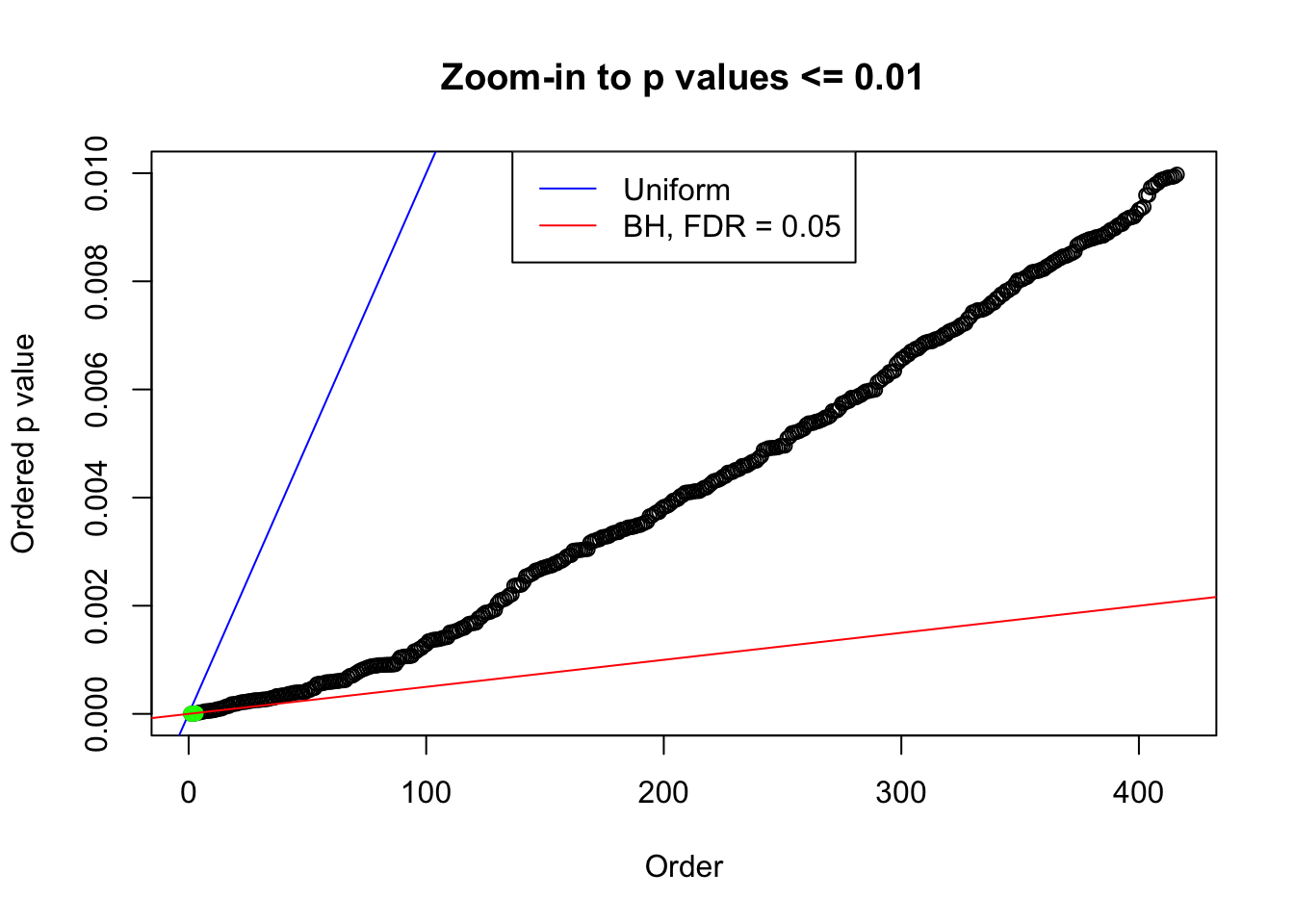
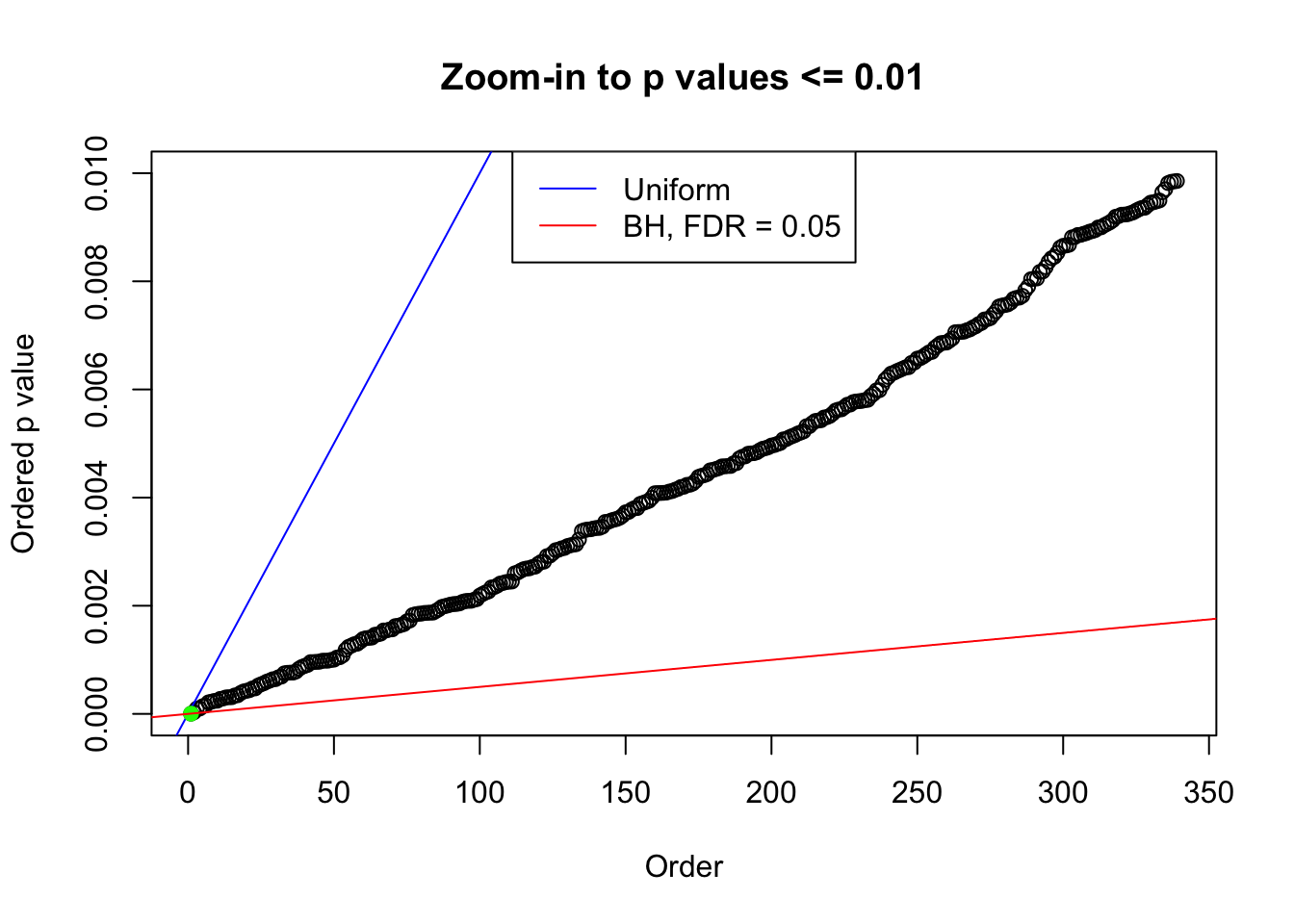
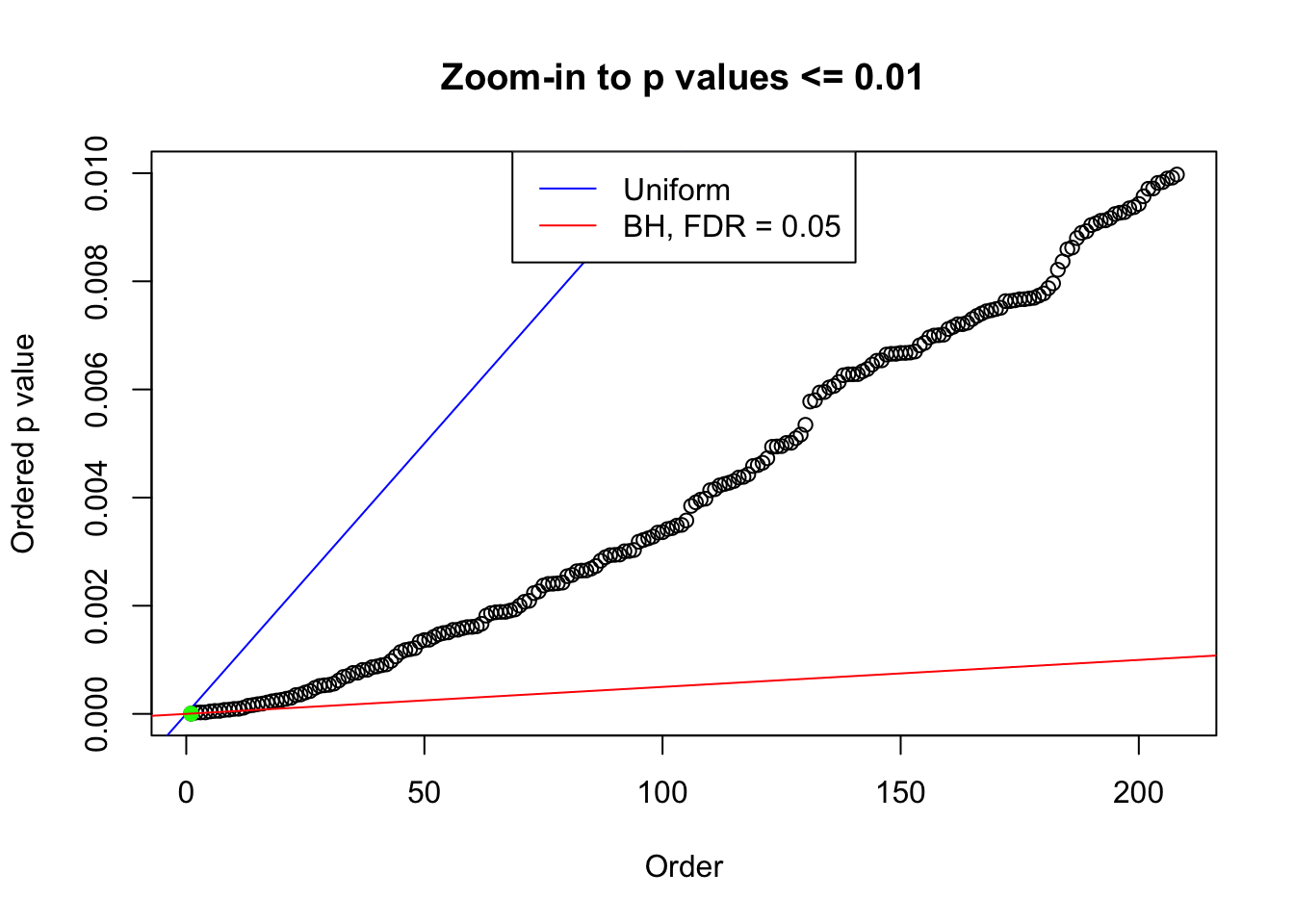
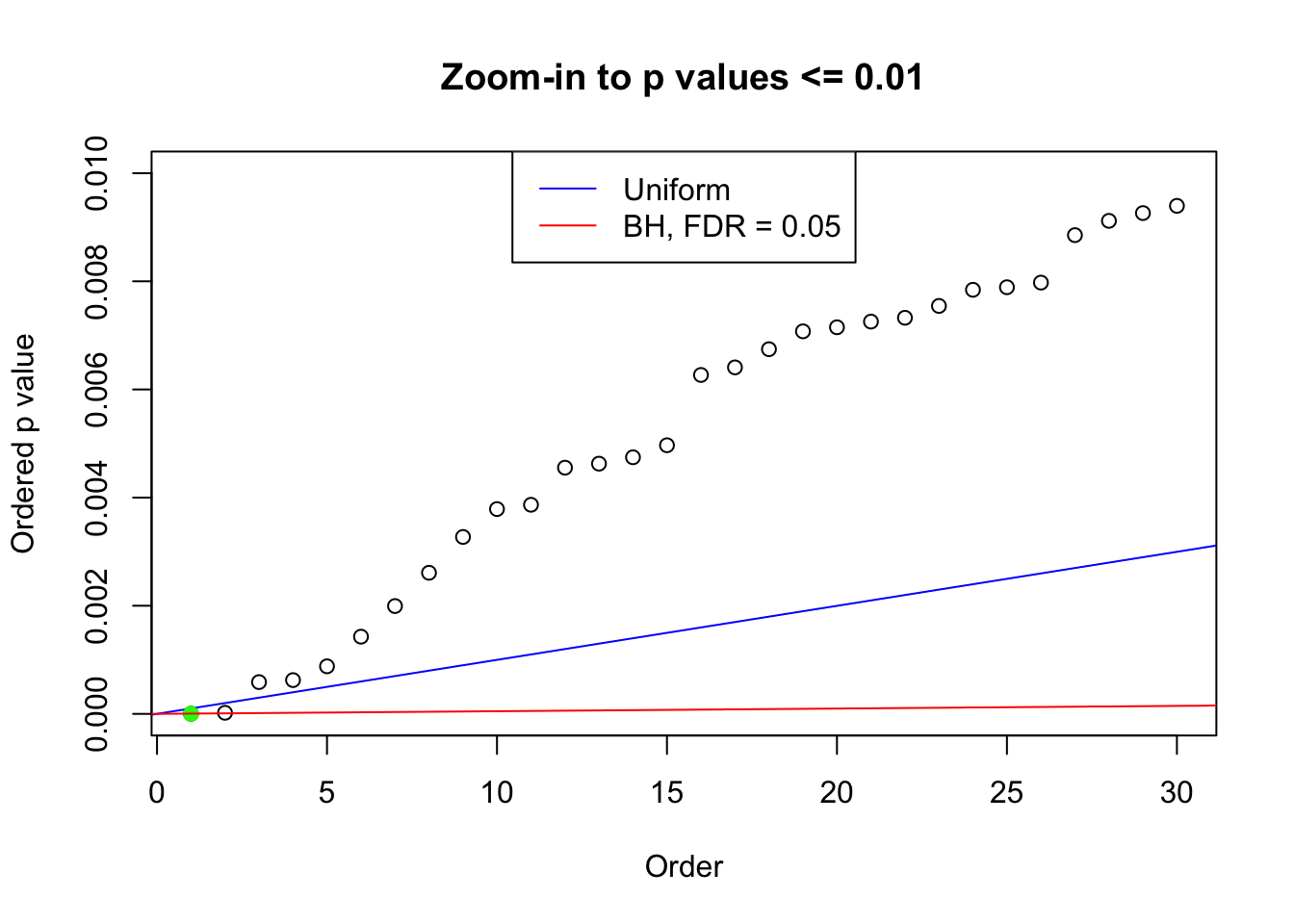
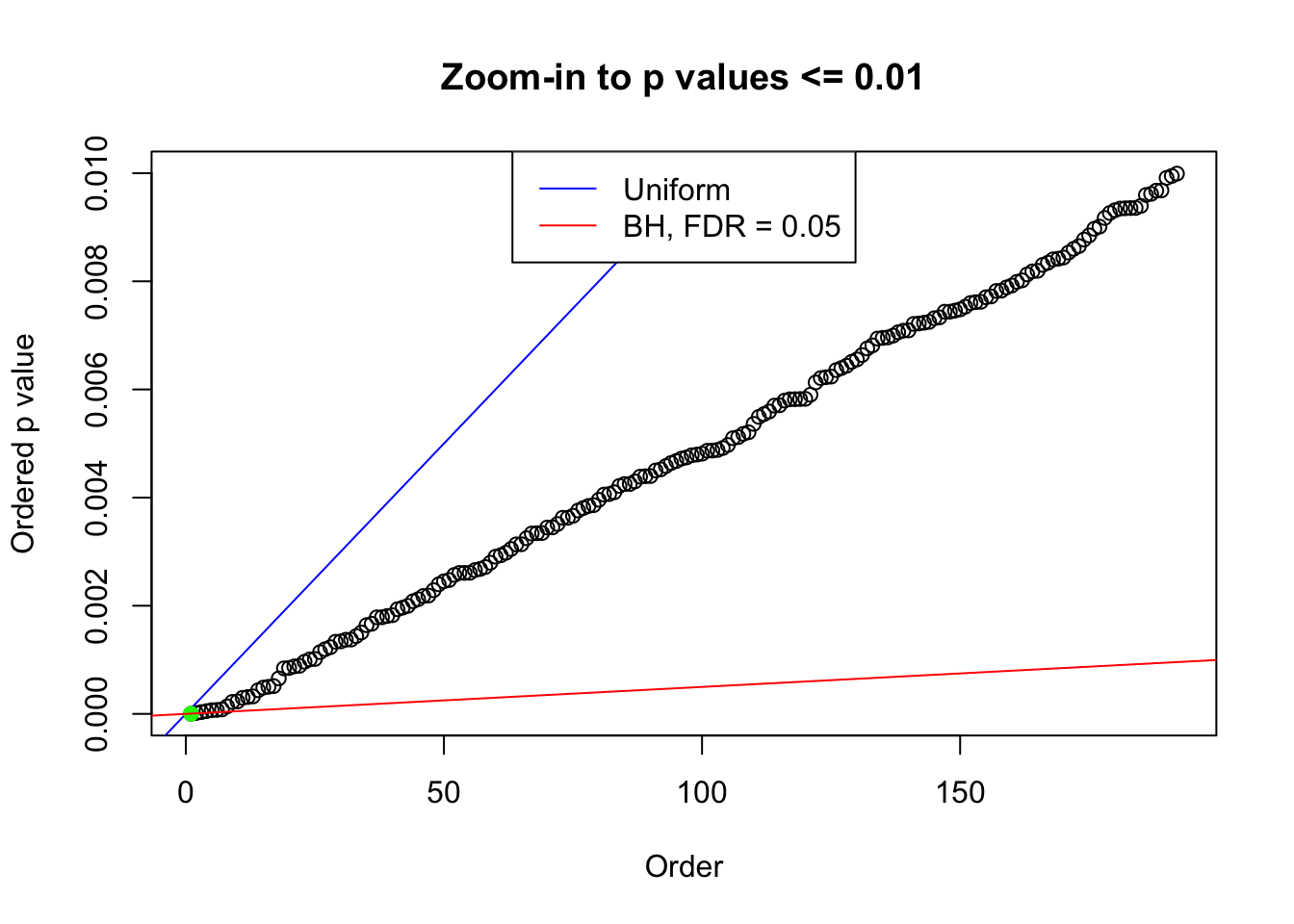
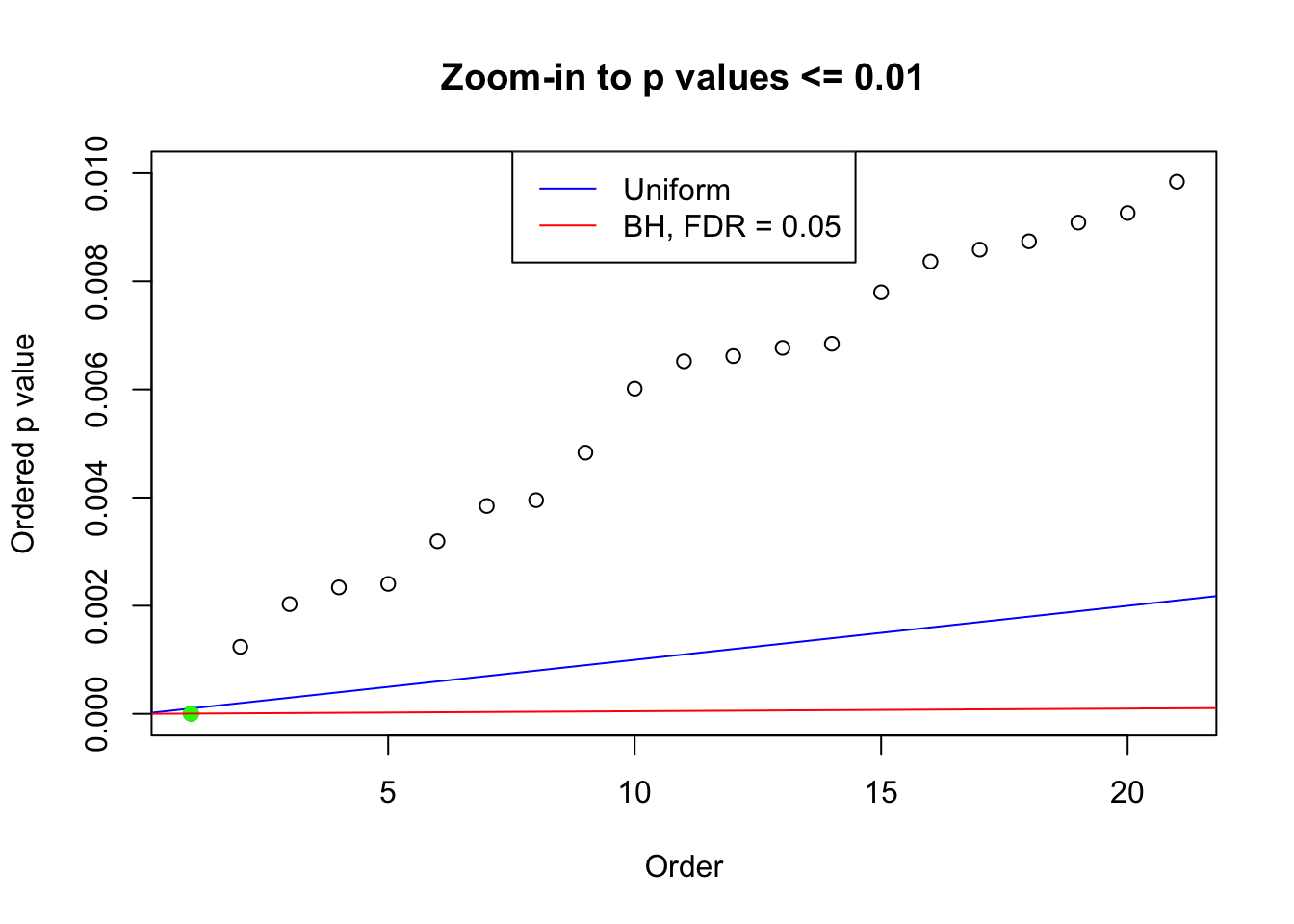
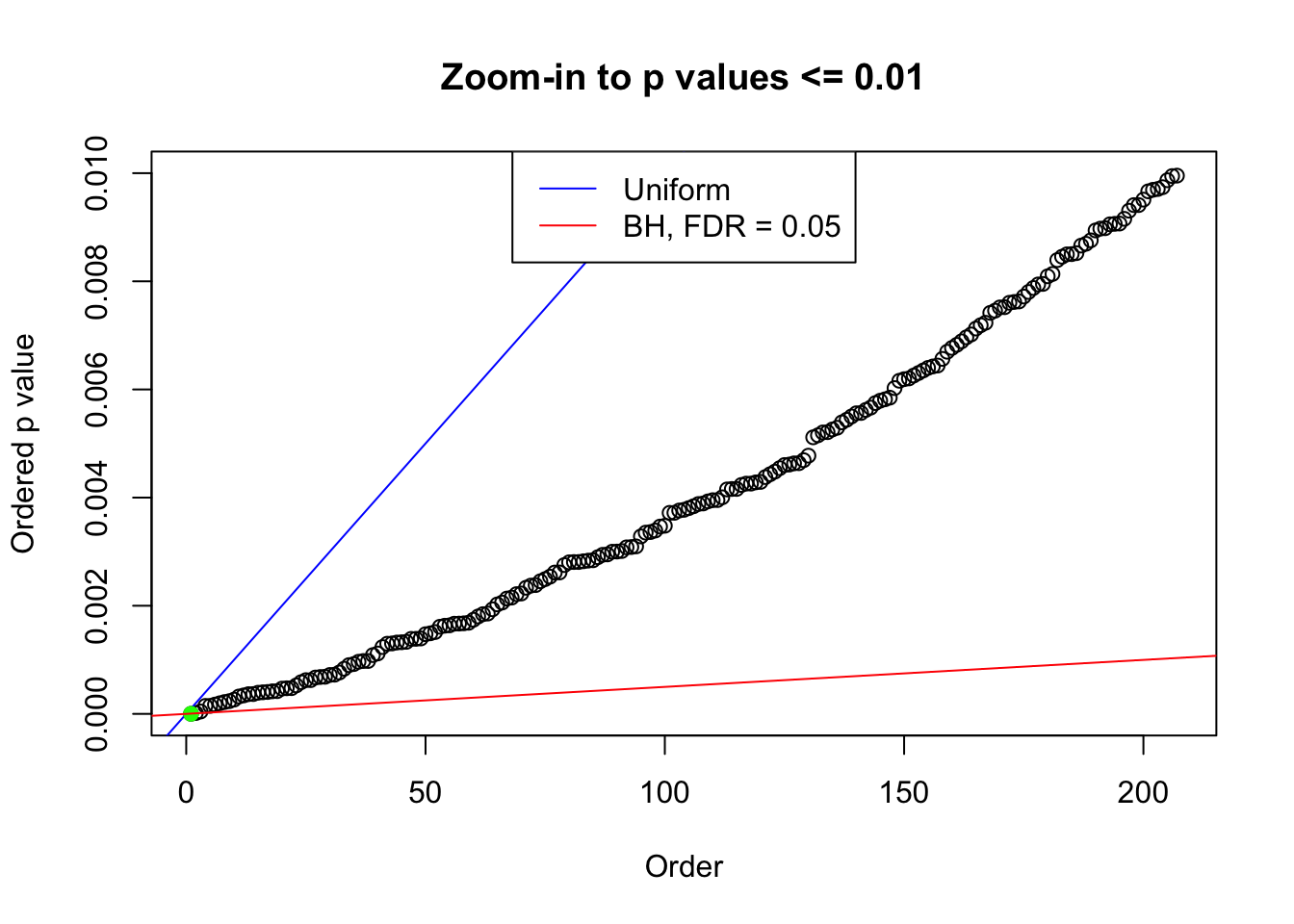
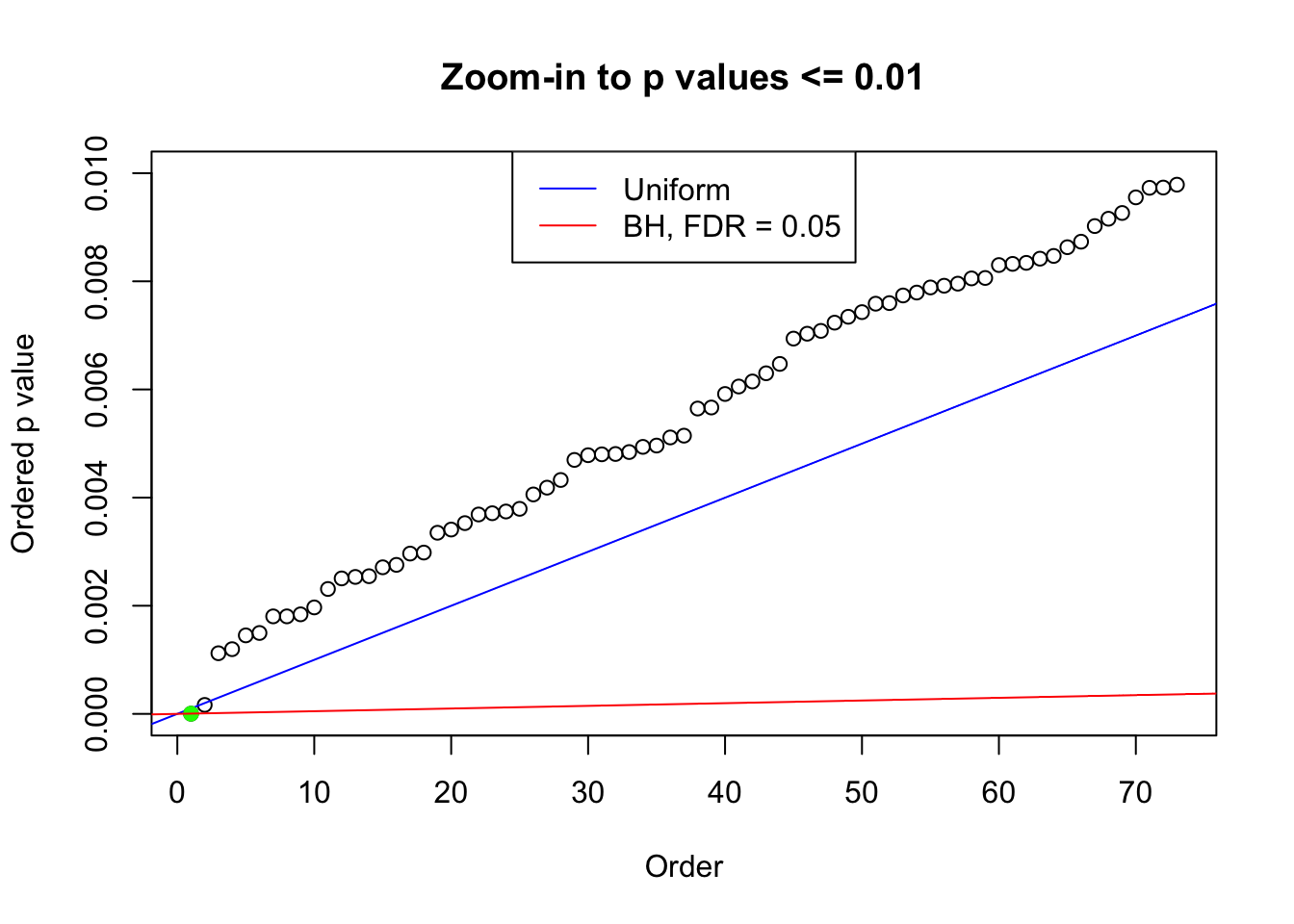
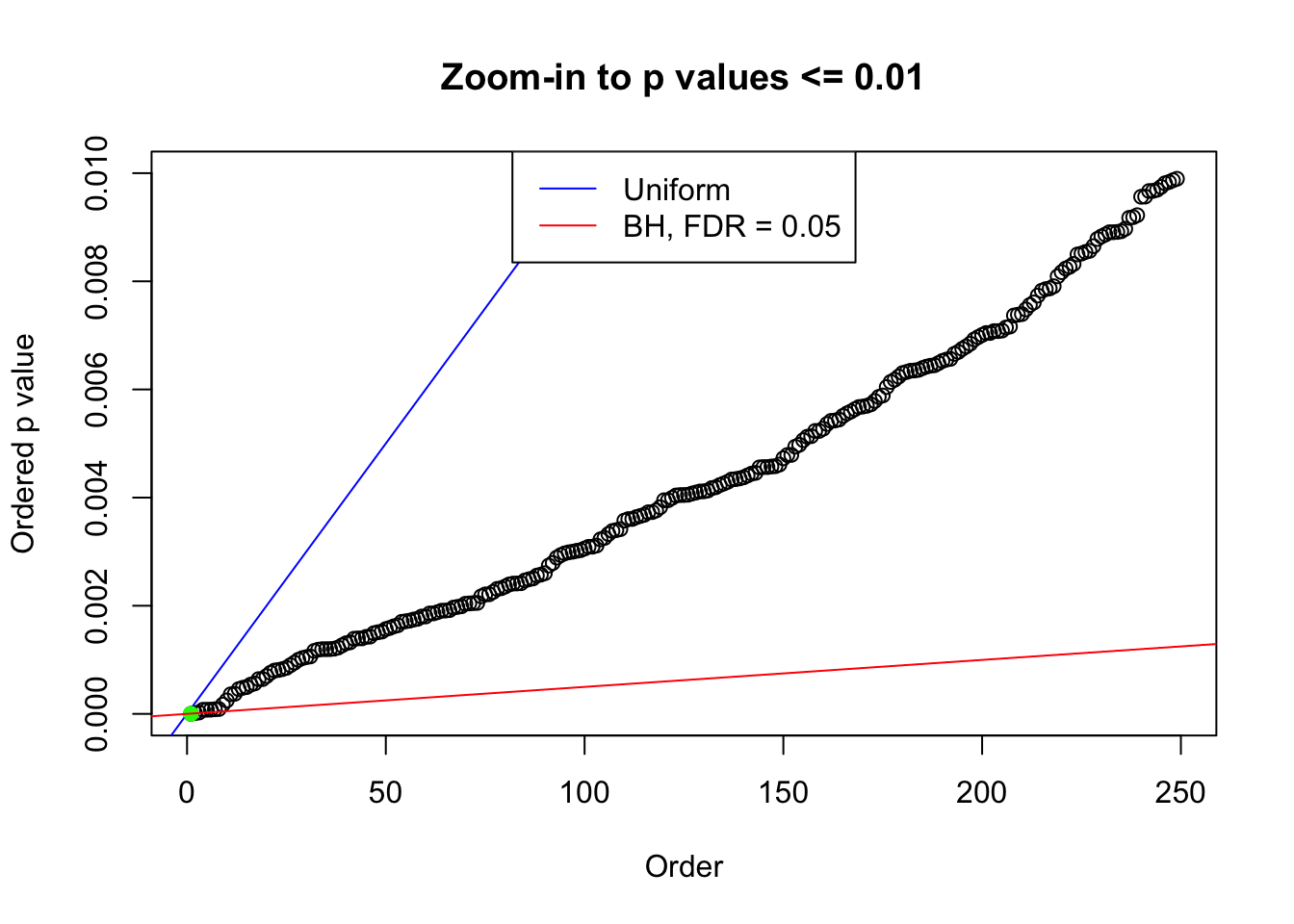
plot(pj[pj <= 0.01], xlab = "Order", ylab = "Ordered p value", main = "Zoom-in to p values <= 0.01", ylim = c(0, 0.01))
abline(0, 1 / m, col = "blue")
points(pj[1:fd.bh[j]], col = "green", pch = 19)
abline(0, 0.05 / m, col = "red")
legend("top", lty = 1, col = c("blue", "red"), c("Uniform", "BH, FDR = 0.05"))
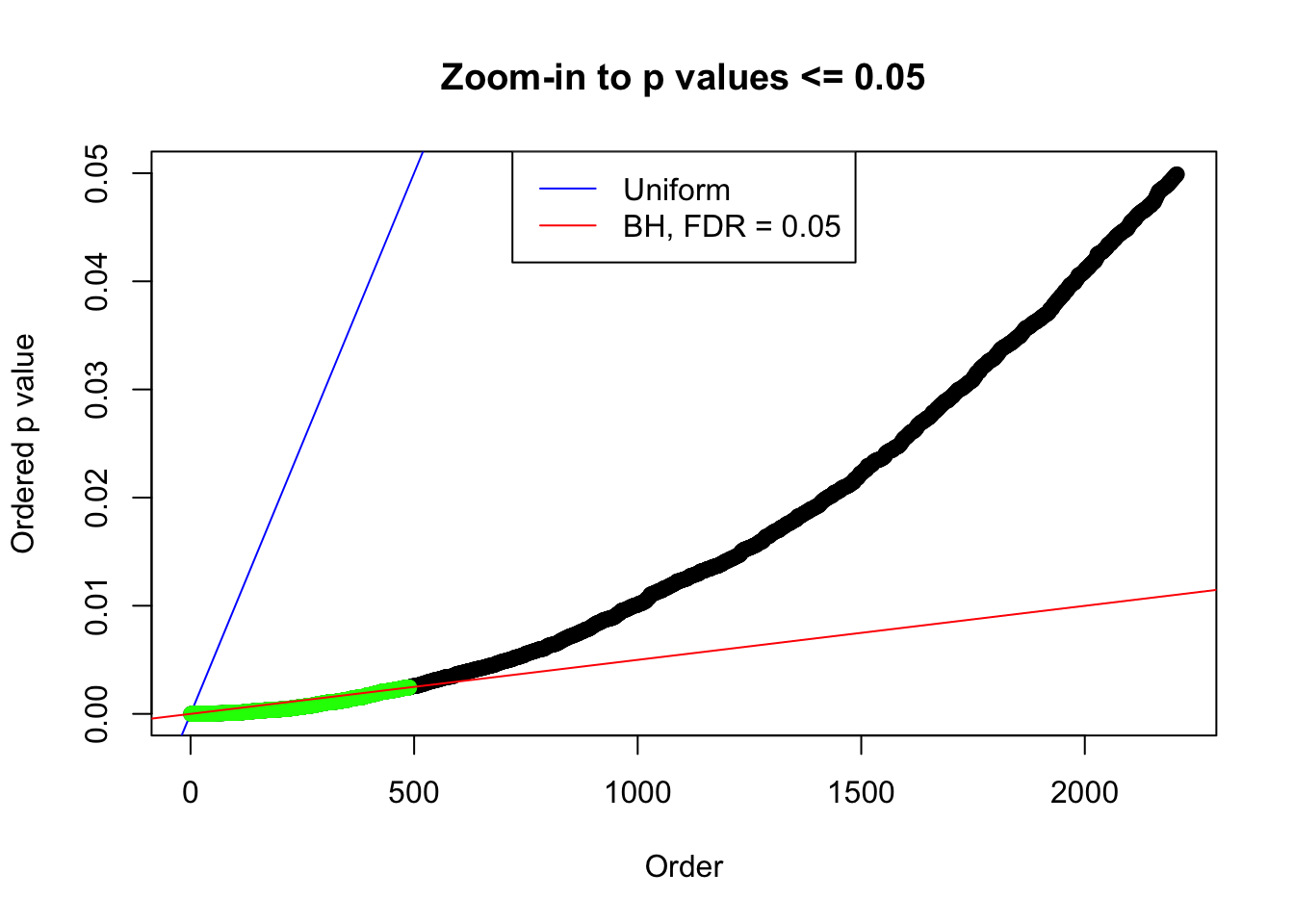
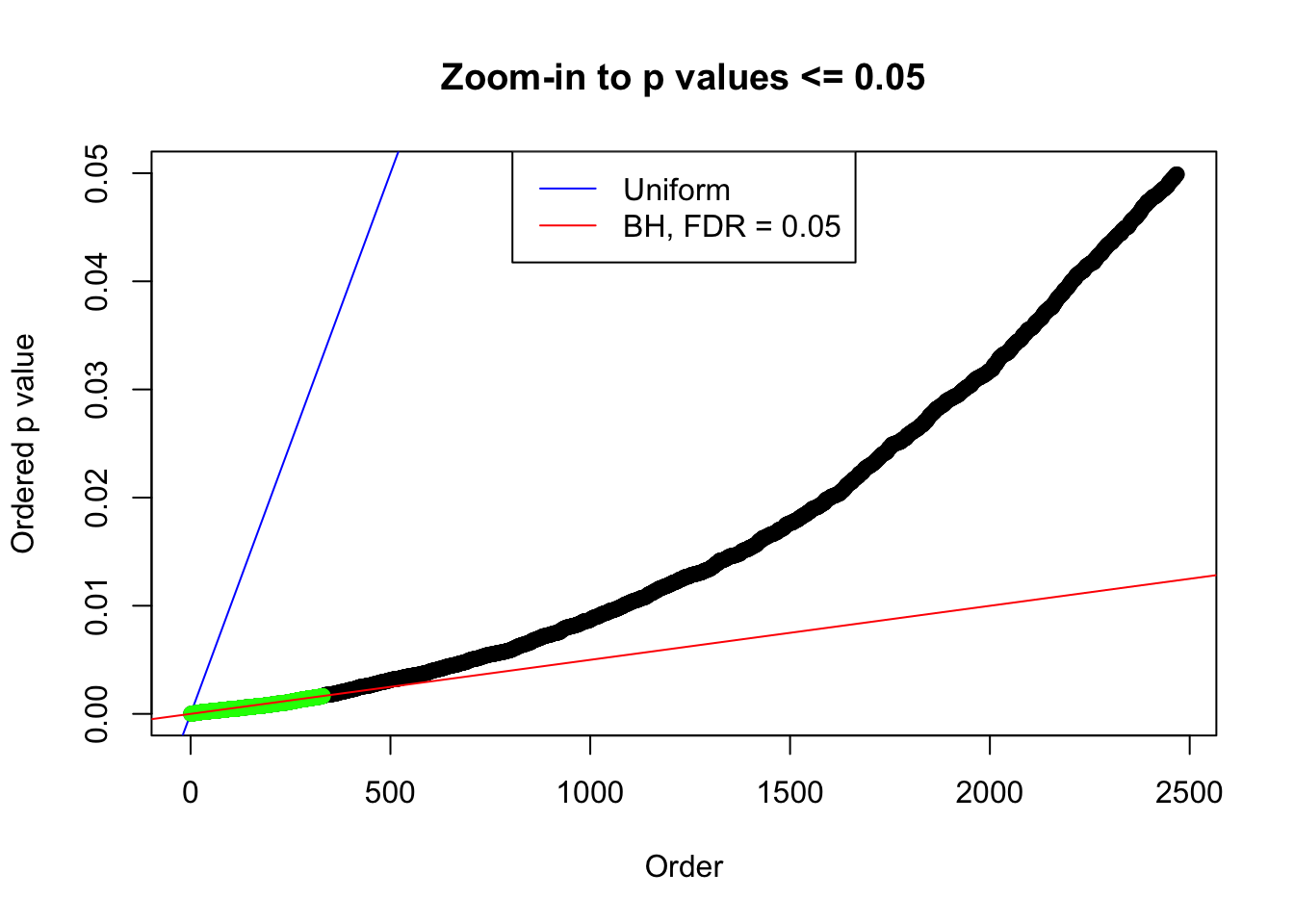
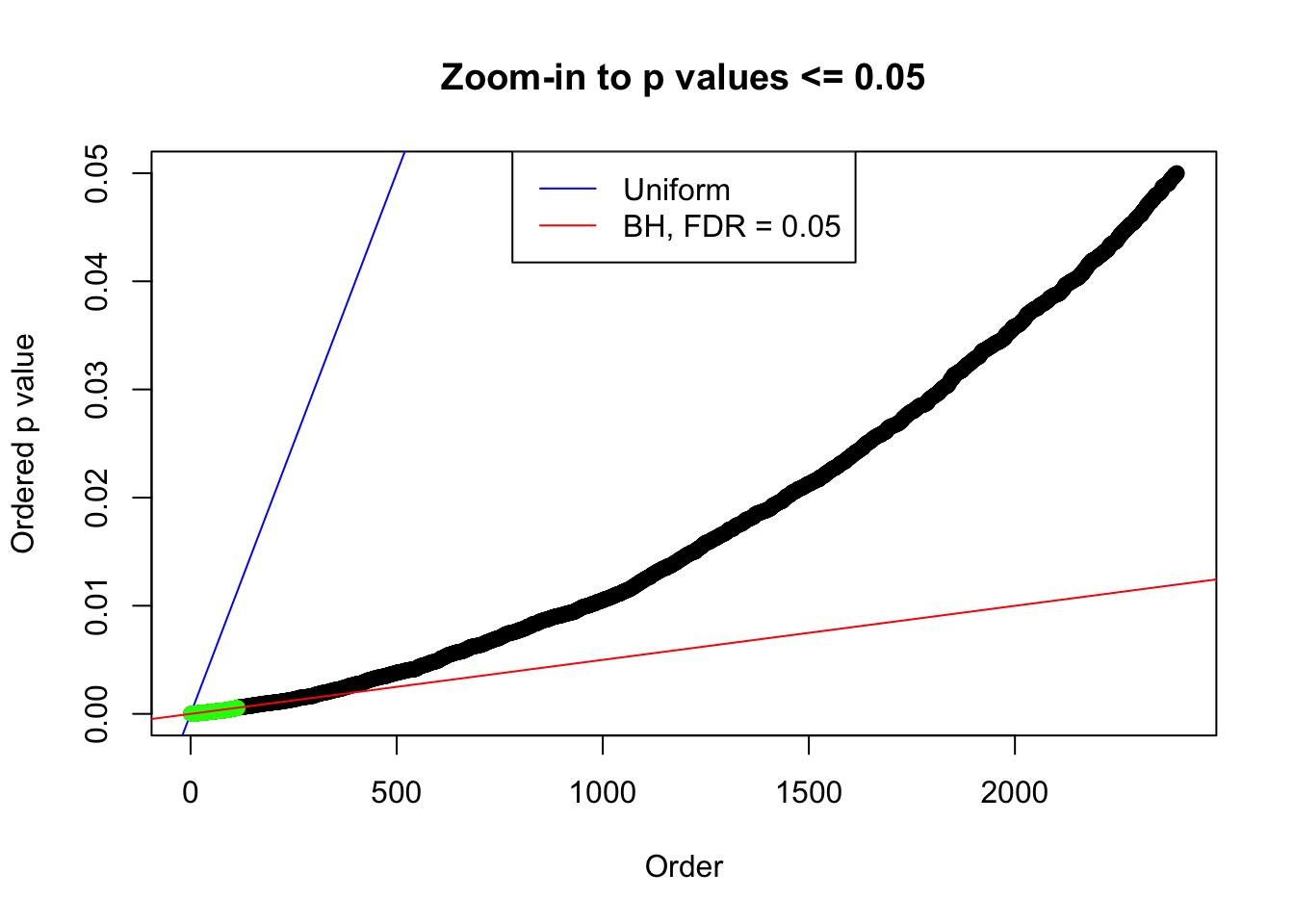
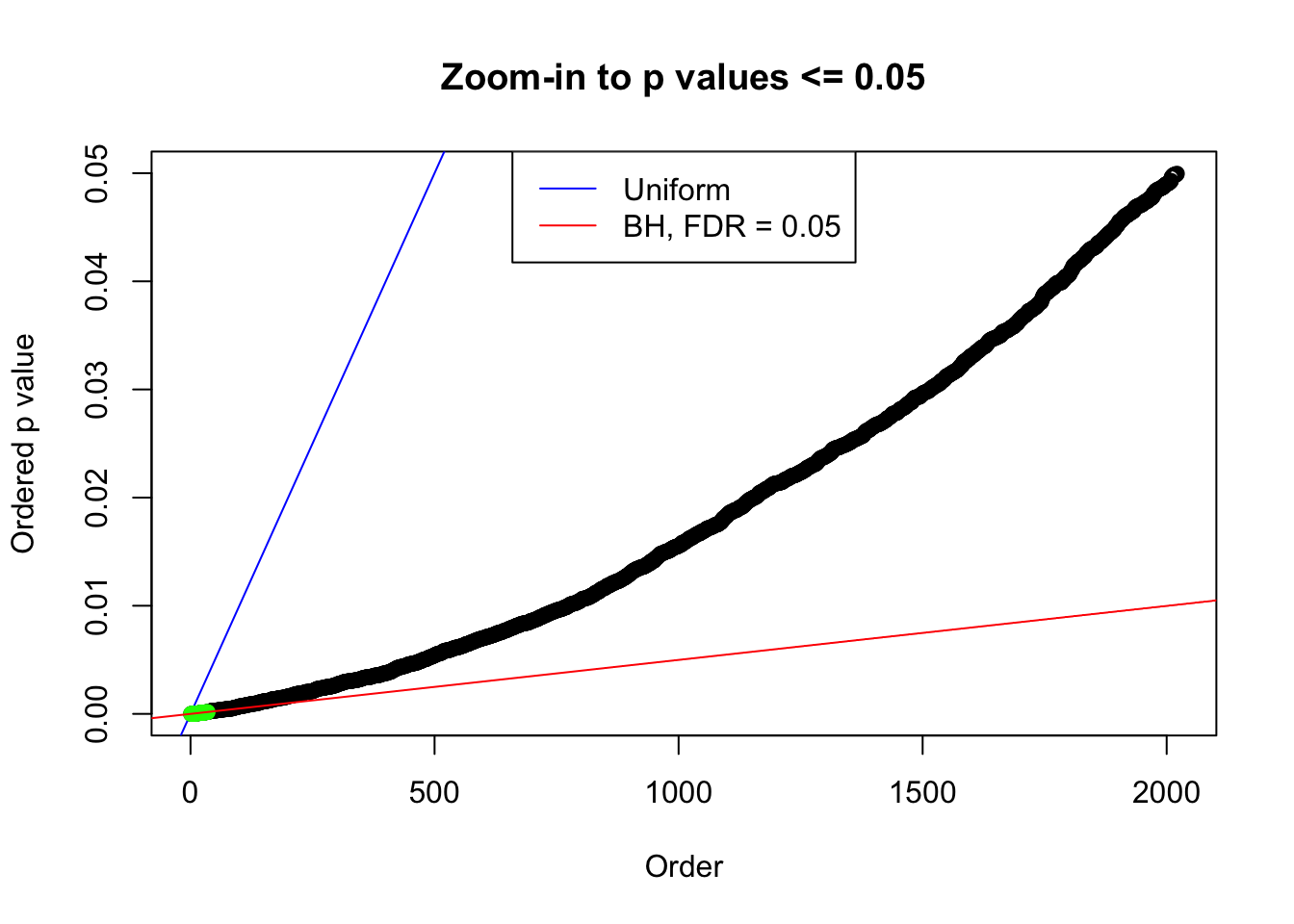
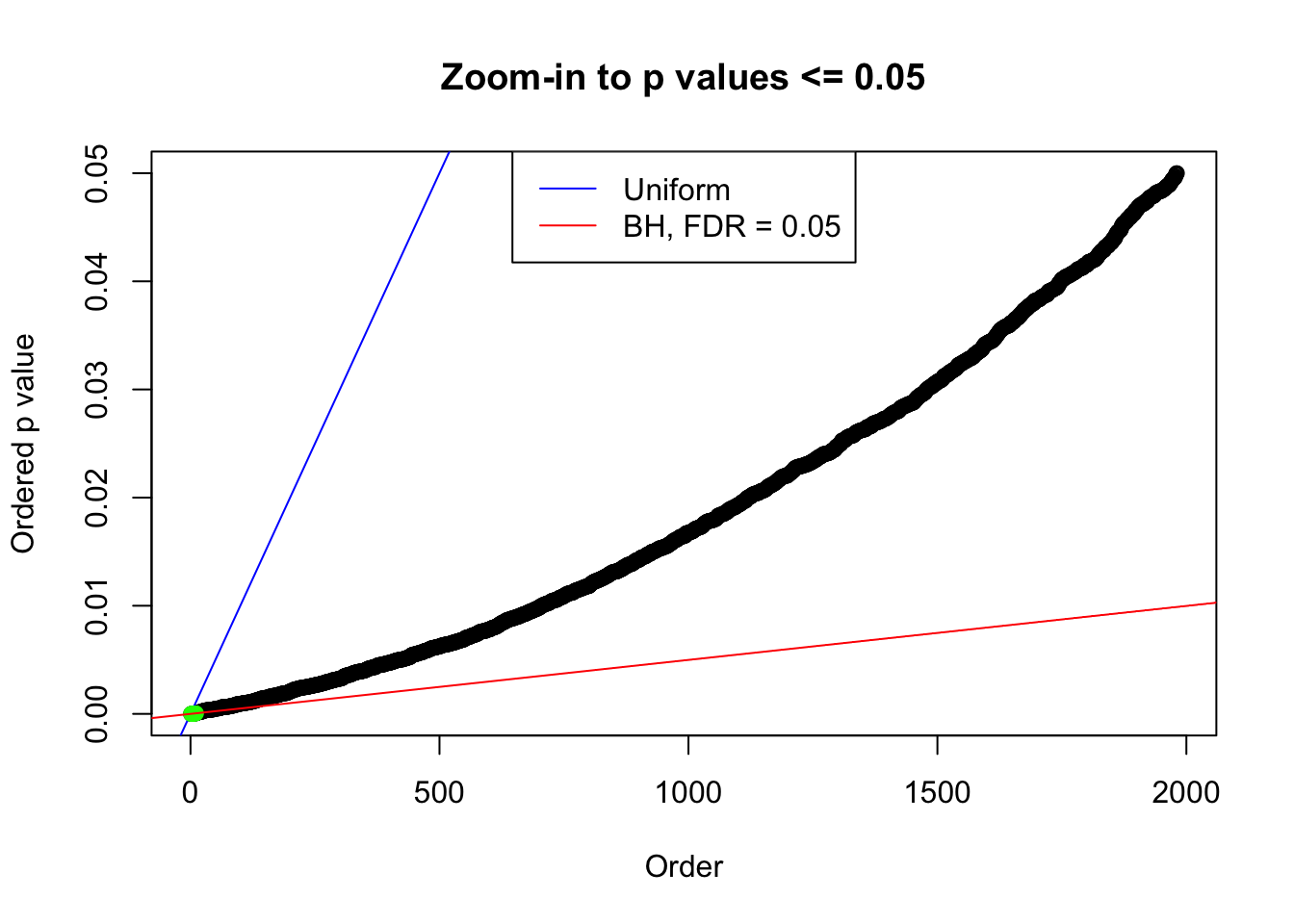
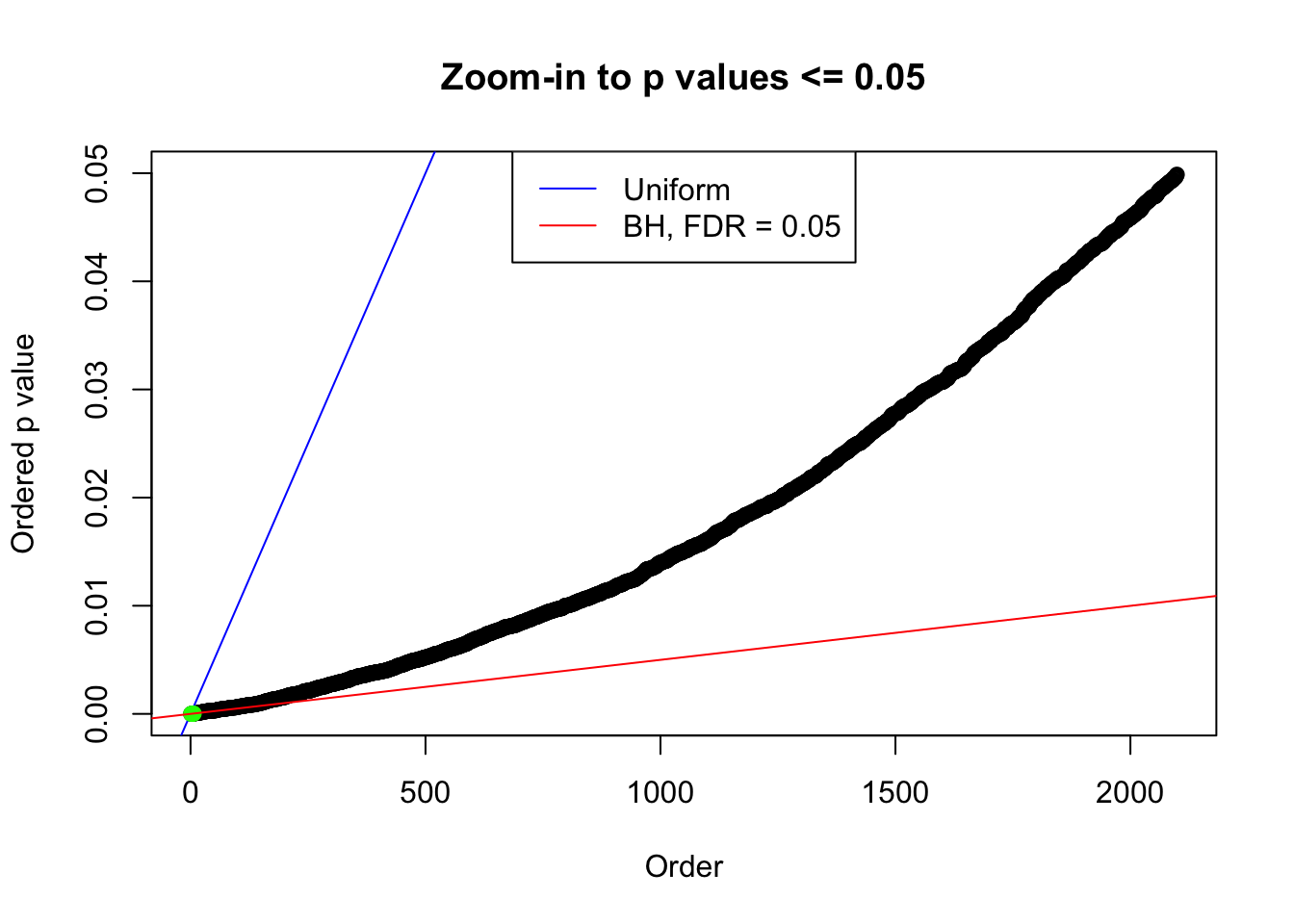
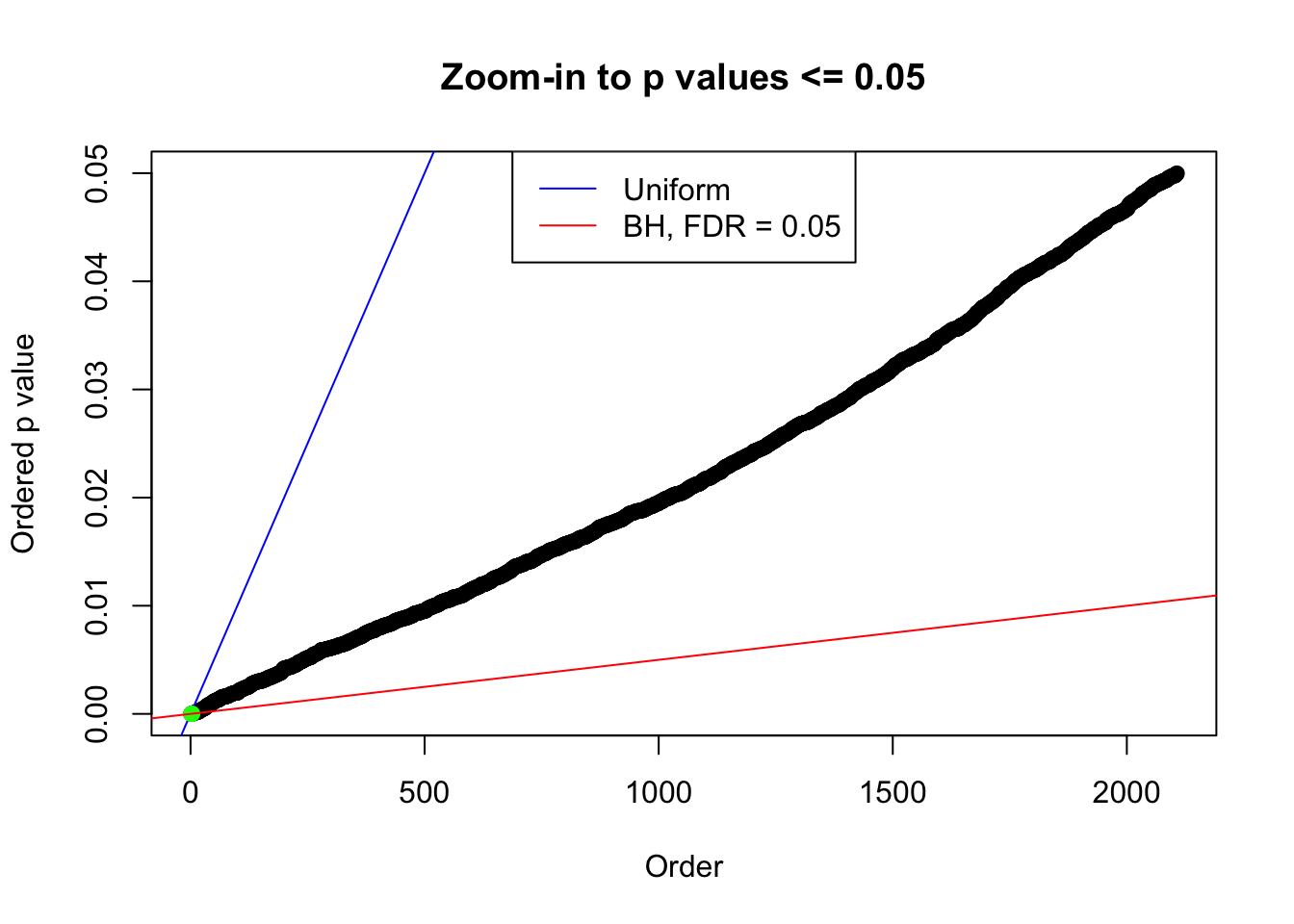
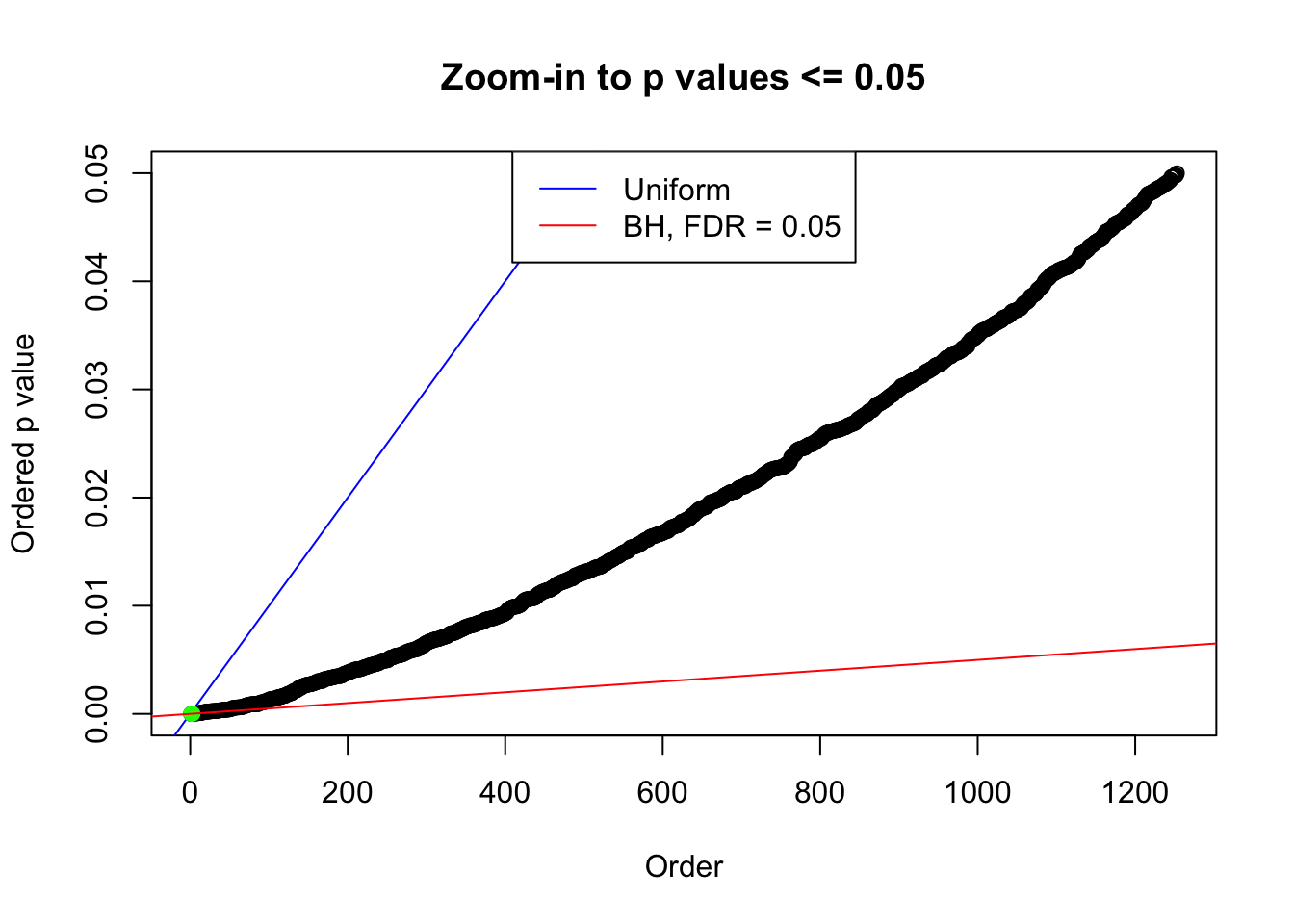
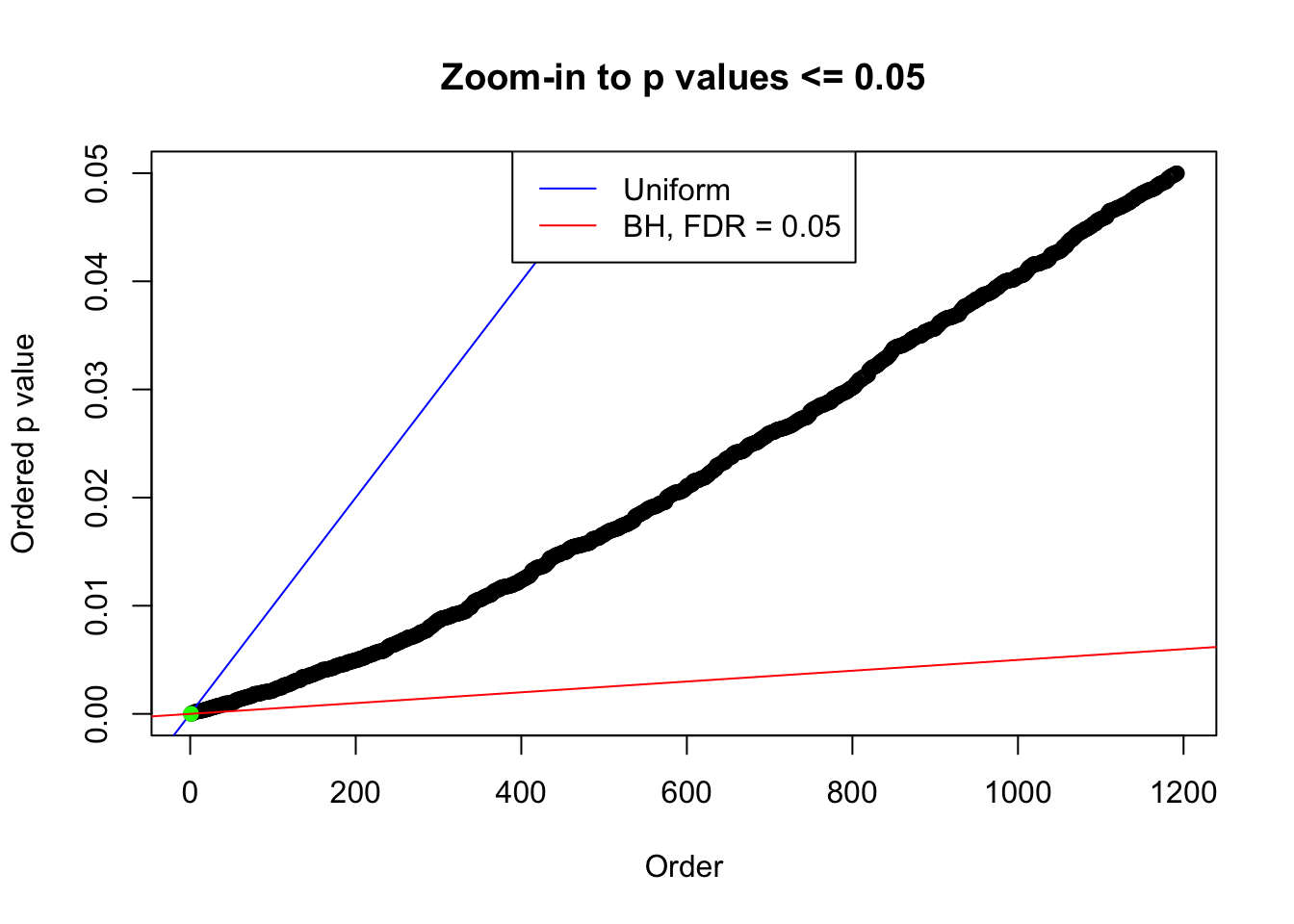
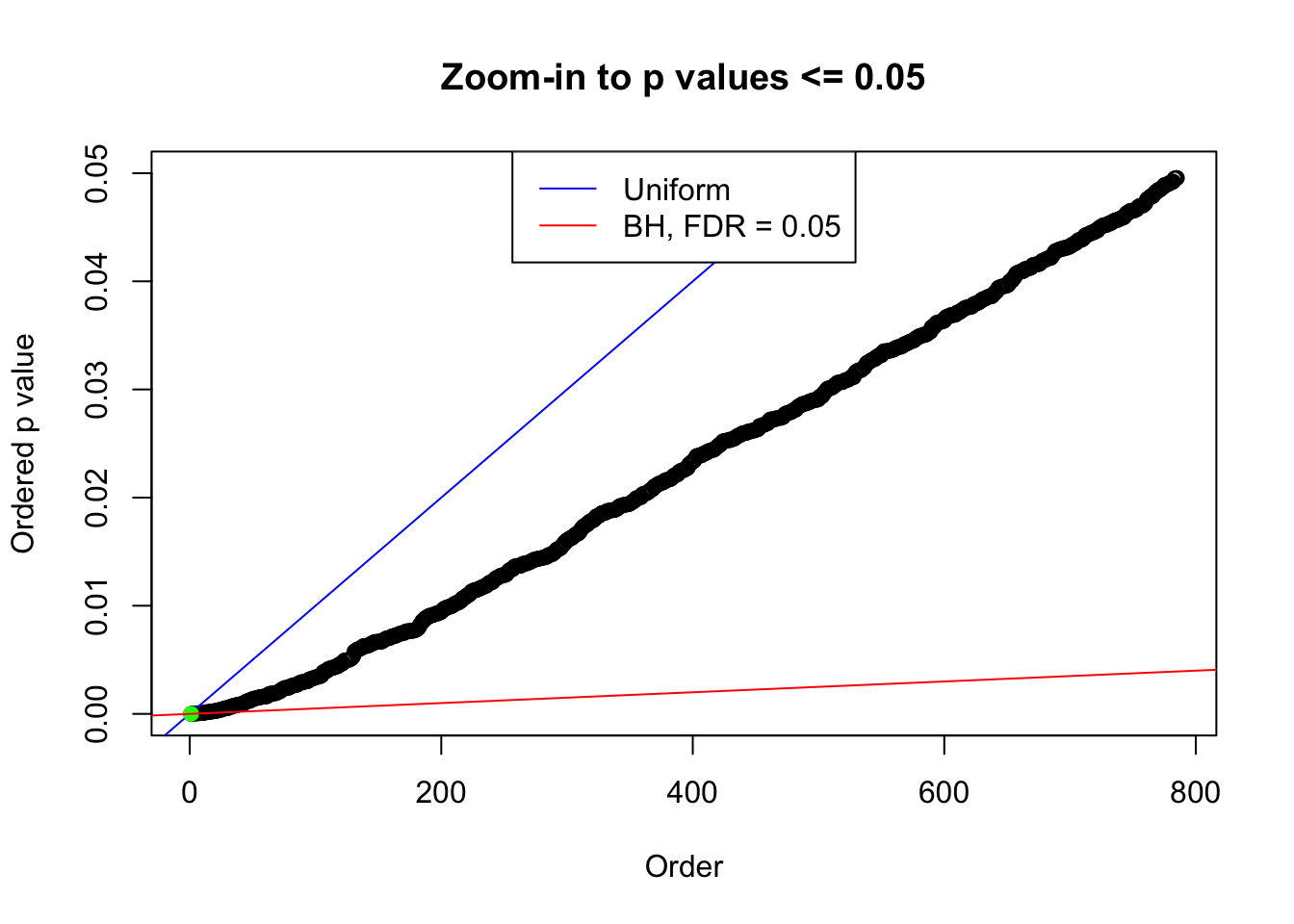
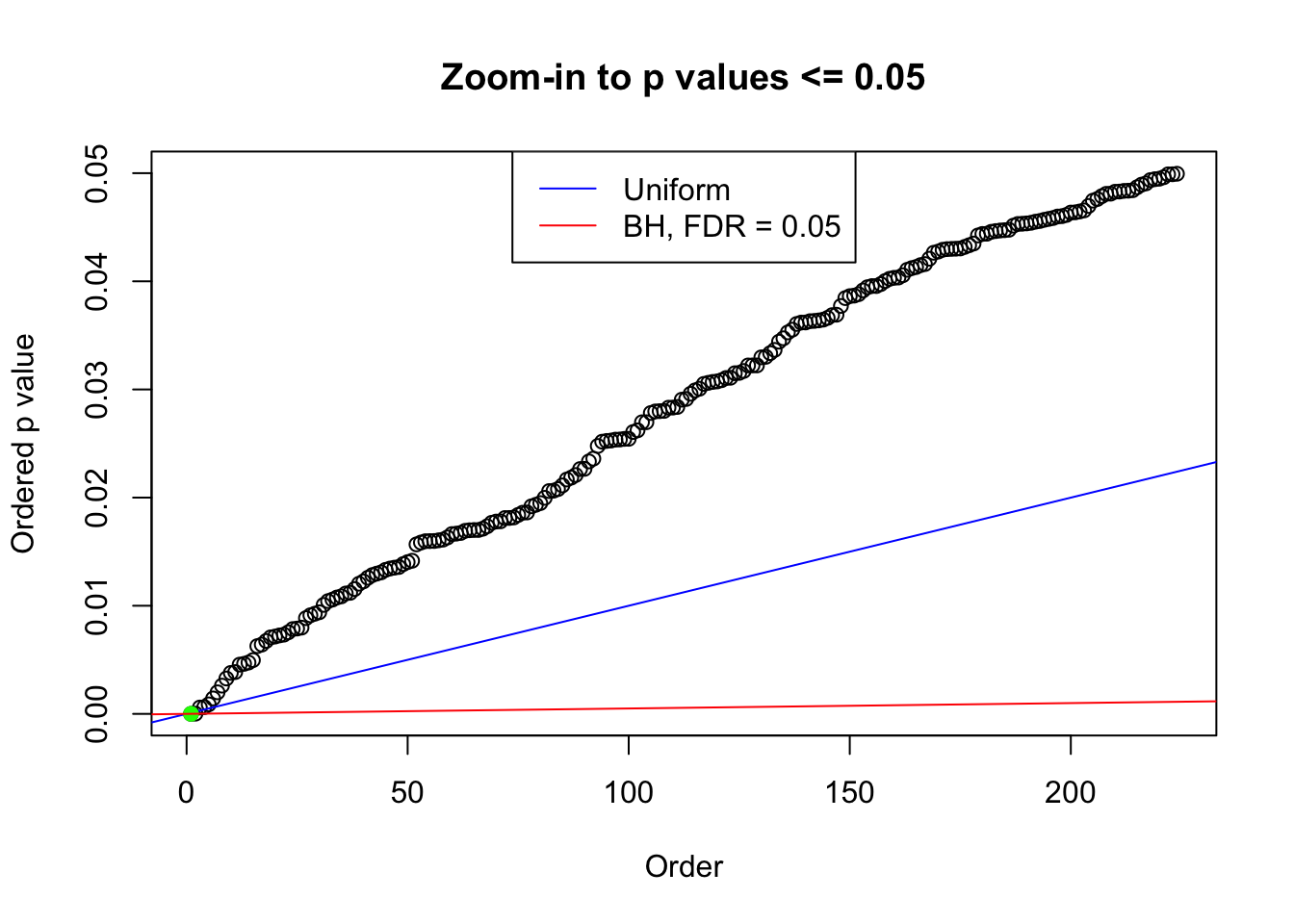
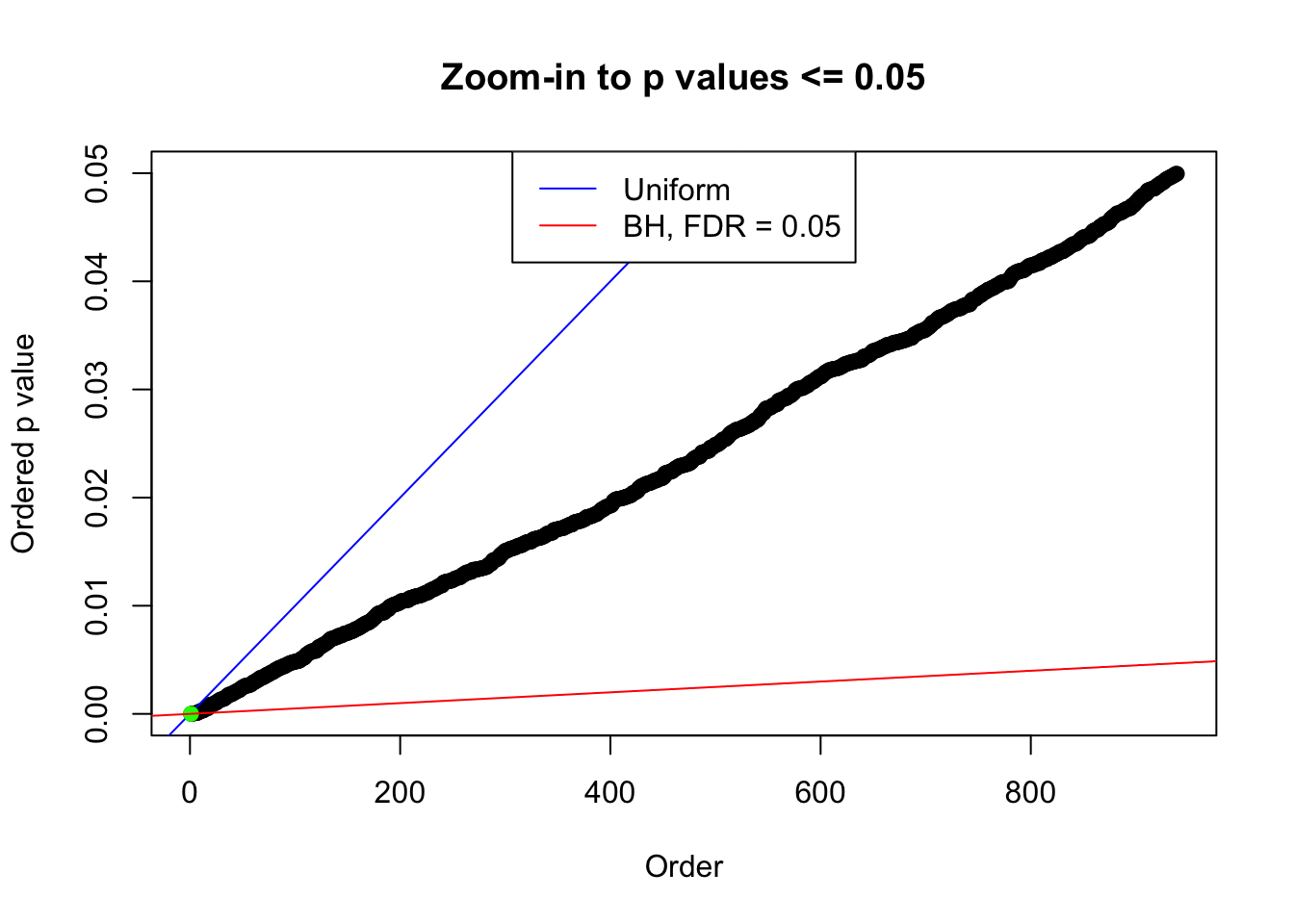
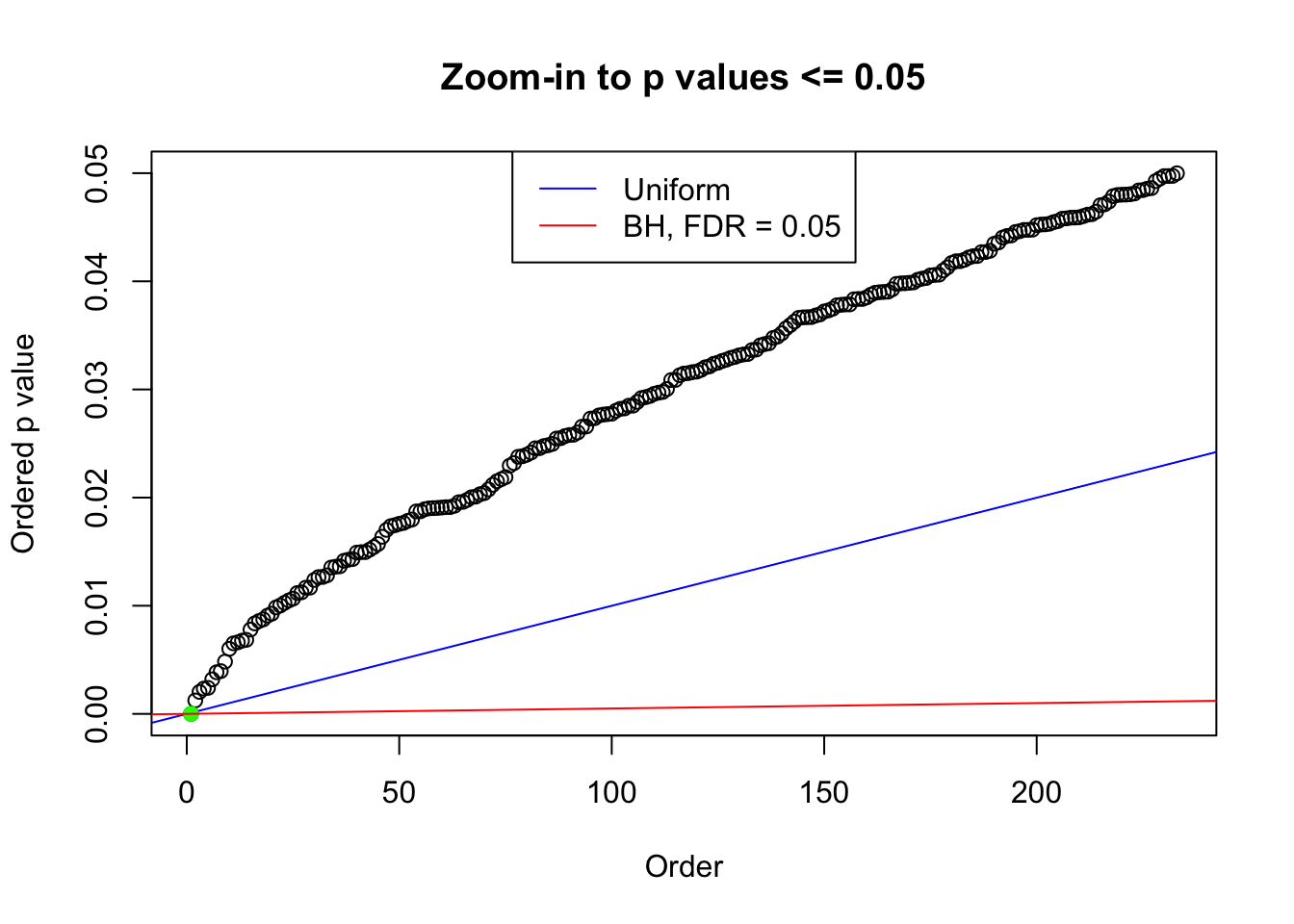
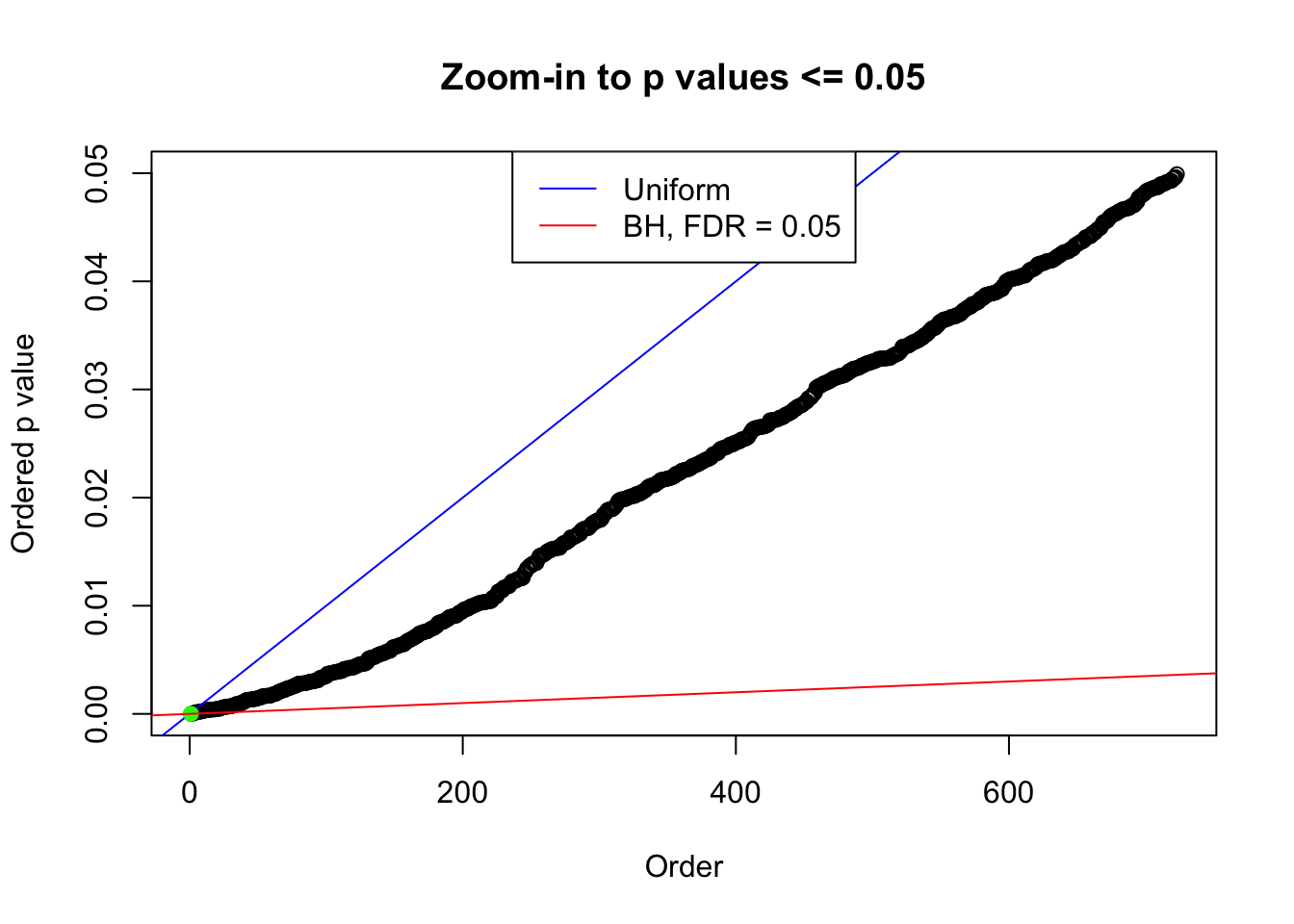
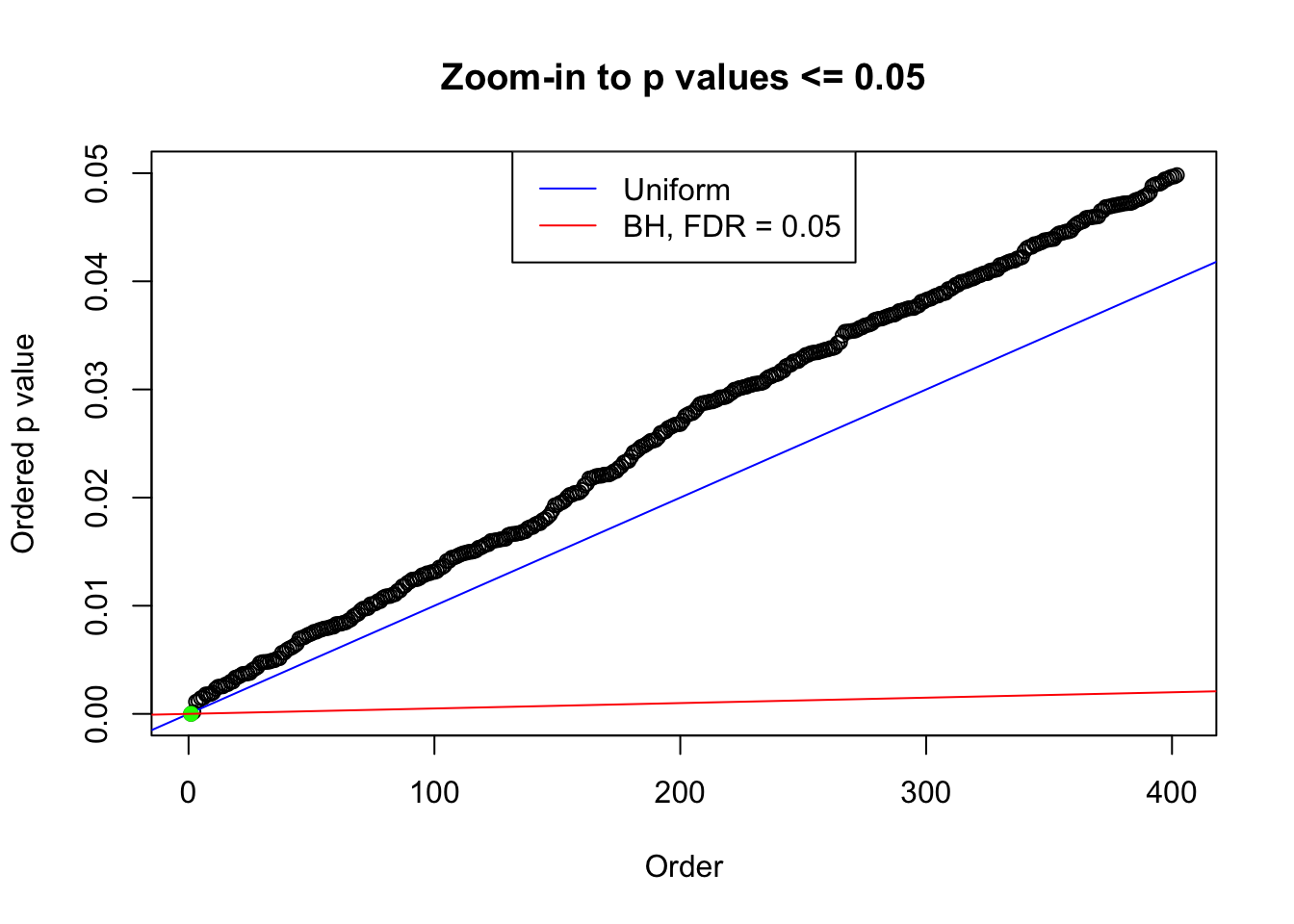
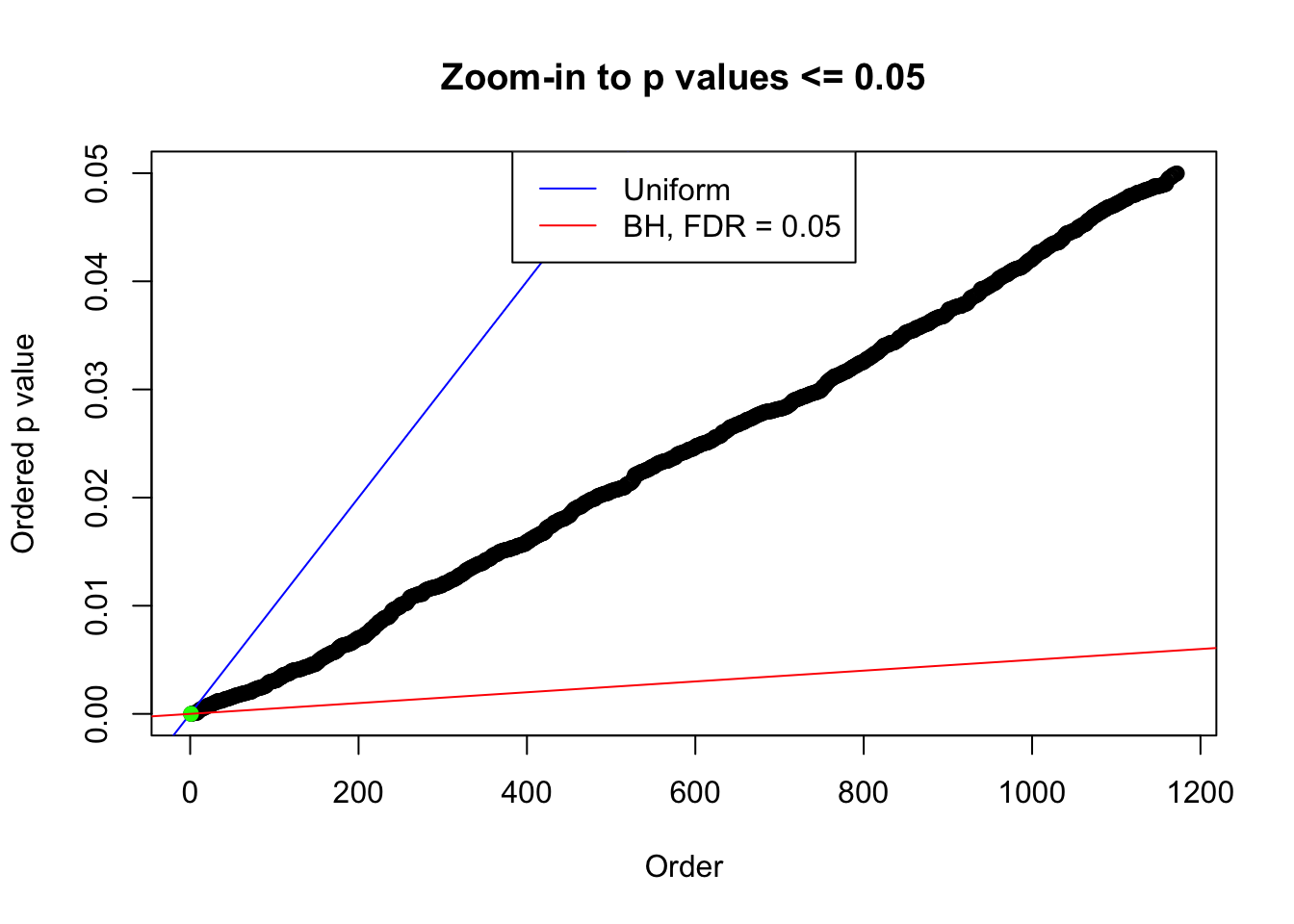
plot(pj[pj <= 0.05], xlab = "Order", ylab = "Ordered p value", main = "Zoom-in to p values <= 0.05", ylim = c(0, 0.05))
abline(0, 1 / m, col = "blue")
points(pj[1:fd.bh[j]], col = "green", pch = 19)
abline(0, 0.05 / m, col = "red")
legend("top", lty = 1, col = c("blue", "red"), c("Uniform", "BH, FDR = 0.05"))
k = k + 1
}N0. 1 : Data Set 355 ; Number of False Discoveries: 639 ; pihat0 = 0.04750946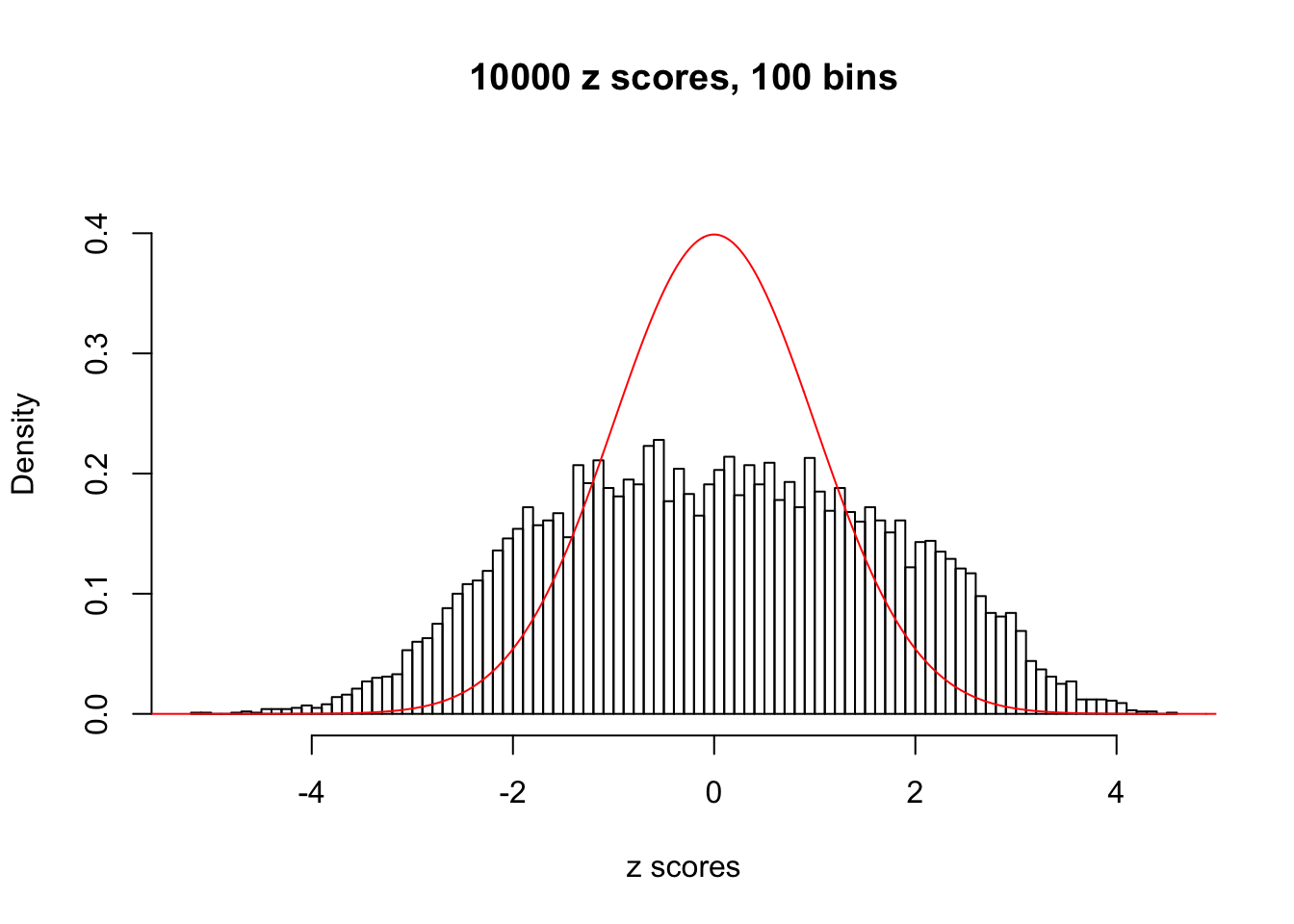
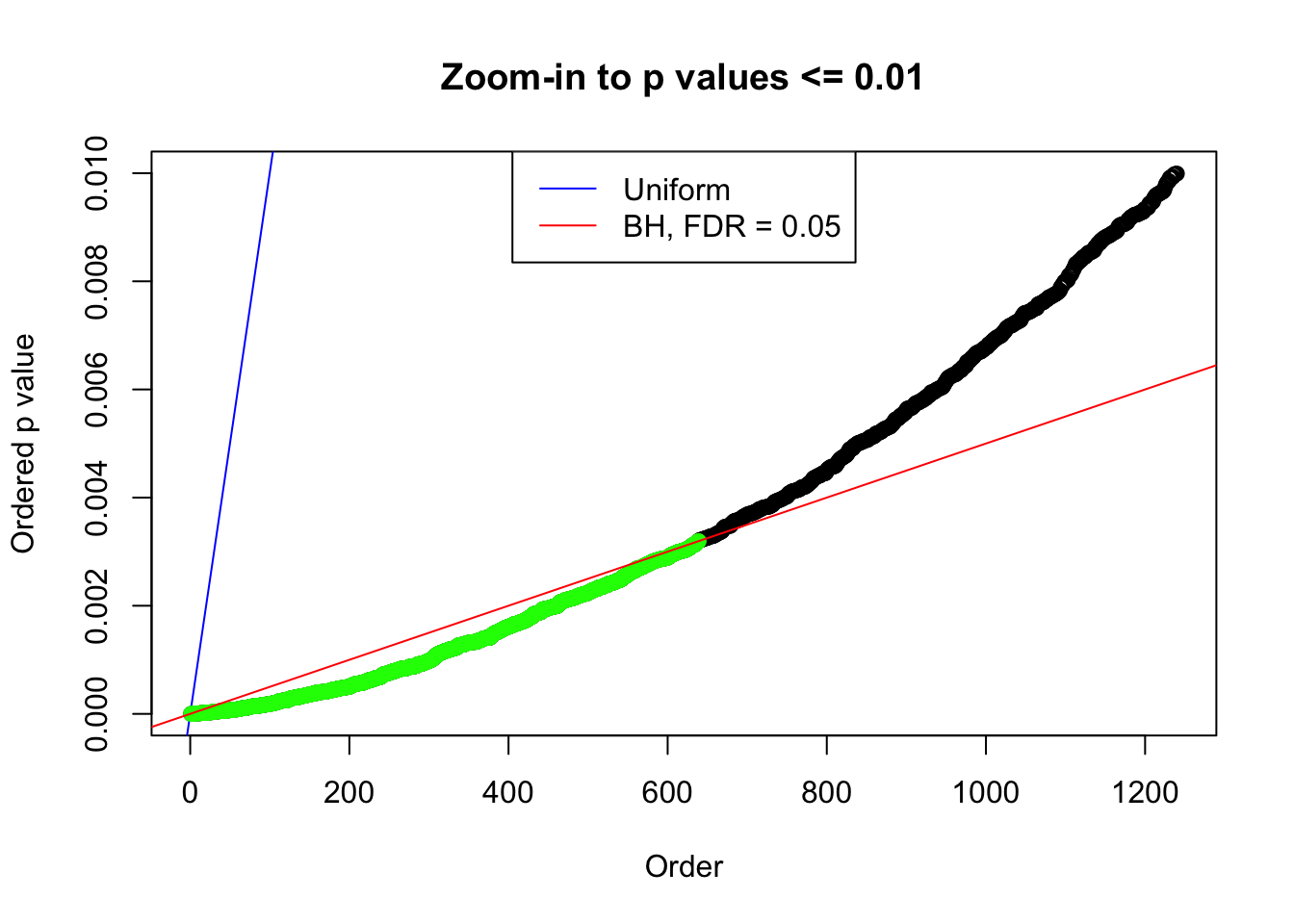
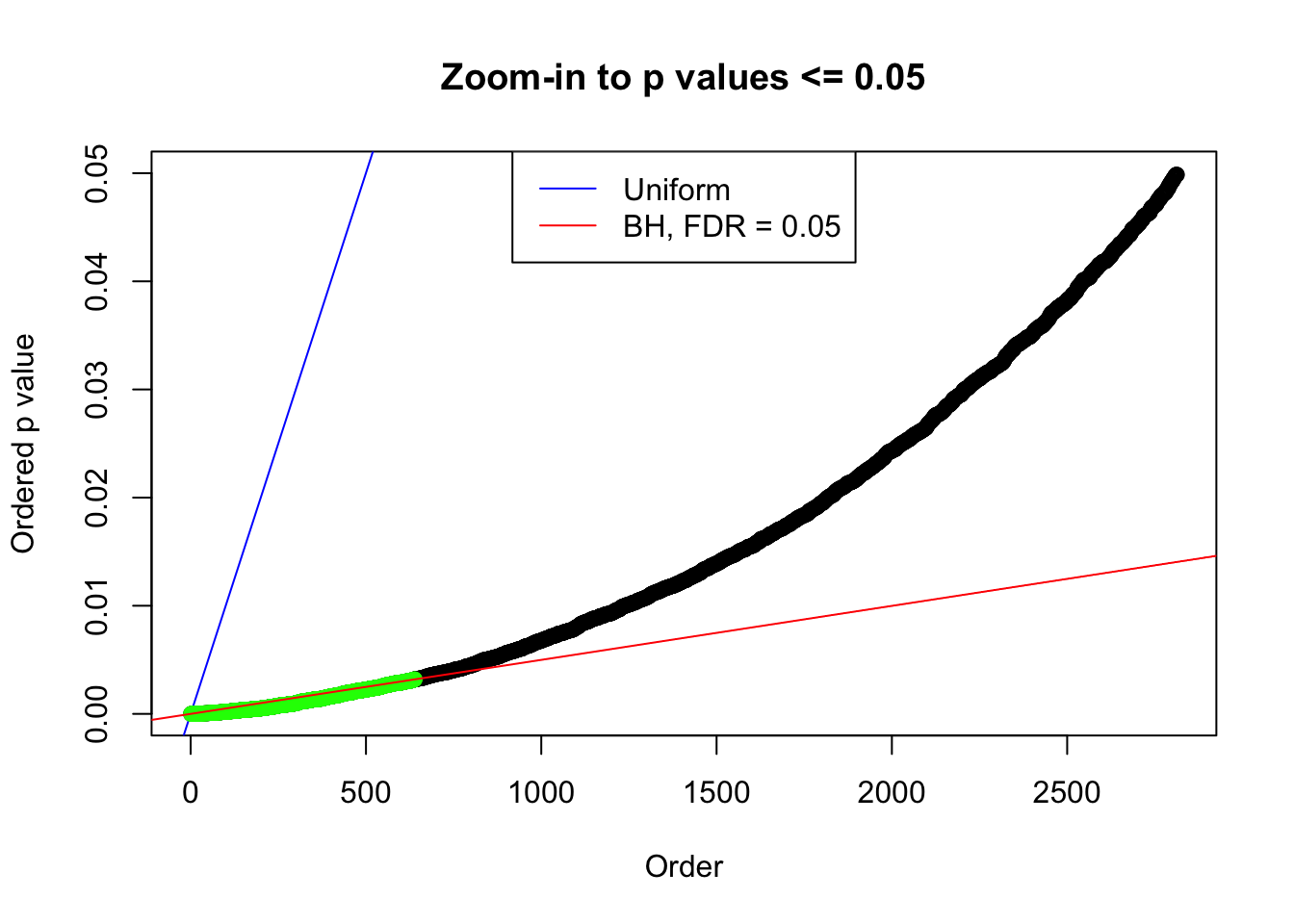
N0. 2 : Data Set 327 ; Number of False Discoveries: 489 ; pihat0 = 0.1522796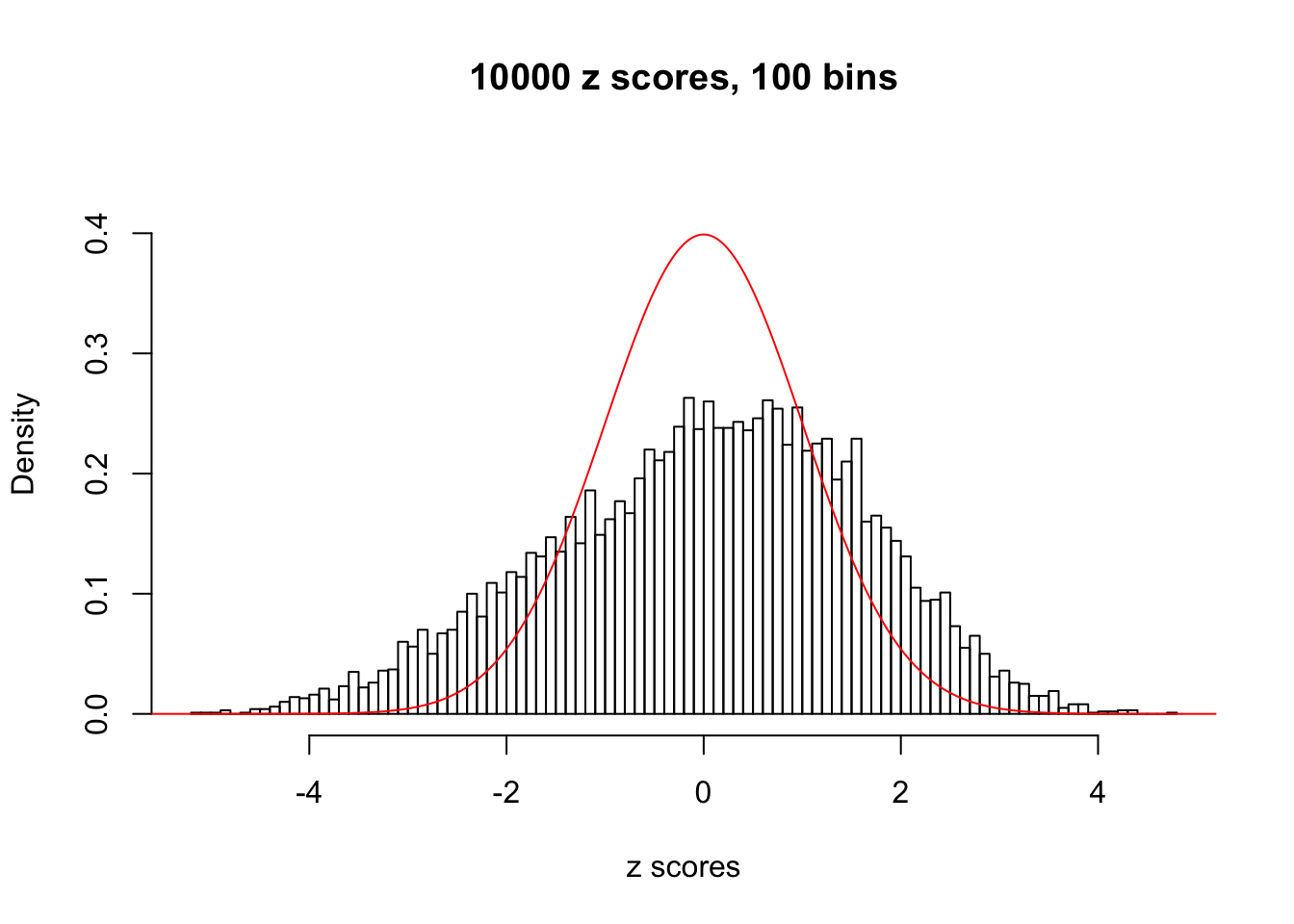
N0. 3 : Data Set 23 ; Number of False Discoveries: 408 ; pihat0 = 0.03139009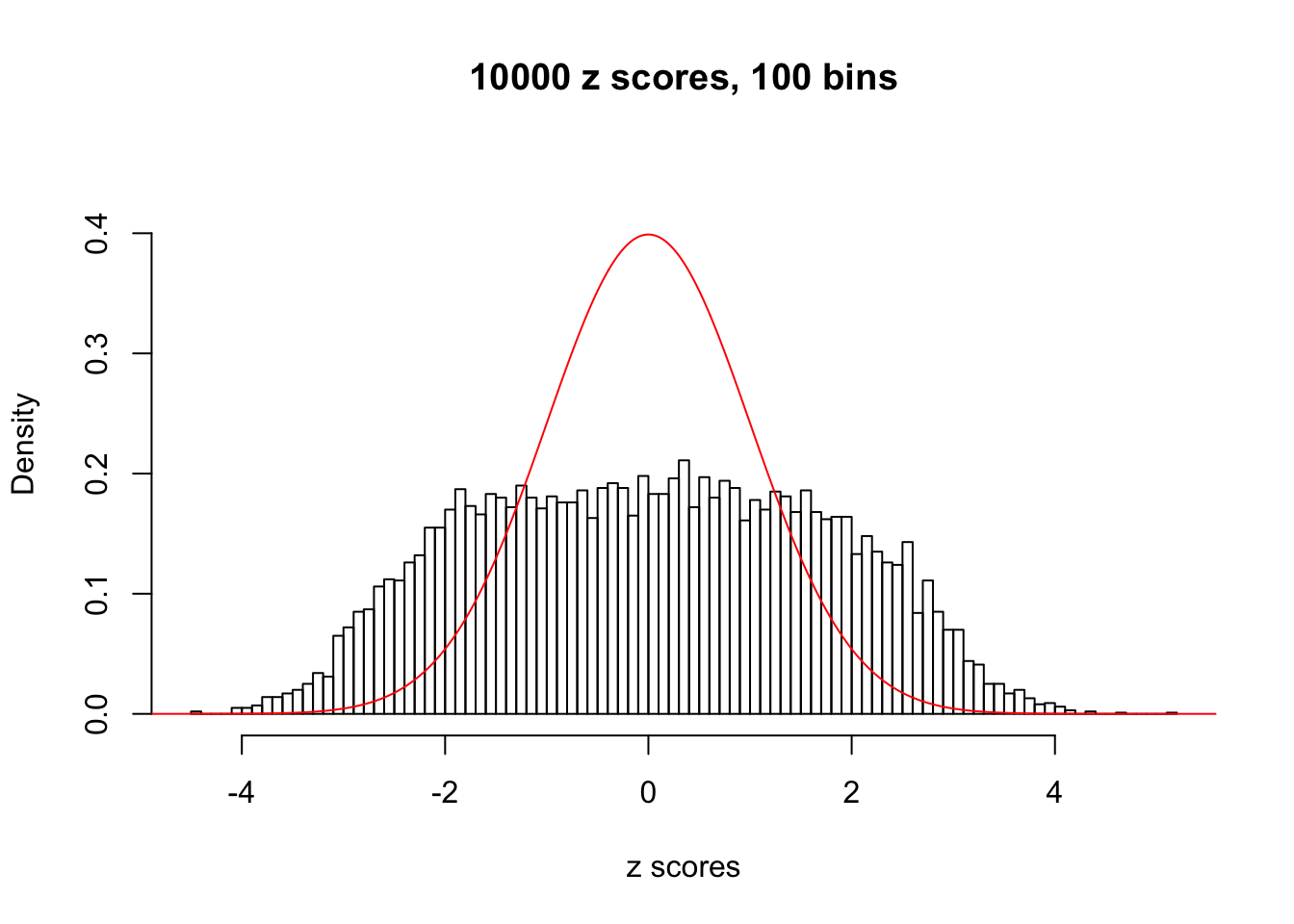
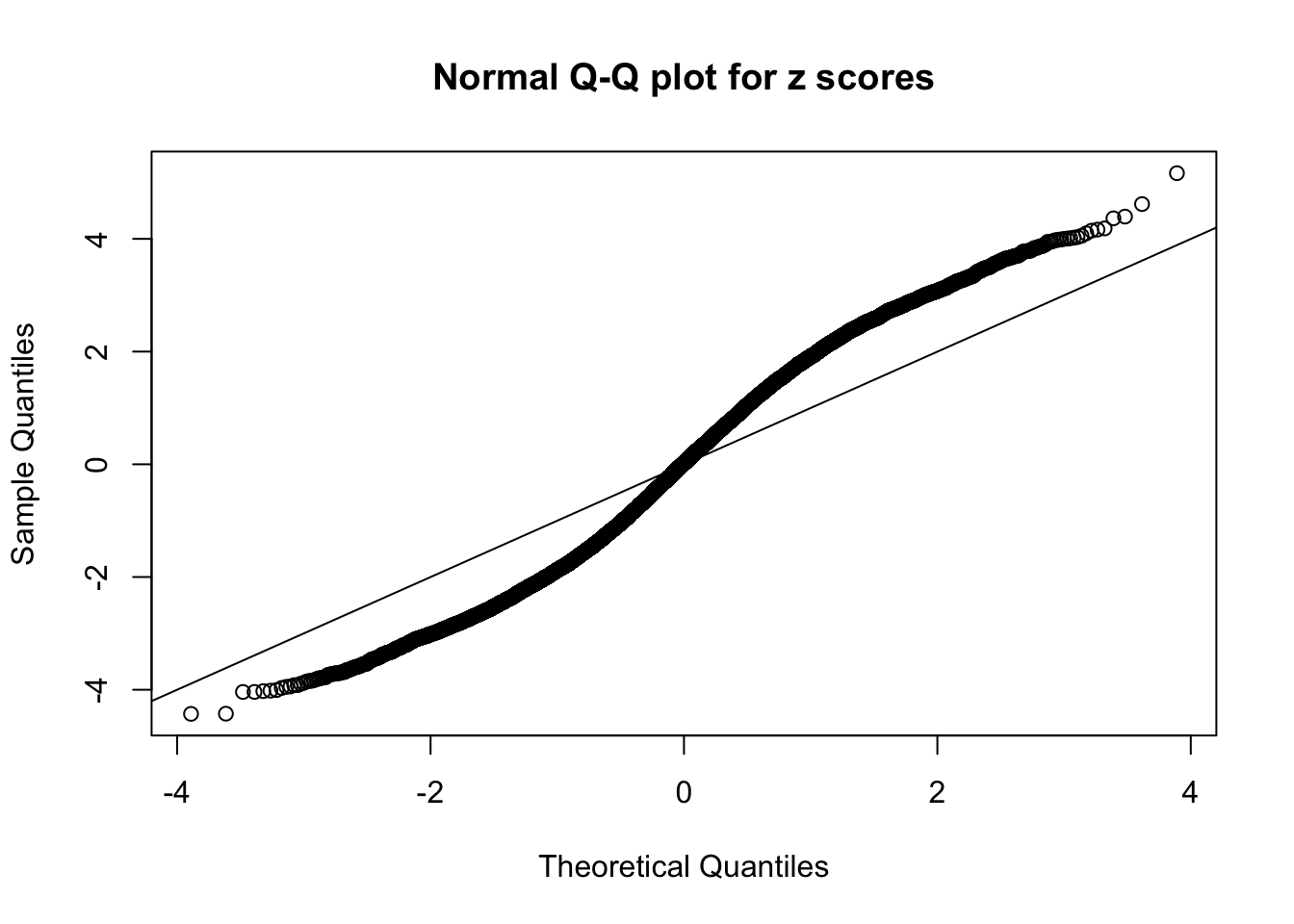
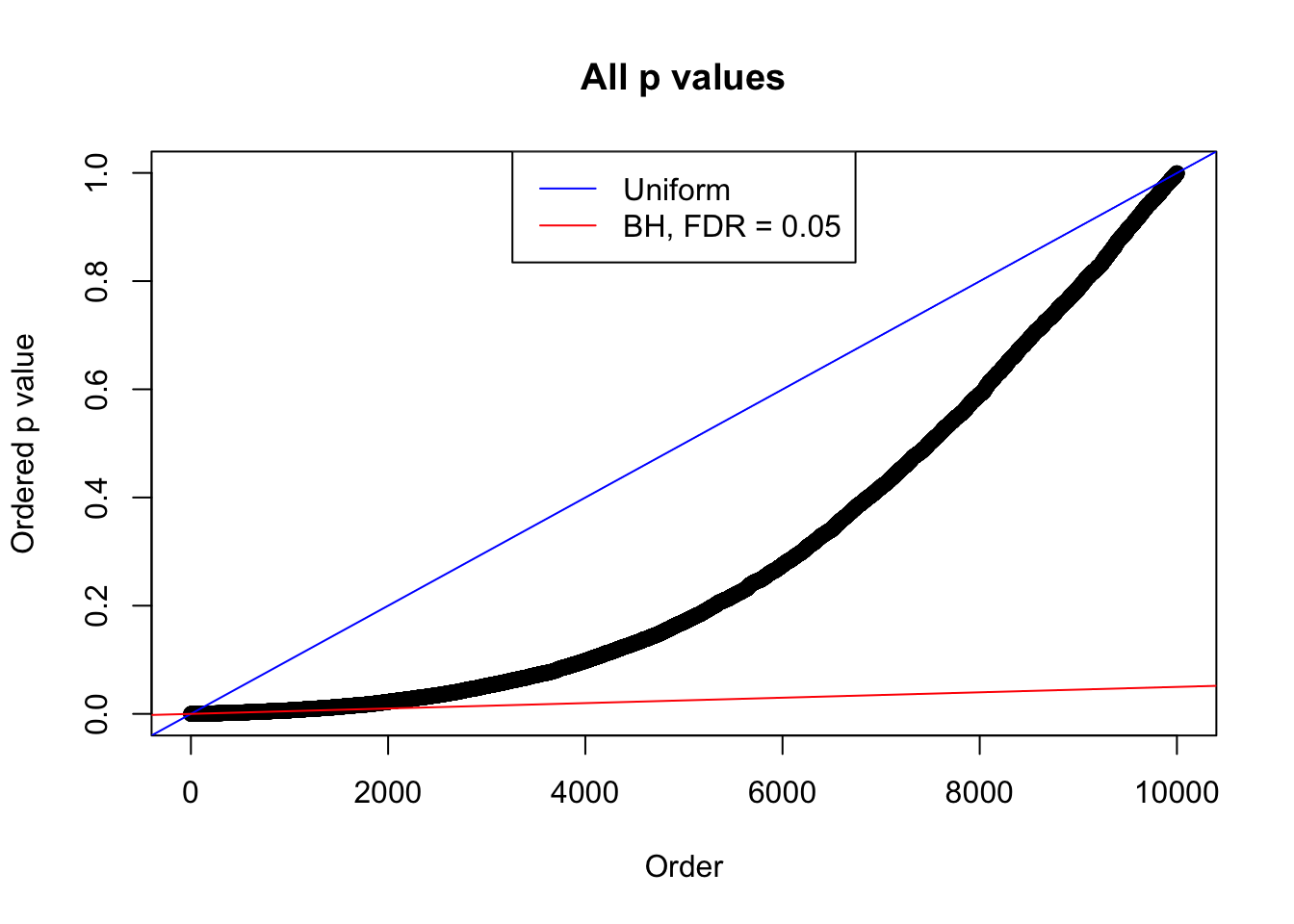
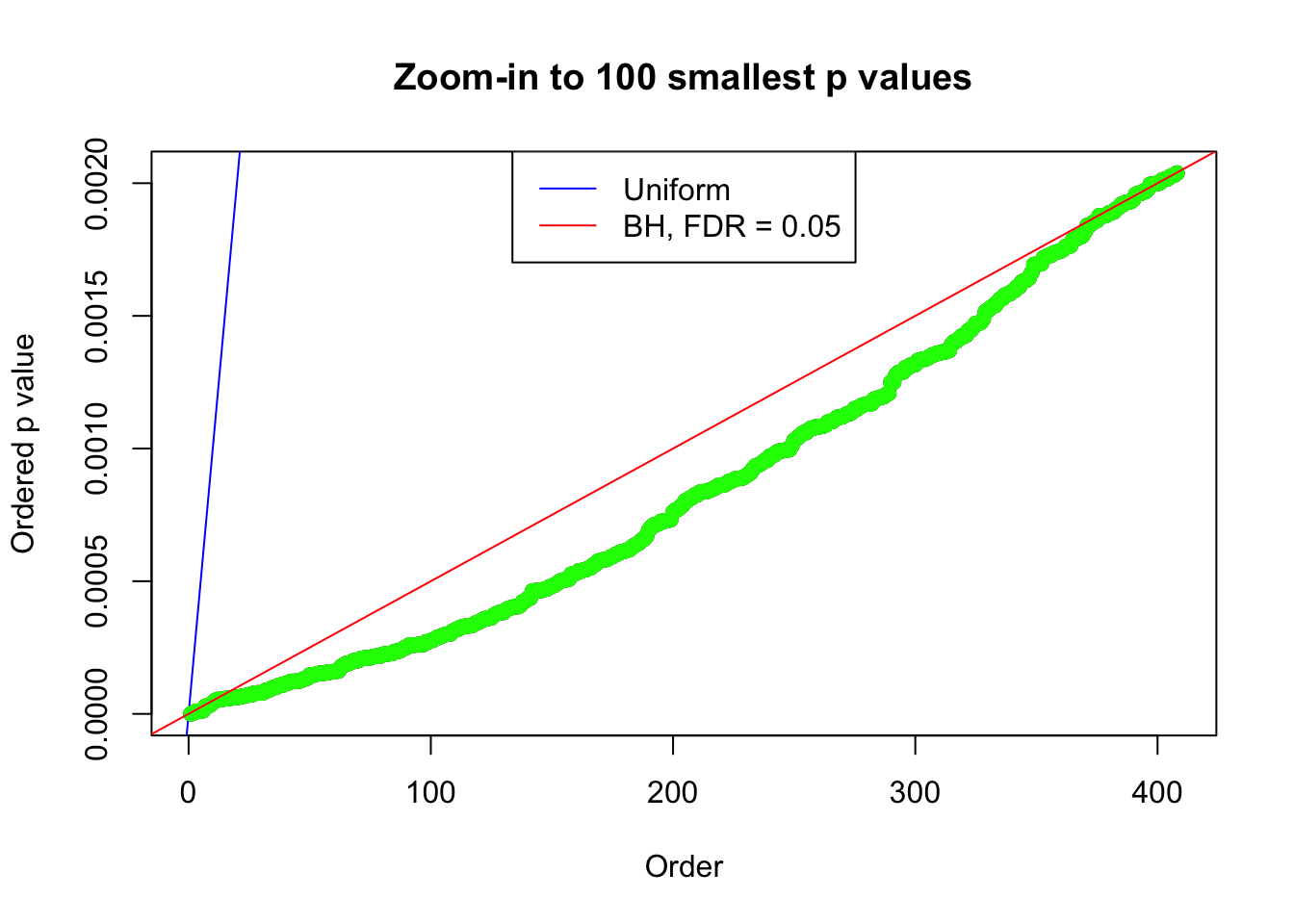
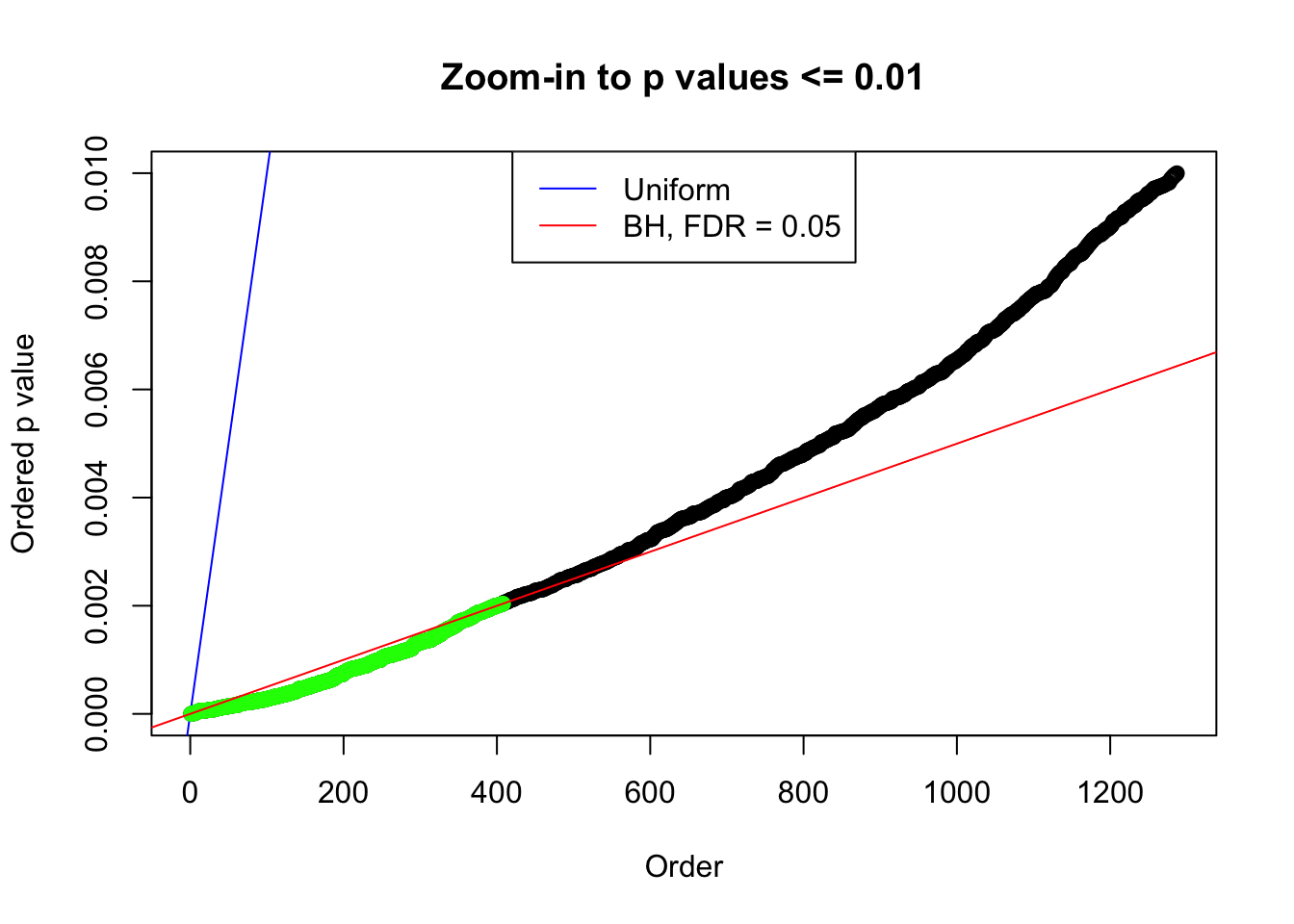
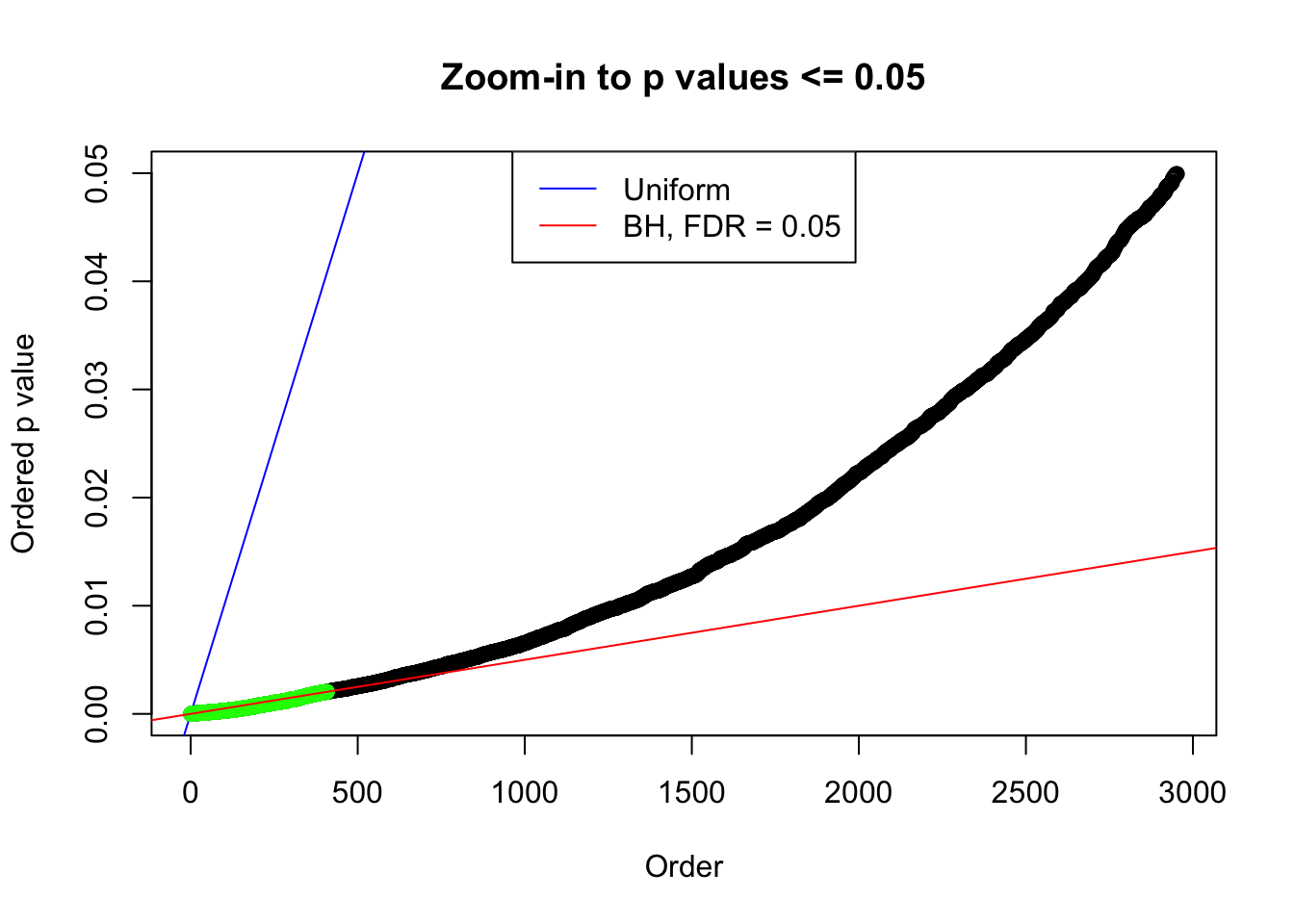
N0. 4 : Data Set 122 ; Number of False Discoveries: 331 ; pihat0 = 0.04301549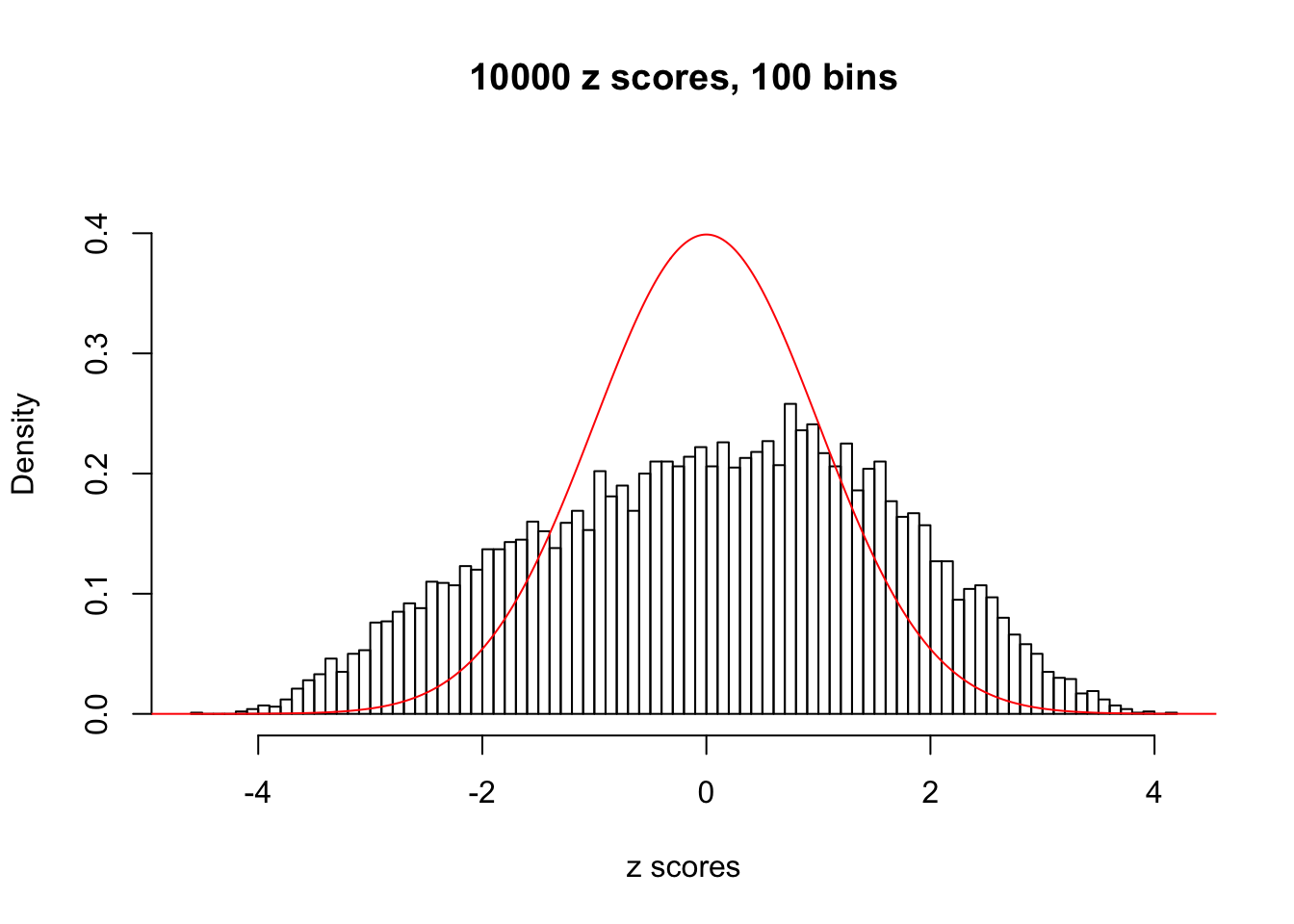
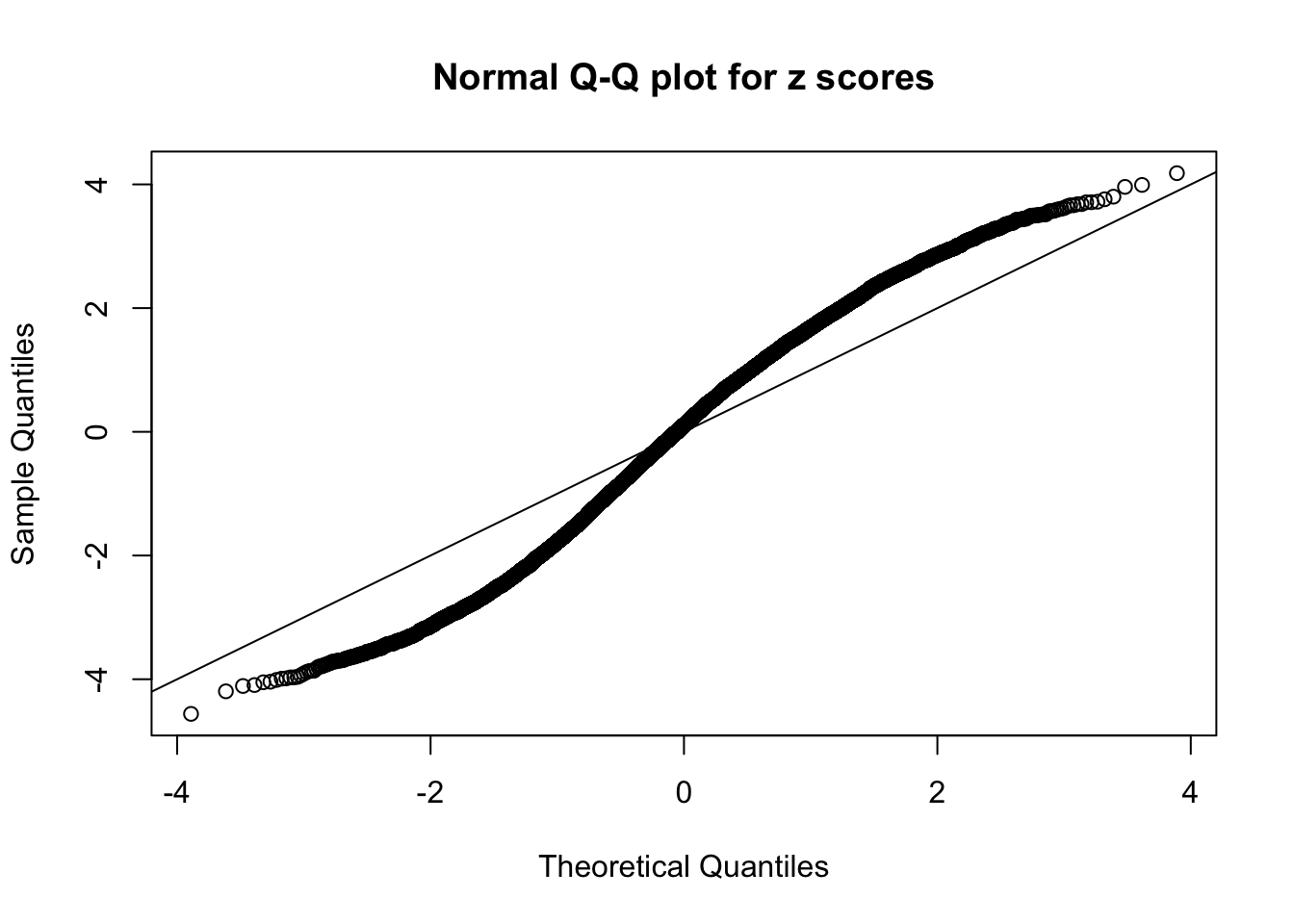
N0. 5 : Data Set 783 ; Number of False Discoveries: 170 ; pihat0 = 0.06208376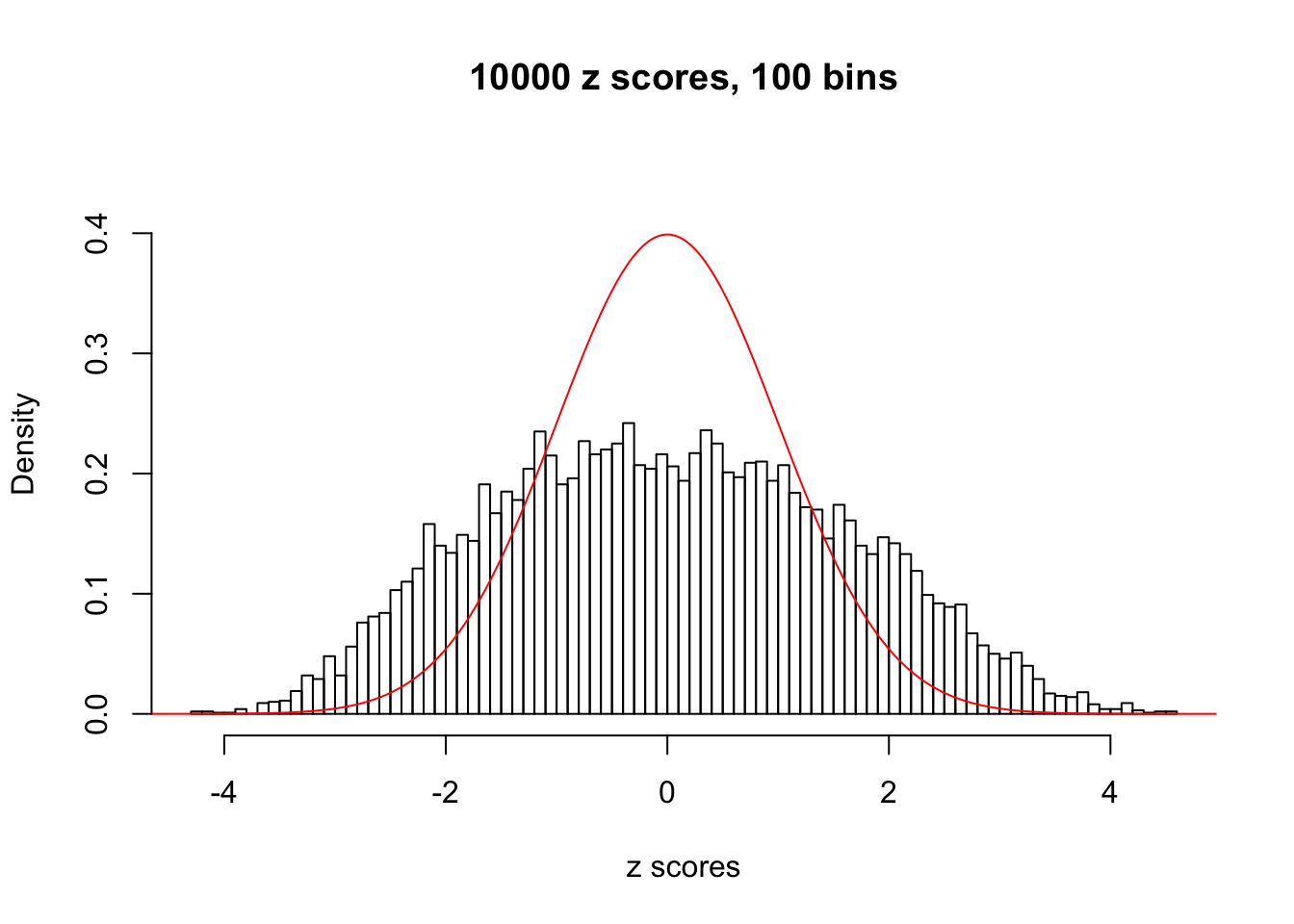
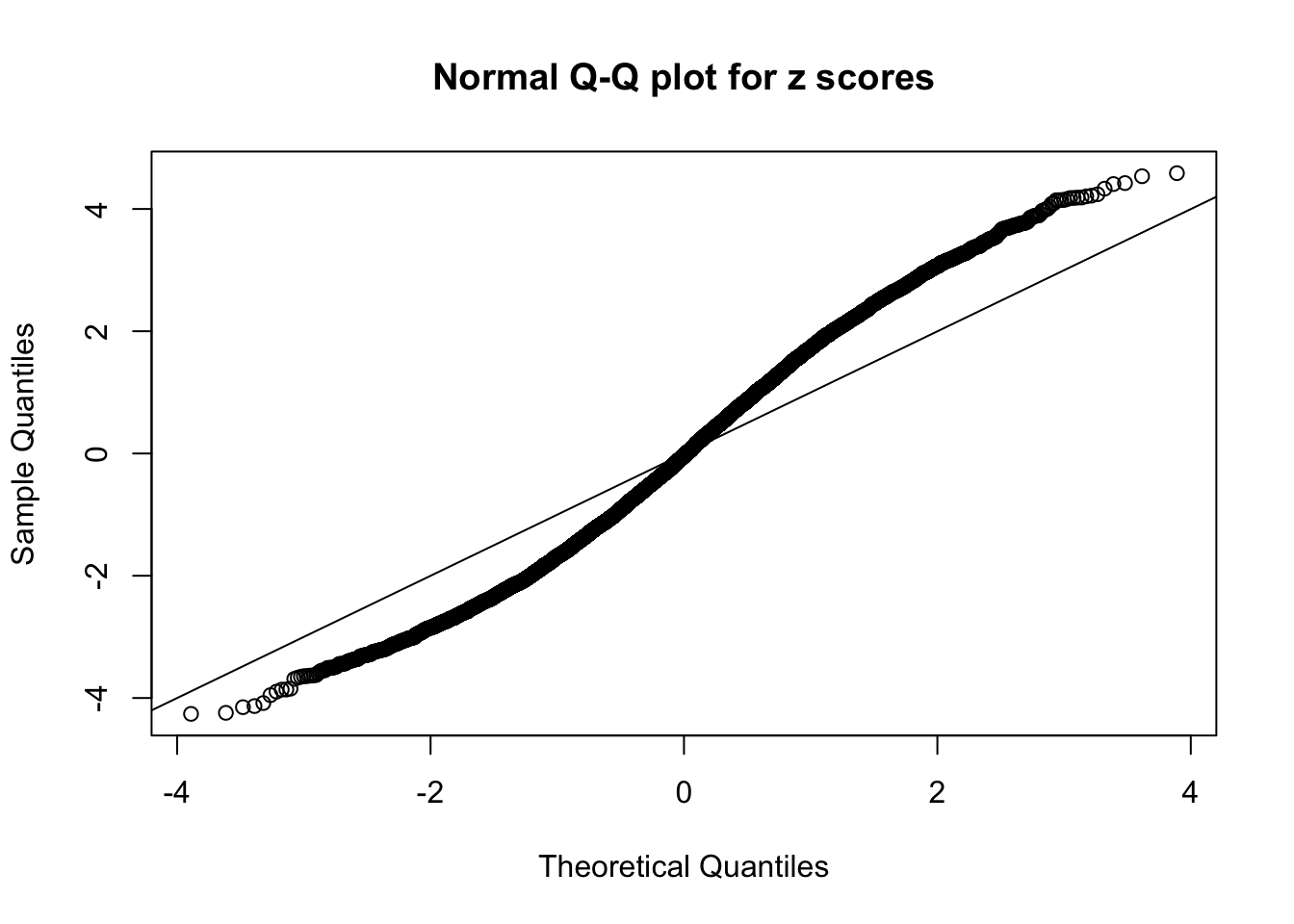
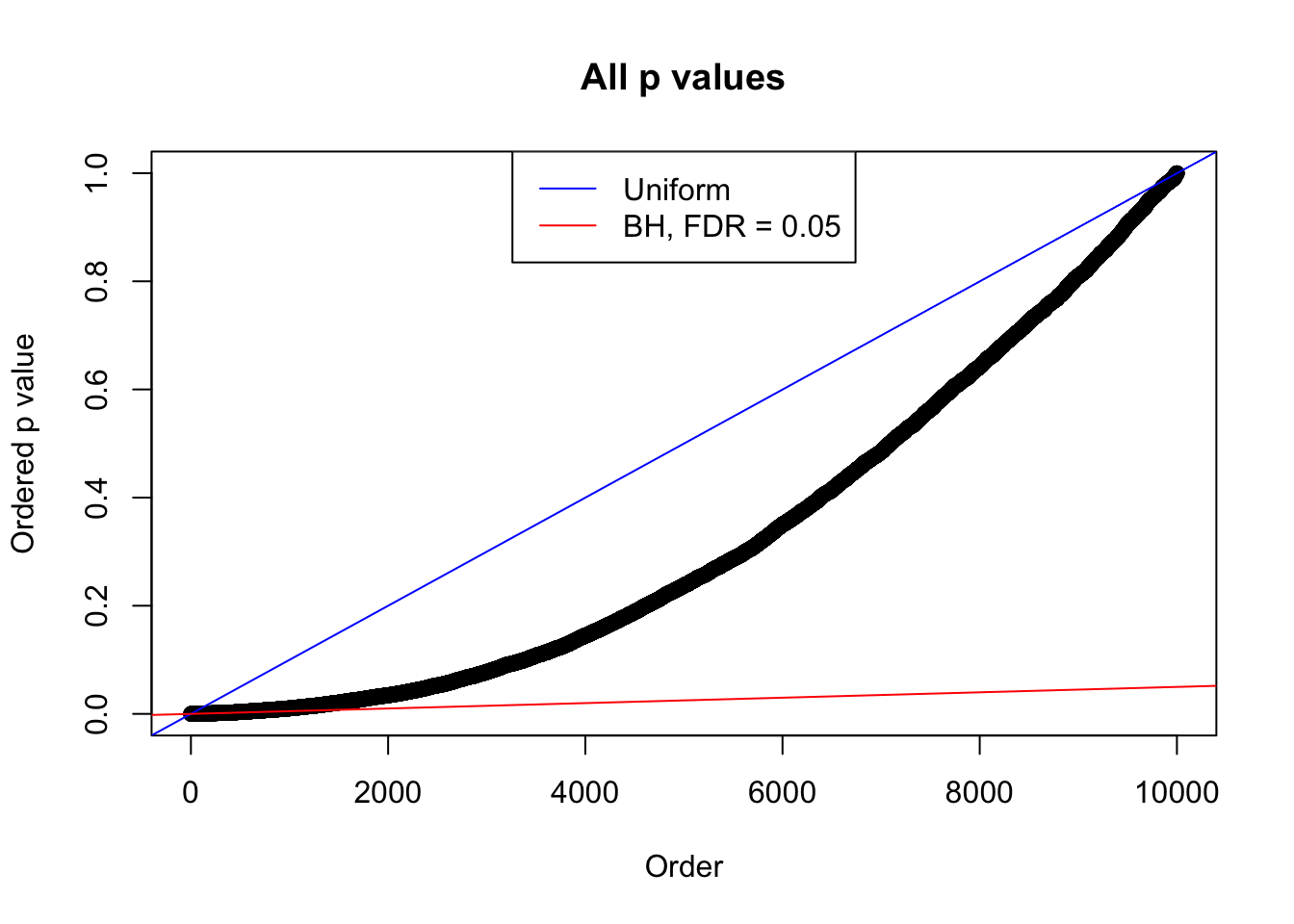
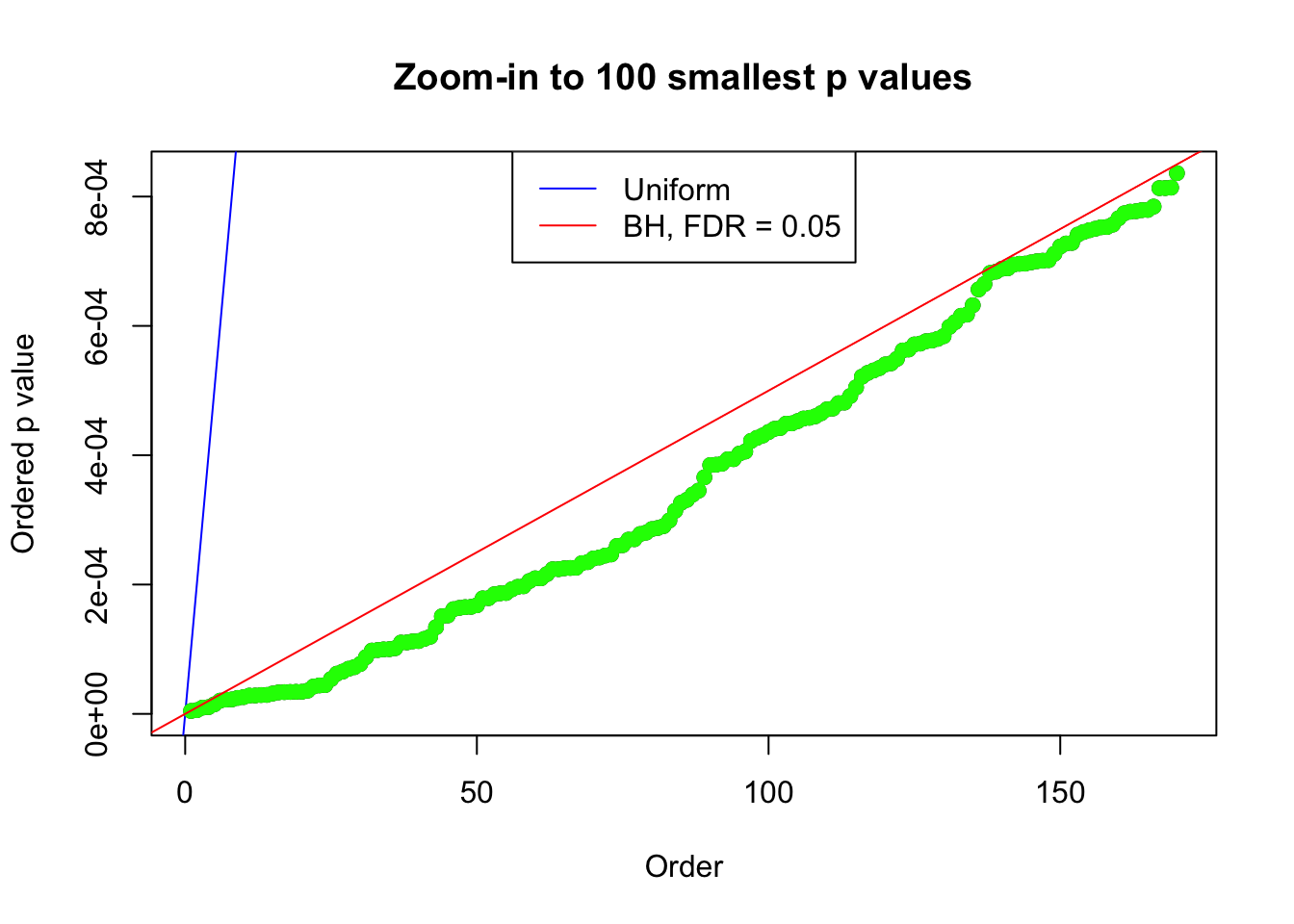
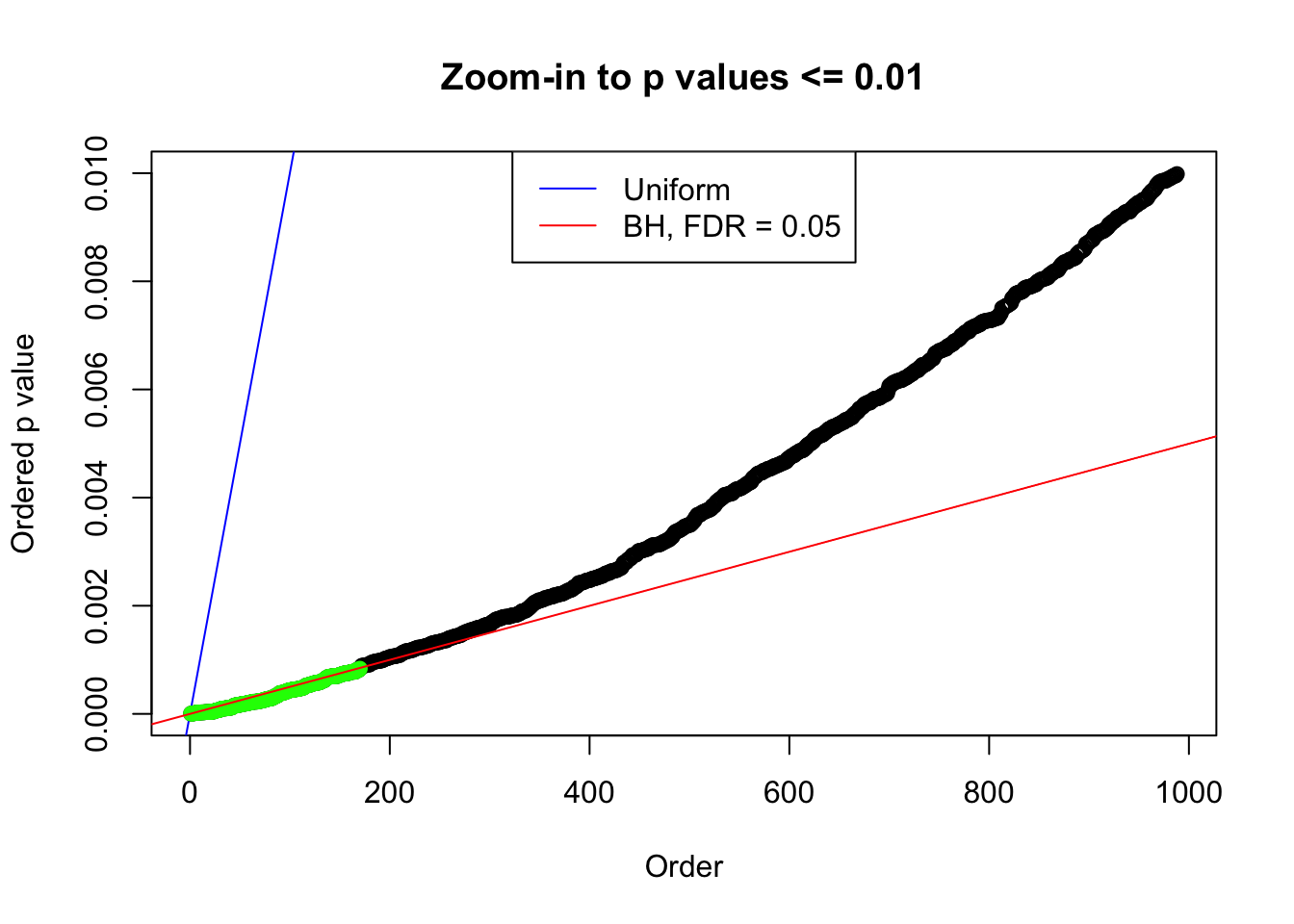
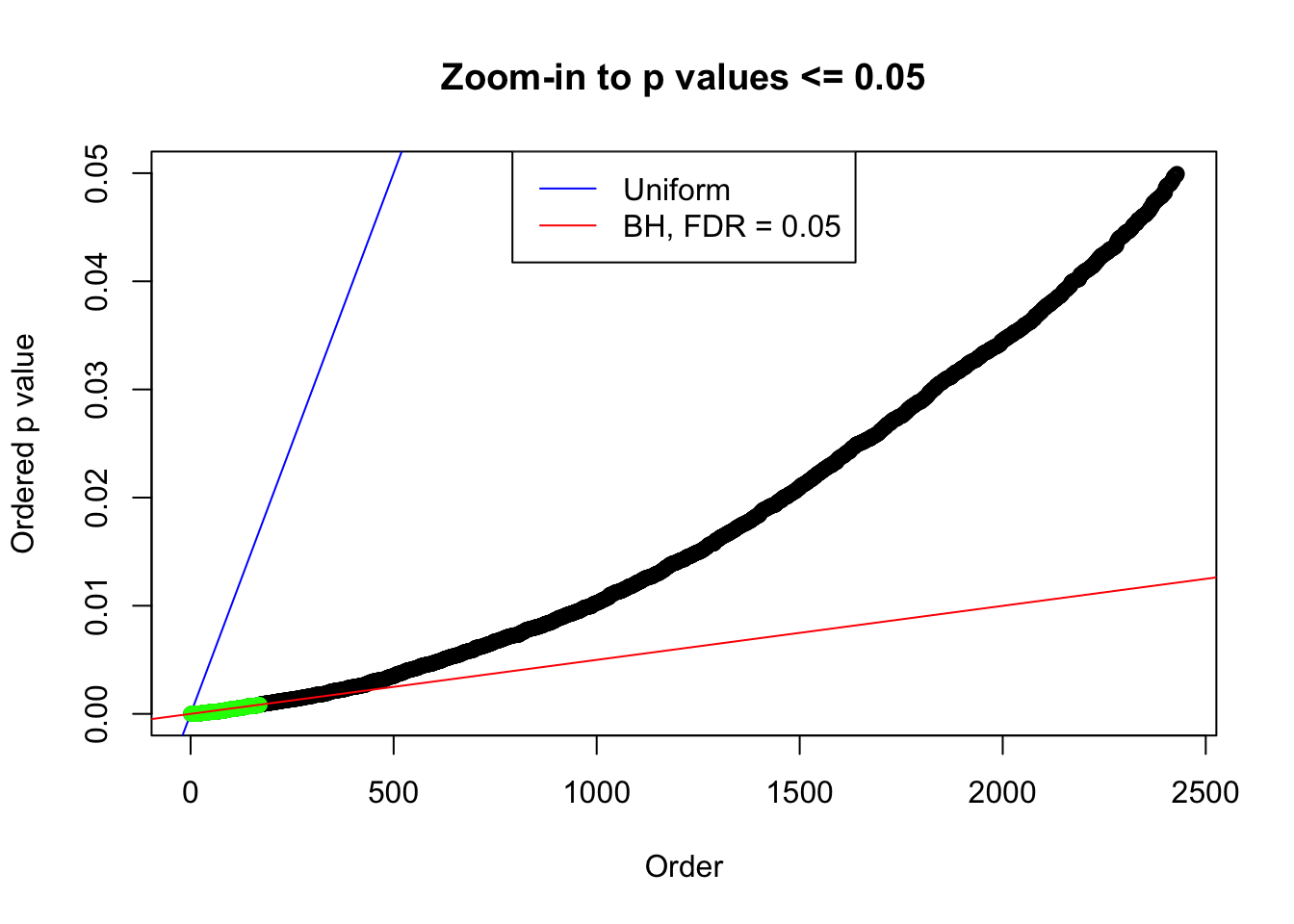
N0. 6 : Data Set 749 ; Number of False Discoveries: 114 ; pihat0 = 0.02583276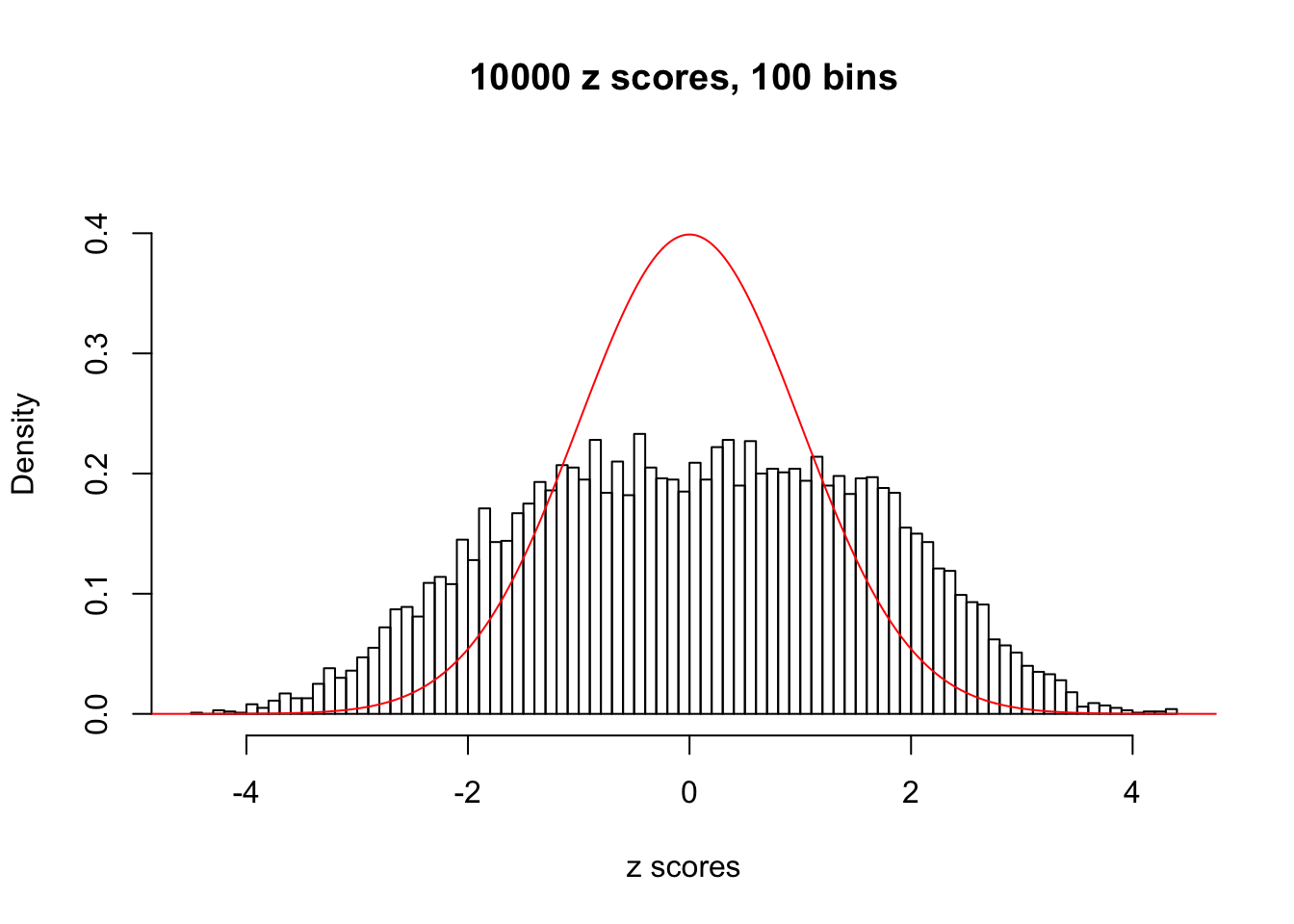
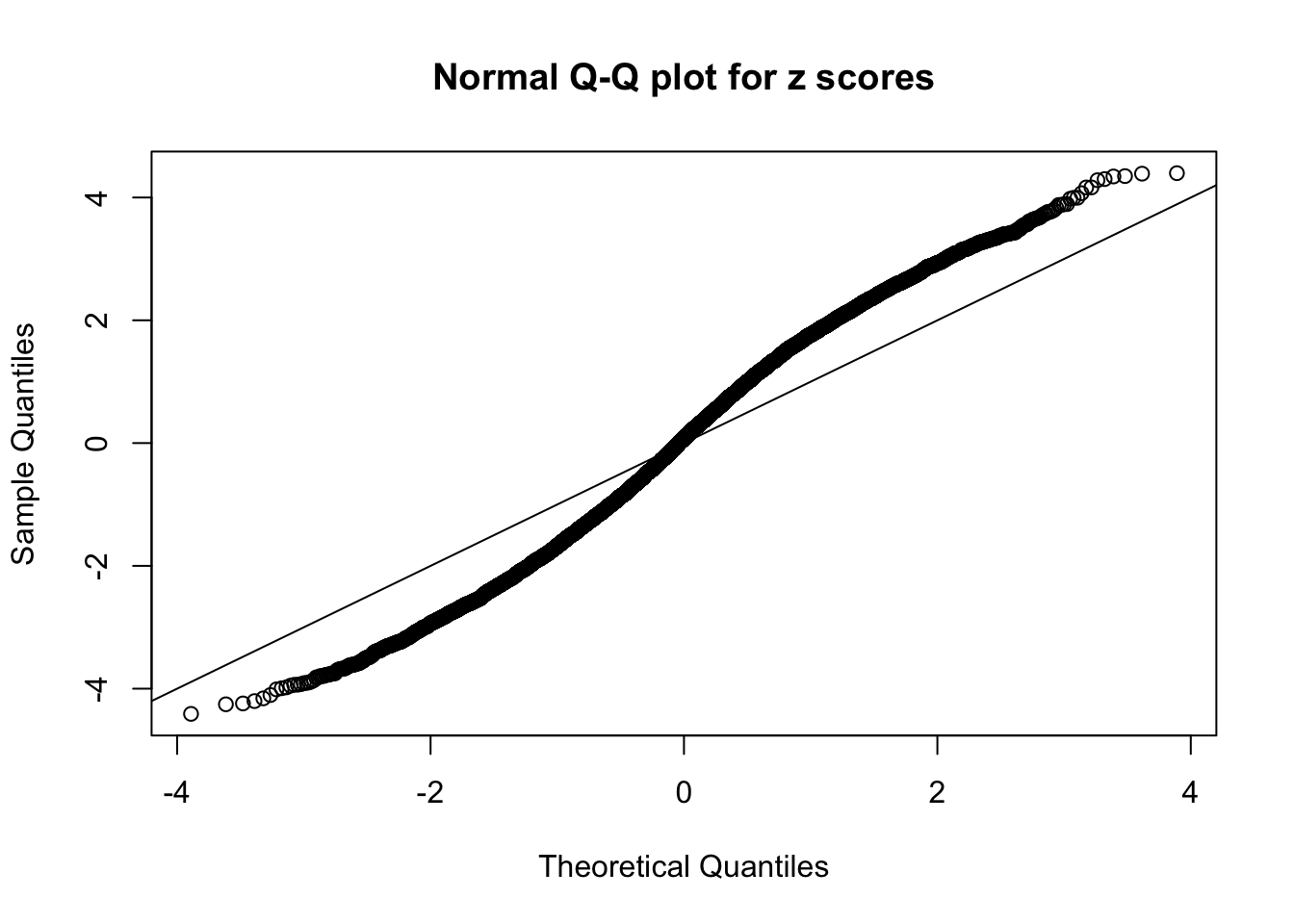
N0. 7 : Data Set 724 ; Number of False Discoveries: 79 ; pihat0 = 0.01606004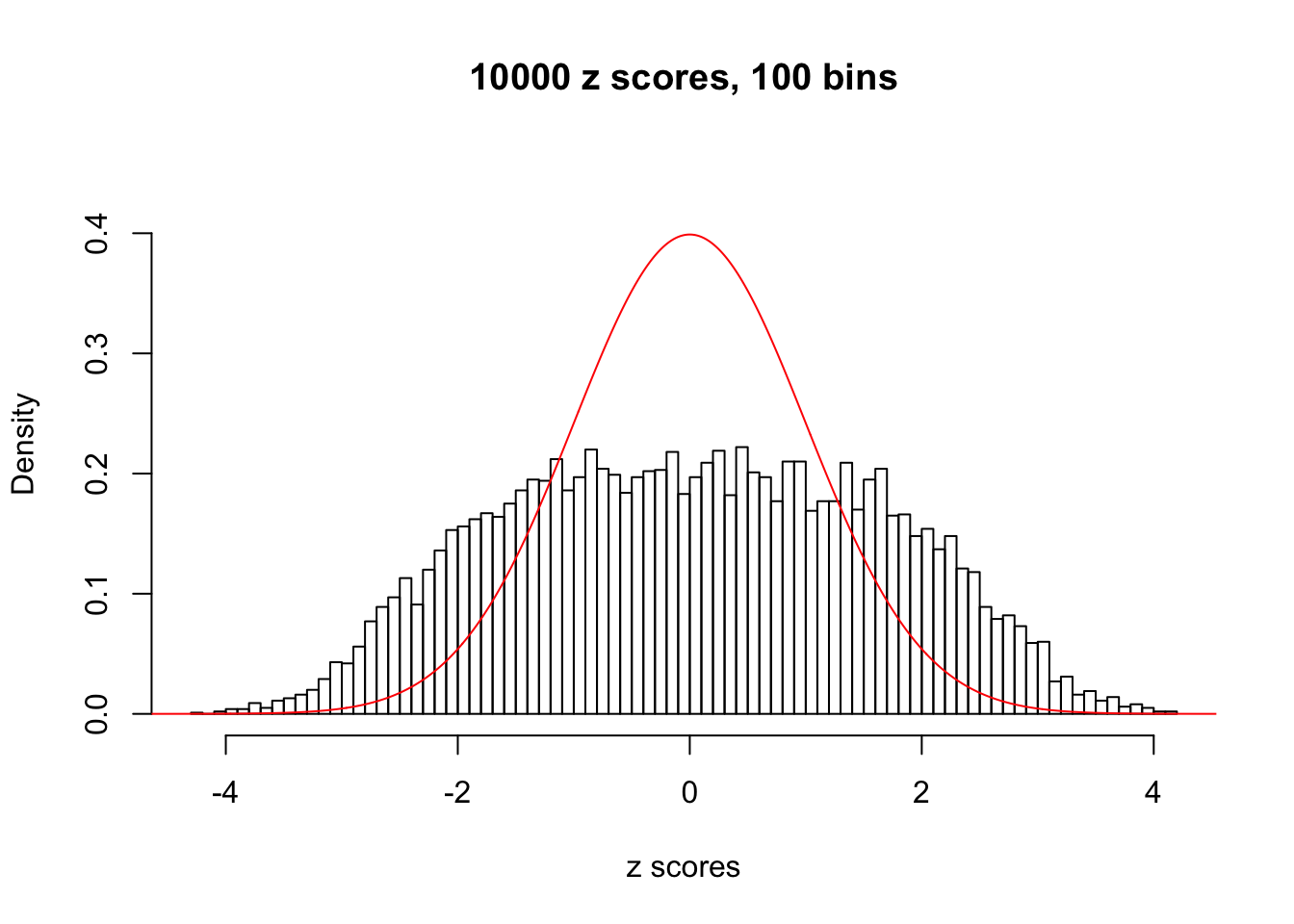
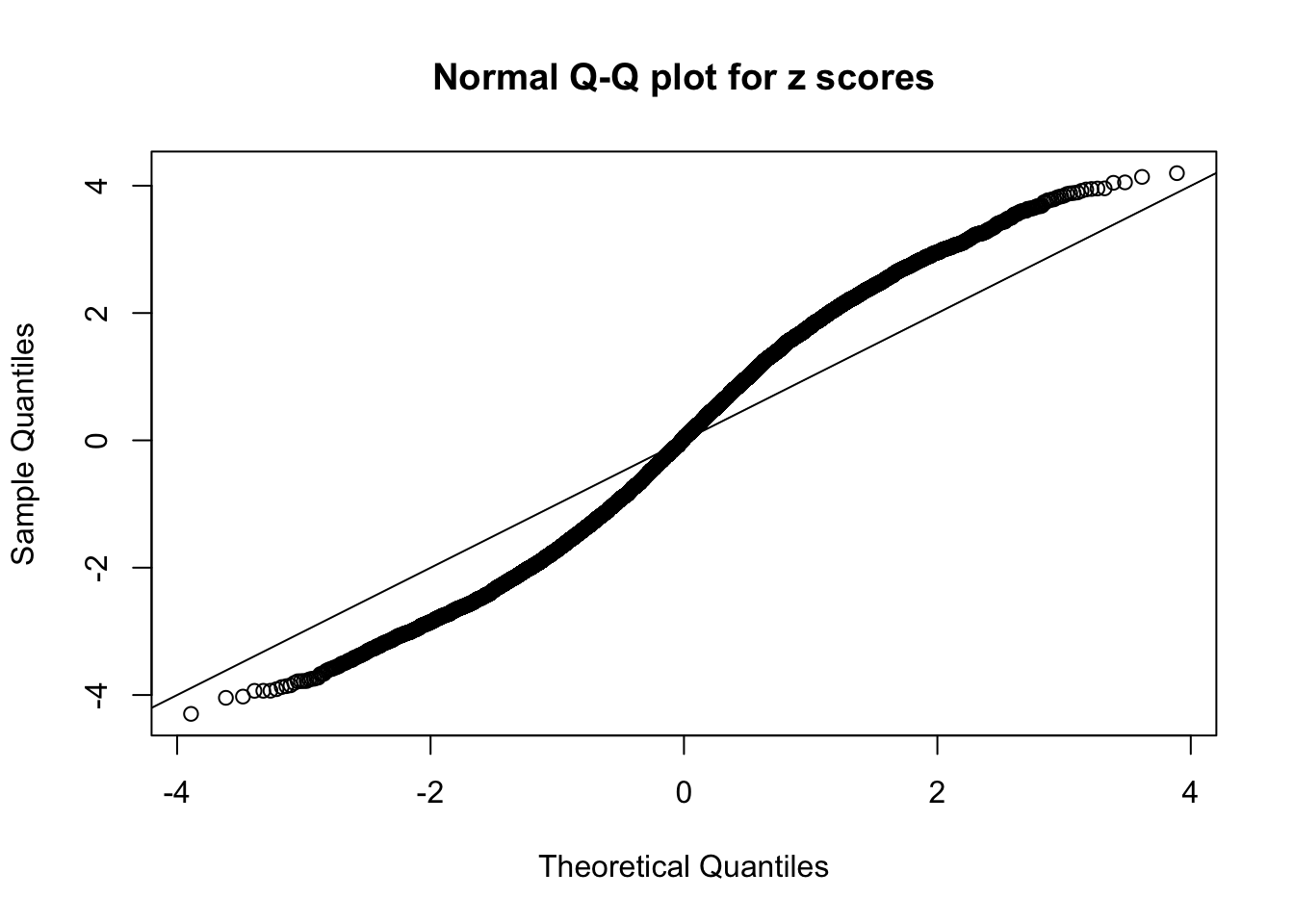
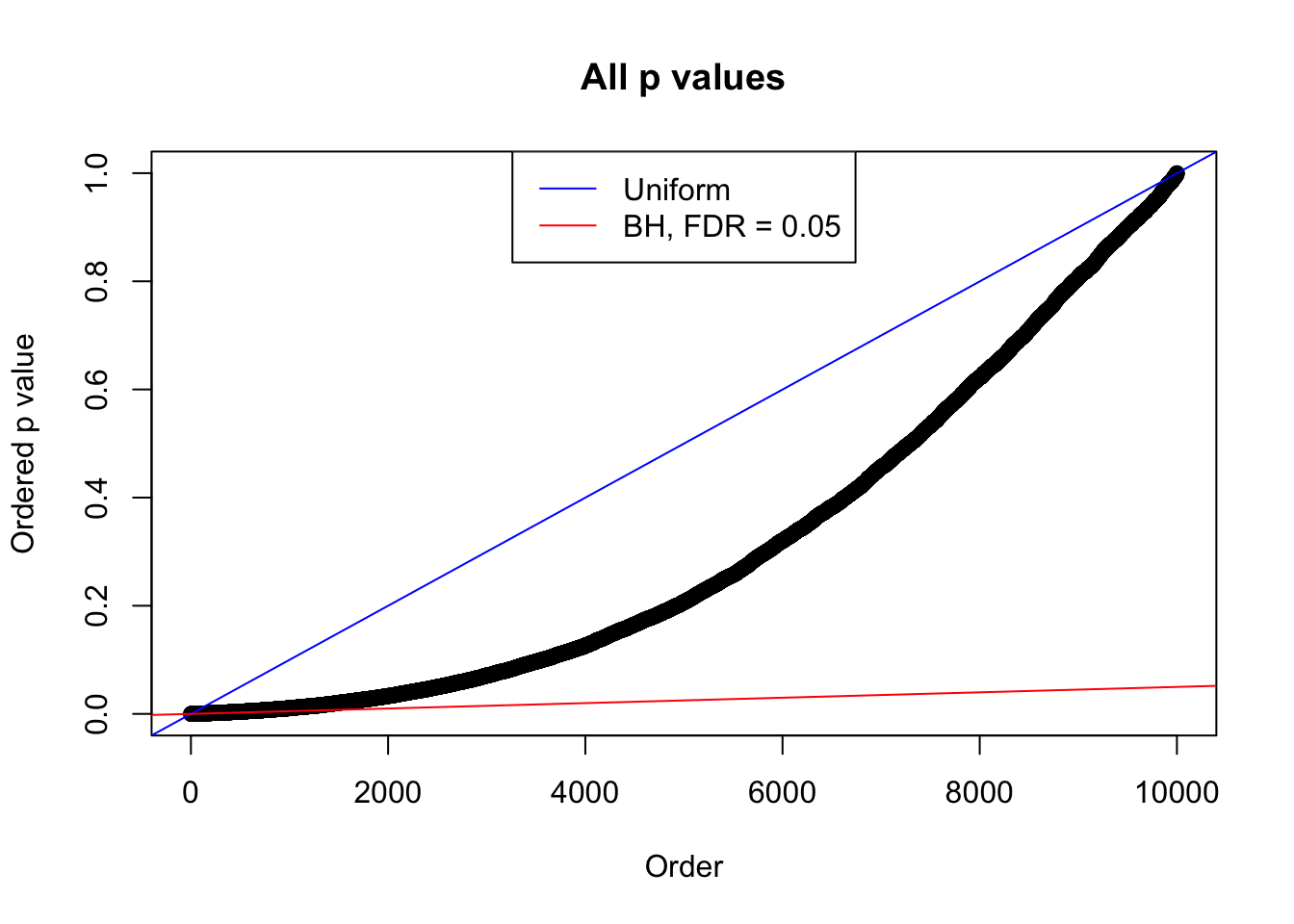
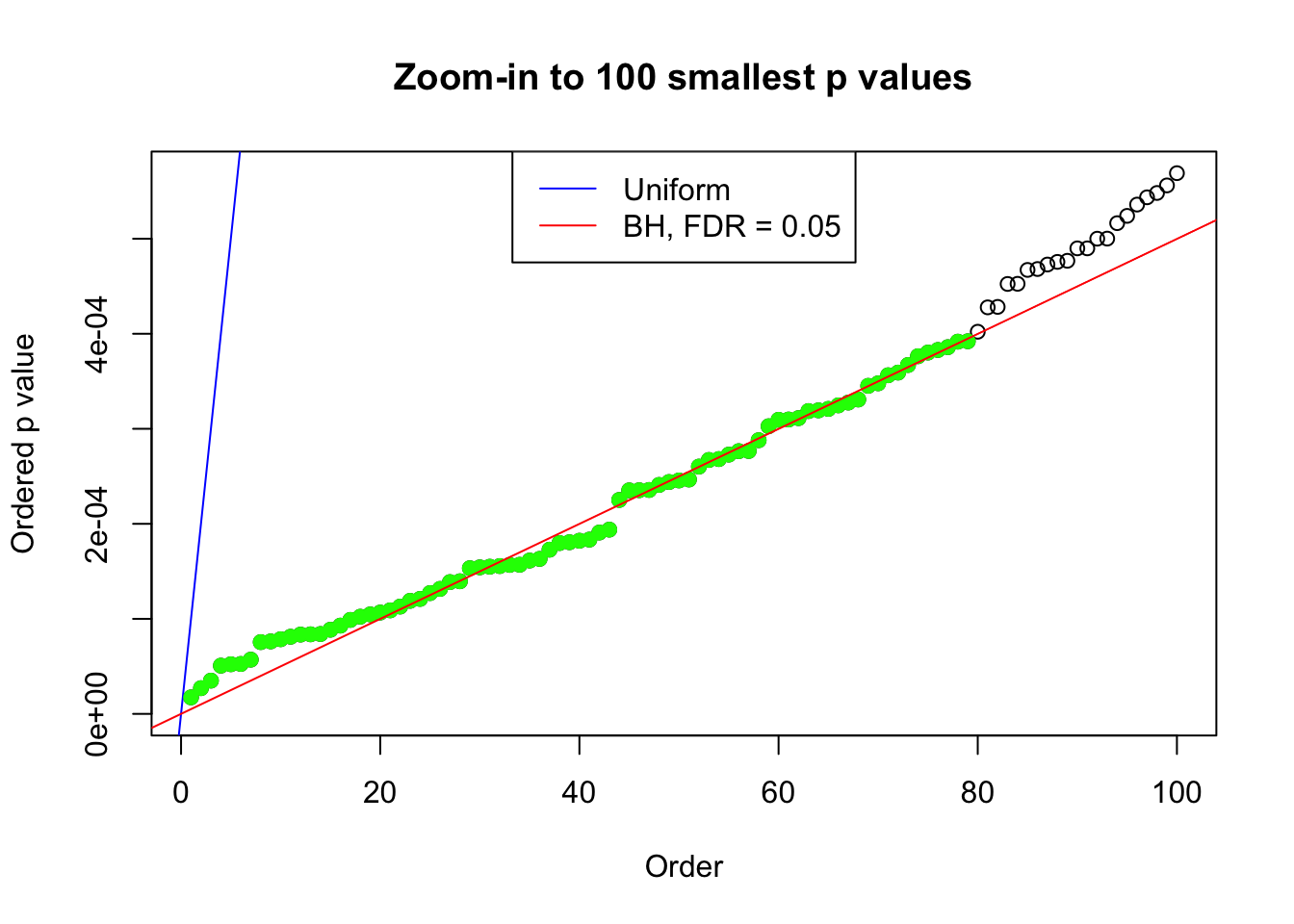
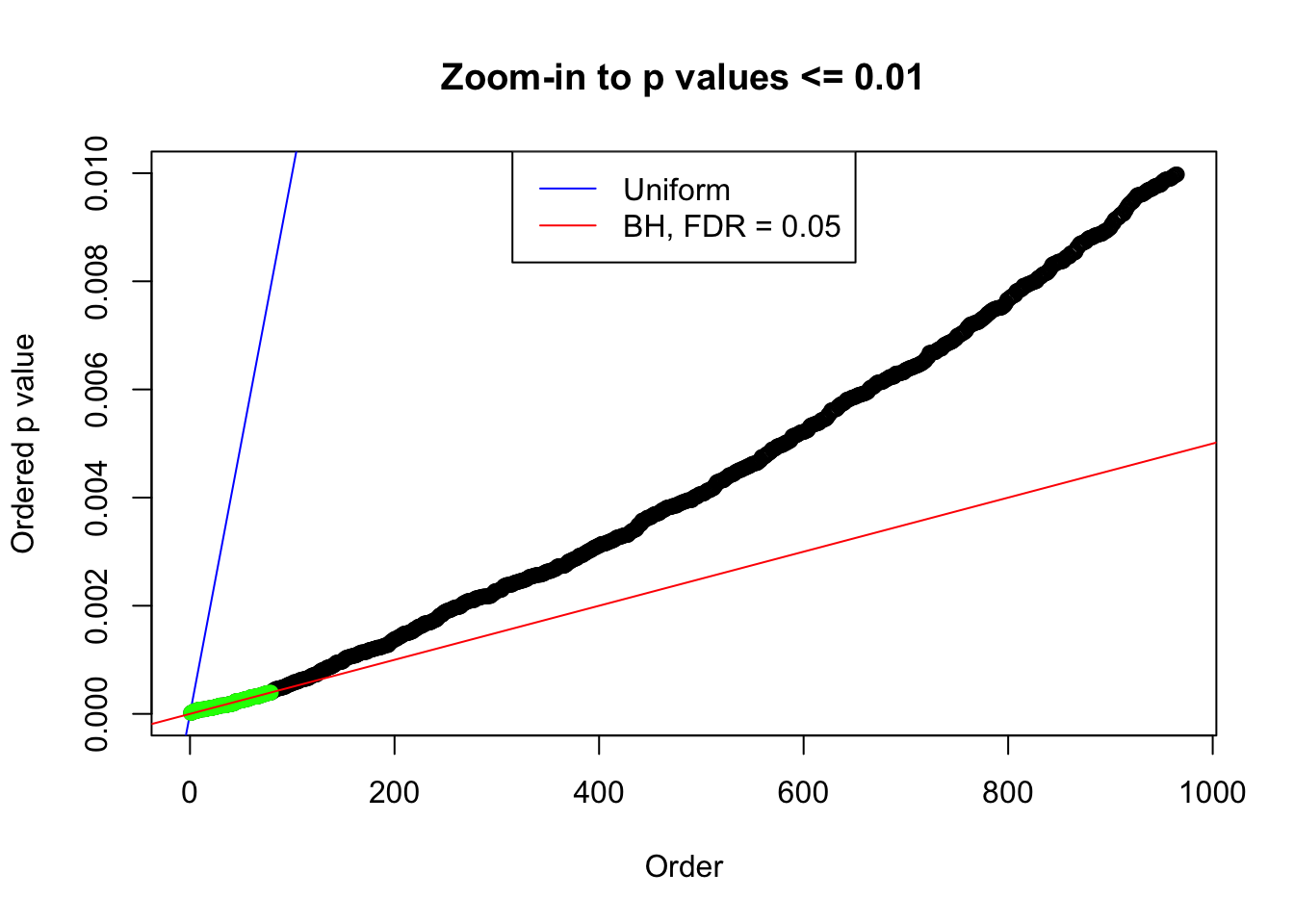
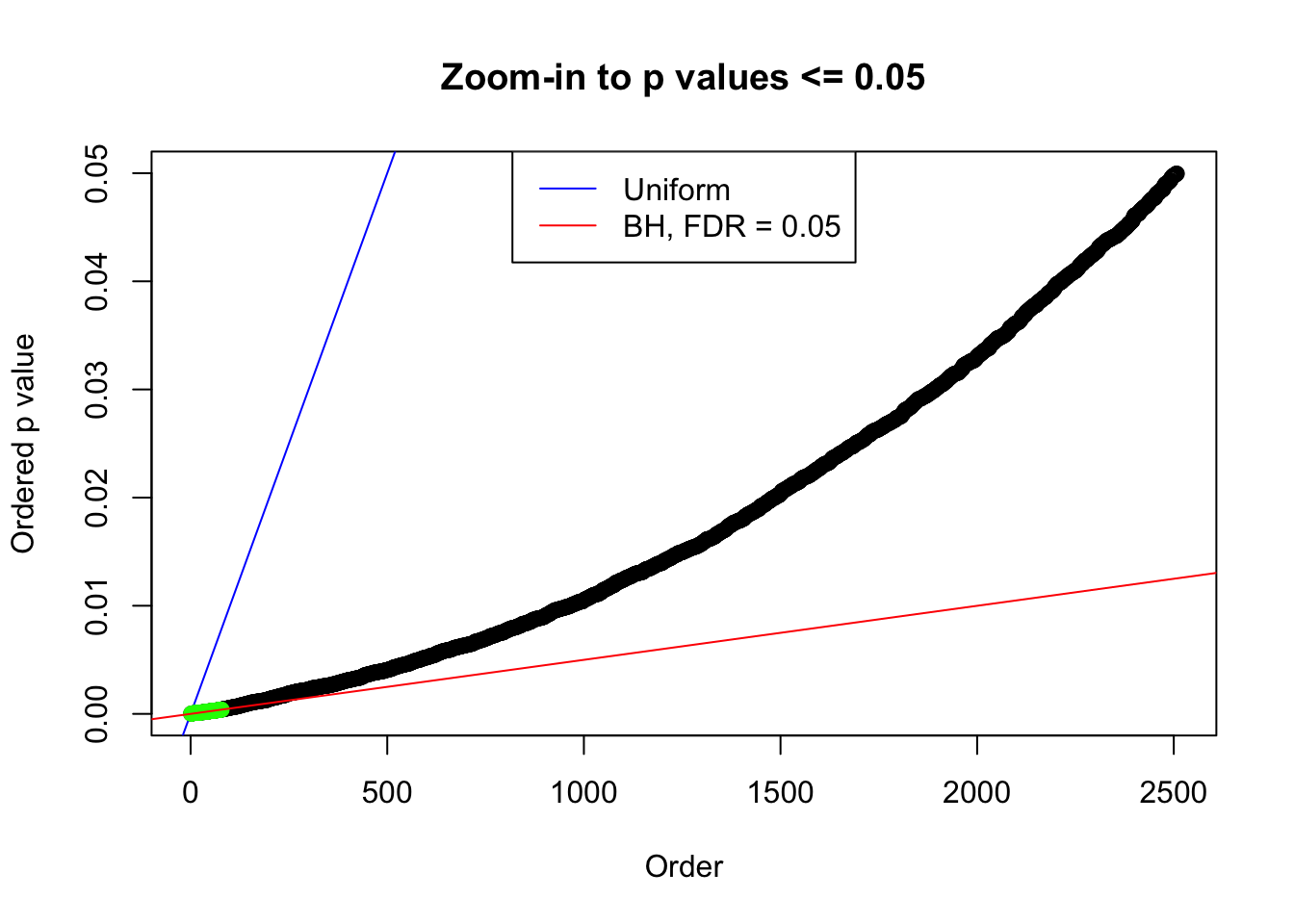
N0. 8 : Data Set 56 ; Number of False Discoveries: 35 ; pihat0 = 0.04829662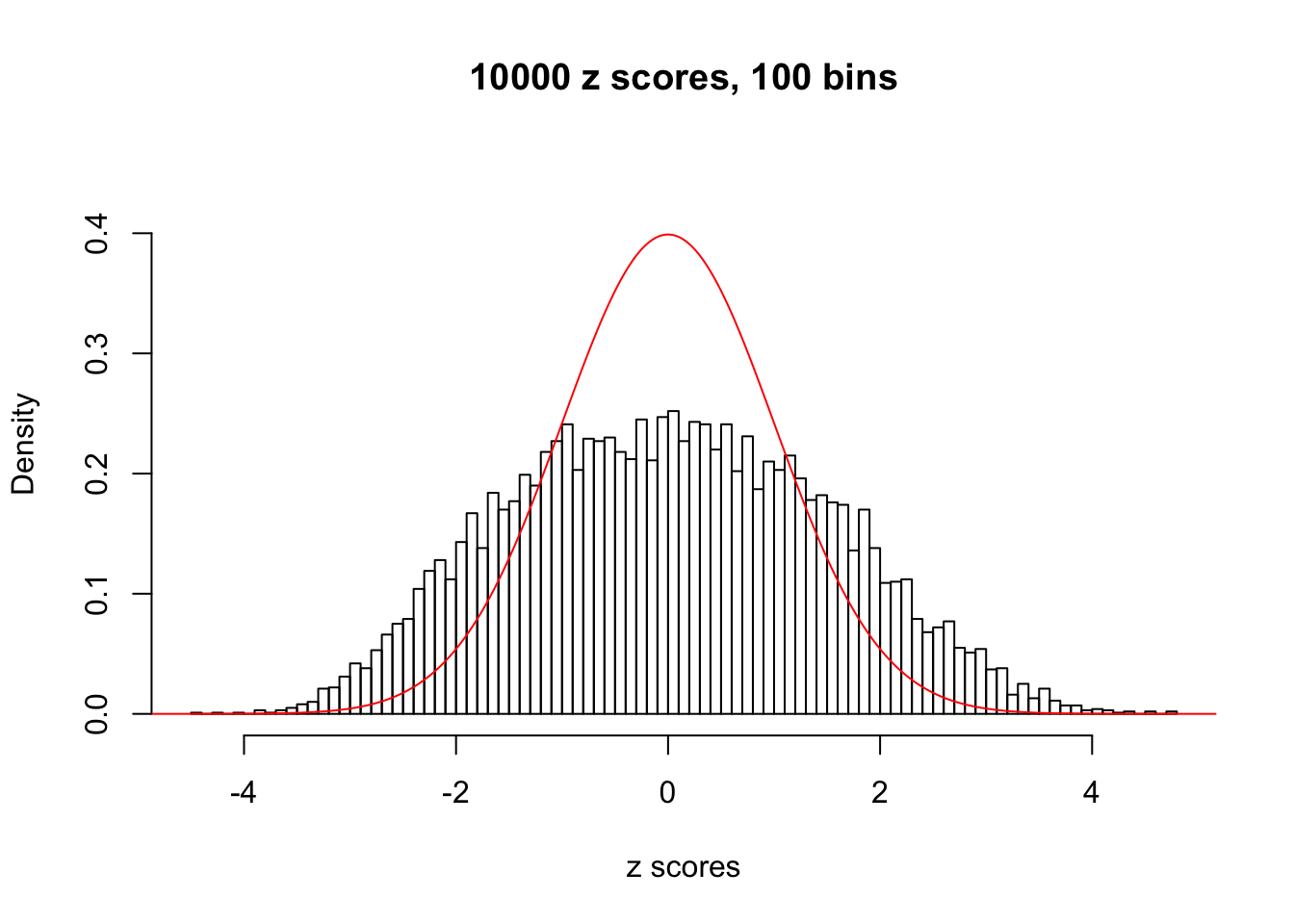
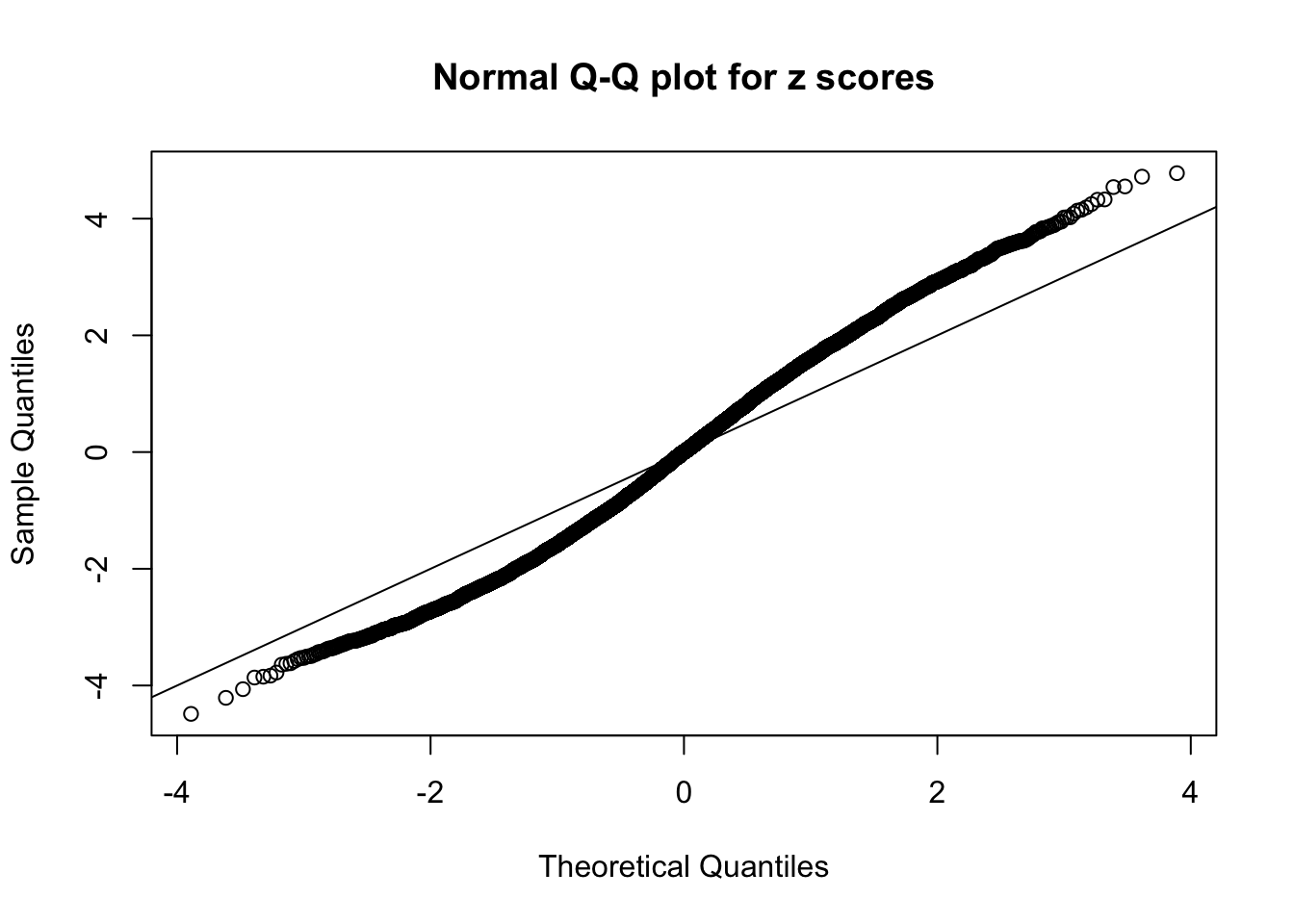
N0. 9 : Data Set 840 ; Number of False Discoveries: 28 ; pihat0 = 0.02316832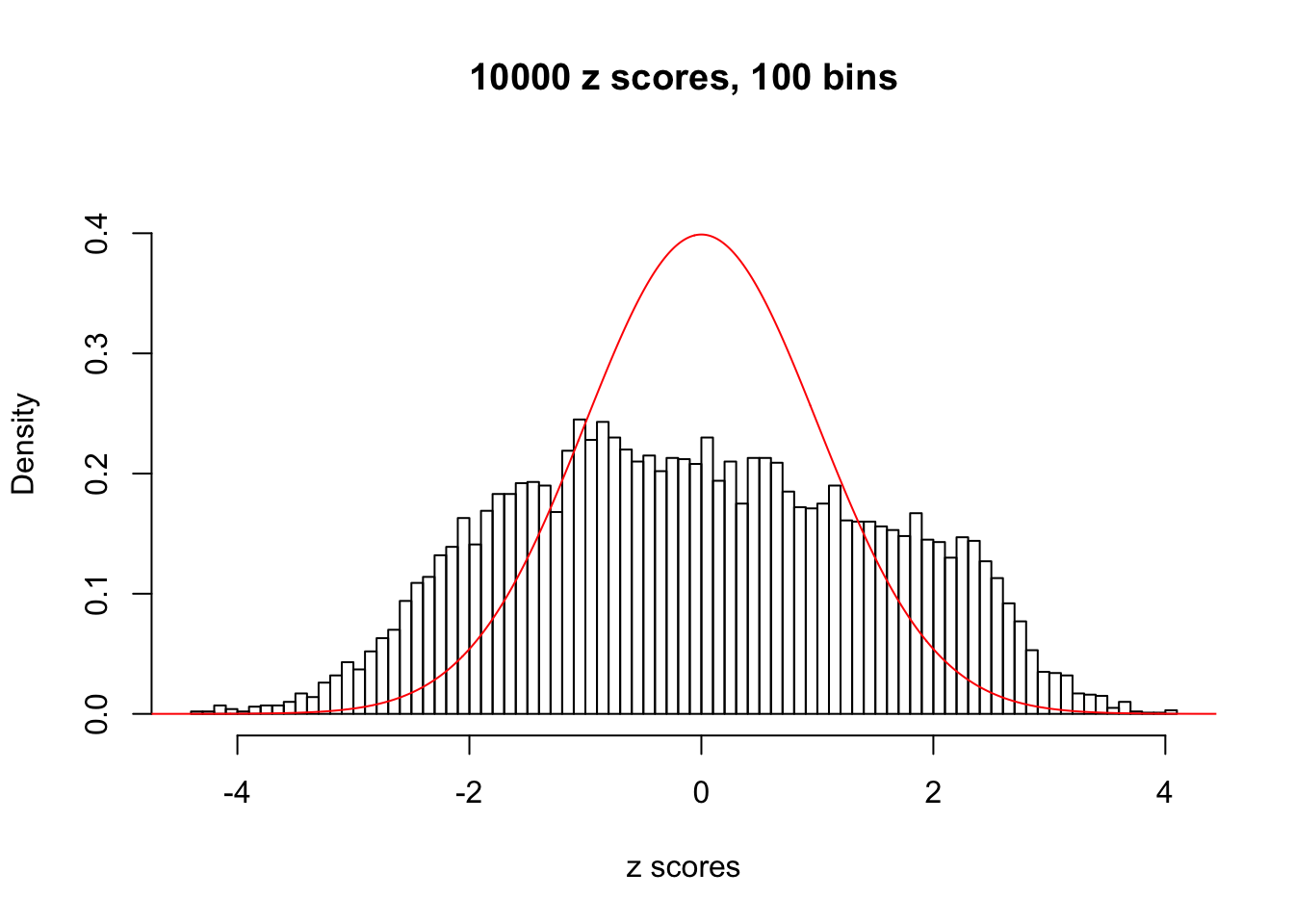
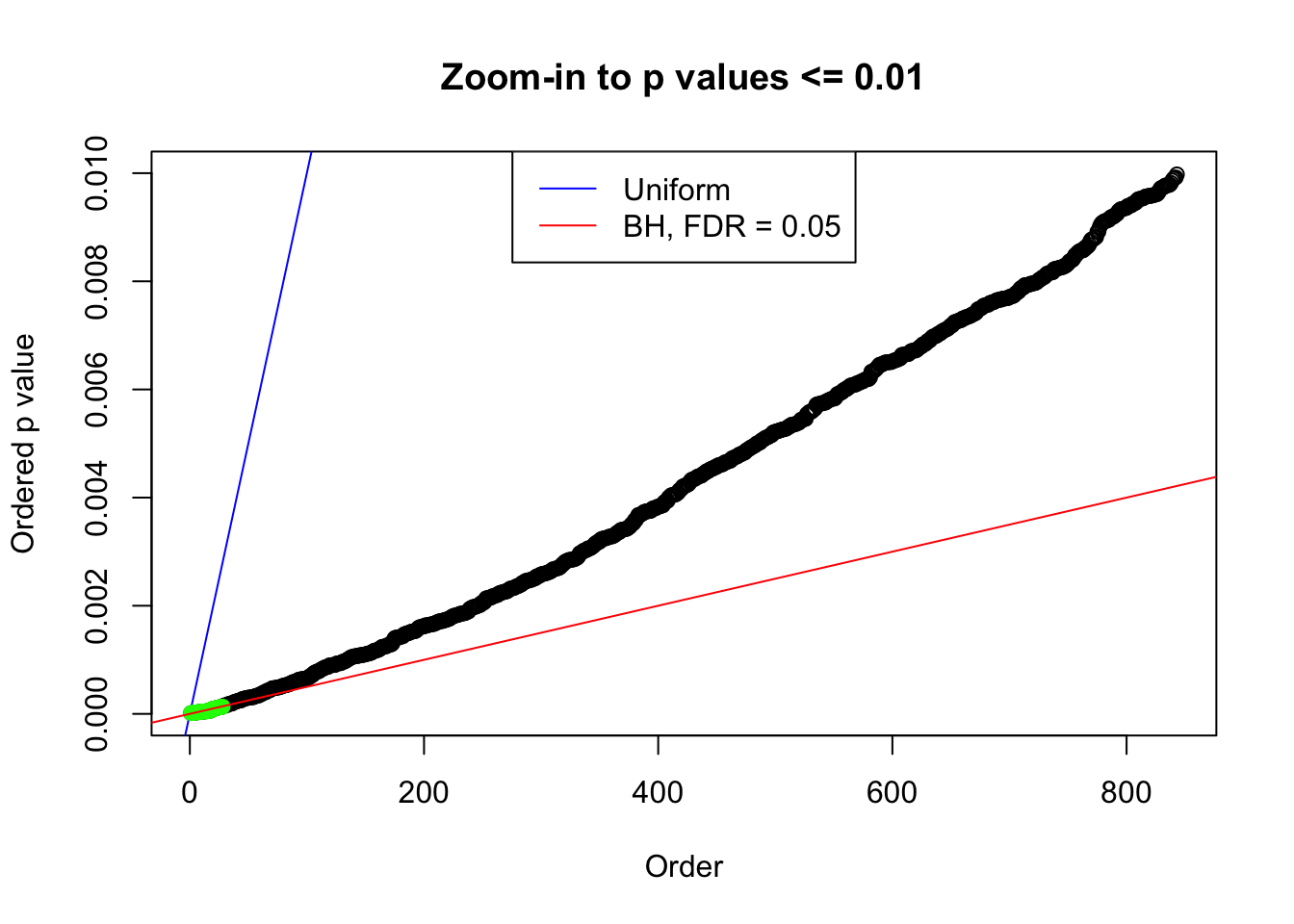
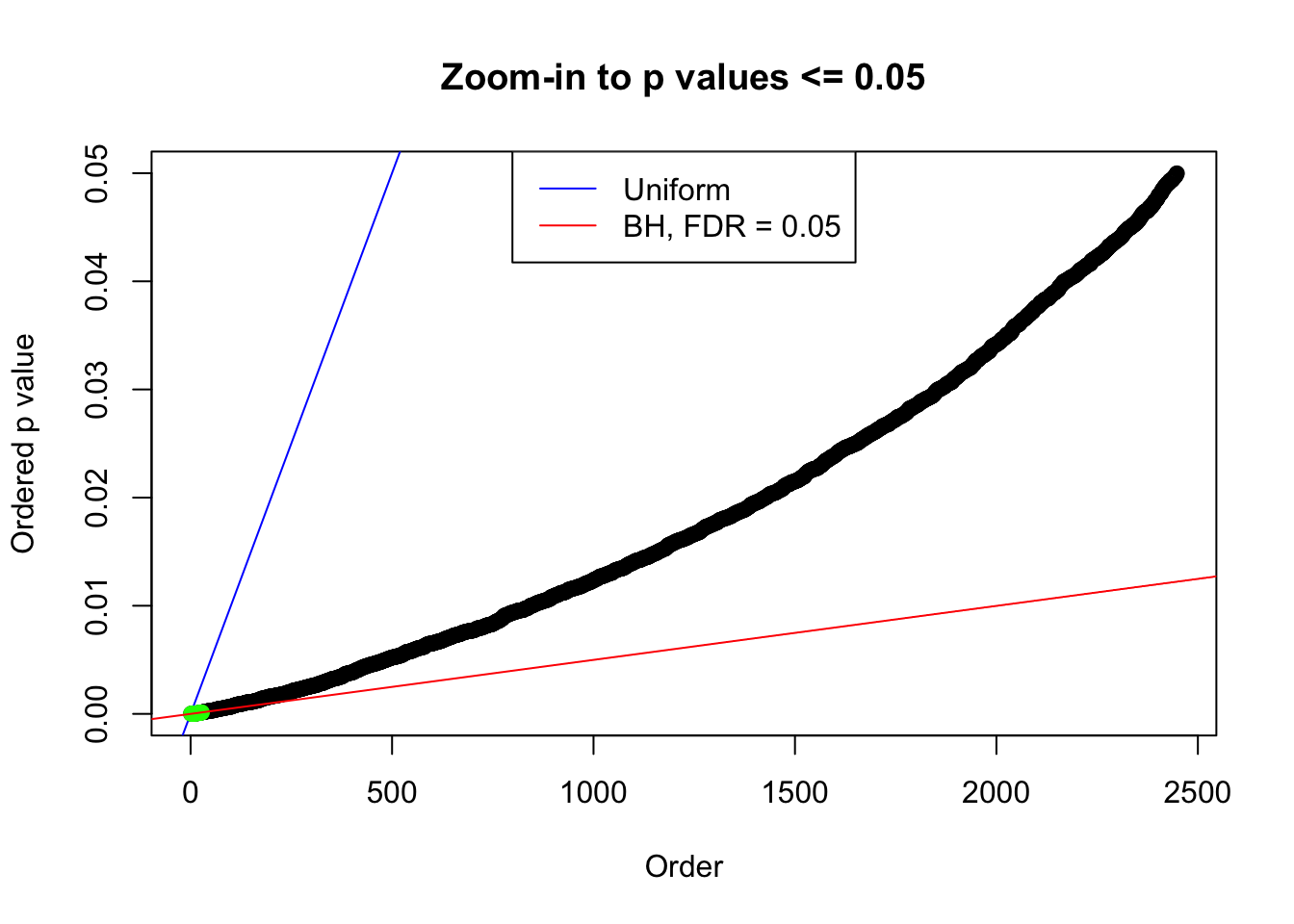
N0. 10 : Data Set 858 ; Number of False Discoveries: 16 ; pihat0 = 0.05110069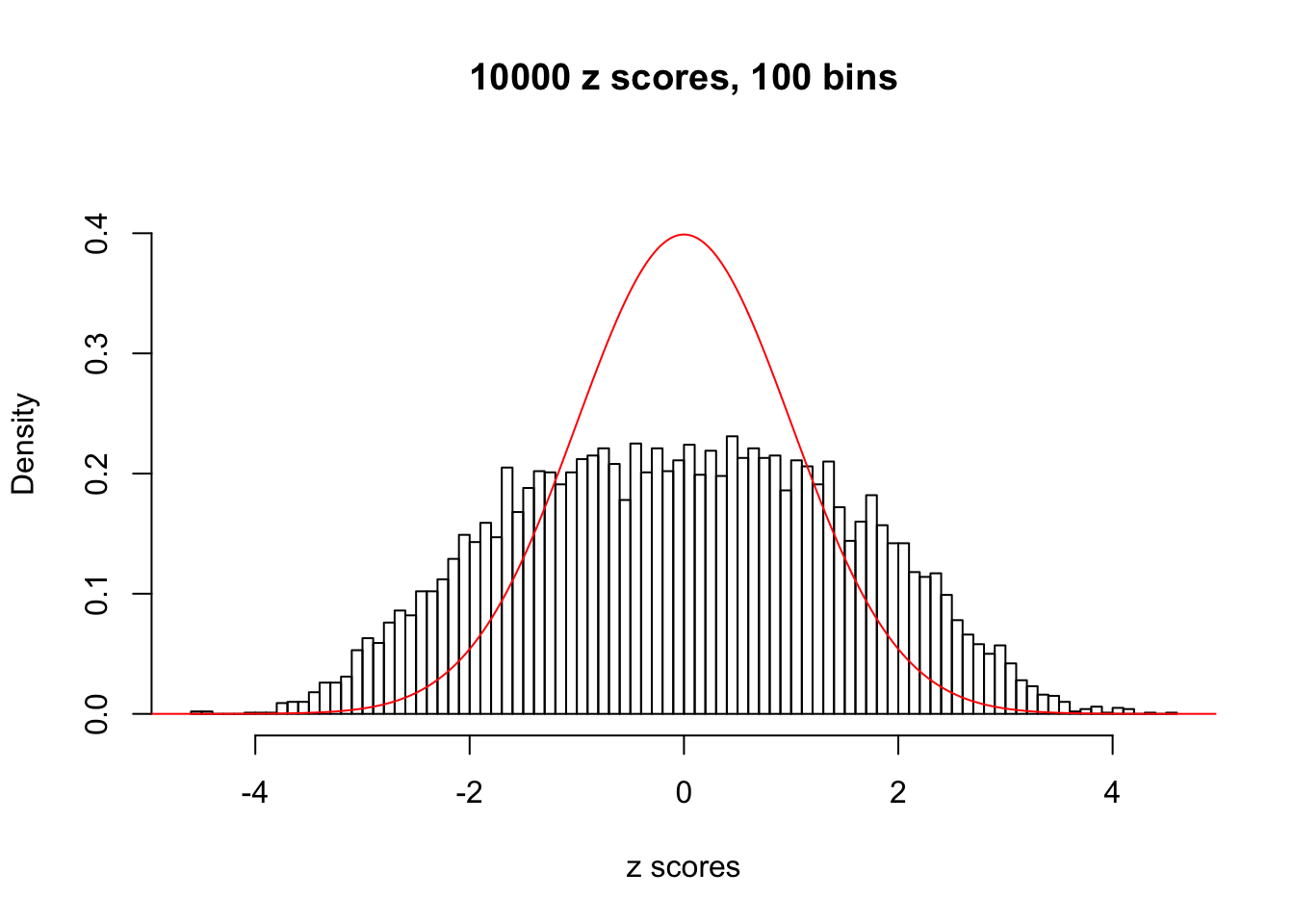
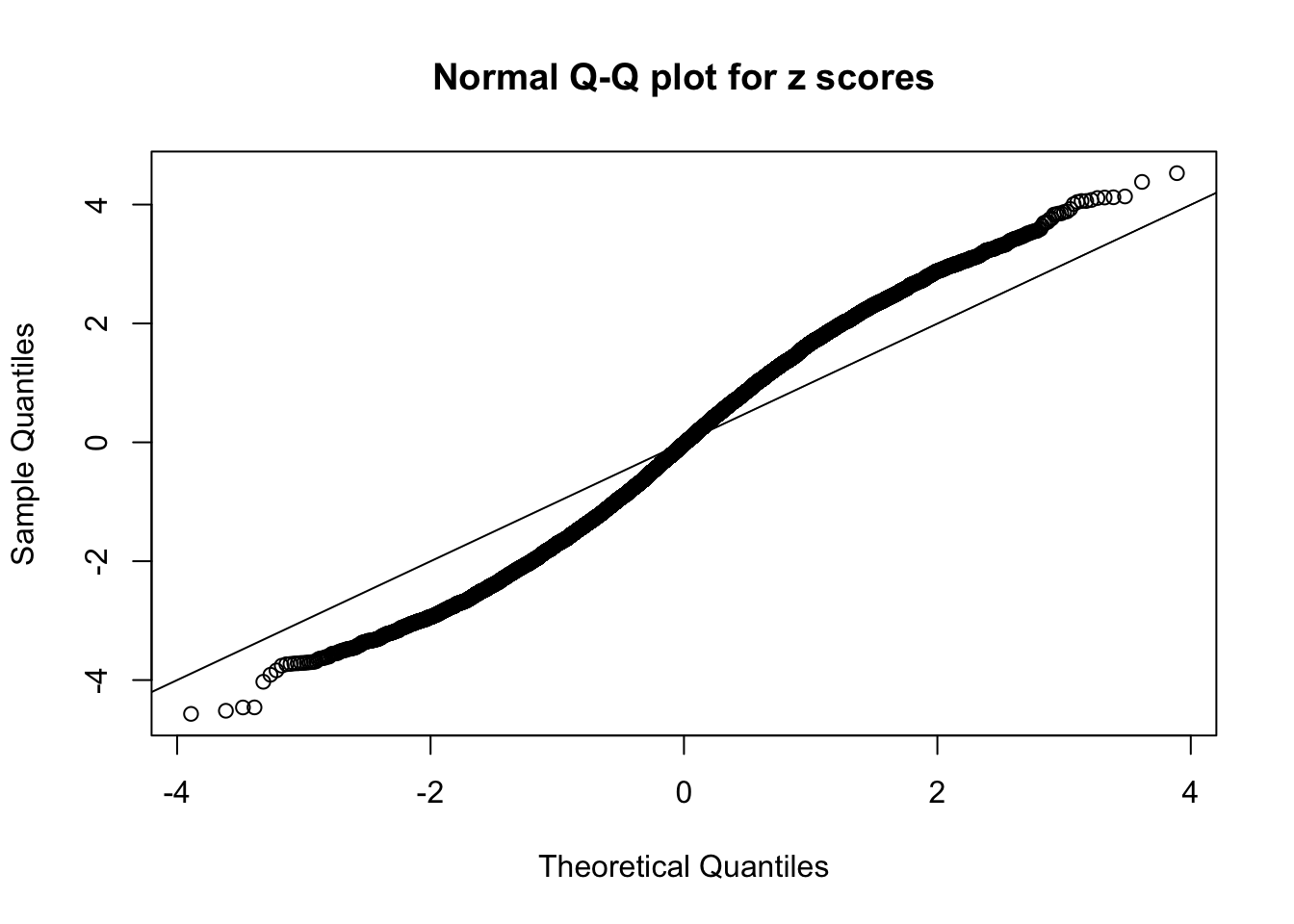
N0. 11 : Data Set 771 ; Number of False Discoveries: 12 ; pihat0 = 0.04316169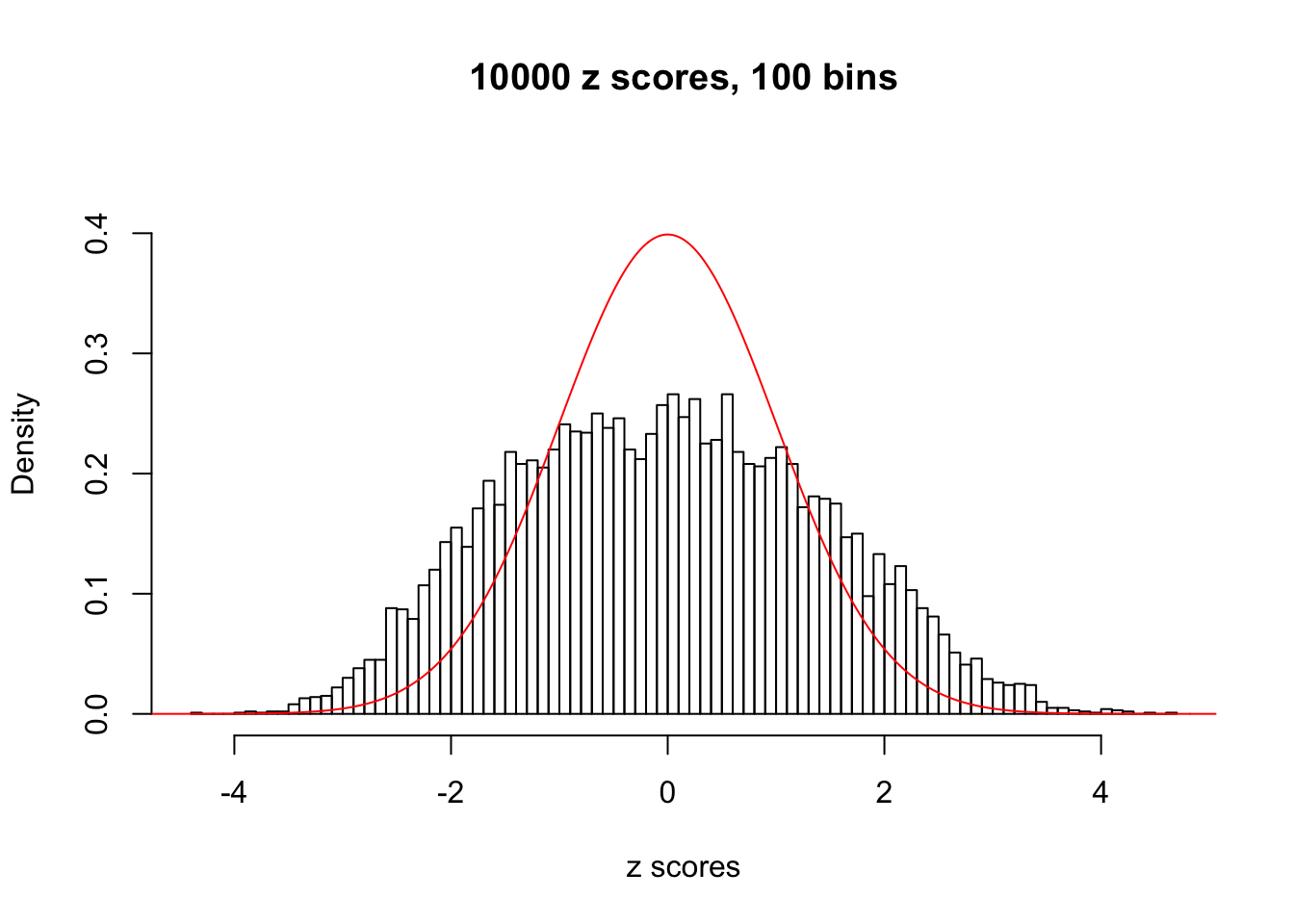
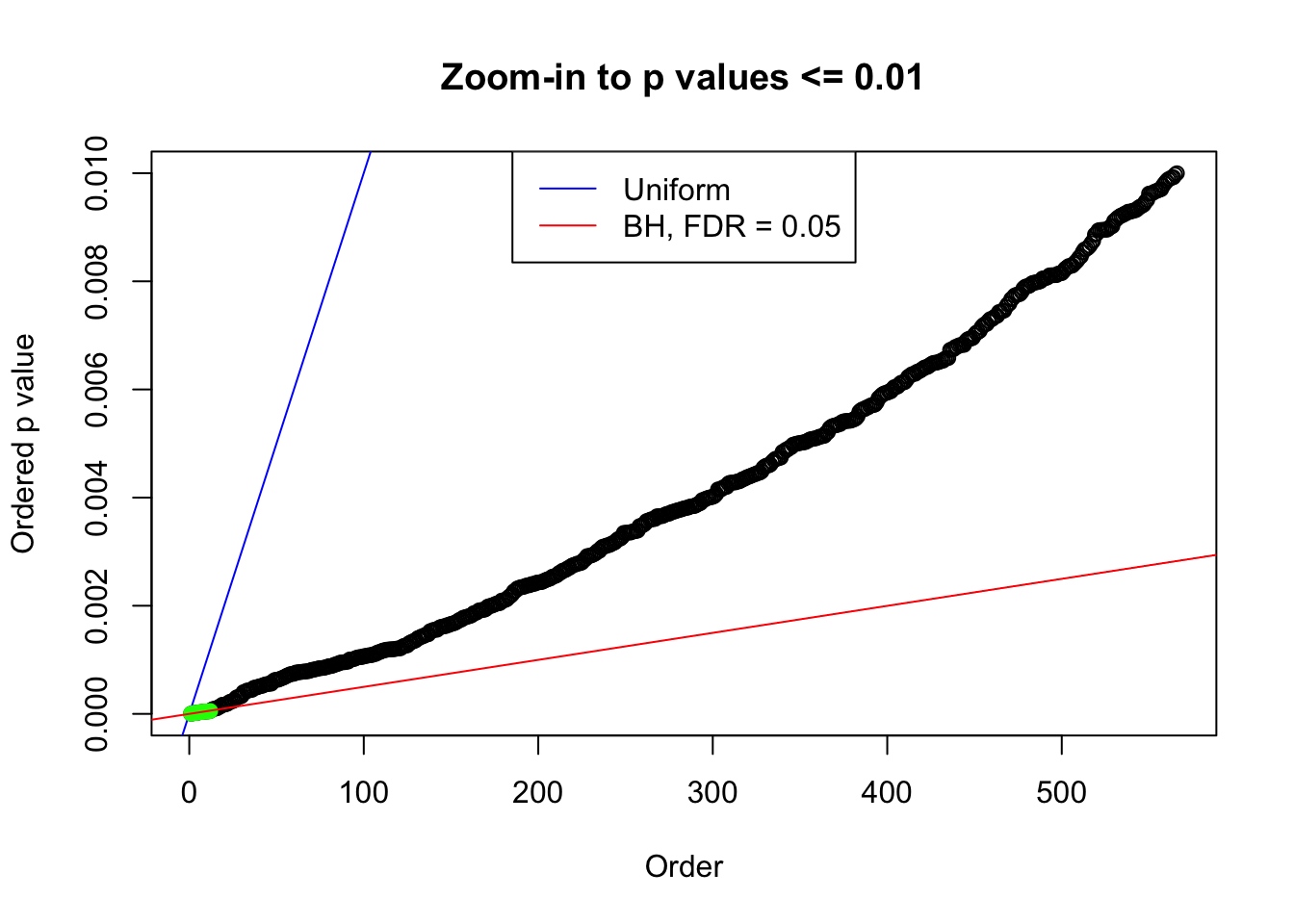
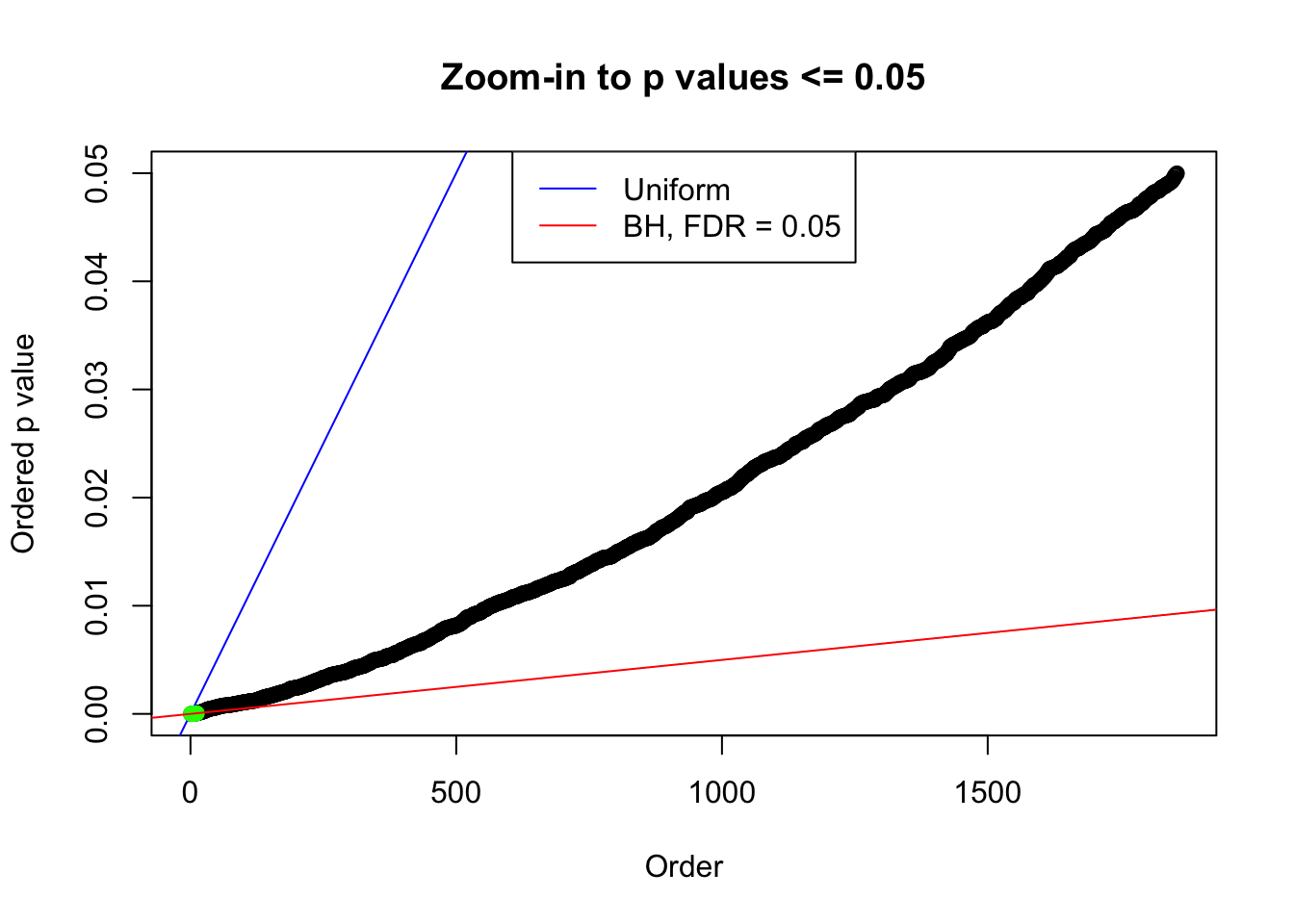
N0. 12 : Data Set 389 ; Number of False Discoveries: 11 ; pihat0 = 0.03156173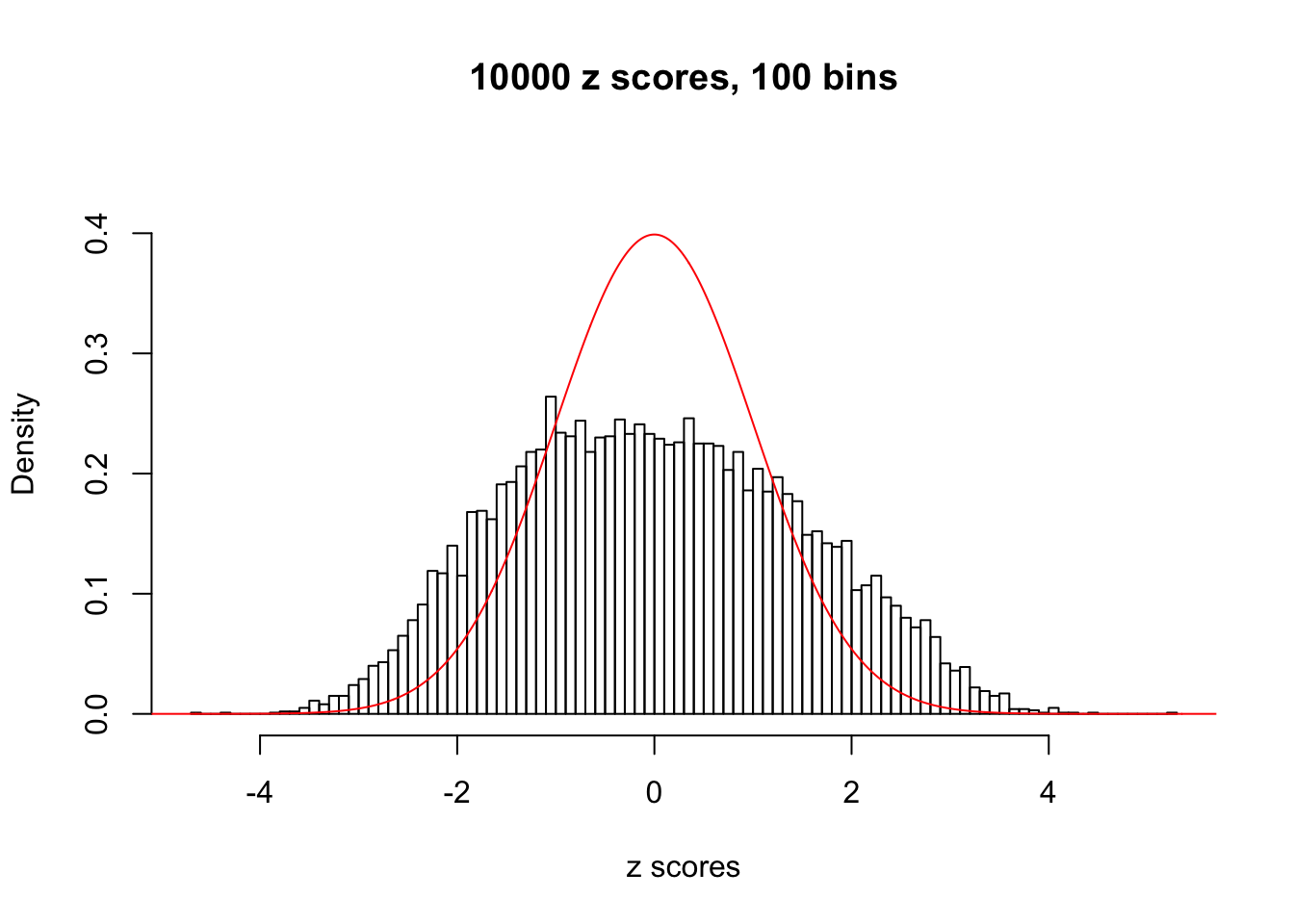
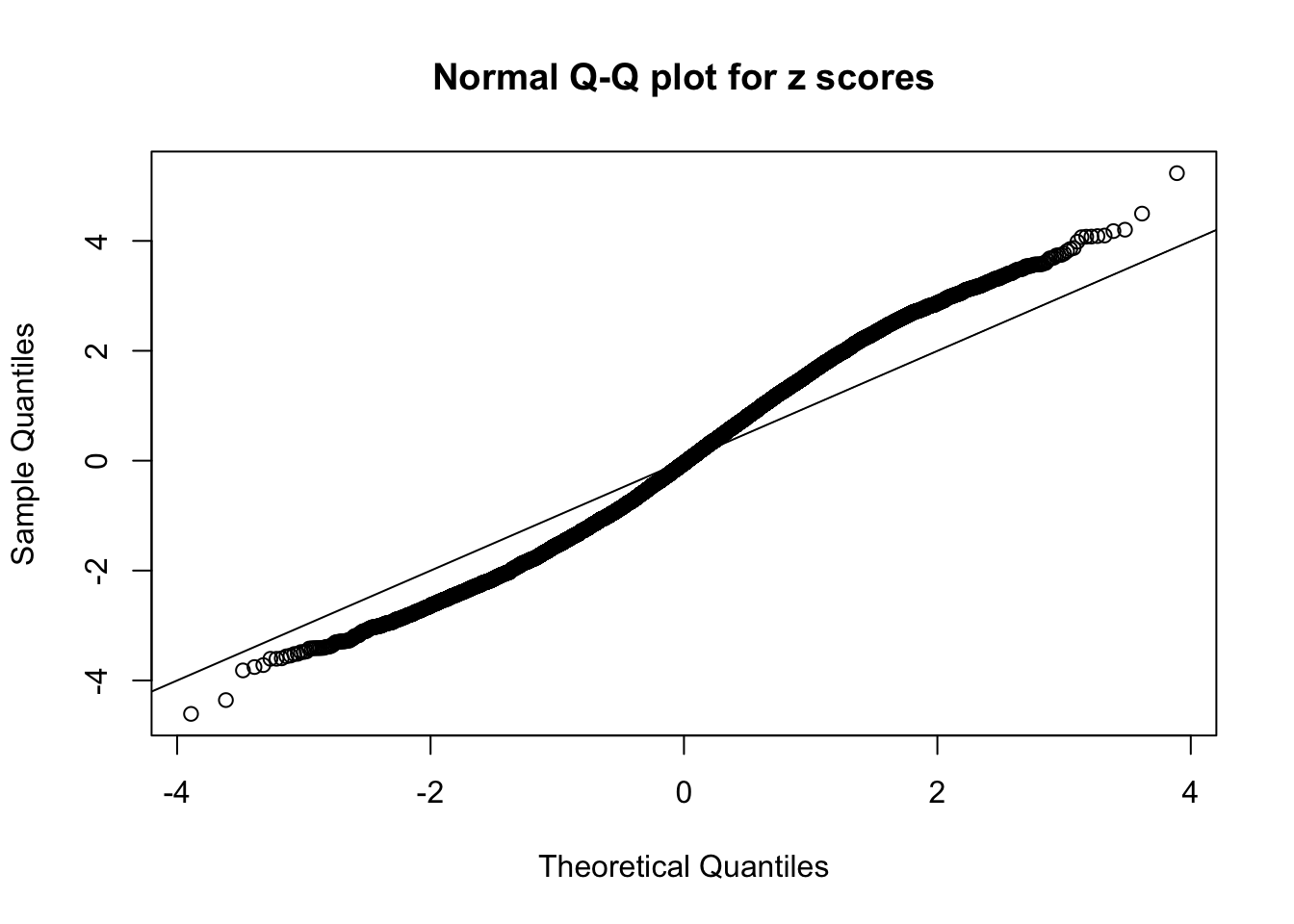
N0. 13 : Data Set 485 ; Number of False Discoveries: 9 ; pihat0 = 0.04794909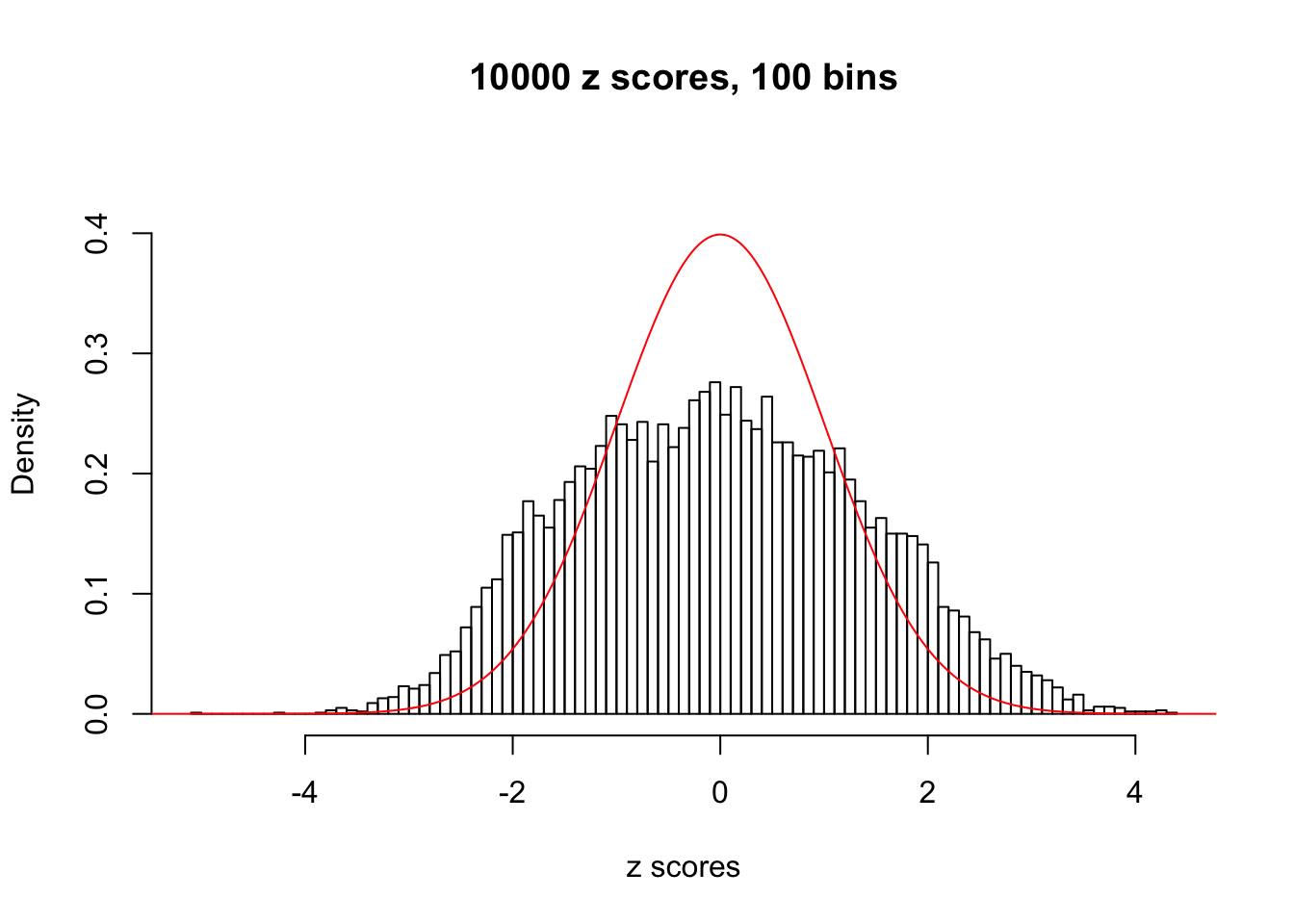
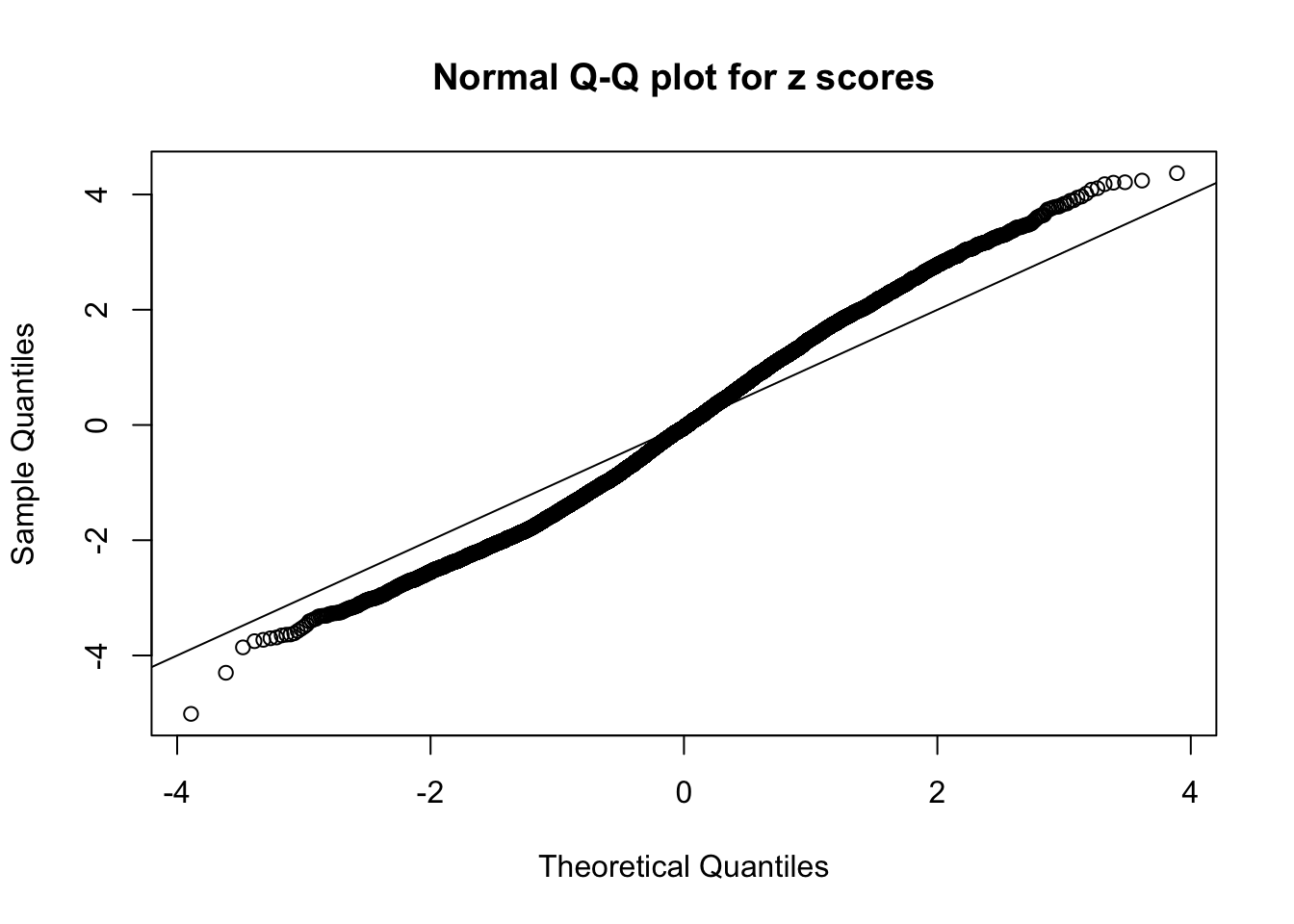
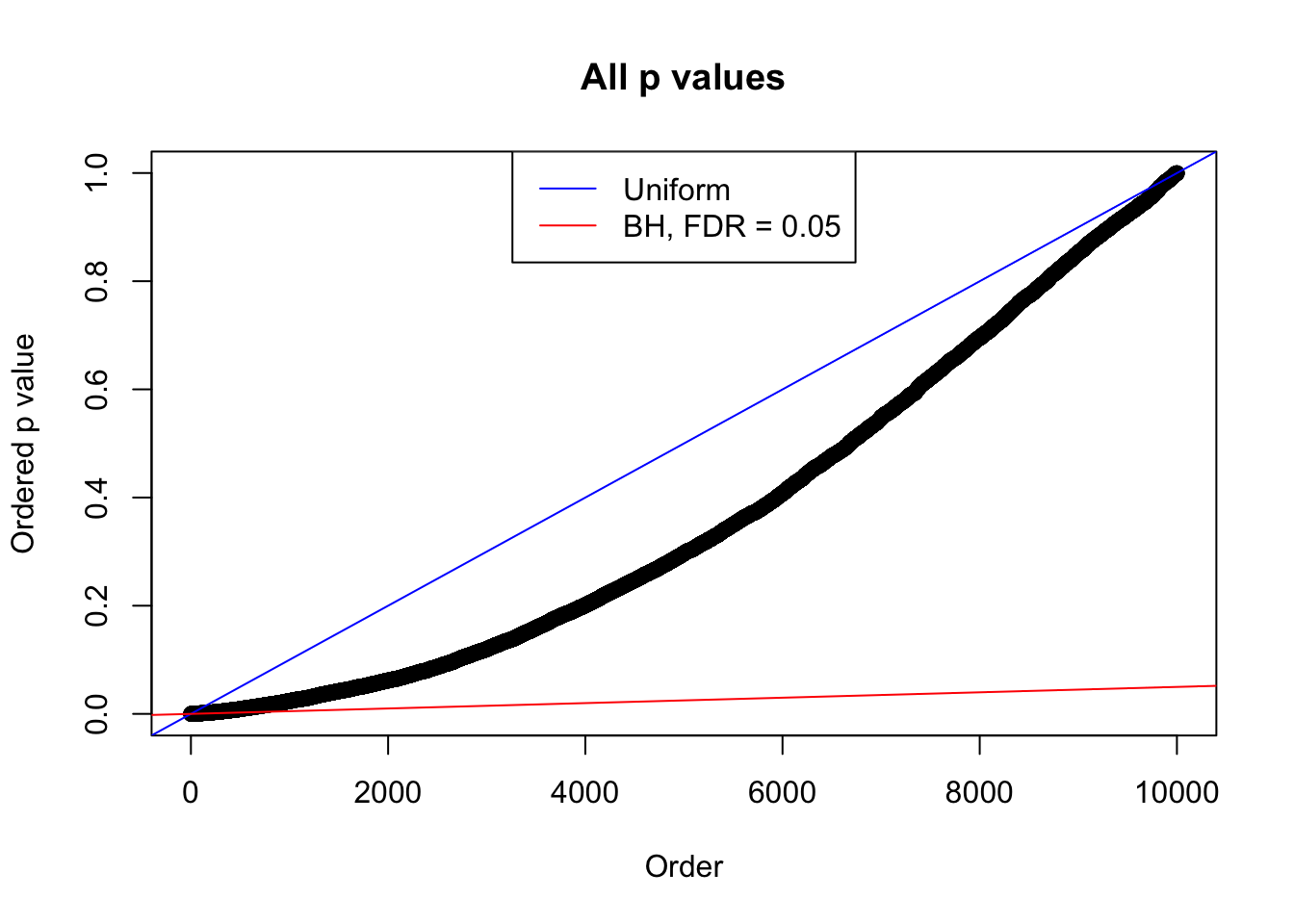
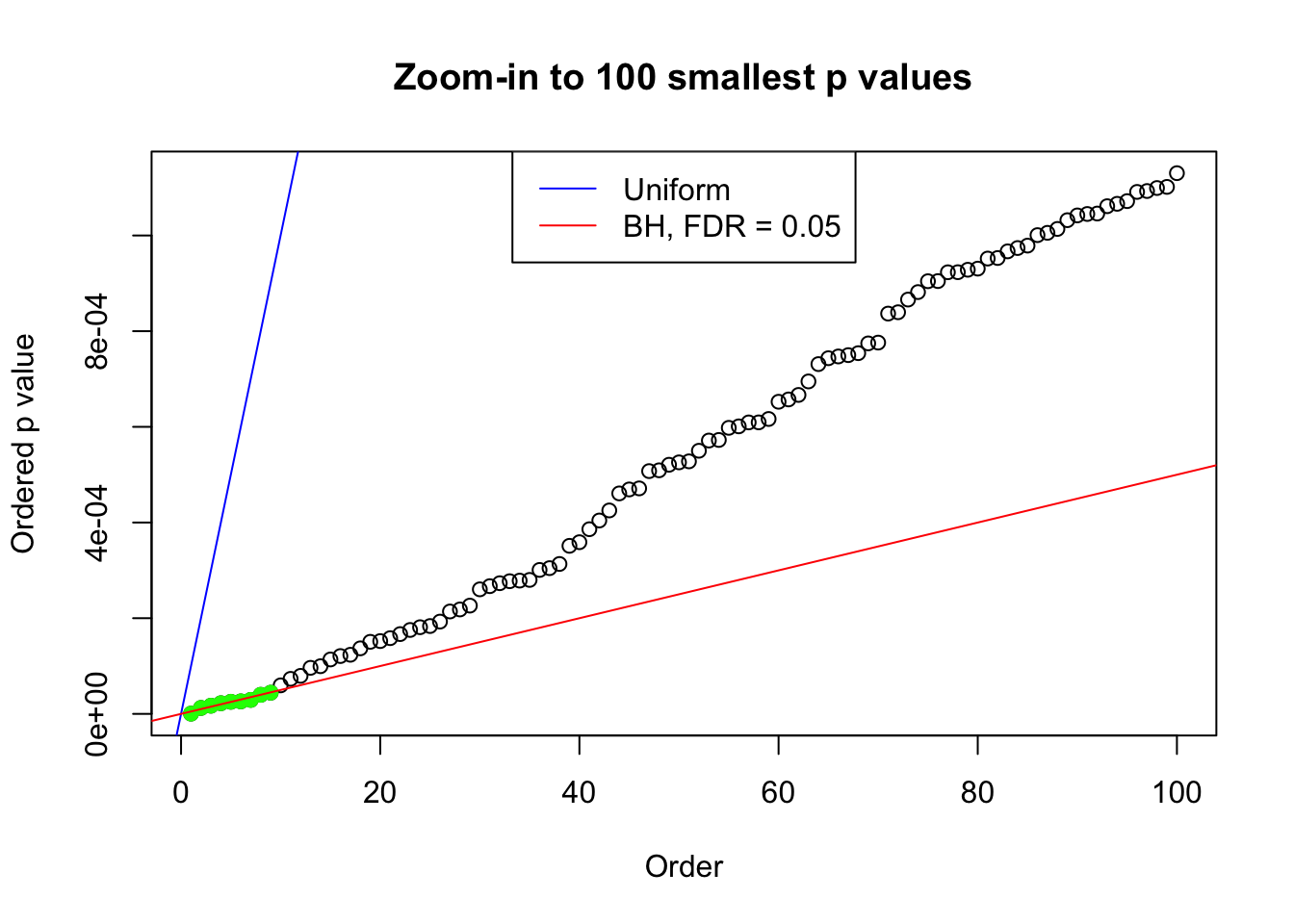
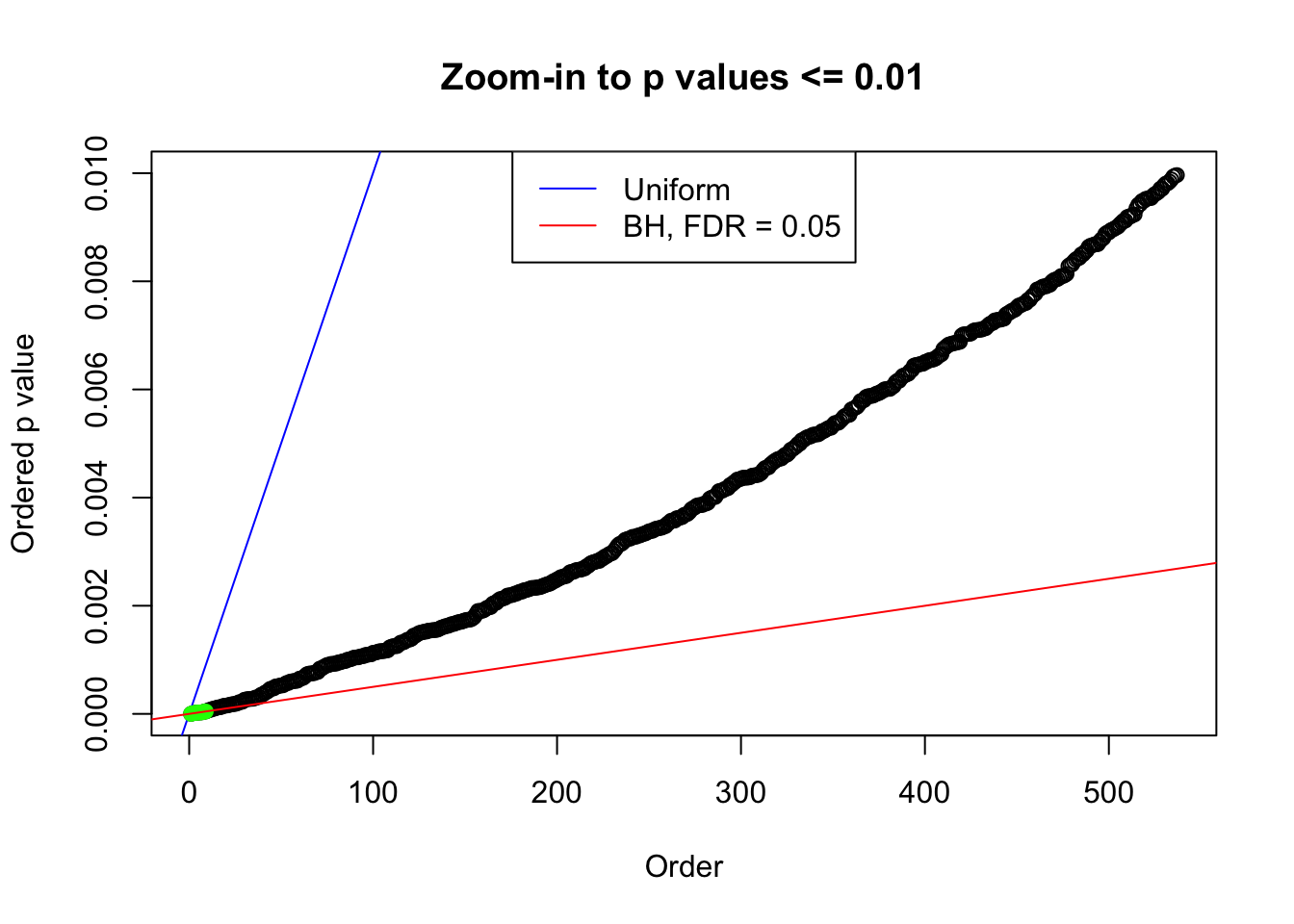
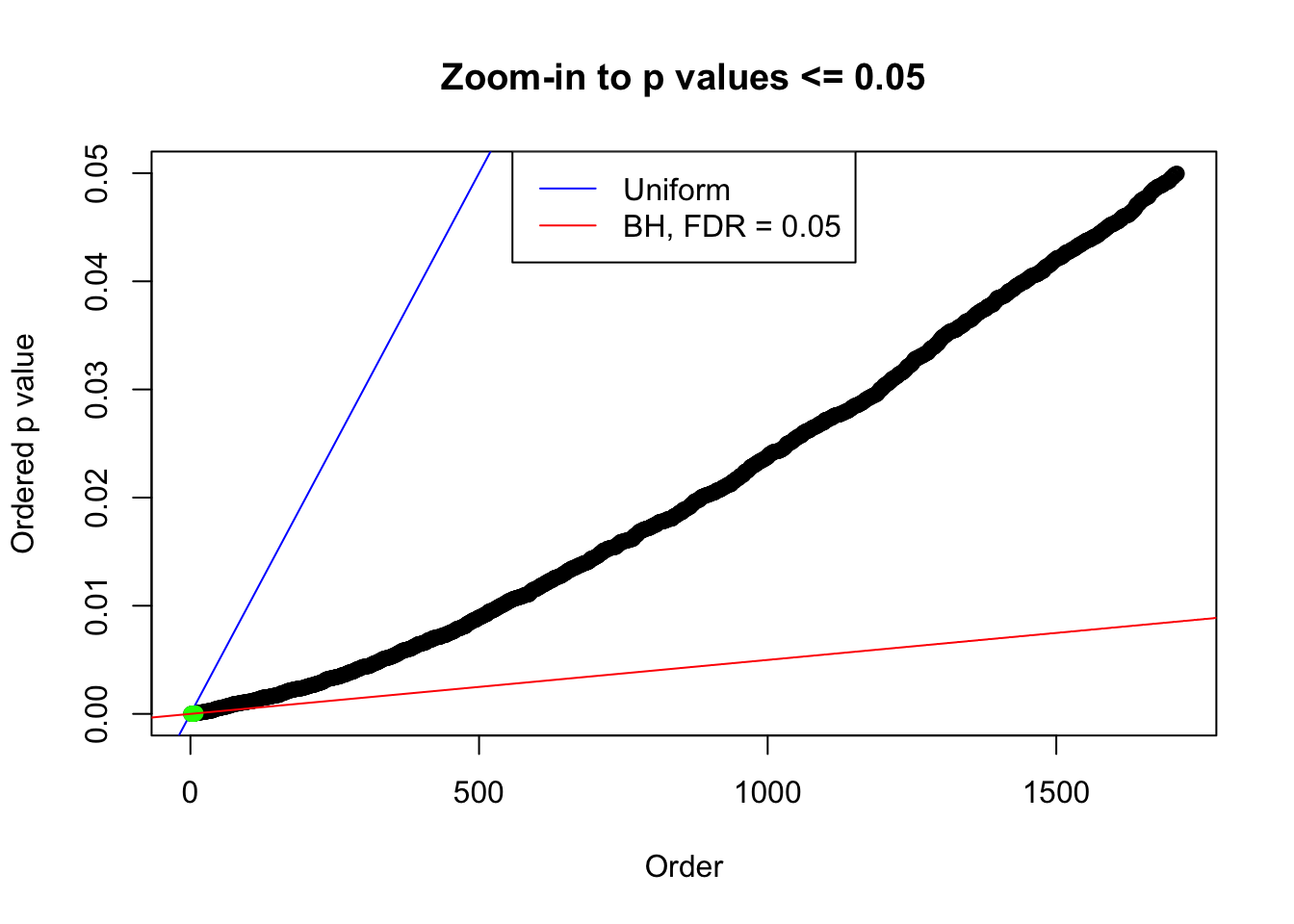
N0. 14 : Data Set 77 ; Number of False Discoveries: 7 ; pihat0 = 0.05151585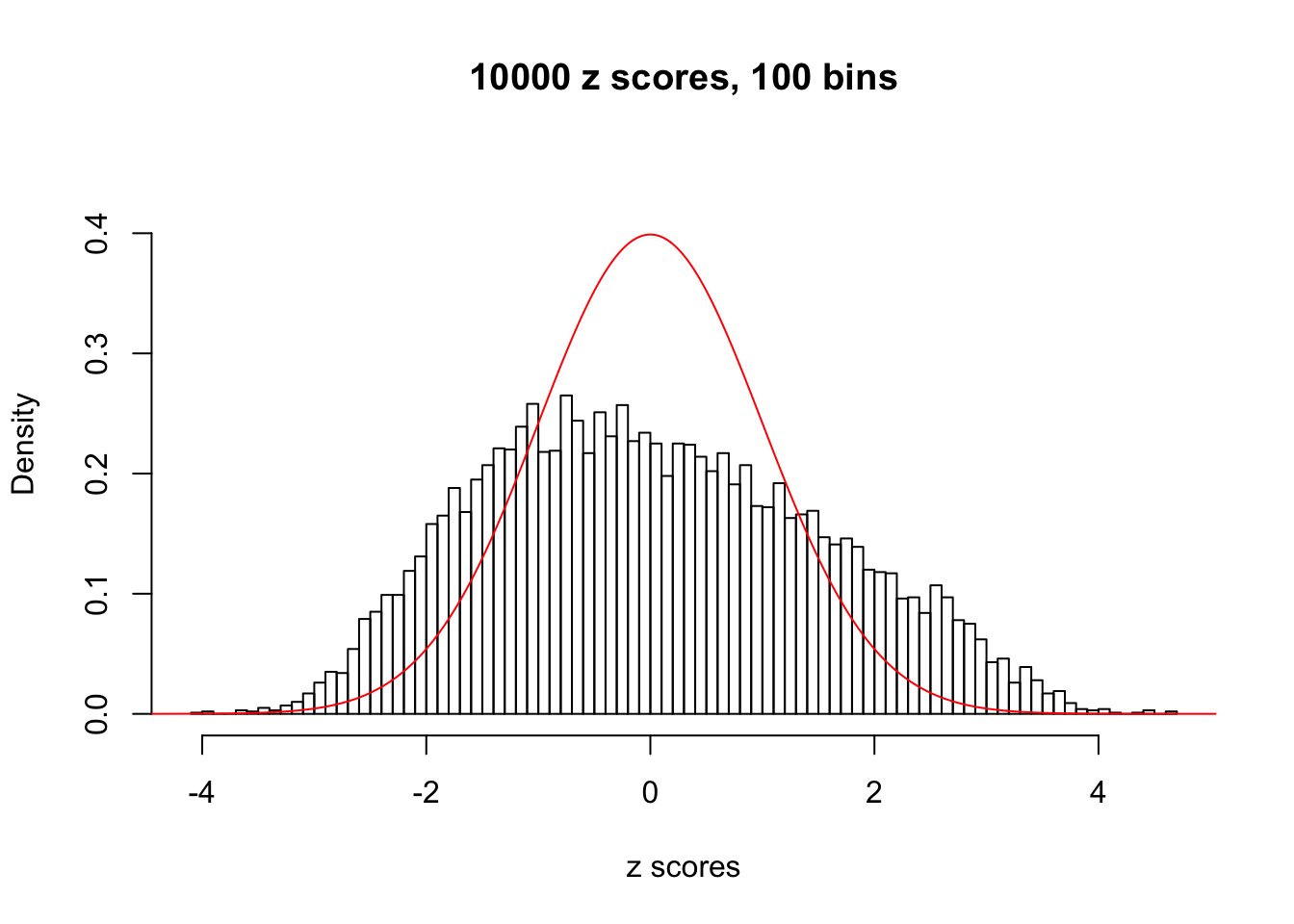
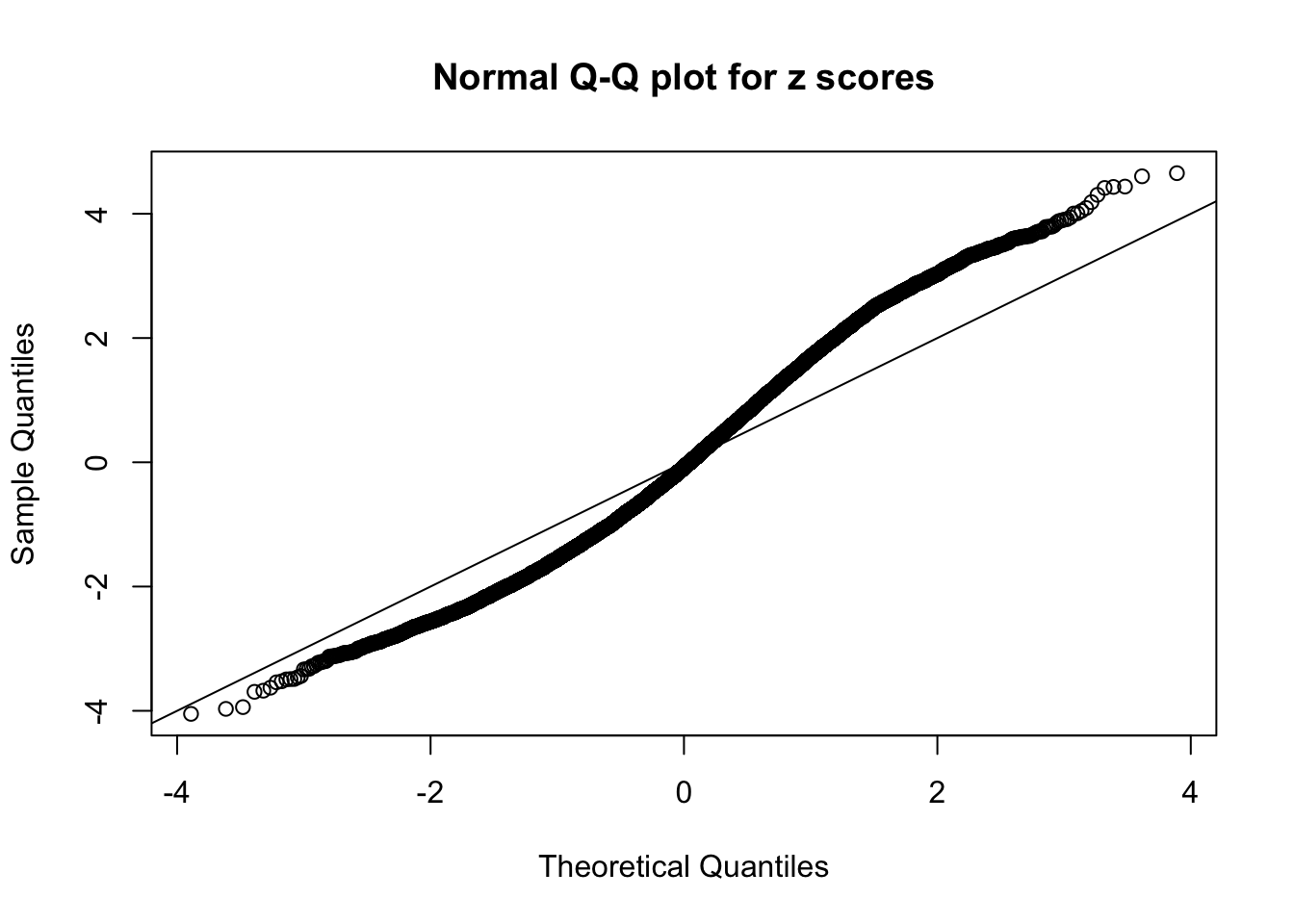
N0. 15 : Data Set 503 ; Number of False Discoveries: 7 ; pihat0 = 0.1545398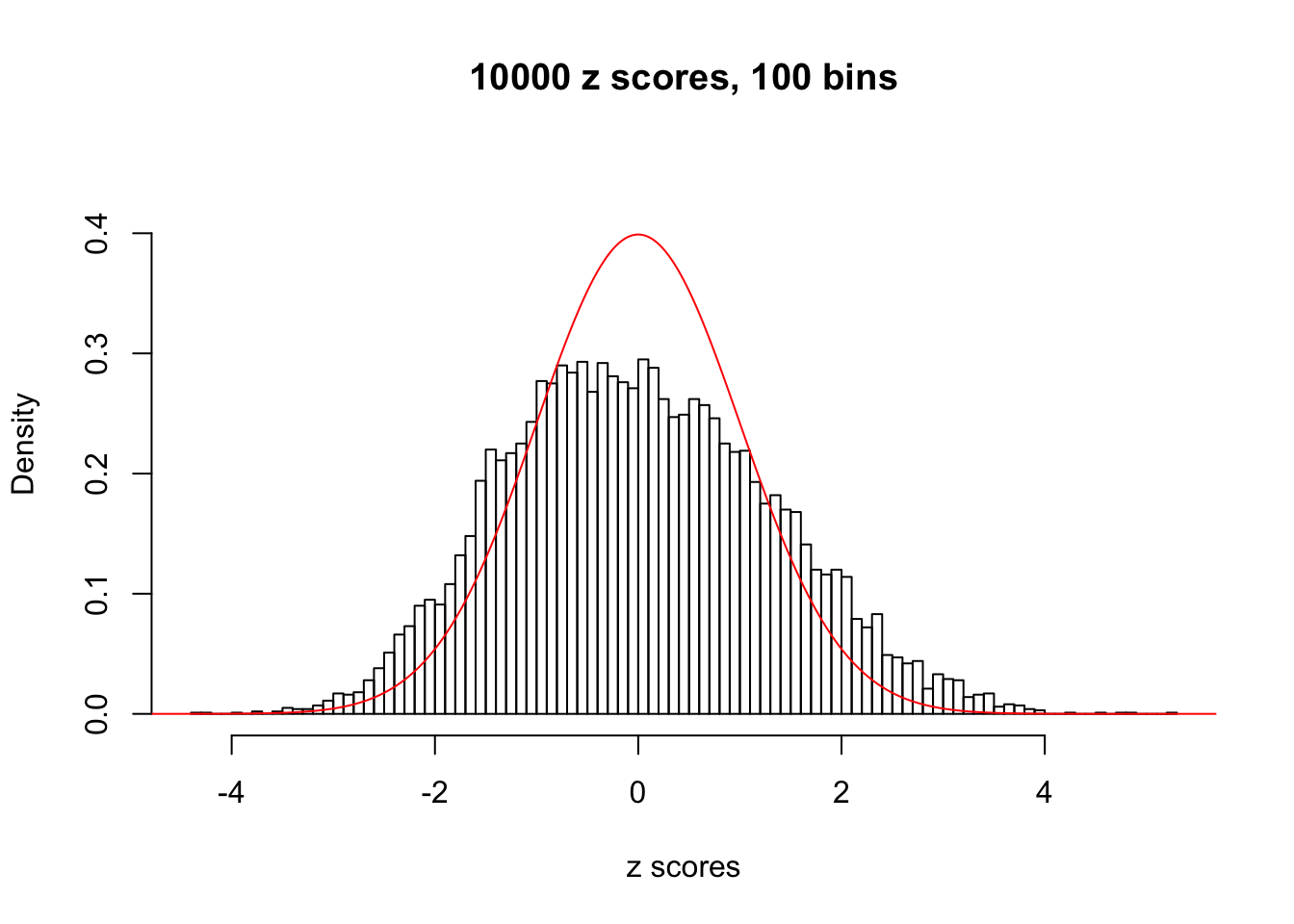
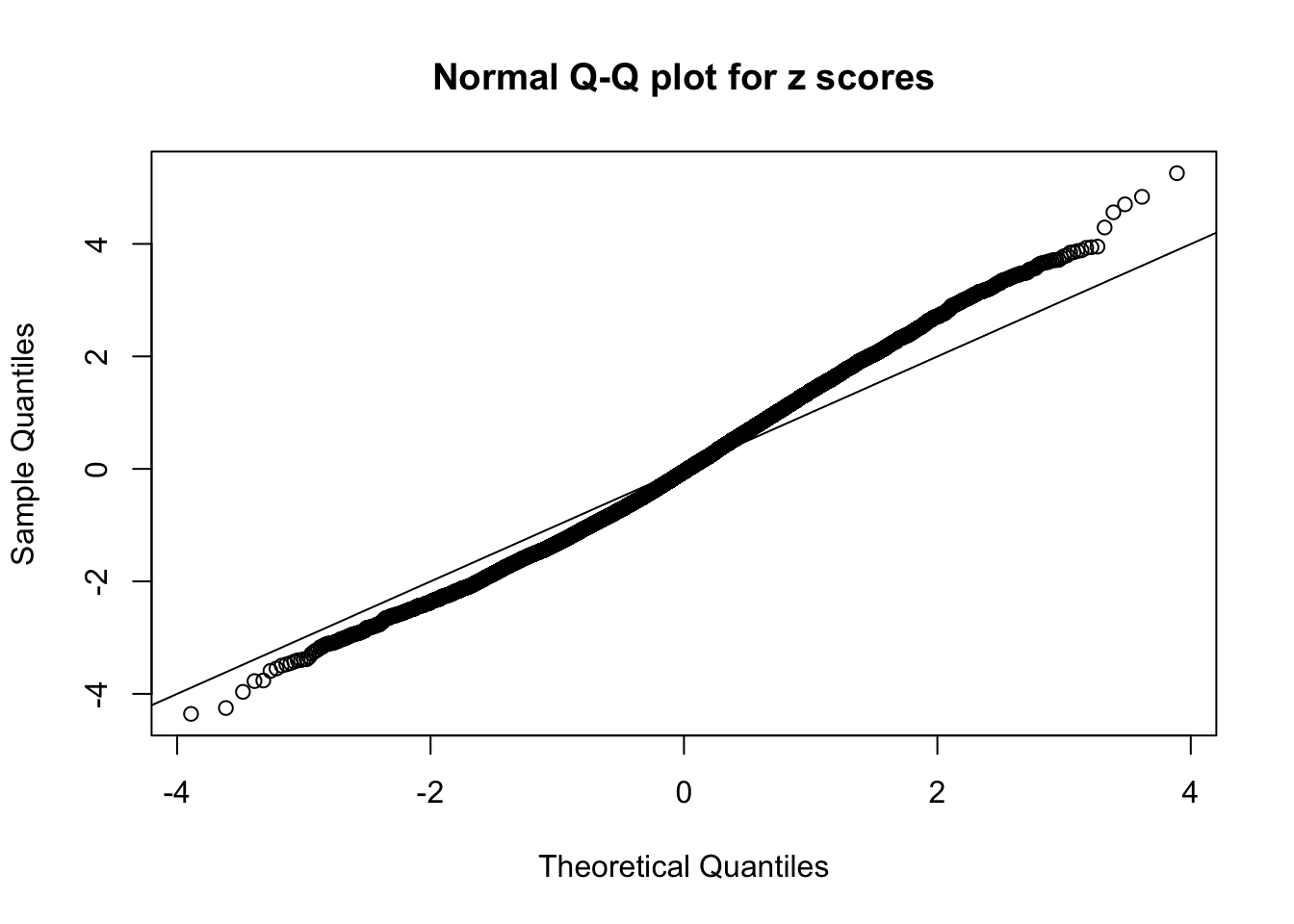
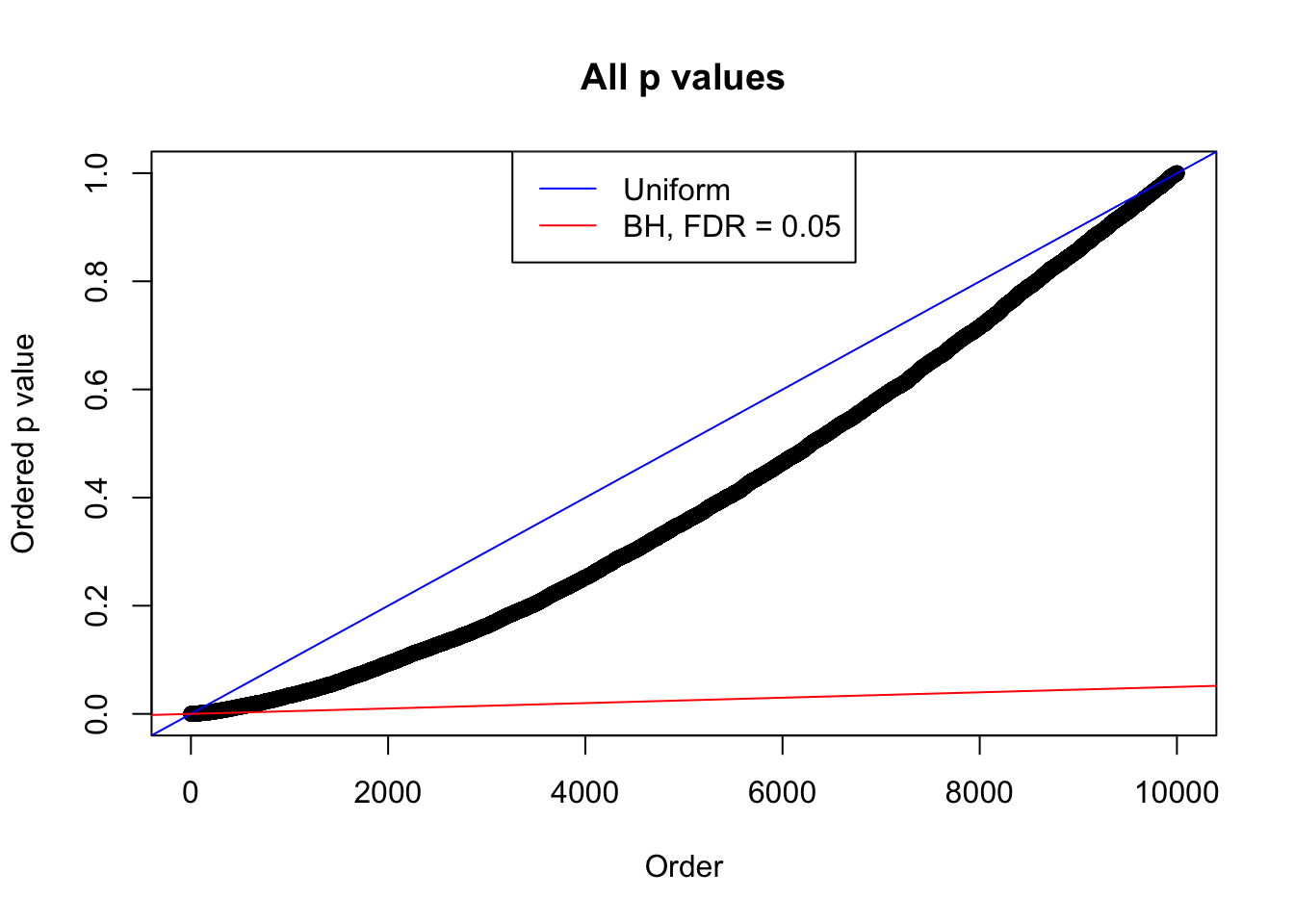
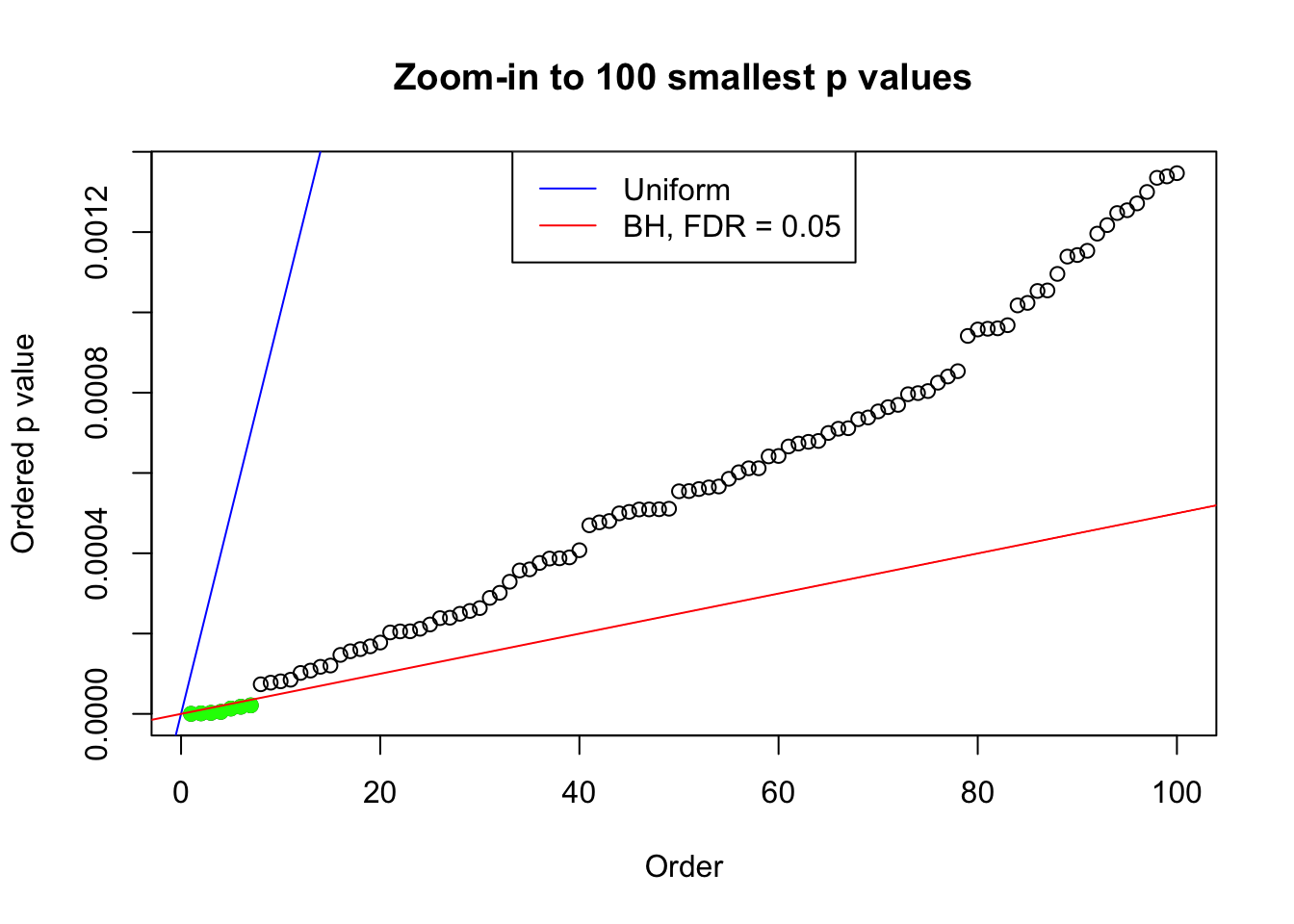
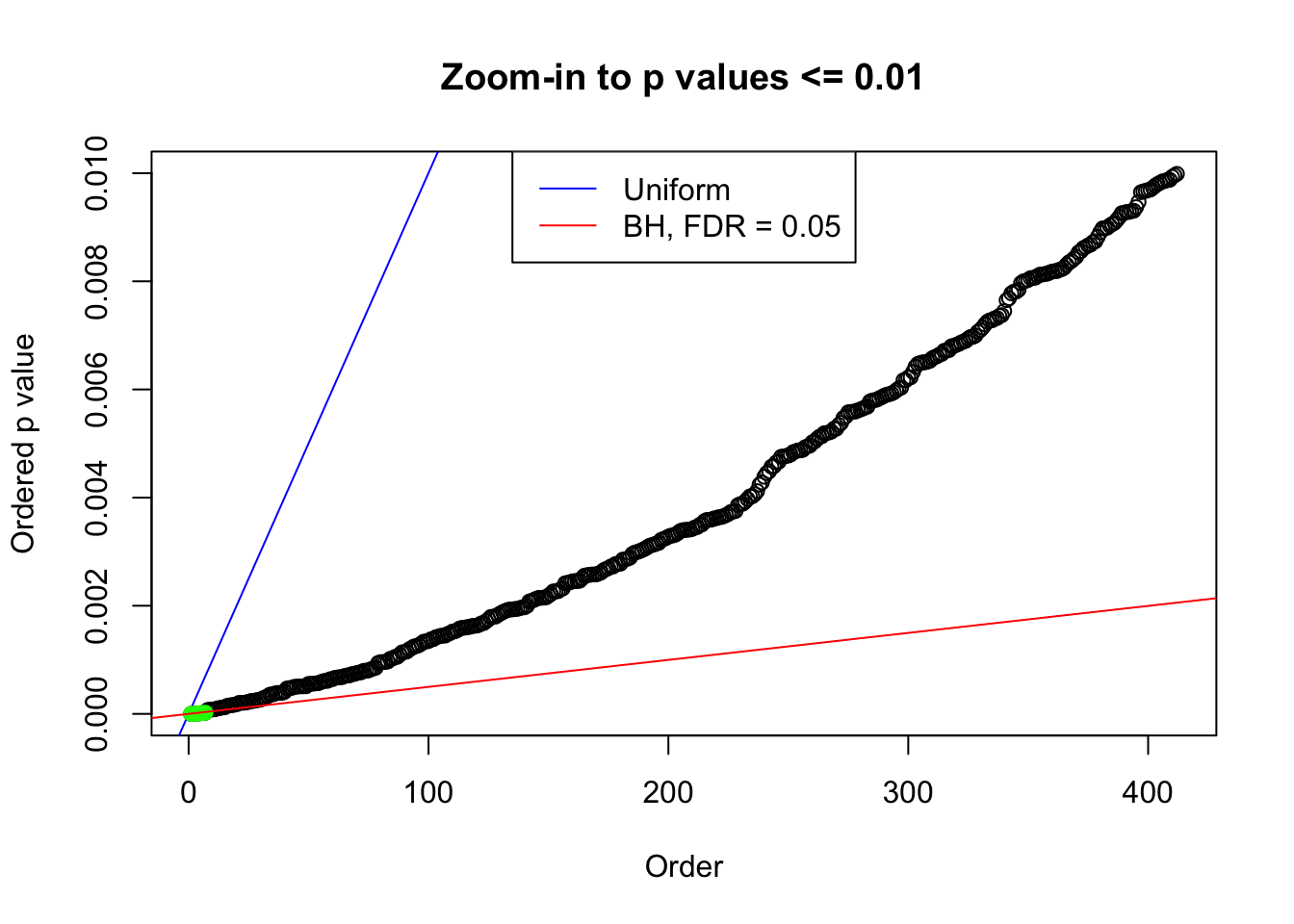
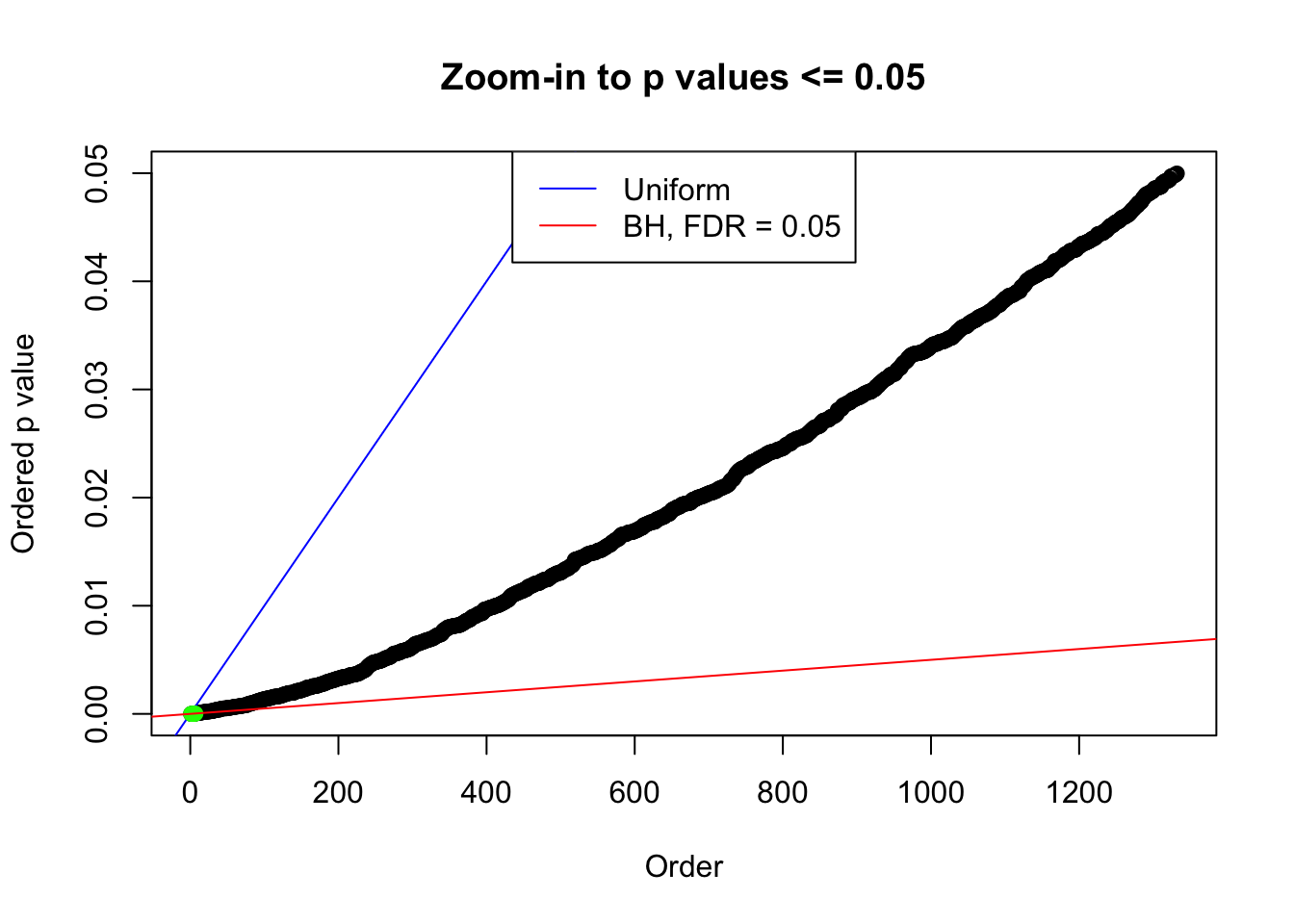
N0. 16 : Data Set 984 ; Number of False Discoveries: 7 ; pihat0 = 0.04567195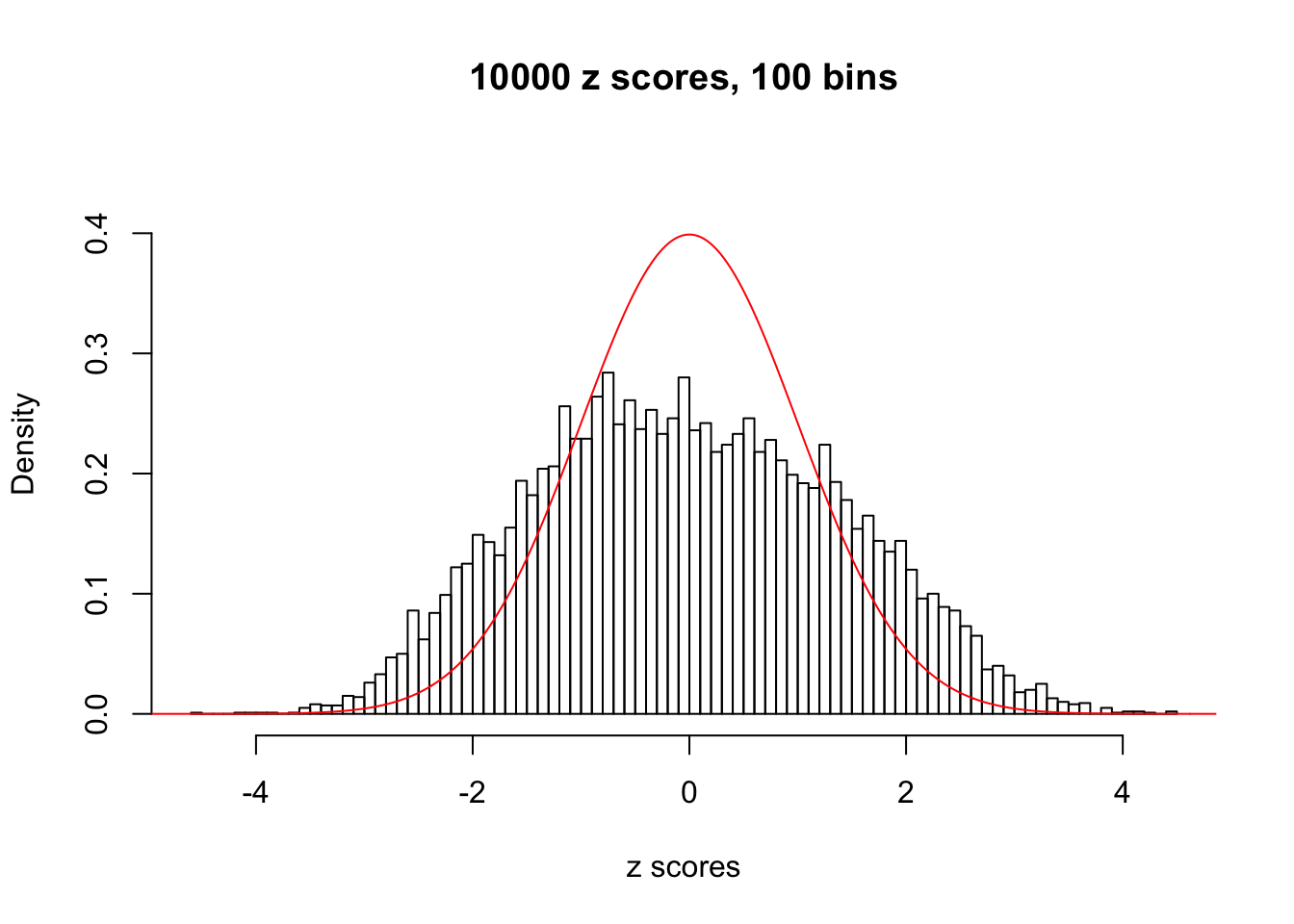
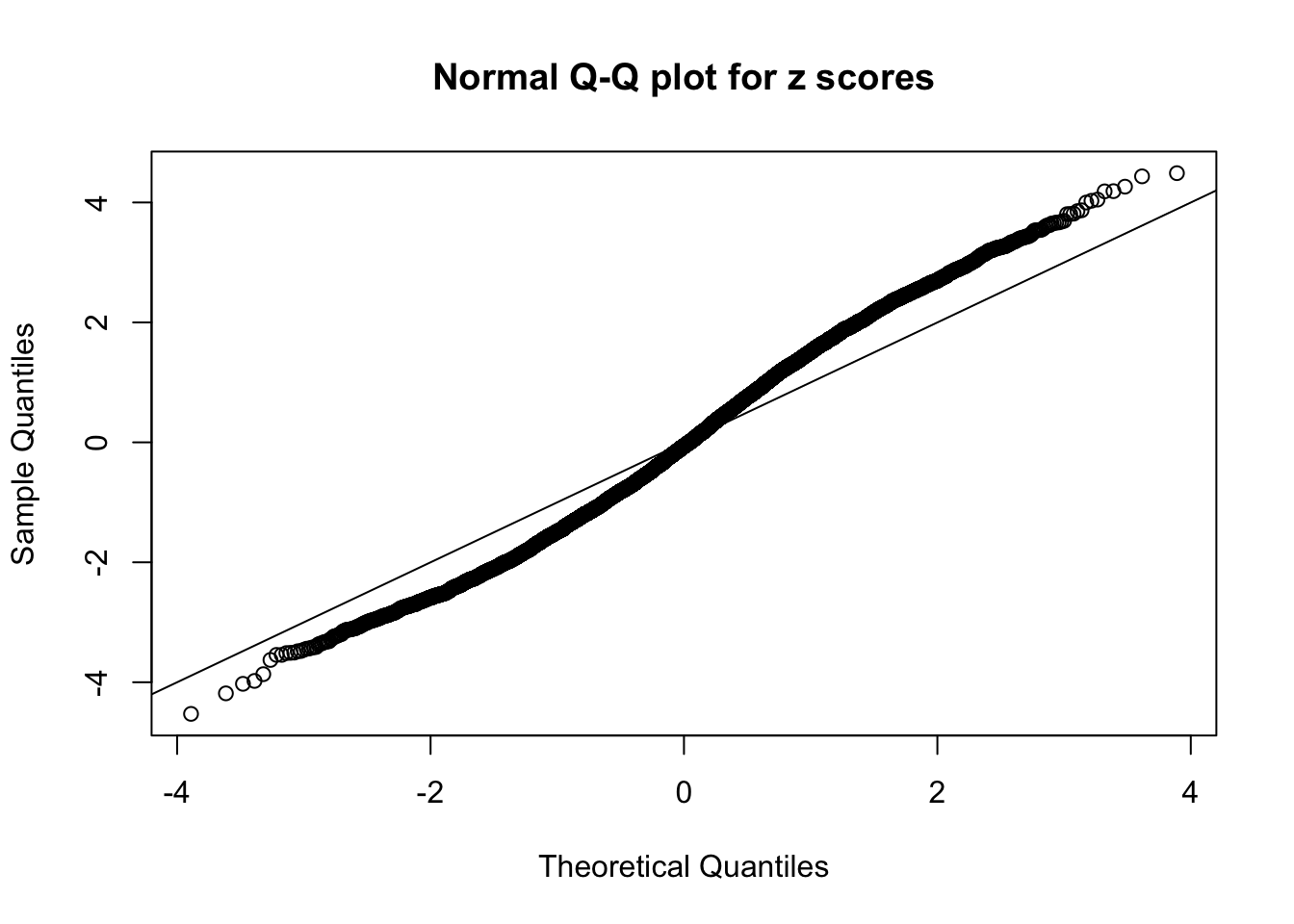
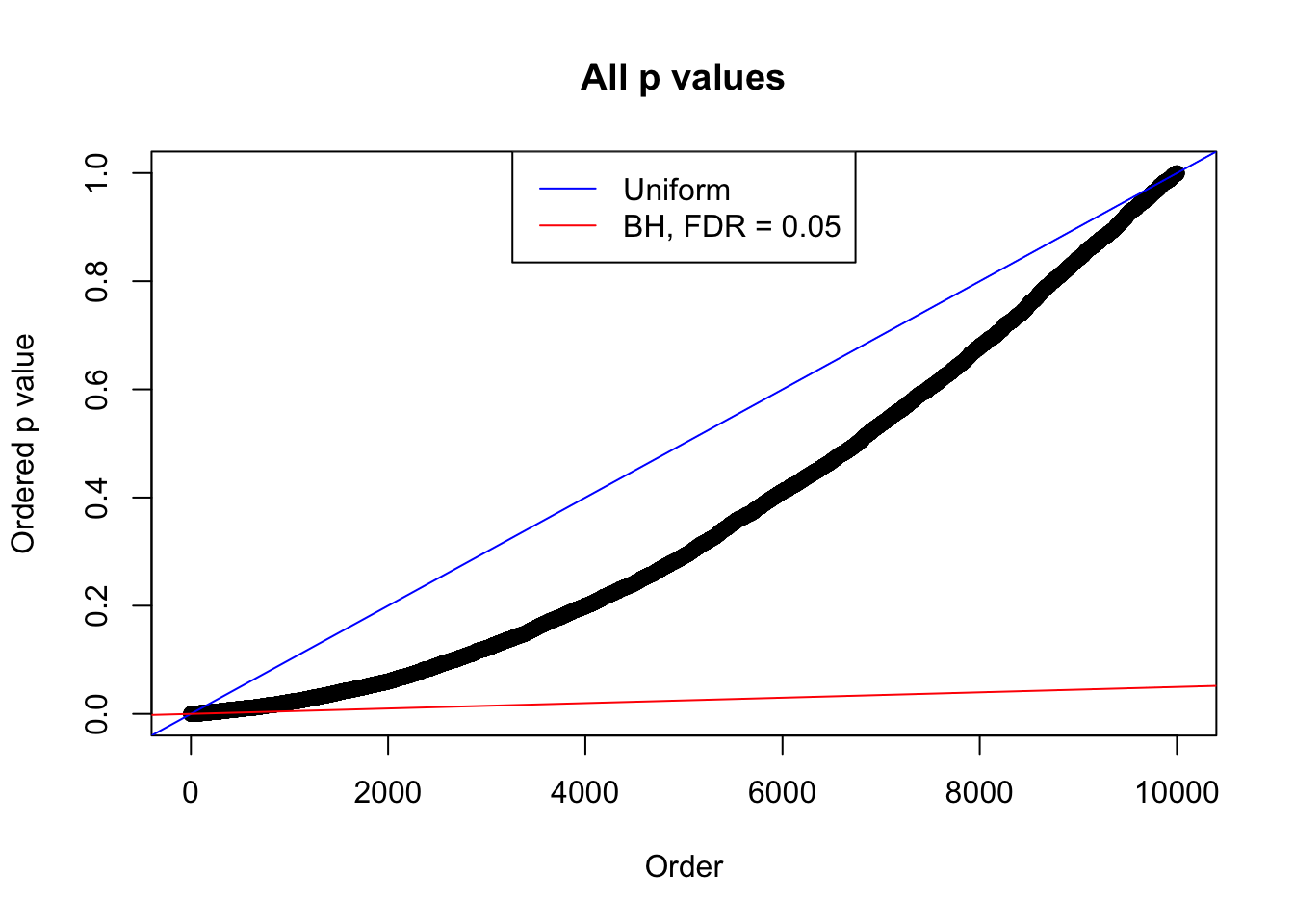
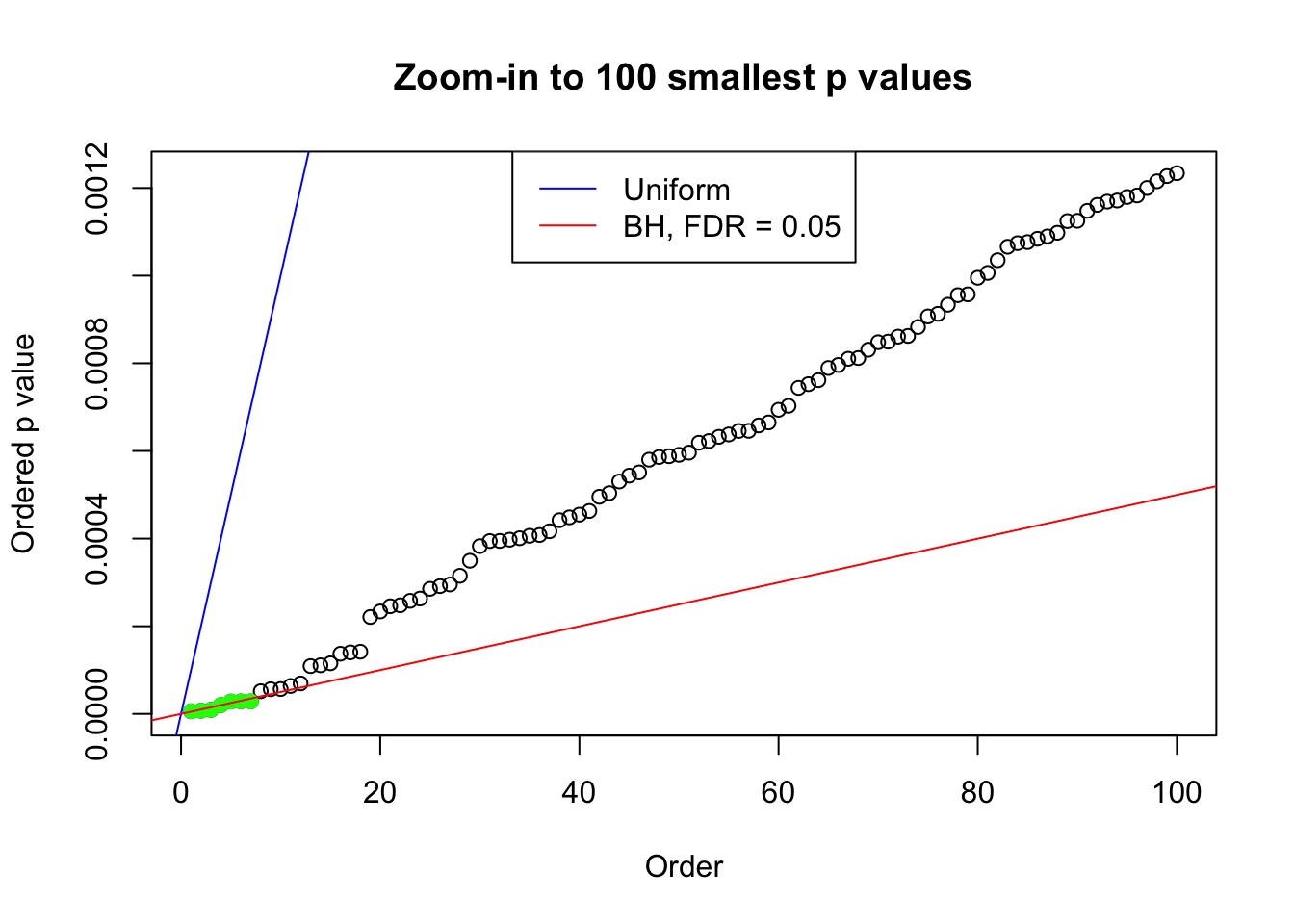
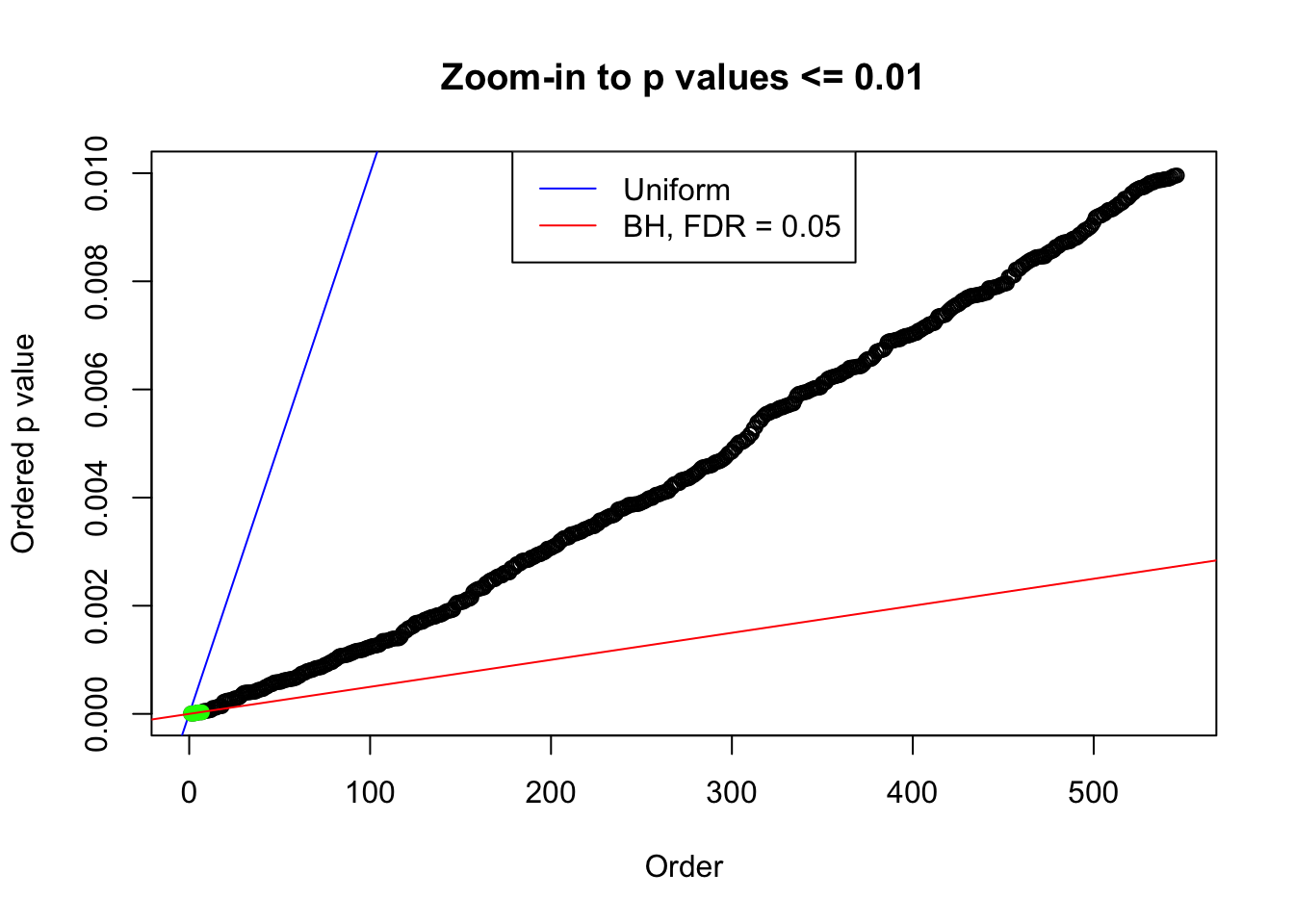
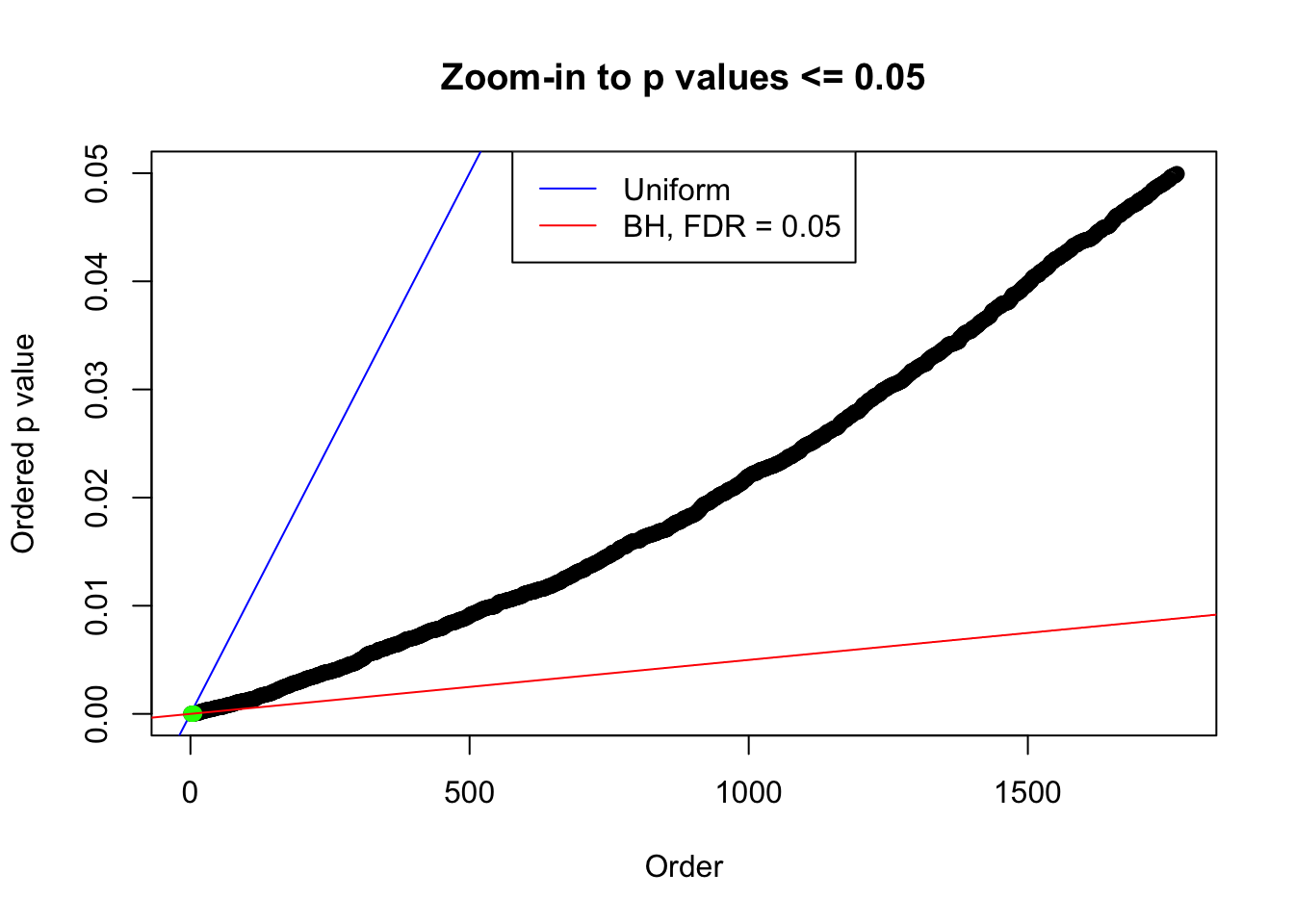
N0. 17 : Data Set 360 ; Number of False Discoveries: 6 ; pihat0 = 0.0308234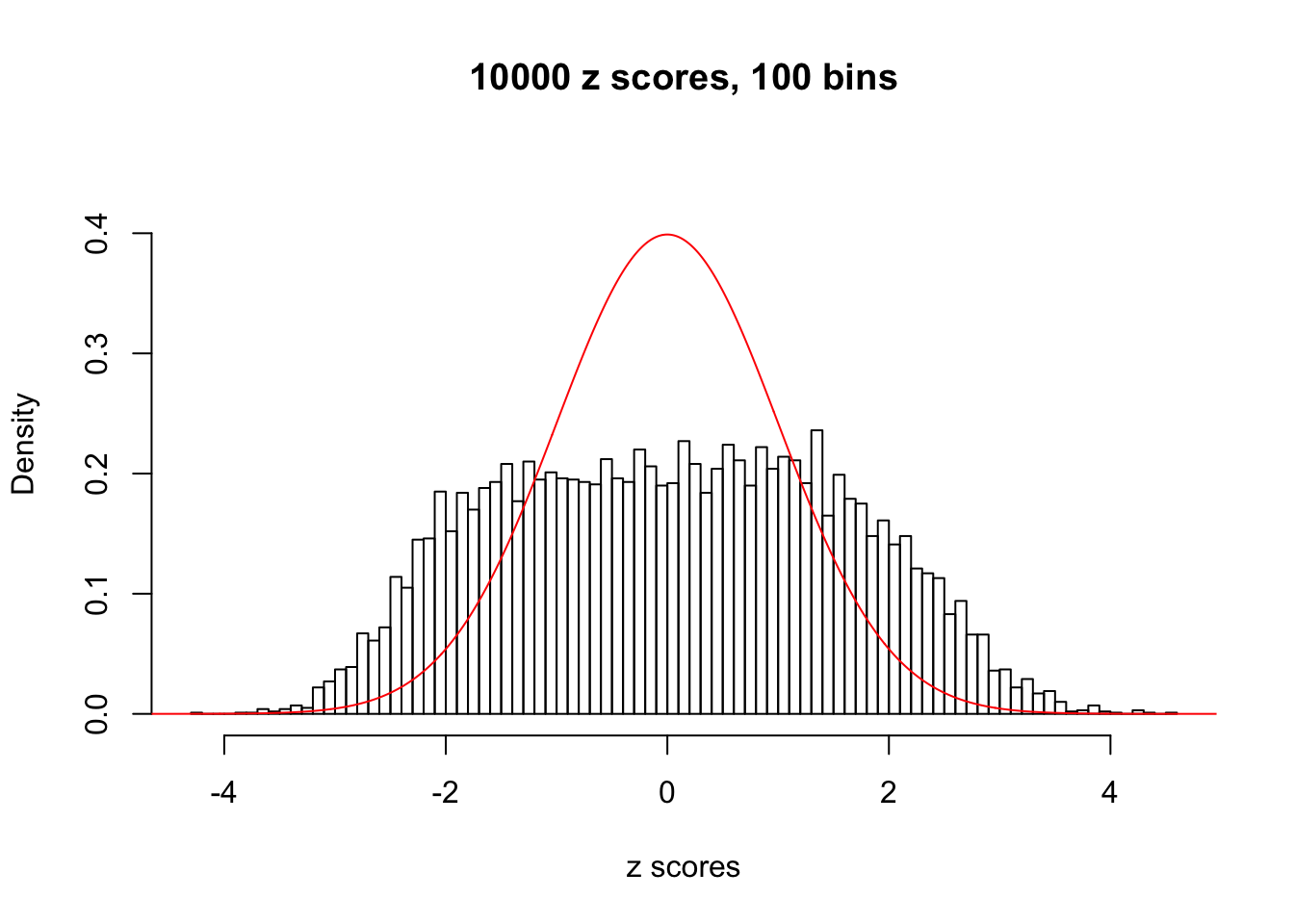
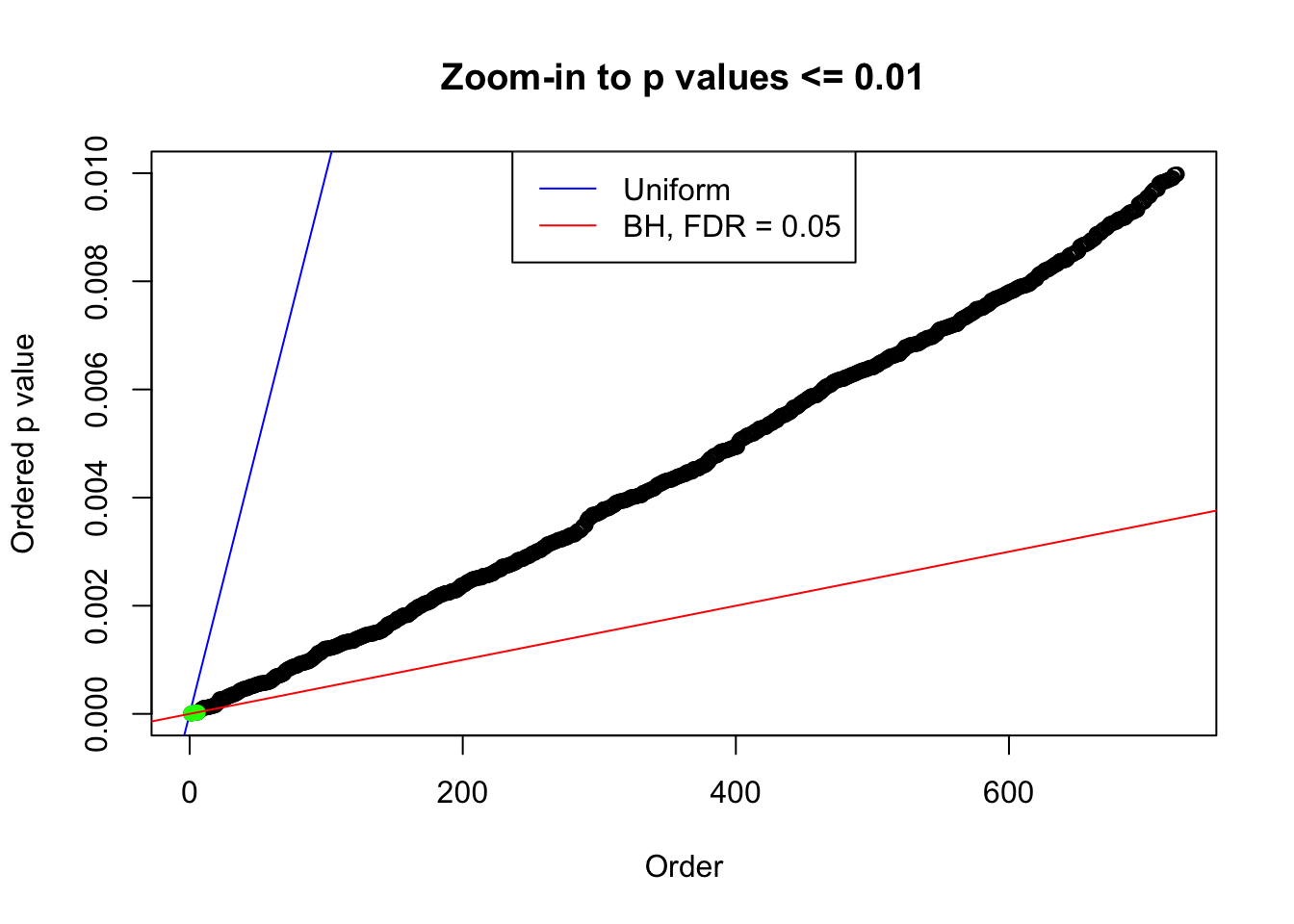
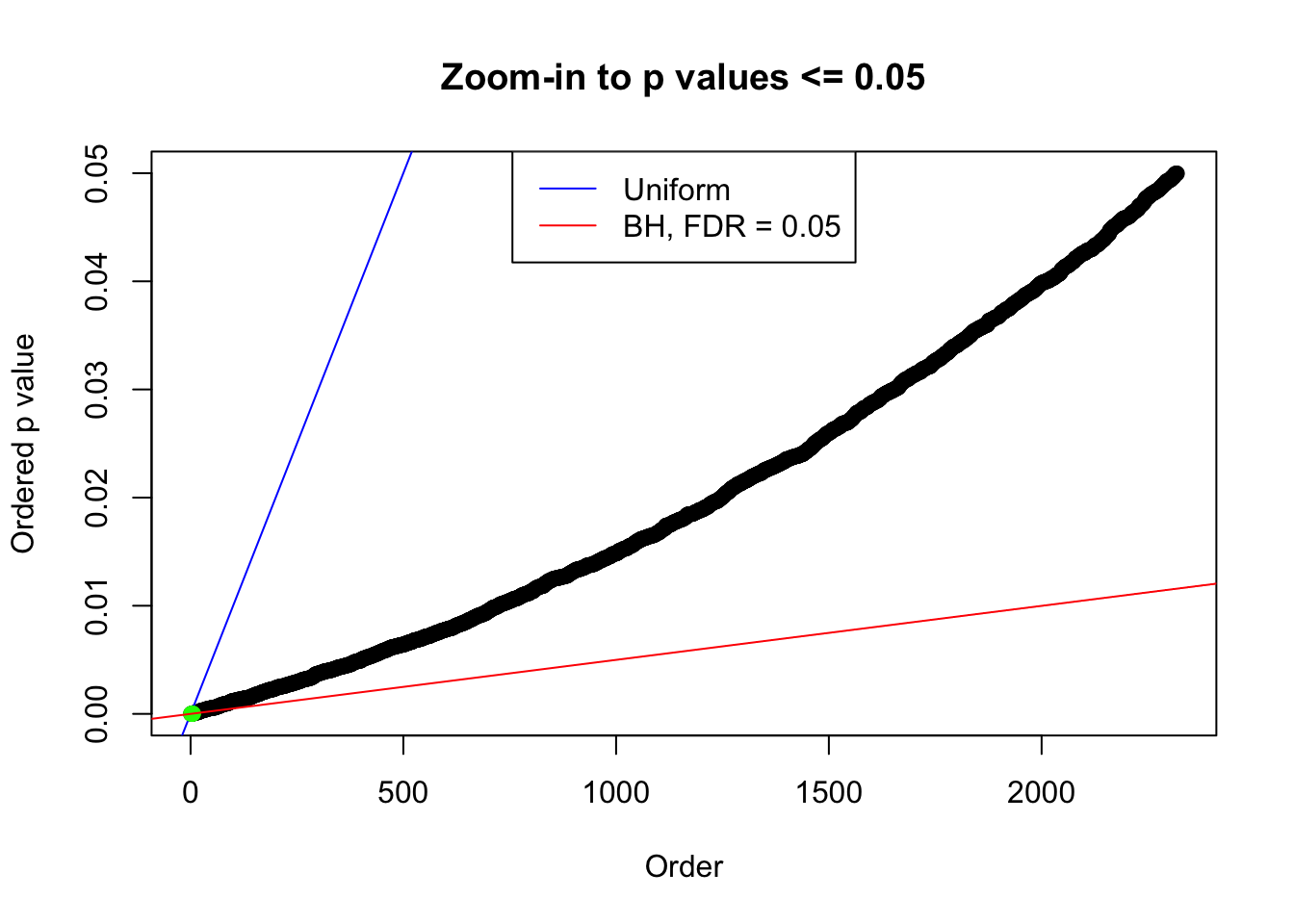
N0. 18 : Data Set 522 ; Number of False Discoveries: 4 ; pihat0 = 0.02083846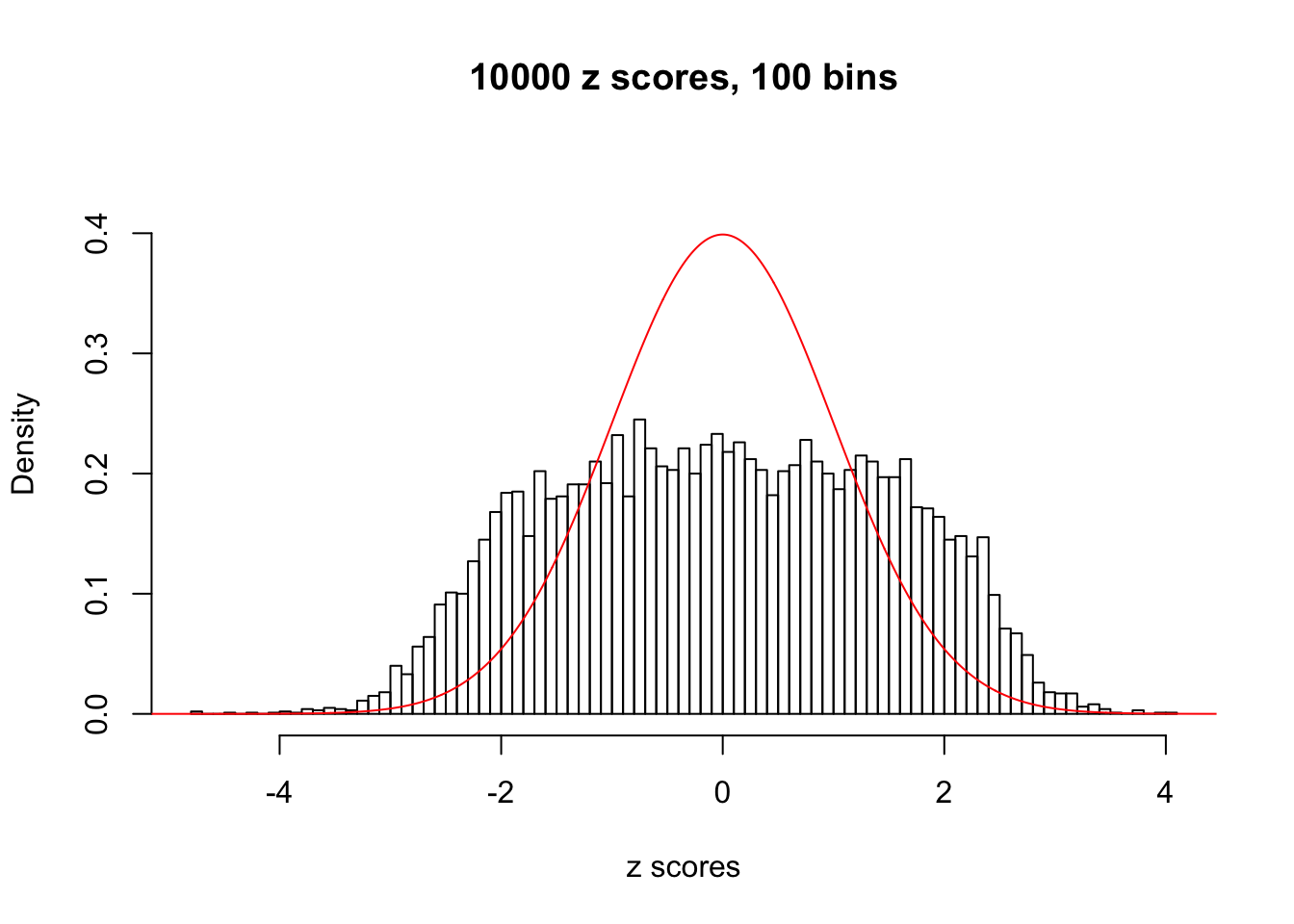
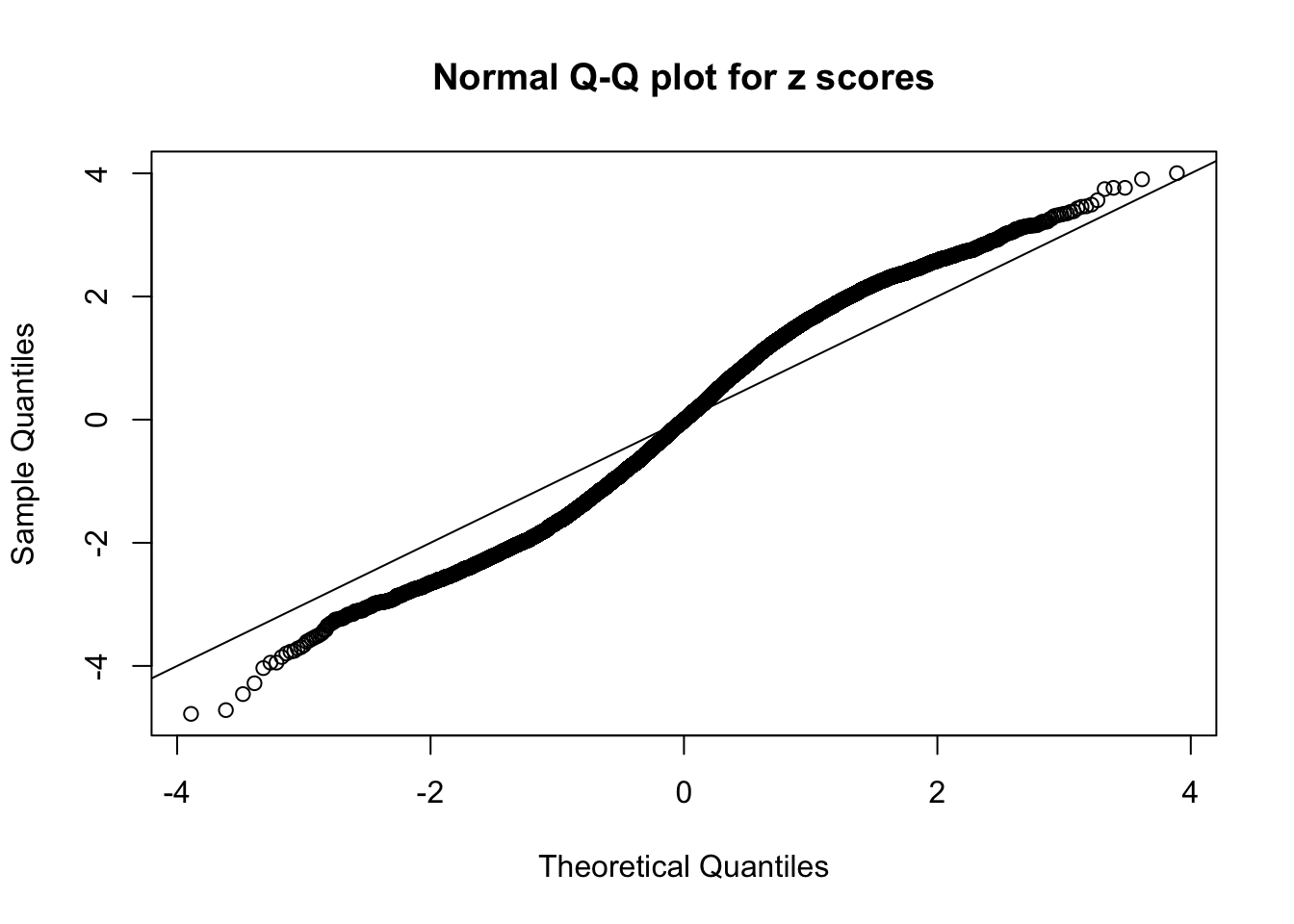
N0. 19 : Data Set 51 ; Number of False Discoveries: 3 ; pihat0 = 0.2435437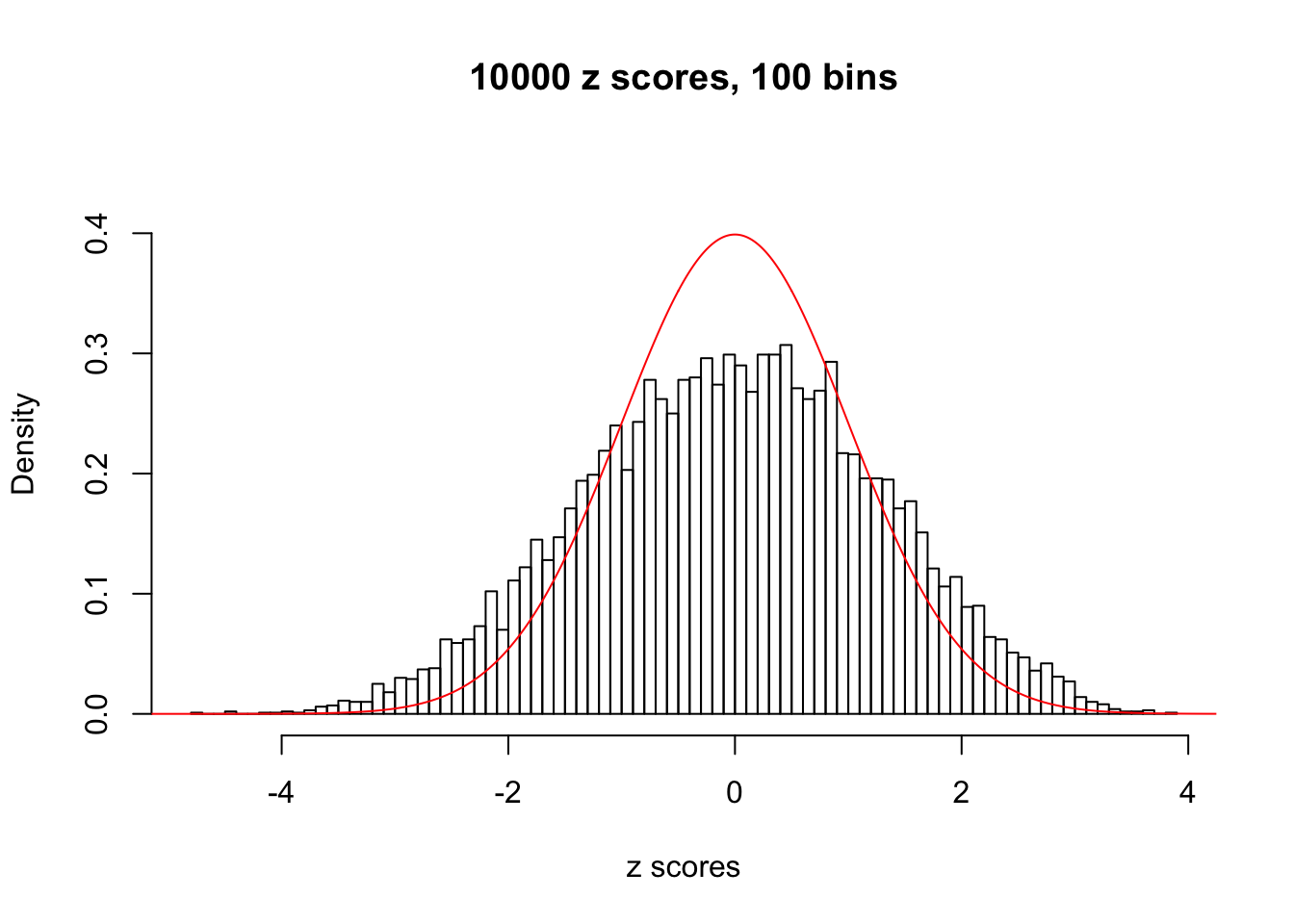
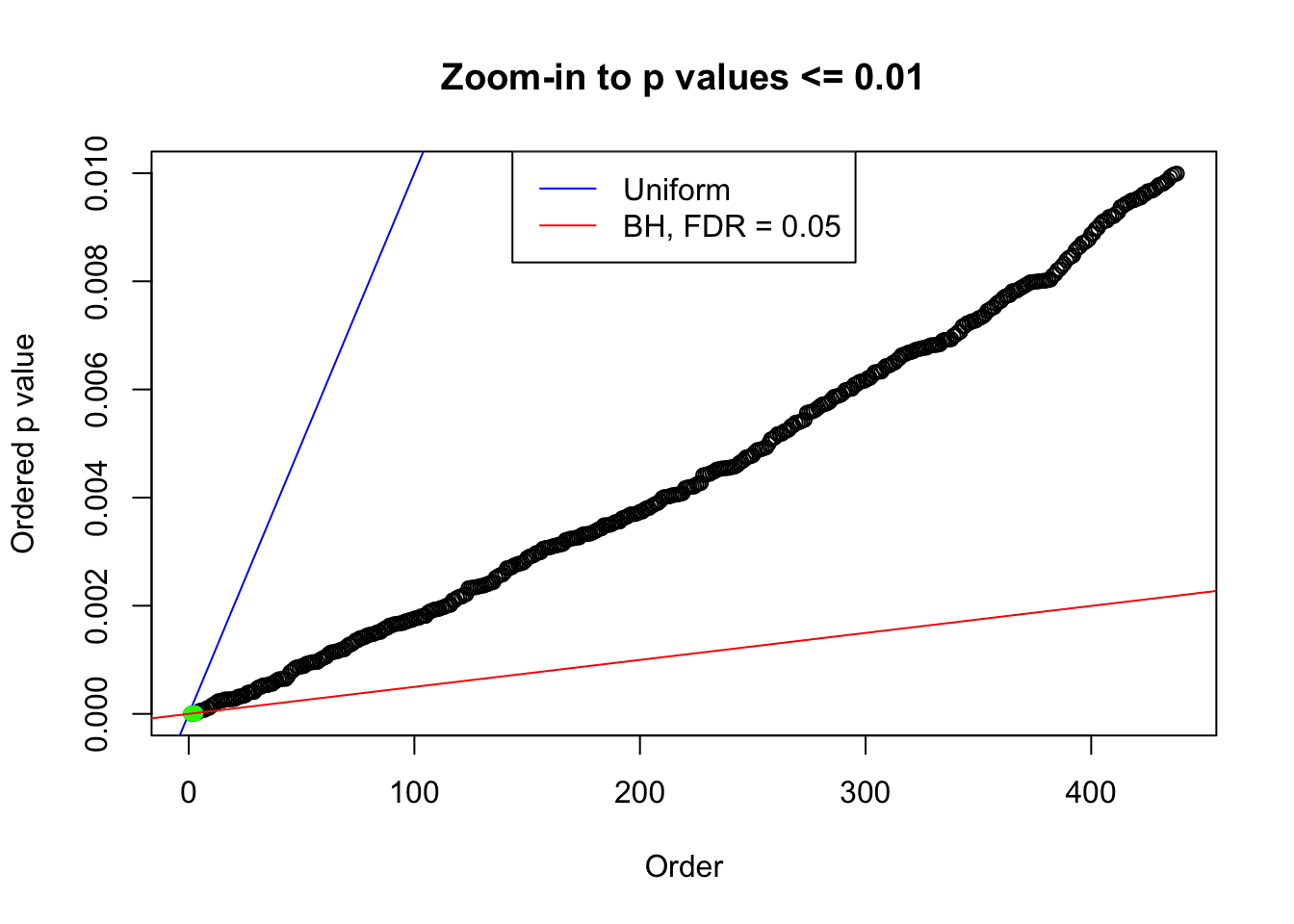
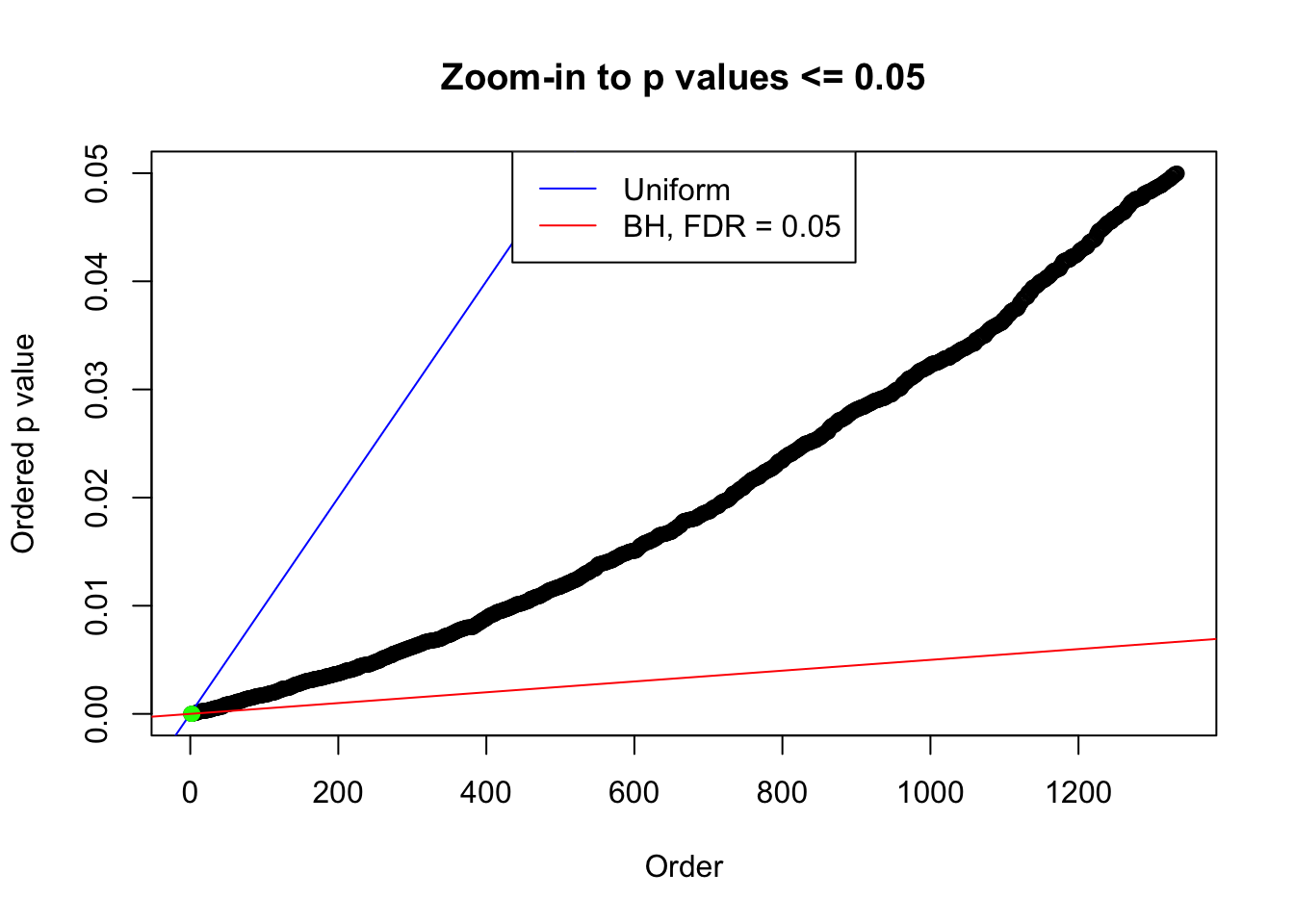
N0. 20 : Data Set 316 ; Number of False Discoveries: 3 ; pihat0 = 0.2961358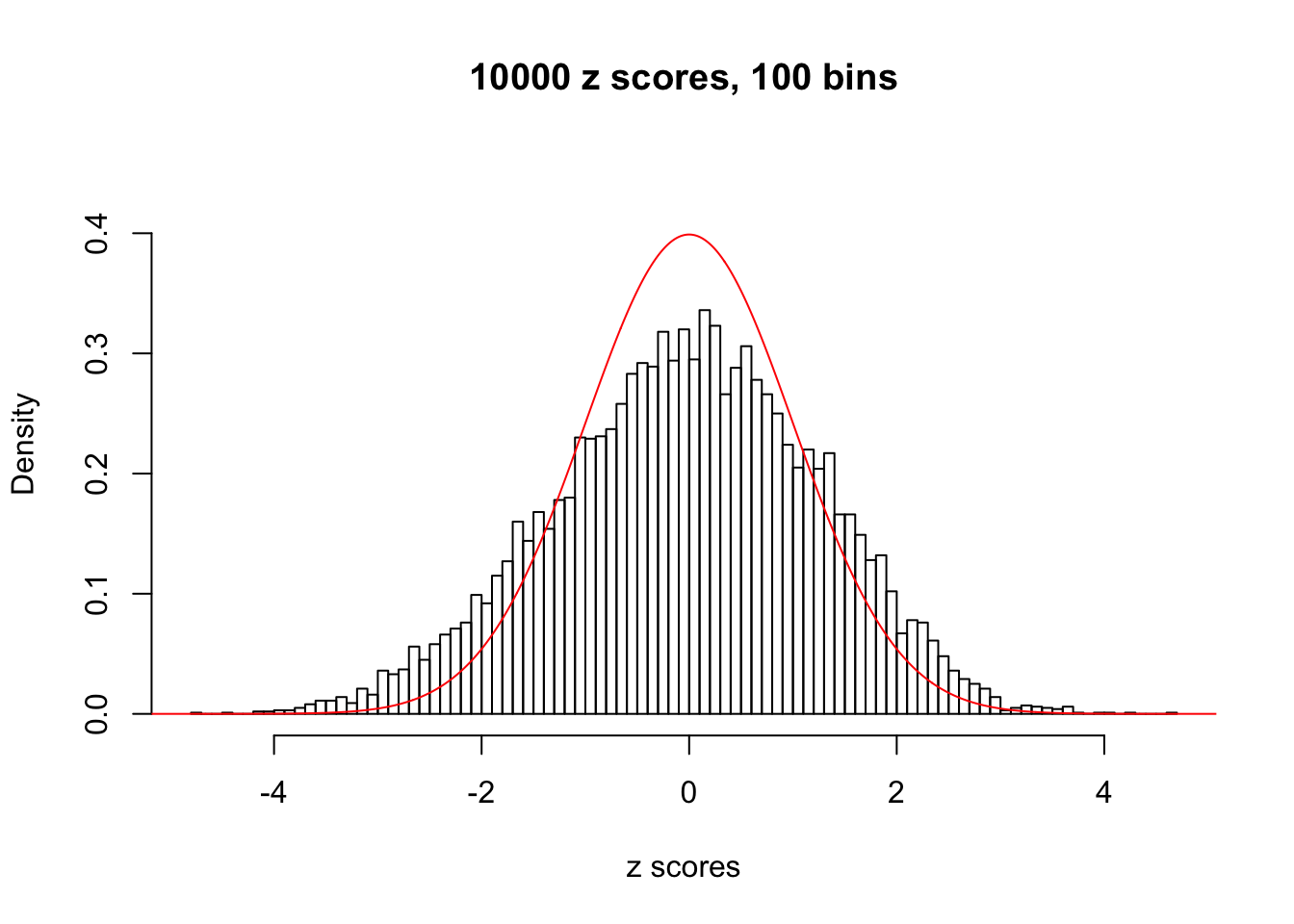
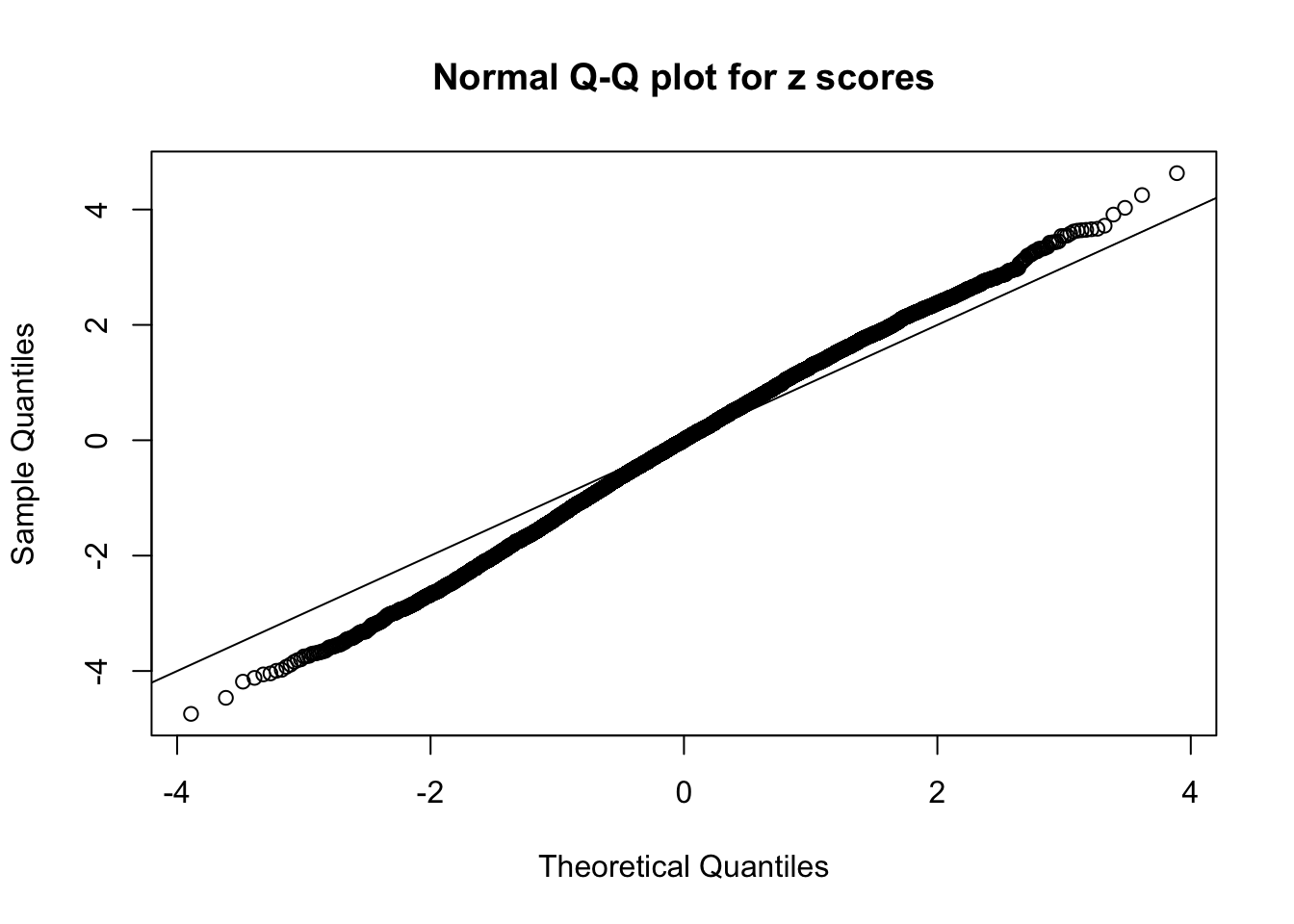
N0. 21 : Data Set 663 ; Number of False Discoveries: 3 ; pihat0 = 0.2818026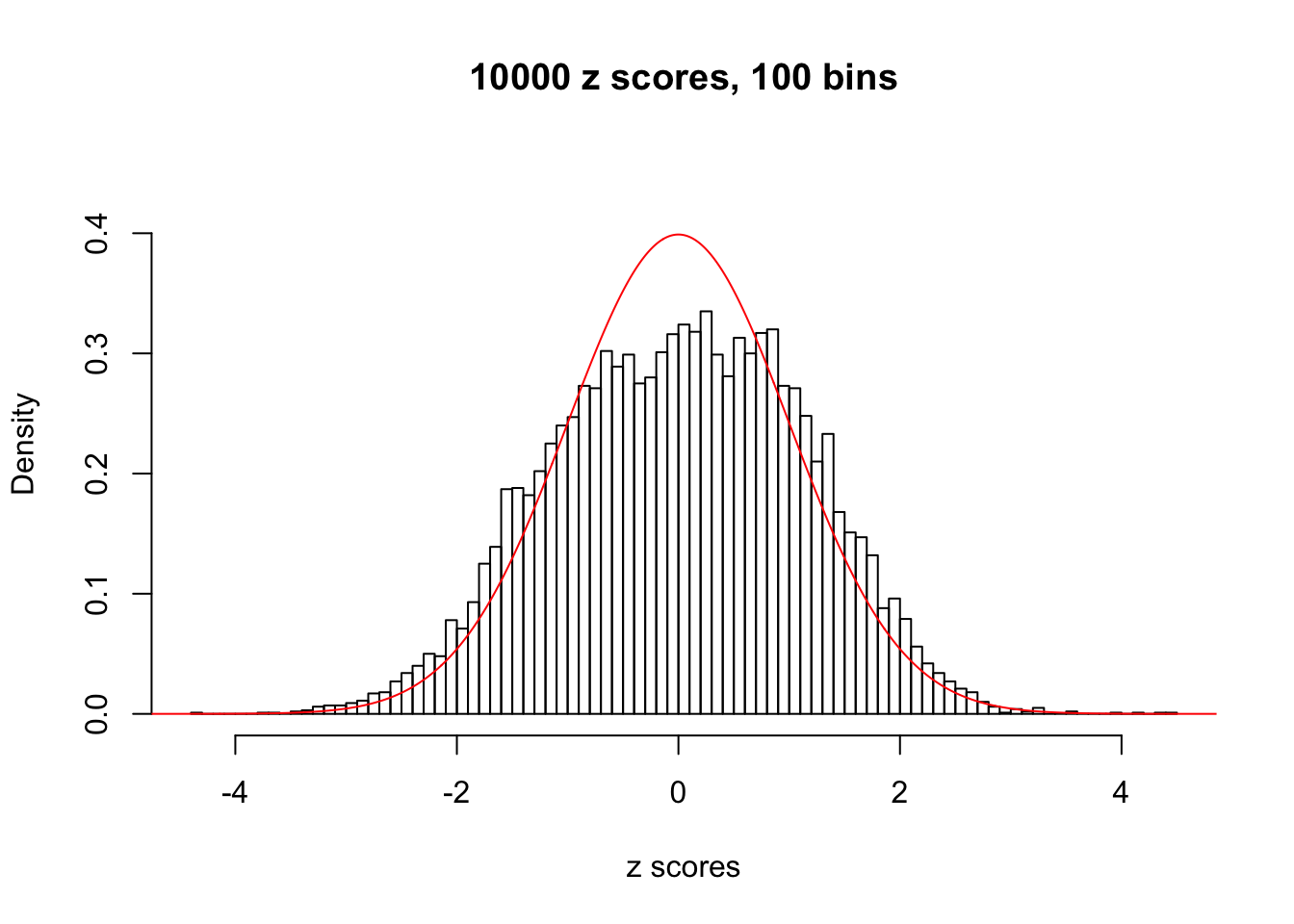
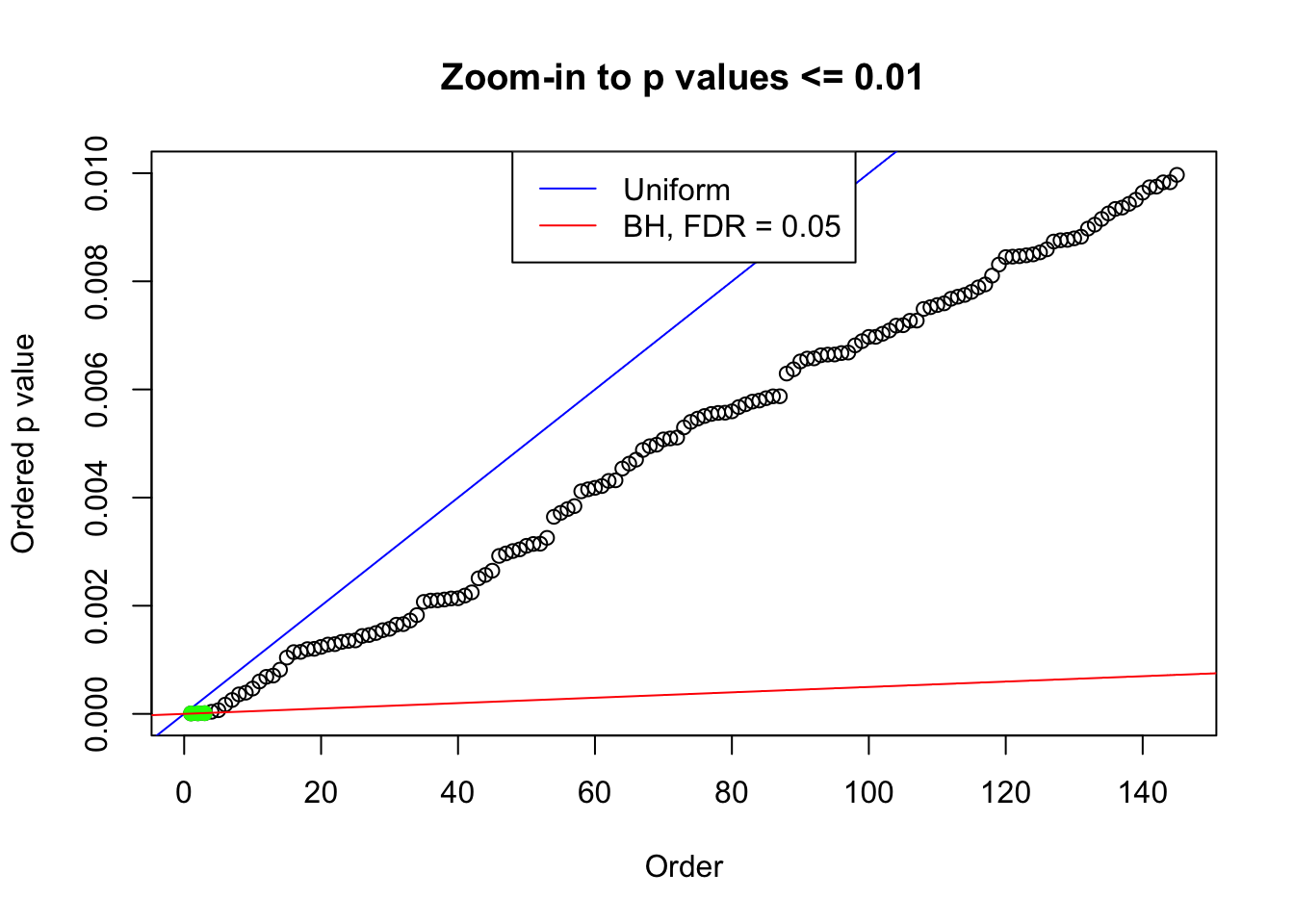
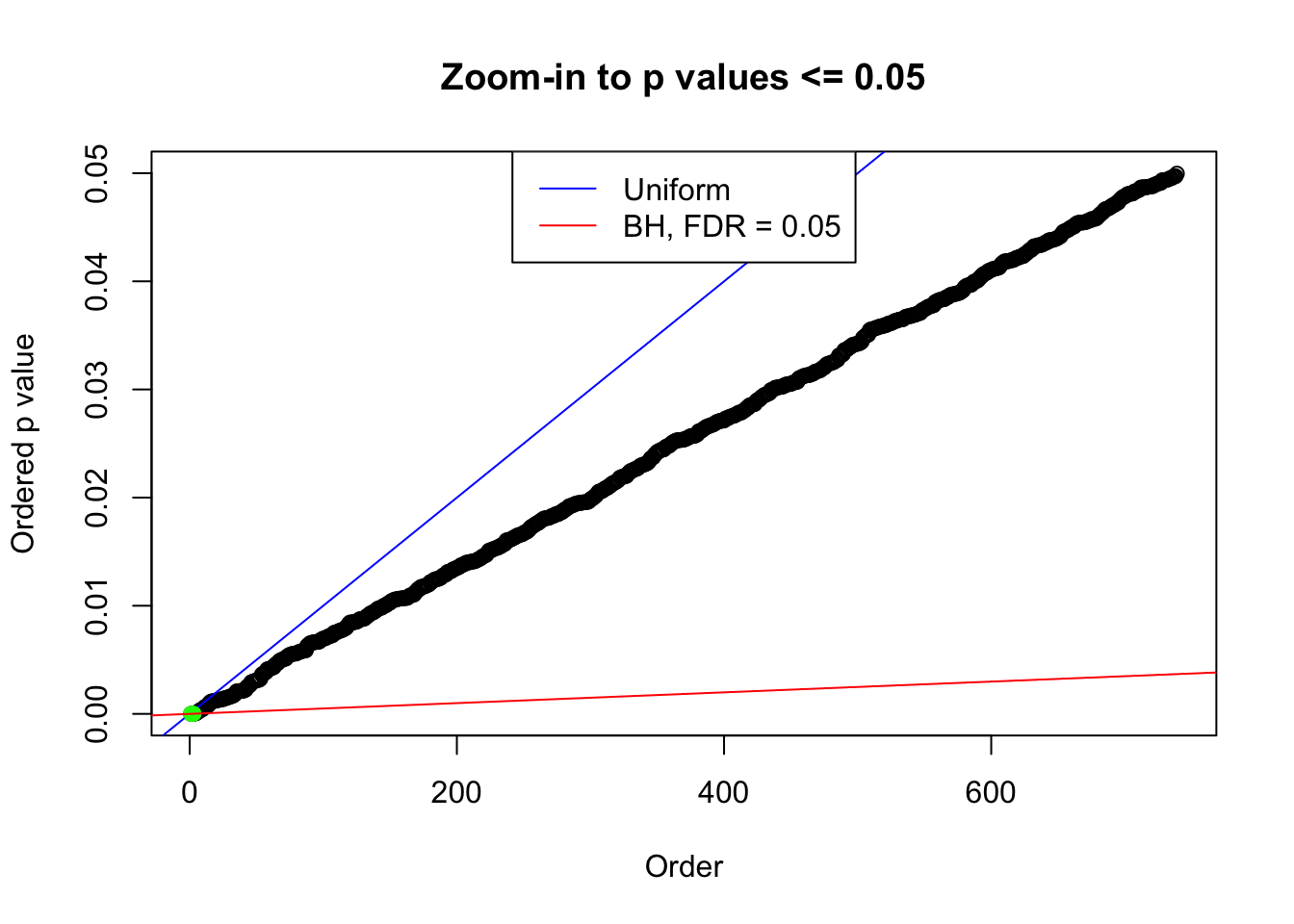
N0. 22 : Data Set 274 ; Number of False Discoveries: 2 ; pihat0 = 0.08580661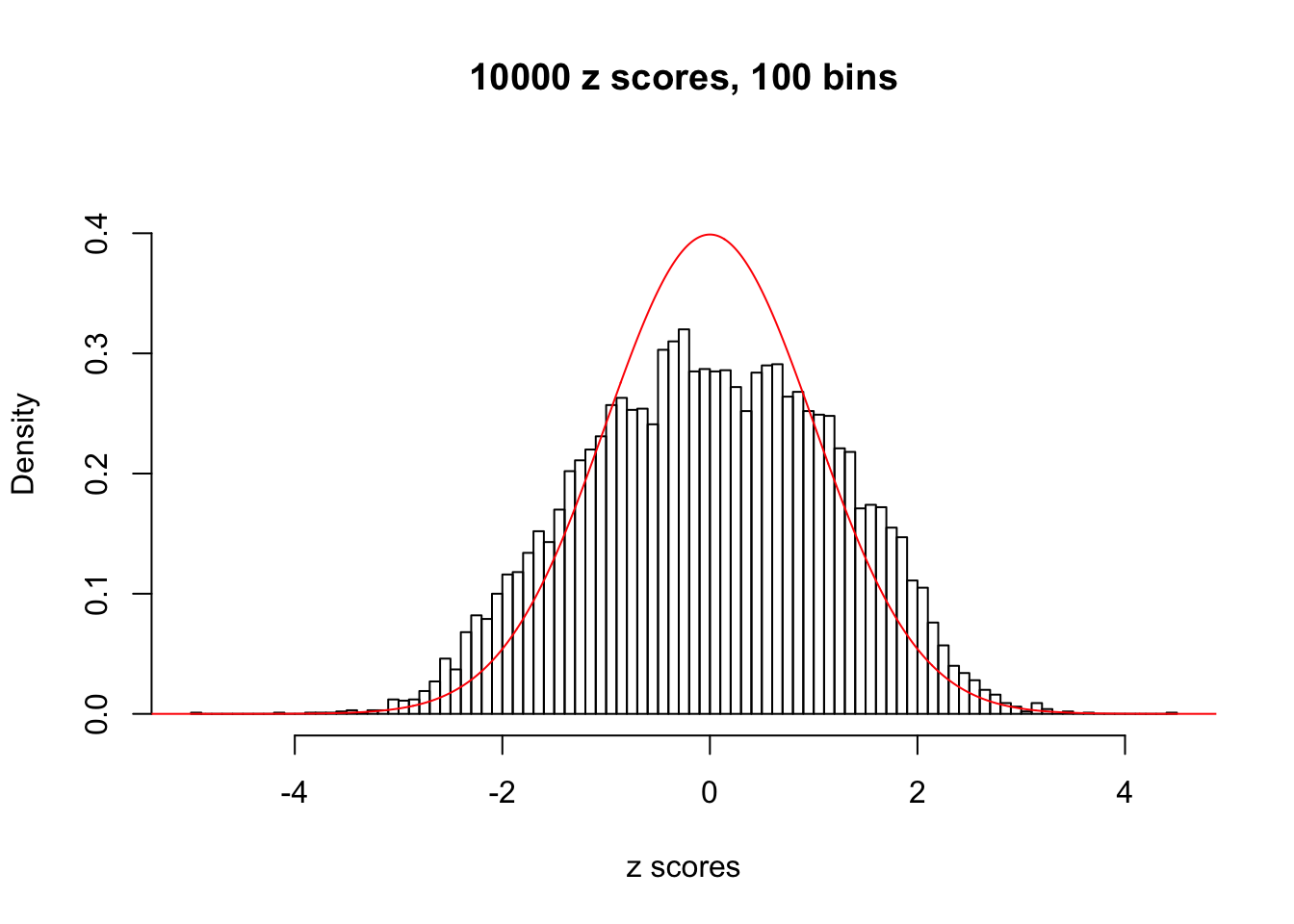
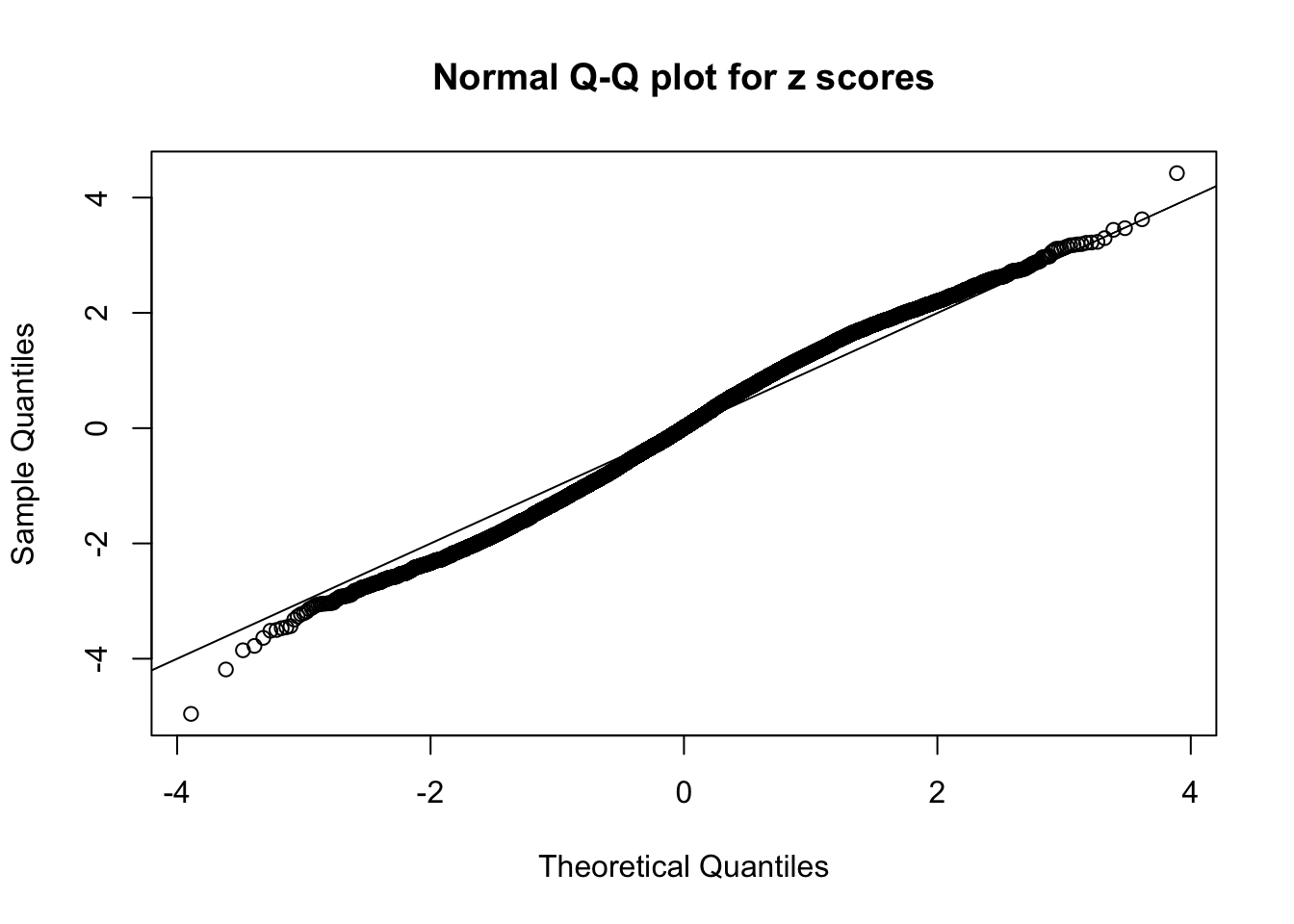
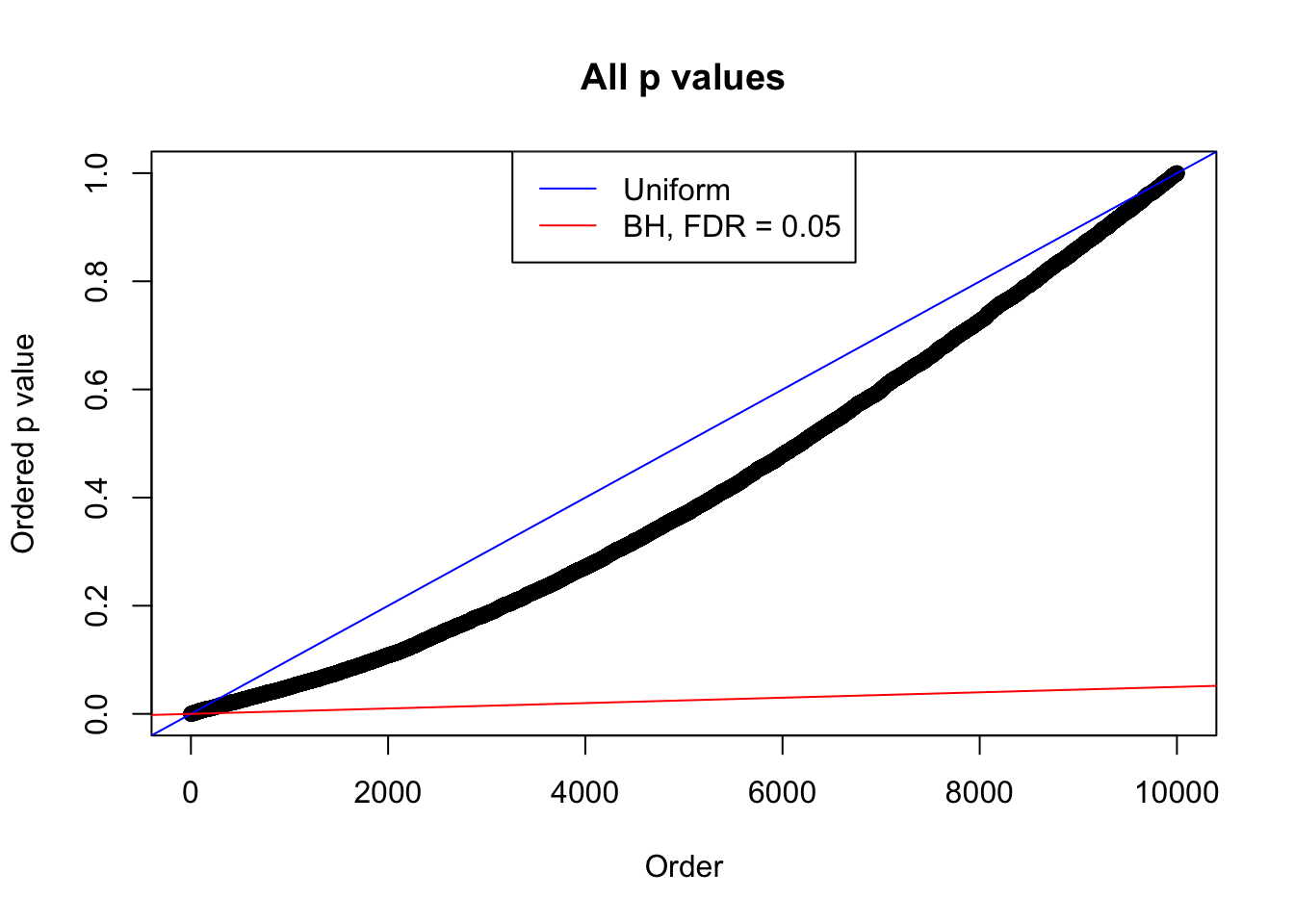
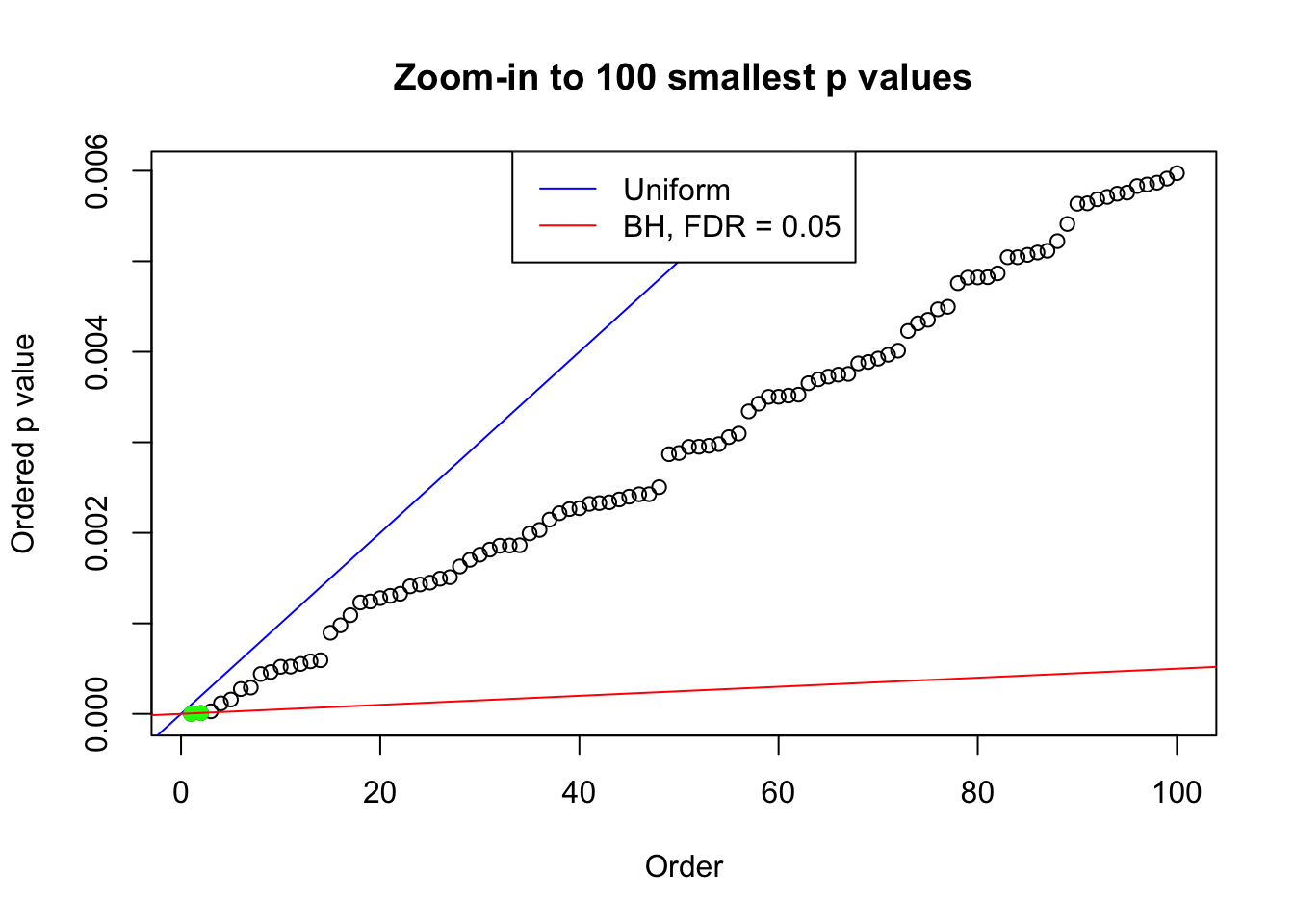
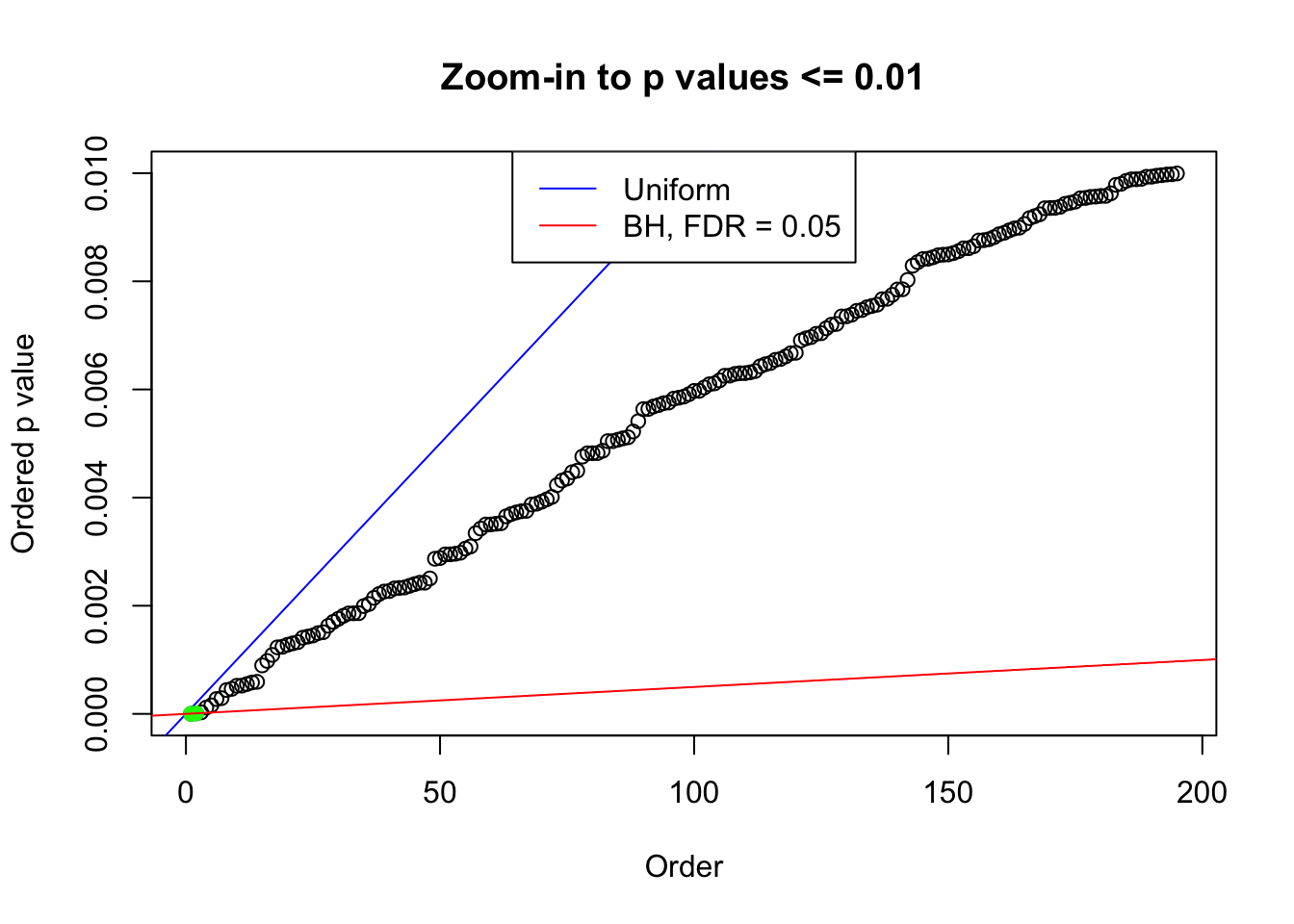
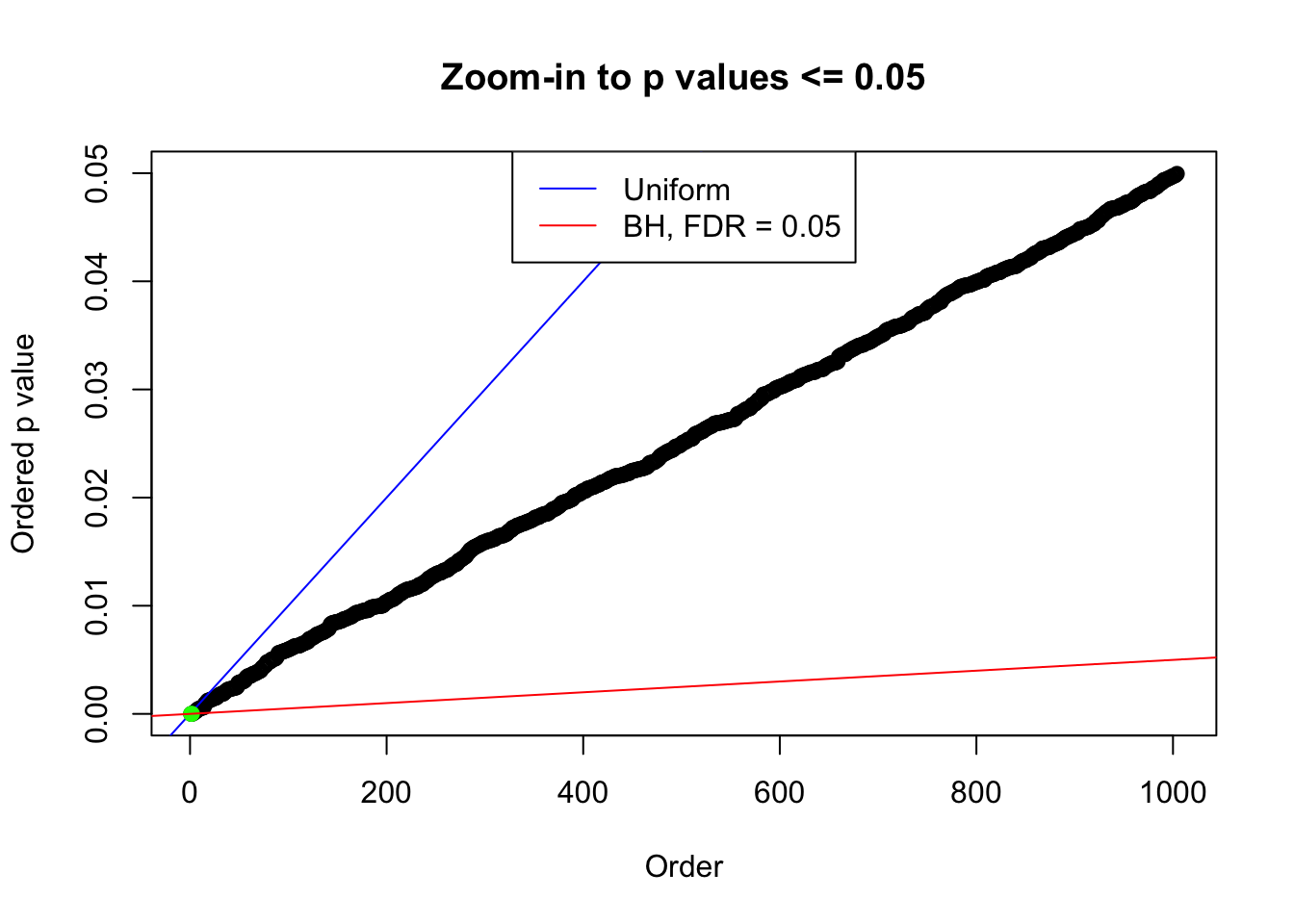
N0. 23 : Data Set 901 ; Number of False Discoveries: 2 ; pihat0 = 0.9997959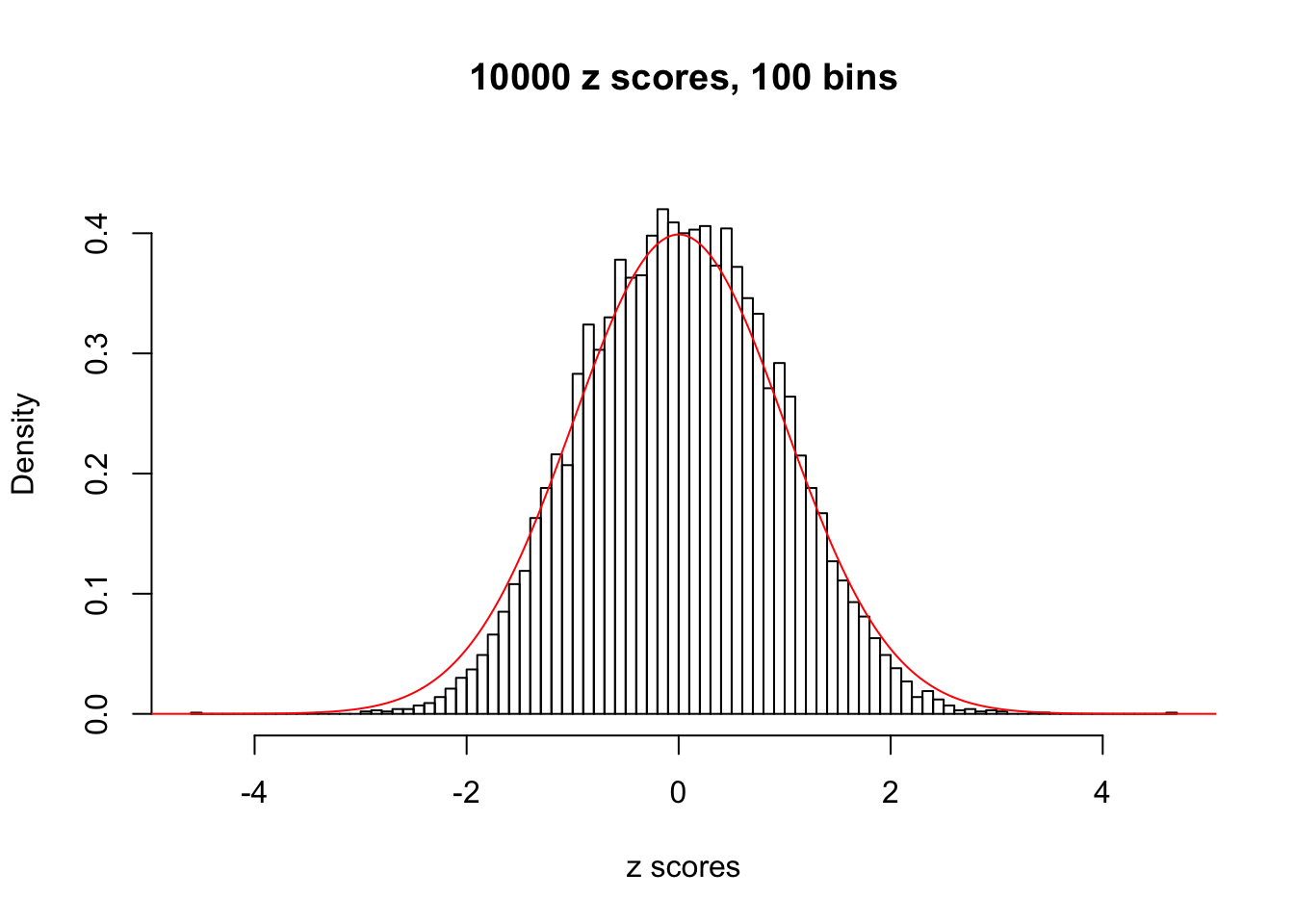
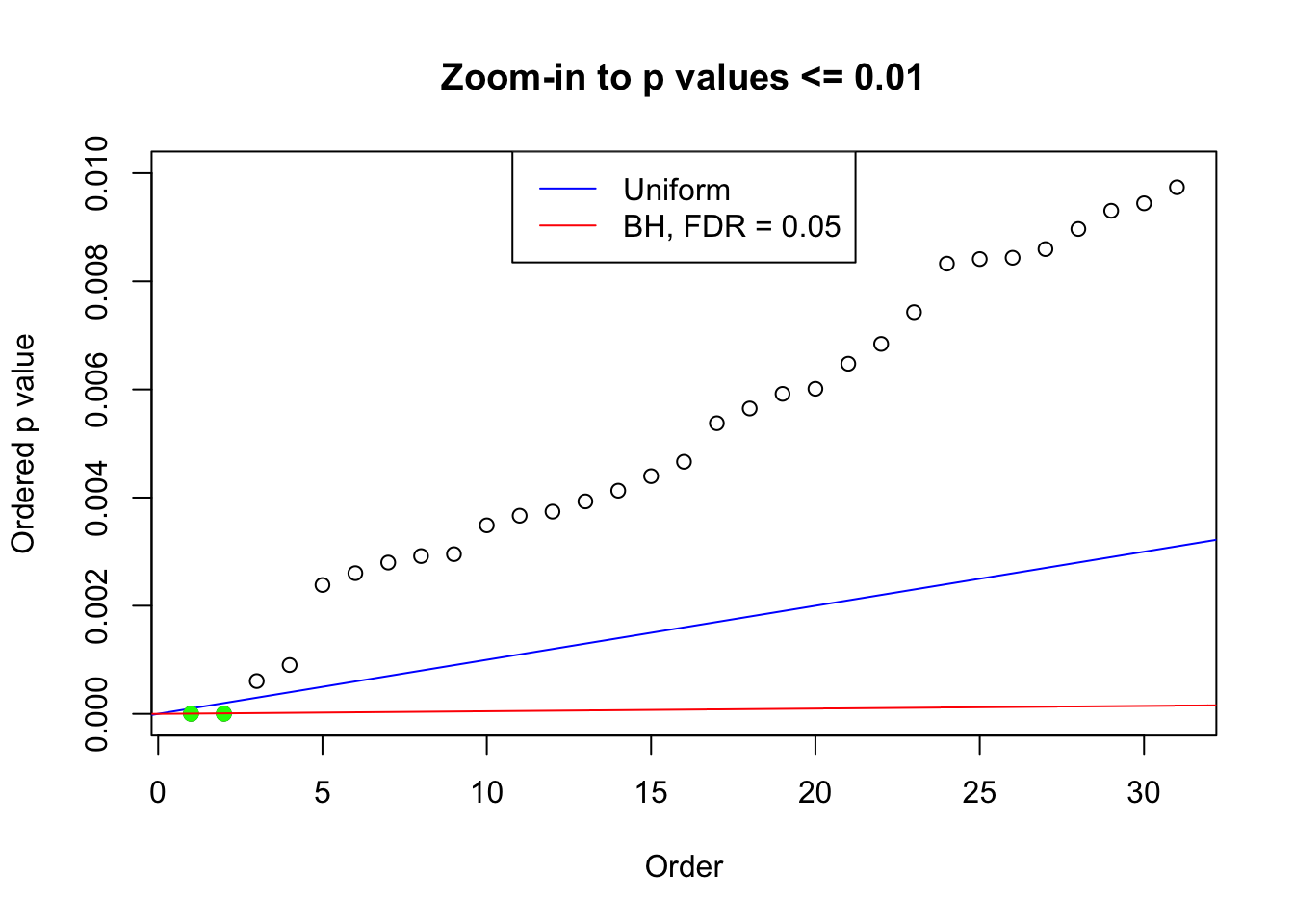
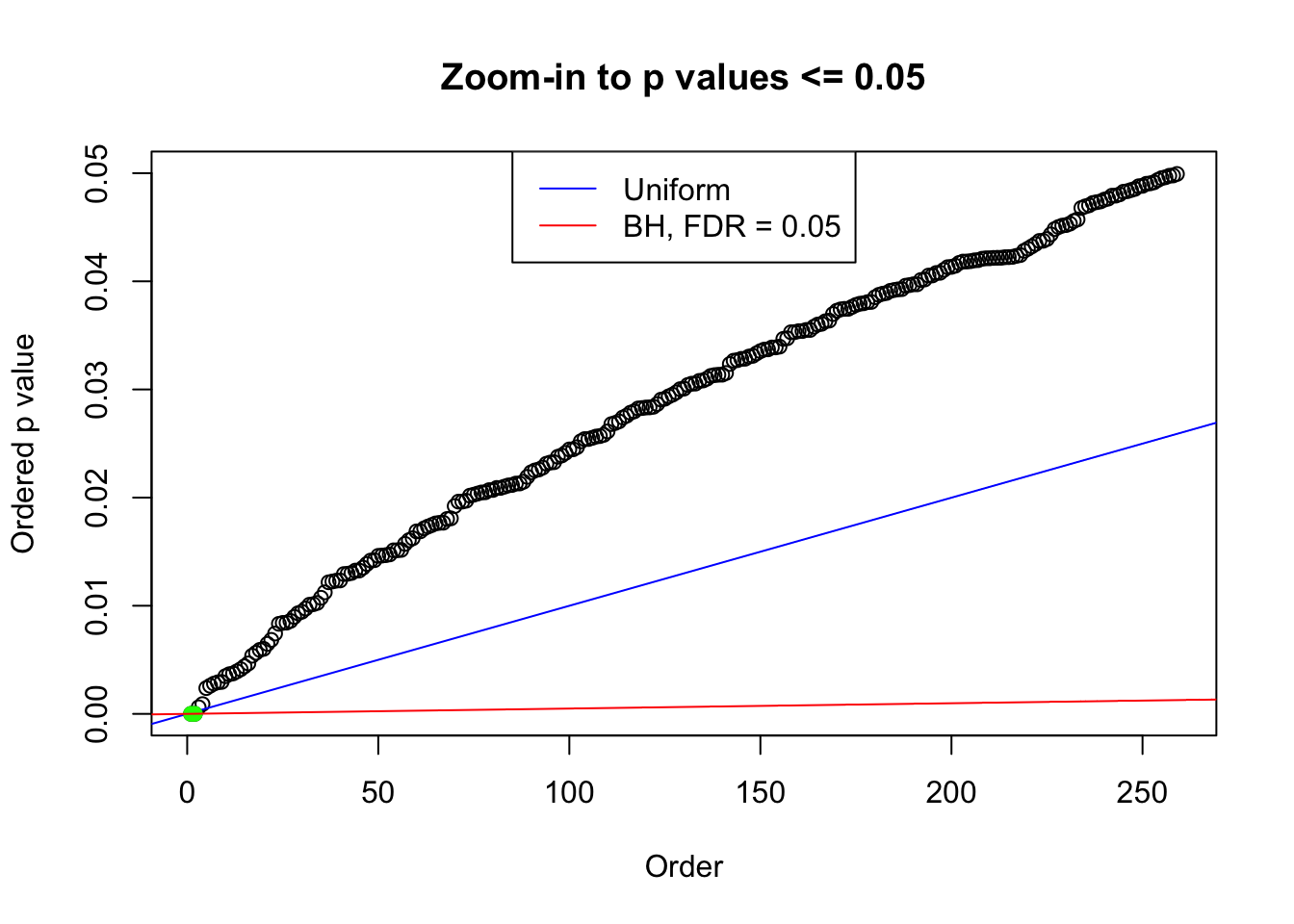
N0. 24 : Data Set 912 ; Number of False Discoveries: 2 ; pihat0 = 0.106048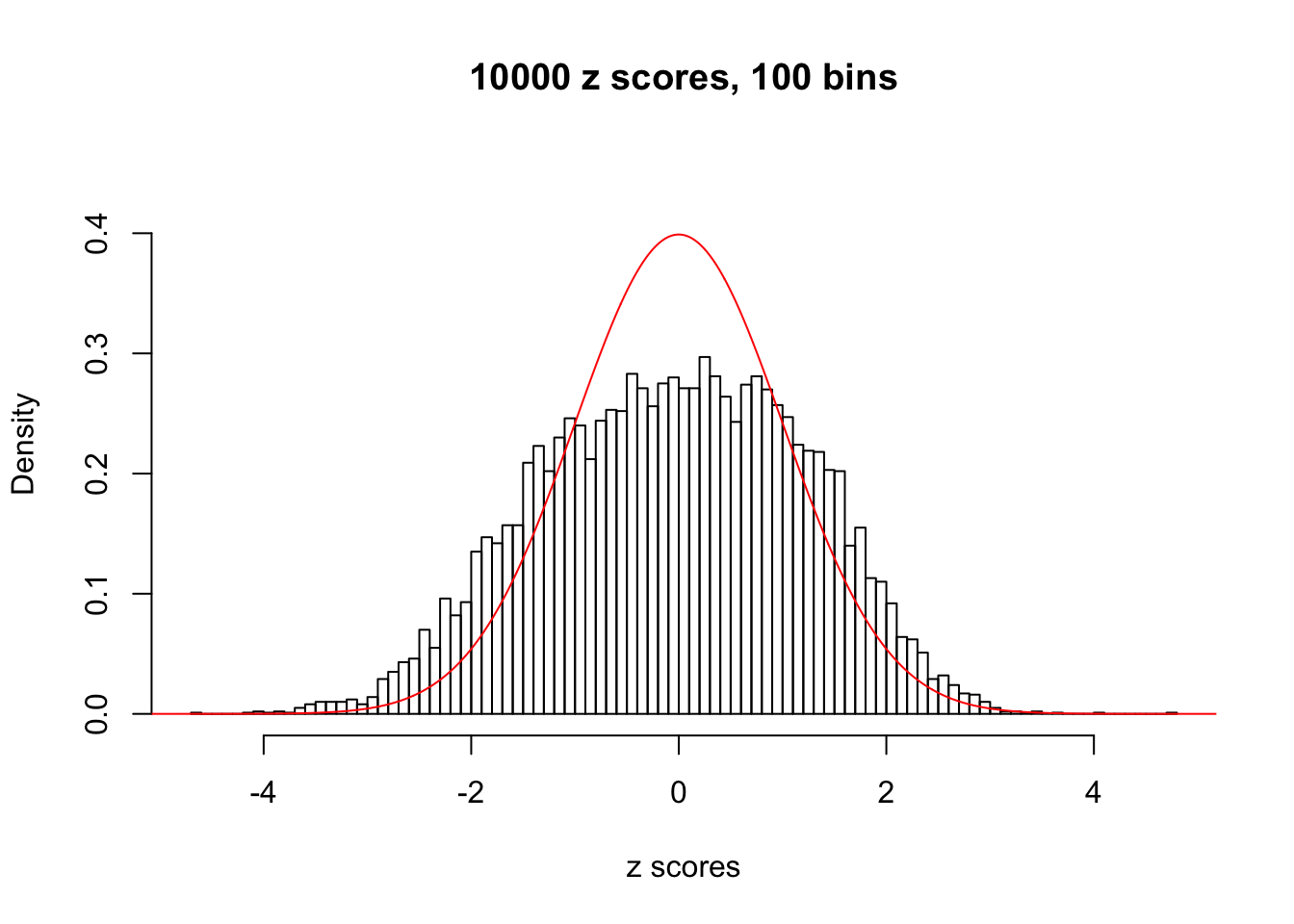
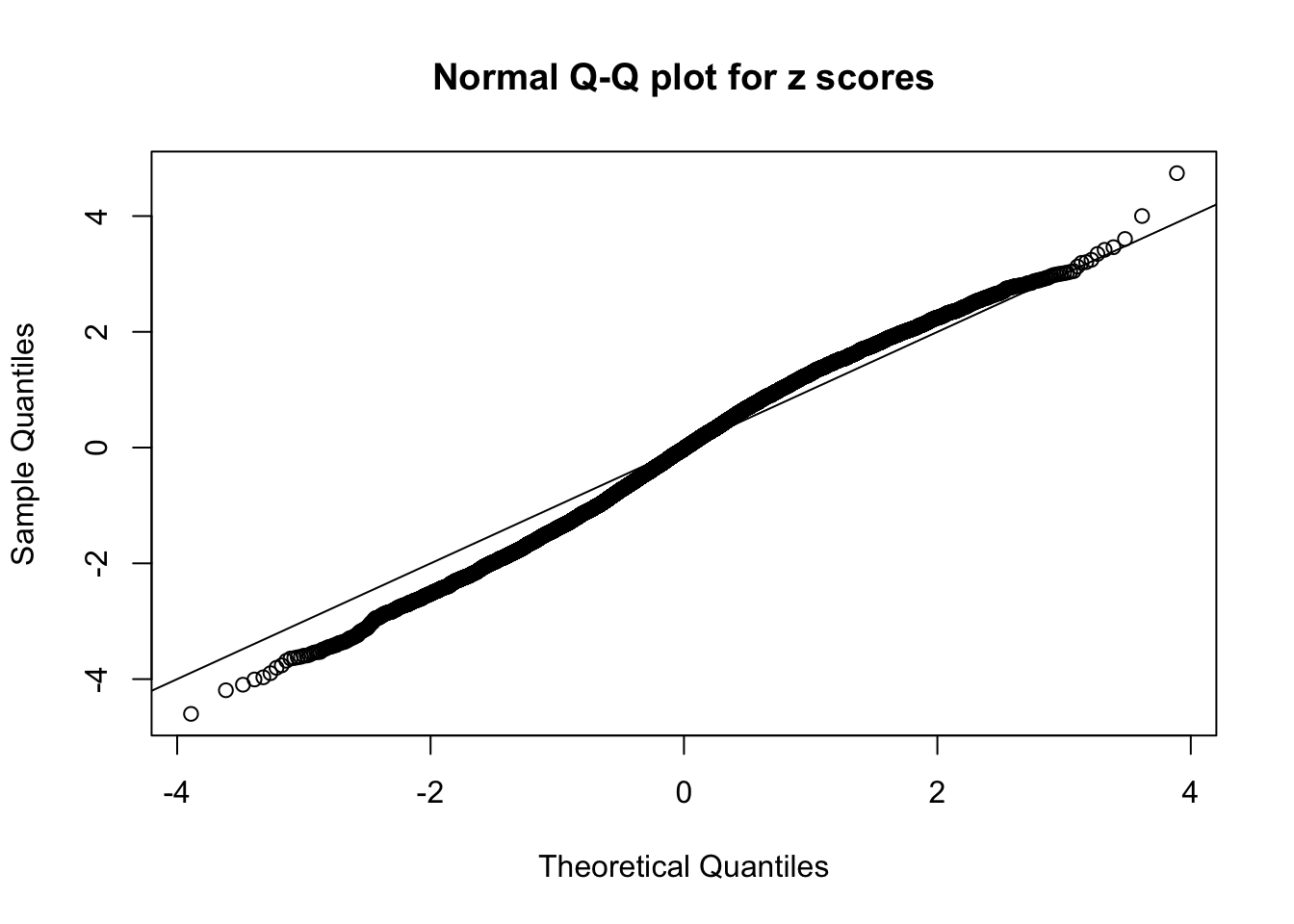
N0. 25 : Data Set 22 ; Number of False Discoveries: 1 ; pihat0 = 0.03271534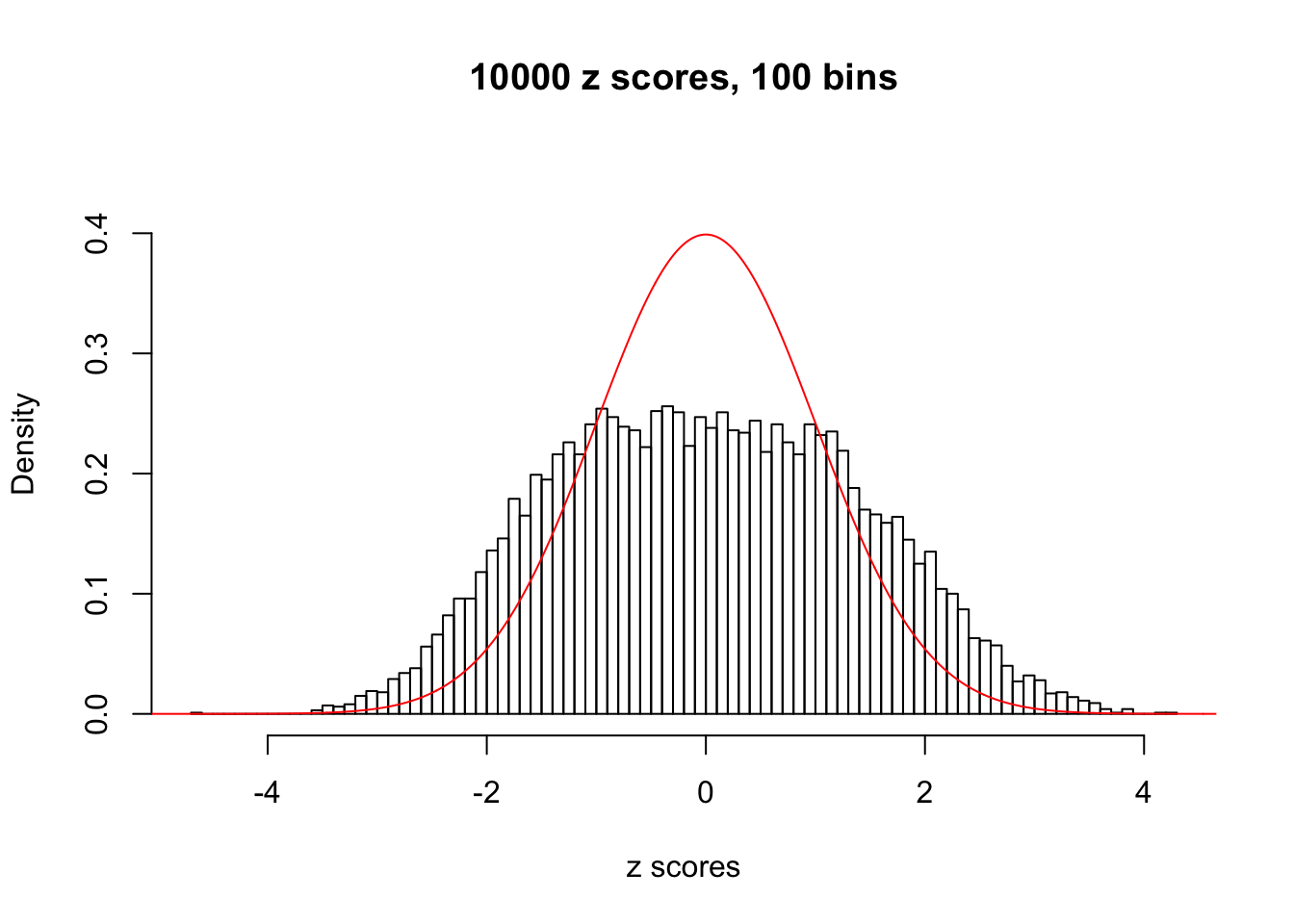
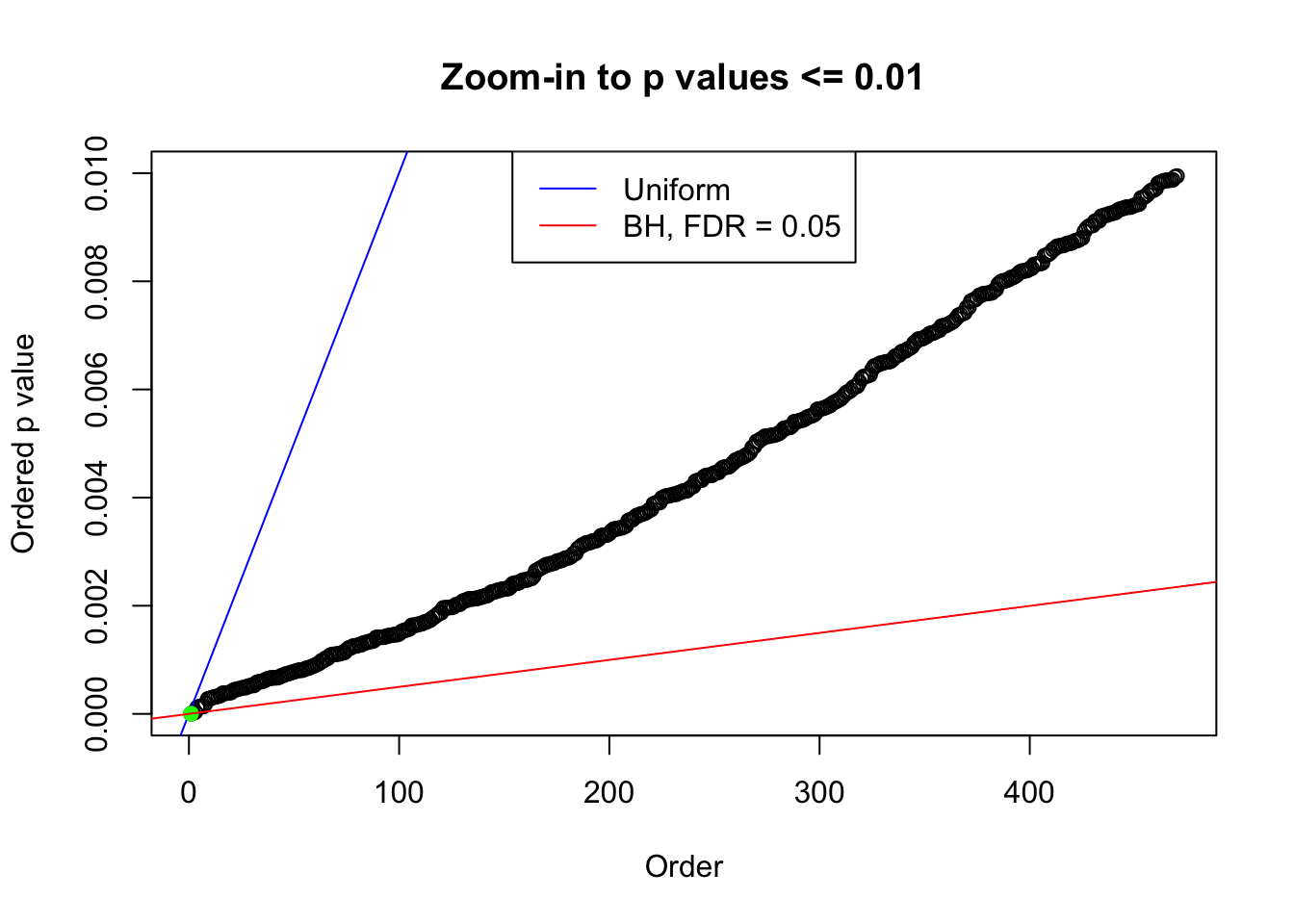
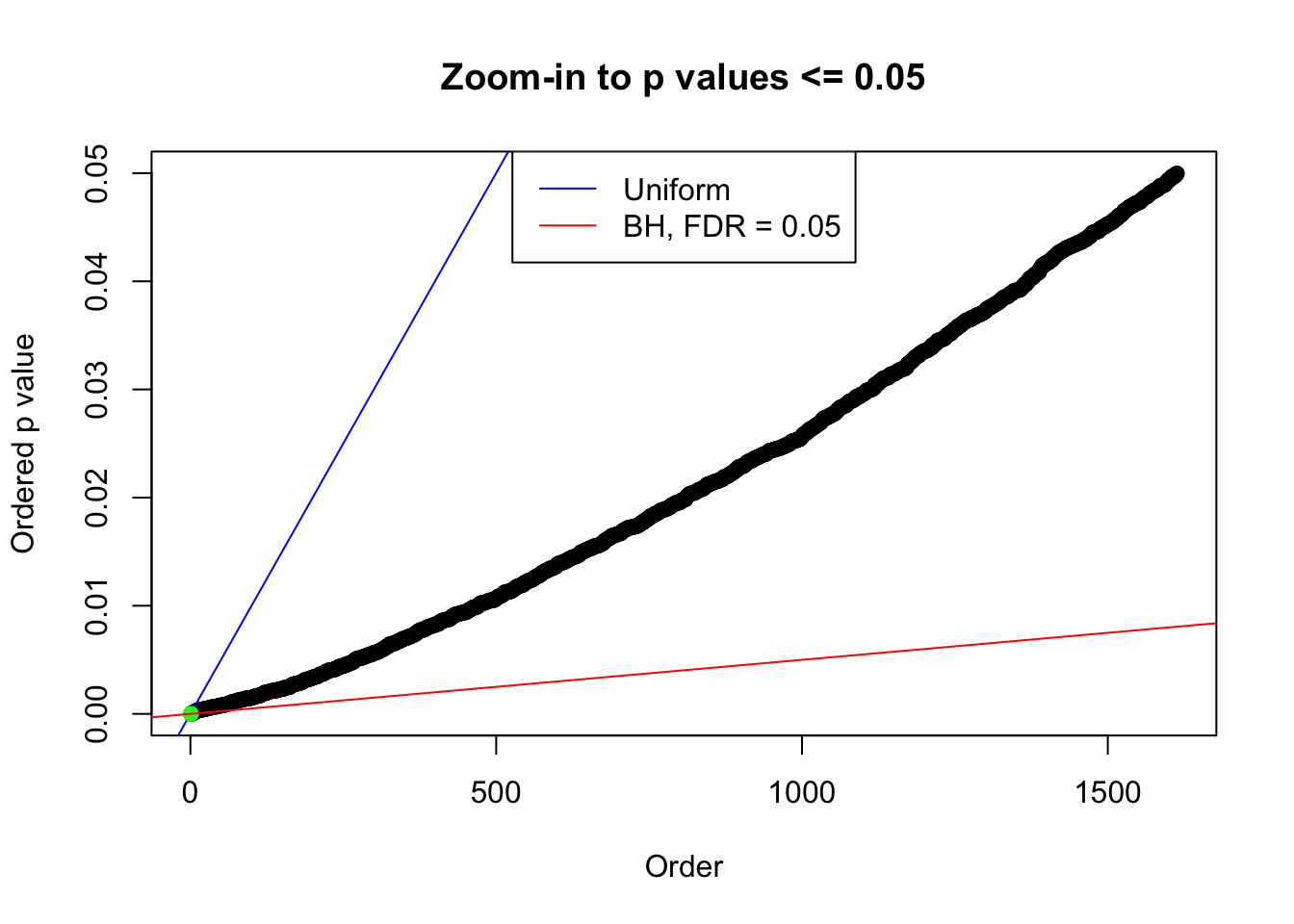
N0. 26 : Data Set 31 ; Number of False Discoveries: 1 ; pihat0 = 0.1874129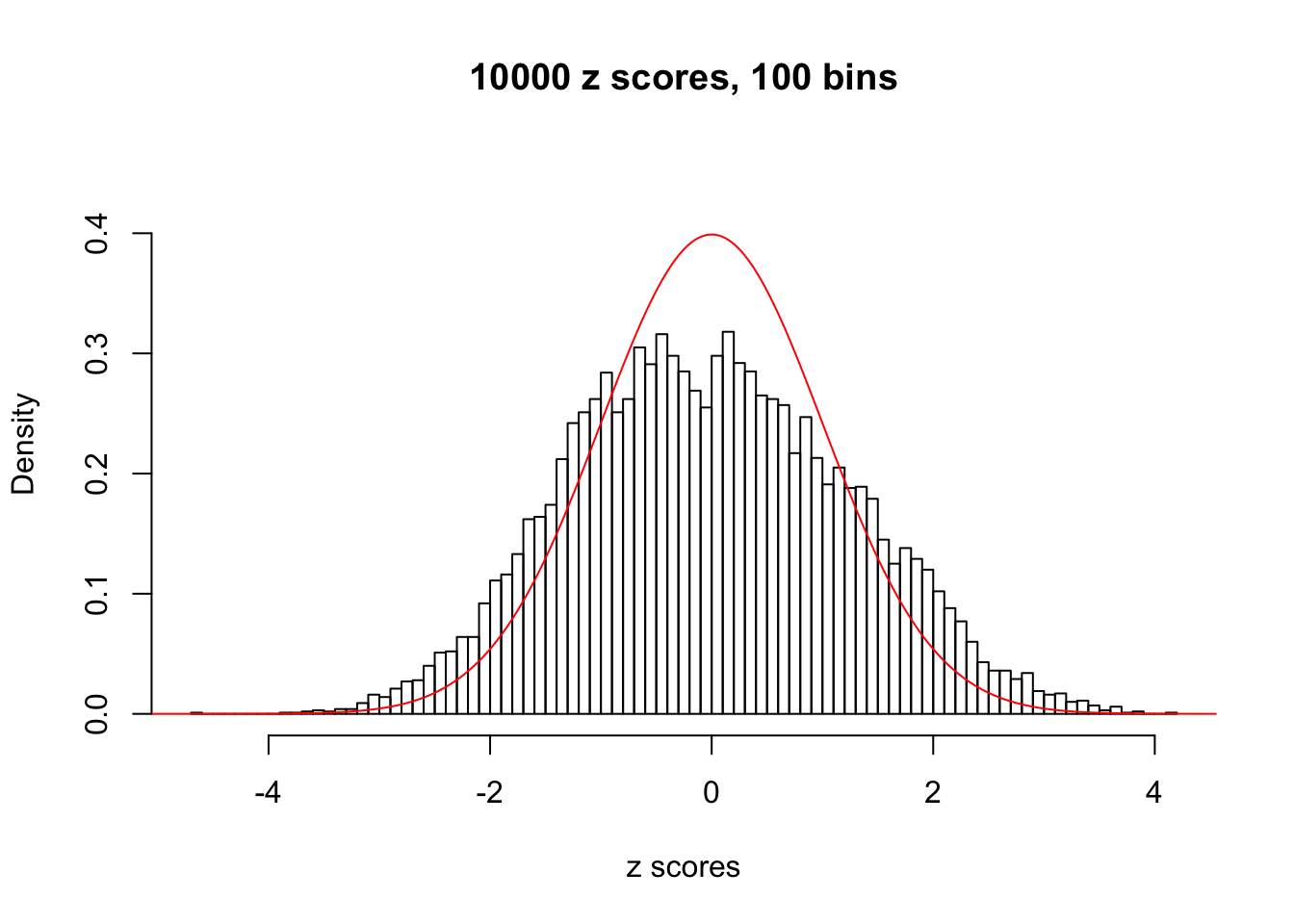
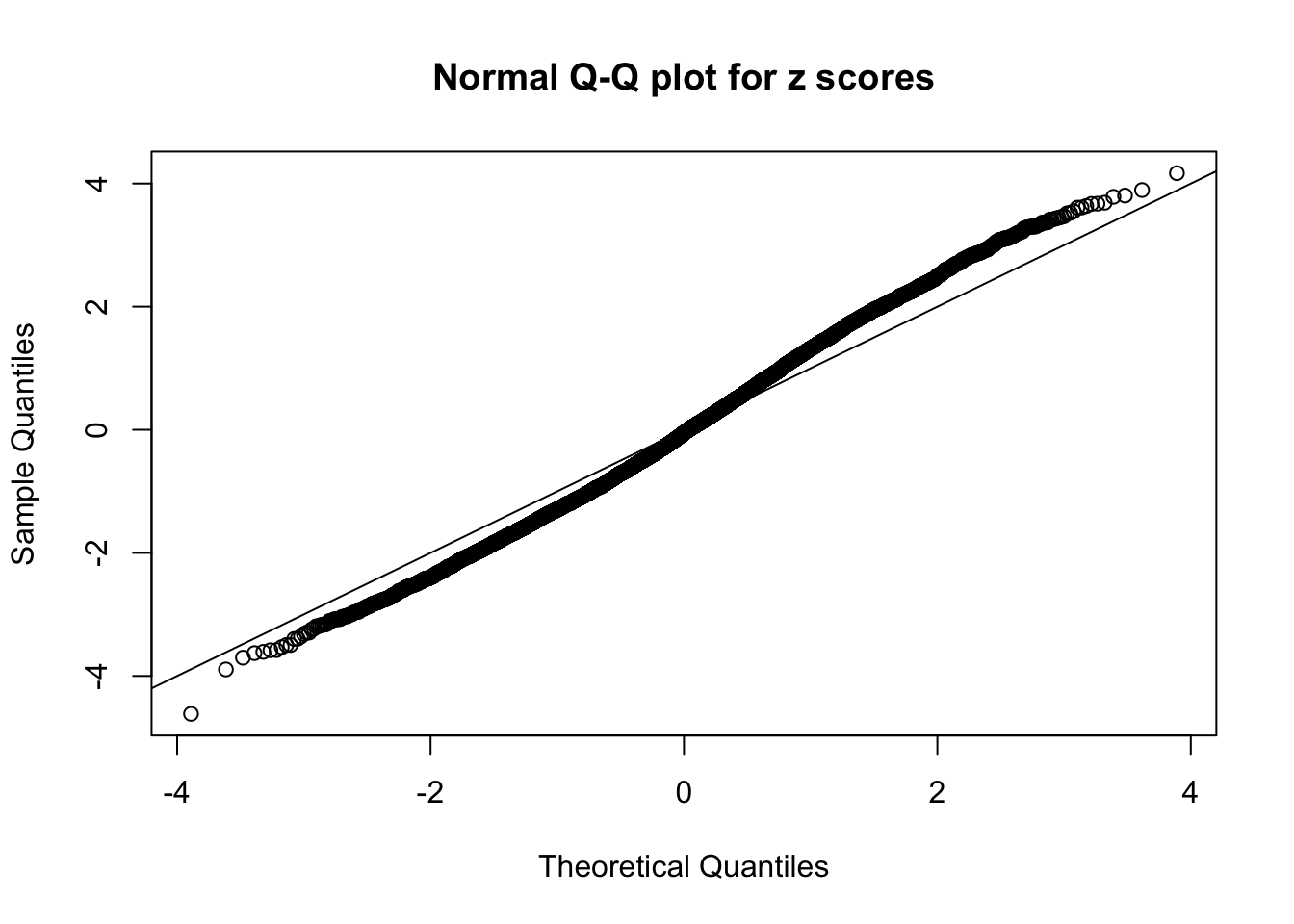
N0. 27 : Data Set 187 ; Number of False Discoveries: 1 ; pihat0 = 0.7071115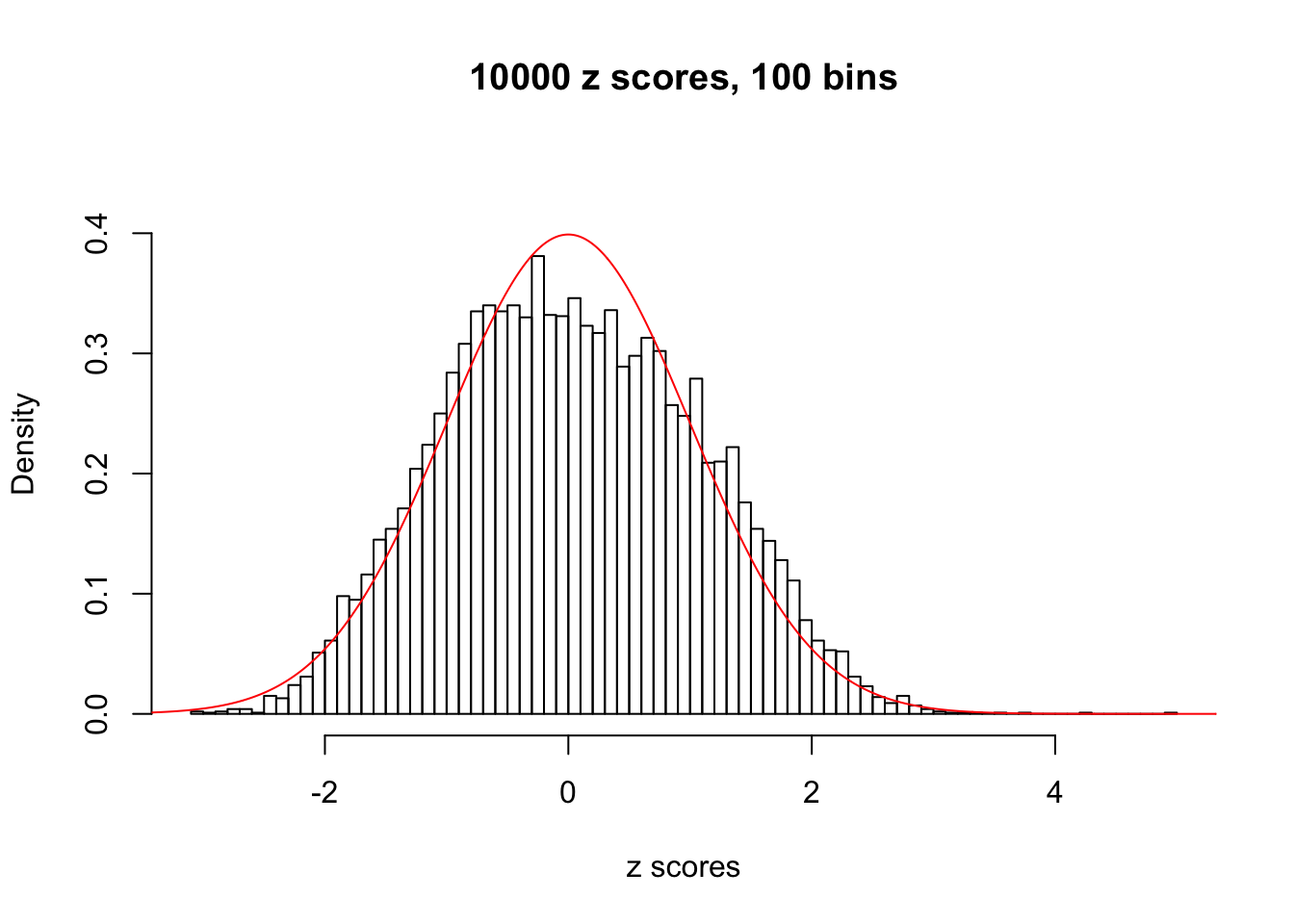
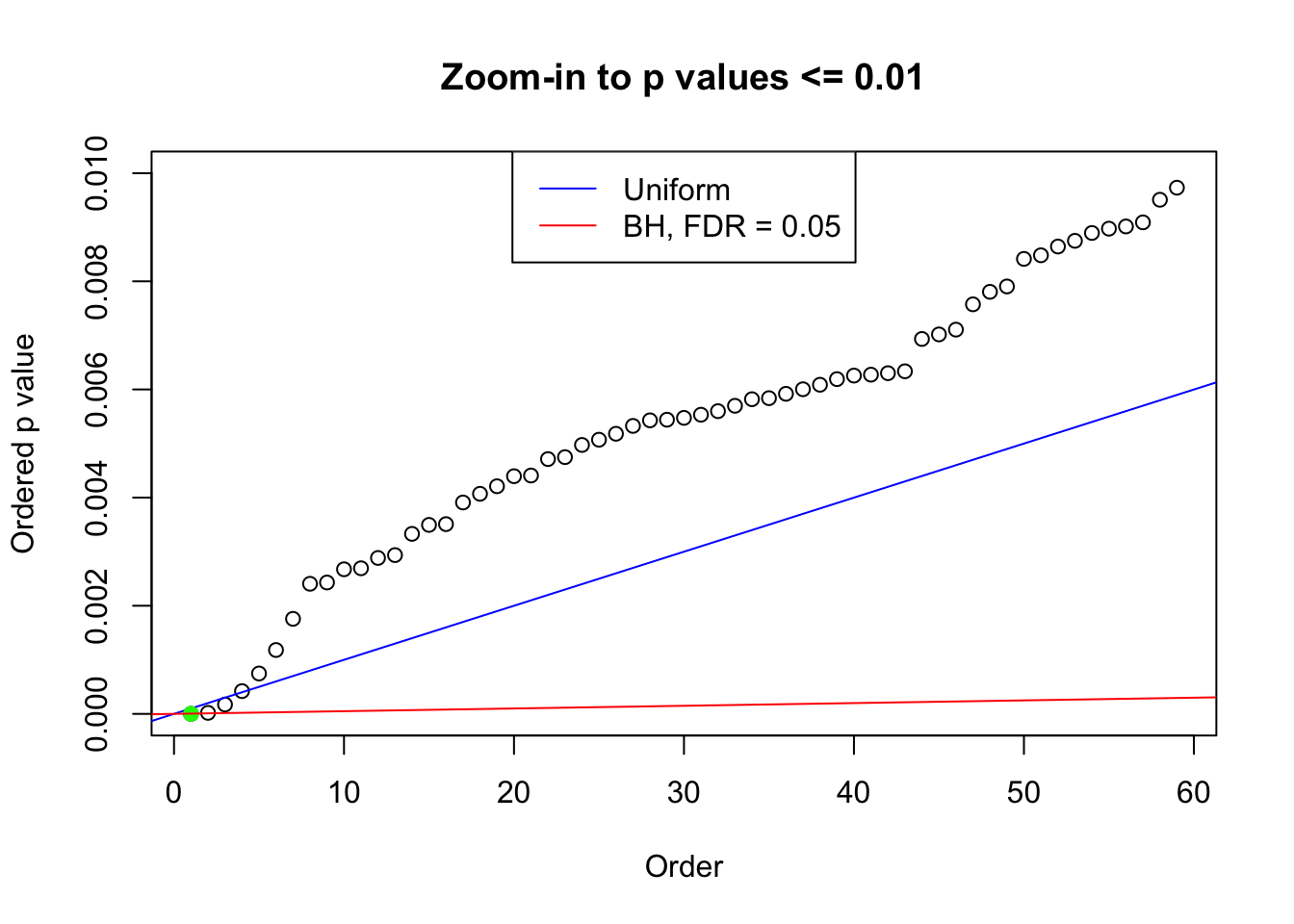
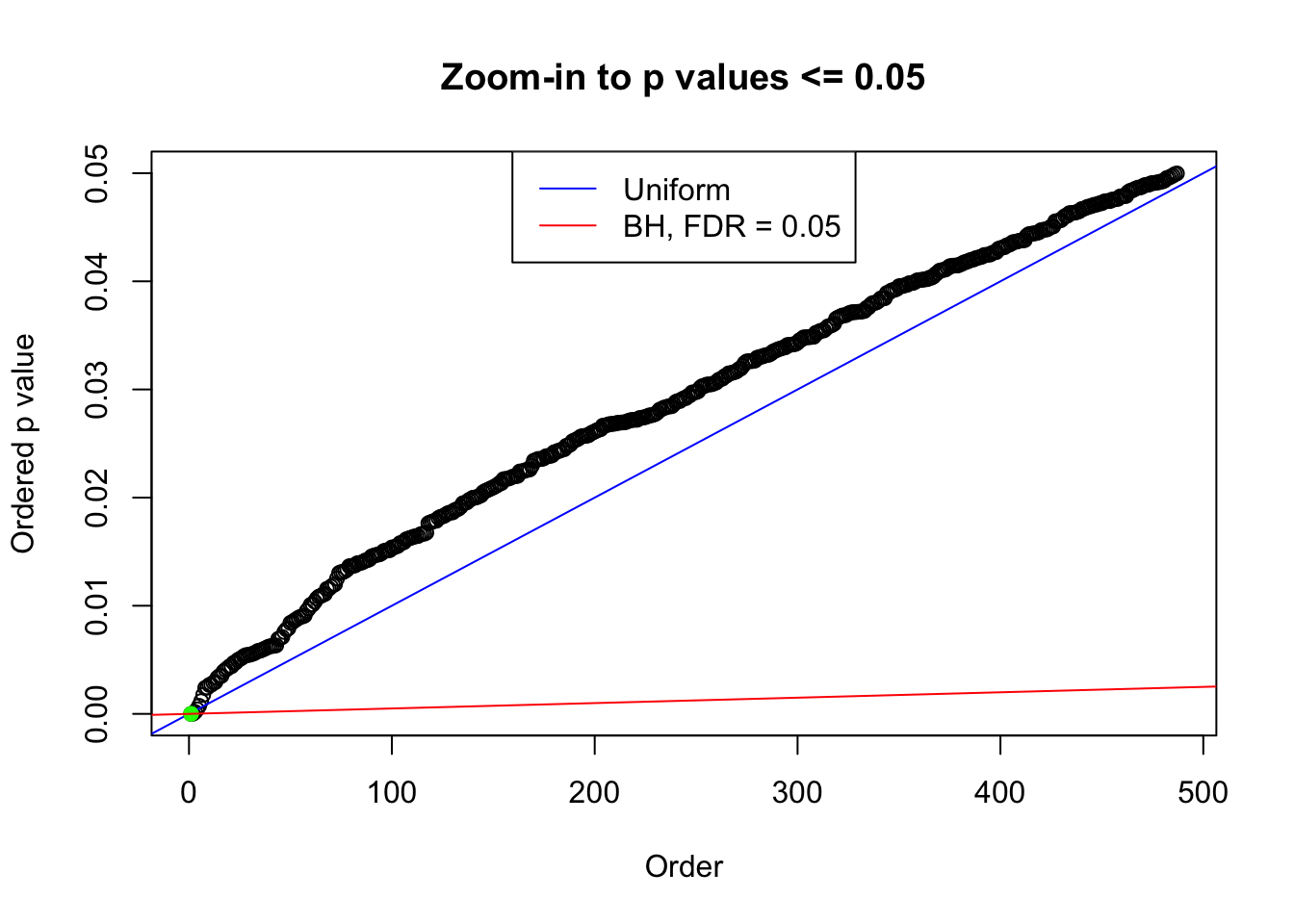
N0. 28 : Data Set 248 ; Number of False Discoveries: 1 ; pihat0 = 0.5095841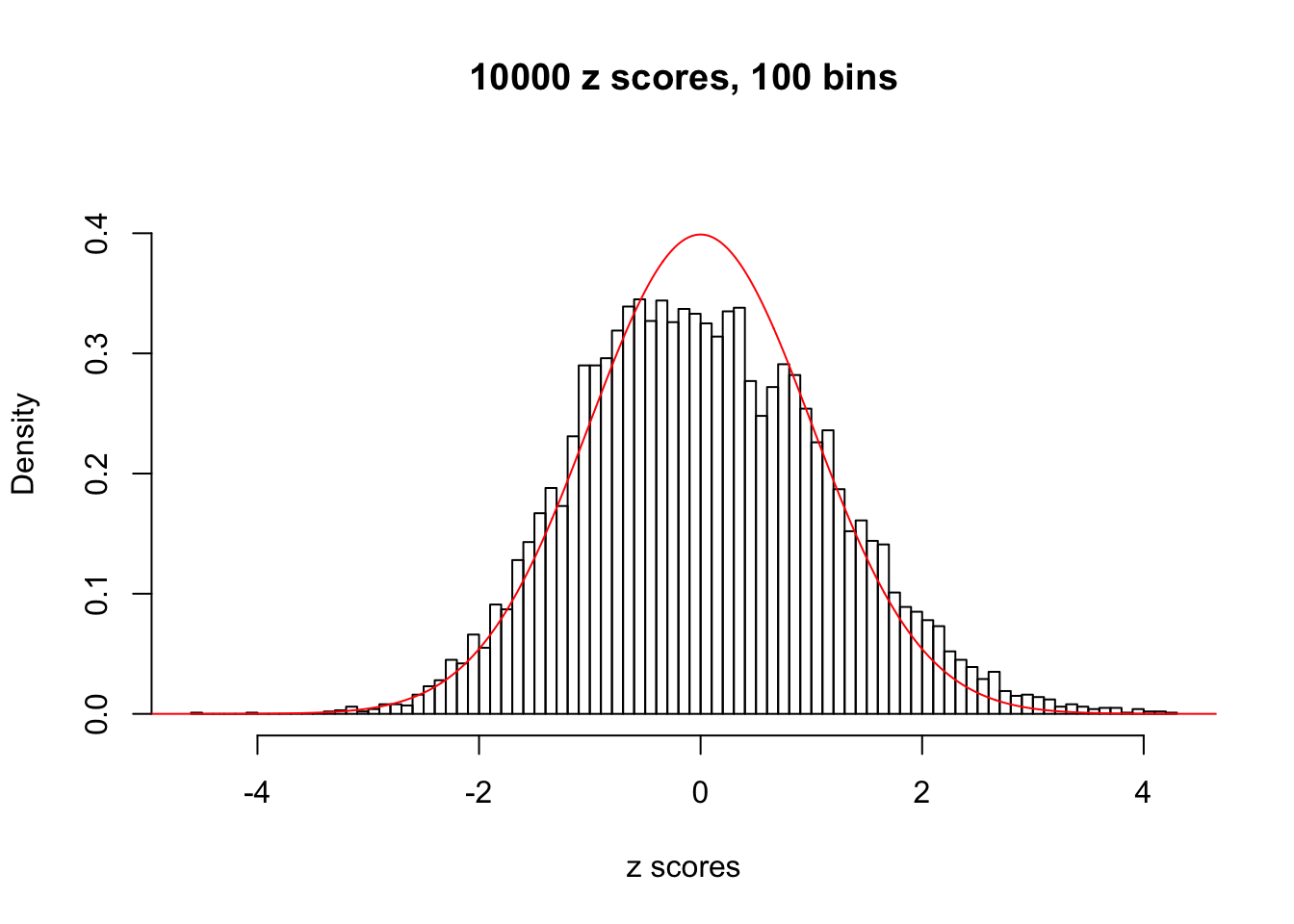
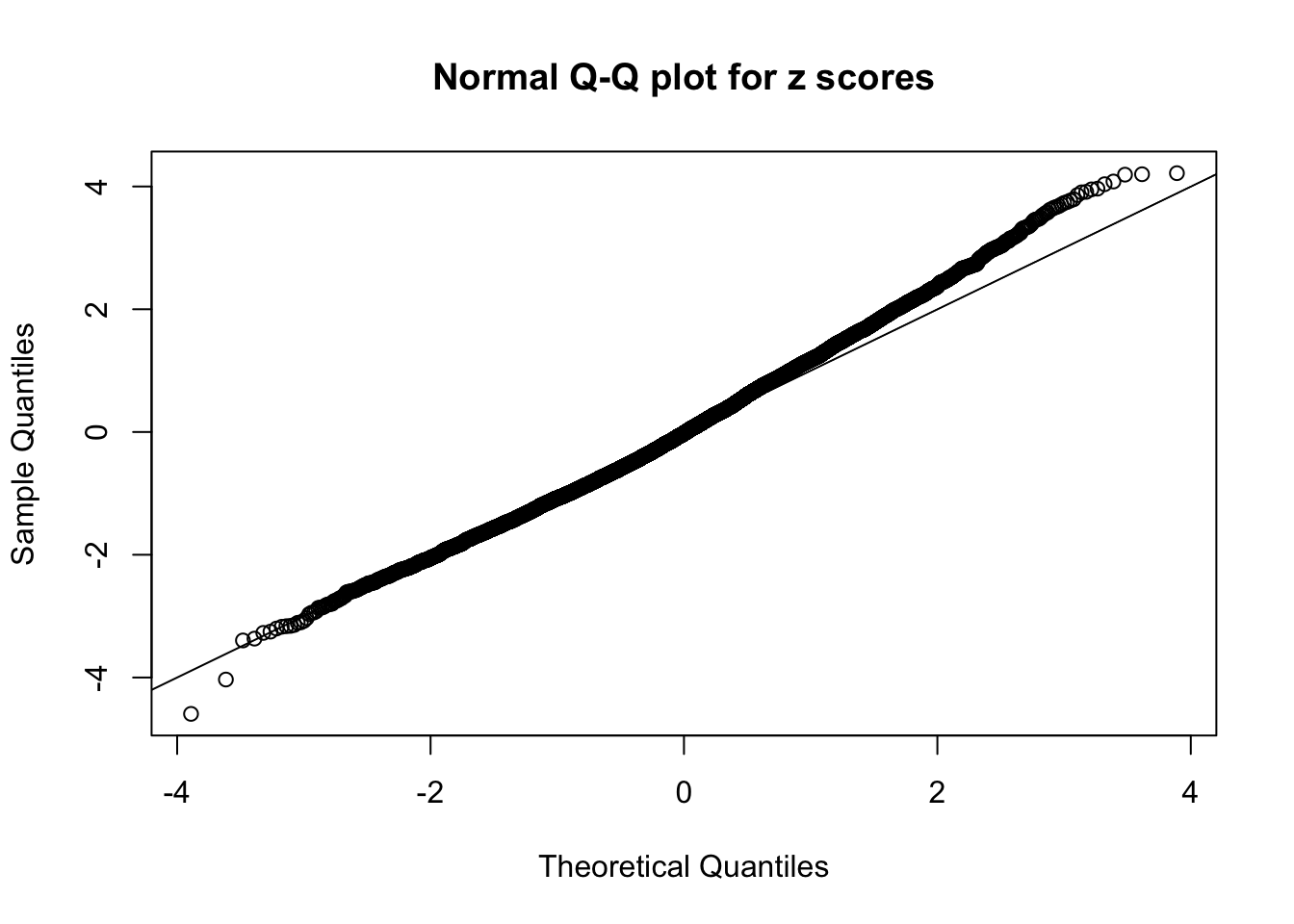
N0. 29 : Data Set 269 ; Number of False Discoveries: 1 ; pihat0 = 0.02787007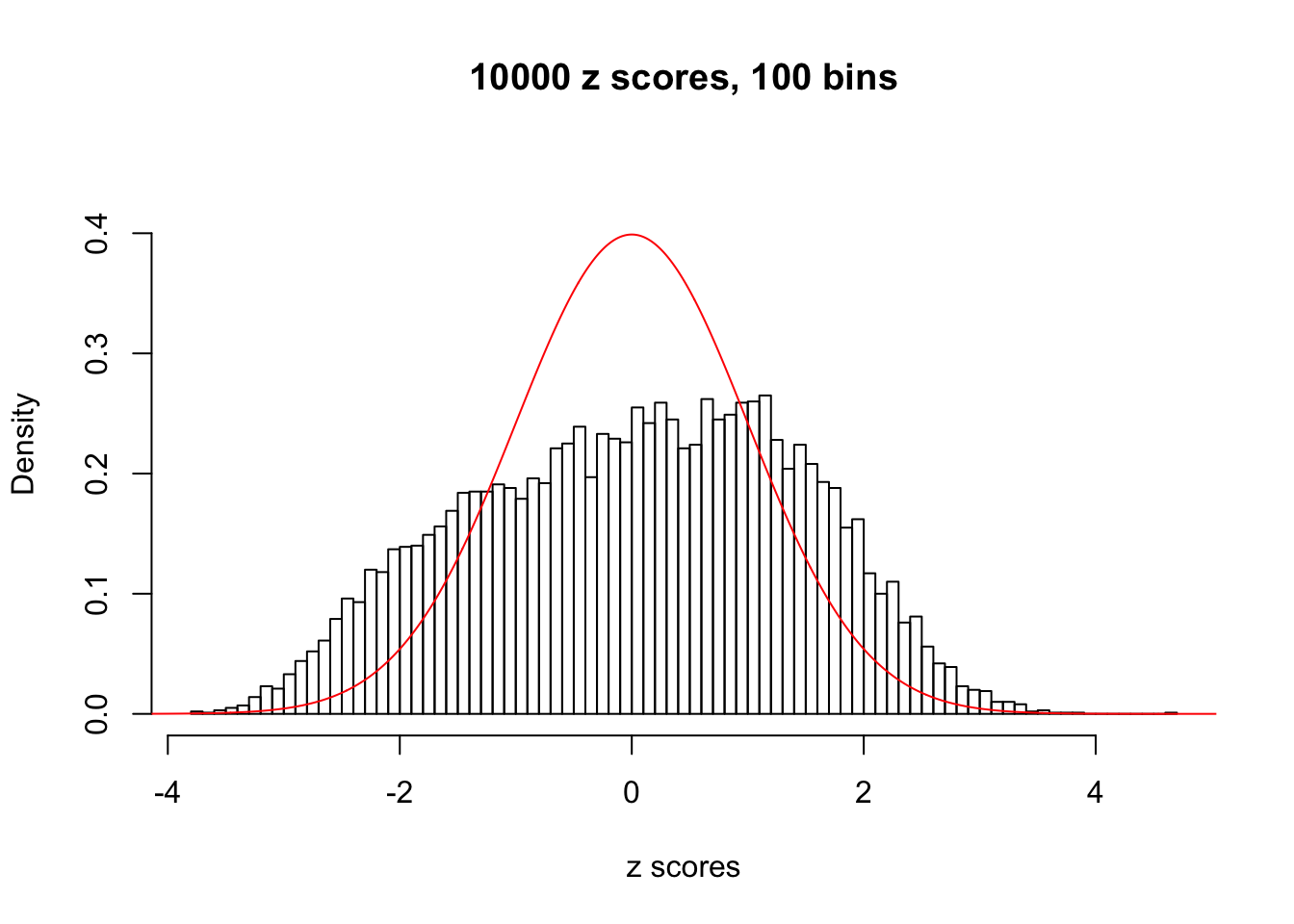
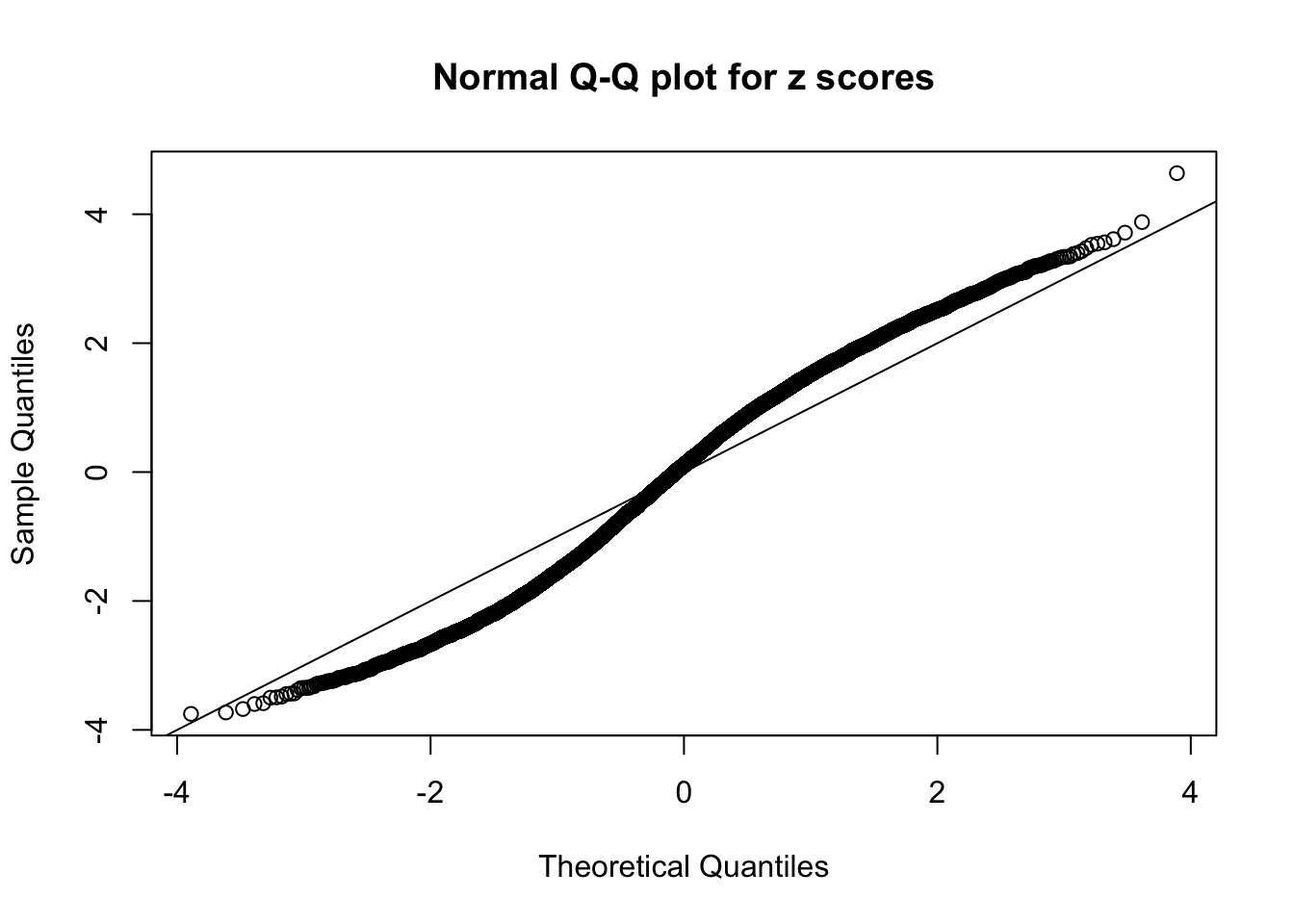
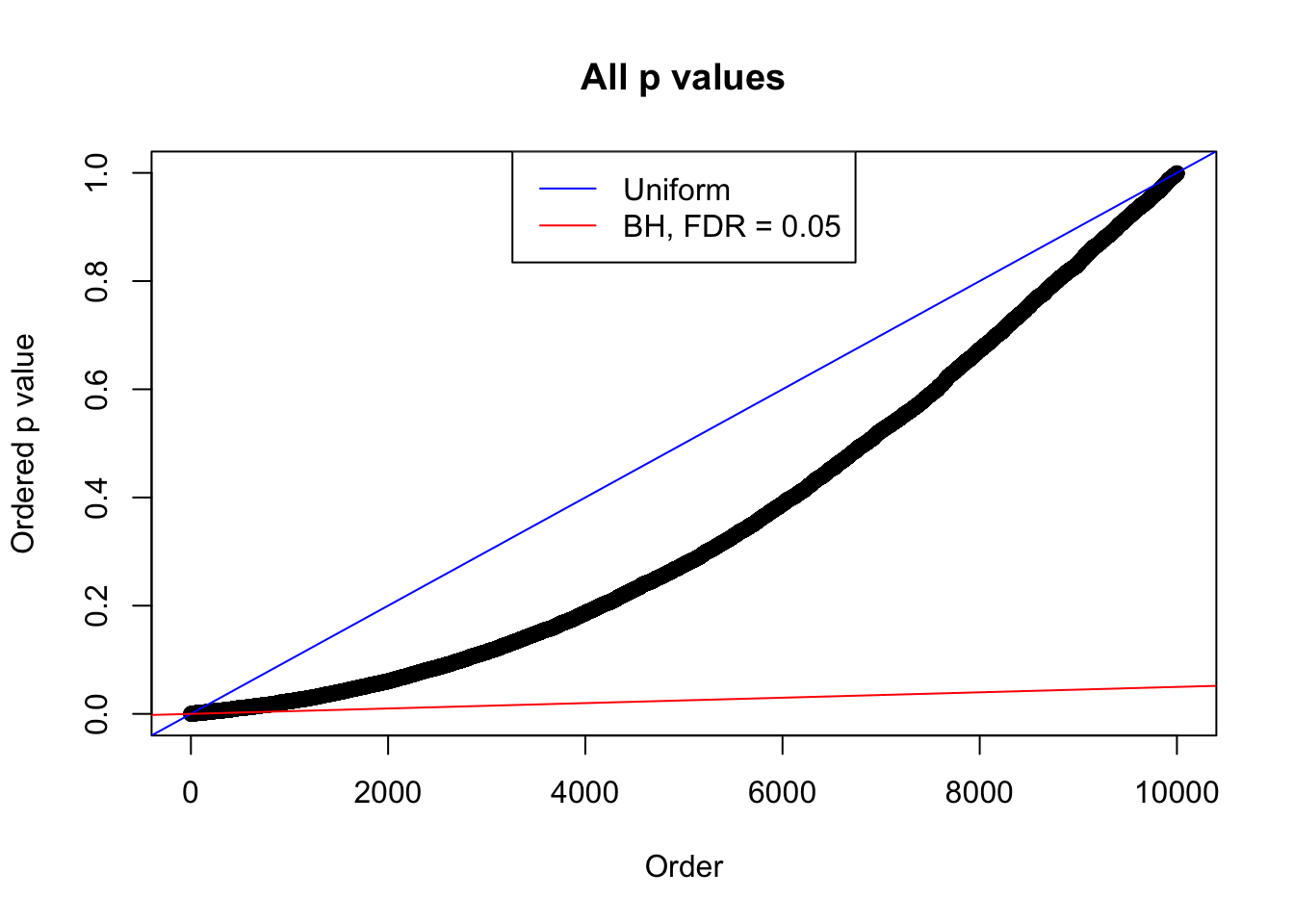
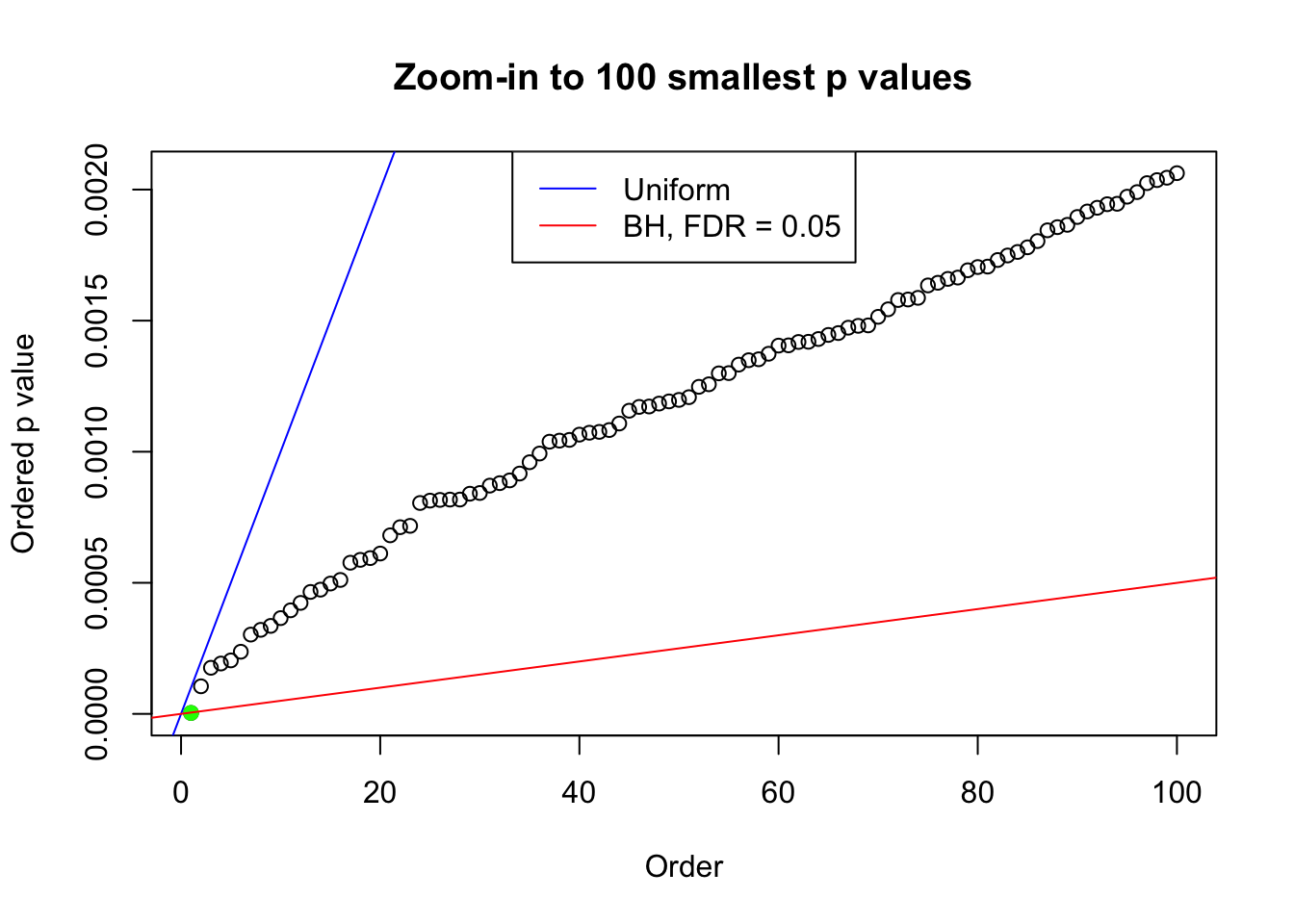
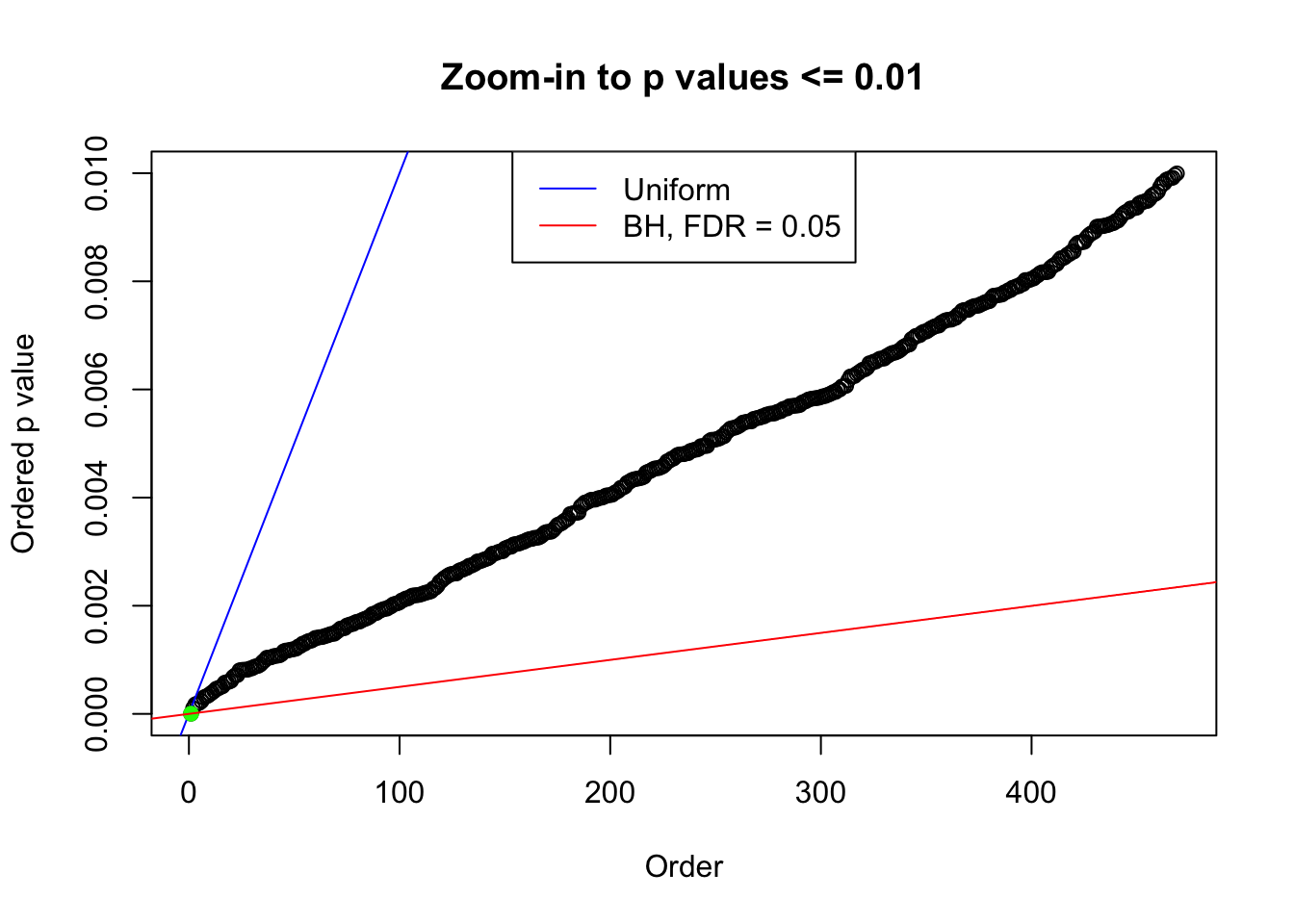
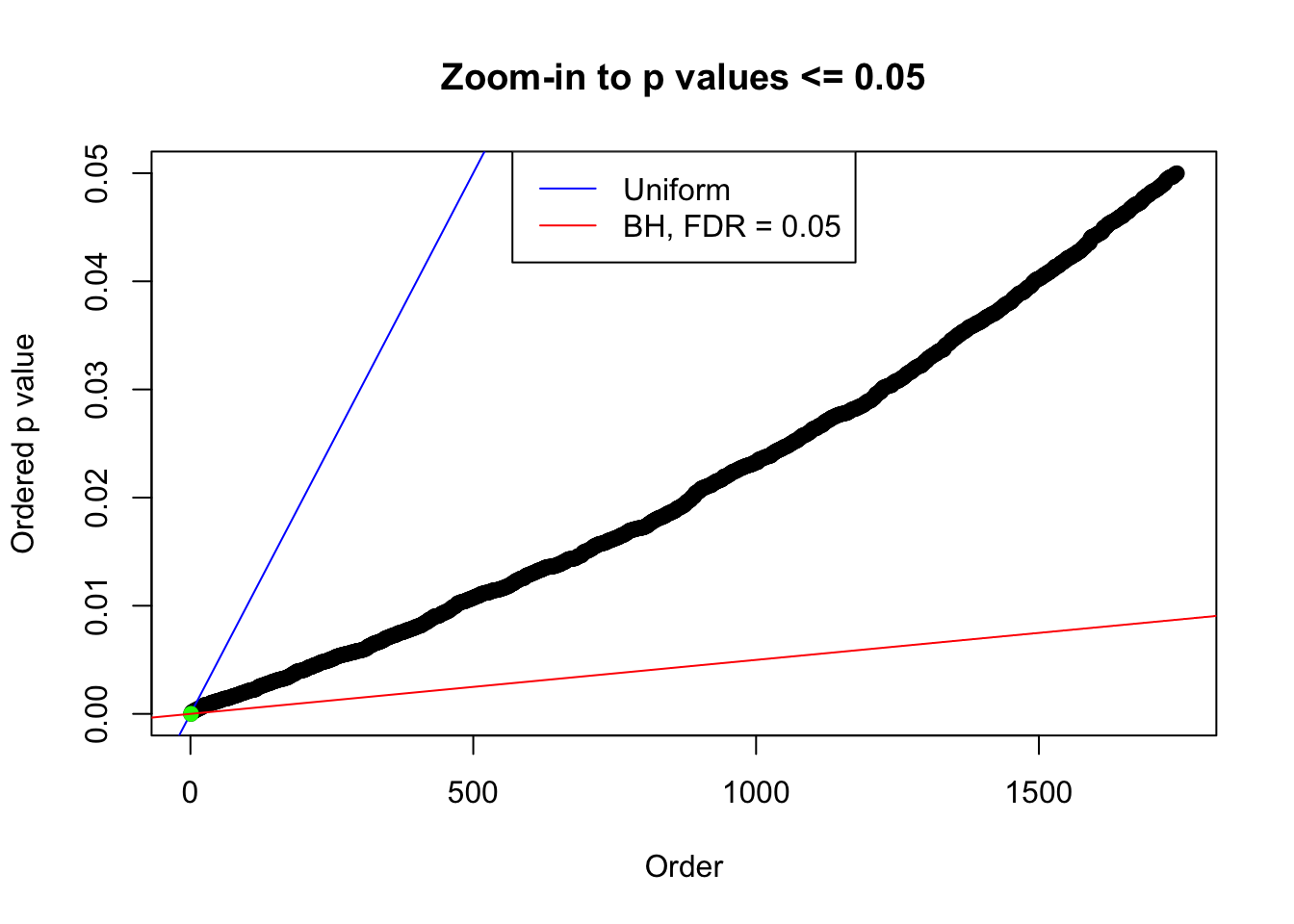
N0. 30 : Data Set 285 ; Number of False Discoveries: 1 ; pihat0 = 0.4624418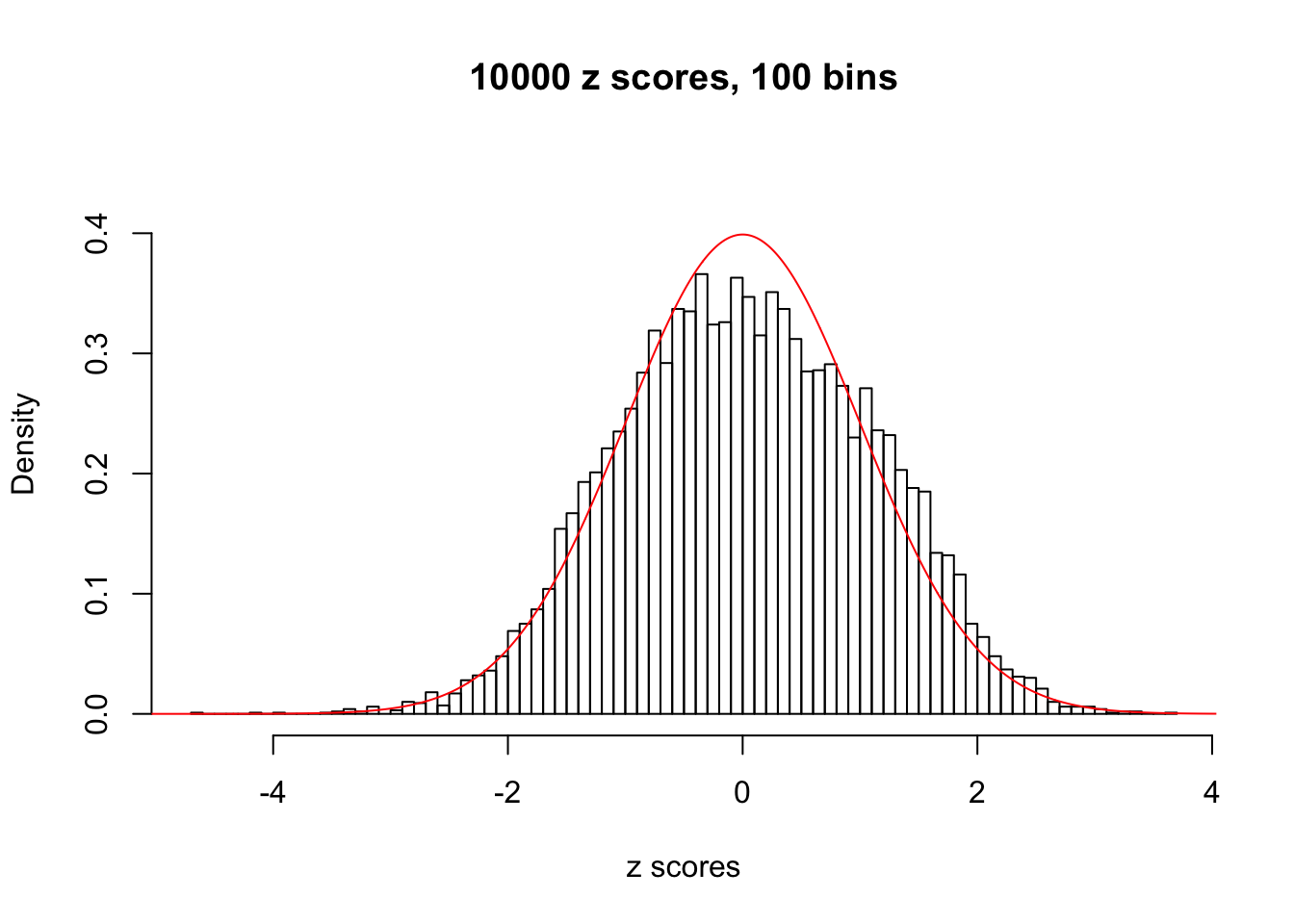
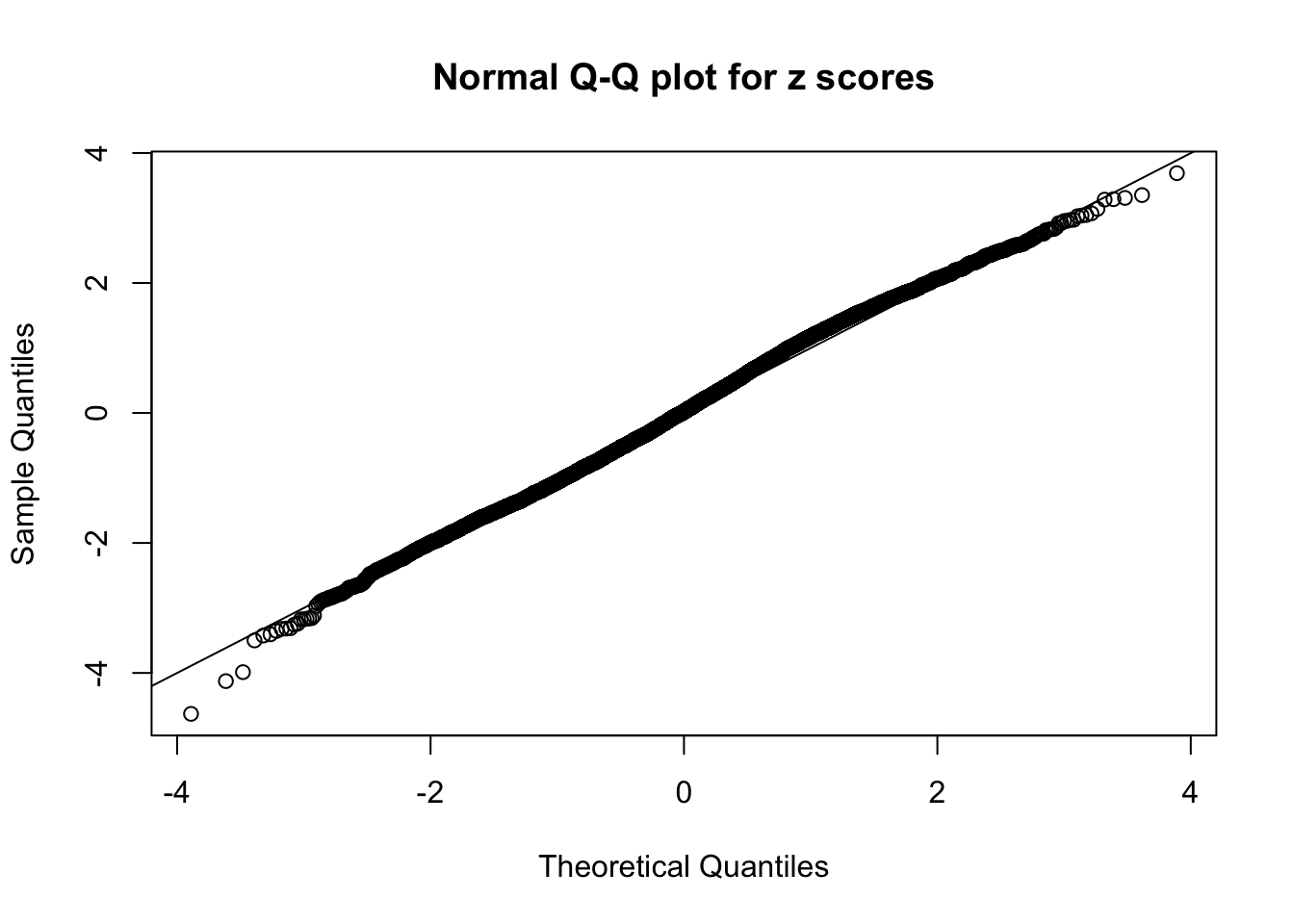
N0. 31 : Data Set 403 ; Number of False Discoveries: 1 ; pihat0 = 0.0531628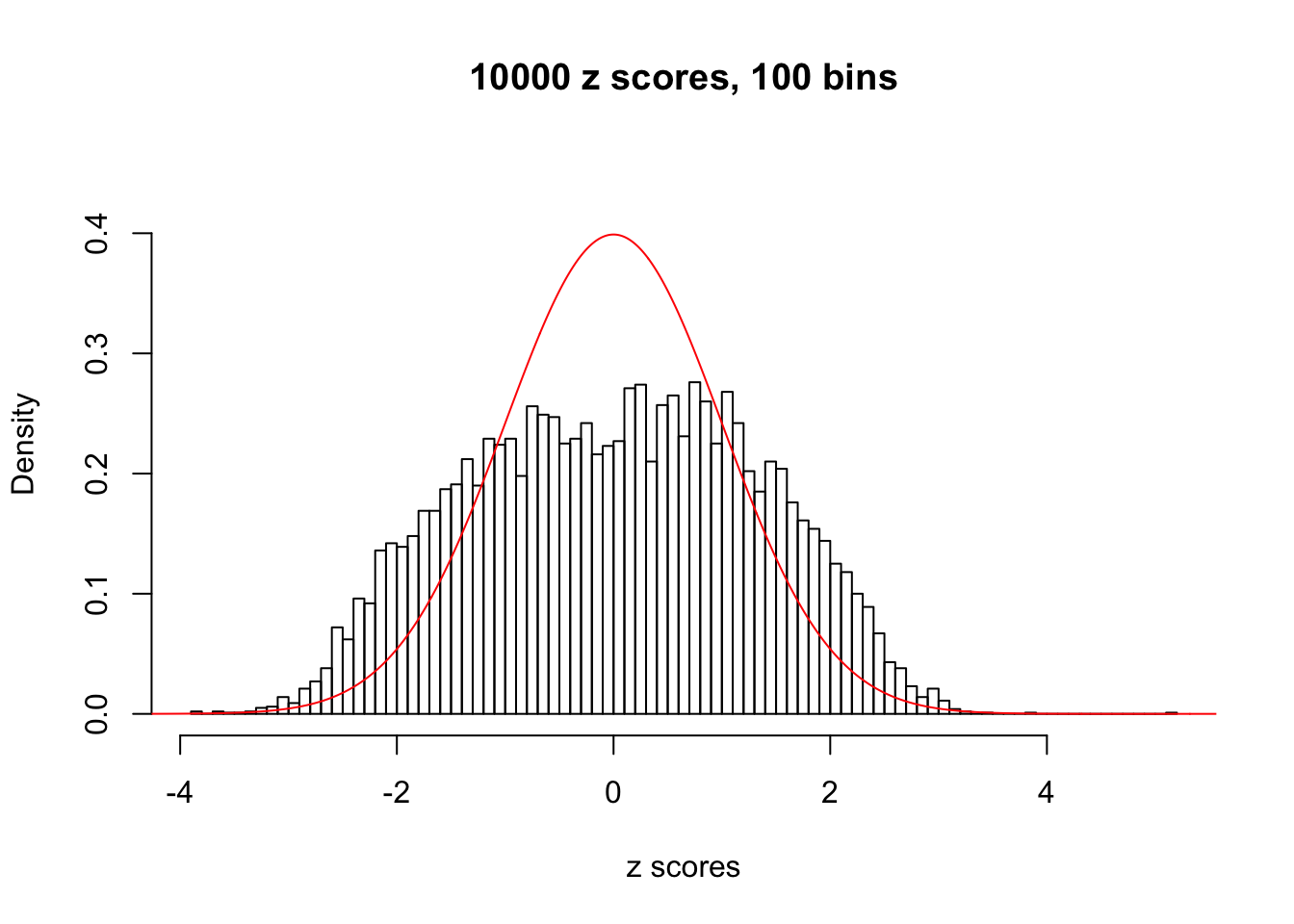
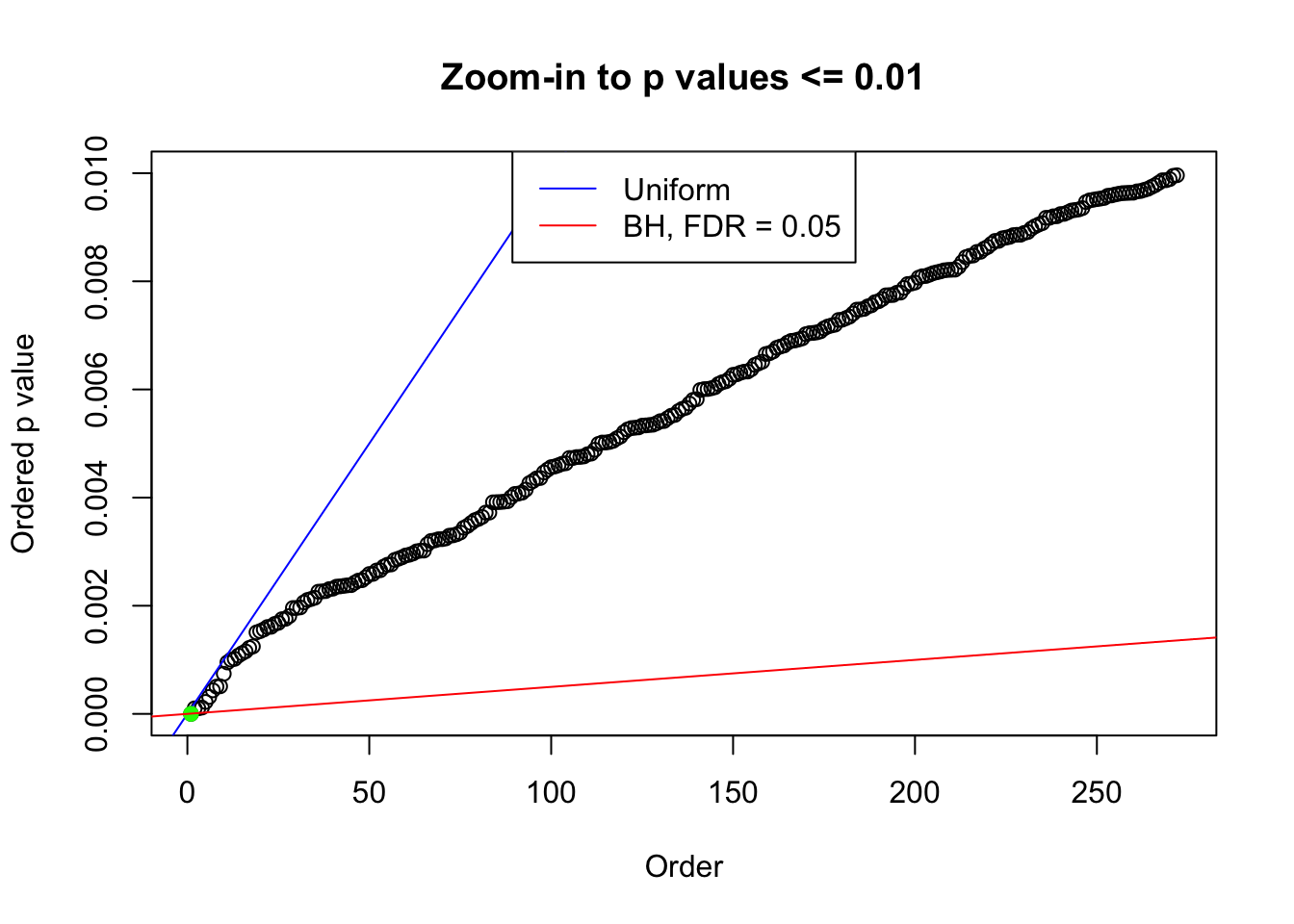
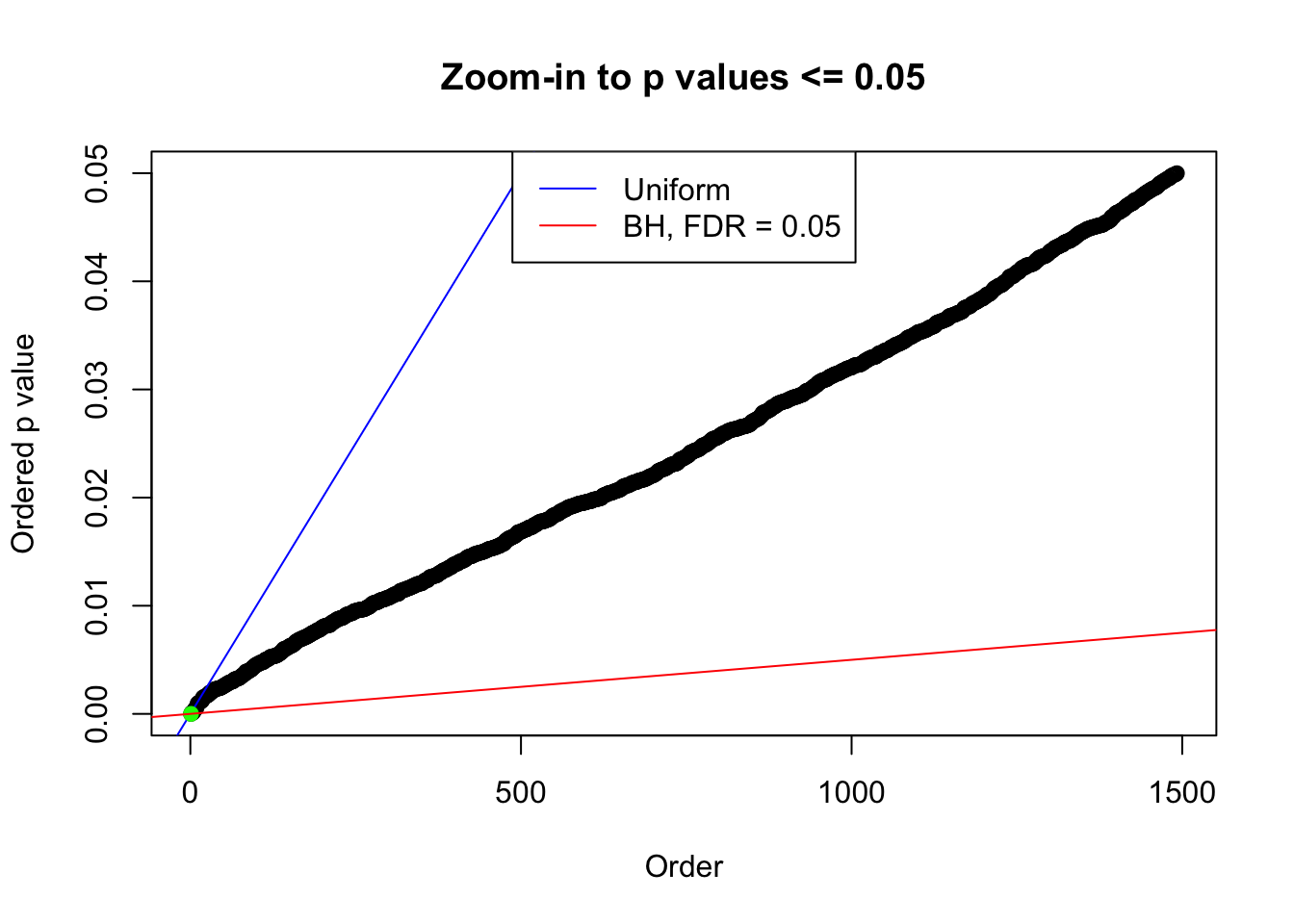
N0. 32 : Data Set 483 ; Number of False Discoveries: 1 ; pihat0 = 0.9998824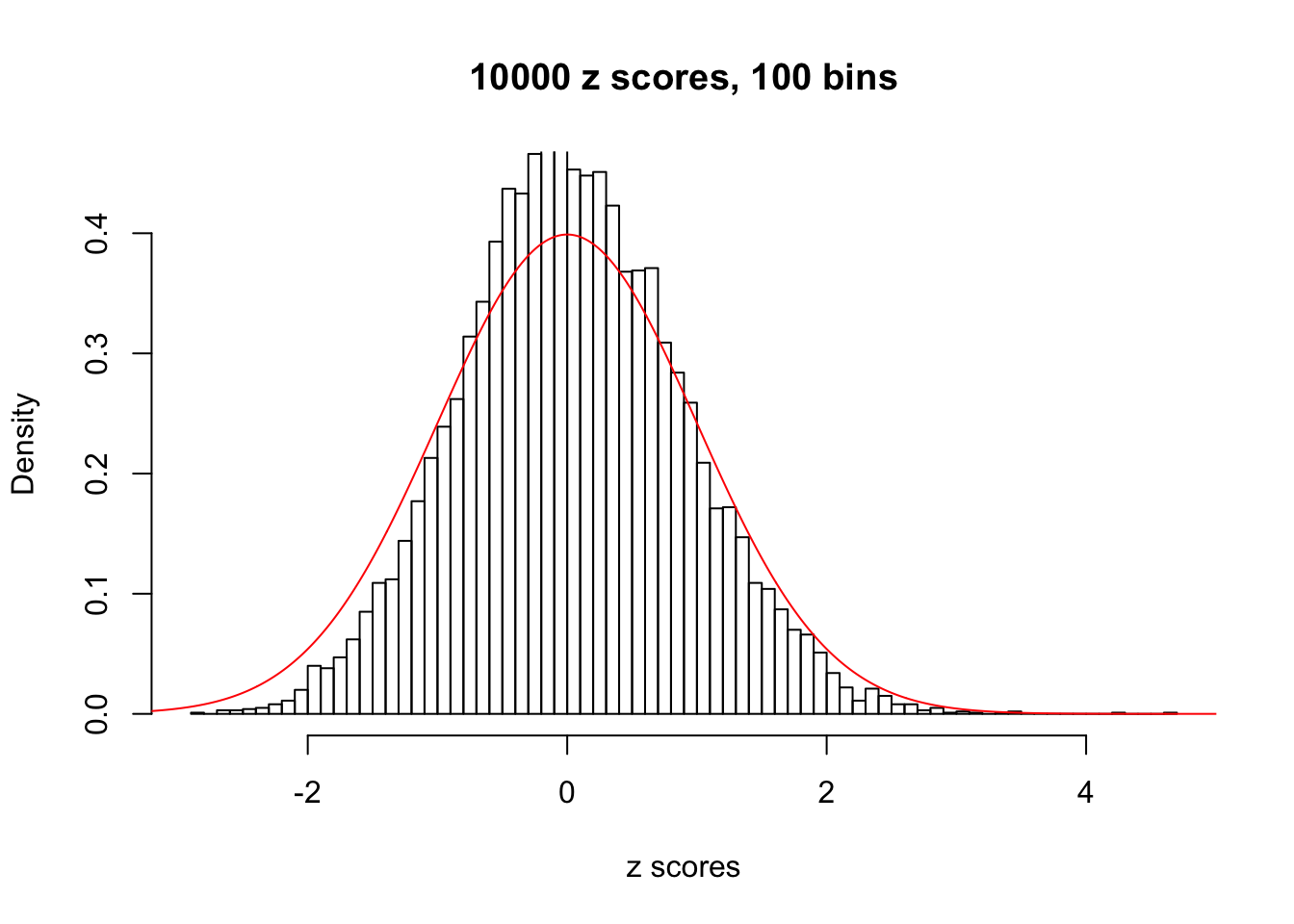
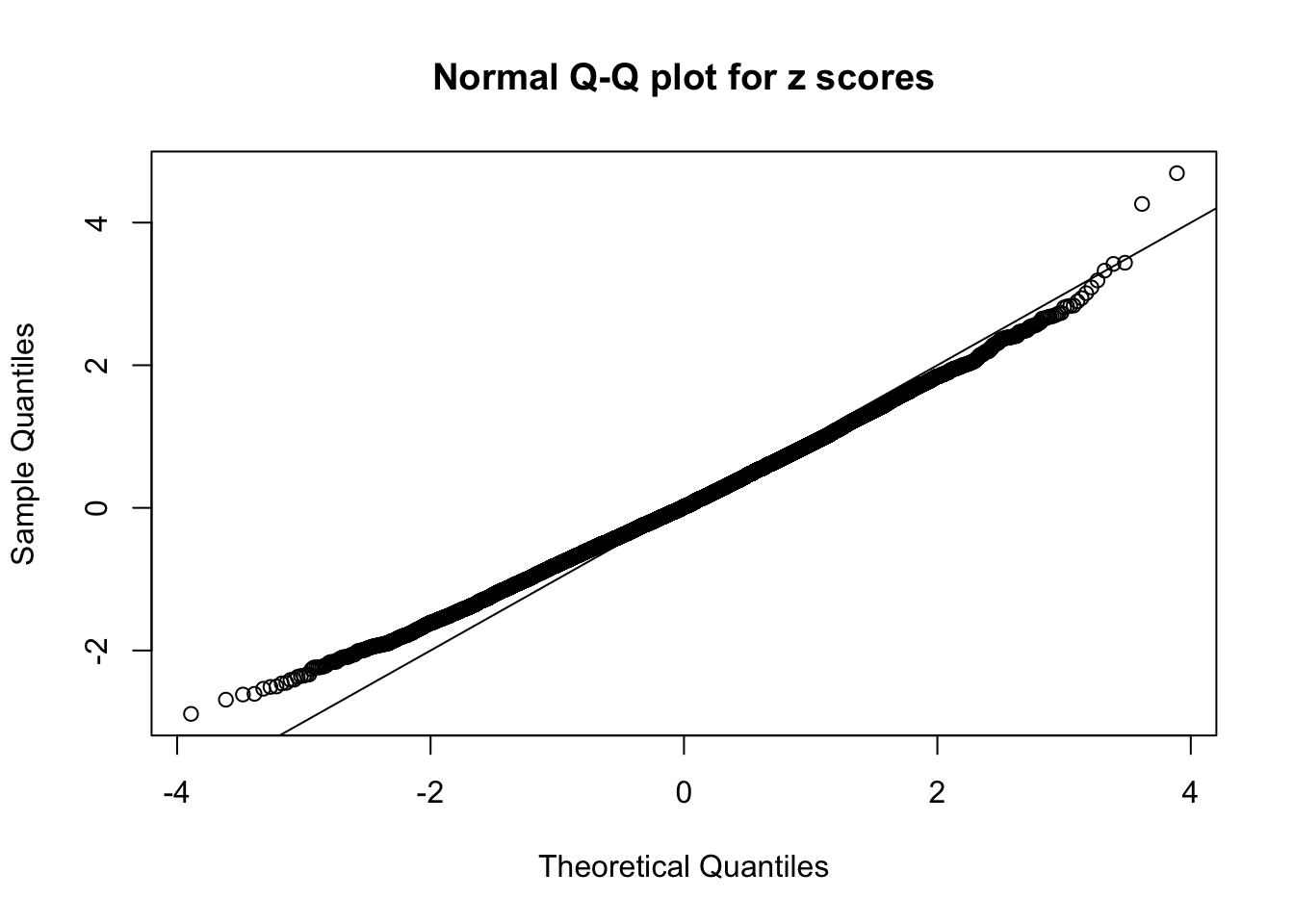
N0. 33 : Data Set 501 ; Number of False Discoveries: 1 ; pihat0 = 0.1090034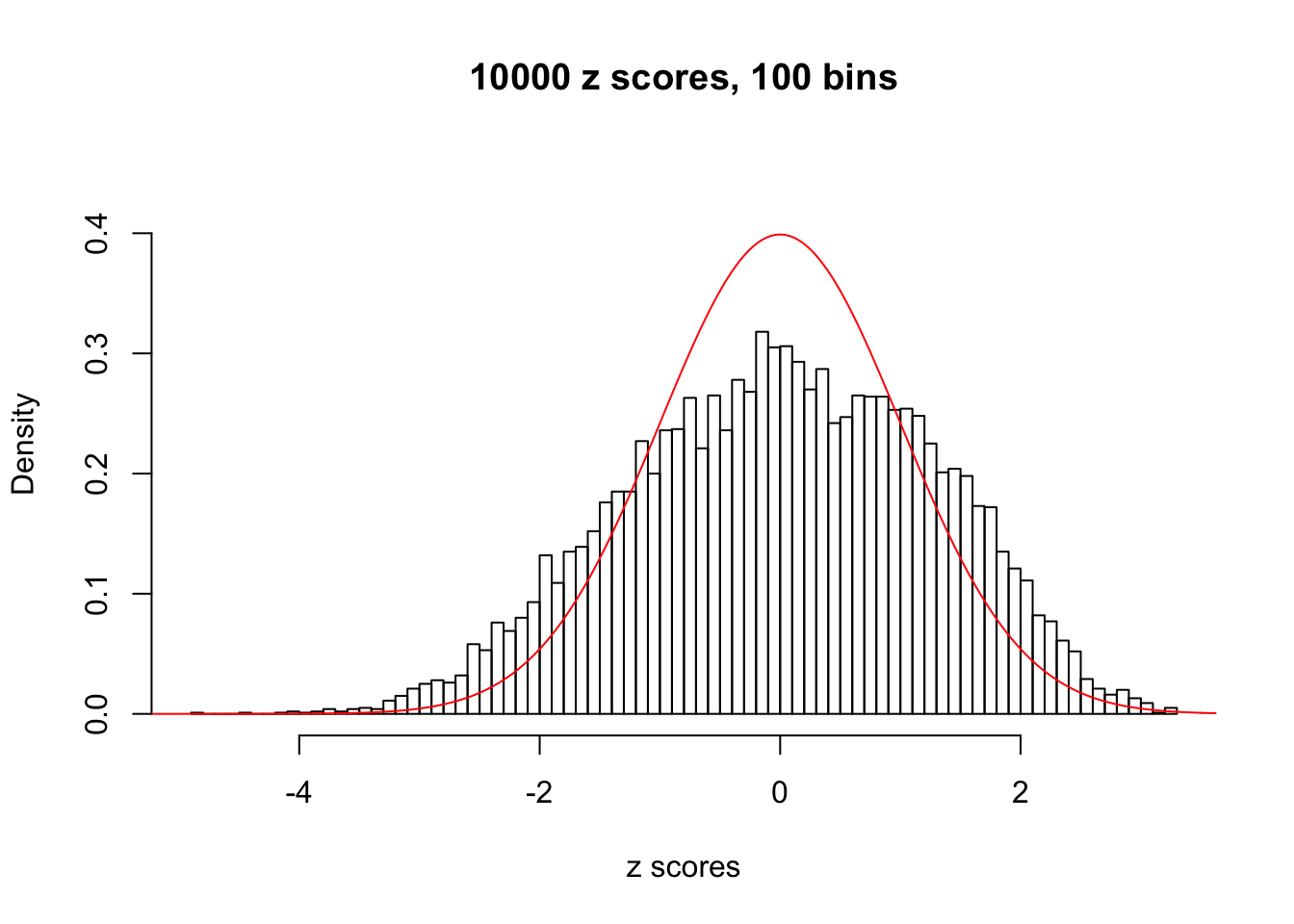
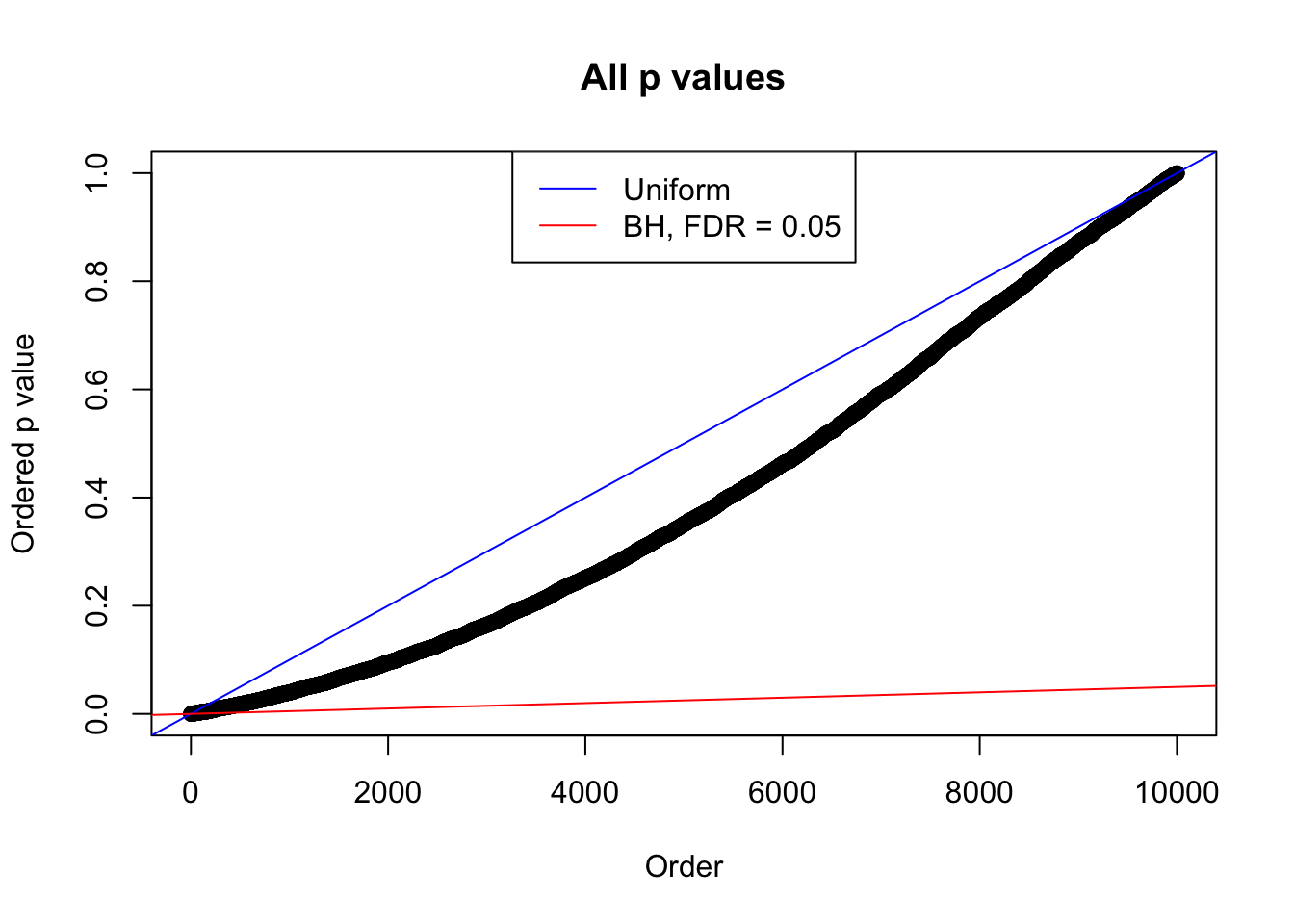
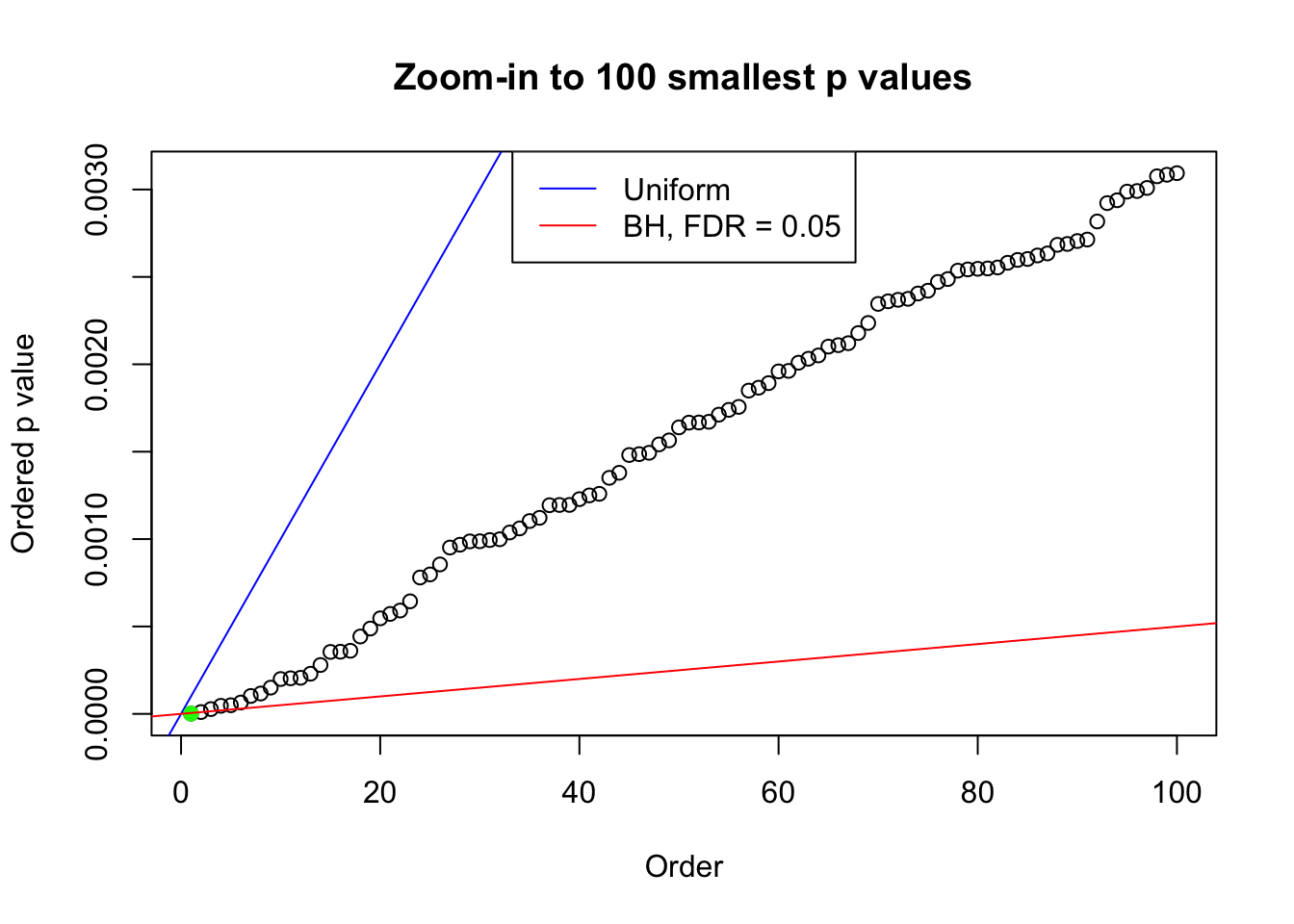
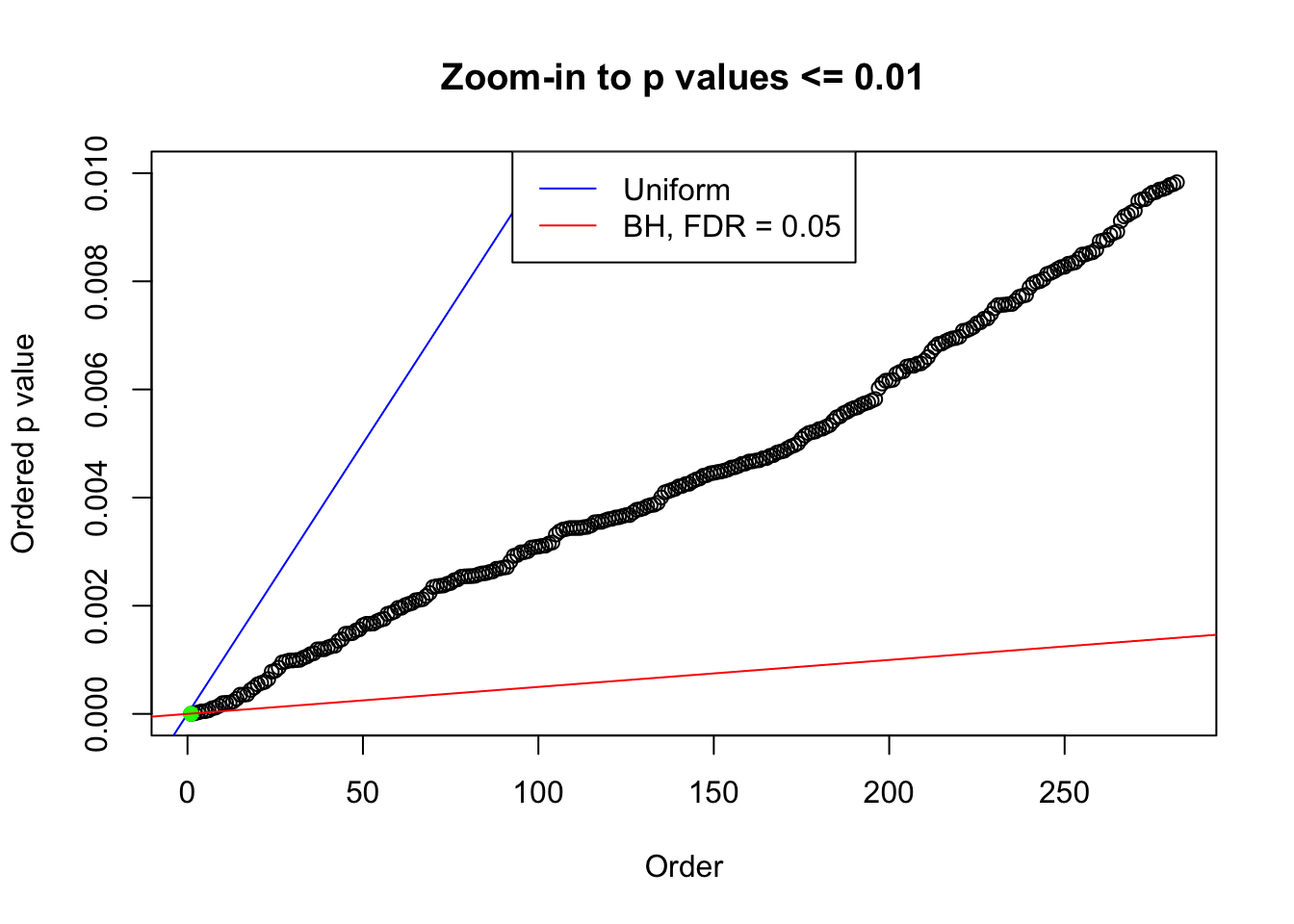
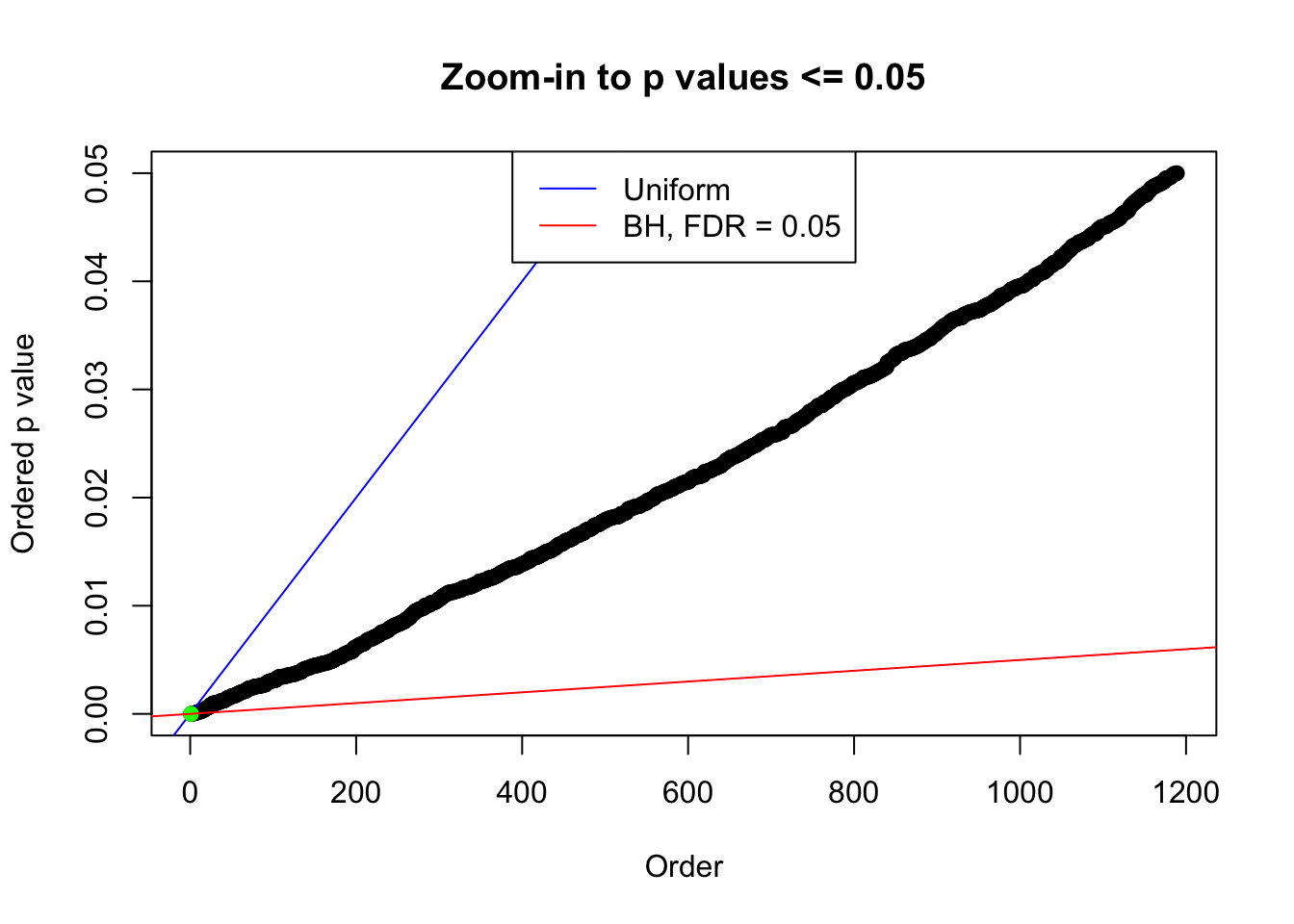
N0. 34 : Data Set 530 ; Number of False Discoveries: 1 ; pihat0 = 0.4743284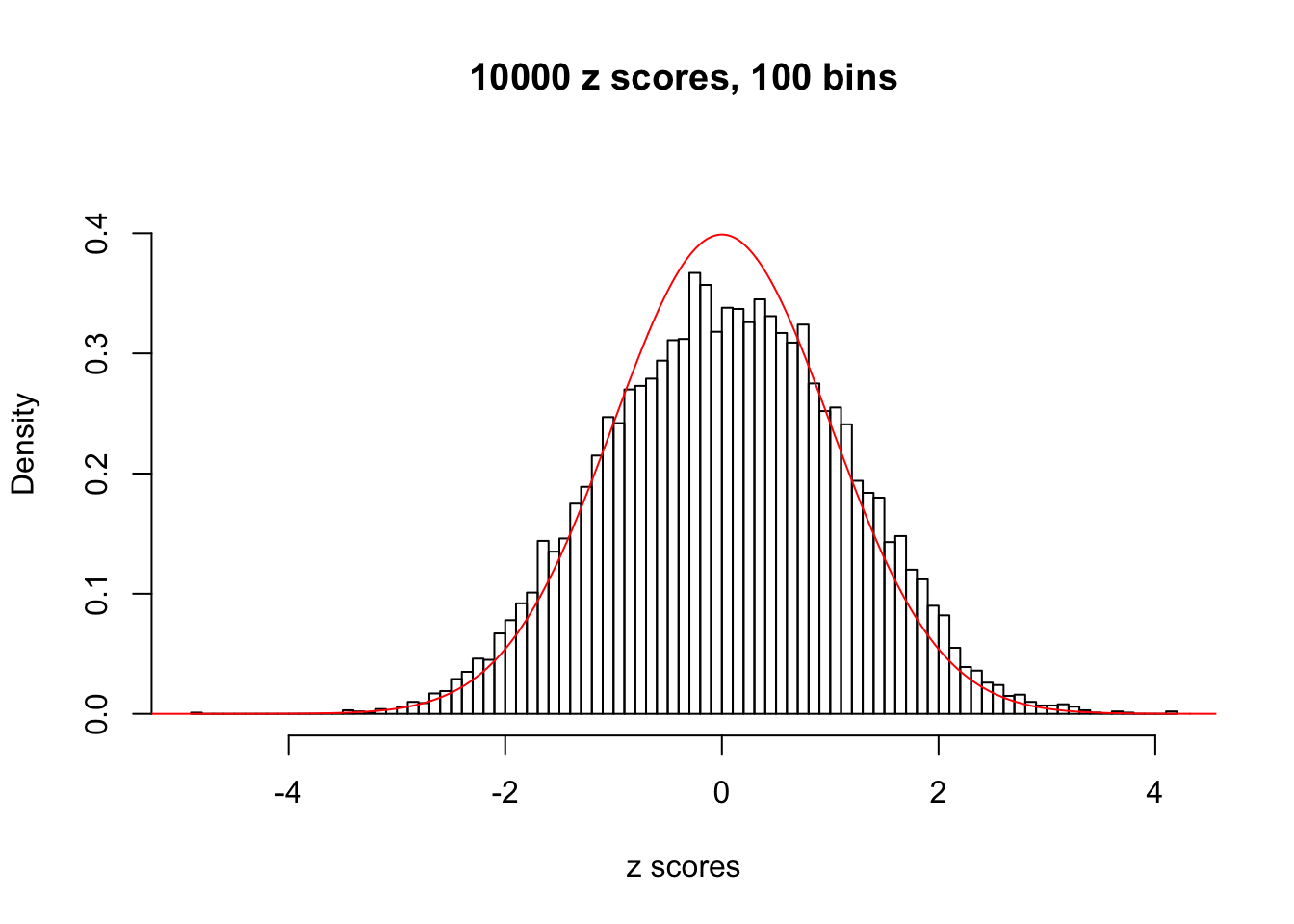
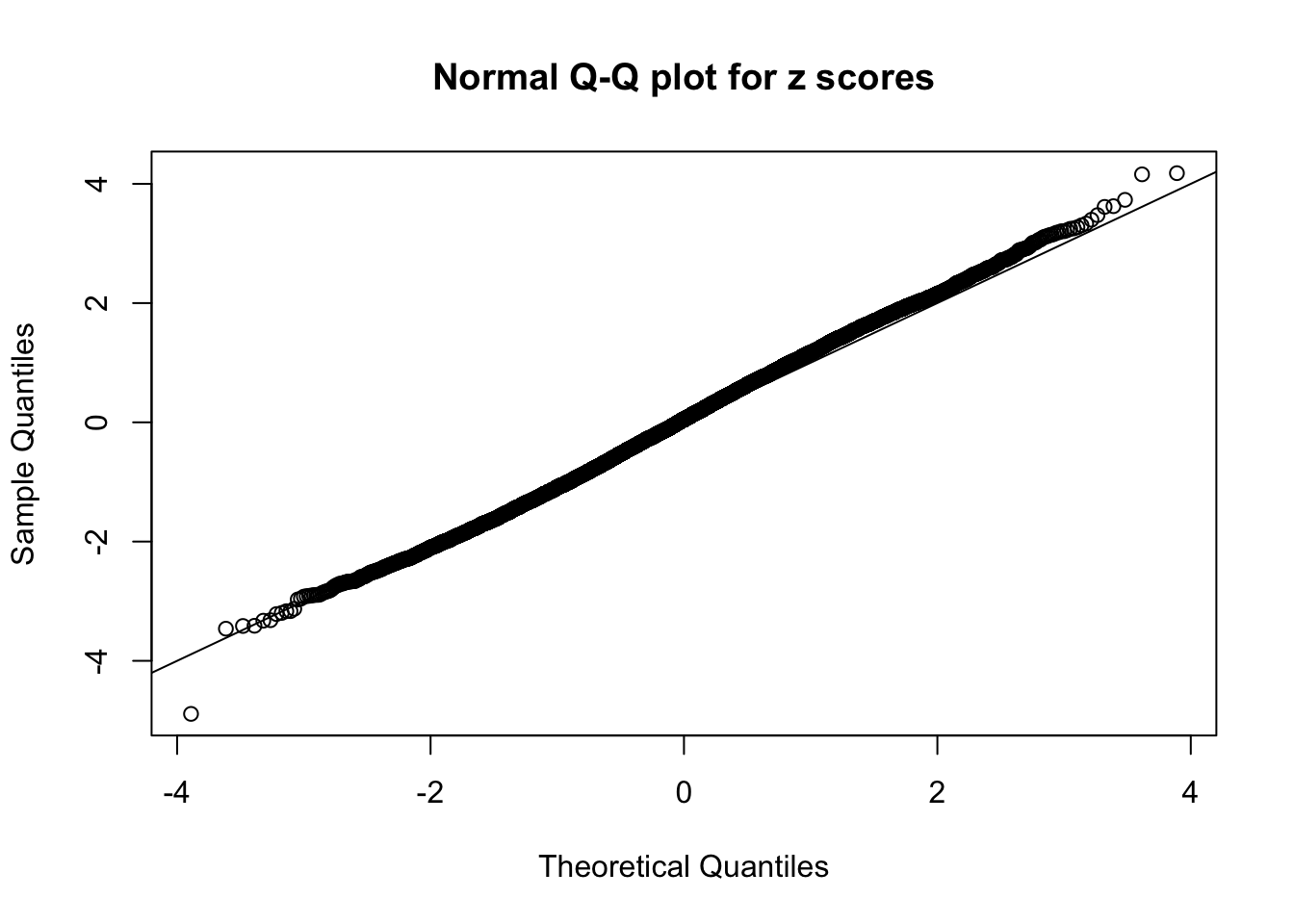
N0. 35 : Data Set 574 ; Number of False Discoveries: 1 ; pihat0 = 0.5260185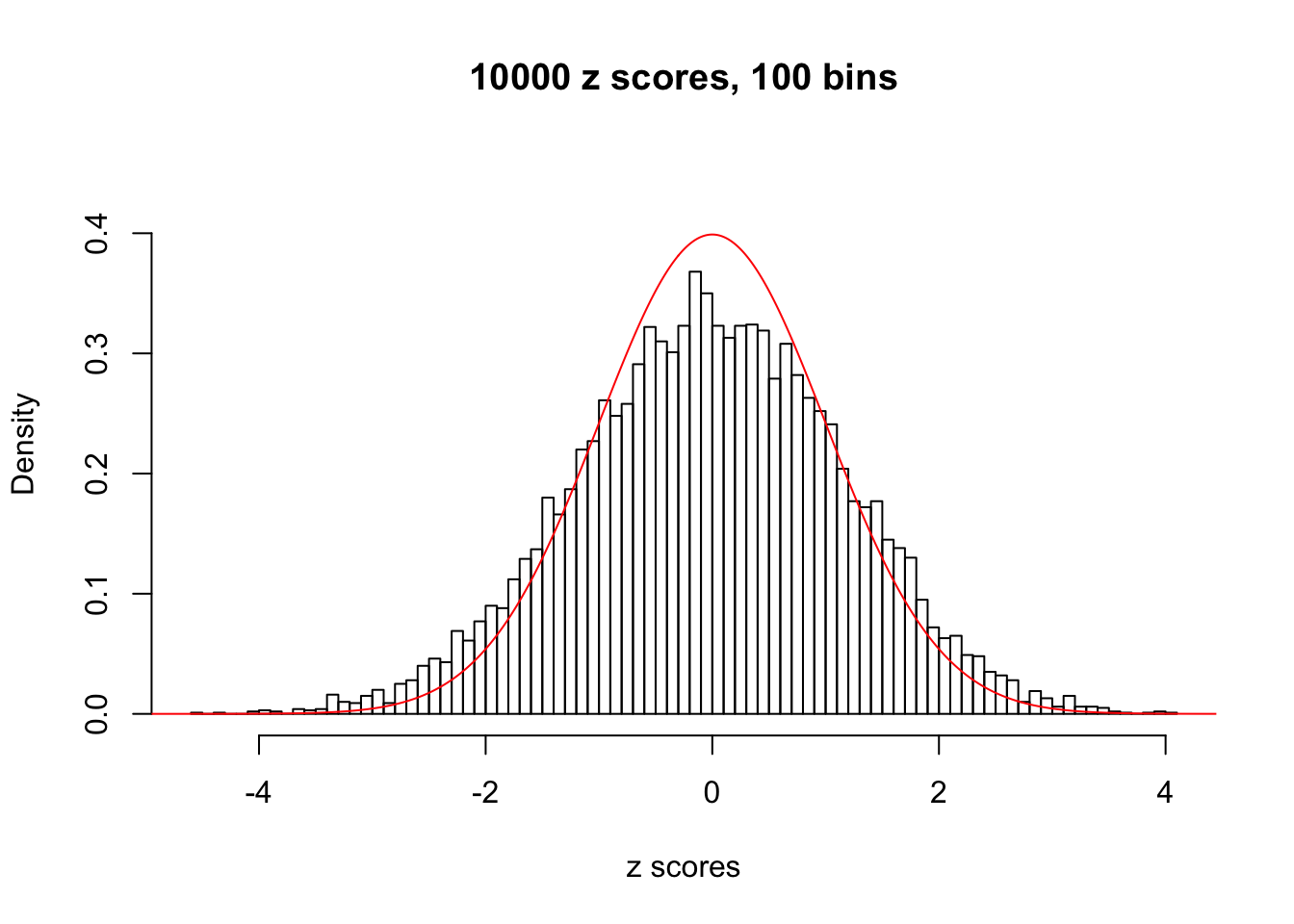
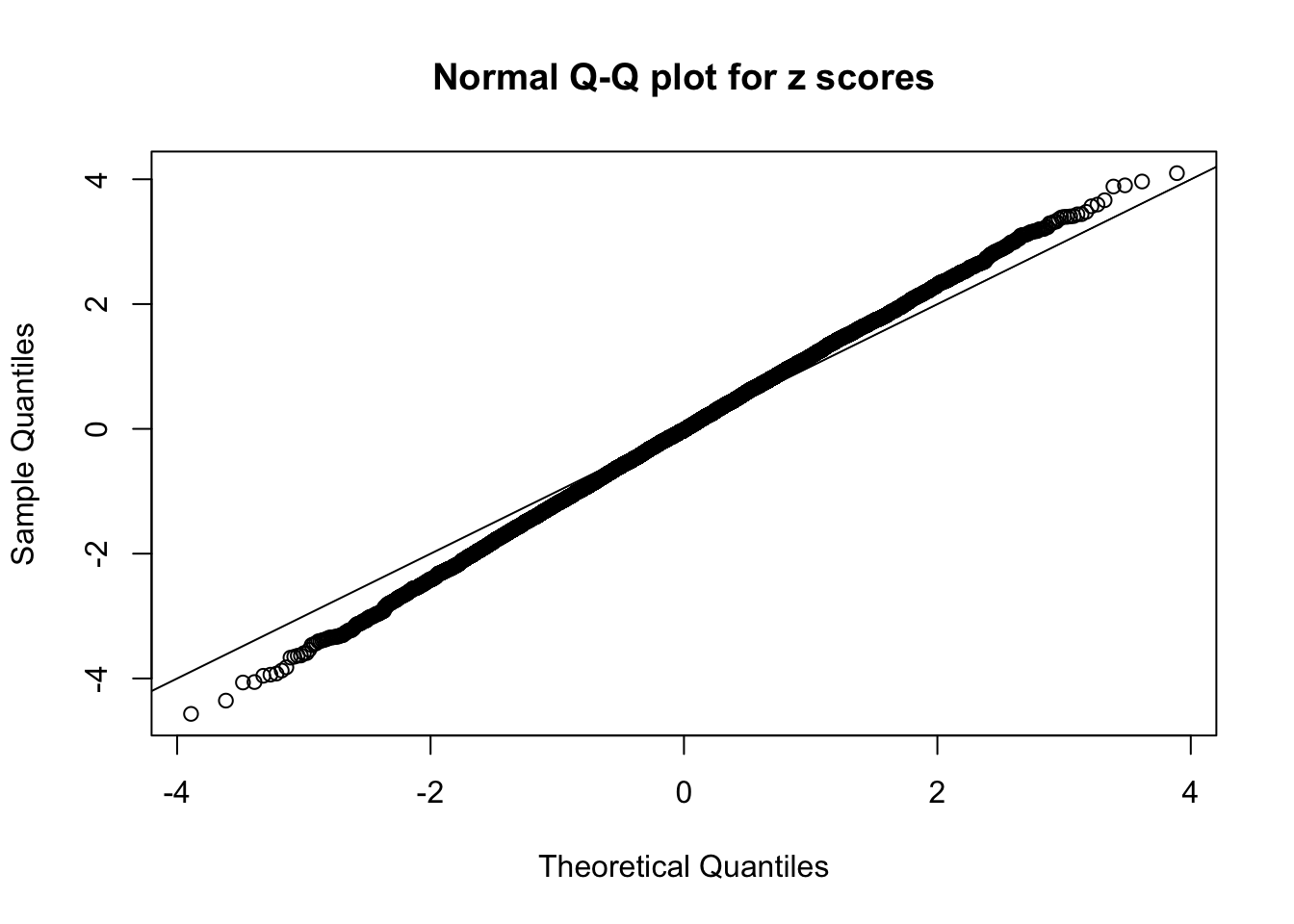
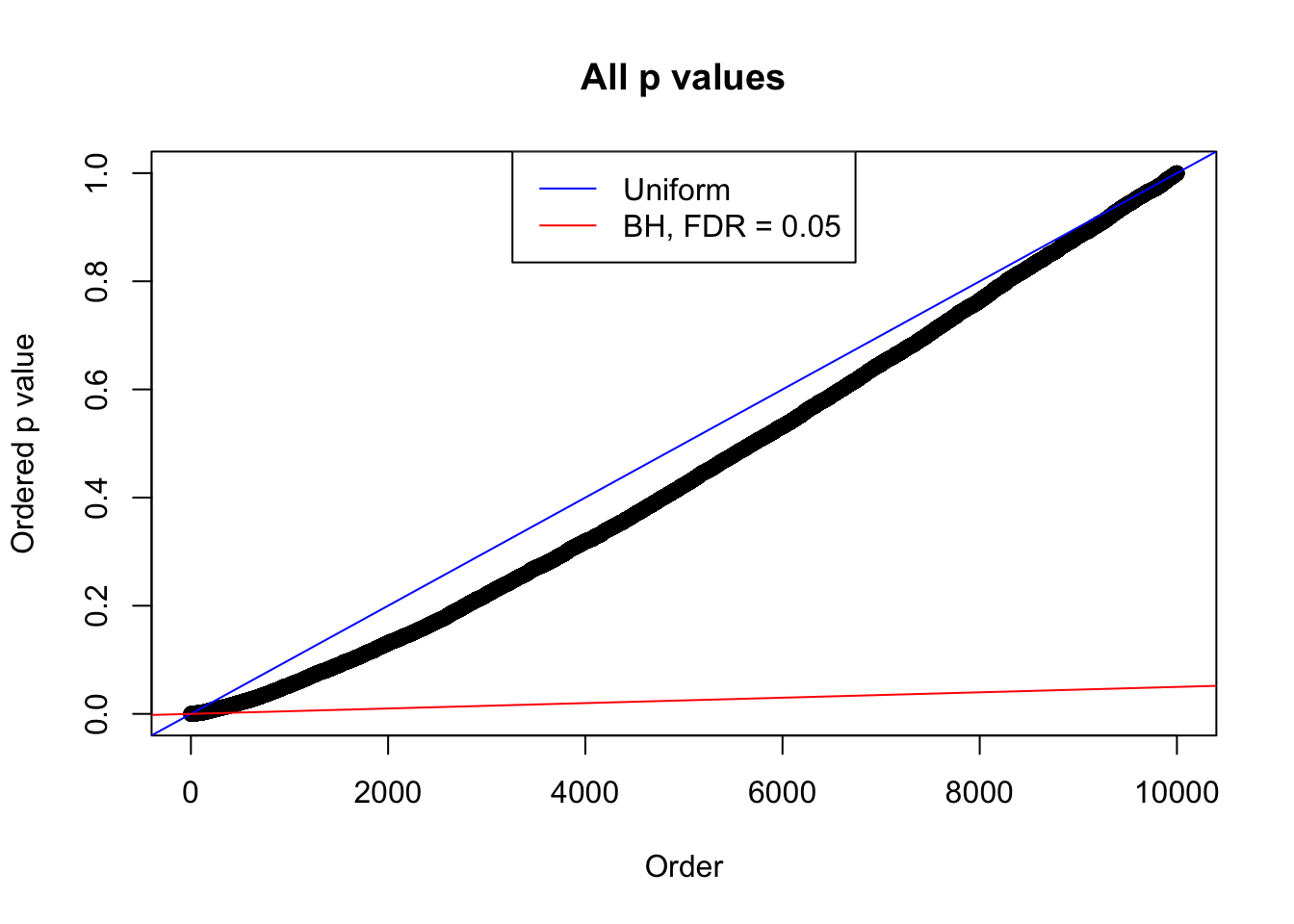
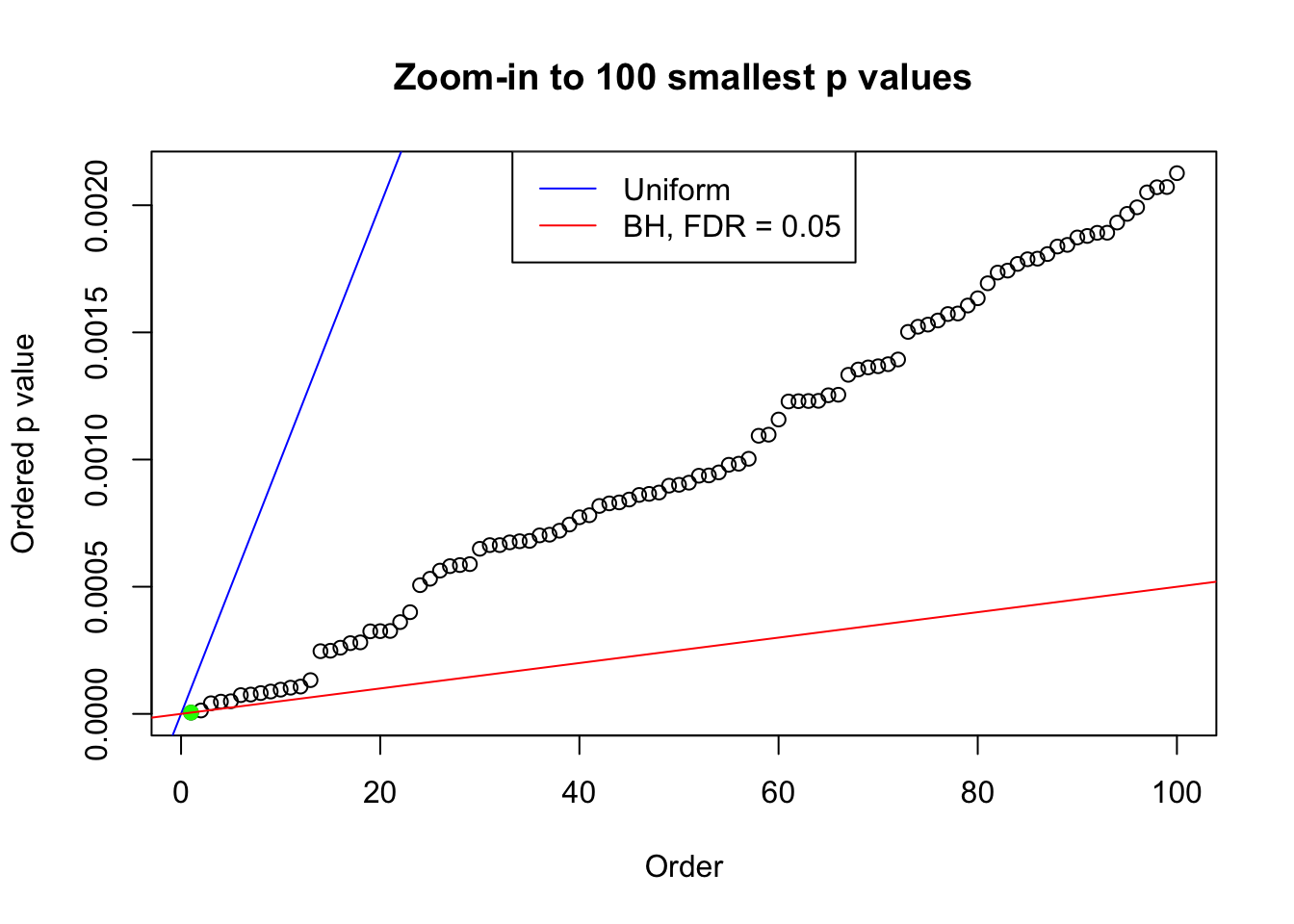
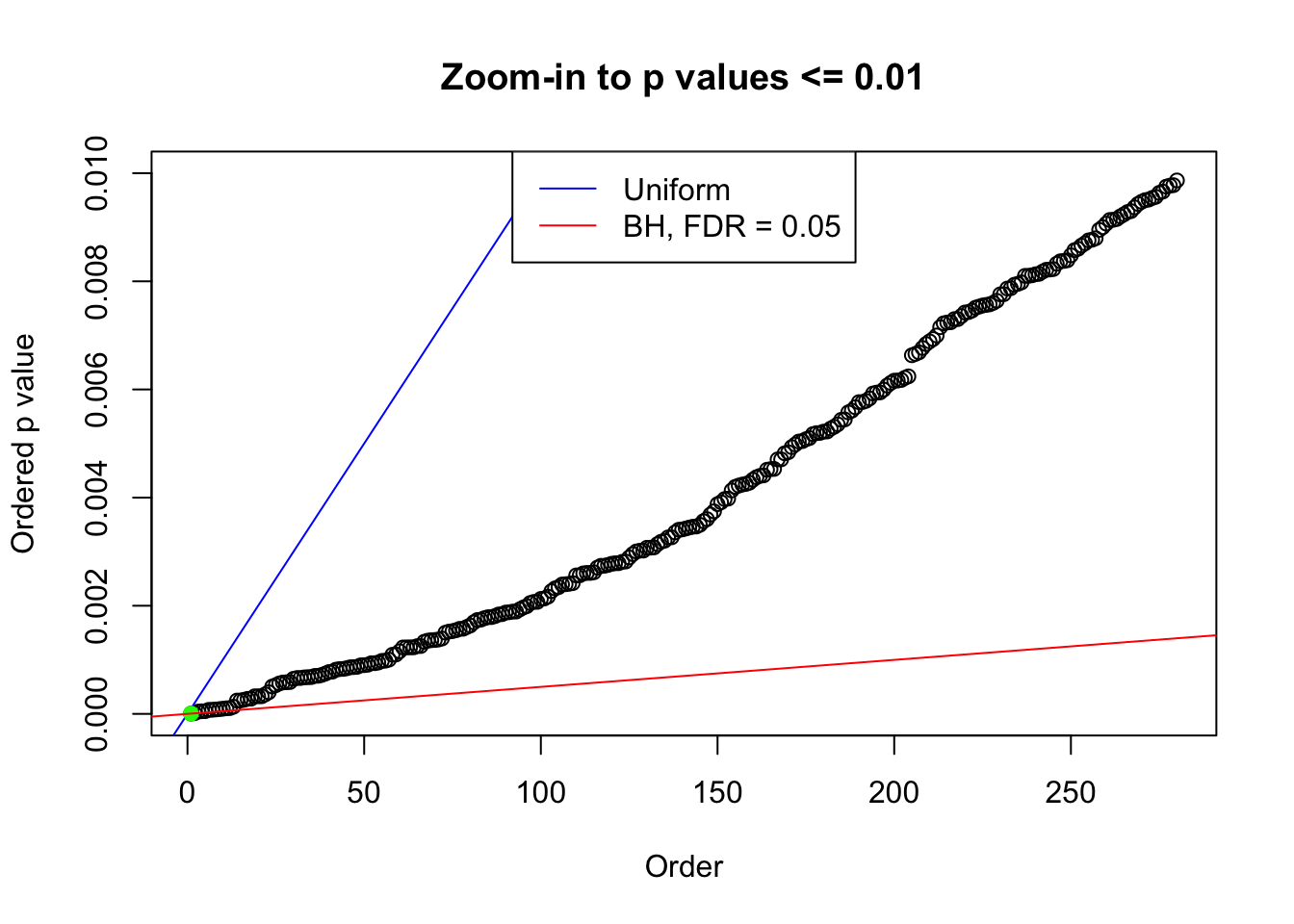
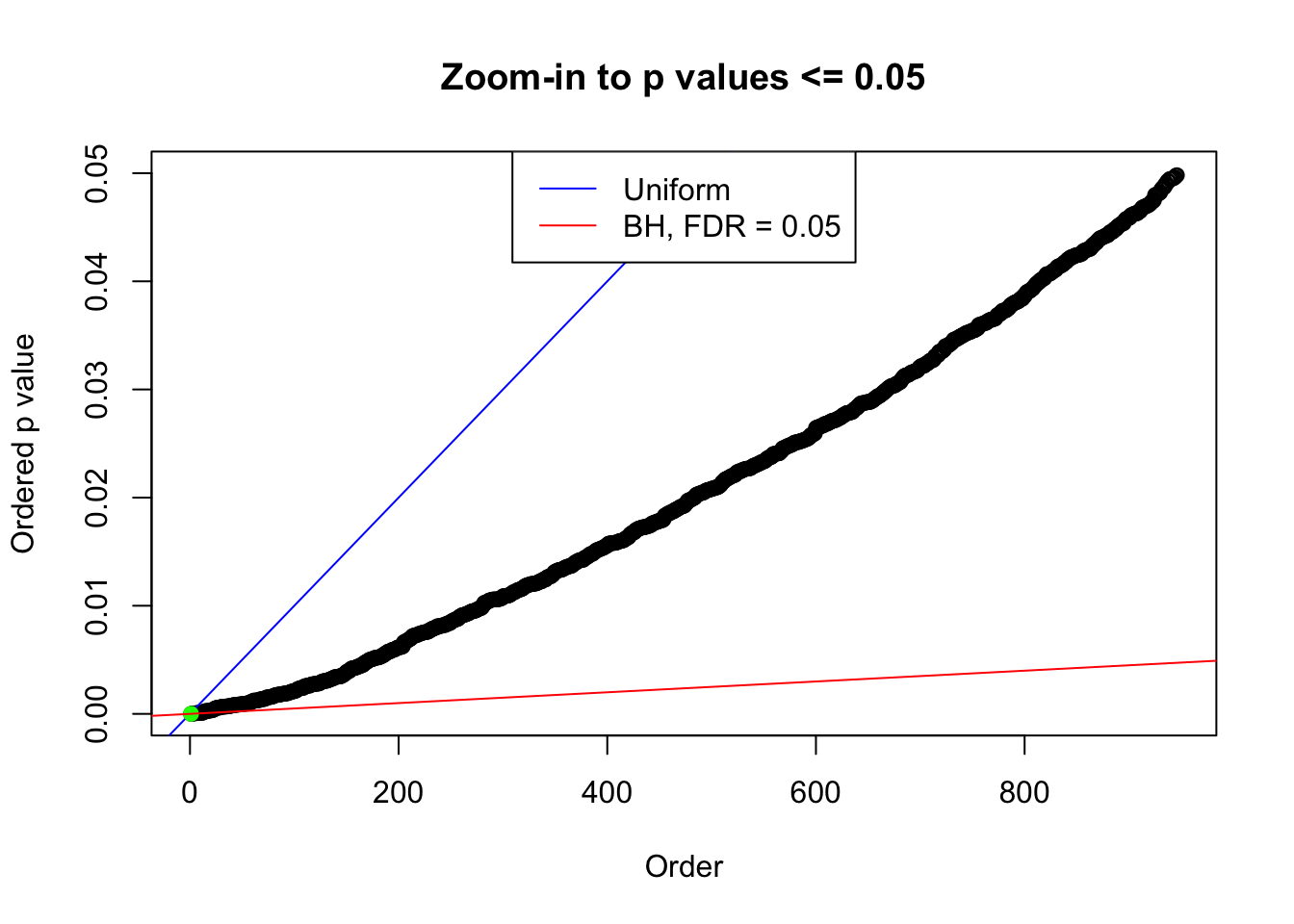
N0. 36 : Data Set 575 ; Number of False Discoveries: 1 ; pihat0 = 0.0946117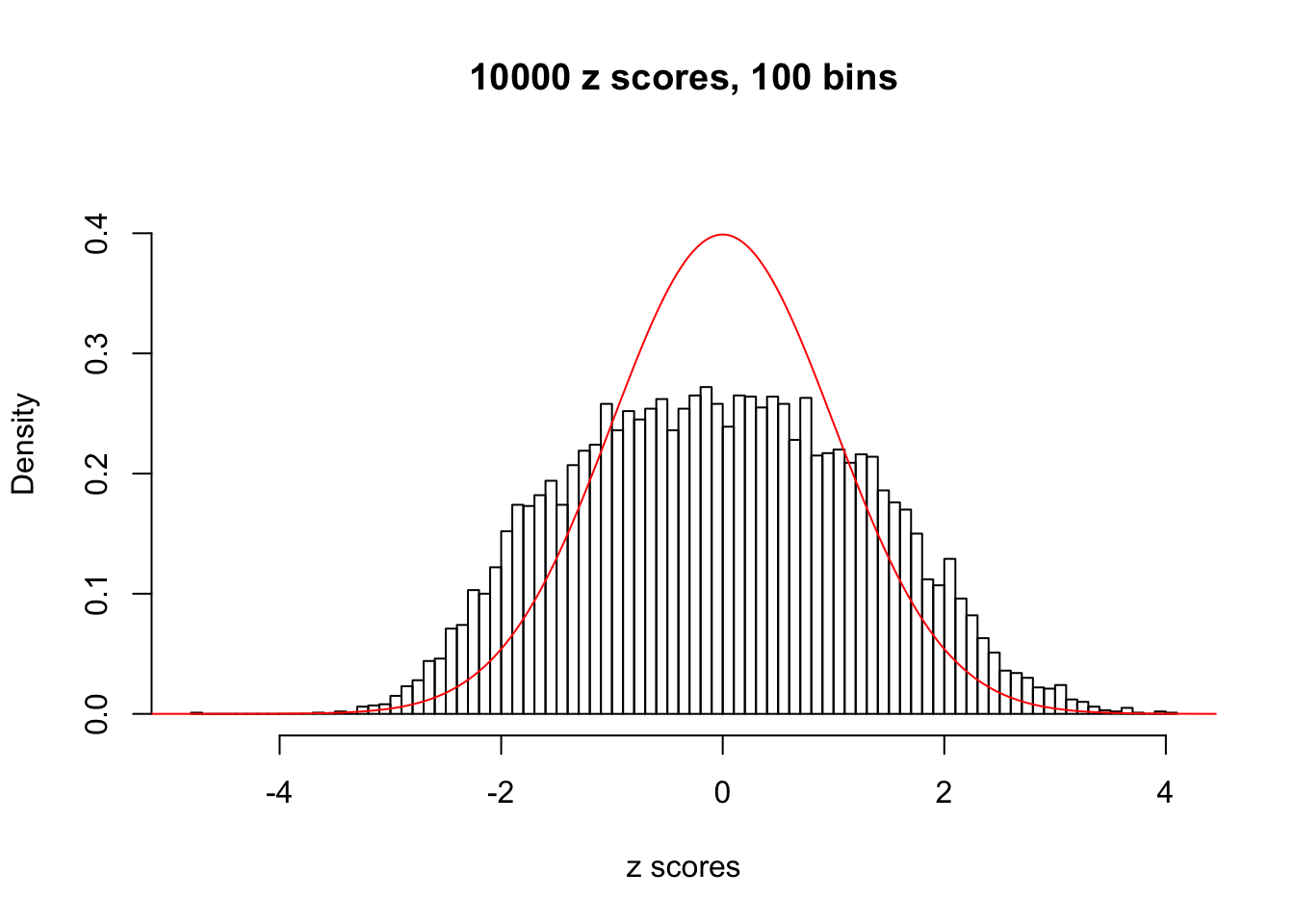
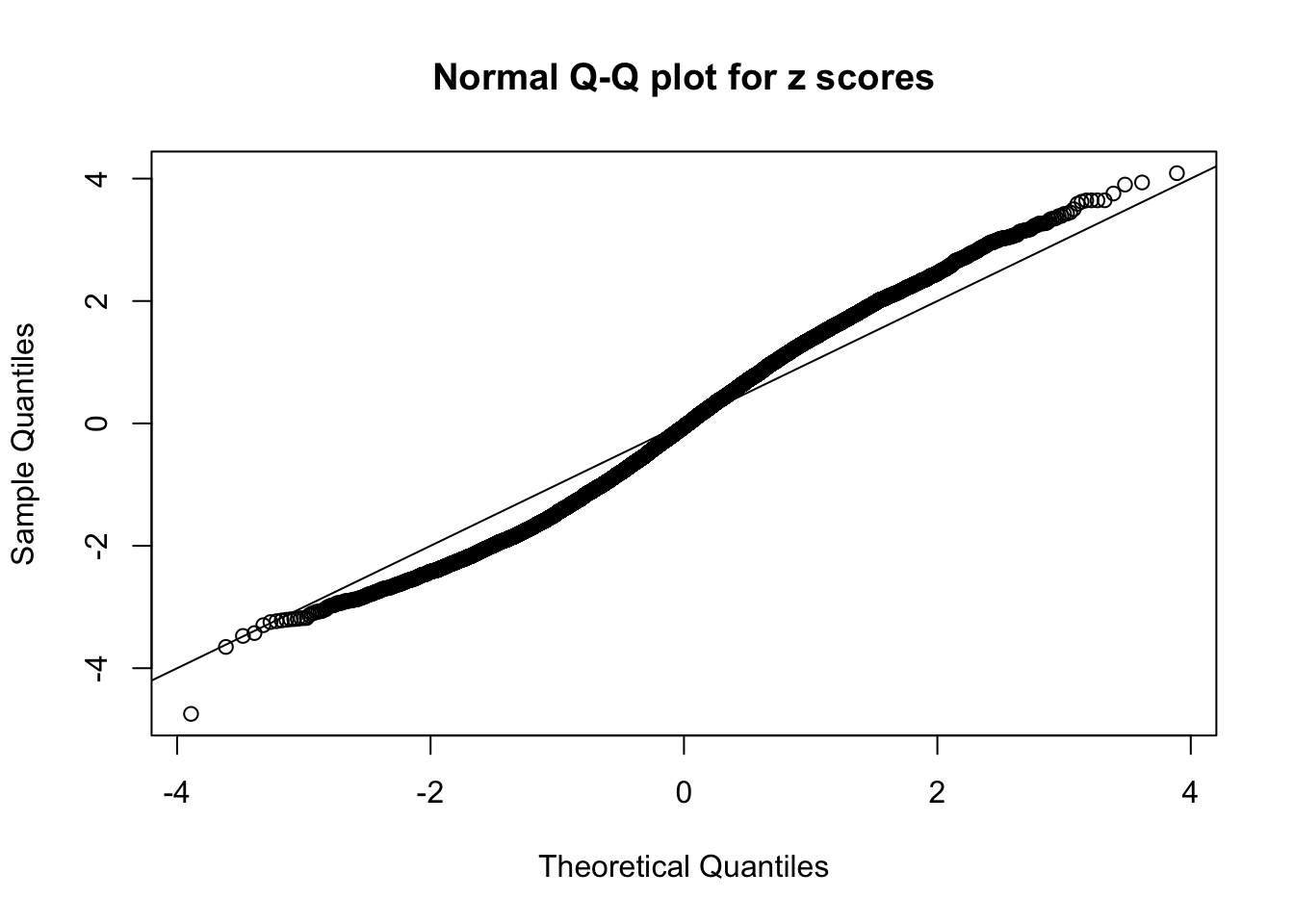
N0. 37 : Data Set 643 ; Number of False Discoveries: 1 ; pihat0 = 0.3321723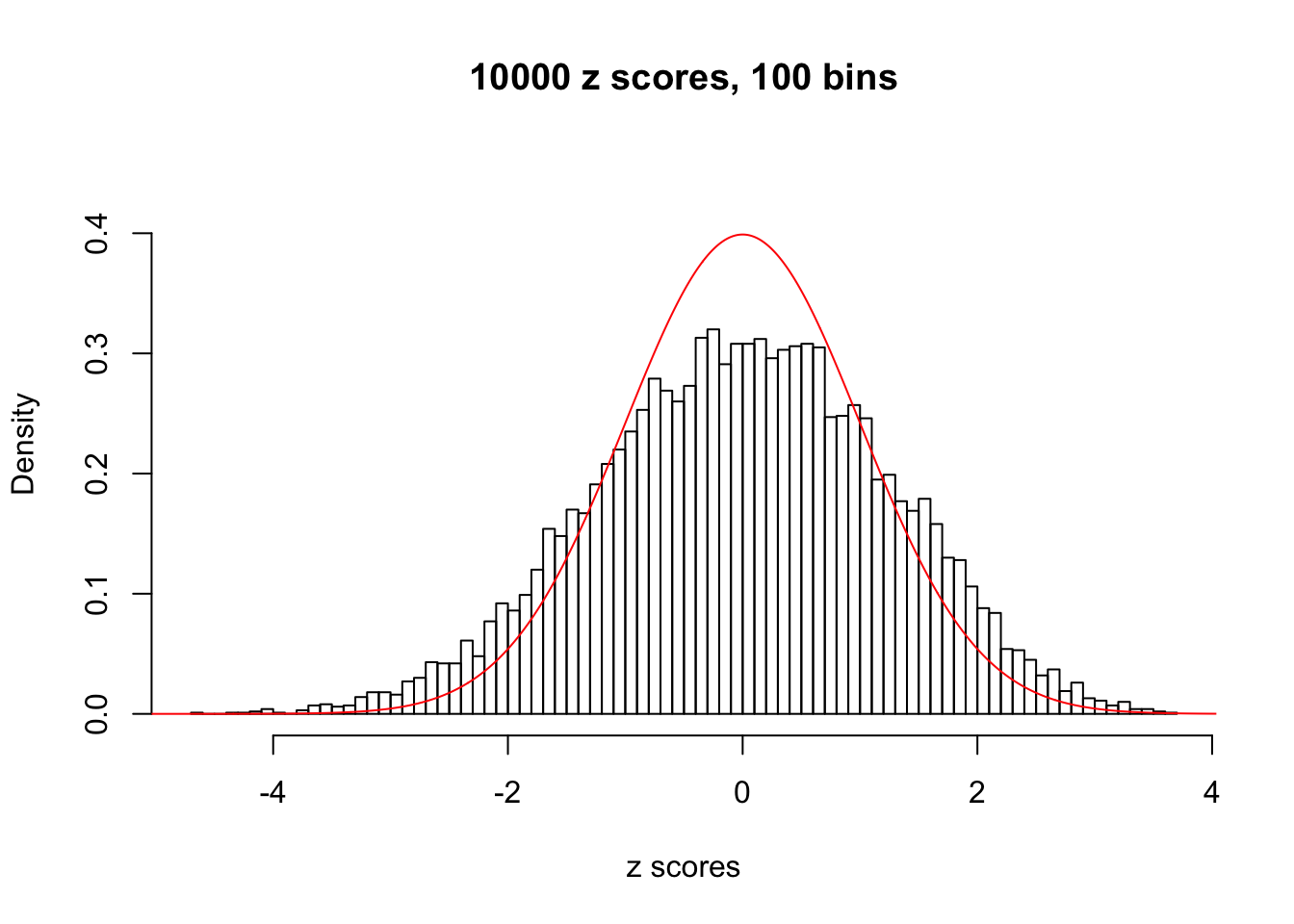
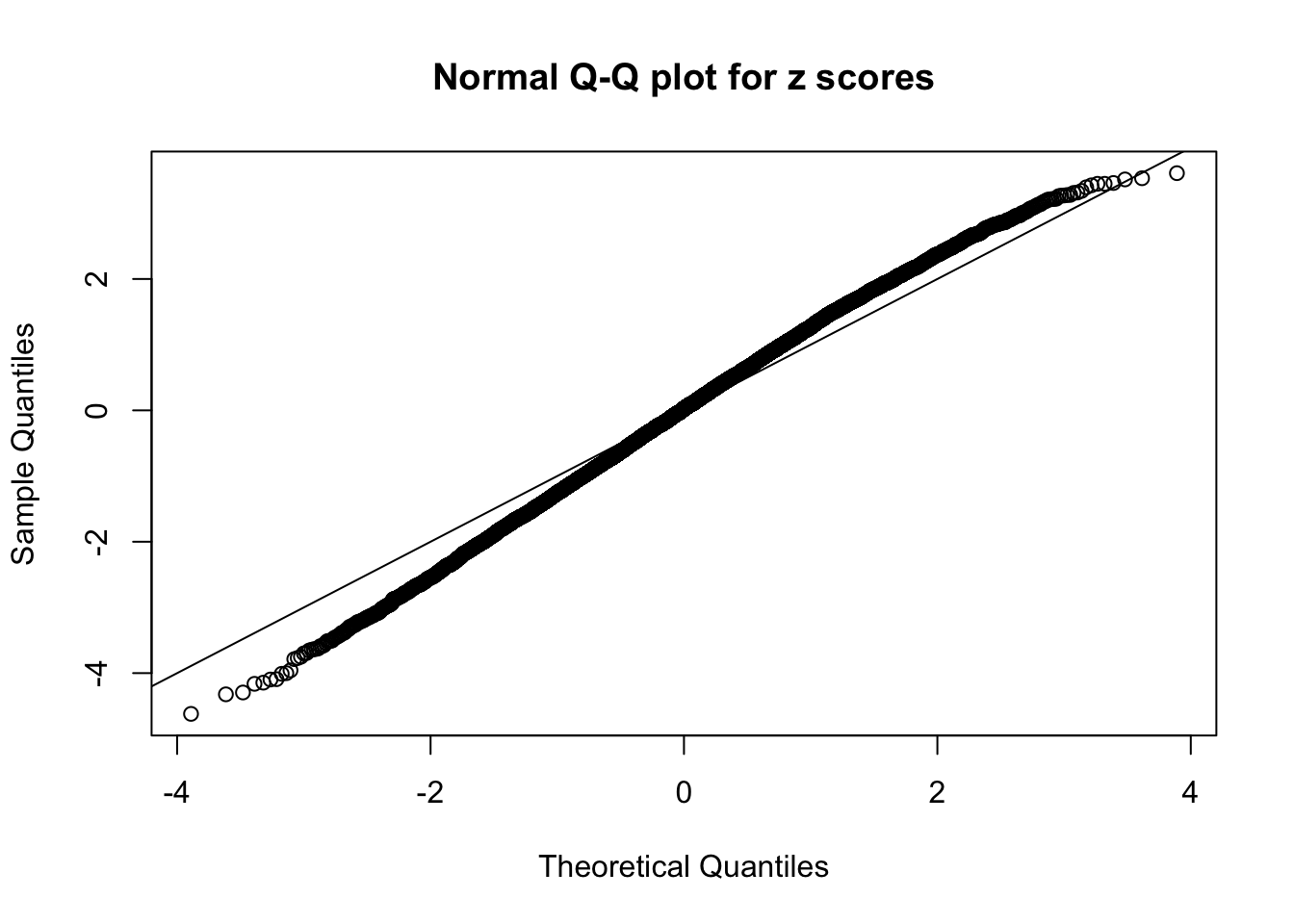
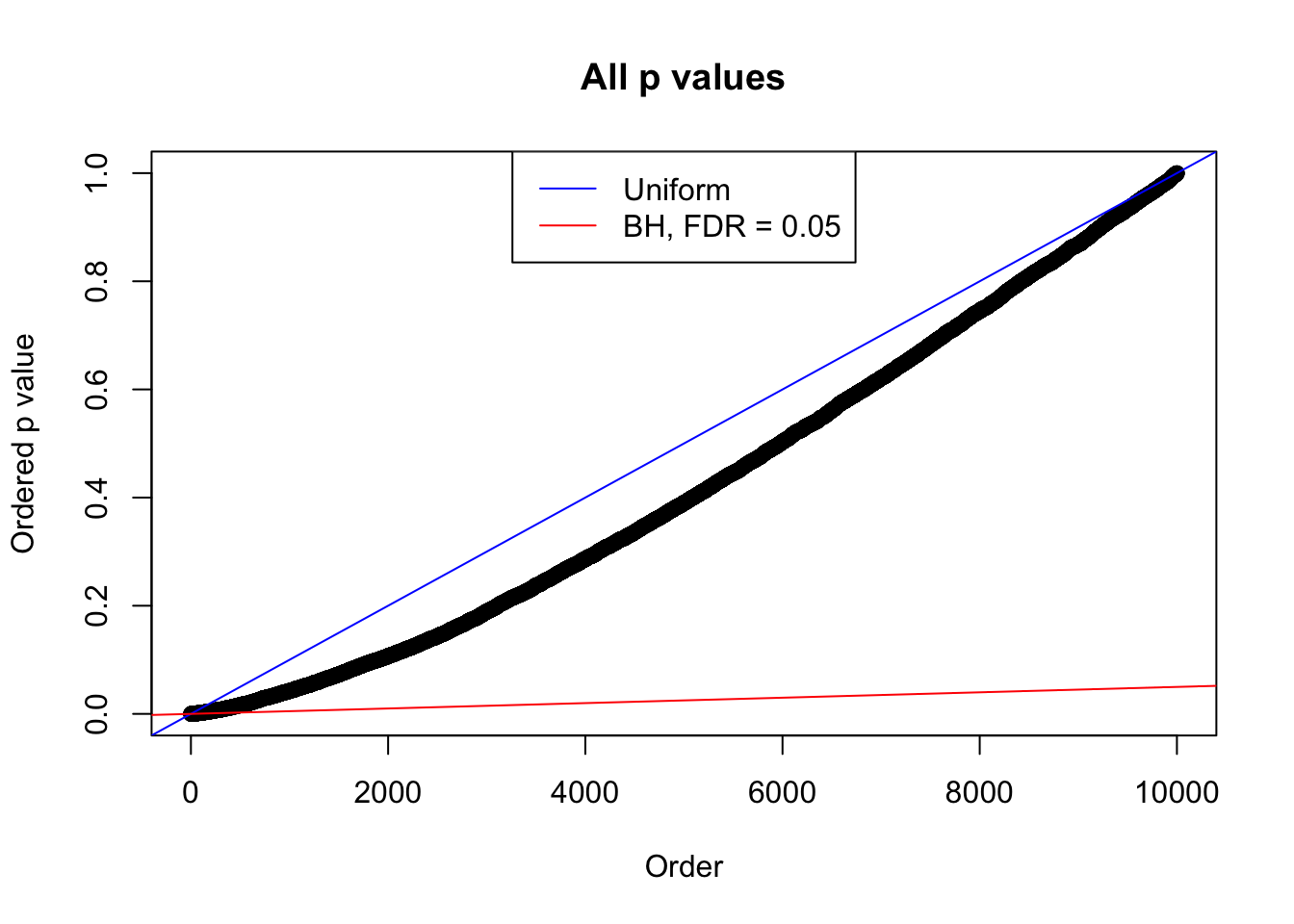
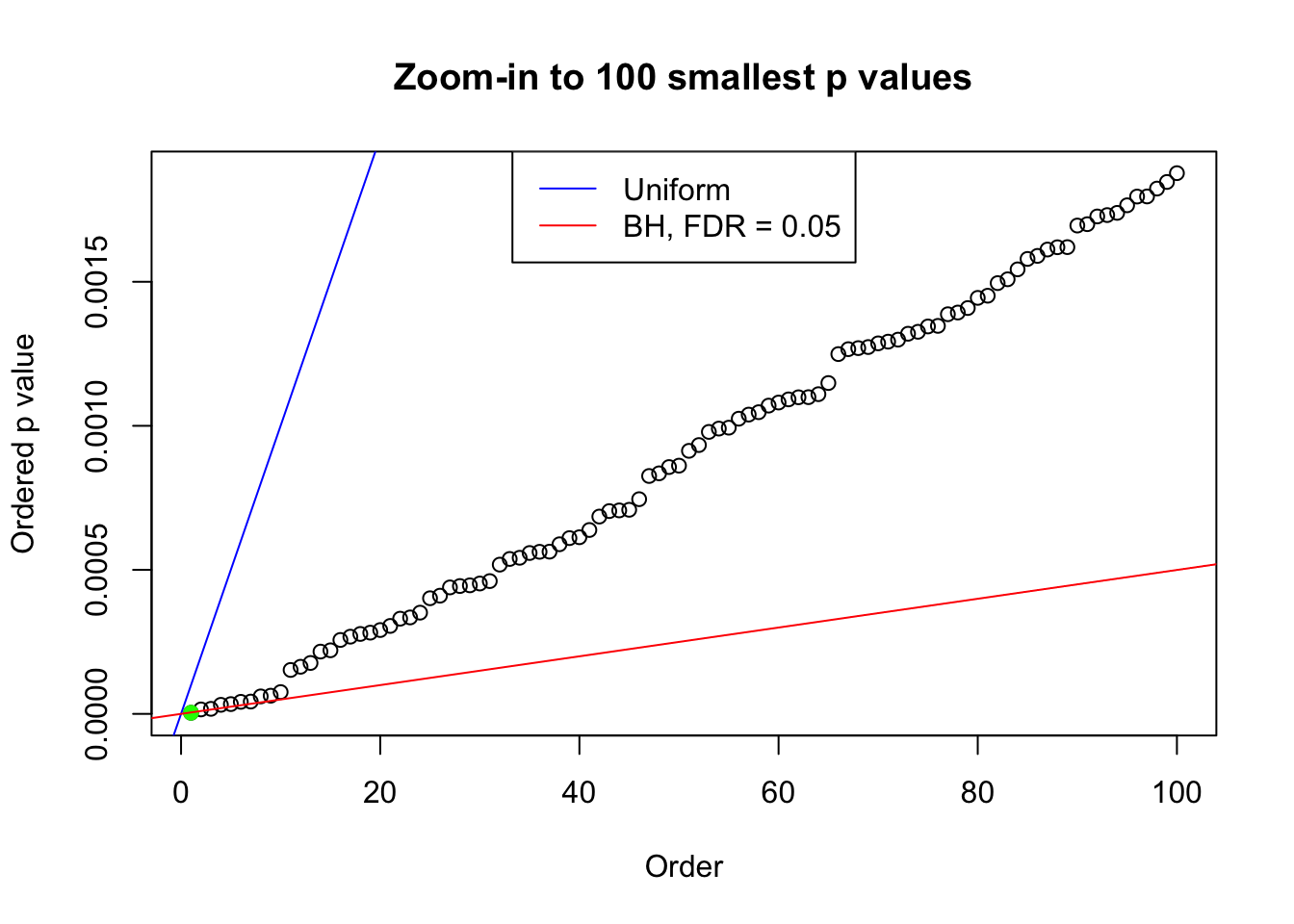
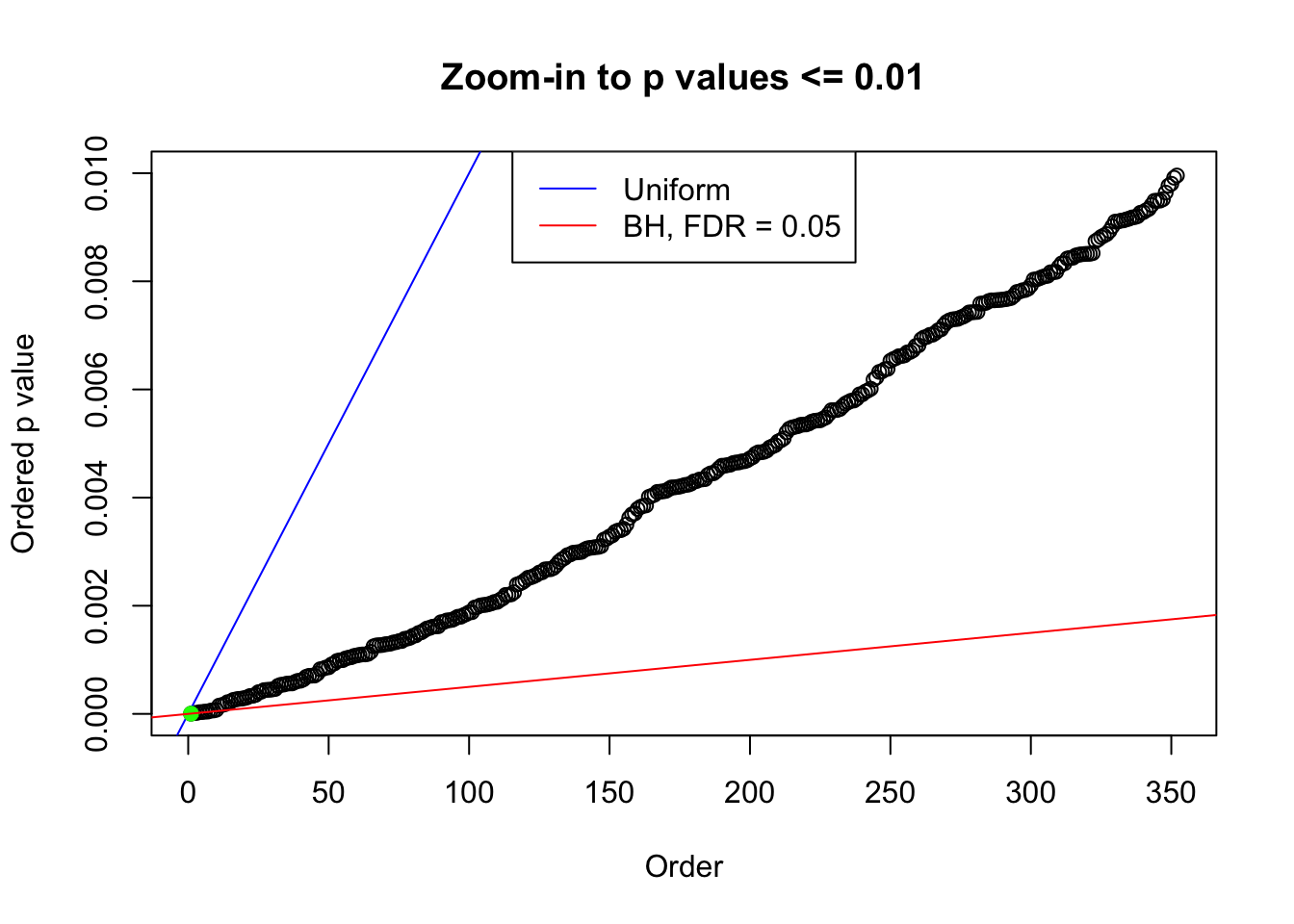
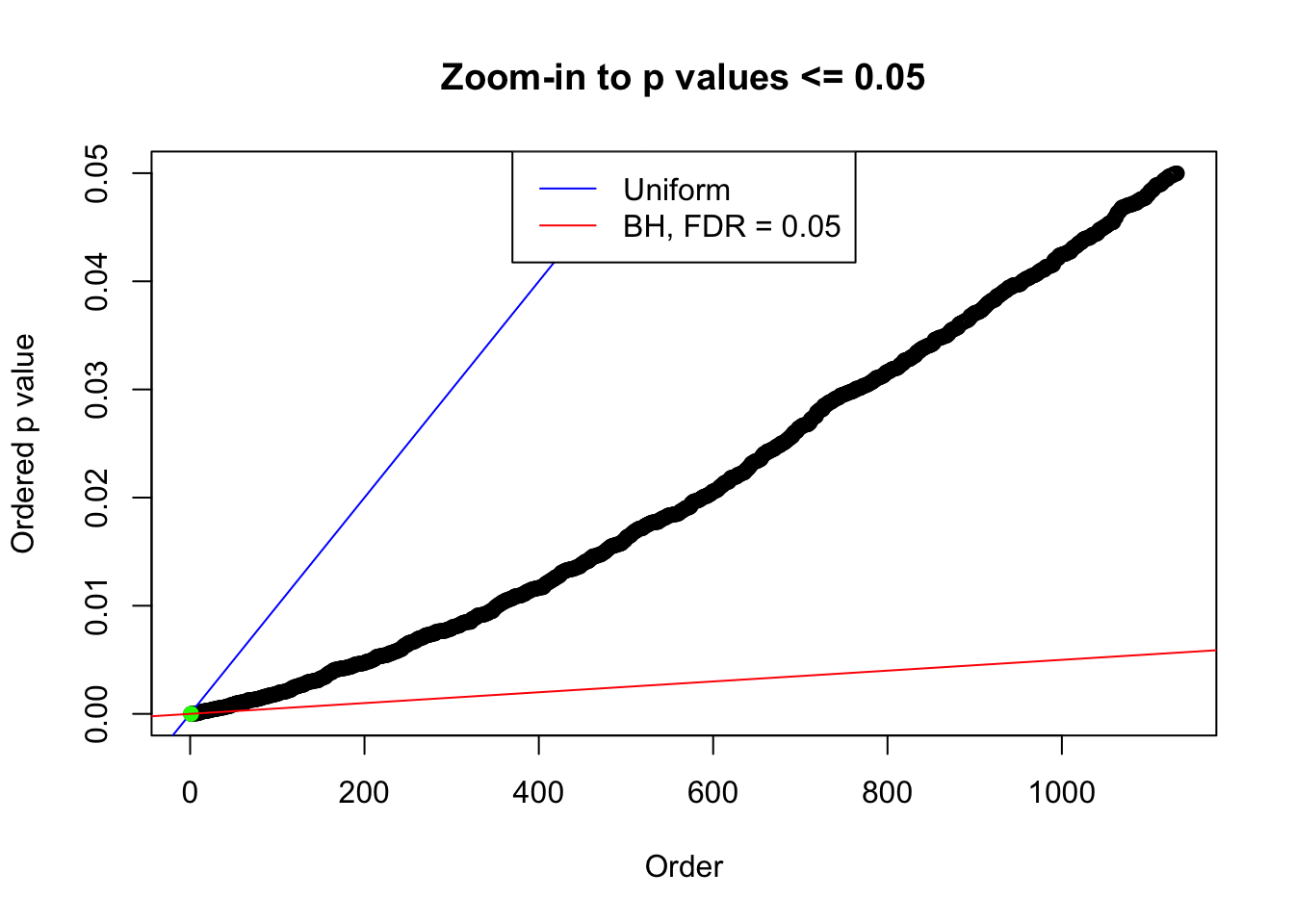
N0. 38 : Data Set 769 ; Number of False Discoveries: 1 ; pihat0 = 0.1187511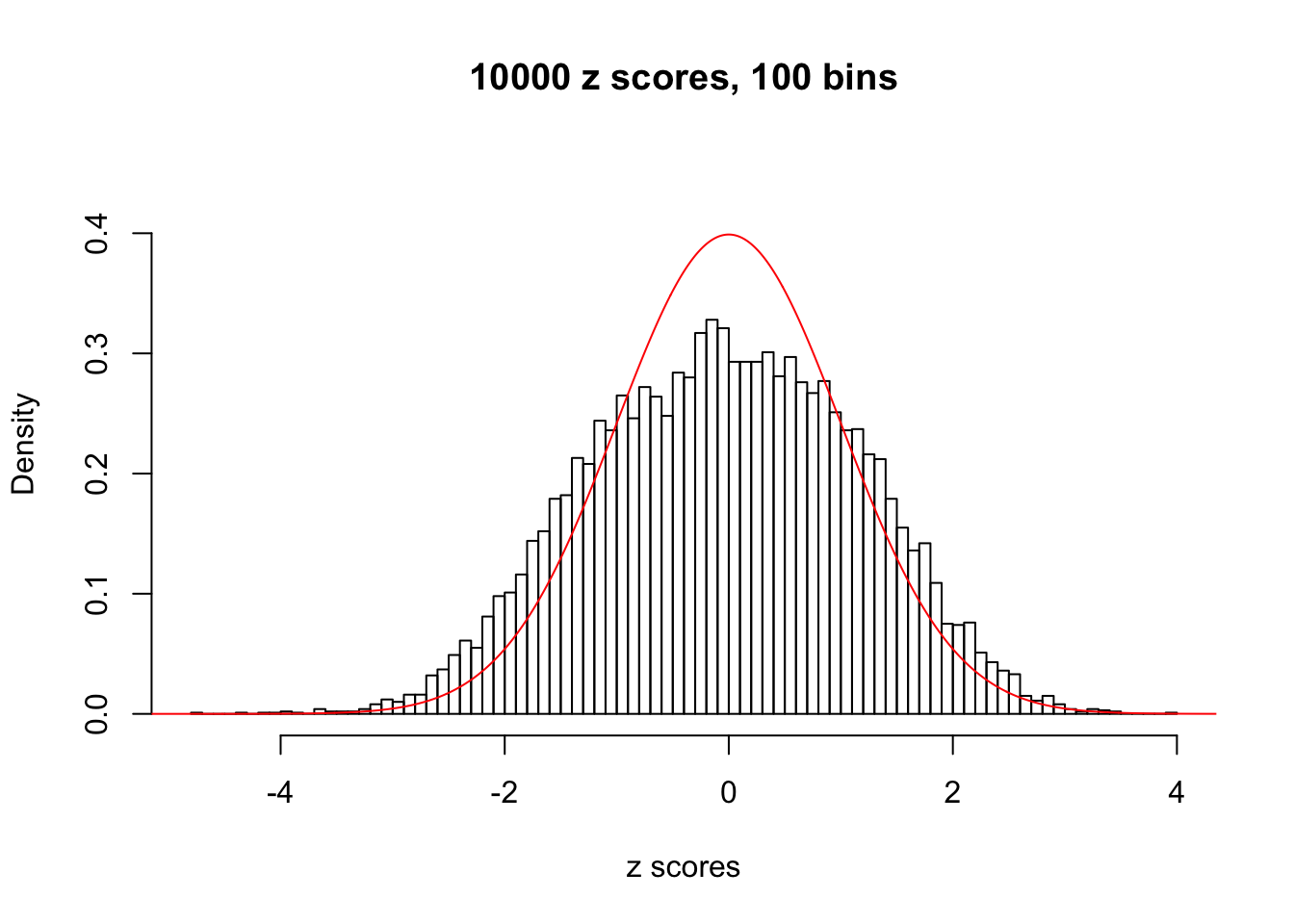
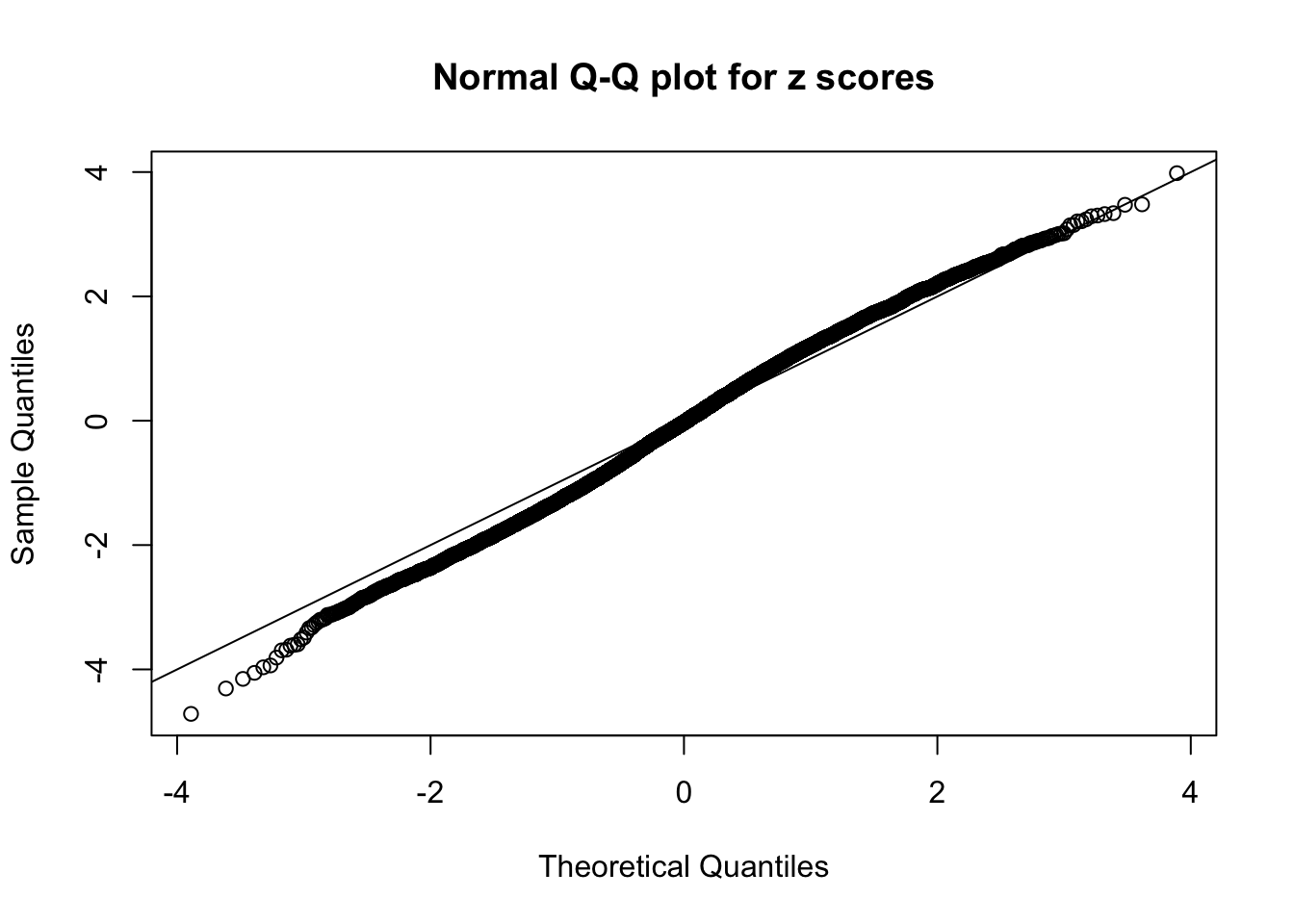
N0. 39 : Data Set 778 ; Number of False Discoveries: 1 ; pihat0 = 0.07619716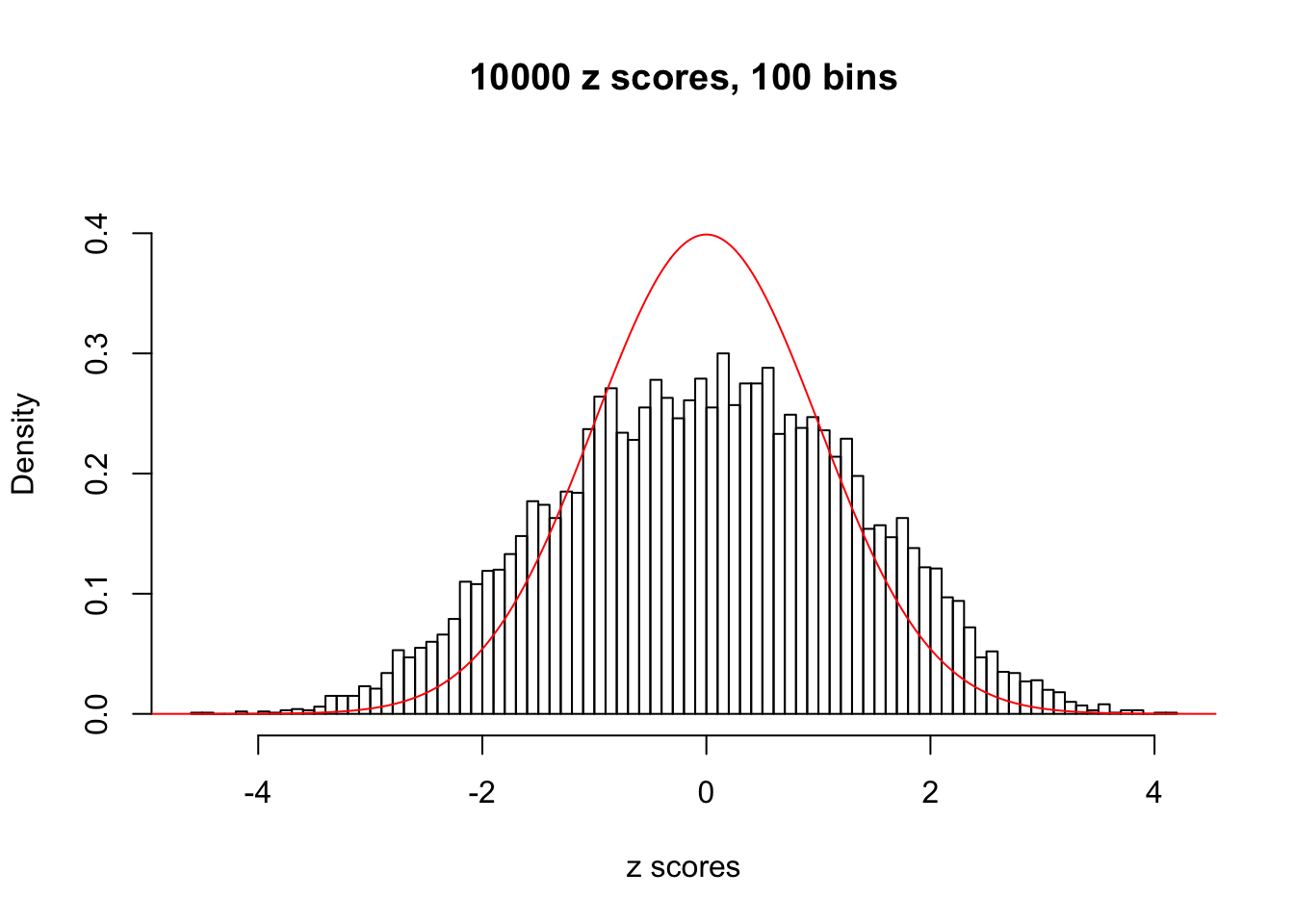
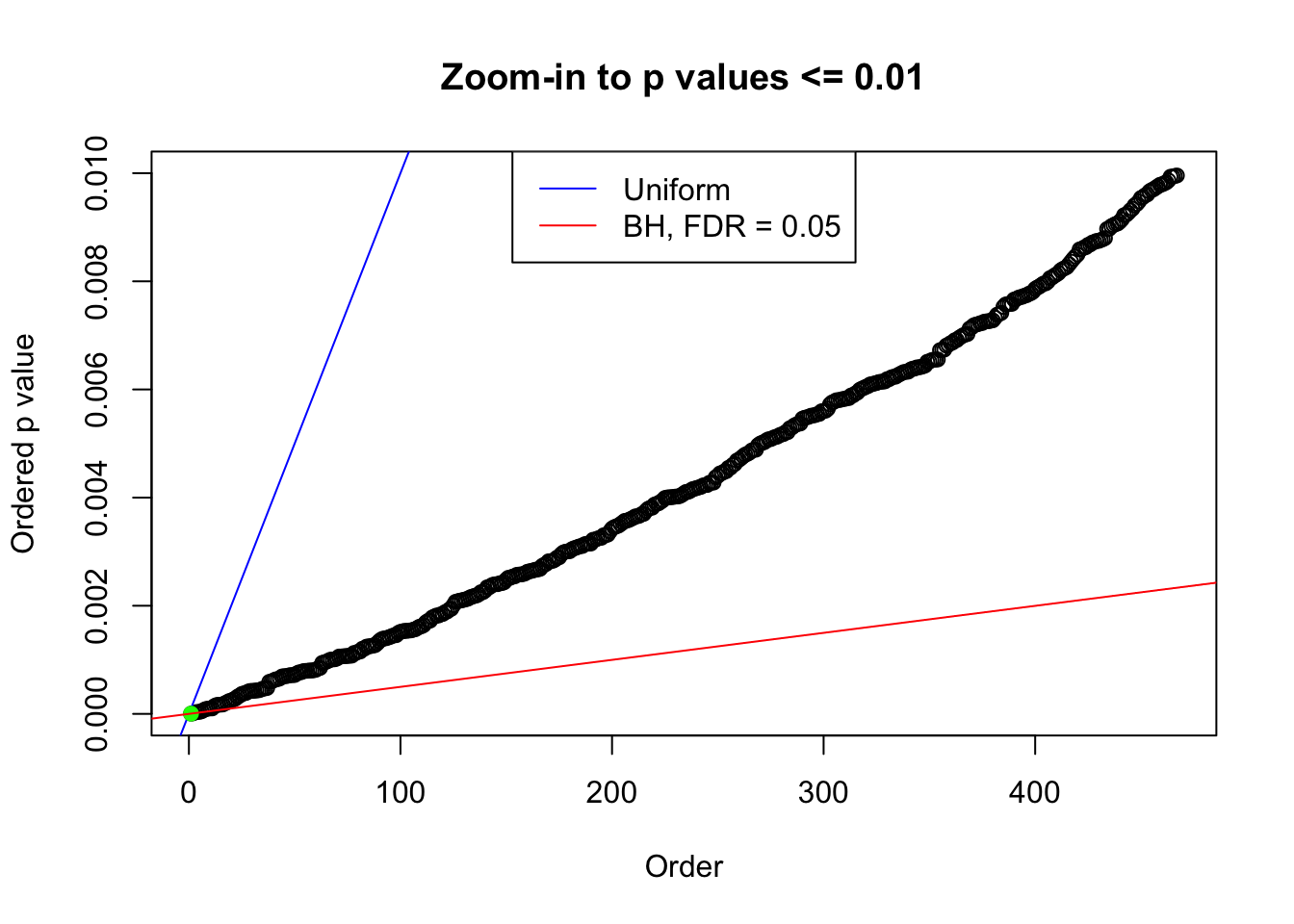
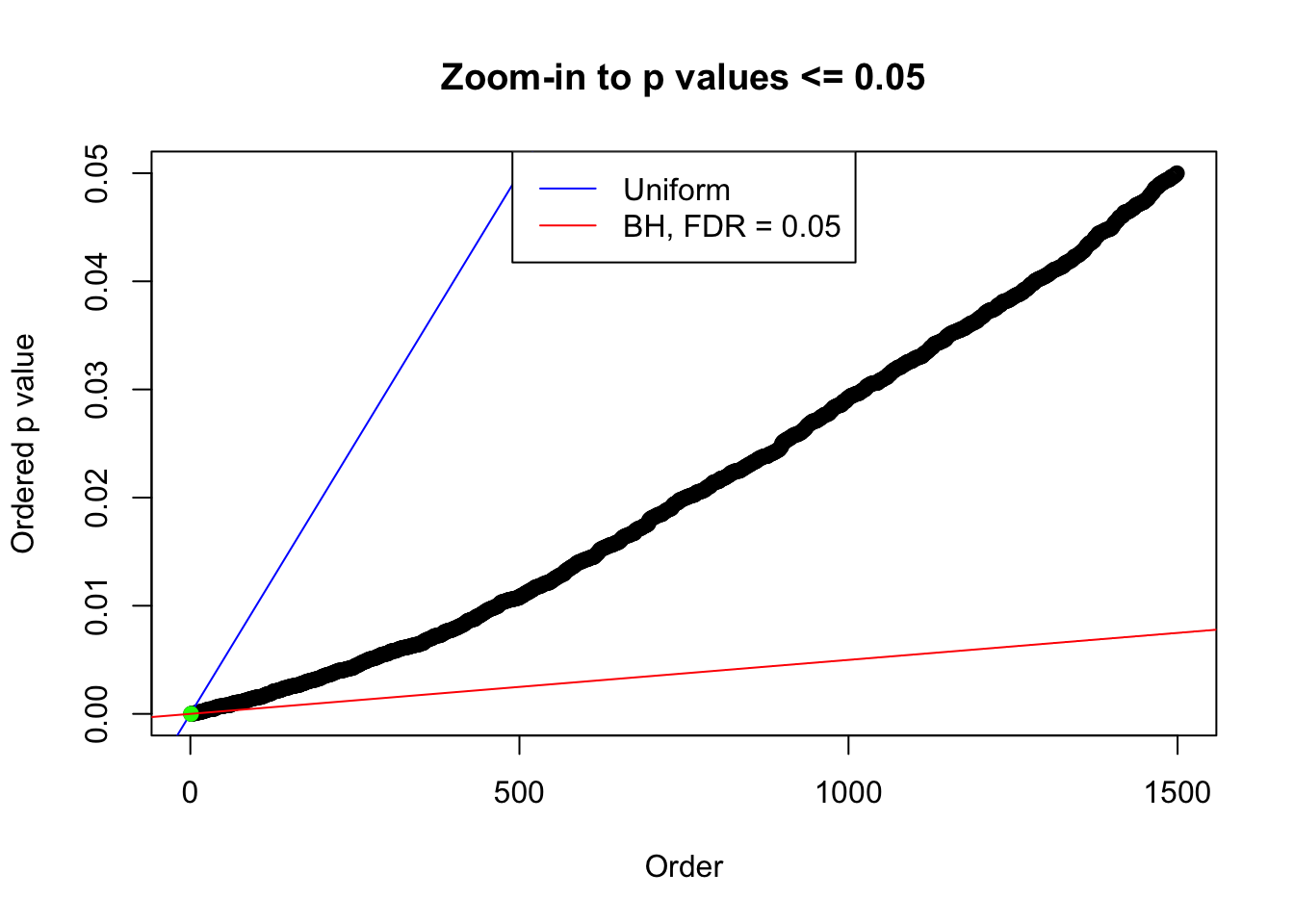
N0. 40 : Data Set 817 ; Number of False Discoveries: 1 ; pihat0 = 0.999989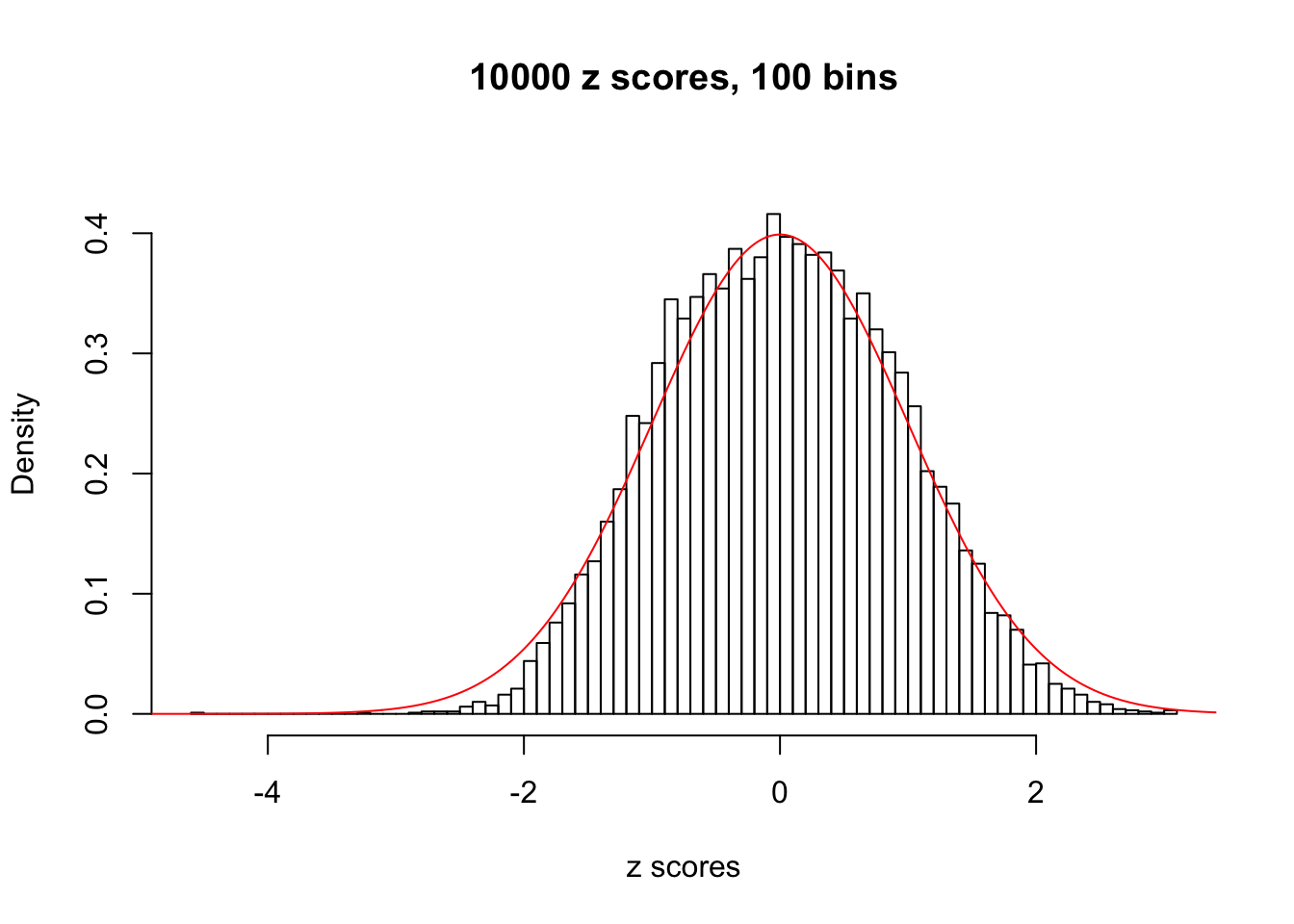
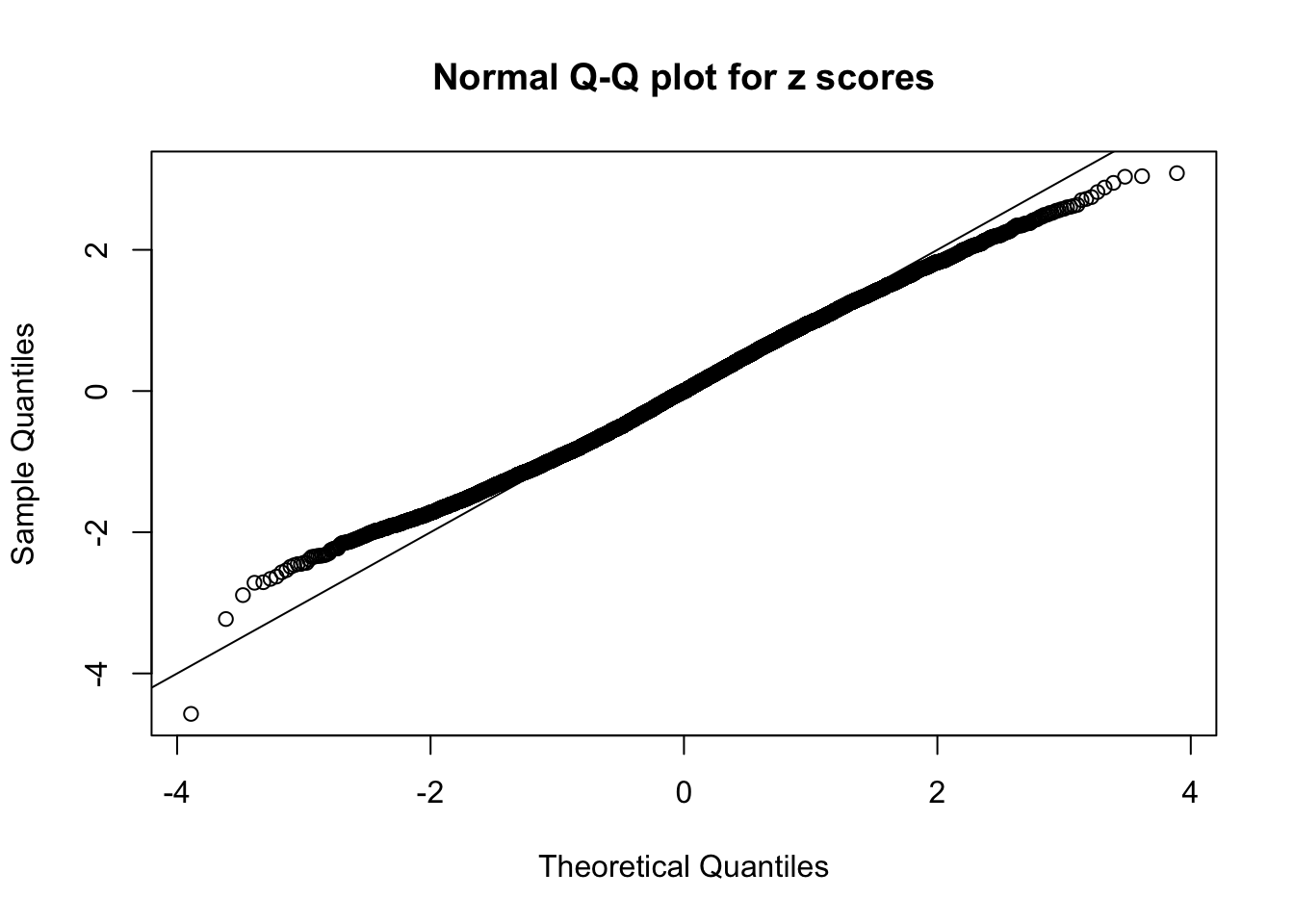
N0. 41 : Data Set 837 ; Number of False Discoveries: 1 ; pihat0 = 0.8625374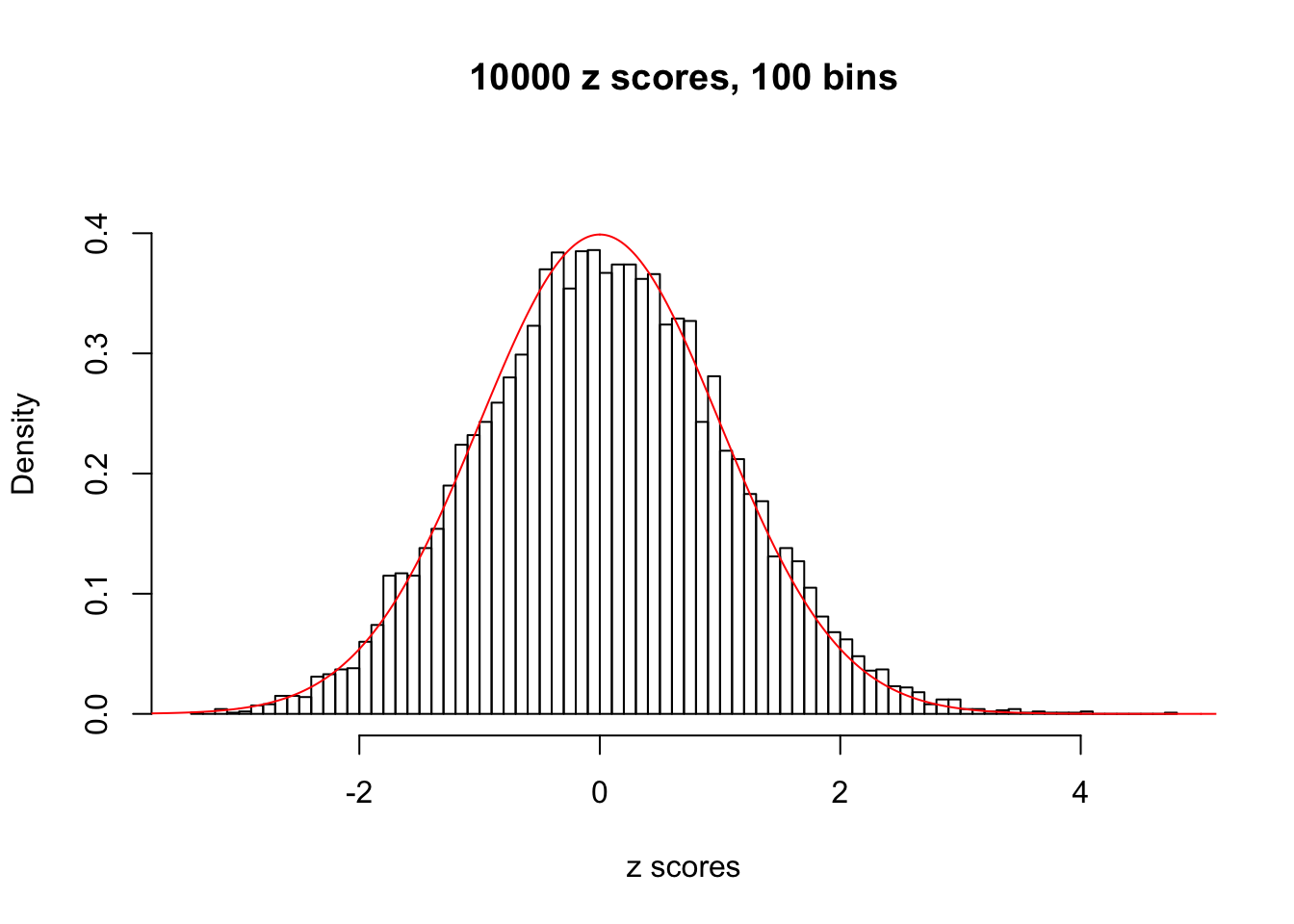
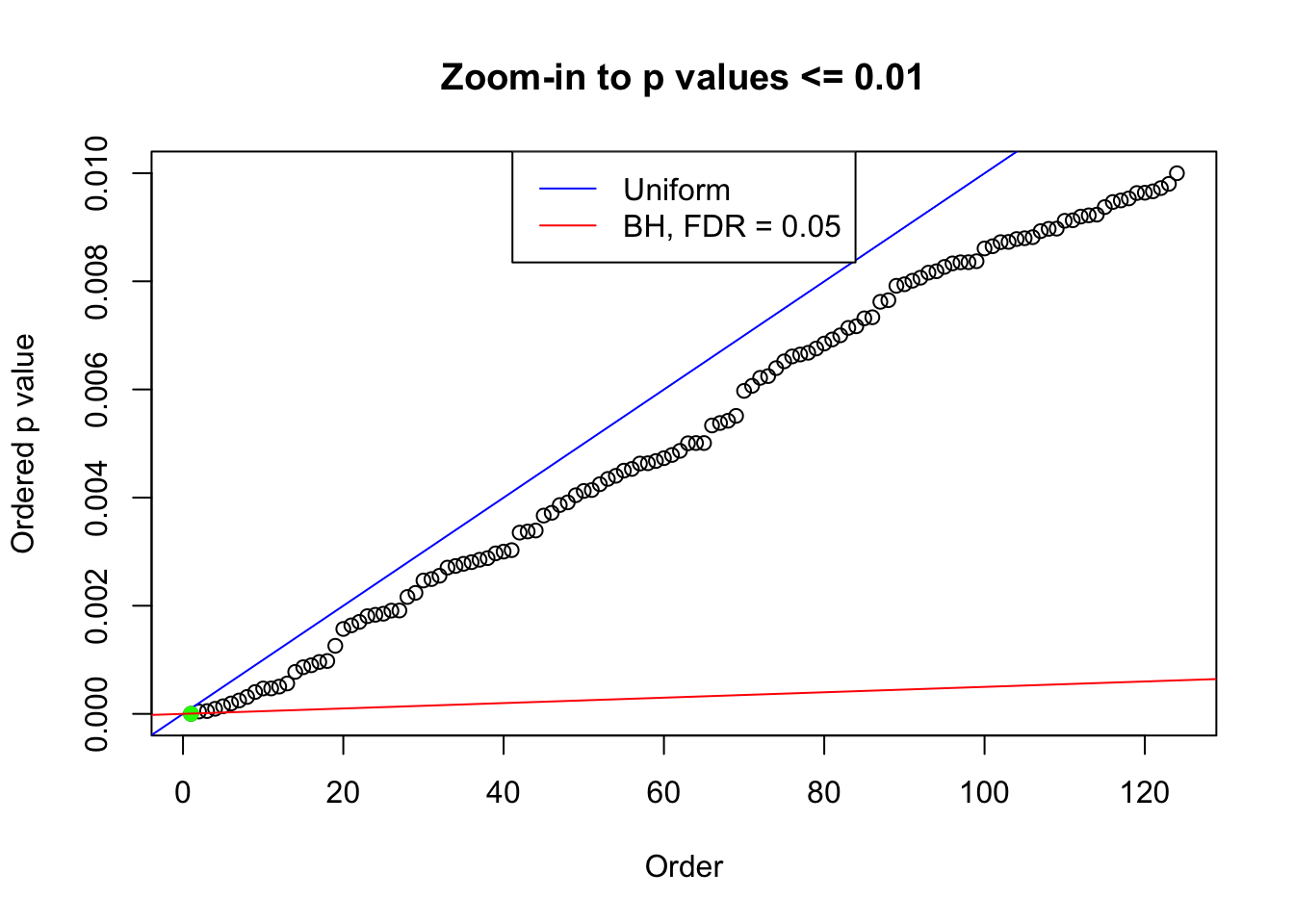
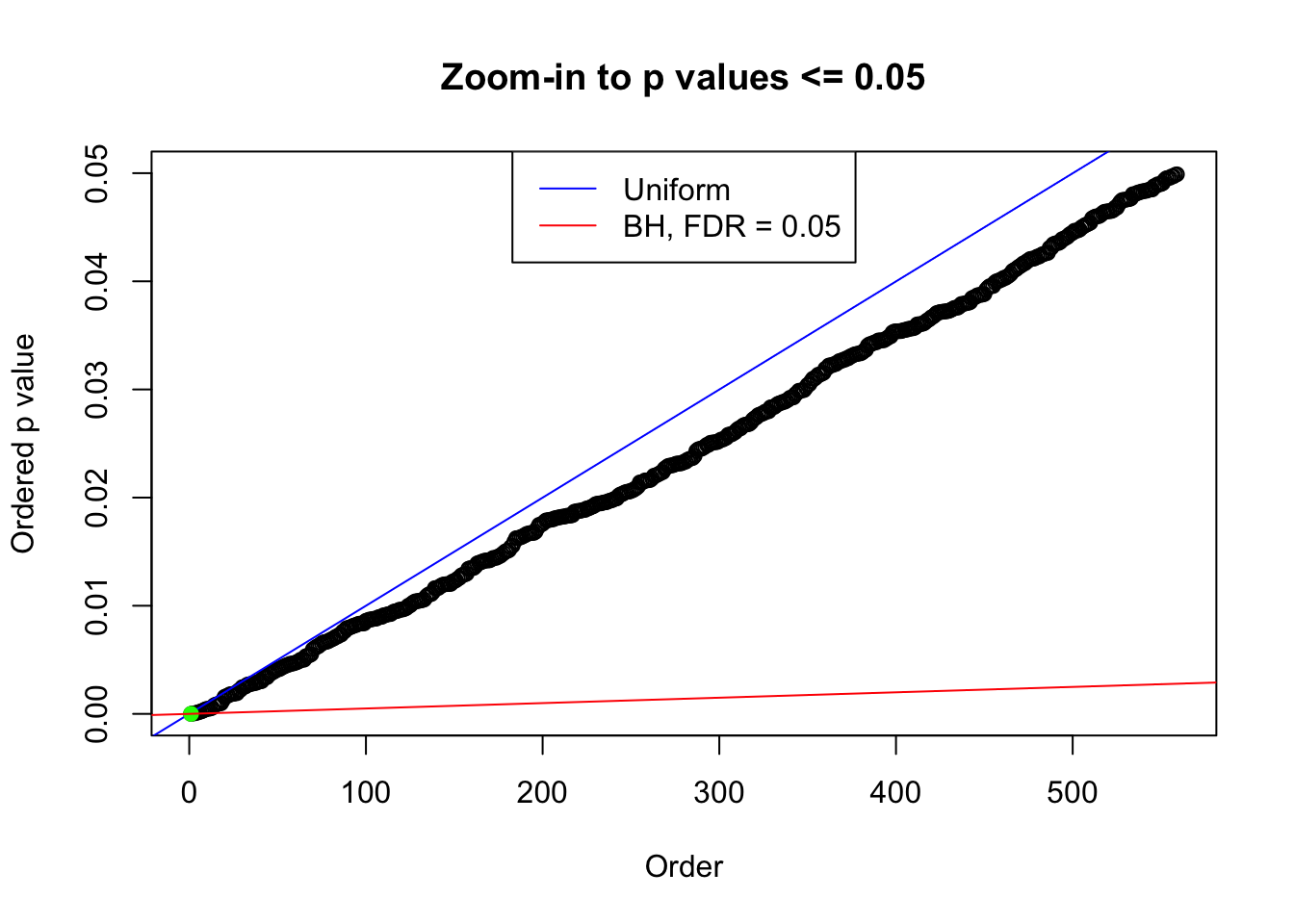
N0. 42 : Data Set 897 ; Number of False Discoveries: 1 ; pihat0 = 0.8465903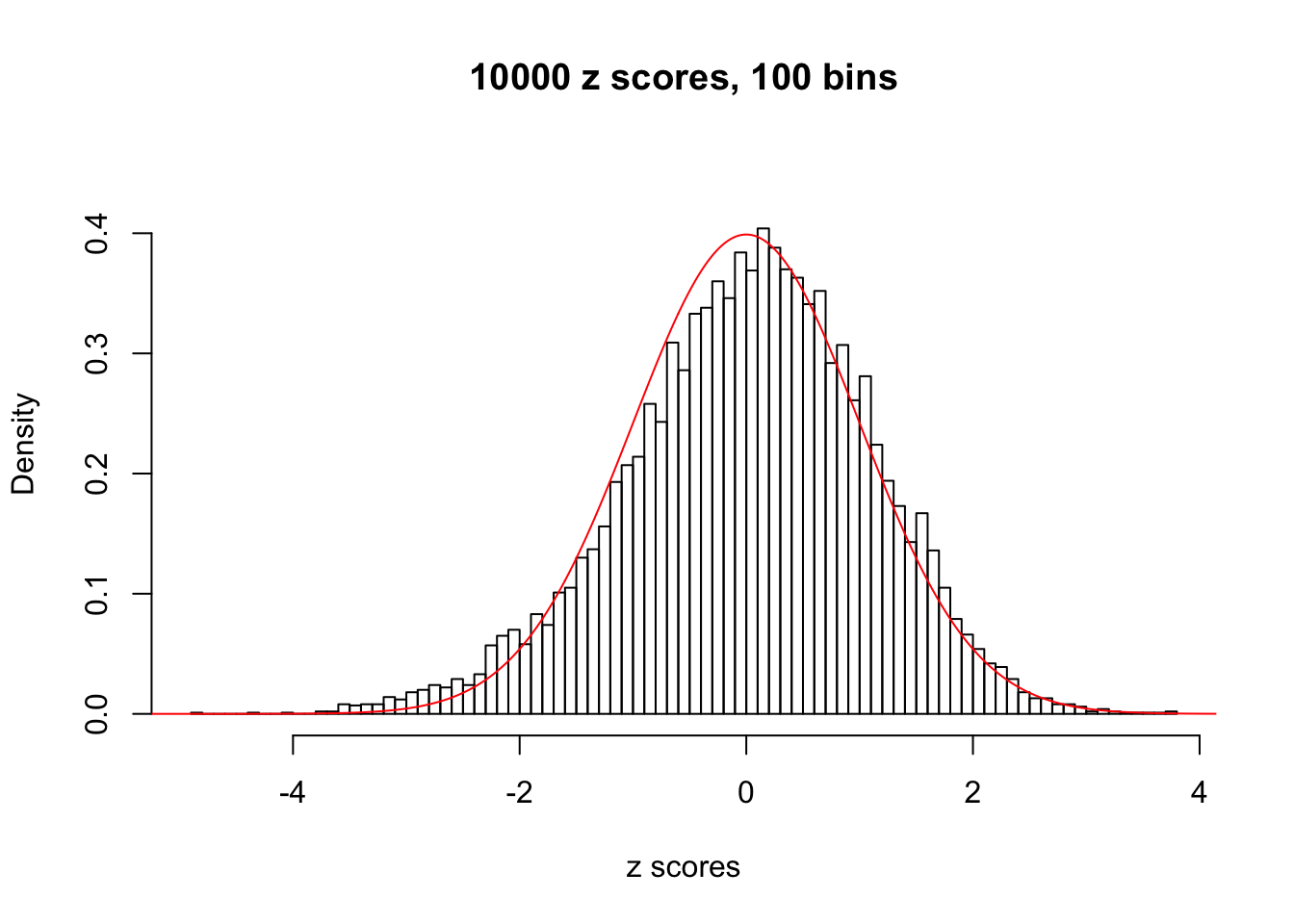
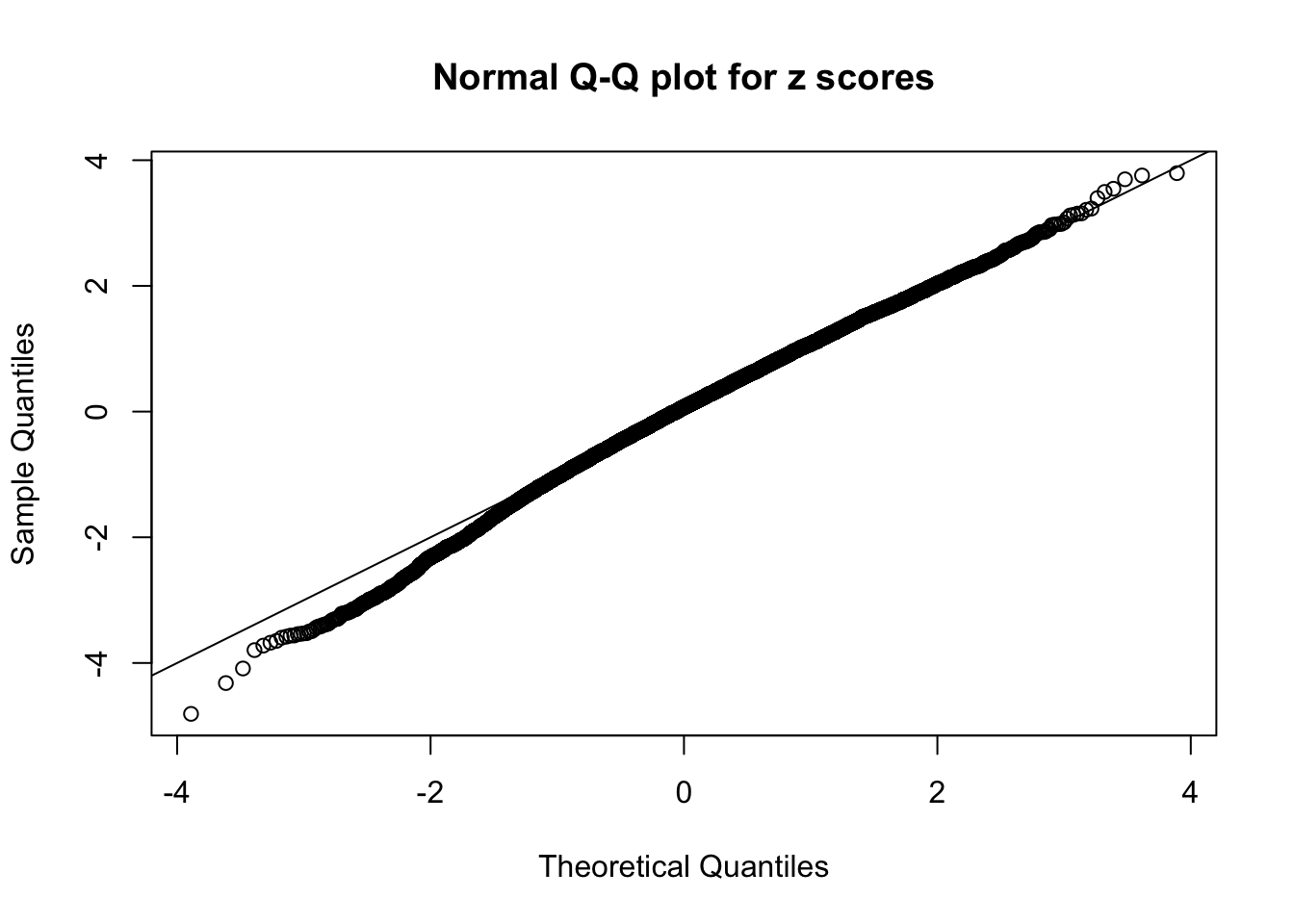
N0. 43 : Data Set 923 ; Number of False Discoveries: 1 ; pihat0 = 0.03239883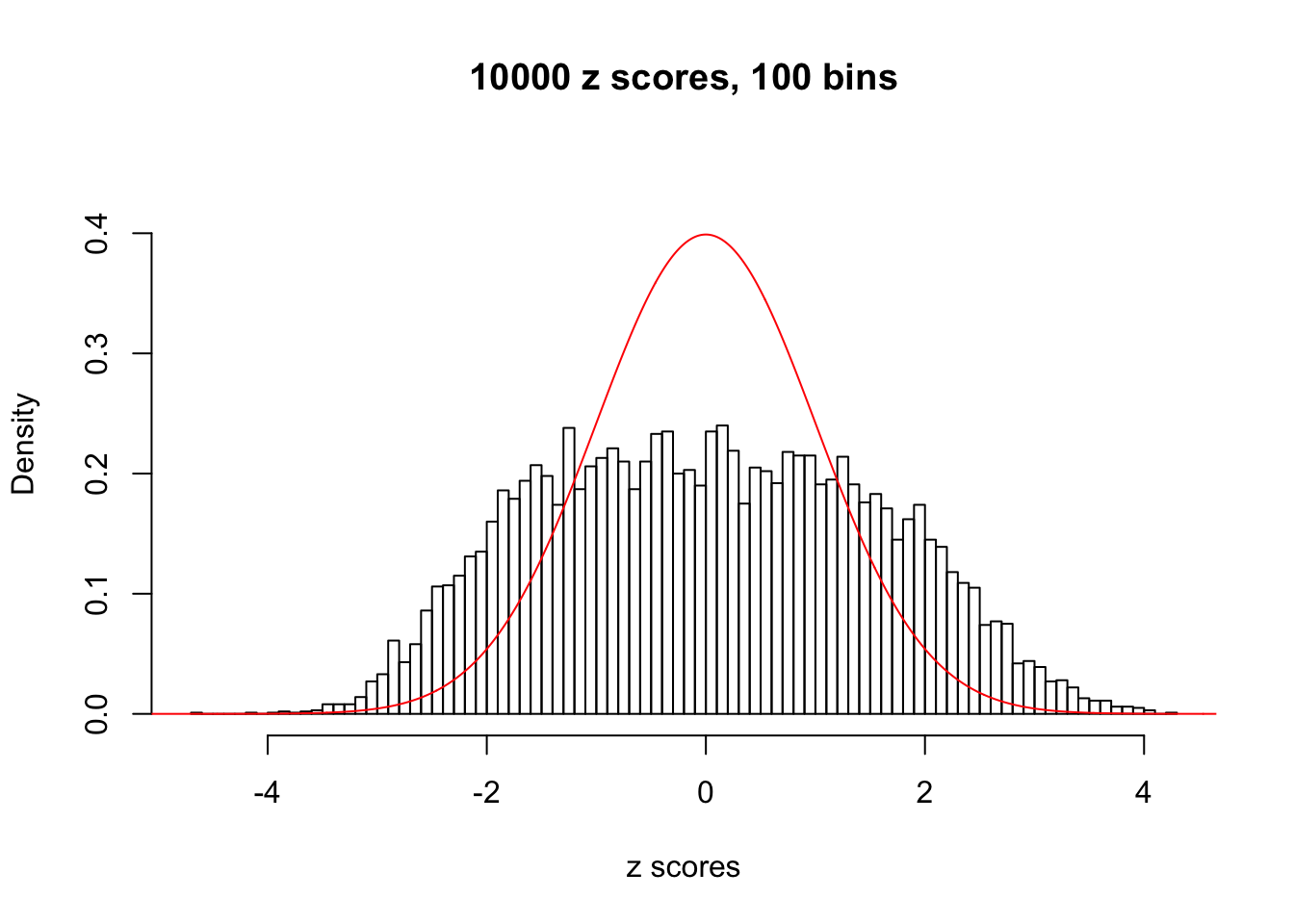
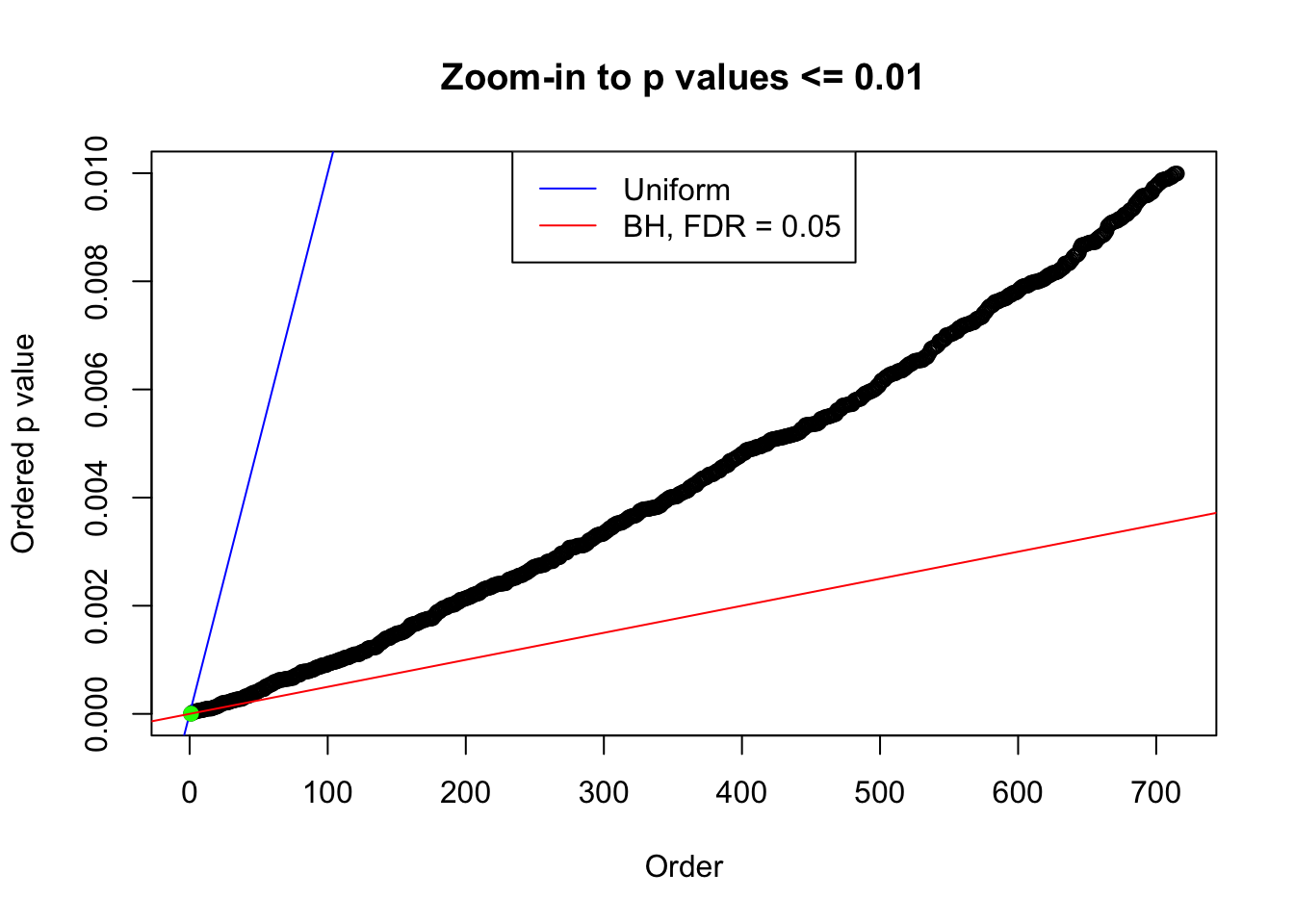
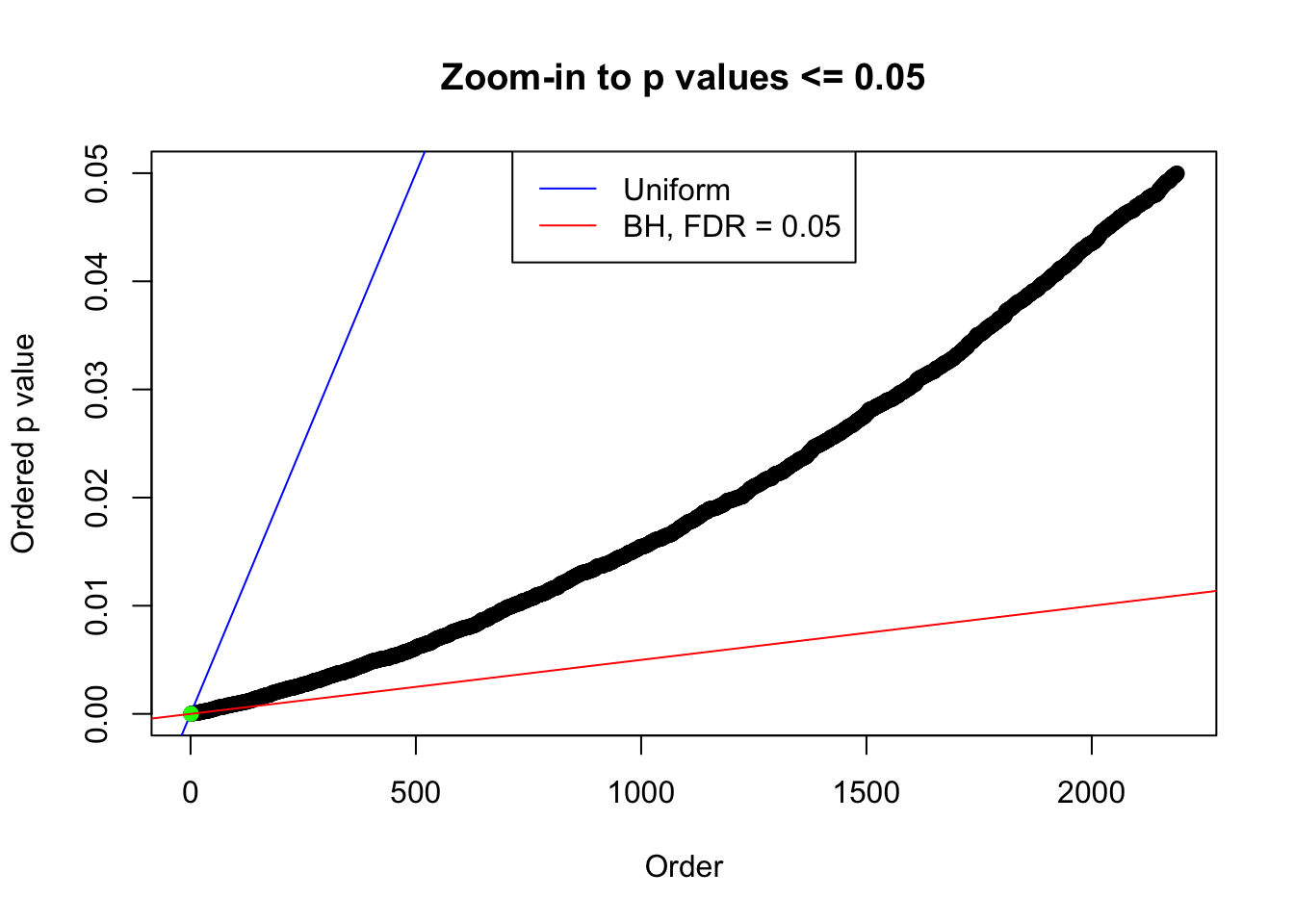
N0. 44 : Data Set 955 ; Number of False Discoveries: 1 ; pihat0 = 0.999845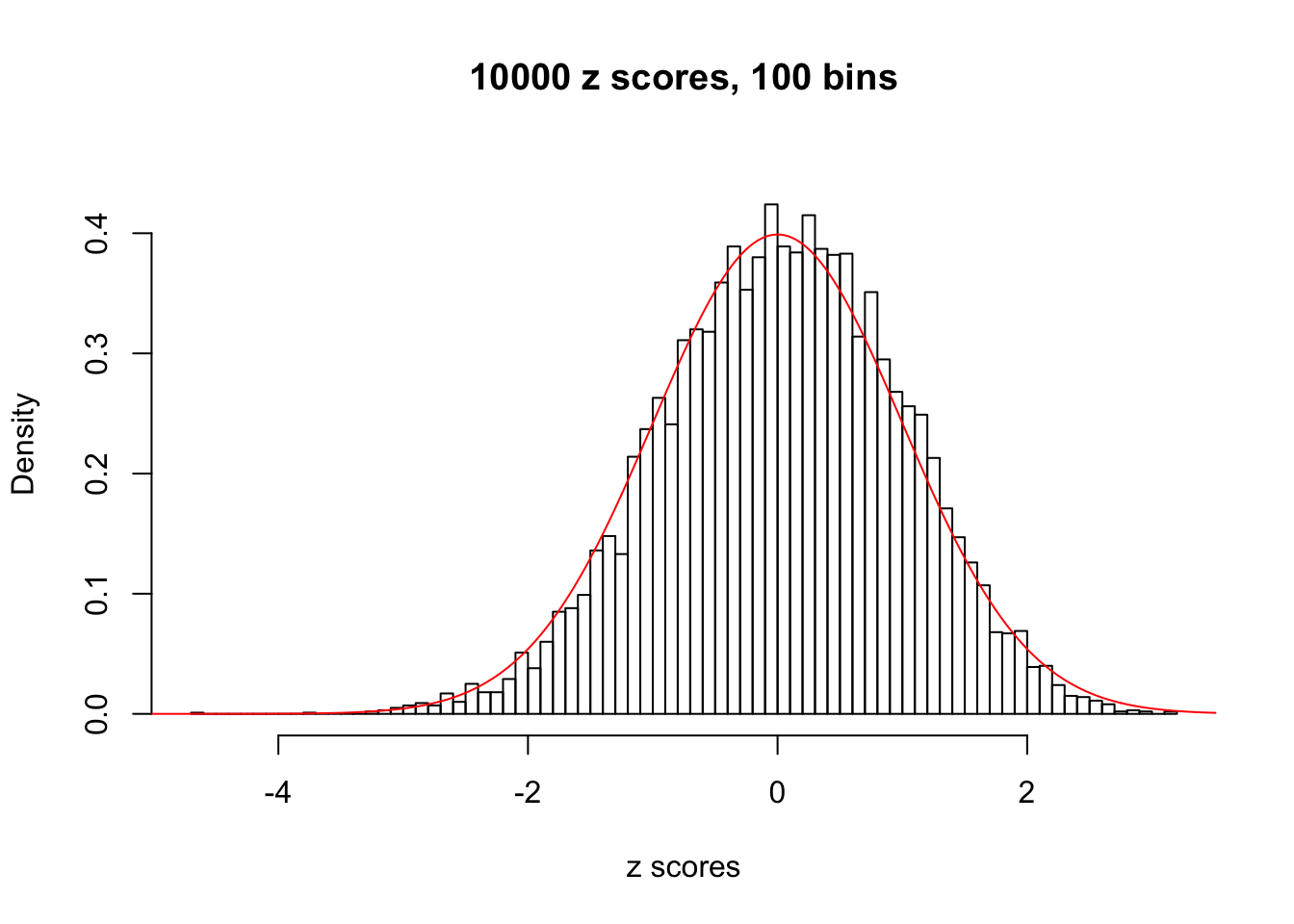
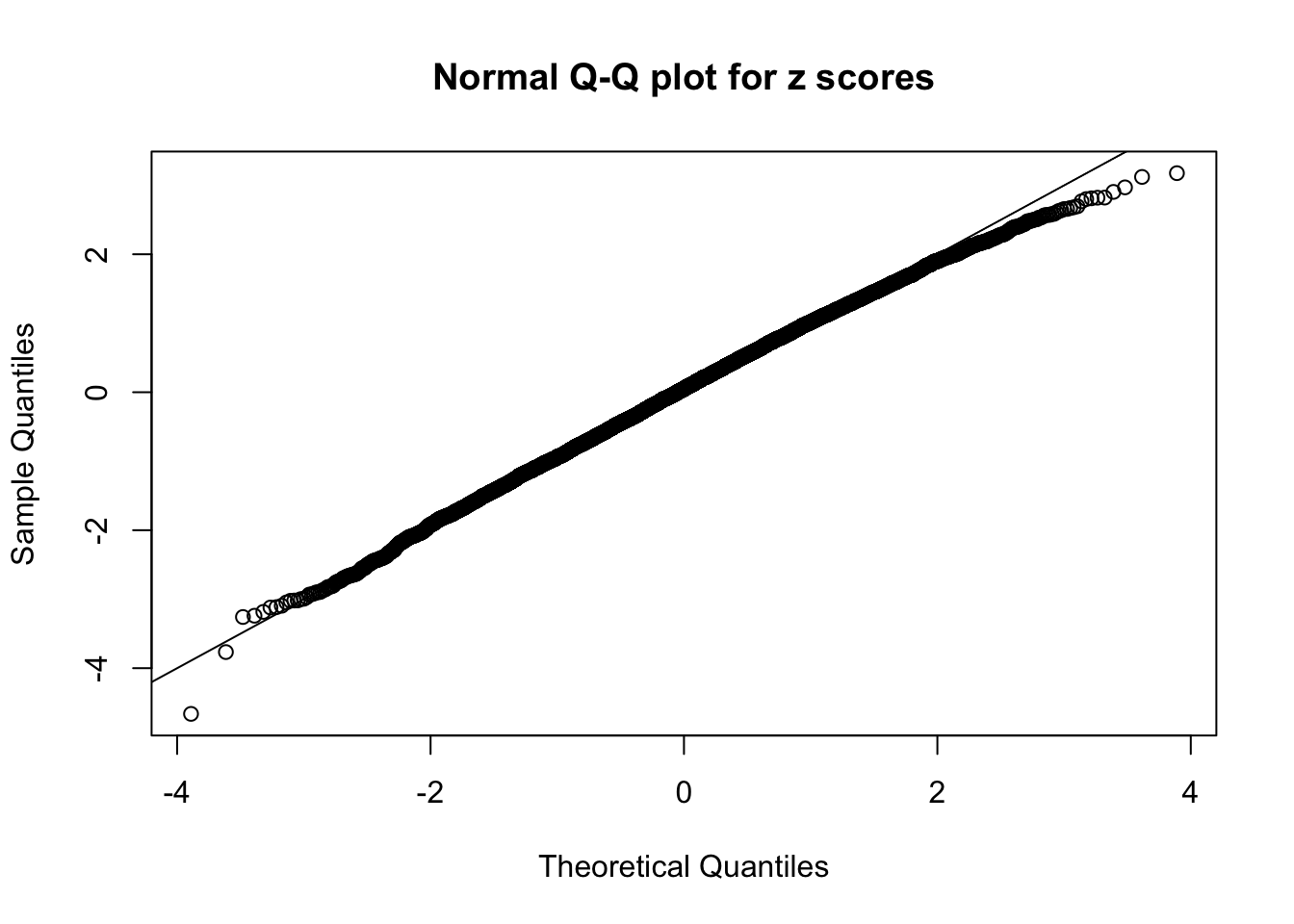
N0. 45 : Data Set 971 ; Number of False Discoveries: 1 ; pihat0 = 0.2387909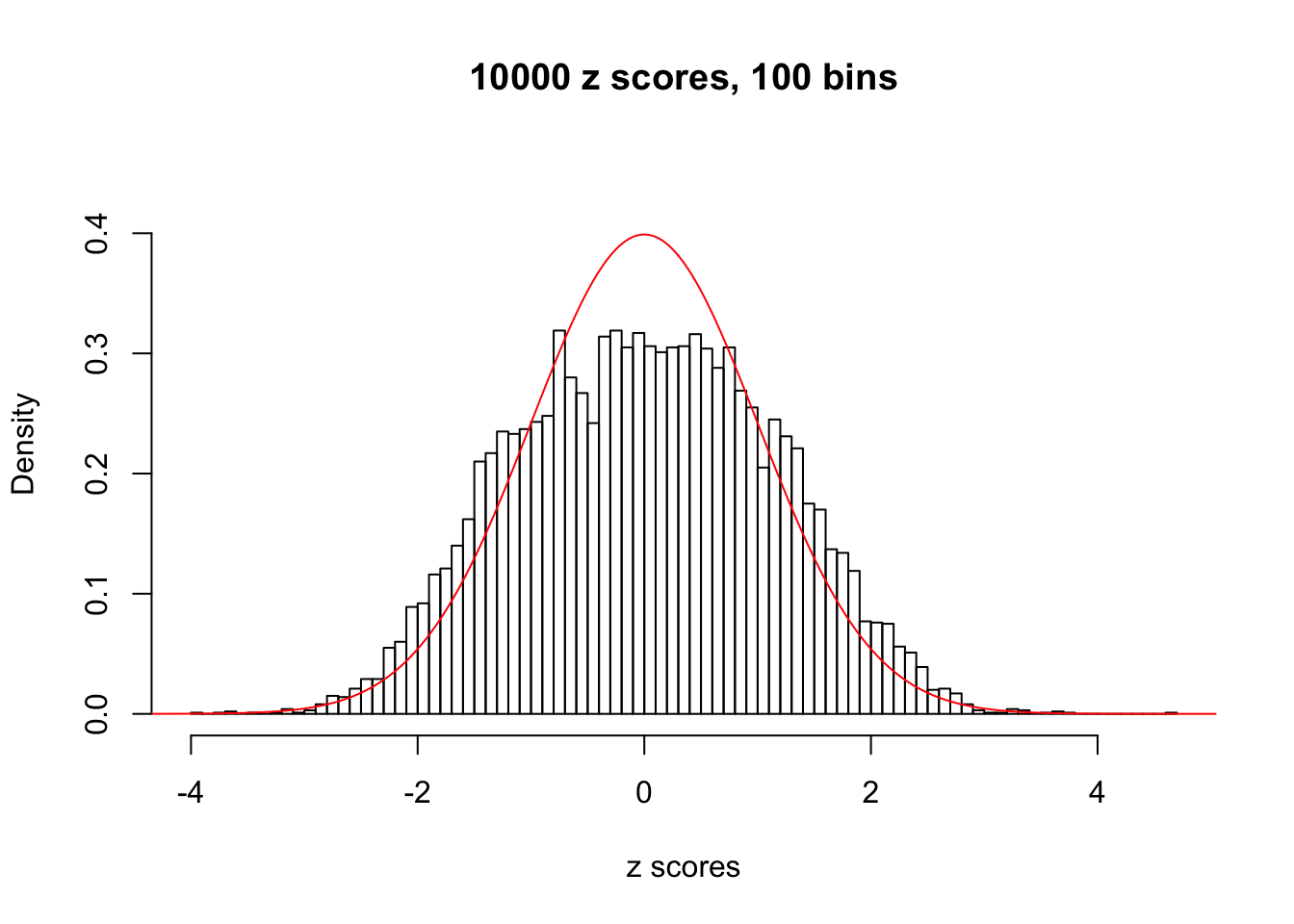
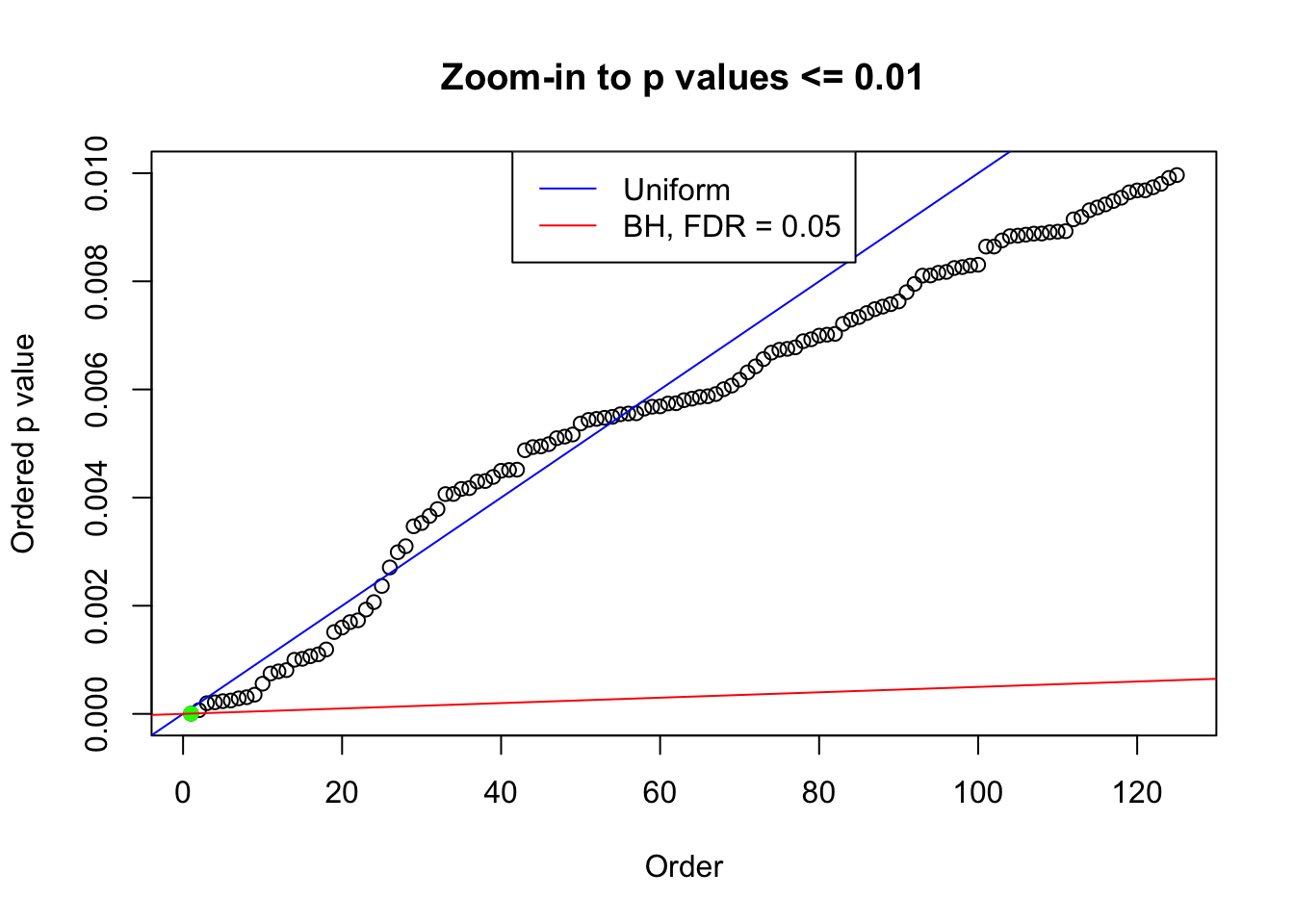
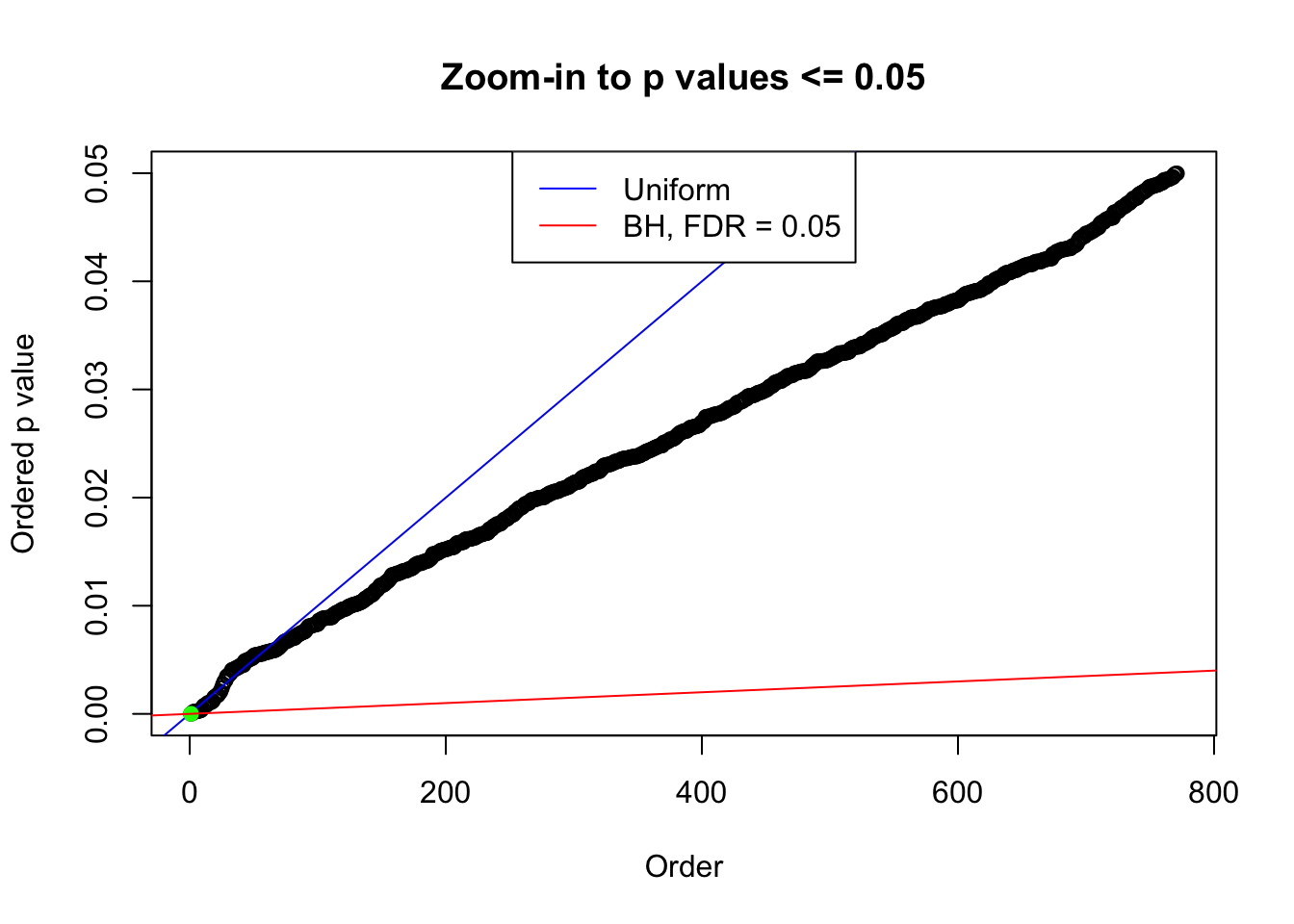
N0. 46 : Data Set 997 ; Number of False Discoveries: 1 ; pihat0 = 0.09560788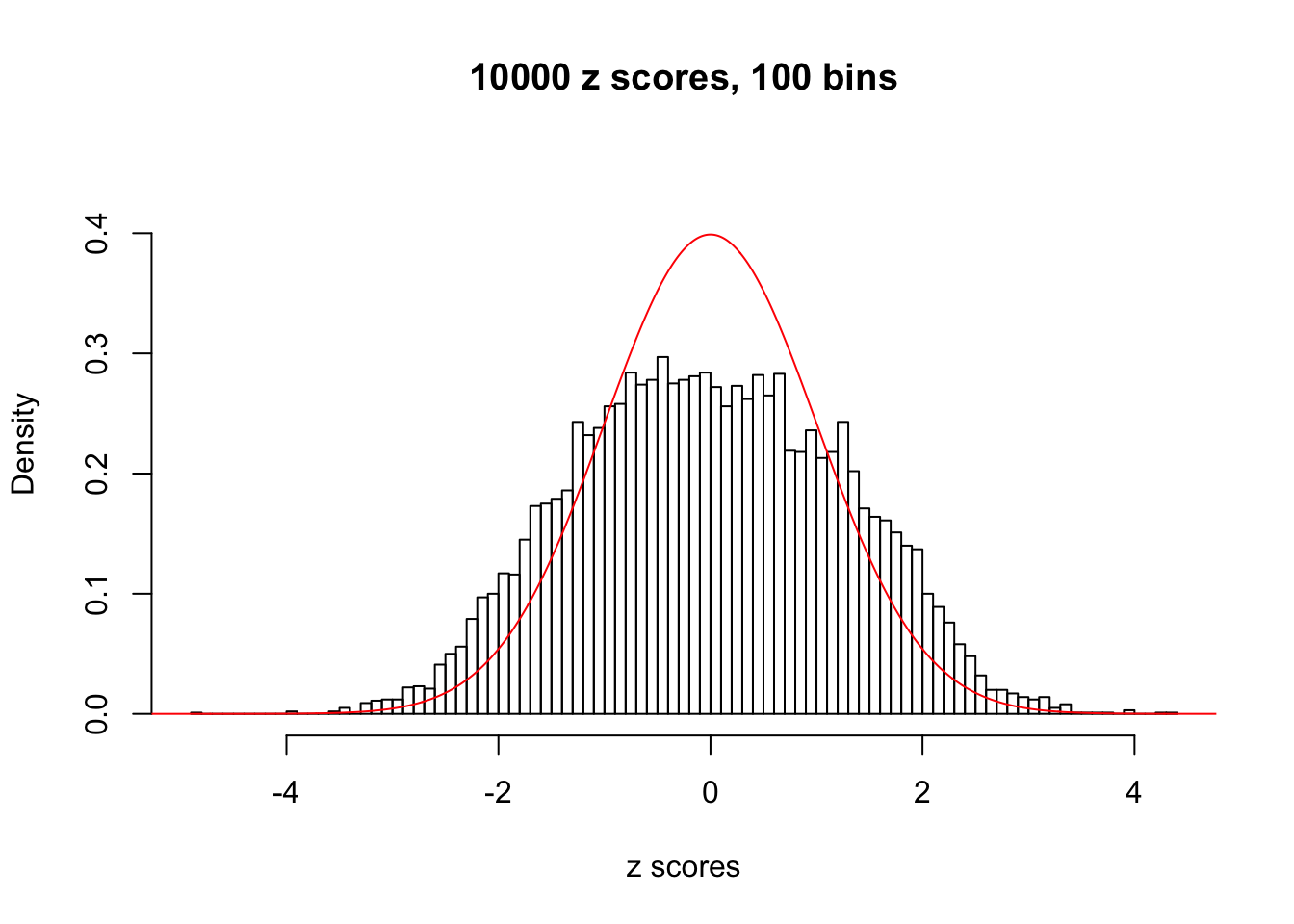
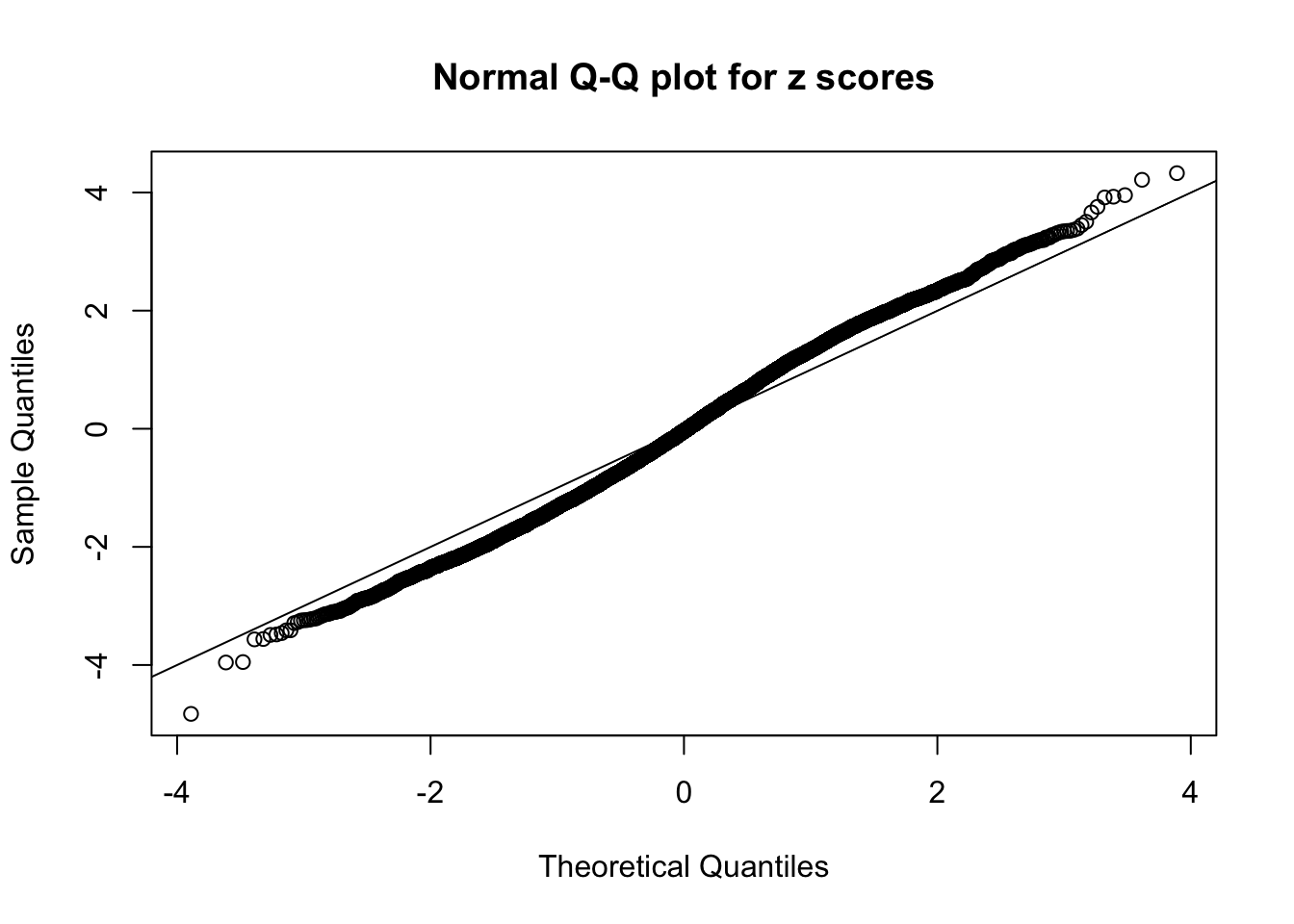
Session Information
sessionInfo()R version 3.3.2 (2016-10-31)
Platform: x86_64-apple-darwin13.4.0 (64-bit)
Running under: macOS Sierra 10.12.3
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
attached base packages:
[1] stats graphics grDevices utils datasets methods base
loaded via a namespace (and not attached):
[1] backports_1.0.5 magrittr_1.5 rprojroot_1.2 tools_3.3.2
[5] htmltools_0.3.5 yaml_2.1.14 Rcpp_0.12.9 stringi_1.1.2
[9] rmarkdown_1.3 knitr_1.15.1 git2r_0.18.0 stringr_1.1.0
[13] digest_0.6.9 workflowr_0.3.0 evaluate_0.10 This R Markdown site was created with workflowr